
阿里-測試開發(fā)面經(jīng)(三)
點擊藍字關(guān)注我們,獲取更多面經(jīng)

一、什么是死鎖
死鎖是指多個進程因競爭資源而造成的一種僵局(互相等待),若無外力作用,這些進程都將無法向前推進。例如,在某一個計算機系統(tǒng)中只有一臺打印機和一臺輸入 設(shè)備,進程P1正占用輸入設(shè)備,同時又提出使用打印機的請求,但此時打印機正被進程P2 所占用,而P2在未釋放打印機之前,又提出請求使用正被P1占用著的輸入設(shè)備。這樣兩個進程相互無休止地等待下去,均無法繼續(xù)執(zhí)行,此時兩個進程陷入死鎖狀態(tài)。
二、死鎖產(chǎn)生的原因
1. 系統(tǒng)資源的競爭
系統(tǒng)資源的競爭導(dǎo)致系統(tǒng)資源不足,以及資源分配不當(dāng),導(dǎo)致死鎖。
2. 進程運行推進順序不合適
進程在運行過程中,請求和釋放資源的順序不當(dāng),會導(dǎo)致死鎖。
三、死鎖的四個必要條件
互斥條件:一個資源每次只能被一個進程使用,即在一段時間內(nèi)某 資源僅為一個進程所占有。此時若有其他進程請求該資源,則請求進程只能等待。
請求與保持條件:進程已經(jīng)保持了至少一個資源,但又提出了新的資源請求,而該資源 已被其他進程占有,此時請求進程被阻塞,但對自己已獲得的資源保持不放。
不可剝奪條件:進程所獲得的資源在未使用完畢之前,不能被其他進程強行奪走,即只能 由獲得該資源的進程自己來釋放(只能是主動釋放)。
循環(huán)等待條件: 若干進程間形成首尾相接循環(huán)等待資源的關(guān)系
這四個條件是死鎖的必要條件,只要系統(tǒng)發(fā)生死鎖,這些條件必然成立,而只要上述條件之一不滿足,就不會發(fā)生死鎖。
四、 死鎖的避免與預(yù)防
1. 死鎖避免
死鎖避免的基本思想:系統(tǒng)對進程發(fā)出的每一個系統(tǒng)能夠滿足的資源申請進行動態(tài)檢查,并根據(jù)檢查結(jié)果決定是否分配資源,如果分配后系統(tǒng)可能發(fā)生死鎖,則不予分配,否則予以分配,這是一種保證系統(tǒng)不進入死鎖狀態(tài)的動態(tài)策略。
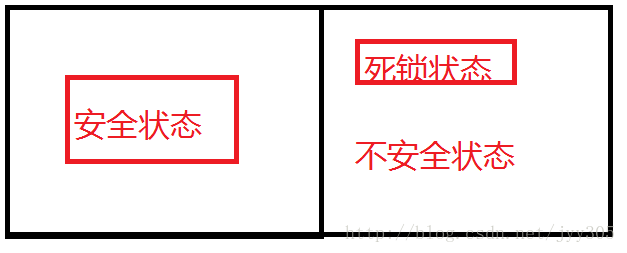
如果操作系統(tǒng)能保證所有進程在有限時間內(nèi)得到需要的全部資源,則系統(tǒng)處于安全狀態(tài)否則系統(tǒng)是不安全的。
安全狀態(tài)是指:如果系統(tǒng)存在所有的安全序列{P1,P2,…Pn},則系統(tǒng)處于安全狀態(tài)。一個進程序列是安全的,如果對其中每一個進程Pi(i >=1 && i <= n)他以后尚需要的資源不超過系統(tǒng)當(dāng)前剩余資源量與所有進程Pj(j < i)當(dāng)前占有資源量之和,系統(tǒng)處于安全狀態(tài)則不會發(fā)生死鎖。
不安全狀態(tài):如果不存在任何一個安全序列,則系統(tǒng)處于不安全狀態(tài)。他們之間的對對應(yīng)關(guān)系如下圖所示:
下面我們來通過一個例子對安全狀態(tài)和不安全狀態(tài)進行更深的了解
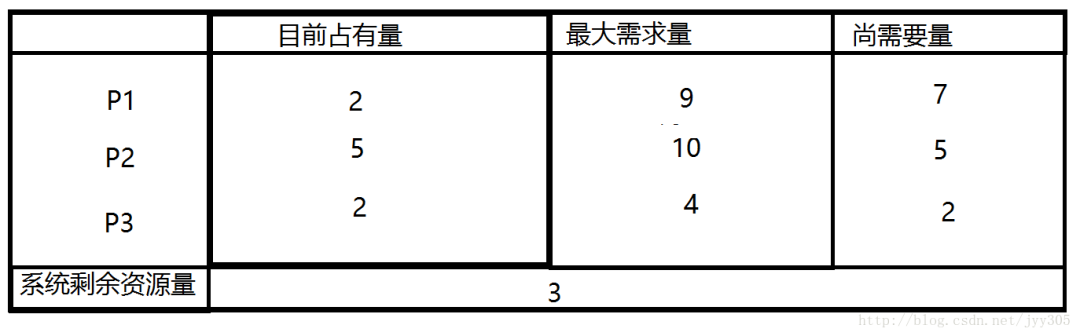
如上圖所示系統(tǒng)處于安全狀態(tài),系統(tǒng)剩余3個資源,可以把其中的2個分配給P3,此時P3已經(jīng)獲得了所有的資源,執(zhí)行完畢后還能還給系統(tǒng)4個資源,此時系統(tǒng)剩余5個資源所以滿足(P2所需的資源不超過系統(tǒng)當(dāng)前剩余量與P3當(dāng)前占有資源量之和),同理P1也可以在P2執(zhí)行完畢后獲得自己需要的資源。
如果P1提出再申請一個資源的要求,系統(tǒng)從剩余的資源中分配一個給進程P1,此時系統(tǒng)剩余2個資源,新的狀態(tài)圖如下:那么是否仍是安全序列呢那我們來分析一下
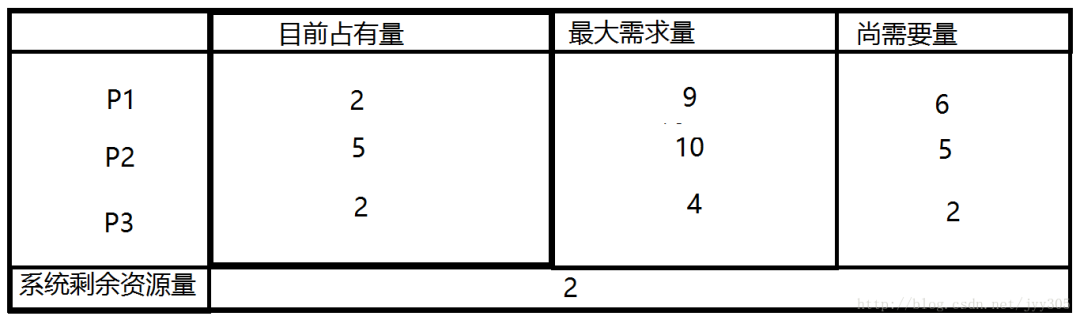
系統(tǒng)當(dāng)前剩余2個資源,分配給P3后P3執(zhí)行完畢還給系統(tǒng)4個資源,但是P2需要5個資源,P1需要6個資源,他們都無法獲得資源執(zhí)行完成,因此找不到一個安全序列。此時系統(tǒng)轉(zhuǎn)到了不安全狀態(tài)。
2. 死鎖預(yù)防
我們可以通過破壞死鎖產(chǎn)生的4個必要條件來 預(yù)防死鎖,由于資源互斥是資源使用的固有特性是無法改變的。
破壞“不可剝奪”條件:一個進程不能獲得所需要的全部資源時便處于等待狀態(tài),等待期間他占有的資源將被隱式的釋放重新加入到 系統(tǒng)的資源列表中,可以被其他的進程使用,而等待的進程只有重新獲得自己原有的資源以及新申請的資源才可以重新啟動,執(zhí)行。
破壞”請求與保持條件“:第一種方法靜態(tài)分配即每個進程在開始執(zhí)行時就申請他所需要的全部資源。第二種是動態(tài)分配即每個進程在申請所需要的資源時他本身不占用系統(tǒng)資源。
破壞“循環(huán)等待”條件:采用資源有序分配其基本思想是將系統(tǒng)中的所有資源順序編號,將緊缺的,稀少的采用較大的編號,在申請資源時必須按照編號的順序進行,一個進程只有獲得較小編號的進程才能申請較大編號的進程。
宏觀:
1.緩存。在持久層或持久層之上做緩存。從數(shù)據(jù)庫中查詢出來的數(shù)據(jù)先放入緩存中,下次查詢時,先訪問緩存。假設(shè)未命中則查詢數(shù)據(jù)庫。
2.表分區(qū)和拆分.不管是業(yè)務(wù)邏輯上的拆分還是無業(yè)務(wù)含義的分區(qū)。
3.提高磁盤速度.這包含RAID和其它磁盤文件分段的處理。基本的思想是提高磁盤的并發(fā)度(多個物理磁盤存放同一個文件)。
微觀:
表設(shè)計方面:
1.字段冗余.降低跨庫查詢和大表連接操作。
2.數(shù)據(jù)庫表的大字段剝離.保證單條記錄的數(shù)據(jù)量非常小。
3.恰當(dāng)?shù)厥褂盟饕? 甚至是多級索引。
查詢優(yōu)化方面:
2.應(yīng)盡量避免在 where 子句中對字段進行 null 值推斷,否則將導(dǎo)致引擎放棄使用索引而進行全表掃描,如:
select id from t where num is null
能夠在num上設(shè)置默認值0,確保表中num列沒有null值。然后這樣查詢:
select id from t where num=0
3.應(yīng)盡量避免在 where 子句中使用!=或<>操作符。否則將引擎放棄使用索引而進行全表掃描。
4.應(yīng)盡量避免在 where 子句中使用 or 來連接條件,否則將導(dǎo)致引擎放棄使用索引而進行全表掃描,如:
select id from t where num=10 or num=20能夠這樣查詢:
select id from t where num=10 union all select id from t where num=20
5.in 和 not in 也要慎用,否則會導(dǎo)致全表掃描。如:
select id from t where num in(1,2,3)
對于連續(xù)的數(shù)值,能用 between 就不要用 in 了:
select id from t where num between 1 and 3
6.以下的查詢也將導(dǎo)致全表掃描:
select id from t where name like '%abc%' 若要提高效率,能夠考慮全文檢索。
7.索引并非越多越好,索引固然能夠提高對應(yīng)的 select 的效率,但同一時候也減少了 insert 及 update 的效率,由于 insert 或 update 時有可能會重建索引。所以如何建索引需要謹慎考慮,視詳細情況而定。一個表的索引數(shù)最好不要超過6個。若太多則應(yīng)考慮一些不常使用到的列上建的索引是否有 必要。
8.盡量使用數(shù)字型字段,若僅僅含數(shù)值信息的字段盡量不要設(shè)計為字符型,這會減少查詢和連接的性能,并會添加存儲開銷。這是由于引擎在處理查詢和連接時會逐個比較字符串中每個字符,而對于數(shù)字型而言僅僅需要比較一次就夠了。
9.不論什么地方都不要使用 select * from t ,用詳細的字段列表取代“*”,不要返回用不到的不論什么字段。
10.避免頻繁創(chuàng)建和刪除暫時表,以降低系統(tǒng)表資源的消耗。
如何優(yōu)化數(shù)據(jù)庫,如何提高數(shù)據(jù)庫的性能?
1) 硬件調(diào)整性能
最有可能影響性能的是磁盤和網(wǎng)絡(luò)吞吐量,解決辦法擴大虛擬內(nèi)存,并保證有足夠可以擴充的空間;把數(shù)據(jù)庫服務(wù)器上的不必要服務(wù)關(guān)閉掉;把數(shù)據(jù)庫服務(wù)器和主域服務(wù)器分開;把SQL數(shù)據(jù)庫服務(wù)器的吞吐量調(diào)為最大;在具有一個以上處理器的機器上運行SQL。
2)調(diào)整數(shù)據(jù)庫
若對該表的查詢頻率比較高,則建立索引;建立索引時,想盡對該表的所有查詢搜索操作, 按照where選擇條件建立索引,盡量為整型鍵建立為有且只有一個簇集索引,數(shù)據(jù)在物理上按順序在數(shù)據(jù)頁上,縮短查找范圍,為在查詢經(jīng)常使用的全部列建立非簇集索引,能最大地覆蓋查詢;但是索引不可太多,執(zhí)行UPDATE DELETE INSERT語句需要用于維護這些索引的開銷量急劇增加;避免在索引中有太多的索引鍵;避免使用大型數(shù)據(jù)類型的列為索引;保證每個索引鍵值有少數(shù)行。
3)使用存儲過程
應(yīng)用程序的實現(xiàn)過程中,能夠采用存儲過程實現(xiàn)的對數(shù)據(jù)庫的操作盡量通過存儲過程來實現(xiàn),因為存儲過程是存放在數(shù)據(jù)庫服務(wù)器上的一次性被設(shè)計、編碼、測試,并被再次使用,需要執(zhí)行該任務(wù)的應(yīng)用可以簡單地執(zhí)行存儲過程,并且只返回結(jié)果集或者數(shù)值,這樣不僅可以使程序模塊化,同時提高響應(yīng)速度,減少網(wǎng)絡(luò)流量,并且通過輸入?yún)?shù)接受輸入,使得在應(yīng)用中完成邏輯的一致性實現(xiàn)。
更多面經(jīng)
掃描二維碼
獲取更多面經(jīng)
扶搖就業(yè)