
Redis 多線程網(wǎng)絡(luò)模型全面揭秘
導(dǎo)言
Redis 有多快?
Redis 為什么快?
Redis 為何選擇單線程?
避免過(guò)多的上下文切換開銷
避免同步機(jī)制的開銷
簡(jiǎn)單可維護(hù)
Redis 真的是單線程?
單線程事件循環(huán)
多線程異步任務(wù)
Redis 多線程網(wǎng)絡(luò)模型
設(shè)計(jì)思路
源碼剖析
性能提升
模型缺陷
總結(jié)
參考&延伸閱讀
References
導(dǎo)言
在目前的技術(shù)選型中,Redis 儼然已經(jīng)成為了系統(tǒng)高性能緩存方案的事實(shí)標(biāo)準(zhǔn),因此現(xiàn)在 Redis 也成為了后端開發(fā)的基本技能樹之一,Redis 的底層原理也順理成章地成為了必須學(xué)習(xí)的知識(shí)。
Redis 從本質(zhì)上來(lái)講是一個(gè)網(wǎng)絡(luò)服務(wù)器,而對(duì)于一個(gè)網(wǎng)絡(luò)服務(wù)器來(lái)說(shuō),網(wǎng)絡(luò)模型是它的精華,搞懂了一個(gè)網(wǎng)絡(luò)服務(wù)器的網(wǎng)絡(luò)模型,你也就搞懂了它的本質(zhì)。
本文通過(guò)層層遞進(jìn)的方式,介紹了 Redis 網(wǎng)絡(luò)模型的版本變更歷程,剖析了其從單線程進(jìn)化到多線程的工作原理,此外,還一并分析并解答了 Redis 的網(wǎng)絡(luò)模型的很多抉擇背后的思考,幫助讀者能更深刻地理解 Redis 網(wǎng)絡(luò)模型的設(shè)計(jì)。
Redis 有多快?
根據(jù)官方的 benchmark,通常來(lái)說(shuō),在一臺(tái)普通硬件配置的 Linux 機(jī)器上跑單個(gè) Redis 實(shí)例,處理簡(jiǎn)單命令(時(shí)間復(fù)雜度 O(N) 或者 O(log(N))),QPS 可以達(dá)到 8w+,而如果使用 pipeline 批處理功能,則 QPS 至高能達(dá)到 100w。
僅從性能層面進(jìn)行評(píng)判,Redis 完全可以被稱之為高性能緩存方案。
Redis 為什么快?
Redis 的高性能得益于以下幾個(gè)基礎(chǔ):
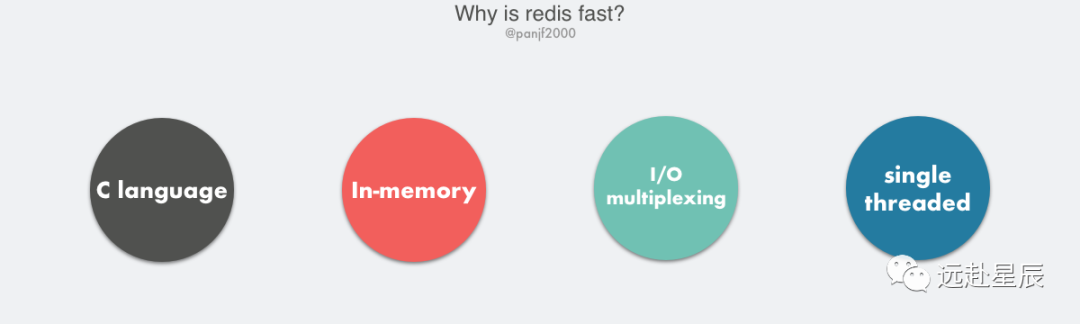
- C 語(yǔ)言實(shí)現(xiàn),雖然 C 對(duì) Redis 的性能有助力,但語(yǔ)言并不是最核心因素。
- 純內(nèi)存 I/O,相較于其他基于磁盤的 DB,Redis 的純內(nèi)存操作有著天然的性能優(yōu)勢(shì)。
- I/O 多路復(fù)用,基于 epoll/select/kqueue 等 I/O 多路復(fù)用技術(shù),實(shí)現(xiàn)高吞吐的網(wǎng)絡(luò) I/O。
- 單線程模型,單線程無(wú)法利用多核,但是從另一個(gè)層面來(lái)說(shuō)則避免了多線程頻繁上下文切換,以及同步機(jī)制如鎖帶來(lái)的開銷。
Redis 為何選擇單線程?
Redis 的核心網(wǎng)絡(luò)模型選擇用單線程來(lái)實(shí)現(xiàn),這在一開始就引起了很多人的不解,Redis 官方的對(duì)于此的回答是:
?It's not very frequent that CPU becomes your bottleneck with Redis, as usually Redis is either memory or network bound. For instance, using pipelining Redis running on an average Linux system can deliver even 1 million requests per second, so if your application mainly uses O(N) or O(log(N)) commands, it is hardly going to use too much CPU.
”
核心意思就是,對(duì)于一個(gè) DB 來(lái)說(shuō),CPU 通常不會(huì)是瓶頸,因?yàn)榇蠖鄶?shù)請(qǐng)求不會(huì)是 CPU 密集型的,而是 I/O 密集型。具體到 Redis 的話,如果不考慮 RDB/AOF 等持久化方案,Redis 是完全的純內(nèi)存操作,執(zhí)行速度是非常快的,因此這部分操作通常不會(huì)是性能瓶頸,Redis 真正的性能瓶頸在于網(wǎng)絡(luò) I/O,也就是客戶端和服務(wù)端之間的網(wǎng)絡(luò)傳輸延遲,因此 Redis 選擇了單線程的 I/O 多路復(fù)用來(lái)實(shí)現(xiàn)它的核心網(wǎng)絡(luò)模型。
上面是比較籠統(tǒng)的官方答案,實(shí)際上更加具體的選擇單線程的原因可以歸納如下:
避免過(guò)多的上下文切換開銷
多線程調(diào)度過(guò)程中必然需要在 CPU 之間切換線程上下文 context,而上下文的切換又涉及程序計(jì)數(shù)器、堆棧指針和程序狀態(tài)字等一系列的寄存器置換、程序堆棧重置甚至是高速緩存、TLB 快表的汰換,如果是進(jìn)程內(nèi)的多線程切換還好一些,因?yàn)閱我贿M(jìn)程內(nèi)多線程共享進(jìn)程地址空間,因此線程上下文比之進(jìn)程上下文要小得多,如果是跨進(jìn)程調(diào)度,則需要切換掉整個(gè)進(jìn)程地址空間。
如果是單線程則可以規(guī)避進(jìn)程內(nèi)頻繁的線程切換開銷,因?yàn)槌绦蚴冀K運(yùn)行在進(jìn)程中單個(gè)線程內(nèi),沒有多線程切換的場(chǎng)景。
避免同步機(jī)制的開銷
如果 Redis 選擇多線程模型,又因?yàn)?Redis 是一個(gè)數(shù)據(jù)庫(kù),那么勢(shì)必涉及到底層數(shù)據(jù)同步的問(wèn)題,則必然會(huì)引入某些同步機(jī)制,比如鎖,而我們知道 Redis 不僅僅提供了簡(jiǎn)單的 key-value 數(shù)據(jù)結(jié)構(gòu),還有 list、set 和 hash 等等其他豐富的數(shù)據(jù)結(jié)構(gòu),而不同的數(shù)據(jù)結(jié)構(gòu)對(duì)同步訪問(wèn)的加鎖粒度又不盡相同,可能會(huì)導(dǎo)致在操作數(shù)據(jù)過(guò)程中帶來(lái)很多加鎖解鎖的開銷,增加程序復(fù)雜度的同時(shí)還會(huì)降低性能。
簡(jiǎn)單可維護(hù)
Redis 的作者 Salvatore Sanfilippo (別稱 antirez) 對(duì) Redis 的設(shè)計(jì)和代碼有著近乎偏執(zhí)的簡(jiǎn)潔性理念,你可以在閱讀 Redis 的源碼或者給 Redis 提交 PR 的之時(shí)感受到這份偏執(zhí)。因此代碼的簡(jiǎn)單可維護(hù)性必然是 Redis 早期的核心準(zhǔn)則之一,而引入多線程必然會(huì)導(dǎo)致代碼的復(fù)雜度上升和可維護(hù)性下降。
事實(shí)上,多線程編程也不是那么盡善盡美,首先多線程的引入會(huì)使得程序不再保持代碼邏輯上的串行性,代碼執(zhí)行的順序?qū)⒆兂刹豢深A(yù)測(cè)的,稍不注意就會(huì)導(dǎo)致程序出現(xiàn)各種并發(fā)編程的問(wèn)題;其次,多線程模式也使得程序調(diào)試更加復(fù)雜和麻煩。網(wǎng)絡(luò)上有一幅很有意思的圖片,生動(dòng)形象地描述了并發(fā)編程面臨的窘境。
你期望的多線程編程 VS 實(shí)際上的多線程編程:
 你期望的多線程VS實(shí)際上的多線程
你期望的多線程VS實(shí)際上的多線程前面我們提到引入多線程必須的同步機(jī)制,如果 Redis 使用多線程模式,那么所有的底層數(shù)據(jù)結(jié)構(gòu)都必須實(shí)現(xiàn)成線程安全的,這無(wú)疑又使得 Redis 的實(shí)現(xiàn)變得更加復(fù)雜。
總而言之,Redis 選擇單線程可以說(shuō)是多方博弈之后的一種權(quán)衡:在保證足夠的性能表現(xiàn)之下,使用單線程保持代碼的簡(jiǎn)單和可維護(hù)性。
Redis 真的是單線程?
在討論這個(gè)問(wèn)題之前,我們要先明確『?jiǎn)尉€程』這個(gè)概念的邊界:它的覆蓋范圍是核心網(wǎng)絡(luò)模型,抑或是整個(gè) Redis?如果是前者,那么答案是肯定的,在 Redis 的 v6.0 版本正式引入多線程之前,其網(wǎng)絡(luò)模型一直是單線程模式的;如果是后者,那么答案則是否定的,Redis 早在 v4.0 就已經(jīng)引入了多線程。
因此,當(dāng)我們討論 Redis 的多線程之時(shí),有必要對(duì) Redis 的版本劃出兩個(gè)重要的節(jié)點(diǎn):
- Redis v4.0(引入多線程處理異步任務(wù))
- Redis v6.0(正式在網(wǎng)絡(luò)模型中實(shí)現(xiàn) I/O 多線程)
單線程事件循環(huán)
我們首先來(lái)剖析一下 Redis 的核心網(wǎng)絡(luò)模型,從 Redis 的 v1.0 到 v6.0 版本之前,Redis 的核心網(wǎng)絡(luò)模型一直是一個(gè)典型的單 Reactor 模型:利用 epoll/select/kqueue 等多路復(fù)用技術(shù),在單線程的事件循環(huán)中不斷去處理事件(客戶端請(qǐng)求),最后回寫響應(yīng)數(shù)據(jù)到客戶端:
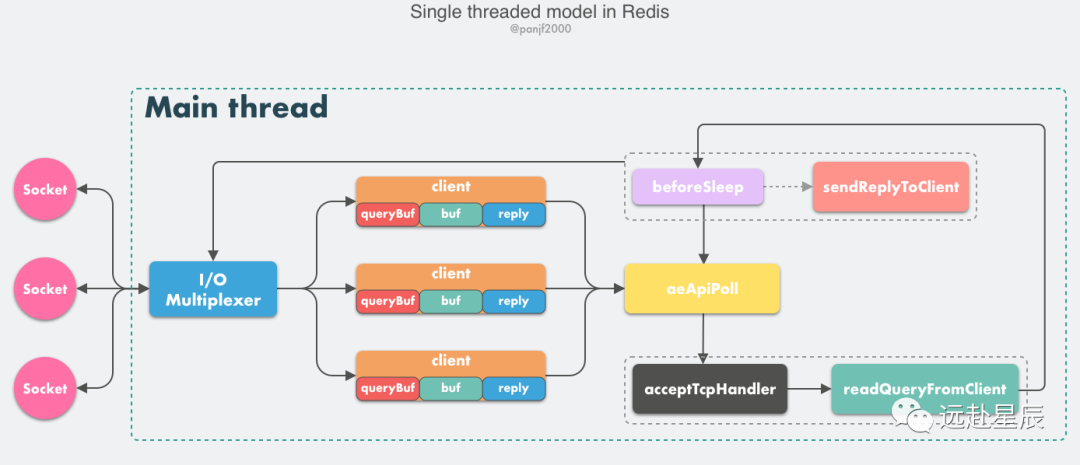
這里有幾個(gè)核心的概念需要學(xué)習(xí):
- client:客戶端對(duì)象,Redis 是典型的 CS 架構(gòu)(Client <---> Server),客戶端通過(guò) socket 與服務(wù)端建立網(wǎng)絡(luò)通道然后發(fā)送請(qǐng)求命令,服務(wù)端執(zhí)行請(qǐng)求的命令并回復(fù)。Redis 使用結(jié)構(gòu)體 client 存儲(chǔ)客戶端的所有相關(guān)信息,包括但不限于
封裝的套接字連接 -- *conn,當(dāng)前選擇的數(shù)據(jù)庫(kù)指針 -- *db,讀入緩沖區(qū) -- querybuf,寫出緩沖區(qū) -- buf,寫出數(shù)據(jù)鏈表 -- reply等。 - aeApiPoll:I/O 多路復(fù)用 API,是基于 epoll_wait/select/kevent 等系統(tǒng)調(diào)用的封裝,監(jiān)聽等待讀寫事件觸發(fā),然后處理,它是事件循環(huán)(Event Loop)中的核心函數(shù),是事件驅(qū)動(dòng)得以運(yùn)行的基礎(chǔ)。
- acceptTcpHandler:連接應(yīng)答處理器,底層使用系統(tǒng)調(diào)用
accept接受來(lái)自客戶端的新連接,并為新連接注冊(cè)綁定命令讀取處理器,以備后續(xù)處理新的客戶端 TCP 連接;除了這個(gè)處理器,還有對(duì)應(yīng)的acceptUnixHandler負(fù)責(zé)處理 Unix Domain Socket 以及acceptTLSHandler負(fù)責(zé)處理 TLS 加密連接。 - readQueryFromClient:命令讀取處理器,解析并執(zhí)行客戶端的請(qǐng)求命令。
- beforeSleep:事件循環(huán)中進(jìn)入 aeApiPoll 等待事件到來(lái)之前會(huì)執(zhí)行的函數(shù),其中包含一些日常的任務(wù),比如把
client->buf或者client->reply(后面會(huì)解釋為什么這里需要兩個(gè)緩沖區(qū))中的響應(yīng)寫回到客戶端,持久化 AOF 緩沖區(qū)的數(shù)據(jù)到磁盤等,相對(duì)應(yīng)的還有一個(gè) afterSleep 函數(shù),在 aeApiPoll 之后執(zhí)行。 - sendReplyToClient:命令回復(fù)處理器,當(dāng)一次事件循環(huán)之后寫出緩沖區(qū)中還有數(shù)據(jù)殘留,則這個(gè)處理器會(huì)被注冊(cè)綁定到相應(yīng)的連接上,等連接觸發(fā)寫就緒事件時(shí),它會(huì)將寫出緩沖區(qū)剩余的數(shù)據(jù)回寫到客戶端。
Redis 內(nèi)部實(shí)現(xiàn)了一個(gè)高性能的事件庫(kù) --- AE,基于 epoll/select/kqueue/evport 四種事件驅(qū)動(dòng)技術(shù),實(shí)現(xiàn) Linux/MacOS/FreeBSD/Solaris 多平臺(tái)的高性能事件循環(huán)模型。Redis 的核心網(wǎng)絡(luò)模型正式構(gòu)筑在 AE 之上,包括 I/O 多路復(fù)用、各類處理器的注冊(cè)綁定,都是基于此才得以運(yùn)行。
至此,我們可以描繪出客戶端向 Redis 發(fā)起請(qǐng)求命令的工作原理:
- Redis 服務(wù)器啟動(dòng),開啟主線程事件循環(huán)(Event Loop),注冊(cè)
acceptTcpHandler連接應(yīng)答處理器到用戶配置的監(jiān)聽端口對(duì)應(yīng)的文件描述符,等待新連接到來(lái); - 客戶端和服務(wù)端建立網(wǎng)絡(luò)連接;
acceptTcpHandler被調(diào)用,主線程使用 AE 的 API 將readQueryFromClient命令讀取處理器綁定到新連接對(duì)應(yīng)的文件描述符上,并初始化一個(gè)client綁定這個(gè)客戶端連接;- 客戶端發(fā)送請(qǐng)求命令,觸發(fā)讀就緒事件,主線程調(diào)用
readQueryFromClient通過(guò) socket 讀取客戶端發(fā)送過(guò)來(lái)的命令存入client->querybuf讀入緩沖區(qū); - 接著調(diào)用
processInputBuffer,在其中使用processInlineBuffer或者processMultibulkBuffer根據(jù) Redis 協(xié)議解析命令,最后調(diào)用processCommand執(zhí)行命令; - 根據(jù)請(qǐng)求命令的類型(SET, GET, DEL, EXEC 等),分配相應(yīng)的命令執(zhí)行器去執(zhí)行,最后調(diào)用
addReply函數(shù)族的一系列函數(shù)將響應(yīng)數(shù)據(jù)寫入到對(duì)應(yīng)client的寫出緩沖區(qū):client->buf或者client->reply,client->buf是首選的寫出緩沖區(qū),固定大小 16KB,一般來(lái)說(shuō)可以緩沖足夠多的響應(yīng)數(shù)據(jù),但是如果客戶端在時(shí)間窗口內(nèi)需要響應(yīng)的數(shù)據(jù)非常大,那么則會(huì)自動(dòng)切換到client->reply鏈表上去,使用鏈表理論上能夠保存無(wú)限大的數(shù)據(jù)(受限于機(jī)器的物理內(nèi)存),最后把client添加進(jìn)一個(gè) LIFO 隊(duì)列clients_pending_write; - 在事件循環(huán)(Event Loop)中,主線程執(zhí)行
beforeSleep-->handleClientsWithPendingWrites,遍歷clients_pending_write隊(duì)列,調(diào)用writeToClient把client的寫出緩沖區(qū)里的數(shù)據(jù)回寫到客戶端,如果寫出緩沖區(qū)還有數(shù)據(jù)遺留,則注冊(cè)sendReplyToClient命令回復(fù)處理器到該連接的寫就緒事件,等待客戶端可寫時(shí)在事件循環(huán)中再繼續(xù)回寫殘余的響應(yīng)數(shù)據(jù)。
對(duì)于那些想利用多核優(yōu)勢(shì)提升性能的用戶來(lái)說(shuō),Redis 官方給出的解決方案也非常簡(jiǎn)單粗暴:在同一個(gè)機(jī)器上多跑幾個(gè) Redis 實(shí)例。事實(shí)上,為了保證高可用,線上業(yè)務(wù)一般不太可能會(huì)是單機(jī)模式,更加常見的是利用 Redis 分布式集群多節(jié)點(diǎn)和數(shù)據(jù)分片負(fù)載均衡來(lái)提升性能和保證高可用。
多線程異步任務(wù)
以上便是 Redis 的核心網(wǎng)絡(luò)模型,這個(gè)單線程網(wǎng)絡(luò)模型一直到 Redis v6.0 才改造成多線程模式,但這并不意味著整個(gè) Redis 一直都只是單線程。
Redis 在 v4.0 版本的時(shí)候就已經(jīng)引入了的多線程來(lái)做一些異步操作,此舉主要針對(duì)的是那些非常耗時(shí)的命令,通過(guò)將這些命令的執(zhí)行進(jìn)行異步化,避免阻塞單線程的事件循環(huán)。
我們知道 Redis 的 DEL 命令是用來(lái)刪除掉一個(gè)或多個(gè) key 儲(chǔ)存的值,它是一個(gè)阻塞的命令,大多數(shù)情況下你要?jiǎng)h除的 key 里存的值不會(huì)特別多,最多也就幾十上百個(gè)對(duì)象,所以可以很快執(zhí)行完,但是如果你要?jiǎng)h的是一個(gè)超大的鍵值對(duì),里面有幾百萬(wàn)個(gè)對(duì)象,那么這條命令可能會(huì)阻塞至少好幾秒,又因?yàn)槭录h(huán)是單線程的,所以會(huì)阻塞后面的其他事件,導(dǎo)致吞吐量下降。
Redis 的作者 antirez 為了解決這個(gè)問(wèn)題進(jìn)行了很多思考,一開始他想的辦法是一種漸進(jìn)式的方案:利用定時(shí)器和數(shù)據(jù)游標(biāo),每次只刪除一小部分的數(shù)據(jù),比如 1000 個(gè)對(duì)象,最終清除掉所有的數(shù)據(jù),但是這種方案有個(gè)致命的缺陷,如果同時(shí)還有其他客戶端往某個(gè)正在被漸進(jìn)式刪除的 key 里繼續(xù)寫入數(shù)據(jù),而且刪除的速度跟不上寫入的數(shù)據(jù),那么將會(huì)無(wú)止境地消耗內(nèi)存,雖然后來(lái)通過(guò)一個(gè)巧妙的辦法解決了,但是這種實(shí)現(xiàn)使 Redis 變得更加復(fù)雜,而多線程看起來(lái)似乎是一個(gè)水到渠成的解決方案:簡(jiǎn)單、易理解。于是,最終 antirez 選擇引入多線程來(lái)實(shí)現(xiàn)這一類非阻塞的命令。更多 antirez 在這方面的思考可以閱讀一下他發(fā)表的博客:Lazy Redis is better Redis。
于是,在 Redis v4.0 之后增加了一些的非阻塞命令如 UNLINK、FLUSHALL ASYNC、FLUSHDB ASYNC。
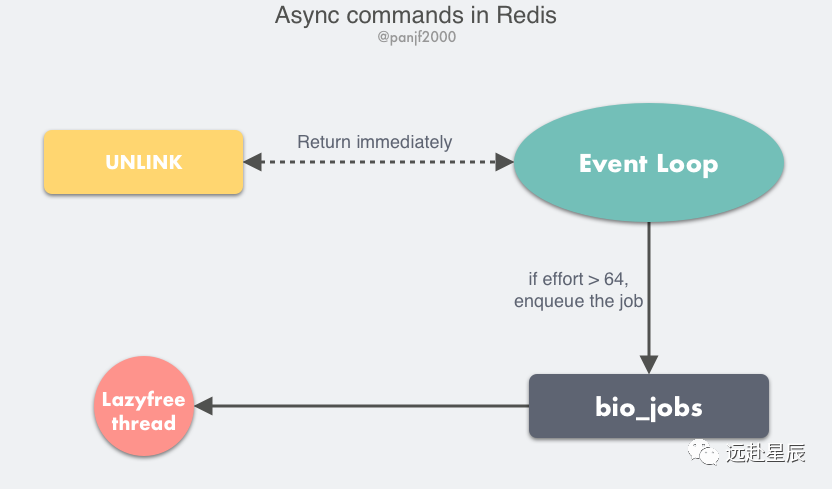
UNLINK 命令其實(shí)就是 DEL 的異步版本,它不會(huì)同步刪除數(shù)據(jù),而只是把 key 從 keyspace 中暫時(shí)移除掉,然后將任務(wù)添加到一個(gè)異步隊(duì)列,最后由后臺(tái)線程去刪除,不過(guò)這里需要考慮一種情況是如果用 UNLINK 去刪除一個(gè)很小的 key,用異步的方式去做反而開銷更大,所以它會(huì)先計(jì)算一個(gè)開銷的閥值,只有當(dāng)這個(gè)值大于 64 才會(huì)使用異步的方式去刪除 key,對(duì)于基本的數(shù)據(jù)類型如 List、Set、Hash 這些,閥值就是其中存儲(chǔ)的對(duì)象數(shù)量。
Redis 多線程網(wǎng)絡(luò)模型
前面提到 Redis 最初選擇單線程網(wǎng)絡(luò)模型的理由是:CPU 通常不會(huì)成為性能瓶頸,瓶頸往往是內(nèi)存和網(wǎng)絡(luò),因此單線程足夠了。那么為什么現(xiàn)在 Redis 又要引入多線程呢?很簡(jiǎn)單,就是 Redis 的網(wǎng)絡(luò) I/O 瓶頸已經(jīng)越來(lái)越明顯了。
隨著互聯(lián)網(wǎng)的飛速發(fā)展,互聯(lián)網(wǎng)業(yè)務(wù)系統(tǒng)所要處理的線上流量越來(lái)越大,Redis 的單線程模式會(huì)導(dǎo)致系統(tǒng)消耗很多 CPU 時(shí)間在網(wǎng)絡(luò) I/O 上從而降低吞吐量,要提升 Redis 的性能有兩個(gè)方向:
- 優(yōu)化網(wǎng)絡(luò) I/O 模塊
- 提高機(jī)器內(nèi)存讀寫的速度
后者依賴于硬件的發(fā)展,暫時(shí)無(wú)解。所以只能從前者下手,網(wǎng)絡(luò) I/O 的優(yōu)化又可以分為兩個(gè)方向:
- 零拷貝技術(shù)或者 DPDK 技術(shù)
- 利用多核優(yōu)勢(shì)
零拷貝技術(shù)有其局限性,無(wú)法完全適配 Redis 這一類復(fù)雜的網(wǎng)絡(luò) I/O 場(chǎng)景,更多網(wǎng)絡(luò) I/O 對(duì) CPU 時(shí)間的消耗和 Linux 零拷貝技術(shù),可以閱讀我的另一篇文章:Linux I/O 原理和 Zero-copy 技術(shù)全面揭秘。而 DPDK 技術(shù)通過(guò)旁路網(wǎng)卡 I/O 繞過(guò)內(nèi)核協(xié)議棧的方式又太過(guò)于復(fù)雜以及需要內(nèi)核甚至是硬件的支持。
因此,利用多核優(yōu)勢(shì)成為了優(yōu)化網(wǎng)絡(luò) I/O 性價(jià)比最高的方案。
6.0 版本之后,Redis 正式在核心網(wǎng)絡(luò)模型中引入了多線程,也就是所謂的 I/O threading,至此 Redis 真正擁有了多線程模型。前一小節(jié),我們了解了 Redis 在 6.0 版本之前的單線程事件循環(huán)模型,實(shí)際上就是一個(gè)非常經(jīng)典的 Reactor 模型:
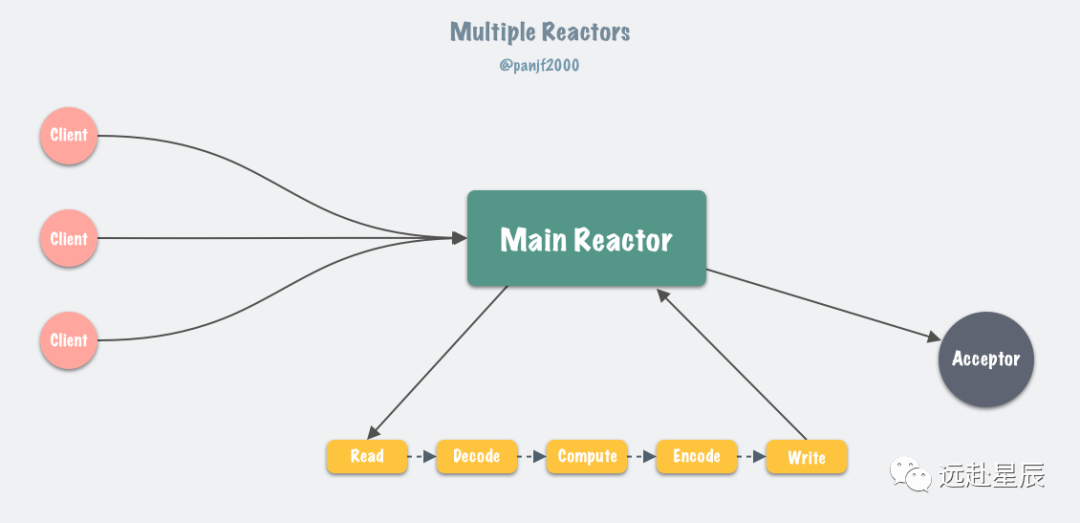
目前 Linux 平臺(tái)上主流的高性能網(wǎng)絡(luò)庫(kù)/框架中,大都采用 Reactor 模式,比如 netty、libevent、libuv、POE(Perl)、Twisted(Python)等。
Reactor 模式本質(zhì)上指的是使用 I/O 多路復(fù)用(I/O multiplexing) + 非阻塞 I/O(non-blocking I/O) 的模式。
更多關(guān)于 Reactor 模式的細(xì)節(jié)可以參考我之前的文章:Go netpoller 原生網(wǎng)絡(luò)模型之源碼全面揭秘,Reactor 網(wǎng)絡(luò)模型那一小節(jié),這里不再贅述。
Redis 的核心網(wǎng)絡(luò)模型在 6.0 版本之前,一直是單 Reactor 模式:所有事件的處理都在單個(gè)線程內(nèi)完成,雖然在 4.0 版本中引入了多線程,但是那個(gè)更像是針對(duì)特定場(chǎng)景(刪除超大 key 值等)而打的補(bǔ)丁,并不能被視作核心網(wǎng)絡(luò)模型的多線程。
通常來(lái)說(shuō),單 Reactor 模式,引入多線程之后會(huì)進(jìn)化為 Multi-Reactors 模式,基本工作模式如下:
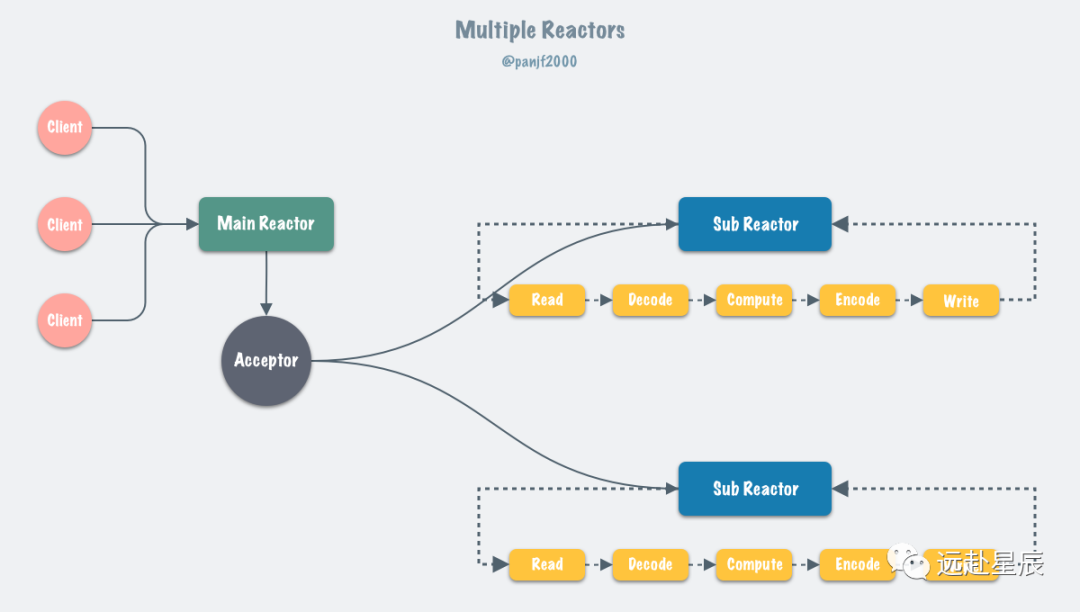
區(qū)別于單 Reactor 模式,這種模式不再是單線程的事件循環(huán),而是有多個(gè)線程(Sub Reactors)各自維護(hù)一個(gè)獨(dú)立的事件循環(huán),由 Main Reactor 負(fù)責(zé)接收新連接并分發(fā)給 Sub Reactors 去獨(dú)立處理,最后 Sub Reactors 回寫響應(yīng)給客戶端。
Multiple Reactors 模式通常也可以等同于 Master-Workers 模式,比如 Nginx 和 Memcached 等就是采用這種多線程模型,雖然不同的項(xiàng)目實(shí)現(xiàn)細(xì)節(jié)略有區(qū)別,但總體來(lái)說(shuō)模式是一致的。
設(shè)計(jì)思路
Redis 雖然也實(shí)現(xiàn)了多線程,但是卻不是標(biāo)準(zhǔn)的 Multi-Reactors/Master-Workers 模式,這其中的緣由我們后面會(huì)分析,現(xiàn)在我們先看一下 Redis 多線程網(wǎng)絡(luò)模型的總體設(shè)計(jì):
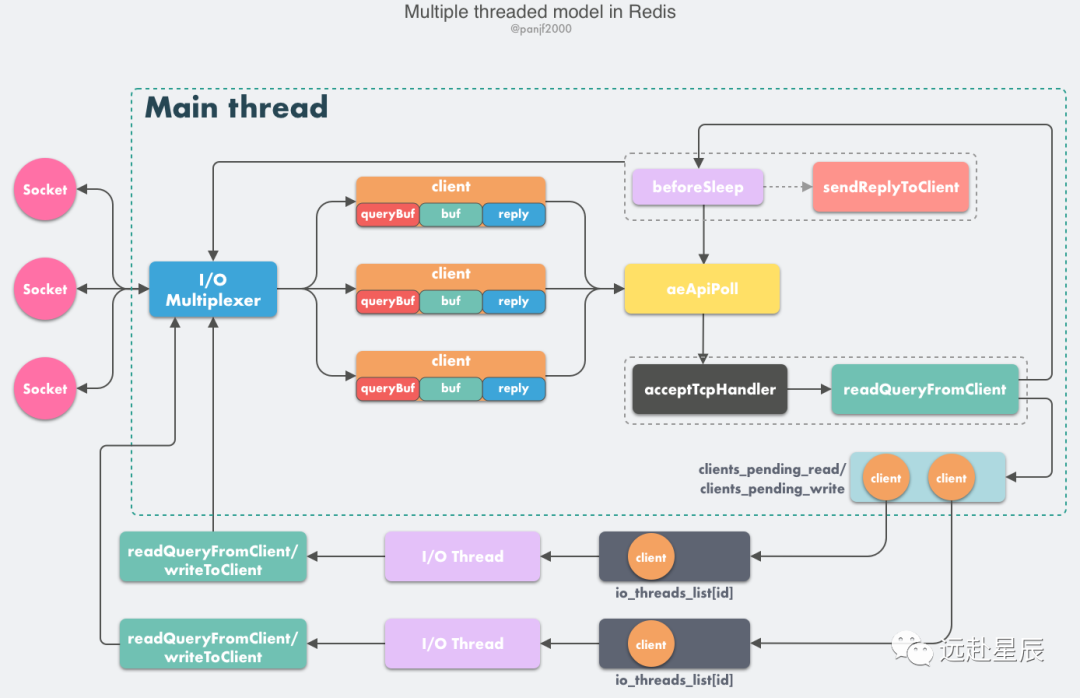
- Redis 服務(wù)器啟動(dòng),開啟主線程事件循環(huán)(Event Loop),注冊(cè)
acceptTcpHandler連接應(yīng)答處理器到用戶配置的監(jiān)聽端口對(duì)應(yīng)的文件描述符,等待新連接到來(lái); - 客戶端和服務(wù)端建立網(wǎng)絡(luò)連接;
acceptTcpHandler被調(diào)用,主線程使用 AE 的 API 將readQueryFromClient命令讀取處理器綁定到新連接對(duì)應(yīng)的文件描述符上,并初始化一個(gè)client綁定這個(gè)客戶端連接;- 客戶端發(fā)送請(qǐng)求命令,觸發(fā)讀就緒事件,服務(wù)端主線程不會(huì)通過(guò) socket 去讀取客戶端的請(qǐng)求命令,而是先將
client放入一個(gè) LIFO 隊(duì)列clients_pending_read; - 在事件循環(huán)(Event Loop)中,主線程執(zhí)行
beforeSleep-->handleClientsWithPendingReadsUsingThreads,利用 Round-Robin 輪詢負(fù)載均衡策略,把clients_pending_read隊(duì)列中的連接均勻地分配給 I/O 線程各自的本地 FIFO 任務(wù)隊(duì)列io_threads_list[id]和主線程自己,I/O 線程通過(guò) socket 讀取客戶端的請(qǐng)求命令,存入client->querybuf并解析第一個(gè)命令,但不執(zhí)行命令,主線程忙輪詢,等待所有 I/O 線程完成讀取任務(wù); - 主線程和所有 I/O 線程都完成了讀取任務(wù),主線程結(jié)束忙輪詢,遍歷
clients_pending_read隊(duì)列,執(zhí)行所有客戶端連接的請(qǐng)求命令,先調(diào)用processCommandAndResetClient執(zhí)行第一條已經(jīng)解析好的命令,然后調(diào)用processInputBuffer解析并執(zhí)行客戶端連接的所有命令,在其中使用processInlineBuffer或者processMultibulkBuffer根據(jù) Redis 協(xié)議解析命令,最后調(diào)用processCommand執(zhí)行命令; - 根據(jù)請(qǐng)求命令的類型(SET, GET, DEL, EXEC 等),分配相應(yīng)的命令執(zhí)行器去執(zhí)行,最后調(diào)用
addReply函數(shù)族的一系列函數(shù)將響應(yīng)數(shù)據(jù)寫入到對(duì)應(yīng)client的寫出緩沖區(qū):client->buf或者client->reply,client->buf是首選的寫出緩沖區(qū),固定大小 16KB,一般來(lái)說(shuō)可以緩沖足夠多的響應(yīng)數(shù)據(jù),但是如果客戶端在時(shí)間窗口內(nèi)需要響應(yīng)的數(shù)據(jù)非常大,那么則會(huì)自動(dòng)切換到client->reply鏈表上去,使用鏈表理論上能夠保存無(wú)限大的數(shù)據(jù)(受限于機(jī)器的物理內(nèi)存),最后把client添加進(jìn)一個(gè) LIFO 隊(duì)列clients_pending_write; - 在事件循環(huán)(Event Loop)中,主線程執(zhí)行
beforeSleep-->handleClientsWithPendingWritesUsingThreads,利用 Round-Robin 輪詢負(fù)載均衡策略,把clients_pending_write隊(duì)列中的連接均勻地分配給 I/O 線程各自的本地 FIFO 任務(wù)隊(duì)列io_threads_list[id]和主線程自己,I/O 線程通過(guò)調(diào)用writeToClient把client的寫出緩沖區(qū)里的數(shù)據(jù)回寫到客戶端,主線程忙輪詢,等待所有 I/O 線程完成寫出任務(wù); - 主線程和所有 I/O 線程都完成了寫出任務(wù), 主線程結(jié)束忙輪詢,遍歷
clients_pending_write隊(duì)列,如果client的寫出緩沖區(qū)還有數(shù)據(jù)遺留,則注冊(cè)sendReplyToClient到該連接的寫就緒事件,等待客戶端可寫時(shí)在事件循環(huán)中再繼續(xù)回寫殘余的響應(yīng)數(shù)據(jù)。
這里大部分邏輯和之前的單線程模型是一致的,變動(dòng)的地方僅僅是把讀取客戶端請(qǐng)求命令和回寫響應(yīng)數(shù)據(jù)的邏輯異步化了,交給 I/O 線程去完成,這里需要特別注意的一點(diǎn)是:I/O 線程僅僅是讀取和解析客戶端命令而不會(huì)真正去執(zhí)行命令,客戶端命令的執(zhí)行最終還是要回到主線程上完成。
源碼剖析
?以下所有代碼基于目前最新的 Redis v6.0.10 版本。
”
多線程初始化
void initThreadedIO(void) {
server.io_threads_active = 0; /* We start with threads not active. */
// 如果用戶只配置了一個(gè) I/O 線程,則不會(huì)創(chuàng)建新線程(效率低),直接在主線程里處理 I/O。
if (server.io_threads_num == 1) return;
if (server.io_threads_num > IO_THREADS_MAX_NUM) {
serverLog(LL_WARNING,"Fatal: too many I/O threads configured. "
"The maximum number is %d.", IO_THREADS_MAX_NUM);
exit(1);
}
// 根據(jù)用戶配置的 I/O 線程數(shù),啟動(dòng)線程。
for (int i = 0; i < server.io_threads_num; i++) {
// 初始化 I/O 線程的本地任務(wù)隊(duì)列。
io_threads_list[i] = listCreate();
if (i == 0) continue; // 線程 0 是主線程。
// 初始化 I/O 線程并啟動(dòng)。
pthread_t tid;
// 每個(gè) I/O 線程會(huì)分配一個(gè)本地鎖,用來(lái)休眠和喚醒線程。
pthread_mutex_init(&io_threads_mutex[i],NULL);
// 每個(gè) I/O 線程分配一個(gè)原子計(jì)數(shù)器,用來(lái)記錄當(dāng)前遺留的任務(wù)數(shù)量。
io_threads_pending[i] = 0;
// 主線程在啟動(dòng) I/O 線程的時(shí)候會(huì)默認(rèn)先鎖住它,直到有 I/O 任務(wù)才喚醒它。
pthread_mutex_lock(&io_threads_mutex[i]);
// 啟動(dòng)線程,進(jìn)入 I/O 線程的主邏輯函數(shù) IOThreadMain。
if (pthread_create(&tid,NULL,IOThreadMain,(void*)(long)i) != 0) {
serverLog(LL_WARNING,"Fatal: Can't initialize IO thread.");
exit(1);
}
io_threads[i] = tid;
}
}
initThreadedIO 會(huì)在 Redis 服務(wù)器啟動(dòng)時(shí)的初始化工作的末尾被調(diào)用,初始化 I/O 多線程并啟動(dòng)。
Redis 的多線程模式默認(rèn)是關(guān)閉的,需要用戶在 redis.conf 配置文件中開啟:
io-threads 4
io-threads-do-reads yes
讀取請(qǐng)求
當(dāng)客戶端發(fā)送請(qǐng)求命令之后,會(huì)觸發(fā) Redis 主線程的事件循環(huán),命令處理器 readQueryFromClient 被回調(diào),在以前的單線程模型下,這個(gè)方法會(huì)直接讀取解析客戶端命令并執(zhí)行,但是多線程模式下,則會(huì)把 client 加入到 clients_pending_read 任務(wù)隊(duì)列中去,后面主線程再分配到 I/O 線程去讀取客戶端請(qǐng)求命令:
void readQueryFromClient(connection *conn) {
client *c = connGetPrivateData(conn);
int nread, readlen;
size_t qblen;
// 檢查是否開啟了多線程,如果是則把 client 加入異步隊(duì)列之后返回。
if (postponeClientRead(c)) return;
// 省略代碼,下面的代碼邏輯和單線程版本幾乎是一樣的。
...
}
int postponeClientRead(client *c) {
// 當(dāng)多線程 I/O 模式開啟、主線程沒有在處理阻塞任務(wù)時(shí),將 client 加入異步隊(duì)列。
if (server.io_threads_active &&
server.io_threads_do_reads &&
!ProcessingEventsWhileBlocked &&
!(c->flags & (CLIENT_MASTER|CLIENT_SLAVE|CLIENT_PENDING_READ)))
{
// 給 client 打上 CLIENT_PENDING_READ 標(biāo)識(shí),表示該 client 需要被多線程處理,
// 后續(xù)在 I/O 線程中會(huì)在讀取和解析完客戶端命令之后判斷該標(biāo)識(shí)并放棄執(zhí)行命令,讓主線程去執(zhí)行。
c->flags |= CLIENT_PENDING_READ;
listAddNodeHead(server.clients_pending_read,c);
return 1;
} else {
return 0;
}
}
接著主線程會(huì)在事件循環(huán)的 beforeSleep() 方法中,調(diào)用 handleClientsWithPendingReadsUsingThreads:
int handleClientsWithPendingReadsUsingThreads(void) {
if (!server.io_threads_active || !server.io_threads_do_reads) return 0;
int processed = listLength(server.clients_pending_read);
if (processed == 0) return 0;
if (tio_debug) printf("%d TOTAL READ pending clients\n", processed);
// 遍歷待讀取的 client 隊(duì)列 clients_pending_read,
// 通過(guò) RR 輪詢均勻地分配給 I/O 線程和主線程自己(編號(hào) 0)。
listIter li;
listNode *ln;
listRewind(server.clients_pending_read,&li);
int item_id = 0;
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
int target_id = item_id % server.io_threads_num;
listAddNodeTail(io_threads_list[target_id],c);
item_id++;
}
// 設(shè)置當(dāng)前 I/O 操作為讀取操作,給每個(gè) I/O 線程的計(jì)數(shù)器設(shè)置分配的任務(wù)數(shù)量,
// 讓 I/O 線程可以開始工作:只讀取和解析命令,不執(zhí)行。
io_threads_op = IO_THREADS_OP_READ;
for (int j = 1; j < server.io_threads_num; j++) {
int count = listLength(io_threads_list[j]);
io_threads_pending[j] = count;
}
// 主線程自己也會(huì)去執(zhí)行讀取客戶端請(qǐng)求命令的任務(wù),以達(dá)到最大限度利用 CPU。
listRewind(io_threads_list[0],&li);
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
readQueryFromClient(c->conn);
}
listEmpty(io_threads_list[0]);
// 忙輪詢,累加所有 I/O 線程的原子任務(wù)計(jì)數(shù)器,直到所有計(jì)數(shù)器的遺留任務(wù)數(shù)量都是 0,
// 表示所有任務(wù)都已經(jīng)執(zhí)行完成,結(jié)束輪詢。
while(1) {
unsigned long pending = 0;
for (int j = 1; j < server.io_threads_num; j++)
pending += io_threads_pending[j];
if (pending == 0) break;
}
if (tio_debug) printf("I/O READ All threads finshed\n");
// 遍歷待讀取的 client 隊(duì)列,清除 CLIENT_PENDING_READ 和 CLIENT_PENDING_COMMAND 標(biāo)記,
// 然后解析并執(zhí)行所有 client 的命令。
while(listLength(server.clients_pending_read)) {
ln = listFirst(server.clients_pending_read);
client *c = listNodeValue(ln);
c->flags &= ~CLIENT_PENDING_READ;
listDelNode(server.clients_pending_read,ln);
if (c->flags & CLIENT_PENDING_COMMAND) {
c->flags &= ~CLIENT_PENDING_COMMAND;
// client 的第一條命令已經(jīng)被解析好了,直接嘗試執(zhí)行。
if (processCommandAndResetClient(c) == C_ERR) {
/* If the client is no longer valid, we avoid
* processing the client later. So we just go
* to the next. */
continue;
}
}
processInputBuffer(c); // 繼續(xù)解析并執(zhí)行 client 命令。
// 命令執(zhí)行完成之后,如果 client 中有響應(yīng)數(shù)據(jù)需要回寫到客戶端,則將 client 加入到待寫出隊(duì)列 clients_pending_write
if (!(c->flags & CLIENT_PENDING_WRITE) && clientHasPendingReplies(c))
clientInstallWriteHandler(c);
}
/* Update processed count on server */
server.stat_io_reads_processed += processed;
return processed;
}
這里的核心工作是:
- 遍歷待讀取的
client隊(duì)列clients_pending_read,通過(guò) RR 策略把所有任務(wù)分配給 I/O 線程和主線程去讀取和解析客戶端命令。 - 忙輪詢等待所有 I/O 線程完成任務(wù)。
- 最后再遍歷
clients_pending_read,執(zhí)行所有client的命令。
寫回響應(yīng)
完成命令的讀取、解析以及執(zhí)行之后,客戶端命令的響應(yīng)數(shù)據(jù)已經(jīng)存入 client->buf 或者 client->reply 中了,接下來(lái)就需要把響應(yīng)數(shù)據(jù)回寫到客戶端了,還是在 beforeSleep 中, 主線程調(diào)用 handleClientsWithPendingWritesUsingThreads:
int handleClientsWithPendingWritesUsingThreads(void) {
int processed = listLength(server.clients_pending_write);
if (processed == 0) return 0; /* Return ASAP if there are no clients. */
// 如果用戶設(shè)置的 I/O 線程數(shù)等于 1 或者當(dāng)前 clients_pending_write 隊(duì)列中待寫出的 client
// 數(shù)量不足 I/O 線程數(shù)的兩倍,則不用多線程的邏輯,讓所有 I/O 線程進(jìn)入休眠,
// 直接在主線程把所有 client 的相應(yīng)數(shù)據(jù)回寫到客戶端。
if (server.io_threads_num == 1 || stopThreadedIOIfNeeded()) {
return handleClientsWithPendingWrites();
}
// 喚醒正在休眠的 I/O 線程(如果有的話)。
if (!server.io_threads_active) startThreadedIO();
if (tio_debug) printf("%d TOTAL WRITE pending clients\n", processed);
// 遍歷待寫出的 client 隊(duì)列 clients_pending_write,
// 通過(guò) RR 輪詢均勻地分配給 I/O 線程和主線程自己(編號(hào) 0)。
listIter li;
listNode *ln;
listRewind(server.clients_pending_write,&li);
int item_id = 0;
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
c->flags &= ~CLIENT_PENDING_WRITE;
/* Remove clients from the list of pending writes since
* they are going to be closed ASAP. */
if (c->flags & CLIENT_CLOSE_ASAP) {
listDelNode(server.clients_pending_write, ln);
continue;
}
int target_id = item_id % server.io_threads_num;
listAddNodeTail(io_threads_list[target_id],c);
item_id++;
}
// 設(shè)置當(dāng)前 I/O 操作為寫出操作,給每個(gè) I/O 線程的計(jì)數(shù)器設(shè)置分配的任務(wù)數(shù)量,
// 讓 I/O 線程可以開始工作,把寫出緩沖區(qū)(client->buf 或 c->reply)中的響應(yīng)數(shù)據(jù)回寫到客戶端。
io_threads_op = IO_THREADS_OP_WRITE;
for (int j = 1; j < server.io_threads_num; j++) {
int count = listLength(io_threads_list[j]);
io_threads_pending[j] = count;
}
// 主線程自己也會(huì)去執(zhí)行讀取客戶端請(qǐng)求命令的任務(wù),以達(dá)到最大限度利用 CPU。
listRewind(io_threads_list[0],&li);
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
writeToClient(c,0);
}
listEmpty(io_threads_list[0]);
// 忙輪詢,累加所有 I/O 線程的原子任務(wù)計(jì)數(shù)器,直到所有計(jì)數(shù)器的遺留任務(wù)數(shù)量都是 0。
// 表示所有任務(wù)都已經(jīng)執(zhí)行完成,結(jié)束輪詢。
while(1) {
unsigned long pending = 0;
for (int j = 1; j < server.io_threads_num; j++)
pending += io_threads_pending[j];
if (pending == 0) break;
}
if (tio_debug) printf("I/O WRITE All threads finshed\n");
// 最后再遍歷一次 clients_pending_write 隊(duì)列,檢查是否還有 client 的中寫出緩沖區(qū)中有殘留數(shù)據(jù),
// 如果有,那就為 client 注冊(cè)一個(gè)命令回復(fù)器 sendReplyToClient,等待客戶端寫就緒再繼續(xù)把數(shù)據(jù)回寫。
listRewind(server.clients_pending_write,&li);
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
// 檢查 client 的寫出緩沖區(qū)是否還有遺留數(shù)據(jù)。
if (clientHasPendingReplies(c) &&
connSetWriteHandler(c->conn, sendReplyToClient) == AE_ERR)
{
freeClientAsync(c);
}
}
listEmpty(server.clients_pending_write);
/* Update processed count on server */
server.stat_io_writes_processed += processed;
return processed;
}
這里的核心工作是:
- 檢查當(dāng)前任務(wù)負(fù)載,如果當(dāng)前的任務(wù)數(shù)量不足以用多線程模式處理的話,則休眠 I/O 線程并且直接同步將響應(yīng)數(shù)據(jù)回寫到客戶端。
- 喚醒正在休眠的 I/O 線程(如果有的話)。
- 遍歷待寫出的
client隊(duì)列clients_pending_write,通過(guò) RR 策略把所有任務(wù)分配給 I/O 線程和主線程去將響應(yīng)數(shù)據(jù)寫回到客戶端。 - 忙輪詢等待所有 I/O 線程完成任務(wù)。
- 最后再遍歷
clients_pending_write,為那些還殘留有響應(yīng)數(shù)據(jù)的client注冊(cè)命令回復(fù)處理器sendReplyToClient,等待客戶端可寫之后在事件循環(huán)中繼續(xù)回寫殘余的響應(yīng)數(shù)據(jù)。
I/O 線程主邏輯
void *IOThreadMain(void *myid) {
/* The ID is the thread number (from 0 to server.iothreads_num-1), and is
* used by the thread to just manipulate a single sub-array of clients. */
long id = (unsigned long)myid;
char thdname[16];
snprintf(thdname, sizeof(thdname), "io_thd_%ld", id);
redis_set_thread_title(thdname);
// 設(shè)置 I/O 線程的 CPU 親和性,盡可能將 I/O 線程(以及主線程,不在這里設(shè)置)綁定到用戶配置的
// CPU 列表上。
redisSetCpuAffinity(server.server_cpulist);
makeThreadKillable();
while(1) {
// 忙輪詢,100w 次循環(huán),等待主線程分配 I/O 任務(wù)。
for (int j = 0; j < 1000000; j++) {
if (io_threads_pending[id] != 0) break;
}
// 如果 100w 次忙輪詢之后如果還是沒有任務(wù)分配給它,則通過(guò)嘗試加鎖進(jìn)入休眠,
// 等待主線程分配任務(wù)之后調(diào)用 startThreadedIO 解鎖,喚醒 I/O 線程去執(zhí)行。
if (io_threads_pending[id] == 0) {
pthread_mutex_lock(&io_threads_mutex[id]);
pthread_mutex_unlock(&io_threads_mutex[id]);
continue;
}
serverAssert(io_threads_pending[id] != 0);
if (tio_debug) printf("[%ld] %d to handle\n", id, (int)listLength(io_threads_list[id]));
// 注意:主線程分配任務(wù)給 I/O 線程之時(shí),
// 會(huì)把任務(wù)加入每個(gè)線程的本地任務(wù)隊(duì)列 io_threads_list[id],
// 但是當(dāng) I/O 線程開始執(zhí)行任務(wù)之后,主線程就不會(huì)再去訪問(wèn)這些任務(wù)隊(duì)列,避免數(shù)據(jù)競(jìng)爭(zhēng)。
listIter li;
listNode *ln;
listRewind(io_threads_list[id],&li);
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
// 如果當(dāng)前是寫出操作,則把 client 的寫出緩沖區(qū)中的數(shù)據(jù)回寫到客戶端。
if (io_threads_op == IO_THREADS_OP_WRITE) {
writeToClient(c,0);
// 如果當(dāng)前是讀取操作,則socket 讀取客戶端的請(qǐng)求命令并解析第一條命令。
} else if (io_threads_op == IO_THREADS_OP_READ) {
readQueryFromClient(c->conn);
} else {
serverPanic("io_threads_op value is unknown");
}
}
listEmpty(io_threads_list[id]);
// 所有任務(wù)執(zhí)行完之后把自己的計(jì)數(shù)器置 0,主線程通過(guò)累加所有 I/O 線程的計(jì)數(shù)器
// 判斷是否所有 I/O 線程都已經(jīng)完成工作。
io_threads_pending[id] = 0;
if (tio_debug) printf("[%ld] Done\n", id);
}
}
I/O 線程啟動(dòng)之后,會(huì)先進(jìn)入忙輪詢,判斷原子計(jì)數(shù)器中的任務(wù)數(shù)量,如果是非 0 則表示主線程已經(jīng)給它分配了任務(wù),開始執(zhí)行任務(wù),否則就一直忙輪詢一百萬(wàn)次等待,忙輪詢結(jié)束之后再查看計(jì)數(shù)器,如果還是 0,則嘗試加本地鎖,因?yàn)橹骶€程在啟動(dòng) I/O 線程之時(shí)就已經(jīng)提前鎖住了所有 I/O 線程的本地鎖,因此 I/O 線程會(huì)進(jìn)行休眠,等待主線程喚醒。
主線程會(huì)在每次事件循環(huán)中嘗試調(diào)用 startThreadedIO 喚醒 I/O 線程去執(zhí)行任務(wù),如果接收到客戶端請(qǐng)求命令,則 I/O 線程會(huì)被喚醒開始工作,根據(jù)主線程設(shè)置的 io_threads_op 標(biāo)識(shí)去執(zhí)行命令讀取和解析或者回寫響應(yīng)數(shù)據(jù)的任務(wù),I/O 線程在收到主線程通知之后,會(huì)遍歷自己的本地任務(wù)隊(duì)列 io_threads_list[id],取出一個(gè)個(gè) client 執(zhí)行任務(wù):
- 如果當(dāng)前是寫出操作,則調(diào)用
writeToClient,通過(guò) socket 把client->buf或者client->reply里的響應(yīng)數(shù)據(jù)回寫到客戶端。 - 如果當(dāng)前是讀取操作,則調(diào)用
readQueryFromClient,通過(guò) socket 讀取客戶端命令,存入client->querybuf,然后調(diào)用processInputBuffer去解析命令,這里最終只會(huì)解析到第一條命令,然后就結(jié)束,不會(huì)去執(zhí)行命令。 - 在全部任務(wù)執(zhí)行完之后把自己的原子計(jì)數(shù)器置 0,以告知主線程自己已經(jīng)完成了工作。
void processInputBuffer(client *c) {
// 省略代碼
...
while(c->qb_pos < sdslen(c->querybuf)) {
/* Return if clients are paused. */
if (!(c->flags & CLIENT_SLAVE) && clientsArePaused()) break;
/* Immediately abort if the client is in the middle of something. */
if (c->flags & CLIENT_BLOCKED) break;
/* Don't process more buffers from clients that have already pending
* commands to execute in c->argv. */
if (c->flags & CLIENT_PENDING_COMMAND) break;
/* Multibulk processing could see a <= 0 length. */
if (c->argc == 0) {
resetClient(c);
} else {
// 判斷 client 是否具有 CLIENT_PENDING_READ 標(biāo)識(shí),如果是處于多線程 I/O 的模式下,
// 那么此前已經(jīng)在 readQueryFromClient -> postponeClientRead 中為 client 打上該標(biāo)識(shí),
// 則立刻跳出循環(huán)結(jié)束,此時(shí)第一條命令已經(jīng)解析完成,但是不執(zhí)行命令。
if (c->flags & CLIENT_PENDING_READ) {
c->flags |= CLIENT_PENDING_COMMAND;
break;
}
// 執(zhí)行客戶端命令
if (processCommandAndResetClient(c) == C_ERR) {
/* If the client is no longer valid, we avoid exiting this
* loop and trimming the client buffer later. So we return
* ASAP in that case. */
return;
}
}
}
...
}
這里需要額外關(guān)注 I/O 線程初次啟動(dòng)時(shí)會(huì)設(shè)置當(dāng)前線程的 CPU 親和性,也就是綁定當(dāng)前線程到用戶配置的 CPU 上,在啟動(dòng) Redis 服務(wù)器主線程的時(shí)候同樣會(huì)設(shè)置 CPU 親和性,Redis 的核心網(wǎng)絡(luò)模型引入多線程之后,加上之前的多線程異步任務(wù)、多進(jìn)程(BGSAVE、AOF、BIO、Sentinel 腳本任務(wù)等),Redis 現(xiàn)如今的系統(tǒng)并發(fā)度已經(jīng)很大了,而 Redis 本身又是一個(gè)對(duì)吞吐量和延遲極度敏感的系統(tǒng),所以用戶需要 Redis 對(duì) CPU 資源有更細(xì)粒度的控制,這里主要考慮的是兩方面:CPU 高速緩存和 NUMA 架構(gòu)。
首先是 CPU 高速緩存(這里討論的是 L1 Cache 和 L2 Cache 都集成在 CPU 中的硬件架構(gòu)),這里想象一種場(chǎng)景:Redis 主進(jìn)程正在 CPU-1 上運(yùn)行,給客戶端提供數(shù)據(jù)服務(wù),此時(shí) Redis 啟動(dòng)了子進(jìn)程進(jìn)行數(shù)據(jù)持久化(BGSAVE 或者 AOF),系統(tǒng)調(diào)度之后子進(jìn)程搶占了主進(jìn)程的 CPU-1,主進(jìn)程被調(diào)度到 CPU-2 上去運(yùn)行,導(dǎo)致之前 CPU-1 的高速緩存里的相關(guān)指令和數(shù)據(jù)被汰換掉,CPU-2 需要重新加載指令和數(shù)據(jù)到自己的本地高速緩存里,浪費(fèi) CPU 資源,降低性能。
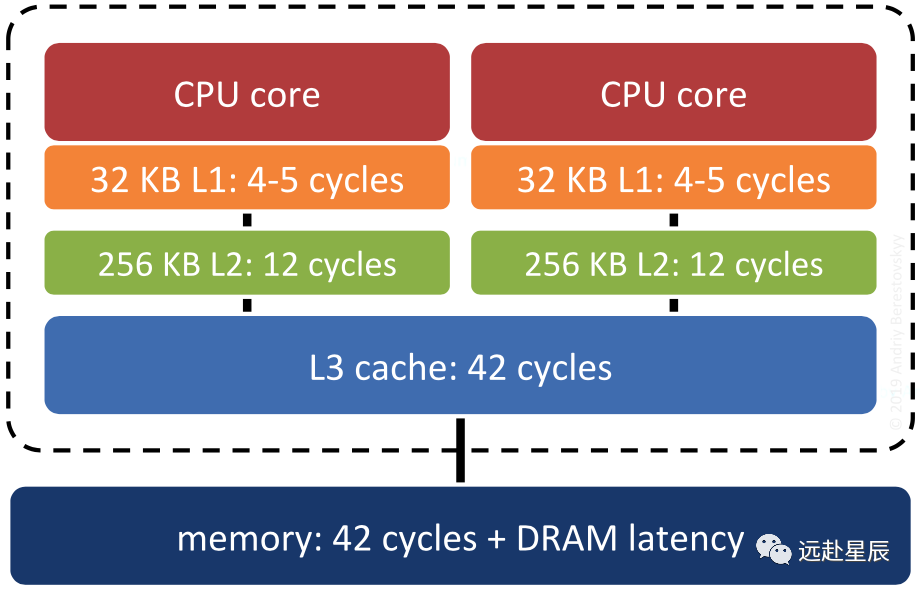
因此,Redis 通過(guò)設(shè)置 CPU 親和性,可以將主進(jìn)程/線程和子進(jìn)程/線程綁定到不同的核隔離開來(lái),使之互不干擾,能有效地提升系統(tǒng)性能。
其次是基于 NUMA 架構(gòu)的考慮,在 NUMA 體系下,內(nèi)存控制器芯片被集成到處理器內(nèi)部,形成 CPU 本地內(nèi)存,訪問(wèn)本地內(nèi)存只需通過(guò)內(nèi)存通道而無(wú)需經(jīng)過(guò)系統(tǒng)總線,訪問(wèn)時(shí)延大大降低,而多個(gè)處理器之間通過(guò) QPI 數(shù)據(jù)鏈路互聯(lián),跨 NUMA 節(jié)點(diǎn)的內(nèi)存訪問(wèn)開銷遠(yuǎn)大于本地內(nèi)存的訪問(wèn):
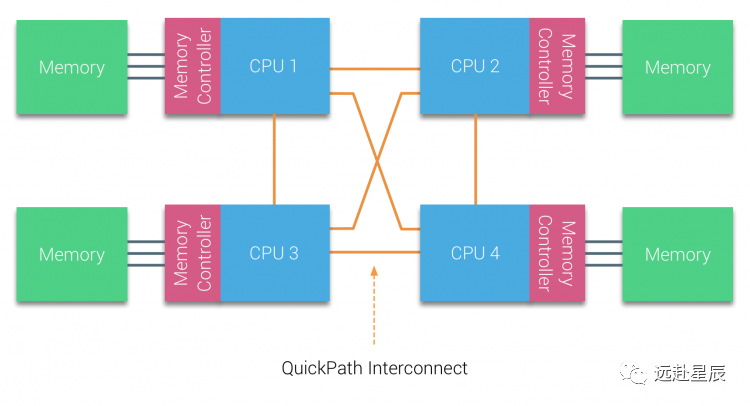
因此,Redis 通過(guò)設(shè)置 CPU 親和性,讓主進(jìn)程/線程盡可能在固定的 NUMA 節(jié)點(diǎn)上的 CPU 上運(yùn)行,更多地使用本地內(nèi)存而不需要跨節(jié)點(diǎn)訪問(wèn)數(shù)據(jù),同樣也能大大地提升性能。
關(guān)于 NUMA 相關(guān)知識(shí)請(qǐng)讀者自行查閱,篇幅所限這里就不再展開,以后有時(shí)間我再單獨(dú)寫一篇文章介紹。
最后還有一點(diǎn),閱讀過(guò)源碼的讀者可能會(huì)有疑問(wèn),Redis 的多線程模式下,似乎并沒有對(duì)數(shù)據(jù)進(jìn)行鎖保護(hù),事實(shí)上 Redis 的多線程模型是全程無(wú)鎖(Lock-free)的,這是通過(guò)原子操作+交錯(cuò)訪問(wèn)來(lái)實(shí)現(xiàn)的,主線程和 I/O 線程之間共享的變量有三個(gè):io_threads_pending 計(jì)數(shù)器、io_threads_op I/O 標(biāo)識(shí)符和 io_threads_list 線程本地任務(wù)隊(duì)列。
io_threads_pending 是原子變量,不需要加鎖保護(hù),io_threads_op 和 io_threads_list ?這兩個(gè)變量則是通過(guò)控制主線程和 I/O 線程交錯(cuò)訪問(wèn)來(lái)規(guī)避共享數(shù)據(jù)競(jìng)爭(zhēng)問(wèn)題:I/O 線程啟動(dòng)之后會(huì)通過(guò)忙輪詢和鎖休眠等待主線程的信號(hào),在這之前它不會(huì)去訪問(wèn)自己的本地任務(wù)隊(duì)列 io_threads_list[id],而主線程會(huì)在分配完所有任務(wù)到各個(gè) I/O 線程的本地隊(duì)列之后才去喚醒 I/O 線程開始工作,并且主線程之后在 I/O 線程運(yùn)行期間只會(huì)訪問(wèn)自己的本地任務(wù)隊(duì)列 io_threads_list[0] 而不會(huì)再去訪問(wèn) I/O 線程的本地隊(duì)列,這也就保證了主線程永遠(yuǎn)會(huì)在 I/O 線程之前訪問(wèn) io_threads_list 并且之后不再訪問(wèn),保證了交錯(cuò)訪問(wèn)。io_threads_op 同理,主線程會(huì)在喚醒 I/O 線程之前先設(shè)置好 io_threads_op 的值,并且在 I/O 線程運(yùn)行期間不會(huì)再去訪問(wèn)這個(gè)變量。
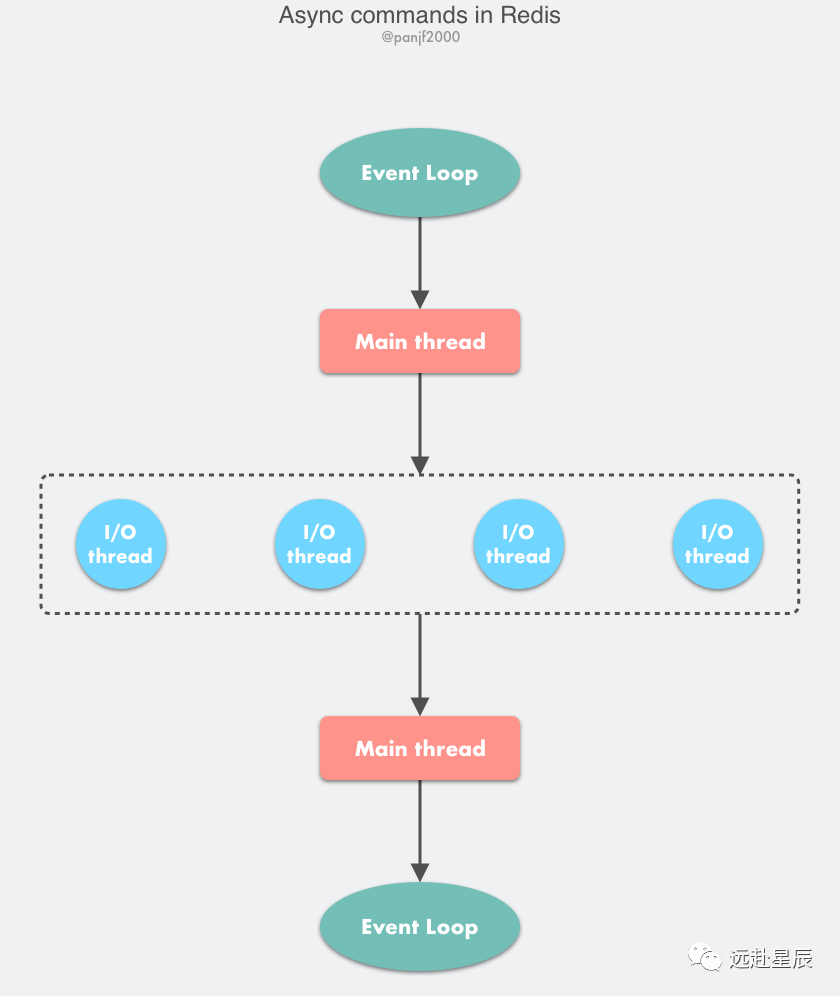
性能提升
Redis 將核心網(wǎng)絡(luò)模型改造成多線程模式追求的當(dāng)然是最終性能上的提升,所以最終還是要以 benchmark 數(shù)據(jù)見真章:
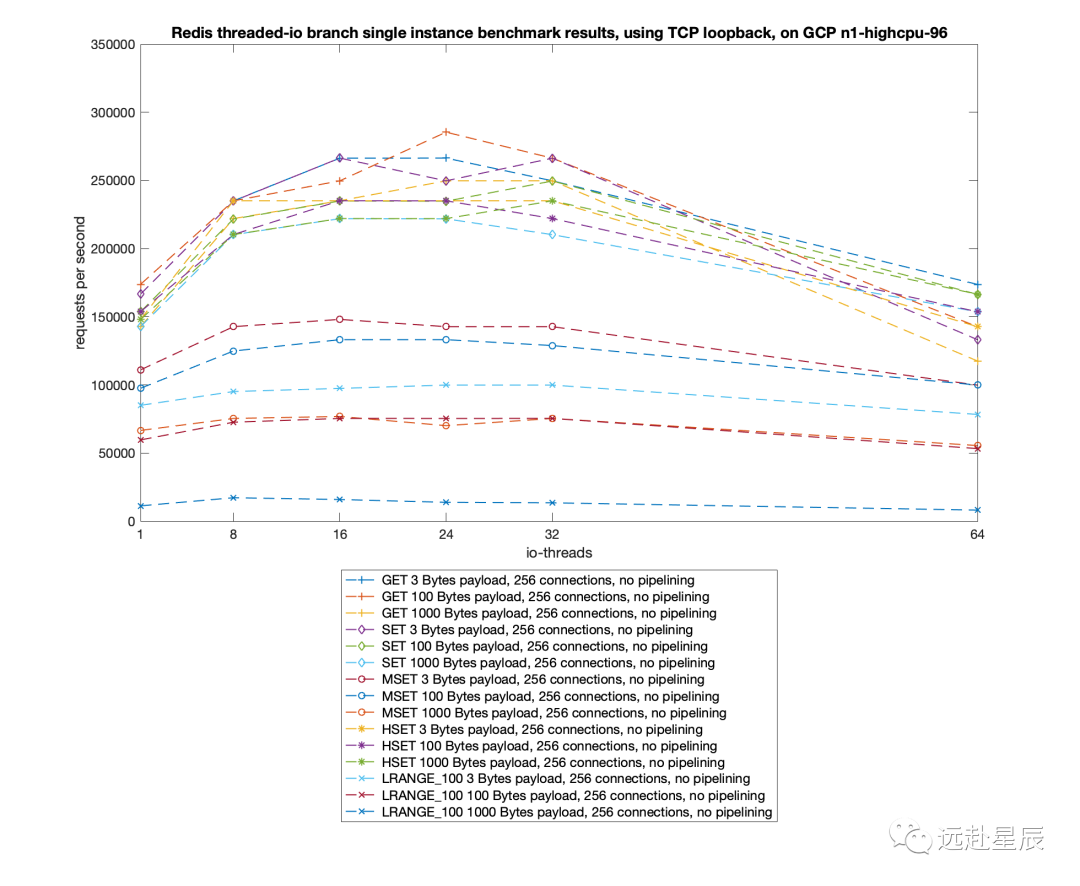
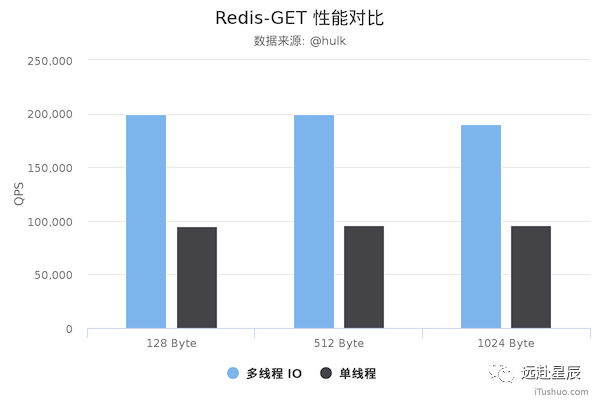
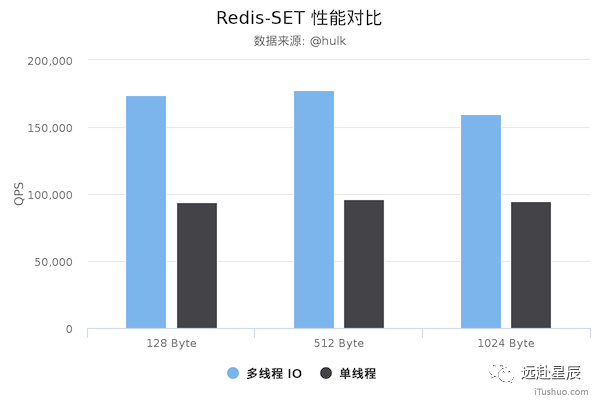
測(cè)試數(shù)據(jù)表明,Redis 在使用多線程模式之后性能大幅提升,達(dá)到了一倍。更詳細(xì)的性能壓測(cè)數(shù)據(jù)可以參閱這篇文章:Benchmarking the experimental Redis Multi-Threaded I/O。
以下是美圖技術(shù)團(tuán)隊(duì)實(shí)測(cè)的新舊 Redis 版本性能對(duì)比圖,僅供參考:
模型缺陷
首先第一個(gè)就是我前面提到過(guò)的,Redis 的多線程網(wǎng)絡(luò)模型實(shí)際上并不是一個(gè)標(biāo)準(zhǔn)的 Multi-Reactors/Master-Workers 模型,和其他主流的開源網(wǎng)絡(luò)服務(wù)器的模式有所區(qū)別,最大的不同就是在標(biāo)準(zhǔn)的 Multi-Reactors/Master-Workers 模式下,Sub Reactors/Workers 會(huì)完成 網(wǎng)絡(luò)讀 -> 數(shù)據(jù)解析 -> 命令執(zhí)行 -> 網(wǎng)絡(luò)寫 整套流程,Main Reactor/Master 只負(fù)責(zé)分派任務(wù),而在 Redis 的多線程方案中,I/O 線程任務(wù)僅僅是通過(guò) socket 讀取客戶端請(qǐng)求命令并解析,卻沒有真正去執(zhí)行命令,所有客戶端命令最后還需要回到主線程去執(zhí)行,因此對(duì)多核的利用率并不算高,而且每次主線程都必須在分配完任務(wù)之后忙輪詢等待所有 I/O 線程完成任務(wù)之后才能繼續(xù)執(zhí)行其他邏輯。
Redis 之所以如此設(shè)計(jì)它的多線程網(wǎng)絡(luò)模型,我認(rèn)為主要的原因是為了保持兼容性,因?yàn)橐郧?Redis 是單線程的,所有的客戶端命令都是在單線程的事件循環(huán)里執(zhí)行的,也因此 Redis 里所有的數(shù)據(jù)結(jié)構(gòu)都是非線程安全的,現(xiàn)在引入多線程,如果按照標(biāo)準(zhǔn)的 Multi-Reactors/Master-Workers 模式來(lái)實(shí)現(xiàn),則所有內(nèi)置的數(shù)據(jù)結(jié)構(gòu)都必須重構(gòu)成線程安全的,這個(gè)工作量無(wú)疑是巨大且麻煩的。
所以,在我看來(lái),Redis 目前的多線程方案更像是一個(gè)折中的選擇:既保持了原系統(tǒng)的兼容性,又能利用多核提升 I/O 性能。
其次,目前 Redis 的多線程模型中,主線程和 I/O 線程的通信過(guò)于簡(jiǎn)單粗暴:忙輪詢和鎖,因?yàn)橥ㄟ^(guò)自旋忙輪詢進(jìn)行等待,導(dǎo)致 Redis 在啟動(dòng)的時(shí)候以及運(yùn)行期間偶爾會(huì)有短暫的 CPU 空轉(zhuǎn)引起的高占用率,而且這個(gè)通信機(jī)制的最終實(shí)現(xiàn)看起來(lái)非常不直觀和不簡(jiǎn)潔,希望后面 Redis 能對(duì)目前的方案加以改進(jìn)。
總結(jié)
Redis 作為緩存系統(tǒng)的事實(shí)標(biāo)準(zhǔn),它的底層原理值得開發(fā)者去深入學(xué)習(xí),Redis 自 2009 年發(fā)布第一版之后,其單線程網(wǎng)絡(luò)模型的選擇在社區(qū)中從未停止過(guò)討論,多年來(lái)一直有呼聲希望 Redis 能引入多線程從而利用多核優(yōu)勢(shì),但是作者 antirez 是一個(gè)追求大道至簡(jiǎn)的開發(fā)者,對(duì) Redis 加入任何新功能都異常謹(jǐn)慎,所以在 Redis 初版發(fā)布的十年后才最終將 Redis 的核心網(wǎng)絡(luò)模型改造成多線程模式,這期間甚至誕生了一些 Redis 多線程的替代項(xiàng)目。雖然 antirez 一直在推遲多線程的方案,但卻從未停止思考多線程的可行性,Redis 多線程網(wǎng)絡(luò)模型的改造不是一朝一夕的事情,這其中牽扯到項(xiàng)目的方方面面,所以我們可以看到 Redis 的最終方案也并不完美,沒有采用主流的多線程模式設(shè)計(jì)。
讓我們來(lái)回顧一下 Redis 多線程網(wǎng)絡(luò)模型的設(shè)計(jì)方案:
- 使用 I/O 線程實(shí)現(xiàn)網(wǎng)絡(luò) I/O 多線程化,I/O 線程只負(fù)責(zé)網(wǎng)絡(luò) I/O 和命令解析,不執(zhí)行客戶端命令。
- 利用原子操作+交錯(cuò)訪問(wèn)實(shí)現(xiàn)無(wú)鎖的多線程模型。
- 通過(guò)設(shè)置 CPU 親和性,隔離主進(jìn)程和其他子進(jìn)程,讓多線程網(wǎng)絡(luò)模型能發(fā)揮最大的性能。
通讀本文之后,相信讀者們應(yīng)該能夠了解到一個(gè)優(yōu)秀的網(wǎng)絡(luò)系統(tǒng)的實(shí)現(xiàn)所涉及到的計(jì)算機(jī)領(lǐng)域的各種技術(shù):設(shè)計(jì)模式、網(wǎng)絡(luò) I/O、并發(fā)編程、操作系統(tǒng)底層,甚至是計(jì)算機(jī)硬件。另外還需要對(duì)項(xiàng)目迭代和重構(gòu)的謹(jǐn)慎,對(duì)技術(shù)方案的深入思考,絕不僅僅是寫好代碼這一個(gè)難點(diǎn)。
參考&延伸閱讀
- Redis v5.0.10
- Redis v6.0.10
- Lazy Redis is better Redis
- An update about Redis developments in 2019
- How fast is Redis?
- Go netpoller 原生網(wǎng)絡(luò)模型之源碼全面揭秘
- Linux I/O 原理和 Zero-copy 技術(shù)全面揭秘
- Benchmarking the experimental Redis Multi-Threaded I/O
- NUMA DEEP DIVE PART 1: FROM UMA TO NUMA
References
[1]?Lazy Redis is better Redis:?http://antirez.com/news/93[2]?Linux I/O 原理和 Zero-copy 技術(shù)全面揭秘:?https://strikefreedom.top/linux-io-and-zero-copy[3]?Go netpoller 原生網(wǎng)絡(luò)模型之源碼全面揭秘:?https://strikefreedom.top/go-netpoll-io-multiplexing-reactor[4]?Redis v6.0.10:?https://github.com/redis/redis/tree/6.0.10[5]?Benchmarking the experimental Redis Multi-Threaded I/O:?https://itnext.io/benchmarking-the-experimental-redis-multi-threaded-i-o-1bb28b69a314[6]?Redis v5.0.10:?https://github.com/redis/redis/tree/5.0.10[7]?Redis v6.0.10:?https://github.com/redis/redis/tree/6.0.10[8]?Lazy Redis is better Redis:?http://antirez.com/news/93[9]?An update about Redis developments in 2019:?http://antirez.com/news/126[10]?How fast is Redis?:?https://redis.io/topics/benchmarks[11]?Go netpoller 原生網(wǎng)絡(luò)模型之源碼全面揭秘:?https://strikefreedom.top/go-netpoll-io-multiplexing-reactor[12]?Linux I/O 原理和 Zero-copy 技術(shù)全面揭秘:?https://strikefreedom.top/linux-io-and-zero-copy[13]?Benchmarking the experimental Redis Multi-Threaded I/O:?https://itnext.io/benchmarking-the-experimental-redis-multi-threaded-i-o-1bb28b69a314[14]?NUMA DEEP DIVE PART 1: FROM UMA TO NUMA:?https://frankdenneman.nl/2016/07/07/numa-deep-dive-part-1-uma-numa

?END_?


