
阿里醫(yī)療NLP實踐與思考

來源:DataFunTalk 本文約8000字,建議閱讀10+分鐘 本文將從數(shù)據(jù)、算法、知識3個層面帶來阿里在醫(yī)療NLP領(lǐng)域的工作、遇到的問題以及相應的思考。

醫(yī)學影像(國內(nèi)較為成功的醫(yī)療AI公司基本都是醫(yī)學影像方向); 文本信息抽取和疾病預測(我們今天分享的重點); 病患語音識別和機器翻譯(三甲醫(yī)院醫(yī)生用話筒講話,然后ASR語音識別轉(zhuǎn)錄成電子病歷的內(nèi)容,通常用到RNN或Seq2Seq的技術(shù)實現(xiàn)); 體征監(jiān)測和疾病風險評估(應用場景包括慢病評估,健康管理等); 新藥研發(fā)(新冠疫情之后逐漸興起,目前該領(lǐng)域較為火爆) 手術(shù)機器人(交叉學科,一般會涉及到增強學習技術(shù))。
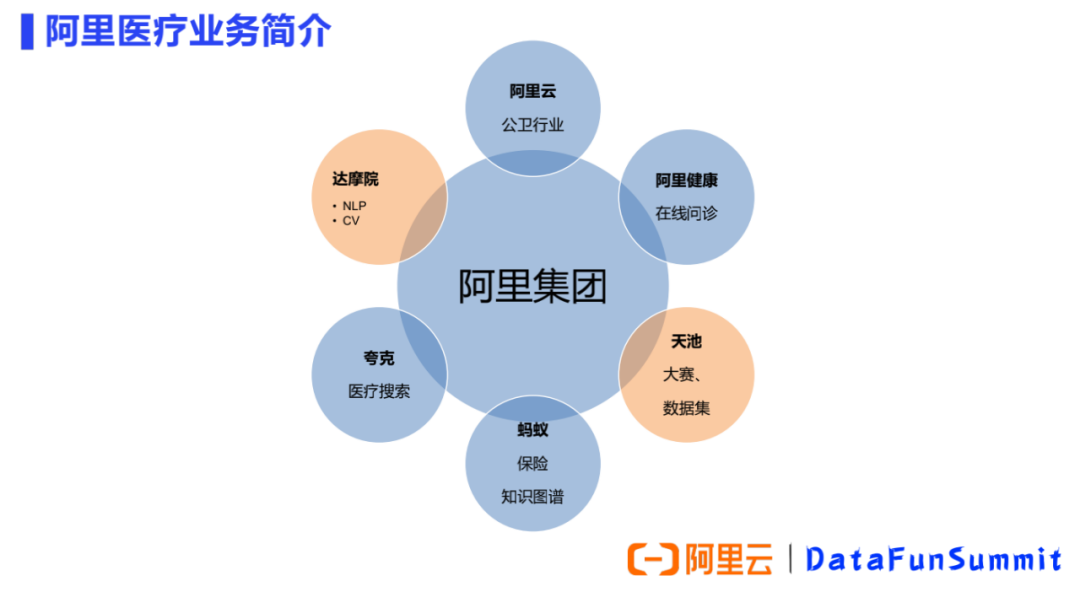
阿里云:面向B端,主要服務(wù)于公衛(wèi)領(lǐng)域如醫(yī)院、衛(wèi)健委等智慧醫(yī)療的應用場景。 阿里健康:可分為兩部分,包括電商售藥和互聯(lián)網(wǎng)在線問診,其中線上問診涉及到的自動問答技術(shù)與NLP強相關(guān)。 螞蟻保險:在智能理賠過程中,患者上傳病歷或收據(jù),經(jīng)OCR識別、文本信息抽取后被用于服務(wù)核保核賠預測模型。 夸克瀏覽器:面向醫(yī)療的垂直搜索。 達摩院:兩個團隊在做醫(yī)療AI的業(yè)務(wù)。①NLP團隊:主要負責NLP原子技術(shù)能力,服務(wù)于阿里集團內(nèi)的一些業(yè)務(wù)方、以及阿里云的生態(tài)合作伙伴。②華先勝博士所負責的城市大腦團隊:主要負責醫(yī)學影像,根據(jù)影像圖片做輔助診療。 天池:天池大賽的定位是針對人工智能技術(shù)尚未成熟的行業(yè),先通過來源于真實場景的數(shù)據(jù)集把問題提出來,然后征募選手來做比賽方案,相當于做一個先期的技術(shù)驗證。天池開放了很多行業(yè)稀缺的數(shù)據(jù)集,尤其是醫(yī)療行業(yè)。
電子病歷數(shù)據(jù):是講者處理較多的數(shù)據(jù),特點是數(shù)據(jù)的非標準化和多樣性。 藥品說明書,檢查報告單和體檢報告:這3類數(shù)據(jù)比較規(guī)范。 在線問診,論壇問答:數(shù)據(jù)質(zhì)量較差,其特點是口語多,噪音大。患者就診過程中涉及較多不相關(guān)信息,醫(yī)生的工作主要負責識別、總結(jié)有效信息,然后我們再應用NLP去做后續(xù)的分析處理。 醫(yī)學教科書、科研文獻:數(shù)據(jù)比較規(guī)范。我們應用NLP技術(shù)把文本類內(nèi)容解析出來。
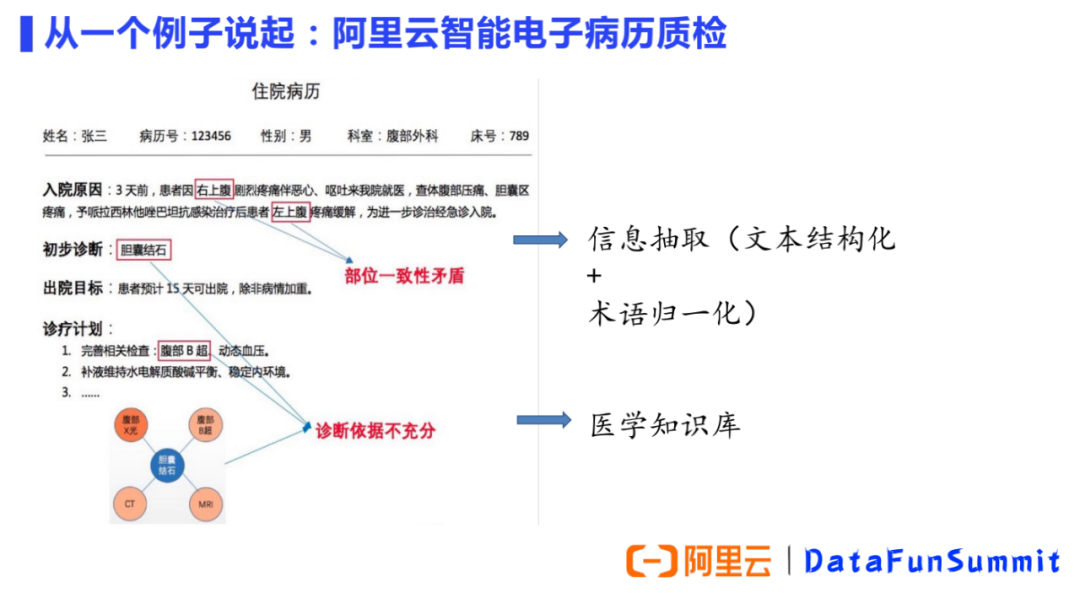
一致性矛盾:患者一開始疼痛的部位是“右”上腹,后來經(jīng)過治療“左”上腹疼痛緩解。我們的產(chǎn)品準確的捕捉到患者初始癥狀出現(xiàn)的部位以及治療改善的部位不一致。 診斷依據(jù)不充分:住院病歷中的初步診斷寫的是膽囊結(jié)石,但是下一步診療計劃里卻出現(xiàn)了腹部B超,可見該患者尚不能明確診斷為膽囊結(jié)石。如果臨床高度懷疑膽囊結(jié)石,初步診斷可寫“腹痛待查,膽囊結(jié)石?”,而不能只寫“膽囊結(jié)石”。我們的產(chǎn)品準確的捕捉了診斷依據(jù)的不充分。

實體屬性:如當前疾病是現(xiàn)病史(現(xiàn)在發(fā)生的)還是既往史(過去就有的),癥狀是陽性(肯定)還是陰性(否定)。傳統(tǒng)的方法是使用關(guān)系抽取模型,但我們的產(chǎn)品為了追求效率沒有用關(guān)系抽取的方式,而是用了下圖中的模型。 嵌套:如圖中的癥狀中就包含了身體部位,醫(yī)學文本中有大量嵌套類型的實體存在。 非連續(xù):在藥品說明書中大量存在。
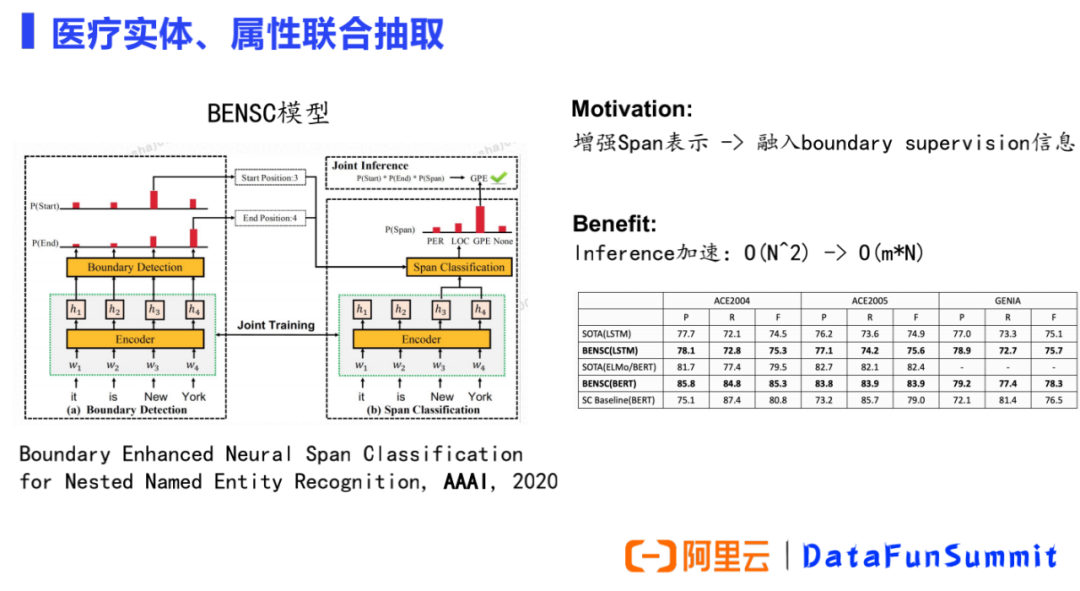
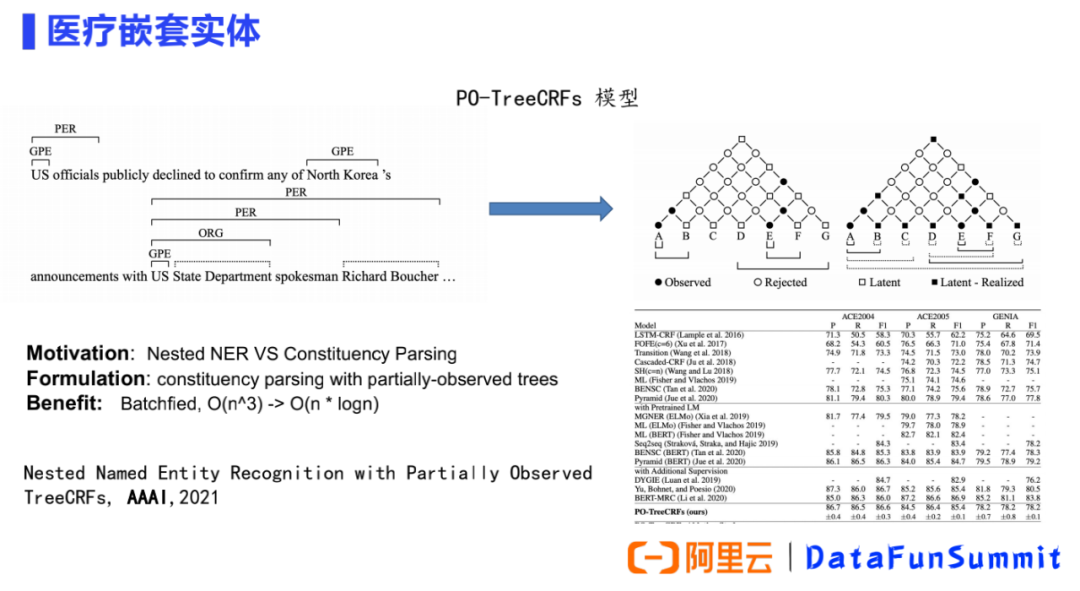
② 基于嵌套實體構(gòu)建模型:
我們針對醫(yī)學嵌套實體的特點開展了很多研究的工作,上圖是我們發(fā)表在AAAI2021的一個工作。我們將嵌套 NER識別問題看作是經(jīng)典的句法成分分析(constituent parsing)問題, 根據(jù)嵌套實體的特點將其視為部分觀察(partial observed)到的樹,進行選區(qū)解析,并使用部分觀察到的 TreeCRF 對其進行建模。具體來說,將所有標記的實體span視為選區(qū)樹中的觀察節(jié)點(黑點),將其他跨度視為潛在節(jié)點(白點)。該模型其中的一個優(yōu)點是,實現(xiàn)了一種統(tǒng)一的方式來聯(lián)合建模觀察到的和潛在的節(jié)點。而另外一個優(yōu)點是,在進行選區(qū)分析時,通過Batchfied將模型復雜度從O(n^3)降為O(nⅹlogn)。
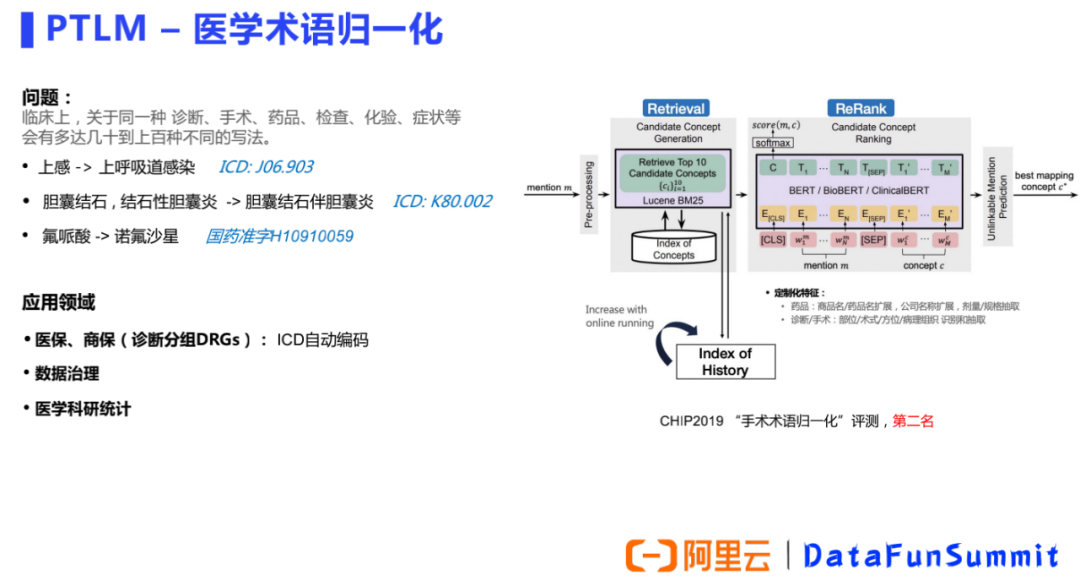

是PTLM應用的另一個場景。例如盡管開塞露的藥品說明書的適應癥只有便秘,但醫(yī)生給診斷是腸梗阻的患者使用開塞露也是合理的。這是因為雖然醫(yī)生的診斷與藥品說明書字面上不match,但腸梗阻實際上會導致便秘,所以經(jīng)過推理醫(yī)生用藥是合理的,而這個推理過程用到的就是醫(yī)學知識。



CBLUE地址:
https://tianchi.aliyun.com/specials/promotion/2021chinesemedicalnlpleaderboardchallenge

編輯:黃繼彥
校對:汪雨晴
評論
圖片
表情