
【NLP】BERT 模型與中文文本分類實(shí)踐
簡介
2018年10月11日,Google發(fā)布的論文《Pre-training of Deep Bidirectional Transformers for Language Understanding》[1],提出的 BERT 模型成功在11項(xiàng) NLP 任務(wù)中取得 state of the art 的結(jié)果,贏得自然語言處理學(xué)界的一片贊譽(yù)之聲,成為 NLP 發(fā)展史上的里程碑式的模型成就。BERT 的全稱是 Bidirectional Encoder Representations from Transformer。
Bidirectional:BERT 的模型結(jié)構(gòu)和 ELMo 類似,均為雙向的。 Encoder:BERT 只是用到了 Transformer 的 Encoder 編碼器部分。 Representation:做詞 / 句子的語義表征。 Transformer:Transformer Encoder 是 BERT 模型的核心組成部分。
BERT 模型的目標(biāo)是利用自監(jiān)督學(xué)習(xí)方法在大規(guī)模無標(biāo)注語料上進(jìn)行預(yù)訓(xùn)練,從而捕捉文本中的豐富語義信息。在后續(xù)特定的 NLP 任務(wù)中,我們可以根據(jù)任務(wù)類型對(duì) BERT 預(yù)訓(xùn)練模型參數(shù)進(jìn)行微調(diào),以取得更好的任務(wù)效果。BERT 論文鏈接:https://arxiv.org/abs/1810.04805 ,github 地址:https://github.com/google-research/bert
模型理解
網(wǎng)絡(luò)架構(gòu)
BERT 的網(wǎng)絡(luò)架構(gòu)使用的是《Attention is all you need》[2] 中提出的多層 Transformer Encoder 結(jié)構(gòu),其最大的特點(diǎn)是拋棄了傳統(tǒng)的 RNN 和 CNN,通過 Attention 機(jī)制將任意位置的兩個(gè)單詞的距離轉(zhuǎn)換成1,有效的解決了 NLP 中棘手的長期依賴問題。Transformer 的結(jié)構(gòu)在 NLP 領(lǐng)域中已經(jīng)得到了廣泛應(yīng)用,其網(wǎng)絡(luò)架構(gòu)如下圖所示,Transformer 是一個(gè) encoder-decoder 的結(jié)構(gòu),由若干個(gè)編碼器和解碼器堆疊形成。圖中的左側(cè)部分為編碼器,由 Multi-Head Attention 和 Feed Forward 全連接層組成,用于將輸入語料轉(zhuǎn)化成特征向量。右側(cè)部分是解碼器,其輸入為編碼器的輸出以及已經(jīng)預(yù)測出的結(jié)果,由 Masked Multi-Head Attention, Multi-Head Attention 以及 Feed Forward 全連接層組成,用于輸出最后結(jié)果的條件概率。
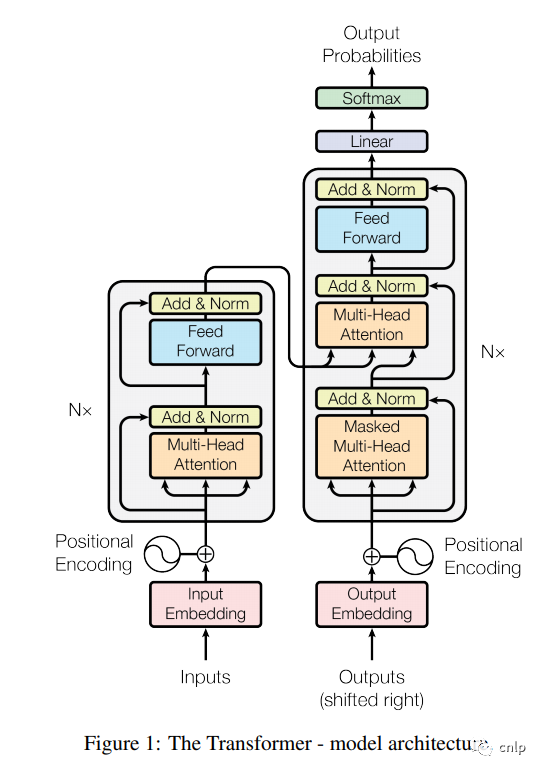
上圖的左側(cè)部分是一個(gè) Transformer Block,對(duì)應(yīng)到下圖中的一個(gè) “Trm”。
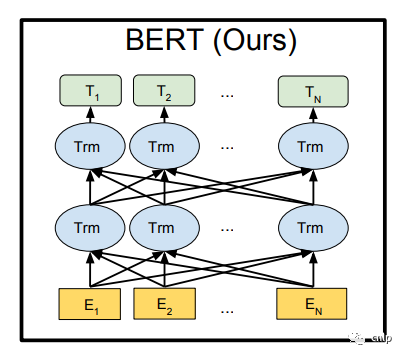
BERT 提供了基礎(chǔ)和復(fù)雜兩個(gè)模型,對(duì)應(yīng)的超參數(shù)分別如下:
:L=12,H=768,A=12,參數(shù)總量110M :L=24,H=1024,A=16,參數(shù)總量340M
其中 L 表示網(wǎng)絡(luò)的層數(shù)(即 Transformer blocks 的數(shù)量),A 表示 Multi-Head Attention 中 self-Attention 的數(shù)量,H 是輸出向量的維度。谷歌提供了中文 BERT 基礎(chǔ)預(yù)訓(xùn)練模型 bert-base-chinese,TensorFlow 版模型鏈接:https://storage.googleapis.com/bert_models/2018_11_03/chinese_L-12_H-768_A-12.zip ,Pytorch 版模型權(quán)重鏈接:https://huggingface.co/bert-base-chinese/tree/main
BERT 論文中還對(duì)比了 GPT[3] 和 ELMo[4],它們兩個(gè)的結(jié)構(gòu)如下圖所示:
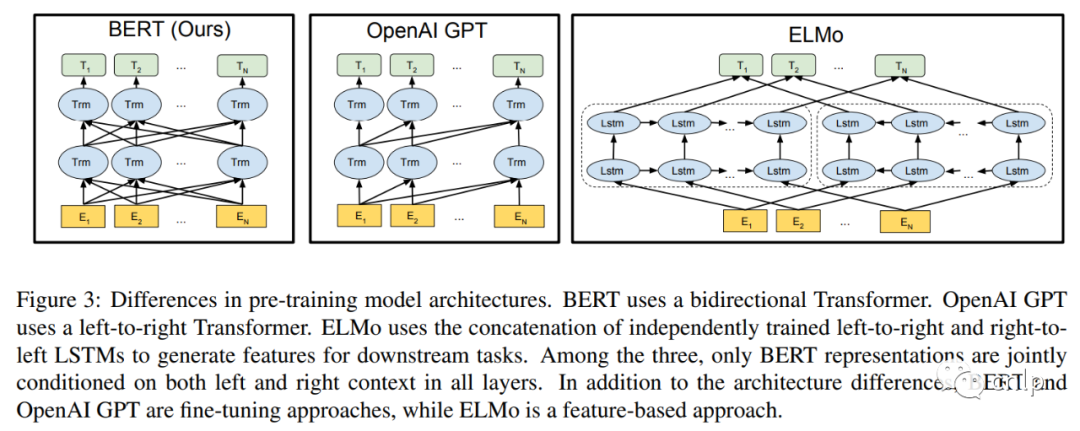
其中 BERT 使用的是雙向 Transformer 編碼器,GPT 使用的是單向 Transformer 解碼器,ELMo 使用兩個(gè)獨(dú)立訓(xùn)練的 LSTM 結(jié)構(gòu),只有BERT表征會(huì)基于所有層中的左右兩側(cè)語境。除了結(jié)構(gòu)上的不同,BERT 和 GPT 是基于微調(diào)的方式,而 ELMo 是基于特征的方法。
輸入表示
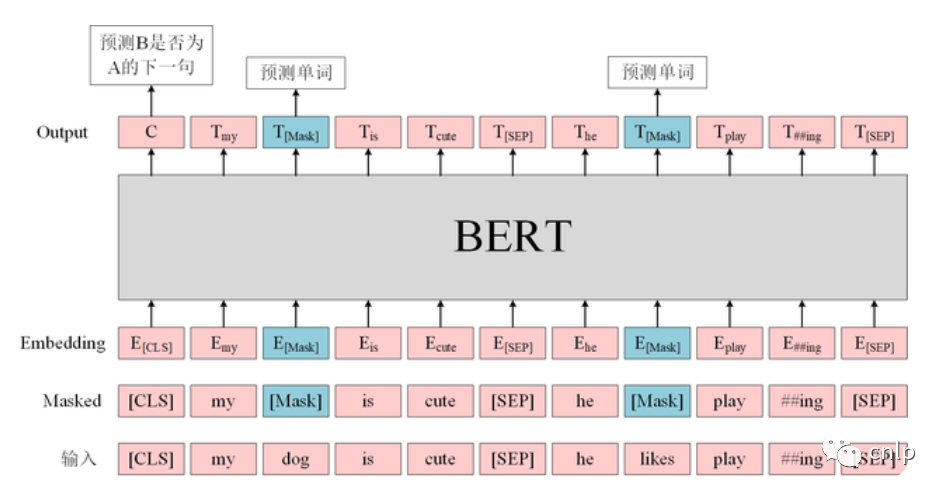
BERT 模型的輸入為表示單個(gè)文本句或一對(duì)文本的詞序列,對(duì)于給定的詞,其輸入表示通過三部分 Embedding 求和得到。
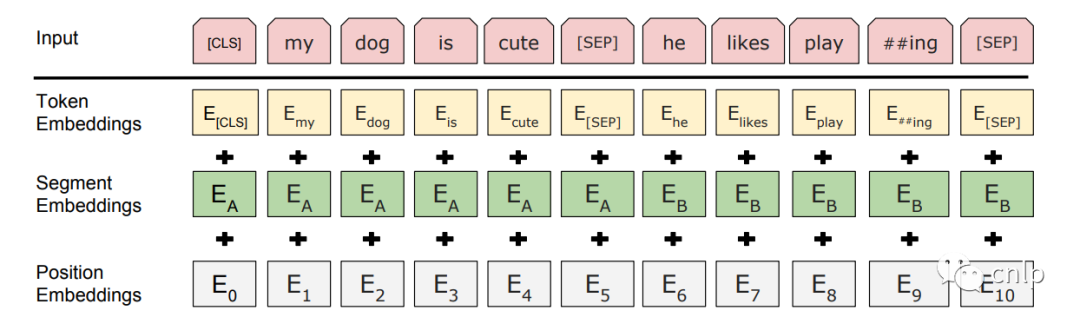
Token Embeddings:WordPiece 分詞后的詞向量。 Position Embedding:位置嵌入是指將單詞的位置信息編碼成特征向量,位置嵌入是向模型中引入單詞位置關(guān)系的至關(guān)重要的一環(huán)。 Segment Embedding:用于區(qū)分兩個(gè)句子。對(duì)于句子對(duì)輸入,第一個(gè)句子的特征值是0,第二個(gè)句子的特征值是1。
圖中的兩個(gè)特殊符號(hào)[CLS]和 [SEP]:[CLS]一般位于句首,是輸入的第一個(gè) token,其對(duì)應(yīng)的輸出向量可以作為整個(gè)輸入句子的表示,用于之后的分類任務(wù)。[SEP]表示分句符號(hào),用于斷開輸入語料中的兩個(gè)句子。
預(yù)訓(xùn)練任務(wù)
BERT 模型使用兩個(gè)新的無監(jiān)督預(yù)測任務(wù)進(jìn)行預(yù)訓(xùn)練,分別是 Masked LM(MLM)和 Next Sentence Prediction(NSP)。
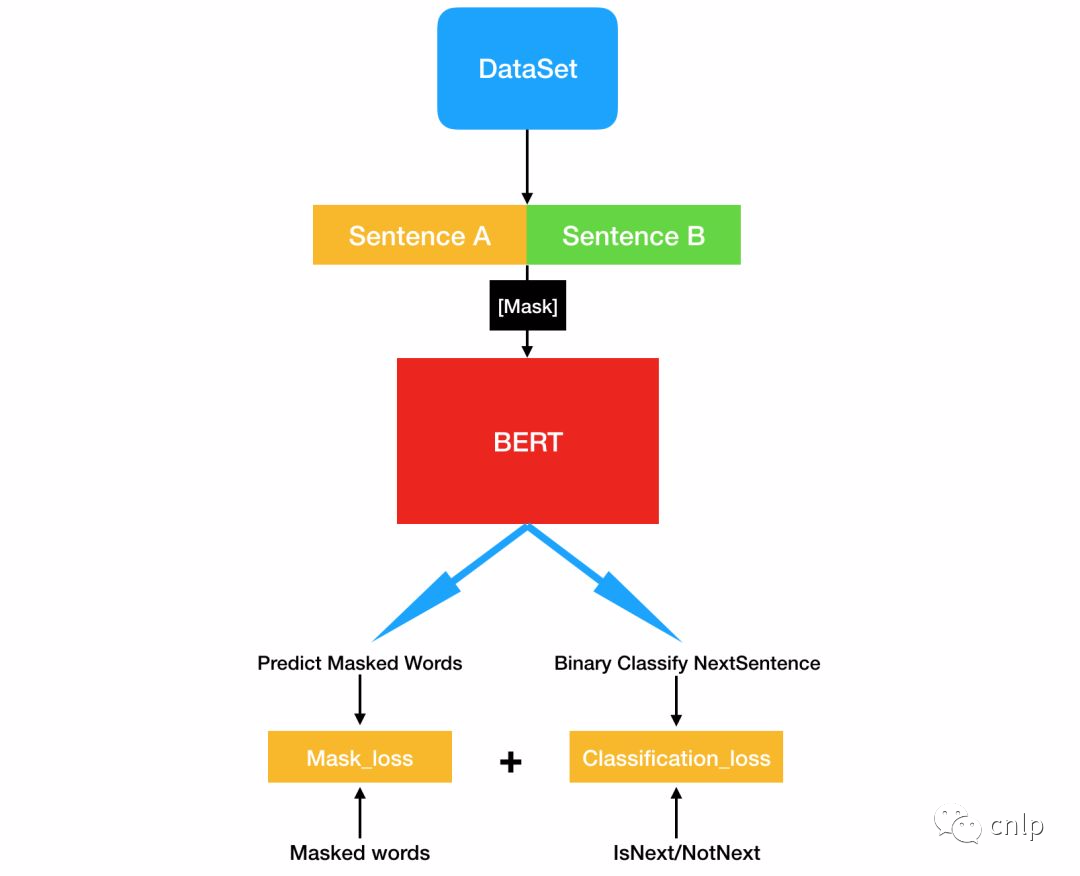
Masked LM
為了訓(xùn)練深度雙向 Transformer 表示,采用了一種簡單的方法:隨機(jī)掩蓋部分輸入詞,然后對(duì)那些被掩蓋的詞進(jìn)行預(yù)測,此方法被稱為“Masked LM”(MLM)。該任務(wù)非常像我們在中學(xué)時(shí)期經(jīng)常做的完形填空。正如傳統(tǒng)的語言模型算法和 RNN 匹配一樣,MLM 的這個(gè)性質(zhì)和 Transformer 的結(jié)構(gòu)也是非常匹配的。
BERT 在預(yù)訓(xùn)練時(shí)只預(yù)測[MASK]位置的單詞,這樣就可以同時(shí)利用上下文信息。但是在后續(xù)使用的時(shí)候,句子中并不會(huì)出現(xiàn)[MASK]的單詞,這樣會(huì)影響模型的性能。因此在訓(xùn)練時(shí)采用如下策略,隨機(jī)選擇句子中15%的單詞進(jìn)行 Mask,在選擇為 Mask 的單詞中,有80%真的使用[MASK]進(jìn)行替換,10%使用一個(gè)隨機(jī)單詞替換,剩下10%保留原詞不進(jìn)行替換。
原句:my dog is hairy 80%:my dog is [MASK]10%:my dog is apple 10%:my dog is hairy
注意最后10%保留原句是為了將表征偏向真實(shí)觀察值,而另外10%用其它隨機(jī)詞替代原詞并不會(huì)影響模型對(duì)語言的理解能力,因?yàn)樗徽妓性~的1.5%(0.1 × 0.15)。此外,作者在論文中還表示因?yàn)槊看沃荒茴A(yù)測15%的詞,因此模型收斂比較慢。
Next Sentence Prediction
Next Sentence Prediction(NSP)是一個(gè)二分類任務(wù),其目標(biāo)是判斷句子 B 是否是句子 A 的下文,如果是的話輸出標(biāo)簽為 ‘IsNext’,否則輸出標(biāo)簽為 ‘NotNext’。BERT 使用這一預(yù)訓(xùn)練任務(wù)的主要原因是,很多句子級(jí)別的任務(wù)如自動(dòng)問答(QA)和自然語言推理(NLI)都需要理解兩個(gè)句子之間的關(guān)系。訓(xùn)練數(shù)據(jù)的生成方式是從平行語料中隨機(jī)抽取的連續(xù)兩句話,其中50%保留抽取的兩句話,它們符合 IsNext 關(guān)系,另外50%的第二句話是隨機(jī)從預(yù)料中提取的,它們的關(guān)系是 NotNext 的。BERT 模型使用[CLS]的編碼信息進(jìn)行預(yù)測。
輸入: [CLS]我 喜 歡 玩 英[MASK]聯(lián) 盟[SEP]我 最 擅 長 的[MASK]色 是 亞 索[SEP]類別:IsNext 輸入: [CLS]我 喜 歡 玩 英[MASK]聯(lián) 盟[SEP]今 天 天 氣 很[MASK][SEP]類別:NotNext
BERT 預(yù)訓(xùn)練的過程可以用下圖來表示。
微調(diào)
預(yù)訓(xùn)練得到的 BERT 模型可以在后續(xù)用于具體 NLP 任務(wù)的時(shí)候進(jìn)行微調(diào) (Fine-tuning 階段),BERT 模型可以適用于多種不同的 NLP 任務(wù),如下圖所示。
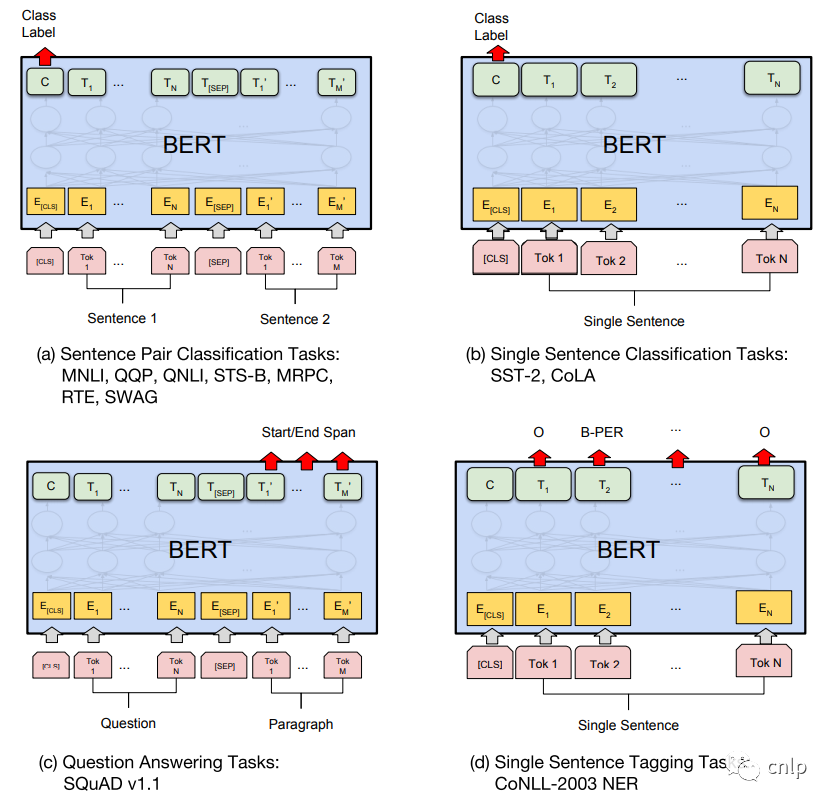
句子對(duì)分類任務(wù)
例如自然語言推斷 (MNLI),句子語義等價(jià)判斷 (QQP) 等,如上圖 (a) 所示,需要將兩個(gè)句子傳入 BERT,然后使用 [CLS] 的輸出向量 C 進(jìn)行句子對(duì)分類。
單句分類任務(wù)
例如句子情感分析 (SST-2),判斷句子語法是否可以接受 (CoLA) 等,如上圖 (b) 所示,只需要輸入一個(gè)句子,無需使用 [SEP] 標(biāo)志,然后也是用 [CLS] 的輸出向量 C 進(jìn)行分類。
問答任務(wù)
如 SQuAD v1.1 數(shù)據(jù)集,樣本是語句對(duì) (Question, Paragraph),Question 表示問題,Paragraph 是一段來自 Wikipedia 的文本,Paragraph 包含了問題的答案。而訓(xùn)練的目標(biāo)是在 Paragraph 中找出答案的起始位置 (Start,End)。如上圖 (c) 所示,將 Question 和 Paragraph 傳入 BERT,然后 BERT 根據(jù) Paragraph 所有單詞的輸出預(yù)測 Start 和 End 的位置。
單句標(biāo)注任務(wù)
例如命名實(shí)體識(shí)別 (NER),輸入單個(gè)句子,然后根據(jù) BERT 對(duì)于每個(gè)單詞的輸出向量 T 預(yù)測這個(gè)單詞的類別,是屬于 Person,Organization,Location,Miscellaneous 還是 Other (非命名實(shí)體)。
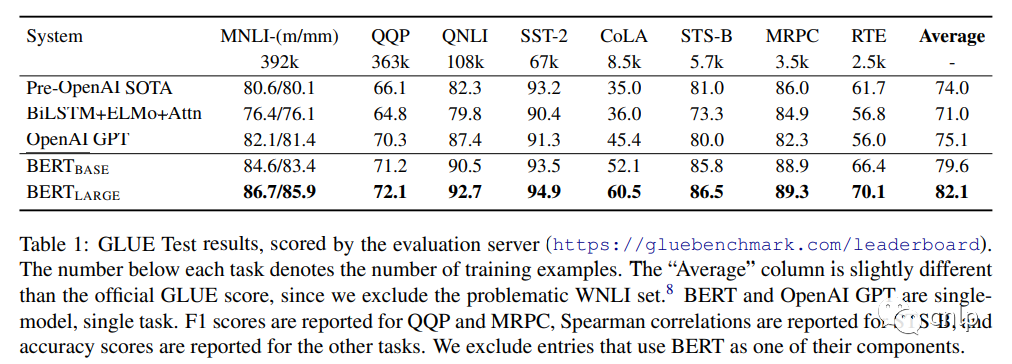
任務(wù)效果
中文文本分類實(shí)踐
基于 pytorch-transformers 實(shí)現(xiàn)的 BERT 中文文本分類代碼倉庫:https://github.com/zejunwang1/bert_text_classification 。該倉庫主要包含 data 文件夾、pretrained_bert 文件夾和4個(gè) python 源文件。
config.py:模型配置文件,主要配置訓(xùn)練集 / 驗(yàn)證集 / 測試集數(shù)據(jù)路徑,模型存儲(chǔ)路徑,batch size,最大句子長度和優(yōu)化器相關(guān)參數(shù)等。 preprocess.py:實(shí)現(xiàn) DataProcessor 數(shù)據(jù)預(yù)處理類。 main.py:主程序入口。 train.py:模型訓(xùn)練和評(píng)估代碼。
從 THUCNews 中隨機(jī)抽取20萬條新聞標(biāo)題,一共有10個(gè)類別:財(cái)經(jīng)、房產(chǎn)、股票、教育、科技、社會(huì)、時(shí)政、體育、游戲、娛樂,每類2萬條標(biāo)題數(shù)據(jù)。數(shù)據(jù)集按如下劃分:
訓(xùn)練集:18萬條新聞標(biāo)題,每個(gè)類別的標(biāo)題數(shù)為18000 驗(yàn)證集:1萬條新聞標(biāo)題,每個(gè)類別的標(biāo)題數(shù)為1000 測試集:1萬條新聞標(biāo)題,每個(gè)類別的標(biāo)題數(shù)為1000
訓(xùn)練集對(duì)應(yīng) data 文件夾下的 train.txt,驗(yàn)證集對(duì)應(yīng) data 文件夾下的 dev.txt,測試集對(duì)應(yīng) data 文件夾下的 test.txt。可以按照 data 文件夾中的數(shù)據(jù)格式來準(zhǔn)備自己任務(wù)所需的數(shù)據(jù),并調(diào)整 config.py 中的相關(guān)配置參數(shù)。
預(yù)訓(xùn)練 BERT 模型
從 huggingface 官網(wǎng)上下載 bert-base-chinese 模型權(quán)重、配置文件和詞典到 pretrained_bert 文件夾中,下載地址:https://huggingface.co/bert-base-chinese/tree/main
模型訓(xùn)練
文本分類模型訓(xùn)練:
python main.py --mode train --data_dir ./data --pretrained_bert_dir ./pretrained_bert
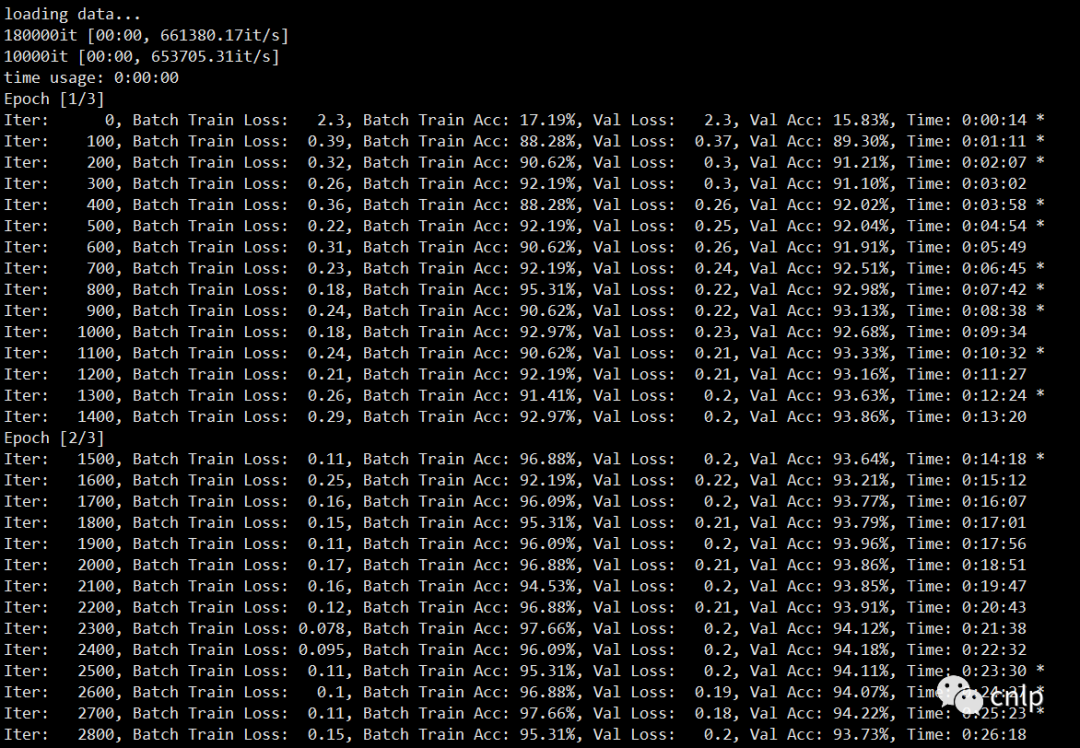
訓(xùn)練中間日志如下:
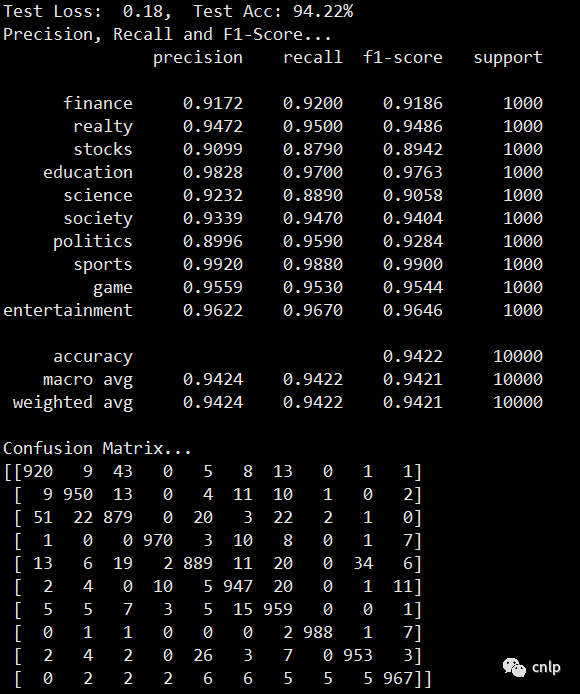
模型在驗(yàn)證集上的效果如下:
Demo演示
文本分類 demo 展示:
python main.py --mode demo --data_dir ./data --pretrained_bert_dir ./pretrained_bert

模型預(yù)測
對(duì) data 文件夾下的 input.txt 中的文本進(jìn)行分類預(yù)測:
python main.py --mode predict --data_dir ./data --pretrained_bert_dir ./pretrained_bert --input_file ./data/input.txt
輸出如下結(jié)果:

參考文獻(xiàn)
[1] BERT: https://arxiv.org/pdf/1810.04805.pdf
[2] Transformer: https://arxiv.org/pdf/1706.03762.pdf
[3] GPT: https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf
[4] ELMo: https://arxiv.org/pdf/1802.05365.pdf
往期精彩回顧 本站qq群851320808,加入微信群請掃碼: