
?Complexer-YOLO:基于語(yǔ)義點(diǎn)云的實(shí)時(shí)三維目標(biāo)檢測(cè)與跟蹤

摘要

主要貢獻(xiàn)
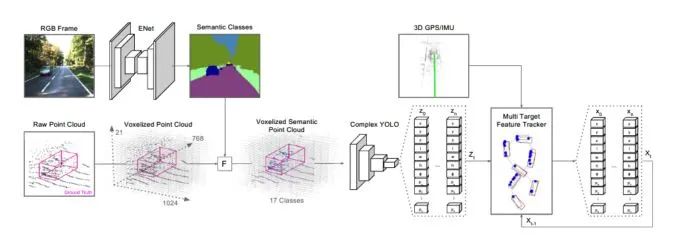
算法結(jié)構(gòu)
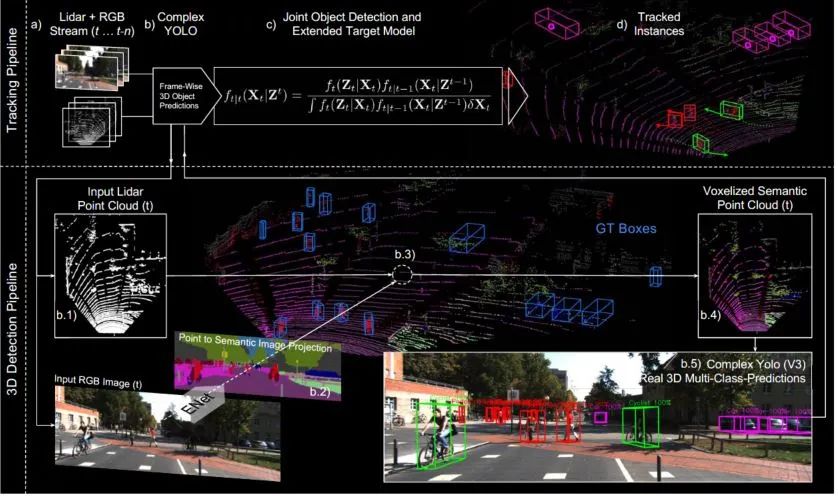
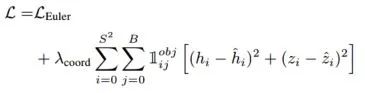
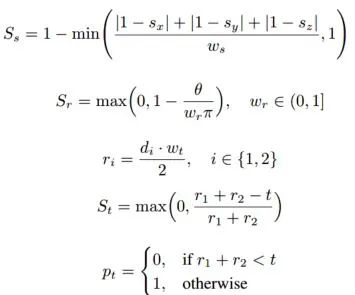
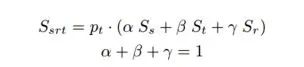
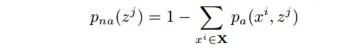
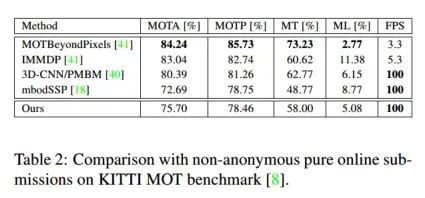
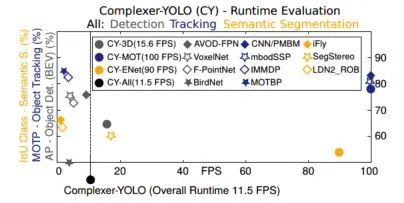
主要結(jié)果

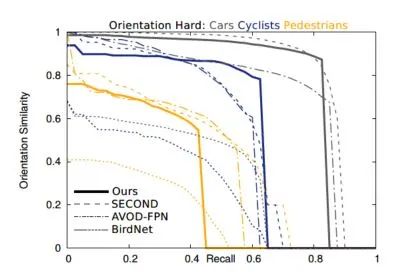

?------------------------------------------------
雙一流大學(xué)研究生團(tuán)隊(duì)創(chuàng)建,一個(gè)專(zhuān)注于目標(biāo)檢測(cè)與深度學(xué)習(xí)的組織,希望可以將分享變成一種習(xí)慣。
整理不易,點(diǎn)贊三連!
評(píng)論
圖片
表情