
【深度學習】一文弄懂CNN及圖像識別(Python)
點擊下方卡片,關注“新機器視覺”公眾號
視覺/圖像重磅干貨,第一時間送達
一、卷積神經(jīng)網(wǎng)絡簡介
卷積神經(jīng)網(wǎng)絡(Convolutional Neural Networks, CNN)是一類包含卷積計算的前饋神經(jīng)網(wǎng)絡,是基于圖像任務的平移不變性(圖像識別的對象在不同位置有相同的含義)設計的,擅長應用于圖像處理等任務。在圖像處理中,圖像數(shù)據(jù)具有非常高的維數(shù)(高維的RGB矩陣表示),因此訓練一個標準的前饋網(wǎng)絡來識別圖像將需要成千上萬的輸入神經(jīng)元,除了顯而易見的高計算量,還可能導致許多與神經(jīng)網(wǎng)絡中的維數(shù)災難相關的問題。
對于高維圖像數(shù)據(jù),卷積神經(jīng)網(wǎng)絡利用了卷積和池化層,能夠高效提取圖像的重要“特征”,再通過后面的全連接層處理“壓縮的圖像信息”及輸出結果。對比標準的全連接網(wǎng)絡,卷積神經(jīng)網(wǎng)絡的模型參數(shù)大大減少了。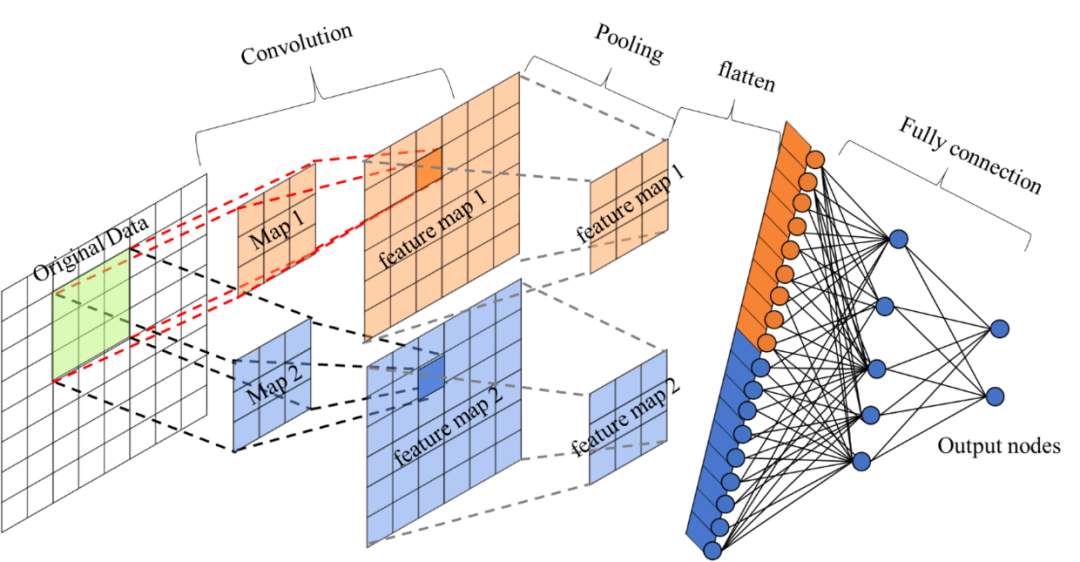
二、卷積神經(jīng)網(wǎng)絡的“卷積”
2.1 卷積運算的原理
在信號處理、圖像處理和其它工程/科學領域,卷積都是一種使用廣泛的技術,卷積神經(jīng)網(wǎng)絡(CNN)這種模型架構就得名于卷積計算。但是,深度學習領域的“卷積”本質上是信號/圖像處理領域內的互相關(cross-correlation),互相關與卷積實際上還是有些差異的。卷積是分析數(shù)學中一種重要的運算。簡單定義f , g 是可積分的函數(shù),兩者的卷積運算如下: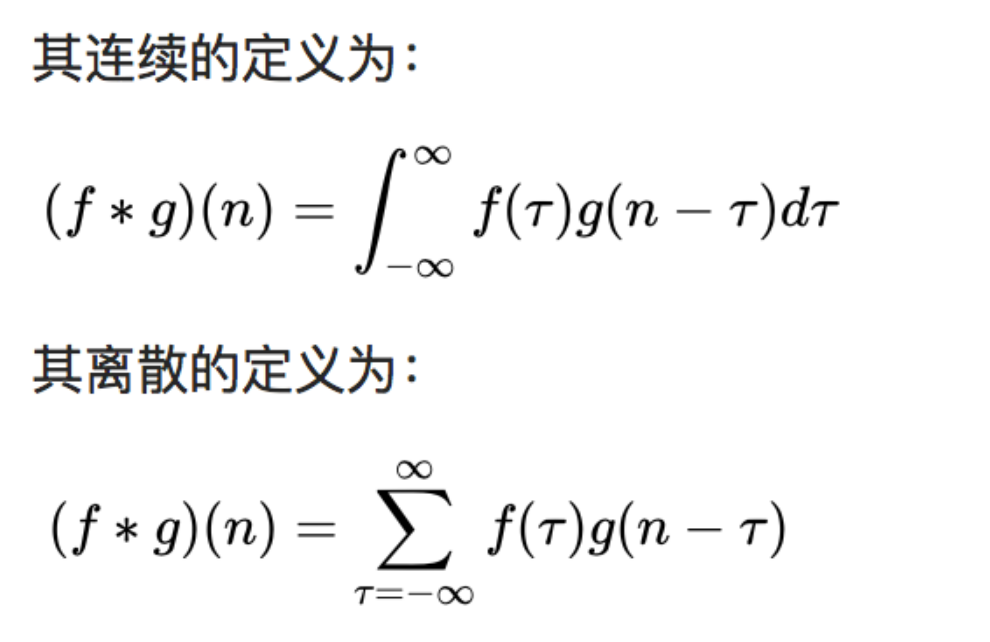
其定義是兩個函數(shù)中一個函數(shù)(g)經(jīng)過反轉和位移后再相乘得到的積的積分。如下圖,函數(shù) g 是過濾器。它被反轉后再沿水平軸滑動。在每一個位置,我們都計算 f 和反轉后的 g 之間相交區(qū)域的面積。這個相交區(qū)域的面積就是特定位置出的卷積值。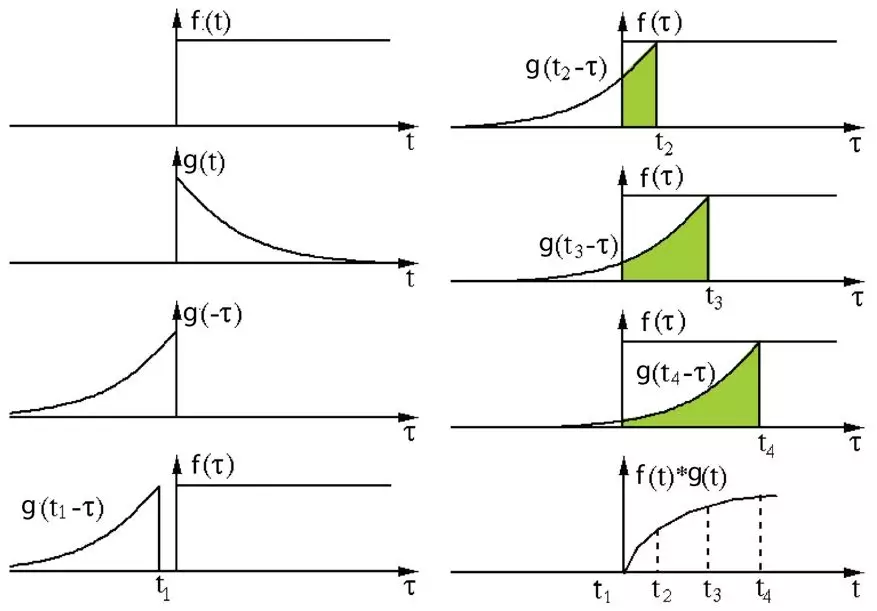
互相關是兩個函數(shù)之間的滑動點積或滑動內積。互相關中的過濾器不經(jīng)過反轉,而是直接滑過函數(shù) f,f 與 g 之間的交叉區(qū)域即是互相關。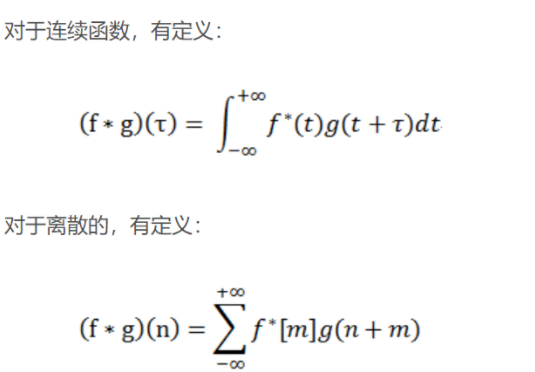
下圖展示了卷積與互相關運算過程,相交區(qū)域的面積變化的差異: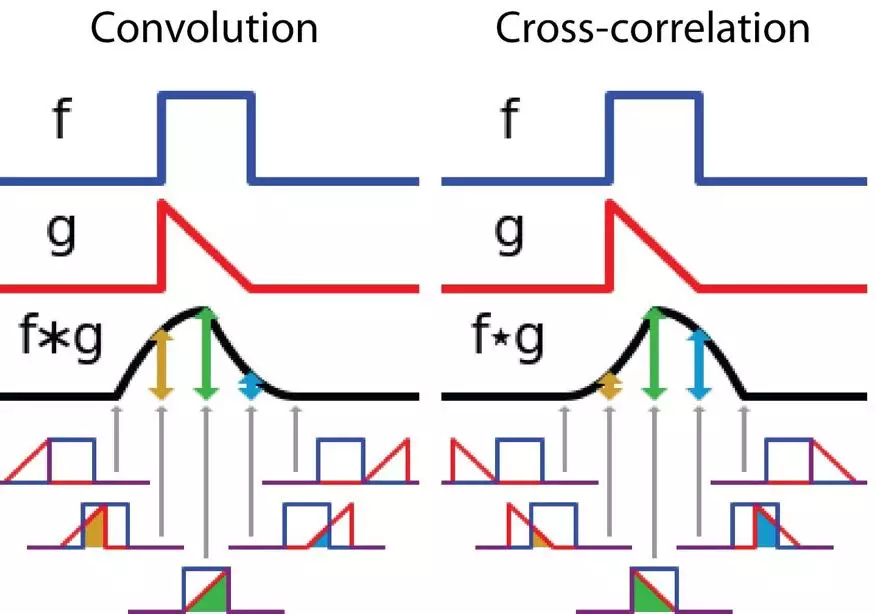
在卷積神經(jīng)網(wǎng)絡中,卷積中的過濾器不經(jīng)過反轉。嚴格來說,這是離散形式的互相關運算,本質上是執(zhí)行逐元素乘法和求和。但兩者的效果是一致,因為過濾器的權重參數(shù)是在訓練階段學習到的,經(jīng)過訓練后,學習得到的過濾器看起來就會像是反轉后的函數(shù)。
2.2 卷積運算的作用
CNN通過設計的卷積核(convolution filter,也稱為kernel)與圖片做卷積運算(平移卷積核去逐步做乘積并求和)。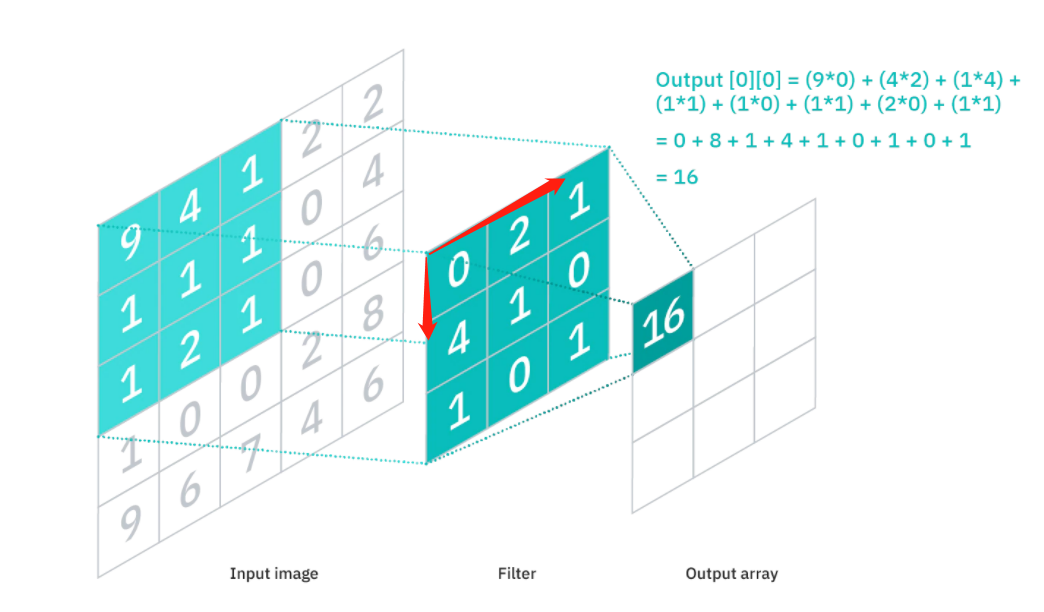
如下示例設計一個(特定參數(shù))的3×3的卷積核: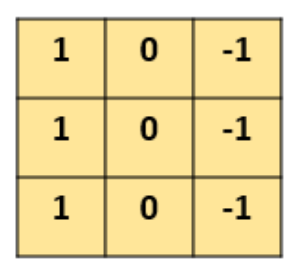
讓它去跟圖片做卷積,卷積的具體過程是:
-
用這個卷積核去覆蓋原始圖片;
-
覆蓋一塊跟卷積核一樣大的區(qū)域之后,對應元素相乘,然后求和;
-
計算一個區(qū)域之后,就向其他區(qū)域挪動(假設步長是1),繼續(xù)計算;
-
直到把原圖片的每一個角落都覆蓋到為止;
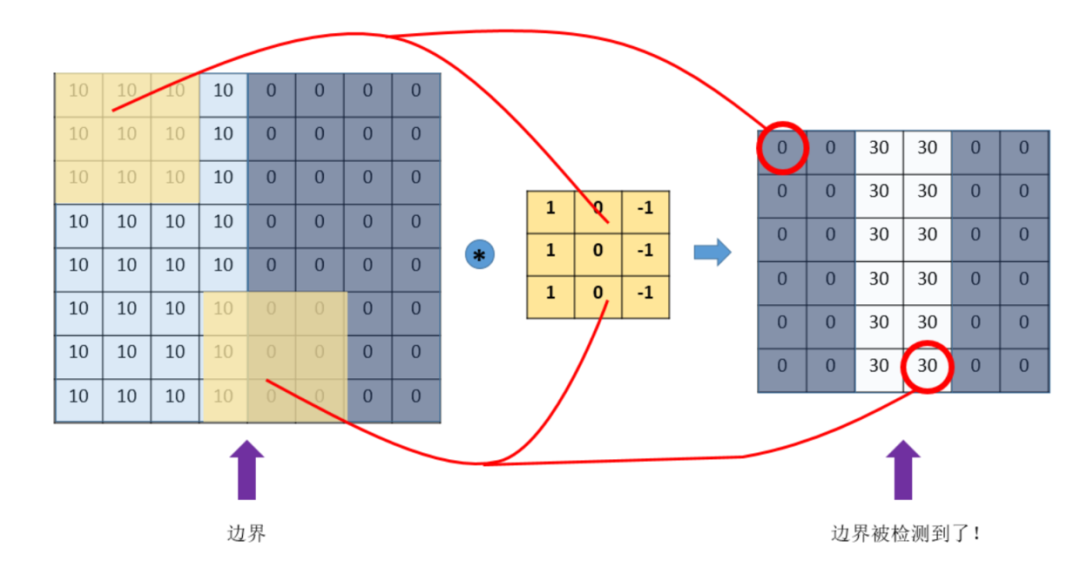 可以發(fā)現(xiàn),通過特定的filter,讓它去跟圖片做卷積,就可以提取出圖片中的某些特征,比如邊界特征。
可以發(fā)現(xiàn),通過特定的filter,讓它去跟圖片做卷積,就可以提取出圖片中的某些特征,比如邊界特征。
進一步的,我們可以借助龐大的數(shù)據(jù),足夠深的神經(jīng)網(wǎng)絡,使用反向傳播算法讓機器去自動學習這些卷積核參數(shù),不同參數(shù)卷積核提取特征也是不一樣的,就能夠提取出局部的、更深層次和更全局的特征以應用于決策。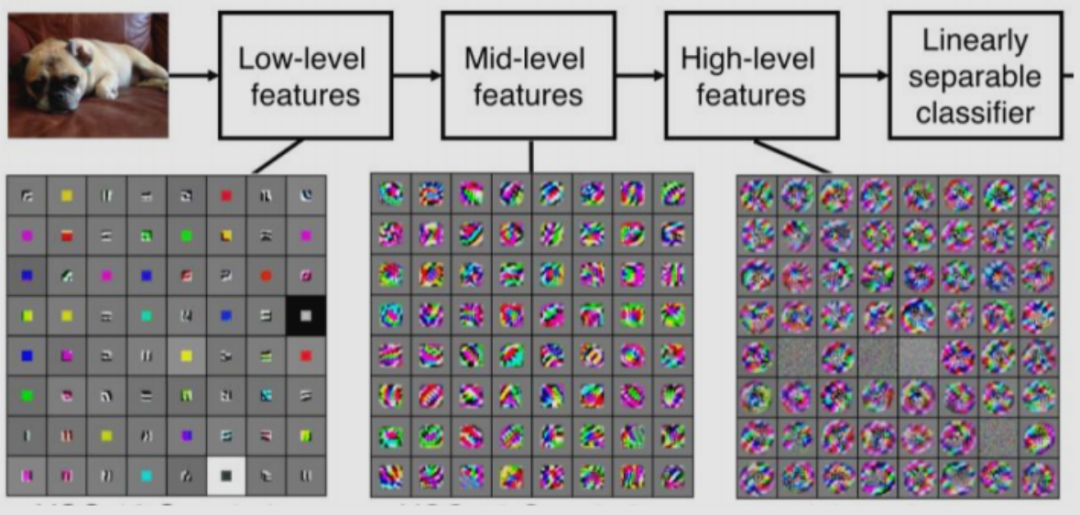
卷積運算的本質性總結:過濾器(g)對圖片(f)執(zhí)行逐步的乘法并求和,以提取特征的過程。卷積過程可視化可訪問:https://poloclub.github.io/cnn-explainer/ 或 https://github.com/vdumoulin/conv_arithmetic
三、卷積神經(jīng)網(wǎng)絡
卷積神經(jīng)網(wǎng)絡通常由3個部分構成:卷積層,池化層,全連接層。簡單來說,卷積層負責提取圖像中的局部及全局特征;池化層用來大幅降低參數(shù)量級(降維);全連接層用于處理“壓縮的圖像信息”并輸出結果。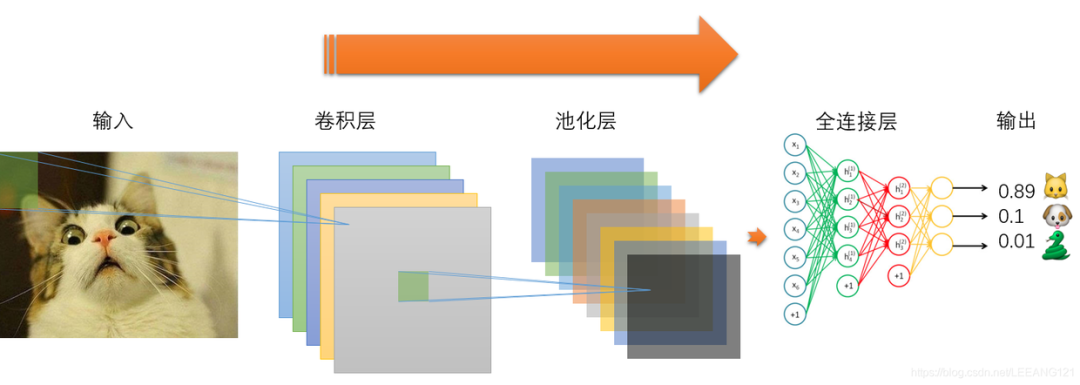
3.1 卷積層(CONV)
3.1.1 卷積層基本屬性
卷積層主要功能是動態(tài)地提取圖像特征,由濾波器filters和激活函數(shù)構成。一般要設置的超參數(shù)包括filters的數(shù)量、大小、步長,激活函數(shù)類型,以及padding是“valid”還是“same”。
-
卷積核大小(Kernel):直觀理解就是一個濾波矩陣,普遍使用的卷積核大小為3×3、5×5等。在達到相同感受野的情況下,卷積核越小,所需要的參數(shù)和計算量越小。卷積核大小必須大于1才有提升感受野的作用,而大小為偶數(shù)的卷積核即使對稱地加padding也不能保證輸入feature map尺寸和輸出feature map尺寸不變(假設n為輸入寬度,d為padding個數(shù),m為卷積核寬度,在步長為1的情況下,如果保持輸出的寬度仍為n,公式,n+2d-m+1=n,得出m=2d+1,需要是奇數(shù)),所以一般都用3作為卷積核大小。
-
卷積核數(shù)目:主要還是根據(jù)實際情況調整, 一般都是取2的整數(shù)次方,數(shù)目越多計算量越大,相應模型擬合能力越強。
-
步長(Stride):卷積核遍歷特征圖時每步移動的像素,如步長為1則每次移動1個像素,步長為2則每次移動2個像素(即跳過1個像素),以此類推。步長越小,提取的特征會更精細。
-
填充(Padding):處理特征圖邊界的方式,一般有兩種,一種是“valid”,對邊界外完全不填充,只對輸入像素執(zhí)行卷積操作,這樣會使輸出特征圖像尺寸變得更小,且邊緣信息容易丟失;另一種是還是“same”,對邊界外進行填充(一般填充為0),再執(zhí)行卷積操作,這樣可使輸出特征圖的尺寸與輸入特征圖的尺寸一致,邊緣信息也可以多次計算。
-
通道(Channel):卷積層的通道數(shù)(層數(shù))。如彩色圖像一般都是RGB三個通道(channel)。
-
激活函數(shù):主要還是根據(jù)實際驗證,通常選擇Relu。
另外的,卷積的類型除了標準卷積,還演變出了反卷積、可分離卷積、分組卷積等各種類型,可以自行驗證。
3.1.2 卷積層的特點
通過卷積運算的介紹,可以發(fā)現(xiàn)卷積層有兩個主要特點:局部連接(稀疏連接)和權值共享。
-
局部連接,就是卷積層的節(jié)點僅僅和其前一層的部分節(jié)點相連接,只用來學習局部區(qū)域特征。(局部連接感知結構的理念來源于動物視覺的皮層結構,其指的是動物視覺的神經(jīng)元在感知外界物體的過程中起作用的只有一部分神經(jīng)元。)
-
權值共享,同一卷積核會和輸入圖片的不同區(qū)域作卷積,來檢測相同的特征,卷積核上面的權重參數(shù)是空間共享的,使得參數(shù)量大大減少。

由于局部連接(稀疏連接)和權值共享的特點,使得CNN具有仿射的不變性(平移、縮放等線性變換)
3.2 池化層(Pooling)
池化層可對提取到的特征信息進行降維,一方面使特征圖變小,簡化網(wǎng)絡計算復雜度;另一方面進行特征壓縮,提取主要特征,增加平移不變性,減少過擬合風險。但其實池化更多程度上是一種計算性能的一個妥協(xié),強硬地壓縮特征的同時也損失了一部分信息,所以現(xiàn)在的網(wǎng)絡比較少用池化層或者使用優(yōu)化后的如SoftPool。
池化層設定的超參數(shù),包括池化層的類型是Max還是Average(Average對背景保留更好,Max對紋理提取更好),窗口大小以及步長等。如下的MaxPooling,采用了一個2×2的窗口,并取步長stride=2,提取出各個窗口的max值特征(AveragePooling就是平均值):
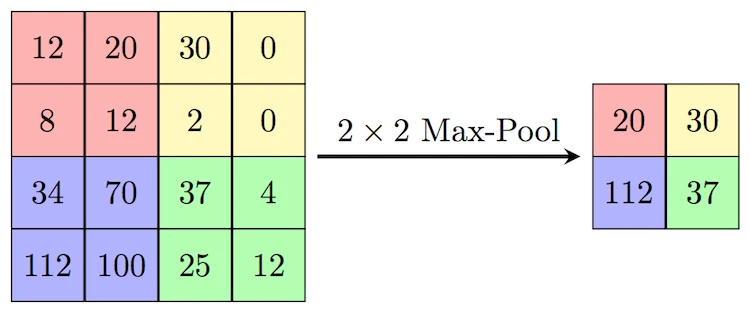
3.3 全連接層(FC)
在經(jīng)過數(shù)次卷積和池化之后,我們最后會先將多維的圖像數(shù)據(jù)進行壓縮“扁平化”, 也就是把 (height,width,channel) 的數(shù)據(jù)壓縮成長度為 height × width × channel 的一維數(shù)組,然后再與全連接層連接(這也就是傳統(tǒng)全連接網(wǎng)絡層,每一個單元都和前一層的每一個單元相連接,需要設定的超參數(shù)主要是神經(jīng)元的數(shù)量,以及激活函數(shù)類型),通過全連接層處理“壓縮的圖像信息”并輸出結果。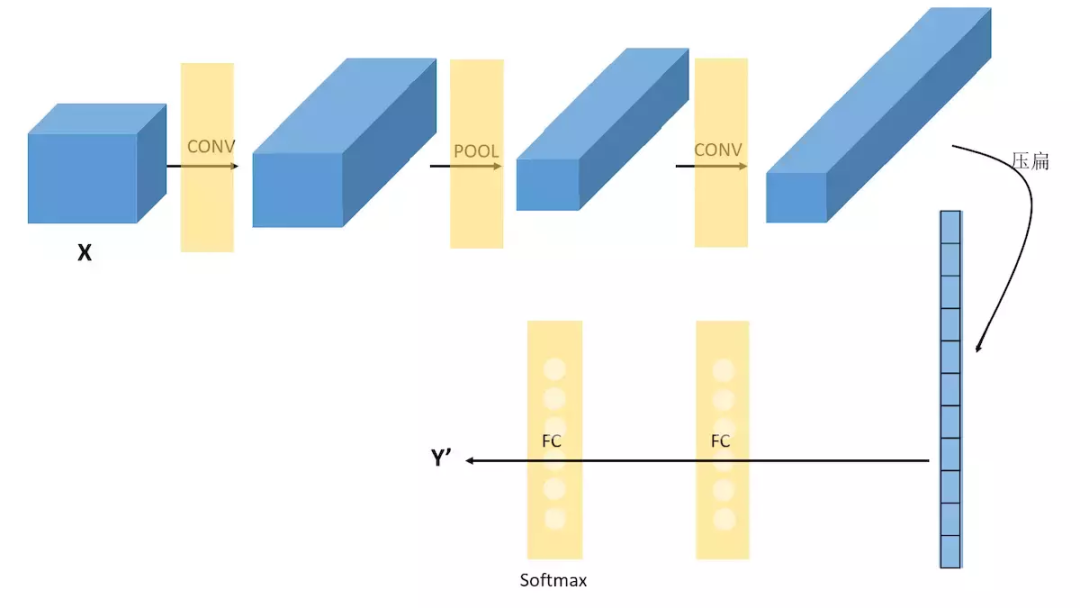
3.4 示例:經(jīng)典CNN的構建(Lenet-5)
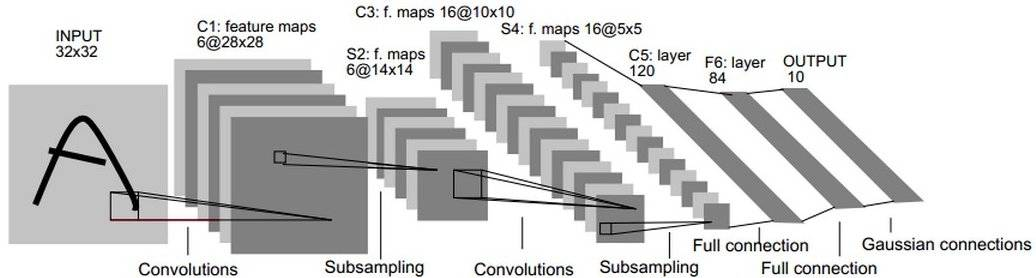 LeNet-5由Yann LeCun設計于 1998年,是最早的卷積神經(jīng)網(wǎng)絡之一。它是針對灰度圖進行訓練的,輸入圖像大小為32321,不包含輸入層的情況下共有7層。下面逐層介紹LeNet-5的結構:
LeNet-5由Yann LeCun設計于 1998年,是最早的卷積神經(jīng)網(wǎng)絡之一。它是針對灰度圖進行訓練的,輸入圖像大小為32321,不包含輸入層的情況下共有7層。下面逐層介紹LeNet-5的結構:
-
1、C1-卷積層
第一層是卷積層,用于過濾噪音,提取關鍵特征。使用5 * 5大小的過濾器6個,步長s = 1,padding = 0。
-
2、S2-采樣層(平均池化層)
第二層是平均池化層,利用了圖像局部相關性的原理,對圖像進行子抽樣,可以減少數(shù)據(jù)處理量同時保留有用信息,降低網(wǎng)絡訓練參數(shù)及模型的過擬合程度。使用2 * 2大小的過濾器,步長s = 2,padding = 0。池化層只有一組超參數(shù)pool_size 和 步長strides,沒有需要學習的模型參數(shù)。
-
3、C3-卷積層
第三層使用5 * 5大小的過濾器16個,步長s = 1,padding = 0。
-
4、S4-下采樣層(平均池化層)
第四層使用2 * 2大小的過濾器,步長s = 2,padding = 0。沒有需要學習的參數(shù)。
-
5、C5-卷積層
第五層是卷積層,有120個5 * 5 的單元,步長s = 1,padding = 0。
-
6、F6-全連接層
有84個單元。每個單元與F5層的全部120個單元之間進行全連接。
-
7、Output-輸出層
Output層也是全連接層,采用RBF網(wǎng)絡的連接方式(現(xiàn)在主要由Softmax取代,如下示例代碼),共有10個節(jié)點,分別代表數(shù)字0到9(因為Lenet用于輸出識別數(shù)字的),如果節(jié)點i的輸出值為0,則網(wǎng)絡識別的結果是數(shù)字i。
如下Keras復現(xiàn)Lenet-5: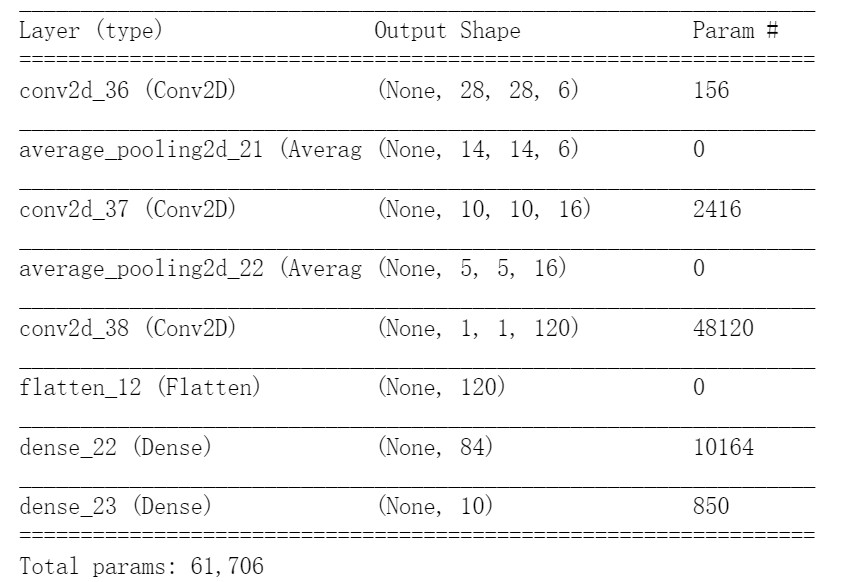
from keras.models import Sequential
from keras import layers
le_model = keras.Sequential()
le_model.add(layers.Conv2D(6, kernel_size=(5, 5), strides=(1, 1), activation='tanh', input_shape=(32,32,1), padding="valid"))
le_model.add(layers.AveragePooling2D(pool_size=(2, 2), strides=(2, 2), padding='valid'))
le_model.add(layers.Conv2D(16, kernel_size=(5, 5), strides=(1, 1), activation='tanh', padding='valid'))
le_model.add(layers.AveragePooling2D(pool_size=(2, 2), strides=(2, 2), padding='valid'))
le_model.add(layers.Conv2D(120, kernel_size=(5, 5), strides=(1, 1), activation='tanh', padding='valid'))
le_model.add(layers.Flatten())
le_model.add(layers.Dense(84, activation='tanh'))
le_model.add(layers.Dense(10, activation='softmax'))
四、CNN圖像分類-keras
以keras實現(xiàn)經(jīng)典的CIFAR10圖像數(shù)據(jù)集的分類為例,代碼:https://github.com/aialgorithm/Blog
-
訓練集輸入數(shù)據(jù)的樣式為:(50000, 32, 32, 3)對應 (樣本數(shù), 圖像高度, 寬度, RGB彩色圖像通道為3)
from keras.datasets import cifar10
from keras.preprocessing.image import ImageDataGenerator
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Conv2D, MaxPooling2D
import keras
import os
# 數(shù)據(jù),切分為訓練和測試集
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
print('x_train shape:', x_train.shape)
print(x_train.shape[0], 'train samples')
print(x_test.shape[0], 'test samples')
-
展示數(shù)據(jù)集,共有10類圖像: 

# 展示數(shù)據(jù)集
import matplotlib.pyplot as plt
class_names = ['airplane', 'automobile', 'bird', 'cat', 'deer',
'dog', 'frog', 'horse', 'ship', 'truck']
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(x_train[i])
# The CIFAR labels happen to be arrays,
# which is why you need the extra index
plt.xlabel(class_names[y_train[i][0]])
plt.show()
-
數(shù)據(jù)及標簽預處理:
# 將標簽向量轉換為二值矩陣。
num_classes = 10 #圖像數(shù)據(jù)有10個實際標簽類別
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
print(y_train.shape, 'ytrain')
# 圖像數(shù)據(jù)歸一化
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
-
構造卷積神經(jīng)網(wǎng)絡: 輸入層->多組卷積及池化層->全連接網(wǎng)絡->softmax多分類輸出層。(如下圖部分網(wǎng)絡結構) 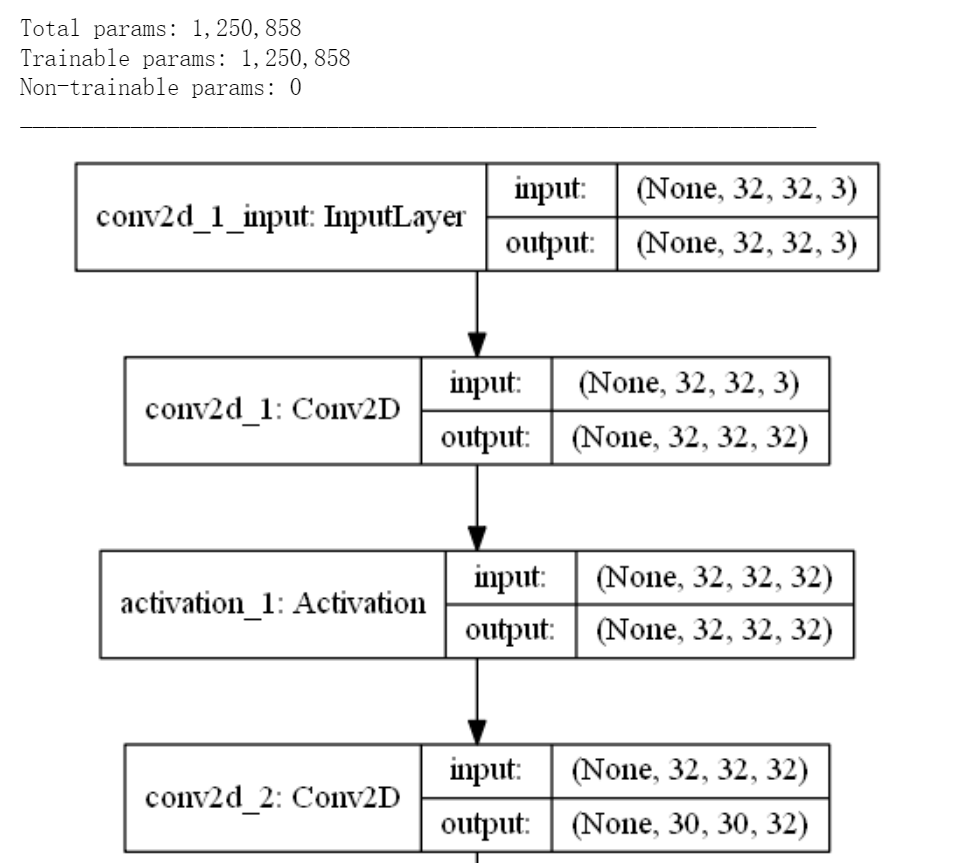
# 構造卷積神經(jīng)網(wǎng)絡
model = Sequential()
# 圖像輸入形狀(32, 32, 3) 對應(image_height, image_width, color_channels)
model.add(Conv2D(32, (3, 3), padding='same',
input_shape=(32, 32, 3)))
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
# 卷積、池化層輸出都是一個三維的(height, width, channels)
# 越深的層中,寬度和高度都會收縮
model.add(Conv2D(64, (3, 3), padding='same'))
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
# 3 維展平為 1 維 ,輸入全連接層
model.add(Flatten())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes)) # CIFAR數(shù)據(jù)有 10 個輸出類,以softmax輸出多分類
model.add(Activation('softmax'))
-
模型編譯:設定RMSprop 優(yōu)化算法;設定分類損失函數(shù).
# 初始化 RMSprop 優(yōu)化器
opt = keras.optimizers.rmsprop(lr=0.001, decay=1e-6)
# 模型編譯:設定RMSprop 優(yōu)化算法;設定分類損失函數(shù);
model.compile(loss='categorical_crossentropy',
optimizer=opt,
metrics=['accuracy'])
-
模型訓練: 簡單驗證5個epochs
batch_size = 64
epochs = 5
history = model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
validation_data=(x_test, y_test),
shuffle=True)
-
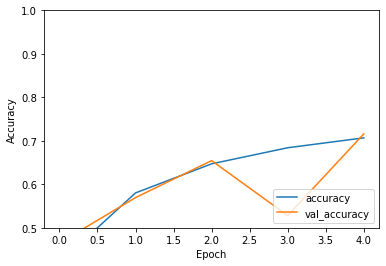
模型評估:測試集accuracy: 0.716,可見訓練/測試集整體的準確率都不太高(欠擬合),可以增加epoch數(shù)、模型調優(yōu)驗證效果。
附 卷積神經(jīng)網(wǎng)絡優(yōu)化方法(tricks):
超參數(shù)優(yōu)化:可以用隨機搜索、貝葉斯優(yōu)化。推薦分布式超參數(shù)調試框架Keras Tuner包括了常用的優(yōu)化方法。
數(shù)據(jù)層面:數(shù)據(jù)增強廣泛用于圖像任務,效果提升大。常用有圖像樣本變換、mixup等。更多優(yōu)化方法具體可見:https://arxiv.org/abs/1812.01187
# 保存模型和權重
num_predictions = 20
save_dir = os.path.join(os.getcwd(), 'saved_models')
model_name = 'keras_cifar10_trained_model.h5'
if not os.path.isdir(save_dir):
os.makedirs(save_dir)
model_path = os.path.join(save_dir, model_name)
model.save(model_path)
print('Saved trained model at %s ' % model_path)
# 評估訓練模型
scores = model.evaluate(x_test, y_test, verbose=1)
print('Test loss:', scores[0])
print('Test accuracy:', scores[1])
plt.plot(history.history['accuracy'], label='accuracy')
plt.plot(history.history['val_accuracy'], label = 'val_accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.ylim([0.5, 1])
plt.legend(loc='lower right')
plt.show()—版權聲明—
僅用于學術分享,版權屬于原作者。
若有侵權,請聯(lián)系微信號:yiyang-sy 刪除或修改!