
一文入門 深度強化學(xué)習(xí)
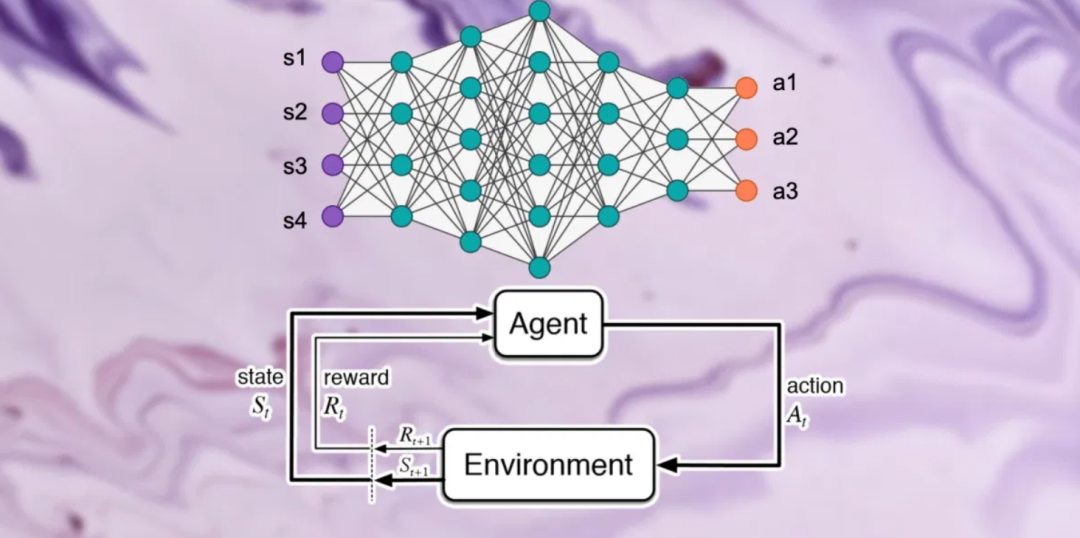
狀態(tài)、獎勵和行動
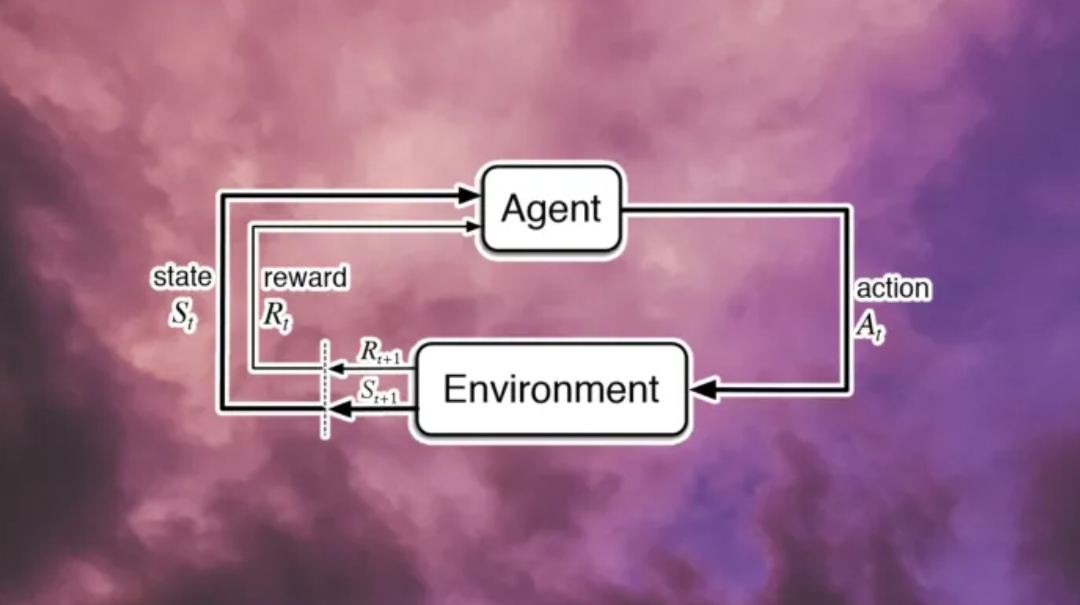
「狀態(tài)-動作-獎勵」的每個循環(huán)都稱為一個步驟。強化學(xué)習(xí)系統(tǒng)持續(xù)循環(huán)迭代,直到達到所需狀態(tài)或達到最大步數(shù)。這一系列的步驟稱為一個「情節(jié)」或者「集」。在每一個情節(jié)開始時,環(huán)境設(shè)置為初始狀態(tài),代理的獎勵重置為零。
為了更好地理解強化學(xué)習(xí)的組成部分,讓我們考慮幾個例子。

基于模型的方法為代理提供了「遠見」,減小了對手動收集數(shù)據(jù)的依賴。這在收集訓(xùn)練數(shù)據(jù)和經(jīng)驗,既昂貴又緩慢的應(yīng)用中非常有利(例如,機器人和自動駕駛汽車)。
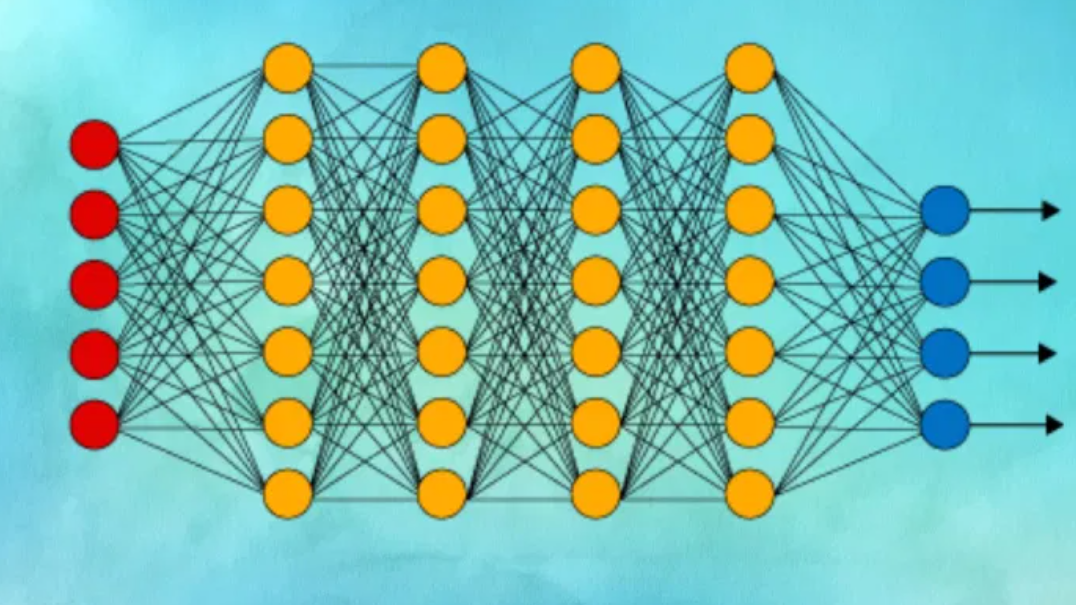
到目前為止,我們還沒有談到深度神經(jīng)網(wǎng)絡(luò)。事實上,你可以以任何你想要的方式實現(xiàn)上述所有算法。例如,Q-learning 是一種經(jīng)典的強化學(xué)習(xí)算法,它在代理與環(huán)境交互時創(chuàng)建了一個狀態(tài)-動作-獎勵值表。當你處理狀態(tài)和操作數(shù)量非常少的簡單環(huán)境時,此類方法非常有效。
掃碼關(guān)注我的視頻號:程序員zhenguo
評論
圖片
表情