
NLP文本分類大殺器:PET范式
作者 | 周俊賢
整理 | NewBeeNLP
之前我們分享了NLP文本分類 落地實(shí)戰(zhàn)五大利器!,今天我們以兩篇論文為例,來看看Pattern Exploiting Training(PET)范式,可以用于半監(jiān)督訓(xùn)練或無監(jiān)督訓(xùn)練。
Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference
論文:《Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference Timo》[1] 項(xiàng)目地址:https://github.com/timoschick/pet
大家思考一個(gè)問題,BERT在預(yù)訓(xùn)練時(shí)學(xué)習(xí)到的知識或者說參數(shù)我們在fine-tunning的時(shí)候都有用到嗎?
答案是不是的。大家看下圖,BERT的預(yù)訓(xùn)練其中一個(gè)任務(wù)是MLM,就是去預(yù)測被【MASK】掉的token,采用的是拿bert的最后一個(gè)encoder(base版本,就是第12層的encoder的輸出,也即下圖左圖藍(lán)色框)作為輸入,然后接全連接層,做一個(gè)全詞表的softmax分類(這部分就是左圖的紅色框)。但在fine tuning的時(shí)候,我們是把MLM任務(wù)的全連接層拋棄掉,在最后一層encoder后接新的初始化層來做具體的下游任務(wù)。
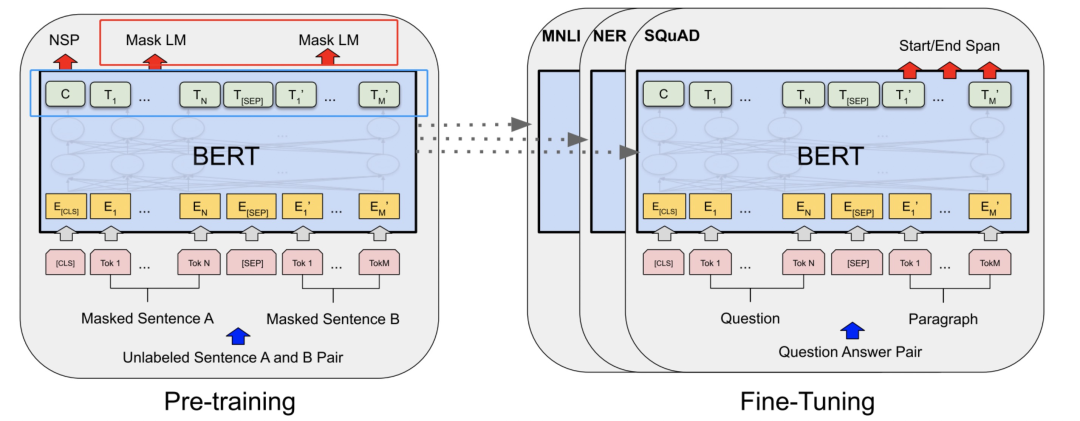
想一個(gè)問題,「能不能通過某些巧妙的設(shè)計(jì),把MLM層學(xué)習(xí)到的參數(shù)也利用上?」 答案當(dāng)然是可以的,請繼續(xù)往下看。
現(xiàn)在舉一個(gè)二分類的例子,輸入一條汽車論壇的評論,輸出這個(gè)評論是屬于【積極】or【消極】。但問題是現(xiàn)在我每個(gè)類別只有10個(gè)labeled數(shù)據(jù),1K條unlabeled數(shù)據(jù)。怎么訓(xùn)練model?
直接做有監(jiān)督訓(xùn)練?樣本量太少,會過擬合。應(yīng)該優(yōu)先采用半監(jiān)督學(xué)習(xí)的方法,如UDA、MixText這種,而PET采用的是另外一種巧妙的設(shè)計(jì)思想。
現(xiàn)在通過改造輸入,如下圖,

一個(gè)樣例是"保養(yǎng)貴,配件貴,小毛病多,還有燒機(jī)油風(fēng)險(xiǎn)"。定義一個(gè)「pattern」函數(shù),把它轉(zhuǎn)變成以下形式"保養(yǎng)貴,配件貴,小毛病多,還有燒機(jī)油風(fēng)險(xiǎn)。真__!"。
這里定義一個(gè)「verblizer」作為映射函數(shù),把label【積極】映射為好,把label【消極】映射為差。然后model對下劃線__部分進(jìn)行預(yù)測。BERT預(yù)訓(xùn)練時(shí)MLM任務(wù)是預(yù)測整個(gè)詞表,而這里把詞表限定在{好,差},cross entropy交叉熵?fù)p失訓(xùn)練模型。預(yù)測時(shí),假如預(yù)測出好,即這個(gè)樣例預(yù)測label就為積極,預(yù)測好差,這個(gè)樣例就是消極。
這樣做的好處是,「BERT預(yù)訓(xùn)練時(shí)的MLM層的參數(shù)能利用上」。而且,「即使model沒有進(jìn)行fine tunning,這個(gè)model其實(shí)就會含有一定的準(zhǔn)確率」!想想,根據(jù)語義來說,沒可能預(yù)測出 "保養(yǎng)貴,配件貴,小毛病多,還有燒機(jī)油風(fēng)險(xiǎn)。真好!" 比 "保養(yǎng)貴,配件貴,小毛病多,還有燒機(jī)油風(fēng)險(xiǎn)。真差!" 的概率還大吧!因?yàn)榍懊嬉痪浜苊黠@是語義矛盾的。
上面定義的Pattern和verblizer,就是一個(gè)PVP(pattern-verbalizer pairs)。
Auxilliary Language Modeling
由于現(xiàn)在是用MLM做分類任務(wù),所以可以引入無標(biāo)注數(shù)據(jù)一起訓(xùn)練!
舉個(gè)簡單的例子,下圖樣例1是labeled數(shù)據(jù),我們利用pattern把它改寫后,對__部分做完形填空預(yù)測(即MLM任務(wù))。樣例2是一個(gè)unlabeled數(shù)據(jù),我們就不對__部分做預(yù)測,而是對被【MASK】做預(yù)測。這里的【MASK】可以采用BERT的方法,隨機(jī)對句子的15%token進(jìn)行【MASK】。

這樣做的好處是,能讓model更適應(yīng)于當(dāng)前的任務(wù),有點(diǎn)像「在預(yù)訓(xùn)練模型上繼續(xù)根據(jù)任務(wù)的domain和task繼續(xù)做預(yù)訓(xùn)練,然后再做fine-tunning呢?」 詳細(xì)的可以看我寫的這篇博文。
Combining PVPs
引入一個(gè)問題,「怎么評價(jià)我們的pattern定義得好不好?」
舉個(gè)例子,如下圖,我們可以造兩個(gè)pattern,又可以造兩個(gè)verblizer。這樣,圖中所示,其實(shí)一共有4個(gè)PVP。我們怎么衡量哪一個(gè)PVP訓(xùn)練完后在測試集上的效果最好?

答案是我們也不知道,因?yàn)?strong>「我們不能站在上帝視角從一開頭就選出最佳的PVP,同樣由于是小樣本學(xué)習(xí),也沒有足夠的驗(yàn)證集讓我們挑選最佳的PVP」。既然如此,解決方式就是「知識蒸餾」。
具體的,我們用20個(gè)labeled數(shù)據(jù)訓(xùn)練4個(gè)PVP模型,然后拿這四個(gè)PVP模型對1K條unlabeled數(shù)據(jù)進(jìn)行預(yù)測,預(yù)測的結(jié)果用下式進(jìn)行平均。
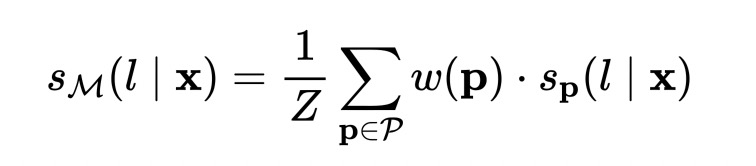
這里的 保持概率和為1, 就是單個(gè)PVP模型對樣本預(yù)測的概率分布, 就是PVP的權(quán)重。有uniform和weighted兩種方式,uniform就是所有PVP的權(quán)重都為1,weighted就是把每個(gè)PVP的權(quán)重設(shè)置為它們在訓(xùn)練集上的準(zhǔn)確率。最后還要對上式進(jìn)行temperature=2的軟化。
這就是在做知識的蒸餾。「何謂知識的蒸餾?」 經(jīng)過這樣處理后,噪聲減少了,利用多個(gè)PVP平均的思想把某些本來單個(gè)PVP預(yù)測偏差比較大的進(jìn)行平均后修正。
這樣子,利用訓(xùn)練好的PVPs所有1K條unlabeled數(shù)據(jù)打上soft label,再用這1K條打上軟標(biāo)簽的數(shù)據(jù)進(jìn)行傳統(tǒng)的有監(jiān)督訓(xùn)練,訓(xùn)練完的model應(yīng)用于下游任務(wù)的model。
注意哦,這里就可以用「輕量的模型」來做fine tuning了哦,因?yàn)閺?0條labeled數(shù)據(jù)擴(kuò)充到1K條有帶有soft label的數(shù)據(jù),labeled數(shù)據(jù)量大大增加,這時(shí)候輕量級的模型也能取得不錯(cuò)的結(jié)果,而且輕量模型對輕量部署、高并發(fā)等場景更加友好。
下圖就是所有的流程,再總結(jié)一下步驟就是
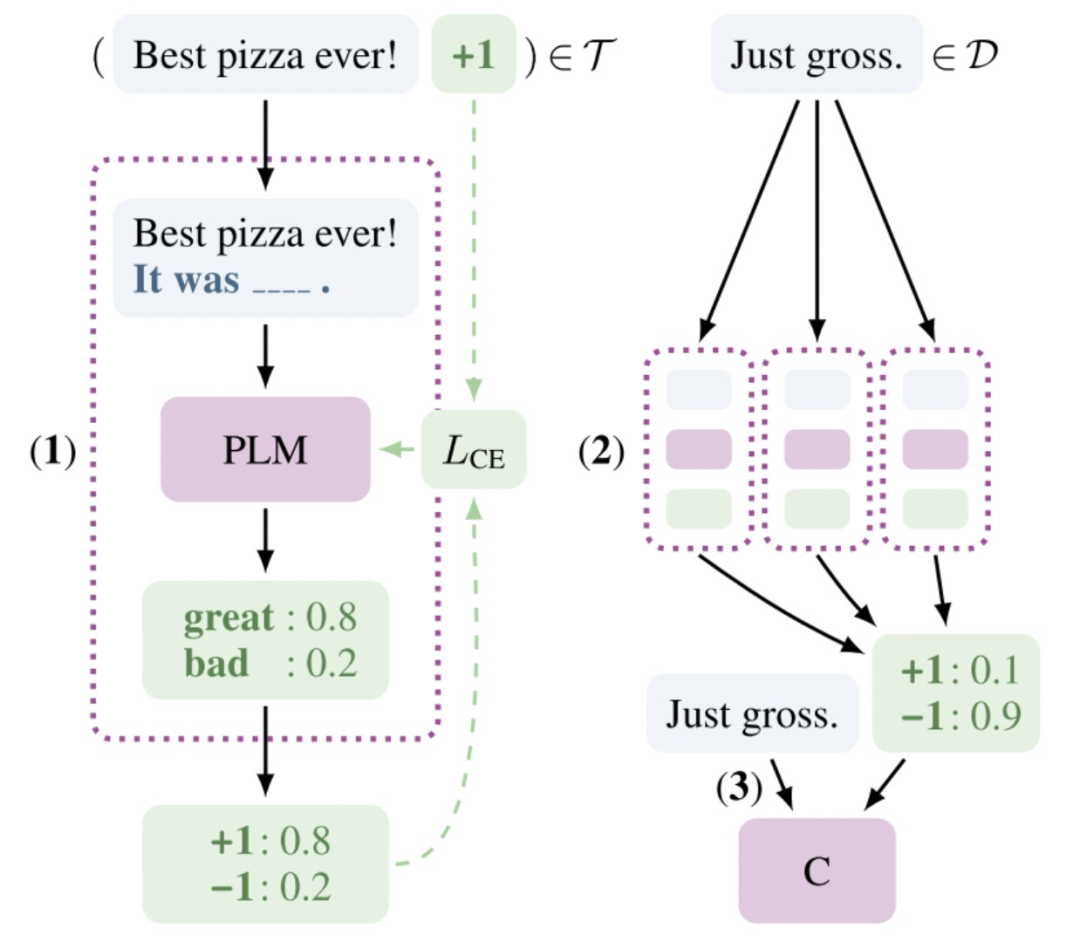
第一步:先定義PVPs,然后對每個(gè)PVP用labeled據(jù)進(jìn)行單獨(dú)的訓(xùn)練,該步可以加入上面提到的Auxiliary Language Modeling一起訓(xùn)練; 第二步:用訓(xùn)練好的PVPs,對unlabled數(shù)據(jù)進(jìn)行預(yù)測,并知識蒸餾,得到大量的soft label; 第三步:用第二步得到的帶有soft label的data,用傳統(tǒng)的fine tuning方法訓(xùn)練model。
IPET
在每個(gè)PVP訓(xùn)練的過程中,互相之間是沒有耦合的,就是沒有互相交換信息,IPET的意思就是想通過迭代,不斷擴(kuò)充上面訓(xùn)練PVP的數(shù)據(jù)集。
這里簡單舉個(gè)例子,現(xiàn)在有20個(gè)labeled數(shù)據(jù),1K個(gè)unlabeled數(shù)據(jù),定義5個(gè)PVP,第一輪,利用20個(gè)labeled數(shù)據(jù)分別訓(xùn)練PVP,第二輪,用第2~4個(gè)PVP來預(yù)測這1K unlabeled數(shù)據(jù),然后選一些模型預(yù)測概率比較高的加入到第一個(gè)PVP的訓(xùn)練集上,同樣用第1、3、4、5個(gè)PVP來訓(xùn)練這1K條,然后也將這部分加入到第2個(gè)PVP的訓(xùn)練集中,然后再訓(xùn)練一輪,訓(xùn)練后,重復(fù),這樣每一輪每個(gè)PVP的訓(xùn)練樣本不斷增多,而且PVP之間的信息也發(fā)生了交互。
實(shí)驗(yàn)
分析
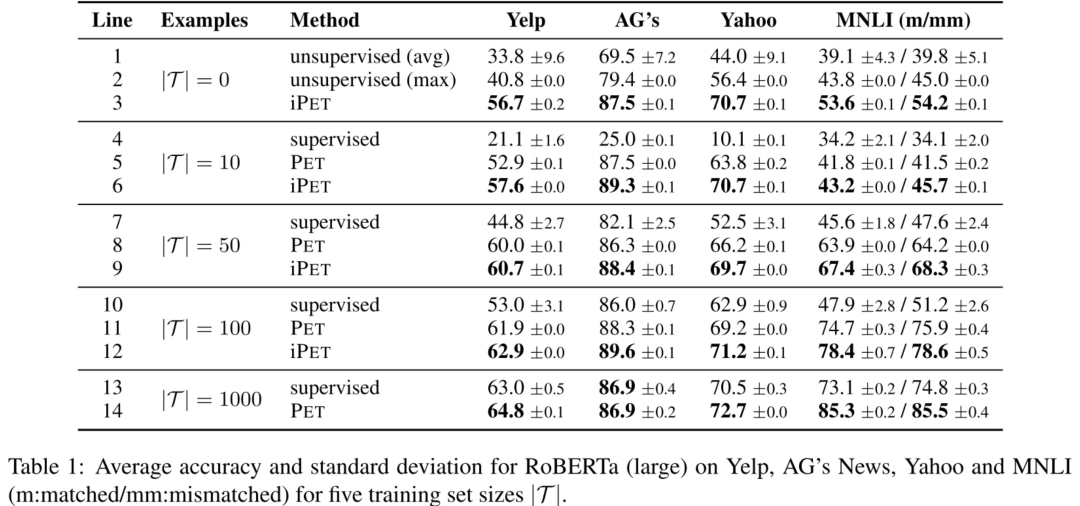
作者發(fā)現(xiàn)不同PVP之間可能有很大的性能差別,如下圖min就是最差的PVP,max就是最好的PVP,可以觀察到它們之間的差別就很大。但是又不能站在上帝視角從一開始就選擇最好的PVP,所以辦法就是做commind PVPs,即上面所提到的知識蒸餾,而且發(fā)現(xiàn)蒸餾后會比采用單個(gè)最好的PVP效果還要好,并且發(fā)現(xiàn)uniform和weighted兩個(gè)方法效果差不多。
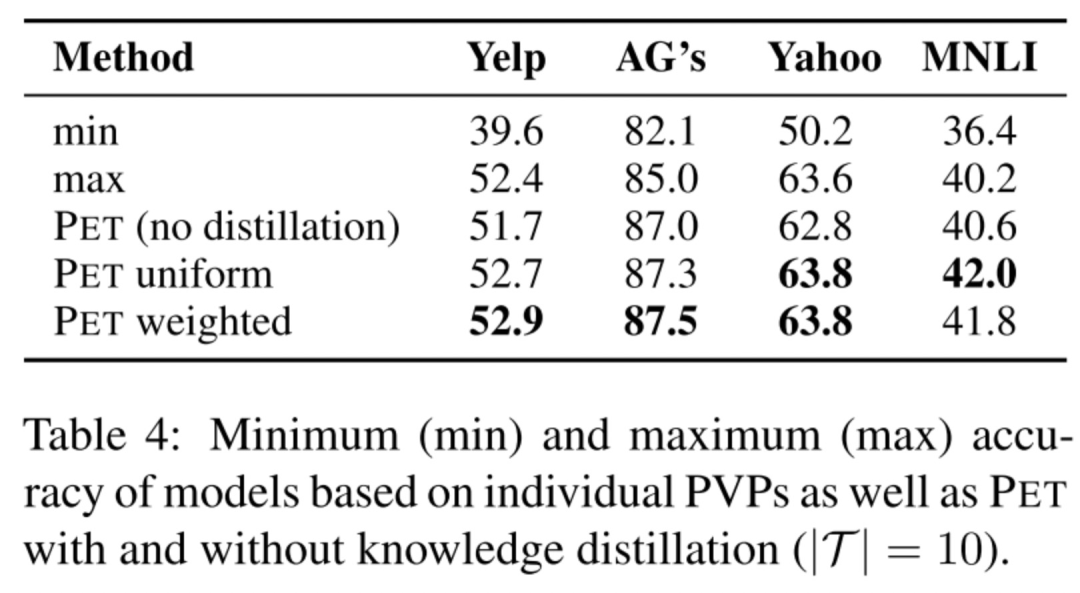
labeled數(shù)據(jù)越少,auxiliary task的提升效果越明顯。

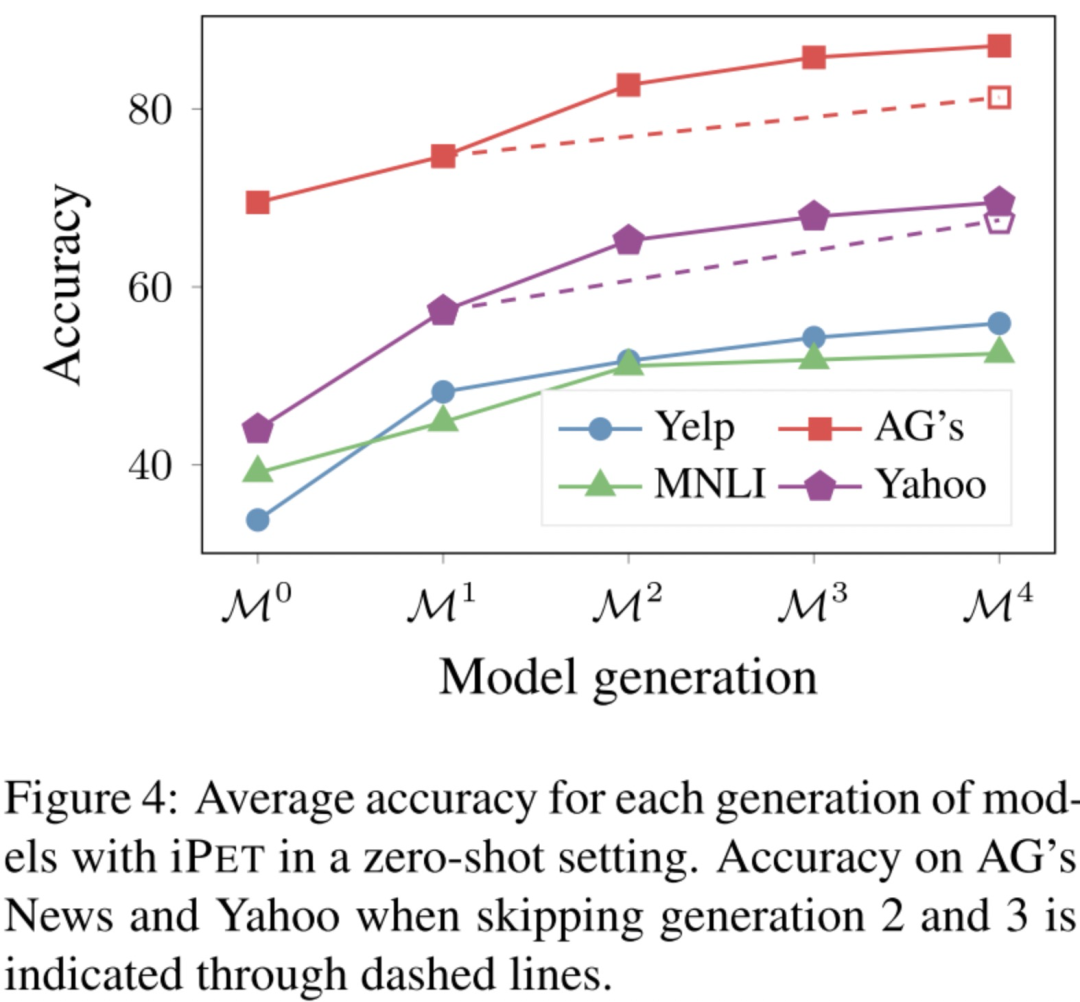
iPET的效果,因?yàn)閕PET是迭代多輪,每一輪每個(gè)PVP的訓(xùn)練集都會增大,從圖可以看到每一輪的模型效果都是越來越好的。
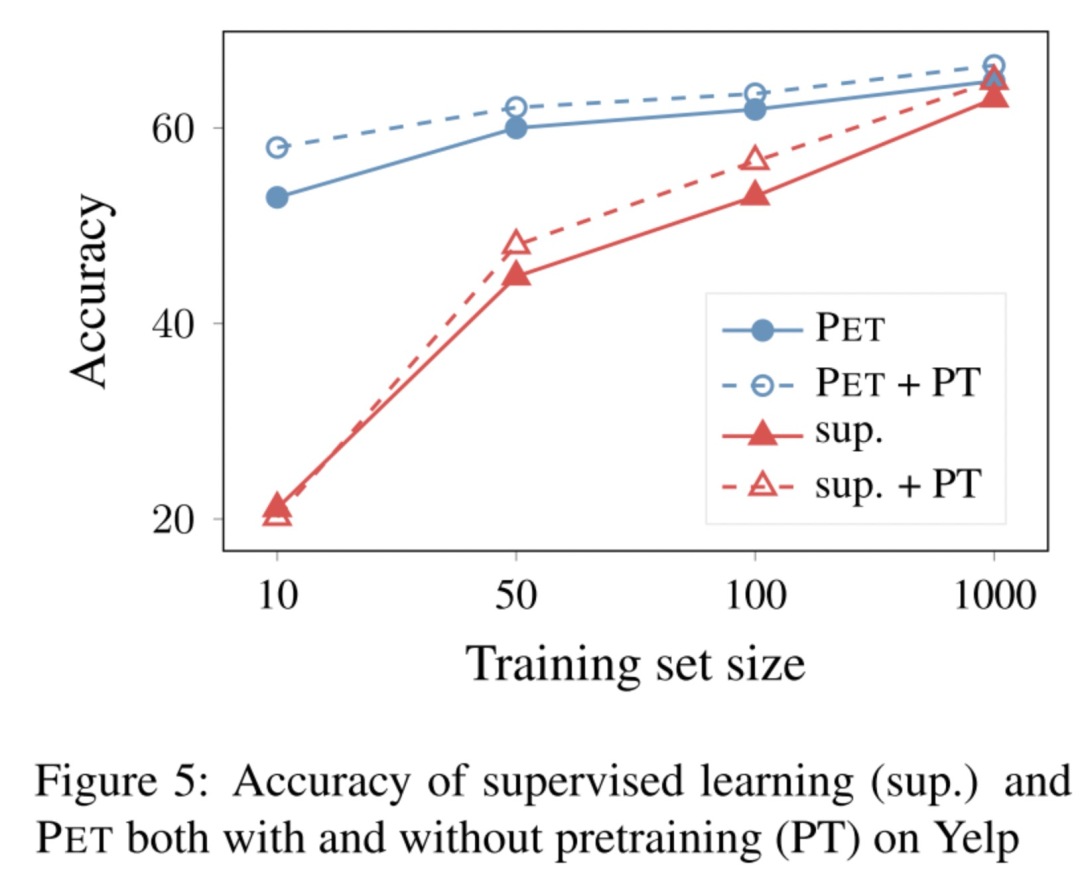
In-Domain Pretraining
這里討論了一個(gè)問題:PET效果比有監(jiān)督訓(xùn)練好,是不是因?yàn)镻ET在大量無標(biāo)簽上打上軟標(biāo)簽,擴(kuò)大了有標(biāo)簽數(shù)據(jù)集?然后作者做了一個(gè)實(shí)驗(yàn),有監(jiān)督訓(xùn)練時(shí),先在所有數(shù)據(jù)集上進(jìn)行繼續(xù)預(yù)訓(xùn)練(這一步作者認(rèn)為相當(dāng)于把無標(biāo)簽數(shù)據(jù)也加進(jìn)來了),然后再fine funing。實(shí)驗(yàn)結(jié)果表明,即使這樣,有監(jiān)督效果也離PET有一定距離。
不過這里想略微吐槽:還可以這樣來做比較的?感覺都不太公平hh。
It's Not Just Size That Matters:Small Language Models Are Also Few-Shot Learners
論文:《It's Not Just Size That Matters: Small Language Models Are Also Few-Shot Learners》[2] 項(xiàng)目地址:https://github.com/timoschick/pet
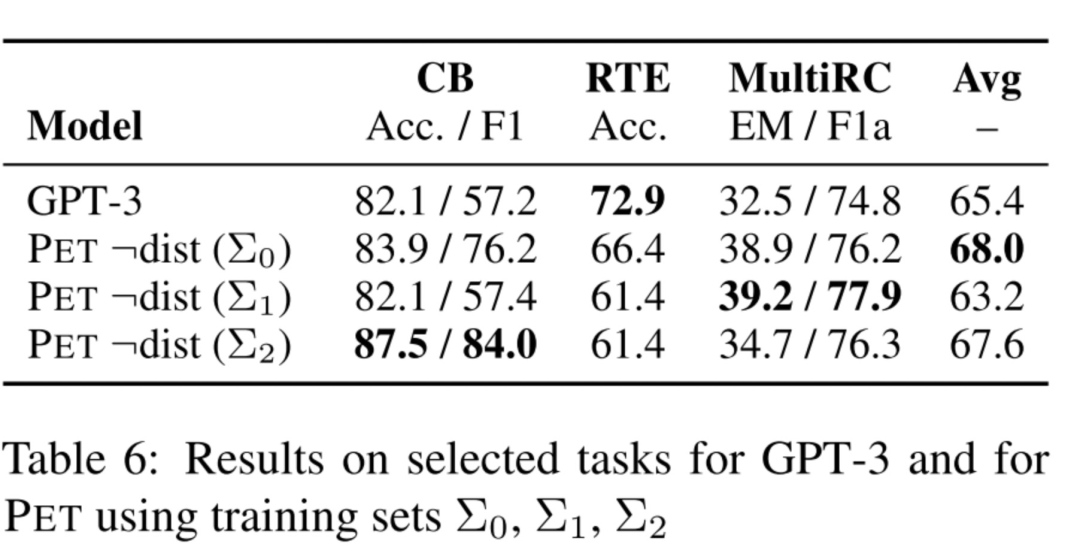
這篇論文是上篇論文的延伸,其實(shí)沒有太多新的工作,主要是下面提到的處理多個(gè)token的mask,這篇論文主要PK GPT3,不斷diss GPT3有多少的不環(huán)保hh。
PET with Multiple Masks
PET要定義pattern和verblizer,還拿那汽車評論那個(gè)場景舉例,我們能不能定義一個(gè)verbilzer,它把不同label映射到長度不一的token,如

因?yàn)関erbilzer把標(biāo)簽映射到長度不一致的token,那我們究竟定義長度為多少的下劃線_,來讓model進(jìn)行完形填空。答案是用最長的那個(gè),例如這里最長的是"不好",長度為2,所以就挖空兩個(gè)下劃線來讓模型做完形填空預(yù)測。
做Inference時(shí),
=第一個(gè)下劃線_模型預(yù)測到token為好的概率;
就麻煩一些,先讓模型對兩個(gè)下劃線,進(jìn)行預(yù)測,看是第一個(gè)下劃線預(yù)測token為不,還是第二個(gè)下劃線預(yù)測token為好的概率高一些,把高的那個(gè)token先填上去,再重新預(yù)測剩下的。舉個(gè)例子,假如模型預(yù)測第一個(gè)下劃線token為不的概率是0.5,第二個(gè)下劃線token為好的概率為0.4,即先把不填上第一個(gè)下劃線,然后再用模型重新預(yù)測第二個(gè)token為好的概率,假如為0.8,即 =0.5*0.8=0.4。
做train時(shí),就不考慮這么細(xì)致了,具體的,取上面的例子為例,
=第一個(gè)下劃線_,模型預(yù)測到token為好的概率,跟inference是一樣的; =0.5*0.4=0.2,這里就不分成兩步,一步KO,目的是一次前向計(jì)算就算完,避免訓(xùn)練過慢。
最后,采用的損失函數(shù)也跟第一篇的不一樣,這里用的是hinge loss,詳細(xì)的請看論文。
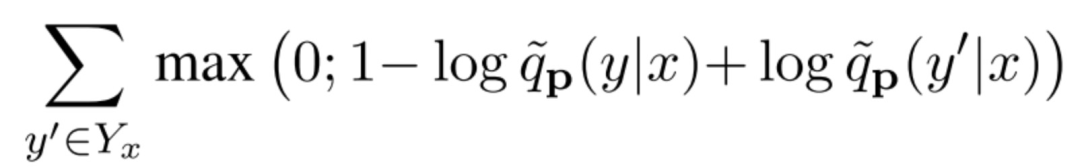
分析
再次強(qiáng)調(diào)Combining PVPs做知識蒸餾的重要性,因?yàn)楫?dāng)我們僅采用單個(gè)pattern的時(shí)候,根本不知道它的效果如何,最好的做法就是定義多個(gè)PVP,然后做平均做知識蒸餾。
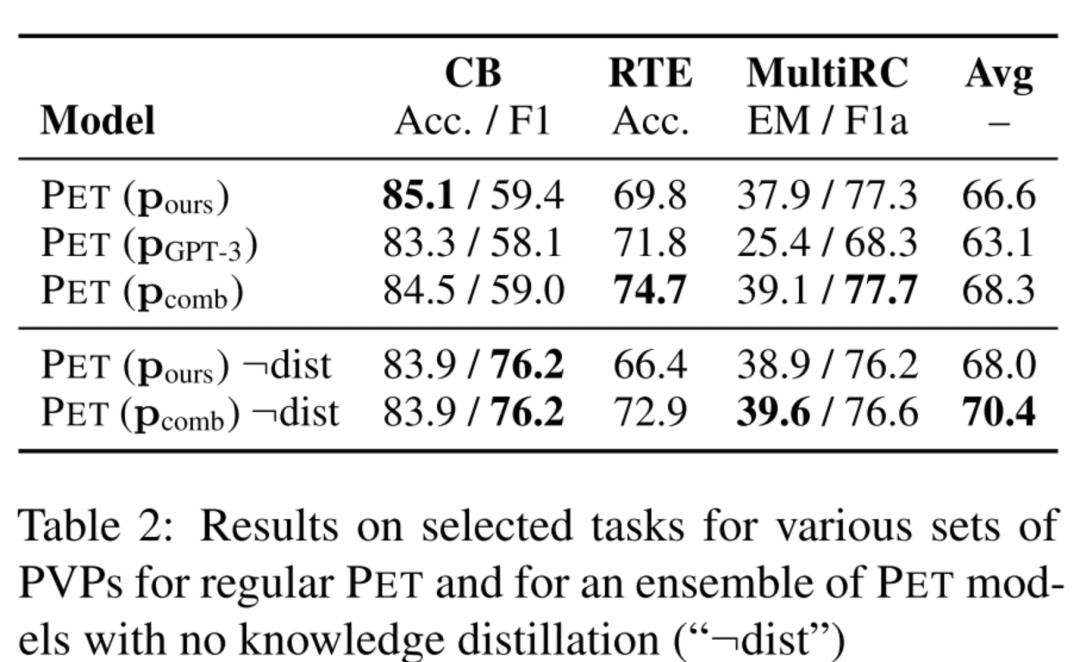
還是下面這幅圖,這里討論了unlabeled數(shù)據(jù)的利用。
在PET利用到unlabeled數(shù)據(jù)的有三個(gè)地方:
第一處:PET的第二步,用PVPs對unlabeled數(shù)據(jù)進(jìn)行知識蒸餾,給數(shù)據(jù)打上soft label,然后第三步利用這些軟標(biāo)簽訓(xùn)練一個(gè)模型; 第二處:PET的第一步,假如用的是iPET的話,每一個(gè)generation都會把部分的無標(biāo)簽數(shù)據(jù)打上標(biāo)簽,加入到PVP的訓(xùn)練集; 第三處:PET的第一步,假如采用的是Auxiliary Language Modelling輔助訓(xùn)練,也會引入無標(biāo)簽數(shù)據(jù)。
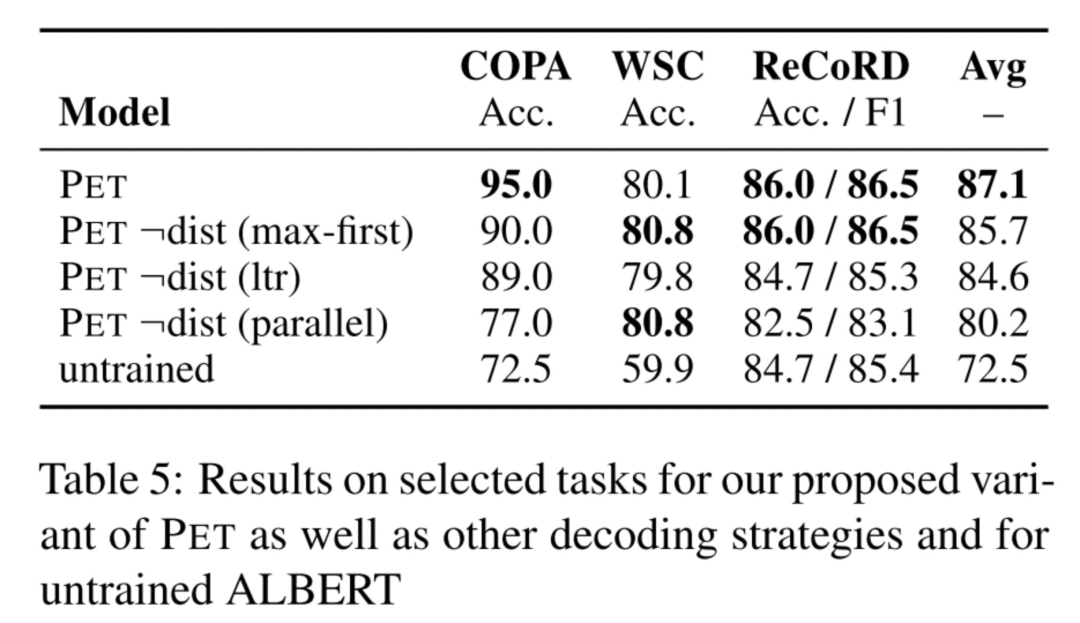
首先,討論上面的第一點(diǎn),究竟能不能直接用PET訓(xùn)練的第一步的PVPs來做預(yù)測,這樣就不用給unlabeled數(shù)據(jù)打軟標(biāo)簽了(因?yàn)殡m然說unlabeled數(shù)據(jù)比labled數(shù)據(jù)容易獲得,但某些場景下unlabeled數(shù)據(jù)也有可能是拿不到的),答案是可以的,大家看下表的倒數(shù)兩列,發(fā)現(xiàn)不用PET訓(xùn)練的第二、第三步,直接采用第一步訓(xùn)練好的PVPs來做下游應(yīng)用的預(yù)測,效果也是OK的。「只不過,這樣做的話,你應(yīng)用于下游任務(wù)的時(shí)候就是一堆PVP模型,而不是單一個(gè)模型了,這樣對輕量部署不是很友好」。

還討論了上面的第二處,發(fā)現(xiàn)iPET訓(xùn)練過程中,每一個(gè)generation從unlabeled數(shù)據(jù)中挑選部分加入到PVP的訓(xùn)練集,能讓PVP收斂更快,減少不穩(wěn)定性。
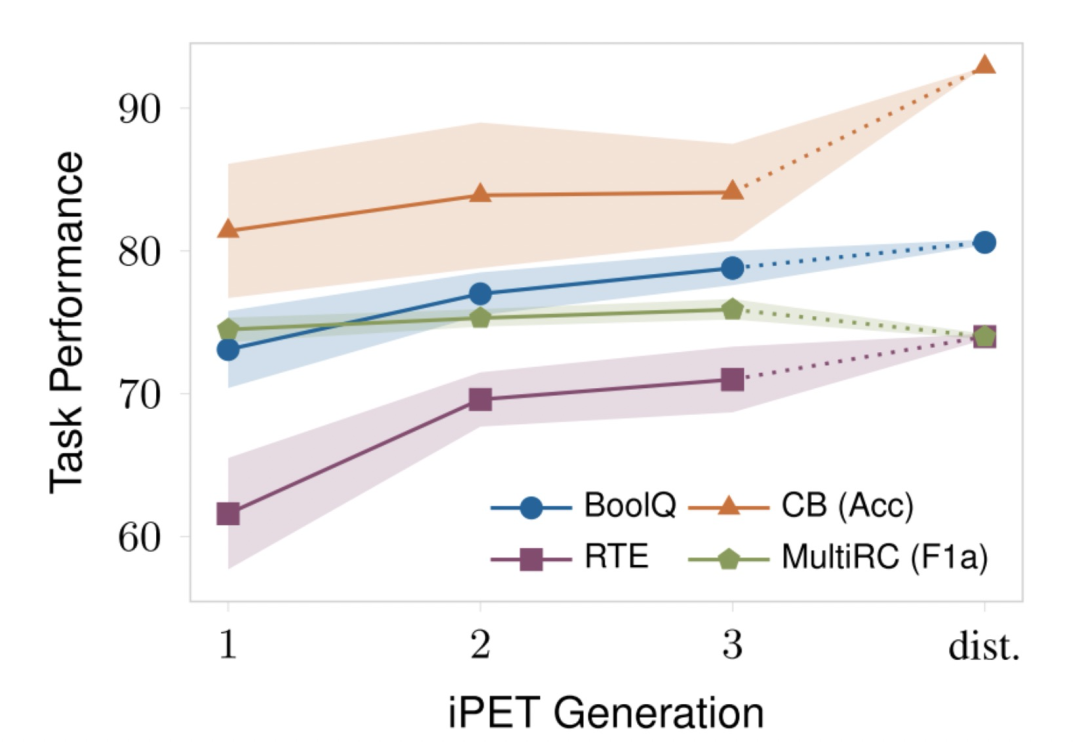
Labeled Data Usage
這里研究了labeled數(shù)據(jù)對PET的影響,
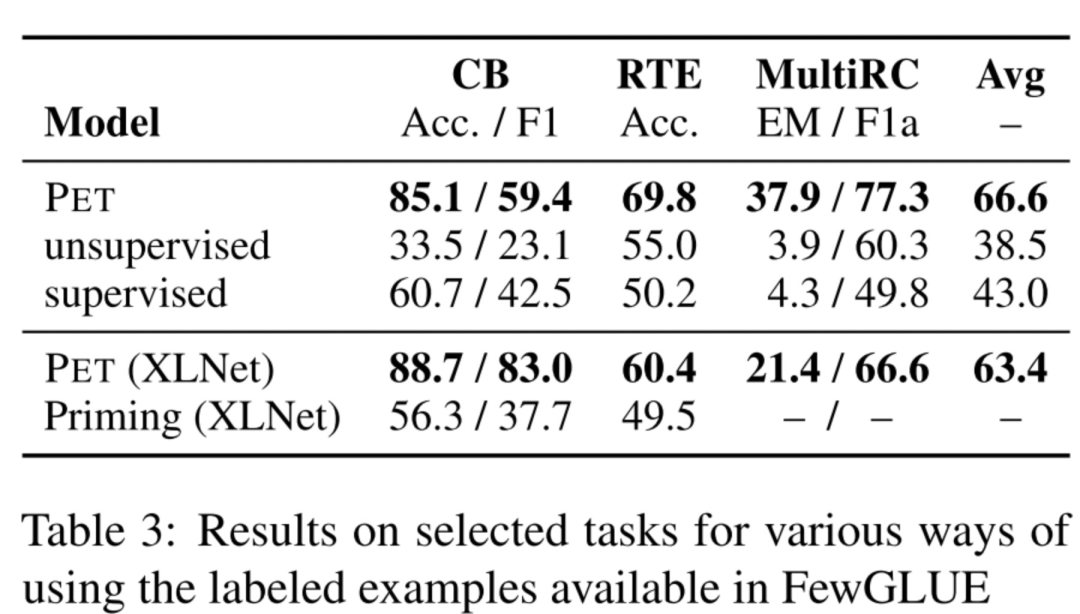
Model Type
不同預(yù)訓(xùn)練模型的影響,像BERT這種雙向的語言模型會比GPT這種單向的要好,因?yàn)榧偃绮捎玫氖菃蜗虻恼Z言模型,那么pattern的下劃線__部分只能放在句子末尾進(jìn)行預(yù)測。
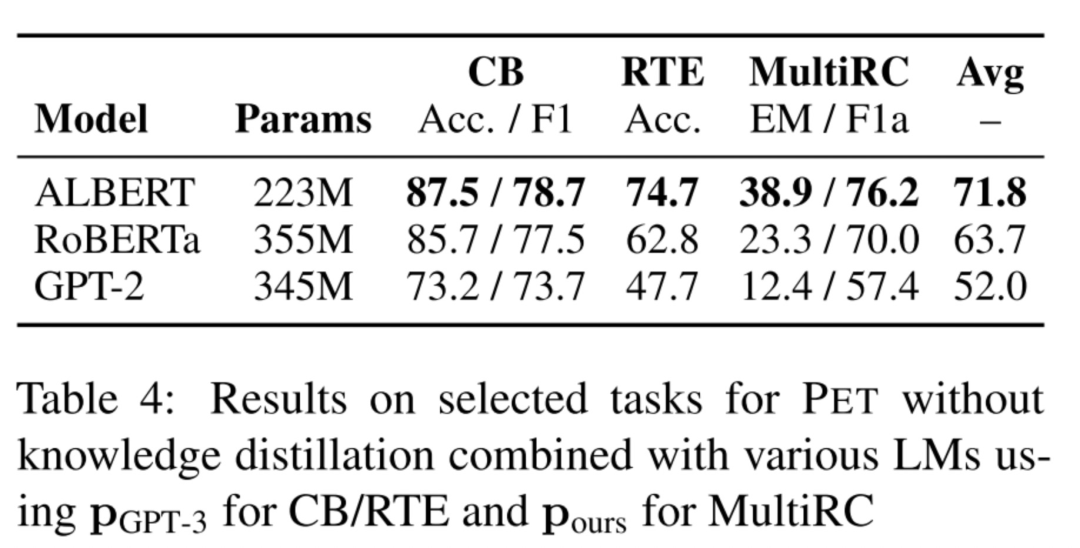
PET with Multiple Masks
討論了上面提到的處理多個(gè)mask token的效果。
Training Examples
由于是小樣本學(xué)習(xí),一開始labeled數(shù)據(jù)對PET最后的效果影響很大。
總結(jié)
個(gè)人覺得PET的思想非常的優(yōu)雅,主要利用把分類任務(wù)轉(zhuǎn)換成完形填空任務(wù),讓模型利用上預(yù)訓(xùn)練時(shí)的MLM信息,讓大家重新審視MLM任務(wù)的重要性。
一起交流
想和你一起學(xué)習(xí)進(jìn)步!『NewBeeNLP』目前已經(jīng)建立了多個(gè)不同方向交流群(機(jī)器學(xué)習(xí) / 深度學(xué)習(xí) / 自然語言處理 / 搜索推薦 / 圖網(wǎng)絡(luò) / 面試交流 / 等),名額有限,趕緊添加下方微信加入一起討論交流吧!(注意一定要備注信息才能通過)
本文參考資料
Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference Timo: https://arxiv.org/abs/2001.07676
[2]It's Not Just Size That Matters: Small Language Models Are Also Few-Shot Learners》: https://arxiv.org/abs/2009.07118
- END -

2021-07-19
2021-07-30
2021-08-06

2021-08-26
