
【NLP】文本分類微調(diào)技巧實(shí)戰(zhàn)2.0
訊飛比賽答辯結(jié)束,筆者和小伙伴們參加了一些訊飛的比賽,今年訊飛文本分類比賽相比去年更加多元化,涉及領(lǐng)域、任務(wù)和數(shù)據(jù)呈現(xiàn)多樣性,聽完各位大佬的答辯之后,結(jié)合之前經(jīng)驗(yàn)和以下賽題總結(jié)下文本分類比賽的實(shí)戰(zhàn)思路。
訊飛文本分類賽題總結(jié)
1.1 非標(biāo)準(zhǔn)化疾病訴求的簡單分診挑戰(zhàn)賽2.0 top3方案總結(jié)
賽事任務(wù)
進(jìn)行簡單分診需要一定的數(shù)據(jù)和經(jīng)驗(yàn)知識進(jìn)行支撐。本次比賽提供了部分好大夫在線的真實(shí)問診數(shù)據(jù),經(jīng)過嚴(yán)格脫敏,提供給參賽者進(jìn)行單分類任務(wù)。具體為:通過處理文字訴求,給出20個常見的就診方向之一和61個疾病方向之一
賽題特點(diǎn)
分類標(biāo)簽有兩個,問診方向和疾病方向,并且評估指標(biāo)分別為macro-f1和micro-f1 疾病方向有不少數(shù)是缺失標(biāo)簽,數(shù)據(jù)集中值為-1 文本方向和疾病方向兩種標(biāo)簽有一定約束關(guān)系,表現(xiàn)為比如問診方向?yàn)椤靶《膊 保膊》较驗(yàn)椤靶合涣肌?/strong> 數(shù)據(jù)特點(diǎn)
就診方向標(biāo)簽中,其中內(nèi)科、小兒保健、咽喉疾病數(shù)量比較多,骨科、甲狀腺疾病問診人數(shù)較少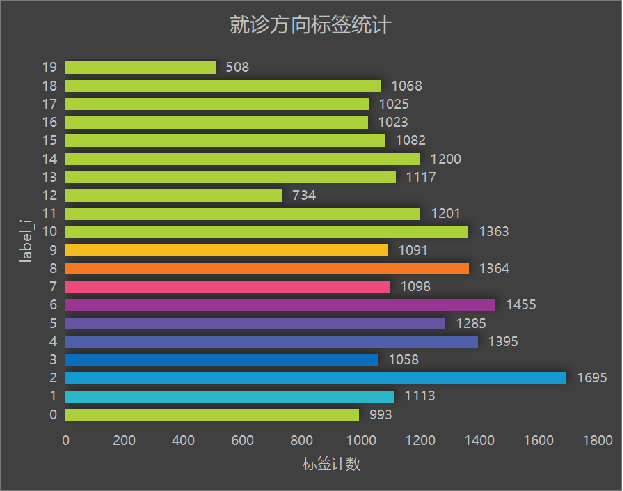
疾病方向標(biāo)簽中,其中內(nèi)科其他最多,宮腔鏡疾病人數(shù)較少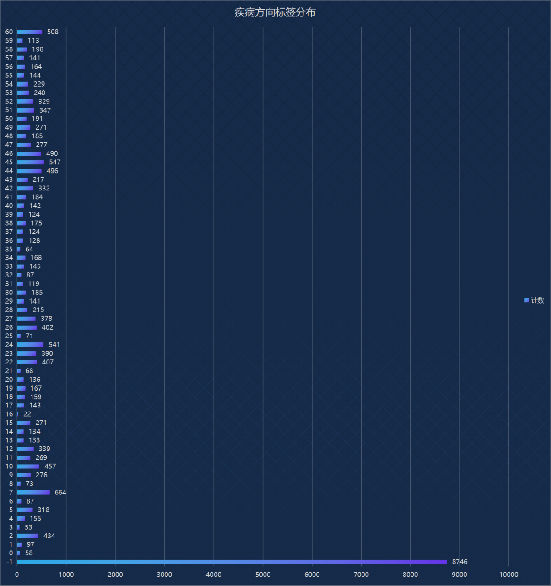
數(shù)據(jù)預(yù)處理
(1) 對于文本字段,缺失值直接用空字符串“”填充
(2) 對于spo.txt文件,根據(jù)第一列疾病名稱構(gòu)建聚合文本,用于文本語義增強(qiáng),比如
(3)如果文本文本中含有疾病名稱,就根據(jù)拼接對應(yīng)疾病的聚合文本,然后按照文本信息曝光量拼接文本,比如疾病名稱很大程度上指定了患者疾病類別歸屬, 注意:title和hopeHelp字段存在重復(fù)的情況,此時僅保留title即可
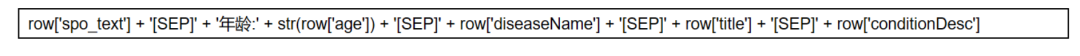
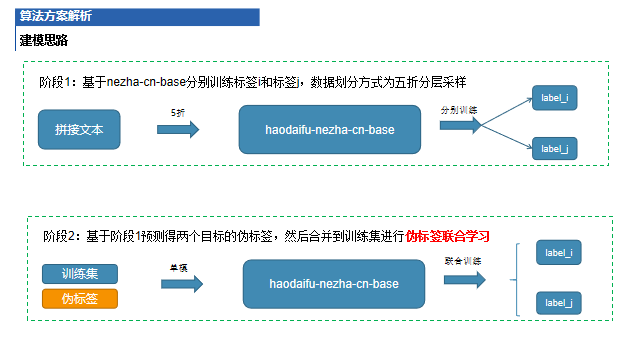
建模思路
賽題總結(jié)
問診疾病的知識文本,每條包含主體/(屬性)/客體的利用對標(biāo)簽學(xué)習(xí)具有提升效果 聯(lián)合訓(xùn)練問診方向與疾病方向標(biāo)簽相比單獨(dú)訓(xùn)練各自標(biāo)簽的模型效果要好 偽標(biāo)簽學(xué)習(xí)能夠進(jìn)一步提升在疾病方向的效果
致謝隊友:我的心是冰冰的、江東、pxx_player
1.2 中文語義病句識別挑戰(zhàn)賽 top2方案總結(jié)
賽事任務(wù)
中文語義病句識別是一個二分類的問題,預(yù)測句子是否是語義病句。語義錯誤和拼寫錯誤、語法錯誤不同,語義錯誤更加關(guān)注句子語義層面的合法性,語義病句例子如下表所示。
賽題特點(diǎn)
本次比賽使用的數(shù)據(jù)一部分來自網(wǎng)絡(luò)上的中小學(xué)病句題庫,一部分來自人工標(biāo)注,比賽一開始拿到數(shù)據(jù)的時候,真的讓人去做病句識別就很難 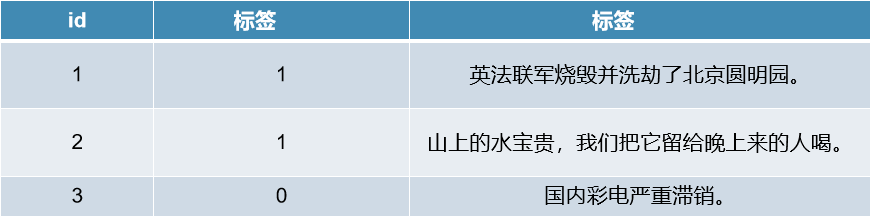
標(biāo)簽分布比較特殊,數(shù)據(jù)量比較大,1的數(shù)據(jù)是0的數(shù)量約3倍 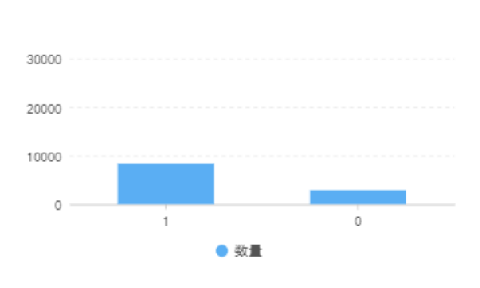
數(shù)據(jù)預(yù)處理
在比賽過程中,選手們可以發(fā)現(xiàn)這個數(shù)據(jù)比較容易擬合,通過分析其中有部分?jǐn)?shù)據(jù)比較相似、甚至有些是重復(fù)數(shù)據(jù),所以需要過濾去除重復(fù)數(shù)據(jù),減少線差 數(shù)據(jù)劃分采用多折分層采樣
建模思路
在實(shí)驗(yàn)過程中,我們嘗試了一些中文預(yù)訓(xùn)練模型,比如選擇macbert或者具有糾錯能力的模型,效果不錯的是macbert和electra
shibing624/macbert4csc-base-chinese
hfl/chinese-macbert-base、hfl/chinese-macbert-large
nezha-large-zh
hfl/chinese-electra-large-discriminator
hfl/chinese-roberta-wwm-ext
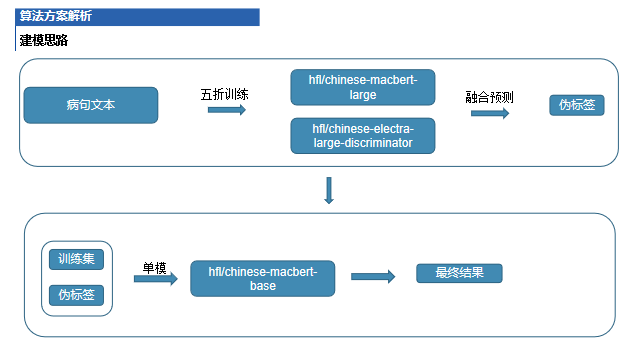
賽題總結(jié)
中文病句識別的預(yù)訓(xùn)練底座基礎(chǔ)選型比較重要,其中electra和macbert不錯,除此看其他大佬使用了prompt learning、pert模型 數(shù)據(jù)去重可以減少線差
致謝隊友:江東、A08B06365ECB216A
1.3 人崗匹配挑戰(zhàn)賽 top2方案總結(jié)
賽題任務(wù)
智能人崗匹配需要強(qiáng)大的數(shù)據(jù)作為支撐,本次大賽提供了大量的崗位JD和求職者簡歷的加密脫敏數(shù)據(jù)作為訓(xùn)練樣本,參賽選手需基于提供的樣本構(gòu)建模型,預(yù)測簡歷與崗位匹配與否。
數(shù)據(jù)預(yù)處理
本次比賽為參賽選手提供了大量的崗位JD和求職者簡歷,其中:
崗位JD數(shù)據(jù)包含4個特征字段:job_id, 職位名稱, 職位描述, 職位要求
求職者簡歷數(shù)據(jù)包含15個特征字段:
id, 學(xué)校類別, 第一學(xué)歷, 第一學(xué)歷學(xué)校, 第一學(xué)歷專業(yè), 最高學(xué)歷, 最高學(xué)歷學(xué)校, 最高學(xué)歷專業(yè), 教育經(jīng)歷, 學(xué)術(shù)成果, 校園經(jīng)歷, 實(shí)習(xí)經(jīng)歷, 獲獎信息, 其他證書信息, job_id。
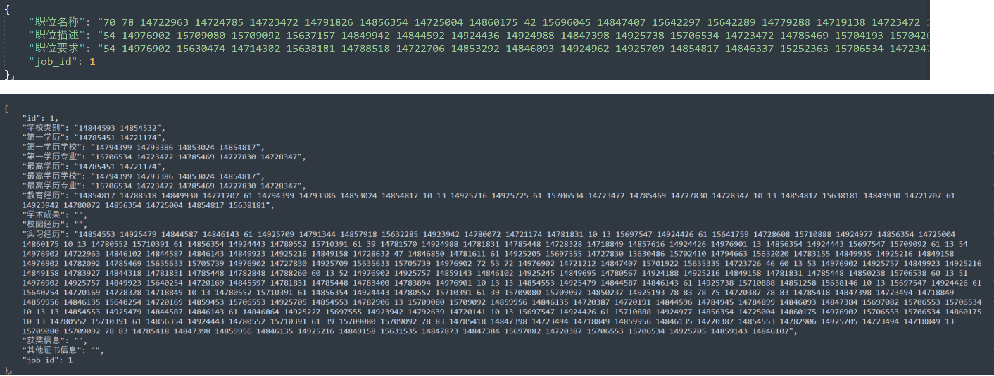
在訓(xùn)練集中,job_id的數(shù)量分布如下,可以看出崗位4和12數(shù)量最多,38和37崗位比較少 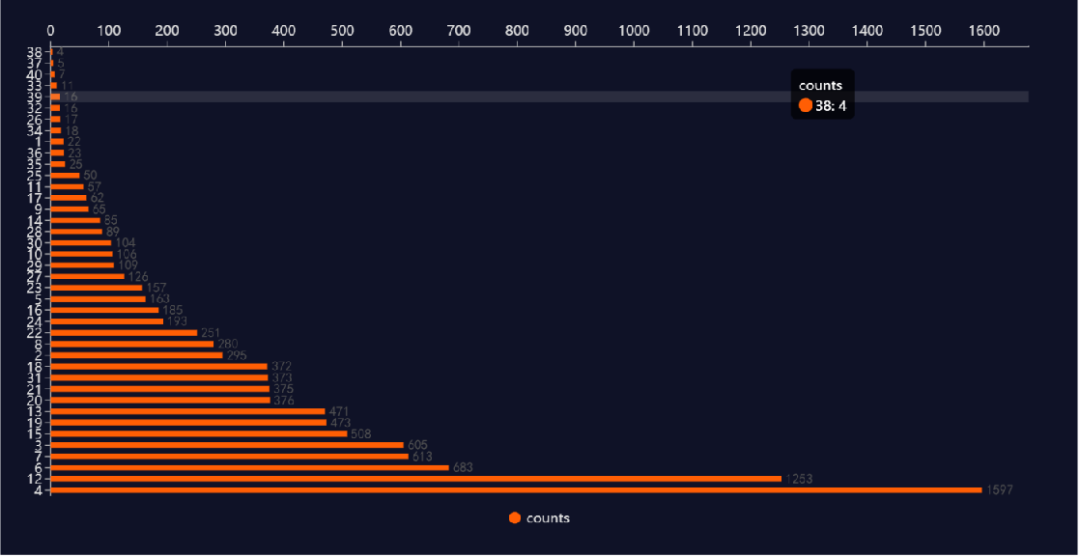
建模思路
詞表構(gòu)建 由于本次比賽數(shù)據(jù)為匿名數(shù)據(jù),開源中文預(yù)訓(xùn)練模型不適用,因此需要重新構(gòu)建詞表、語料,進(jìn)而重新訓(xùn)練預(yù)訓(xùn)練模型 第一步,構(gòu)建詞匯表,根據(jù)訓(xùn)練集、測試集和JD數(shù)據(jù),按照空格分詞,對所有文本進(jìn)行切分,然后構(gòu)建詞匯表,另外需要加入五個特殊字符,[PAD]、[UNK]、[CLS]、[SEP]、[MASK],最后詞匯表大小為4571 預(yù)訓(xùn)練語料構(gòu)建 由于本次比賽數(shù)據(jù)為匿名數(shù)據(jù),開源中文預(yù)訓(xùn)練模型不適用,因此需要重新構(gòu)建詞表、語料,進(jìn)而重新訓(xùn)練預(yù)訓(xùn)練模型
第二步,構(gòu)建預(yù)訓(xùn)練語料,直接將學(xué)校類別, 第一學(xué)歷, 第一學(xué)歷學(xué)校, 第一學(xué)歷專業(yè), 最高學(xué)歷, 最高學(xué)歷學(xué)校, 最高學(xué)歷專業(yè), 教育經(jīng)歷, 學(xué)術(shù)成果, 校園經(jīng)歷, 實(shí)習(xí)經(jīng)歷, 獲獎信息, 其他證書信息這些字段的文本拼接在一起,生成一個人的簡歷描述。

預(yù)訓(xùn)練任務(wù) 在實(shí)驗(yàn)過程中,我們選擇了兩種預(yù)訓(xùn)練模型結(jié)構(gòu):Bert和Nezha,其中Nezha效果要明顯優(yōu)于Bert
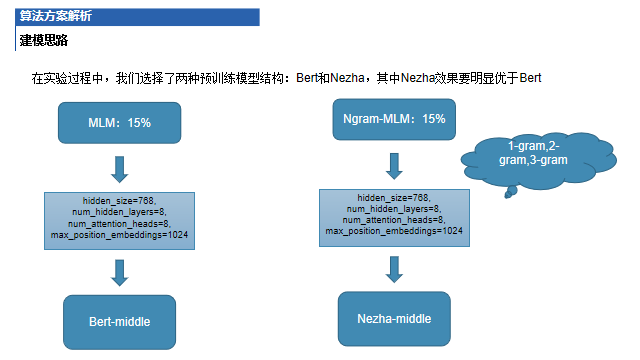
分類微調(diào) 將人崗匹配任務(wù)看做是文本分類任務(wù),對簡歷文本進(jìn)行多分類 
賽題總結(jié)
在人崗匿名數(shù)據(jù)上微調(diào),能夠有效地捕獲語義知識,并識別出不同崗位類型 NEZHA基于BERT模型,并進(jìn)行了多處優(yōu)化,能夠在一系列中文自然語言理解任務(wù)達(dá)到先進(jìn)水平 老肥隊伍、舉哥采用的思路都不同,給了很大啟發(fā),統(tǒng)計特征以及傳統(tǒng)NN網(wǎng)絡(luò)對文本分類進(jìn)一步提升
致謝隊友:WEI Z/江東/小澤/跟大佬喝口湯
優(yōu)化算法合集
下面是一些常規(guī)套路,不一定每一個任務(wù)都有作用,和數(shù)據(jù)集、預(yù)訓(xùn)練模型有很大關(guān)系,大家可以酌情選擇
FGM EMA PGD FreeLB AWP MultiDropout -MixOut
微調(diào)方法總結(jié)
文本分類還有一些微調(diào)的小技巧,也歡迎大家補(bǔ)充
分層學(xué)習(xí)率 多折交叉驗(yàn)證 偽標(biāo)簽學(xué)習(xí) Freeze Embedding Fp16混合精度訓(xùn)練
往期精彩回顧
適合初學(xué)者入門人工智能的路線及資料下載 (圖文+視頻)機(jī)器學(xué)習(xí)入門系列下載 機(jī)器學(xué)習(xí)及深度學(xué)習(xí)筆記等資料打印 《統(tǒng)計學(xué)習(xí)方法》的代碼復(fù)現(xiàn)專輯 機(jī)器學(xué)習(xí)交流qq群955171419,加入微信群請掃碼