
深度學(xué)習(xí)論文精讀[6]:UNet++

UNet的編解碼結(jié)構(gòu)一經(jīng)提出以來,大有統(tǒng)一深度學(xué)習(xí)圖像分割之勢(shì),后續(xù)基于UNet的改進(jìn)方案也經(jīng)久不衰,一些研究者也在從網(wǎng)絡(luò)結(jié)構(gòu)本身來思考UNet的有效性。比如說編解碼網(wǎng)絡(luò)應(yīng)該取幾層,跳躍連接是否能夠有更多的變化以及什么樣的結(jié)構(gòu)訓(xùn)練起來更加有效等問題。UNet本身是針對(duì)醫(yī)學(xué)圖像分割任務(wù)而提出來的網(wǎng)絡(luò)結(jié)構(gòu),該任務(wù)不像自然圖像分割,對(duì)分割精度要求并不是十分嚴(yán)格。但對(duì)于醫(yī)學(xué)圖像而言,器官和病灶的分割則要求極高的精確性,因?yàn)楹芏鄷r(shí)候分割效果的好壞直接關(guān)系到對(duì)應(yīng)的臨床診斷決策。出于上述兩個(gè)方面的動(dòng)機(jī),即設(shè)計(jì)更好的UNet結(jié)構(gòu)和提升醫(yī)學(xué)圖像分割的精度,相關(guān)研究者提出了一種嵌套的UNet結(jié)構(gòu)(Nested UNet),也叫UNet++,提出UNet++的論文為UNet++: A Nested U-Net Architecture for Medical Image Segmentation,發(fā)表于2018年的醫(yī)學(xué)圖像計(jì)算和計(jì)算機(jī)輔助干預(yù)(Medical Image Computing and Computer Assisted Intervention,MICCAI)會(huì)議上。
UNet++取名為嵌套的UNet,就在于其整體編解碼網(wǎng)絡(luò)結(jié)構(gòu)中還嵌套了編解碼的子網(wǎng)絡(luò)(sub-networks),在此基礎(chǔ)上重新設(shè)計(jì)UNet中間的跳躍連接,并補(bǔ)充了深監(jiān)督機(jī)制加速網(wǎng)絡(luò)訓(xùn)練收斂。完整的UNet++結(jié)構(gòu)如下圖所示。
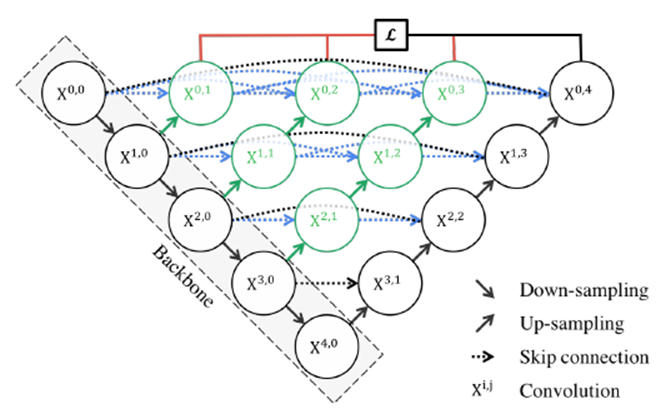
圖中黑色部分為原始的UNet結(jié)構(gòu),包括編碼器下采樣、解碼器上采樣和黑色虛線的跳躍連接三個(gè)部分;綠色部分即嵌套的UNet子網(wǎng)絡(luò),包括卷積和上采樣兩部分,而藍(lán)色虛線部分就是UNet++重新設(shè)計(jì)后的跳躍連接,這部分跟DenseNet的密集連接類似,這里是為子網(wǎng)絡(luò)提供跳躍連接;最上面紅黑連線則是UNet++補(bǔ)充的深監(jiān)督機(jī)制,目的是為了網(wǎng)絡(luò)能夠順利得到訓(xùn)練。
下面我們從結(jié)構(gòu)設(shè)計(jì)的角度來對(duì)UNet++進(jìn)行解讀。關(guān)于UNet結(jié)構(gòu),最首要的問題就是網(wǎng)絡(luò)應(yīng)該有幾層,原始的UNet結(jié)構(gòu)用了4層下采樣和4層上采樣,那么是不是4層就足以滿足所有的分割任務(wù)需要?答案是否定的。通過本節(jié)之前的網(wǎng)絡(luò)結(jié)構(gòu)分析,我們已經(jīng)知道,淺層網(wǎng)絡(luò)能夠提取圖像粗粒度特征,獲取圖像基本形態(tài);深層網(wǎng)絡(luò)能夠提取圖像的抽象特征,獲取圖像語義信息,總之淺有淺的側(cè)重,深有深的好處。同之前RefineNet的觀點(diǎn)一樣,UNet++的作者認(rèn)為,不管是淺層、深層還是中層,所有層次的特征對(duì)于最后的分割都是重要的。有的數(shù)據(jù)分割任務(wù)簡單,圖像信息單一,可能淺層網(wǎng)絡(luò)就足以達(dá)到很好的效果,而有的數(shù)據(jù)任務(wù)復(fù)雜,圖像信息豐富,可能需要更深層的網(wǎng)絡(luò)結(jié)構(gòu)才能達(dá)到不錯(cuò)的效果,之前的UNet結(jié)構(gòu)設(shè)計(jì)很難同時(shí)照顧到這種普適性。而UNet++通過設(shè)計(jì)不同深度的嵌套UNet子網(wǎng)絡(luò)來實(shí)現(xiàn)這種普適性,所以UNet的深度到這里就解決了。
第二個(gè)問題則是加入不同深度的嵌套網(wǎng)絡(luò)后,跳躍連接部分該如何調(diào)整。在UNet中,跳躍連接由同層編碼器直連到編碼器上采樣對(duì)應(yīng)層。但加入嵌套子網(wǎng)絡(luò)后,UNet中原先的長連接就不復(fù)存在了,取而代之的是各子網(wǎng)絡(luò)中的短連接。UNet++的作者們認(rèn)為,長連接在UNet中是有必要的,能夠?qū)D像中前后信息聯(lián)系起來,對(duì)于下采樣造成的信息損失有很好的補(bǔ)充作用。所以,UNet++又參考DenseNet的密集連接設(shè)計(jì),給嵌套網(wǎng)絡(luò)補(bǔ)充了長連接,如下圖5所示。
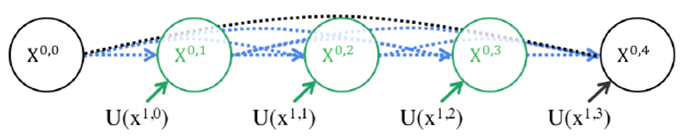
但是這樣又帶來了第三個(gè)問題:反向傳播的時(shí)候中間部分可能會(huì)收不到由損失函數(shù)反傳回來的梯度。所以見招拆招,UNet++又通過深監(jiān)督的方法來強(qiáng)行加梯度,幫助網(wǎng)絡(luò)正常進(jìn)行訓(xùn)練。但深監(jiān)督對(duì)于UNet++的好處絕不僅僅限于此,通過不同深監(jiān)督損失函數(shù),UNet++可以通過網(wǎng)絡(luò)剪枝來實(shí)現(xiàn)可伸縮性。所以,總結(jié)來說UNet++相較于原始的UNet,有如下兩個(gè)優(yōu)勢(shì):
(1)通過嵌套子網(wǎng)絡(luò)和長短連接來整合不同層次的圖像特征,使得網(wǎng)絡(luò)分割精度更高;
(2)靈活的網(wǎng)絡(luò)結(jié)構(gòu)配合深監(jiān)督機(jī)制,讓參數(shù)量巨大的深度網(wǎng)絡(luò)在可接受的精度范圍內(nèi)能夠大幅度的縮減參數(shù)量。
UNet++與UNet等網(wǎng)絡(luò)分割效果對(duì)比如下圖所示。

UNet++也進(jìn)一步壯大了UNet家族網(wǎng)絡(luò),后續(xù)基于其的改進(jìn)版本也有很多,比如Attention UNet++、UNet 3+等。下述代碼給出了UNet++的一個(gè)實(shí)現(xiàn)參考。完整代碼可參考:
https://github.com/4uiiurz1/pytorch-nested-unet/blob/master/archs.py
class NestedUNet(nn.Module):def __init__(self, num_classes, input_channels=3, deep_supervision=False, **kwargs):super().__init__()nb_filter = [32, 64, 128, 256, 512]self.deep_supervision = deep_supervisionself.pool = nn.MaxPool2d(2, 2)self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)self.conv0_0 = VGGBlock(input_channels, nb_filter[0], nb_filter[0])self.conv1_0 = VGGBlock(nb_filter[0], nb_filter[1], nb_filter[1])self.conv2_0 = VGGBlock(nb_filter[1], nb_filter[2], nb_filter[2])self.conv3_0 = VGGBlock(nb_filter[2], nb_filter[3], nb_filter[3])self.conv4_0 = VGGBlock(nb_filter[3], nb_filter[4], nb_filter[4])self.conv0_1 = VGGBlock(nb_filter[0]+nb_filter[1], nb_filter[0], nb_filter[0])self.conv1_1 = VGGBlock(nb_filter[1]+nb_filter[2], nb_filter[1], nb_filter[1])self.conv2_1 = VGGBlock(nb_filter[2]+nb_filter[3], nb_filter[2], nb_filter[2])self.conv3_1 = VGGBlock(nb_filter[3]+nb_filter[4], nb_filter[3], nb_filter[3])self.conv0_2 = VGGBlock(nb_filter[0]*2+nb_filter[1], nb_filter[0], nb_filter[0])self.conv1_2 = VGGBlock(nb_filter[1]*2+nb_filter[2], nb_filter[1], nb_filter[1])self.conv2_2 = VGGBlock(nb_filter[2]*2+nb_filter[3], nb_filter[2], nb_filter[2])self.conv0_3 = VGGBlock(nb_filter[0]*3+nb_filter[1], nb_filter[0], nb_filter[0])self.conv1_3 = VGGBlock(nb_filter[1]*3+nb_filter[2], nb_filter[1], nb_filter[1])self.conv0_4 = VGGBlock(nb_filter[0]*4+nb_filter[1], nb_filter[0], nb_filter[0])if self.deep_supervision:self.final1 = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)self.final2 = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)self.final3 = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)self.final4 = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)else:self.final = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)def forward(self, input):x0_0 = self.conv0_0(input)x1_0 = self.conv1_0(self.pool(x0_0))x0_1 = self.conv0_1(torch.cat([x0_0, self.up(x1_0)], 1))x2_0 = self.conv2_0(self.pool(x1_0))x1_1 = self.conv1_1(torch.cat([x1_0, self.up(x2_0)], 1))x0_2 = self.conv0_2(torch.cat([x0_0, x0_1, self.up(x1_1)], 1))x3_0 = self.conv3_0(self.pool(x2_0))x2_1 = self.conv2_1(torch.cat([x2_0, self.up(x3_0)], 1))x1_2 = self.conv1_2(torch.cat([x1_0, x1_1, self.up(x2_1)], 1))x0_3 = self.conv0_3(torch.cat([x0_0, x0_1, x0_2, self.up(x1_2)], 1))x4_0 = self.conv4_0(self.pool(x3_0))x3_1 = self.conv3_1(torch.cat([x3_0, self.up(x4_0)], 1))x2_2 = self.conv2_2(torch.cat([x2_0, x2_1, self.up(x3_1)], 1))x1_3 = self.conv1_3(torch.cat([x1_0, x1_1, x1_2, self.up(x2_2)], 1))x0_4 = self.conv0_4(torch.cat([x0_0, x0_1, x0_2, x0_3, self.up(x1_3)], 1))if self.deep_supervision:output1 = self.final1(x0_1)output2 = self.final2(x0_2)output3 = self.final3(x0_3)output4 = self.final4(x0_4)return [output1, output2, output3, output4]else:output = self.final(x0_4)return output
根據(jù)讀者對(duì)于本系列的反饋,后續(xù)相關(guān)內(nèi)容會(huì)逐步更新到深度學(xué)習(xí)語義分割與實(shí)戰(zhàn)指南GitHub地址:
https://github.com/luwill/Semantic-Segmentation-Guide
往期精彩:
深度學(xué)習(xí)論文精讀[1]:FCN全卷積網(wǎng)絡(luò)
深度學(xué)習(xí)論文精讀[2]:UNet網(wǎng)絡(luò)
深度學(xué)習(xí)論文精讀[4]:RefineNet
深度學(xué)習(xí)論文精讀[5]:Attention UNet
講解視頻來了!機(jī)器學(xué)習(xí) 公式推導(dǎo)與代碼實(shí)現(xiàn)開錄!
完結(jié)!《機(jī)器學(xué)習(xí) 公式推導(dǎo)與代碼實(shí)現(xiàn)》全書1-26章PPT下載