
Linux文本三劍客超詳細教程---grep、sed、awk
公眾號關(guān)注“杰哥的IT之旅”,
選擇“星標”,重磅干貨,第一時間送達!

awk、grep、sed是linux操作文本的三大利器,合稱文本三劍客,也是必須掌握的linux命令之一。三者的功能都是處理文本,但側(cè)重點各不相同,其中屬awk功能最強大,但也最復雜。grep更適合單純的查找或匹配文本,sed更適合編輯匹配到的文本,awk更適合格式化文本,對文本進行較復雜格式處理。
1、grep
1.1 什么是grep和egrep
Linux系統(tǒng)中g(shù)rep命令是一種強大的文本搜索工具,它能使用正則表達式搜索文本,并把匹配的行打印出來(匹配到的標紅)。grep全稱是Global Regular Expression Print,表示全局正則表達式版本,它的使用權(quán)限是所有用戶。
grep的工作方式是這樣的,它在一個或多個文件中搜索字符串模板。如果模板包括空格,則必須被引用,模板后的所有字符串被看作文件名。搜索的結(jié)果被送到標準輸出,不影響原文件內(nèi)容。
grep可用于shell腳本,因為grep通過返回一個狀態(tài)值來說明搜索的狀態(tài),如果模板搜索成功,則返回0,如果搜索不成功,則返回1,如果搜索的文件不存在,則返回2。我們利用這些返回值就可進行一些自動化的文本處理工作。
egrep = grep -E:擴展的正則表達式 (除了< , \> , \b 使用其他正則都可以去掉\)
1.2 使用grep
1.2.1 命令格式
grep [option] pattern file
1.2.2 命令功能
用于過濾/搜索的特定字符。可使用正則表達式能多種命令配合使用,使用上十分靈活。
1.2.3 命令參數(shù)
常用參數(shù)已加粗
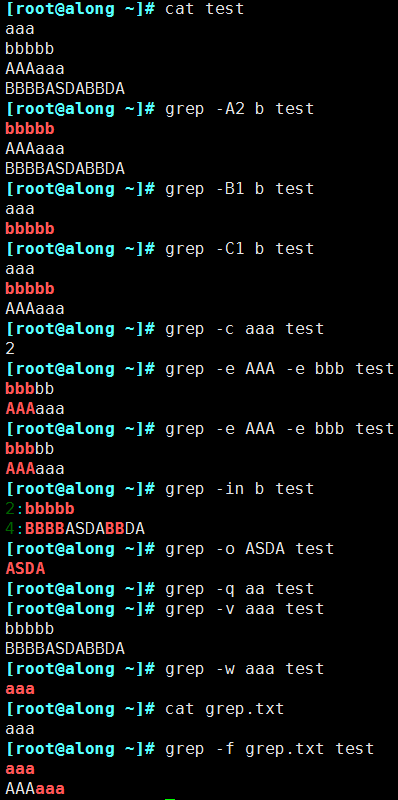
-A<顯示行數(shù)>:除了顯示符合范本樣式的那一列之外,并顯示該行之后的內(nèi)容。
-B<顯示行數(shù)>:除了顯示符合樣式的那一行之外,并顯示該行之前的內(nèi)容。
-C<顯示行數(shù)>:除了顯示符合樣式的那一行之外,并顯示該行之前后的內(nèi)容。
-c:統(tǒng)計匹配的行數(shù)
-e:實現(xiàn)多個選項間的邏輯or 關(guān)系
-E:擴展的正則表達式
-f FILE:從FILE獲取PATTERN匹配
-F:相當于fgrep
-i --ignore-case #忽略字符大小寫的差別。
-n:顯示匹配的行號
-o:僅顯示匹配到的字符串
-q:靜默模式,不輸出任何信息
-s:不顯示錯誤信息。
-v:顯示不被pattern 匹配到的行,相當于[^] 反向匹配
-w:匹配 整個單詞
1.3 grep實戰(zhàn)演示
2、正則表達式
2.1 認識正則
(1)介紹
正則表達式應用廣泛,在絕大多數(shù)的編程語言都可以完美應用,在Linux中,也有著極大的用處。
使用正則表達式,可以有效的篩選出需要的文本,然后結(jié)合相應的支持的工具或語言,完成任務(wù)需求。
在本篇博客中,我們使用grep/egrep來完成對正則表達式的調(diào)用
(2)正則表達式類型
正則表達式可以使用正則表達式引擎實現(xiàn),正則表達式引擎是解釋正則表達式模式并使用這些模式匹配文本的基礎(chǔ)軟件。
在Linux中,常用的正則表達式有:
POSIX 基本正則表達式(BRE)引擎
POSIX 擴展正則表達式(BRE)引擎
2.2 基本正則表達式
2.2.1 匹配字符
(1)格式
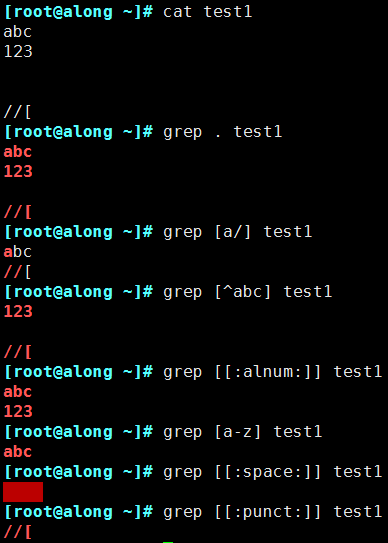
. 匹配任意單個字符,不能匹配空行
[] 匹配指定范圍內(nèi)的任意單個字符
[^] 取反
[:alnum:] 或 [0-9a-zA-Z]
[:alpha:] 或 [a-zA-Z]
[:upper:] 或 [A-Z]
[:lower:] 或 [a-z]
[:blank:] 空白字符(空格和制表符)
[:space:] 水平和垂直的空白字符(比[:blank:]包含的范圍廣)
[:cntrl:] 不可打印的控制字符(退格、刪除、警鈴…)
[:digit:] 十進制數(shù)字 或[0-9]
[:xdigit:]十六進制數(shù)字
[:graph:] 可打印的非空白字符
[:print:] 可打印字符
[:punct:] 標點符號
(2)演示
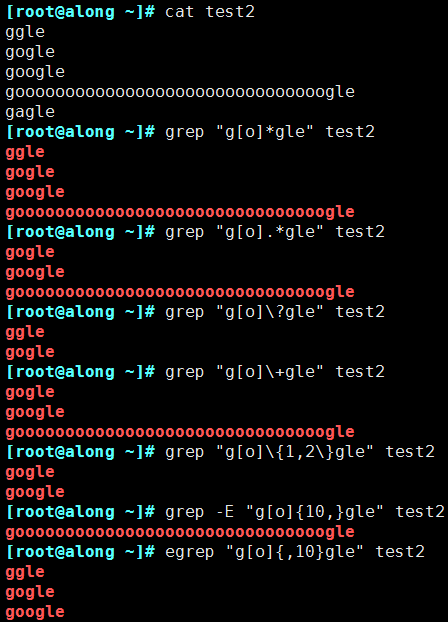
2.2.2 配置參數(shù)

(2)演示
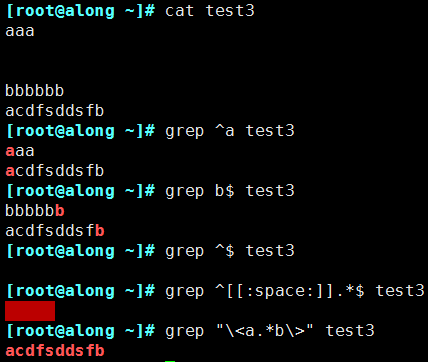
2.2.3 位置錨定:定位出現(xiàn)的位置

(2)演示
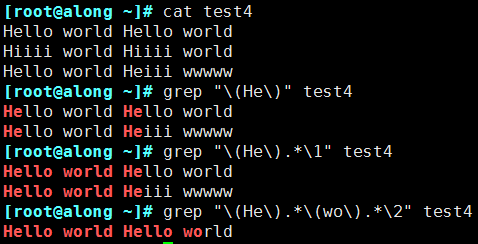
2.2.4 分組和后向引用
(1)格式
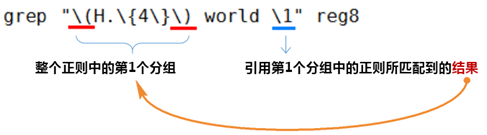
① 分組:() 將一個或多個字符捆綁在一起,當作一個整體進行處理
分組括號中的模式匹配到的內(nèi)容會被正則表達式引擎記錄于內(nèi)部的變量中,這些變量的命名方式為: \1, \2, \3, …
② 后向引用
引用前面的分組括號中的模式所匹配字符,而非模式本身
\1 表示從左側(cè)起第一個左括號以及與之匹配右括號之間的模式所匹配到的字符
\2 表示從左側(cè)起第2個左括號以及與之匹配右括號之間的模式所匹配到的字符,以此類推
\& 表示前面的分組中所有字符
③ 流程分析如下:
(2)演示
2.3 擴展正則表達式

3、sed
3.1 認識sed
sed 是一種流編輯器,它一次處理一行內(nèi)容。處理時,把當前處理的行存儲在臨時緩沖區(qū)中,稱為“模式空間”(patternspace ),接著用sed 命令處理緩沖區(qū)中的內(nèi)容,處理完成后,把緩沖區(qū)的內(nèi)容送往屏幕。然后讀入下行,執(zhí)行下一個循環(huán)。如果沒有使諸如‘D’ 的特殊命令,那會在兩個循環(huán)之間清空模式空間,但不會清空保留空間。這樣不斷重復,直到文件末尾。文件內(nèi)容并沒有改變,除非你使用重定向存儲輸出或-i。
功能:主要用來自動編輯一個或多個文件, 簡化對文件的反復操作
3.2 使用sed
3.2.1 命令格式
sed [options] '[地址定界] command' file(s)
3.2.2 常用選項options
-n:不輸出模式空間內(nèi)容到屏幕,即不自動打印,只打印匹配到的行
-e:多點編輯,對每行處理時,可以有多個Script
-f:把Script寫到文件當中,在執(zhí)行sed時-f 指定文件路徑,如果是多個Script,換行寫
-r:支持擴展的正則表達式
-i:直接將處理的結(jié)果寫入文件
-i.bak:在將處理的結(jié)果寫入文件之前備份一份
3.2.3 地址定界

3.2.4 編輯命令command

3.3 sed用法演示
3.3.1 常用選項options演示
[root@along ~]# cat demo
aaa
bbbb
AABBCCDD
[root@along ~]# sed "/aaa/p" demo #匹配到的行會打印一遍,不匹配的行也會打印
aaa
aaa
bbbb
AABBCCDD
[root@along ~]# sed -n "/aaa/p" demo #-n不顯示沒匹配的行
aaa
[root@along ~]# sed -e "s/a/A/" -e "s/b/B/" demo #-e多點編輯
Aaa
Bbbb
AABBCCDD
[root@along ~]# cat sedscript.txt
s/A/a/g
[root@along ~]# sed -f sedscript.txt demo #-f使用文件處理
aaa
bbbb
aaBBCCDD
[root@along ~]# sed -i.bak "s/a/A/g" demo #-i直接對文件進行處理
[root@along ~]# cat demo
AAA
bbbb
AABBCCDD
[root@along ~]# cat demo.bak
aaa
bbbb
AABBCCDD
3.3.2 地址界定演示
[root@along ~]# cat demo
aaa
bbbb
AABBCCDD
[root@along ~]# sed -n "p" demo #不指定行,打印全文
aaa
bbbb
AABBCCDD
[root@along ~]# sed "2s/b/B/g" demo #替換第2行的b->B
aaa
BBBB
AABBCCDD
[root@along ~]# sed -n "/aaa/p" demo
aaa
[root@along ~]# sed -n "1,2p" demo #打印1-2行
aaa
bbbb
[root@along ~]# sed -n "/aaa/,/DD/p" demo
aaa
bbbb
AABBCCDD
[root@along ~]# sed -n "2,/DD/p" demo
bbbb
AABBCCDD
[root@along ~]# sed "1~2s/[aA]/E/g" demo #將奇數(shù)行的a或A替換為E
EEE
bbbb
EEBBCCDD
3.3.3 編輯命令command演示
[root@along ~]# cat demo
aaa
bbbb
AABBCCDD
[root@along ~]# sed "2d" demo #刪除第2行
aaa
AABBCCDD
[root@along ~]# sed -n "2p" demo #打印第2行
bbbb
[root@along ~]# sed "2a123" demo #在第2行后加123
aaa
bbbb
123
AABBCCDD
[root@along ~]# sed "1i123" demo #在第1行前加123
123
aaa
bbbb
AABBCCDD
[root@along ~]# sed "3c123\n456" demo #替換第3行內(nèi)容
aaa
bbbb
123
456
[root@along ~]# sed -n "3w/root/demo3" demo #保存第3行的內(nèi)容到demo3文件中
[root@along ~]# cat demo3
AABBCCDD
[root@along ~]# sed "1r/root/demo3" demo #讀取demo3的內(nèi)容到第1行后
aaa
AABBCCDD
bbbb
AABBCCDD
[root@along ~]# sed -n "=" demo #=打印行號
1
2
3
[root@along ~]# sed -n '2!p' demo #打印除了第2行的內(nèi)容
aaa
AABBCCDD
[root@along ~]# sed 's@[a-z]@\u&@g' demo #將全文的小寫字母替換為大寫字母
AAA
BBBB
AABBCCDD
3.4 sed高級編輯命令
(1)格式
h:把模式空間中的內(nèi)容覆蓋至保持空間中
H:把模式空間中的內(nèi)容追加至保持空間中
g:從保持空間取出數(shù)據(jù)覆蓋至模式空間
G:從保持空間取出內(nèi)容追加至模式空間
x:把模式空間中的內(nèi)容與保持空間中的內(nèi)容進行互換
n:讀取匹配到的行的下一行覆蓋 至模式空間
N:讀取匹配到的行的下一行追加 至模式空間
d:刪除模式空間中的行
D:刪除 當前模式空間開端至\n 的內(nèi)容(不再傳 至標準輸出),放棄之后的命令,但是對剩余模式空間重新執(zhí)行sed
(2)一個案例+示意圖演示
① 案例:倒序輸出文本內(nèi)容
[root@along ~]# cat num.txt
One
Two
Three
[root@along ~]# sed '1!G;h;$!d' num.txt
Three
Two
One
② 示意圖如下:
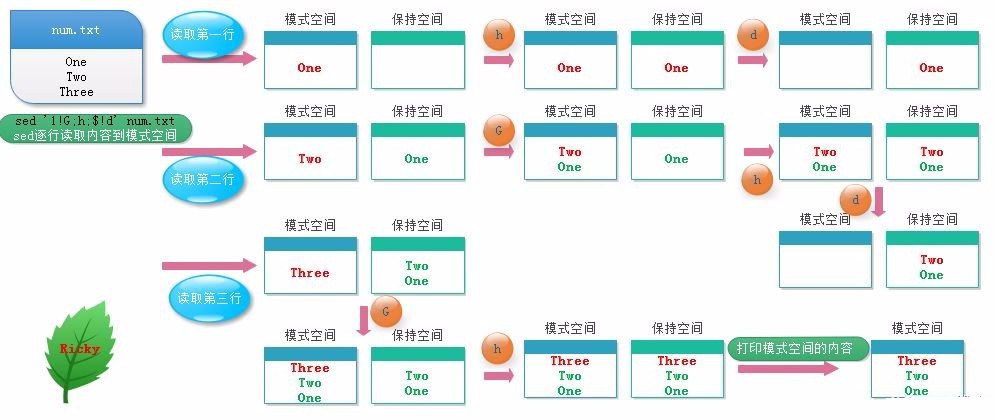
③ 總結(jié)模式空間與保持空間關(guān)系:
保持空間是模式空間一個臨時存放數(shù)據(jù)的緩沖區(qū),協(xié)助模式空間進行數(shù)據(jù)處理
(3)演示
① 顯示偶數(shù)行
[root@along ~]# seq 9 |sed -n 'n;p'
2
4
6
8
② 倒序顯示
[root@along ~]# seq 9 |sed '1!G;h;$!d'
9
8
7
6
5
4
3
2
1
③ 顯示奇數(shù)行
[root@along ~]# seq 9 |sed 'H;n;d'
1
3
5
7
9
④ 顯示最后一行
[root@along ~]# seq 9| sed 'N;D'
9
⑤ 每行之間加空行
[root@along ~]# seq 9 |sed 'G'
1
2
3
4
5
6
7
8
9
---
⑥ 把每行內(nèi)容替換成空行
[root@along ~]# seq 9 |sed "g"
---
⑦ 確保每一行下面都有一個空行
[root@along ~]# seq 9 |sed '/^$/d;G'
1
2
3
4
5
6
7
8
9
4、awk
4.1 認識awk
awk是一種編程語言,用于在linux/unix下對文本和數(shù)據(jù)進行處理。數(shù)據(jù)可以來自標準輸入(stdin)、一個或多個文件,或其它命令的輸出。它支持用戶自定義函數(shù)和動態(tài)正則表達式等先進功能,是linux/unix下的一個強大編程工具。它在命令行中使用,但更多是作為腳本來使用。awk有很多內(nèi)建的功能,比如數(shù)組、函數(shù)等,這是它和C語言的相同之處,靈活性是awk最大的優(yōu)勢。
awk其實不僅僅是工具軟件,還是一種編程語言。不過,本文只介紹它的命令行用法,對于大多數(shù)場合,應該足夠用了。
4.2 使用awk
4.2.1 語法
awk [options] 'program' var=value file…
awk [options] -f programfile var=value file…
awk [options] 'BEGIN{ action;… } pattern{ action;… } END{ action;… }' file ...
4.2.2 常用命令選項
-F fs:fs指定輸入分隔符,fs可以是字符串或正則表達式,如-F:
-v var=value:賦值一個用戶定義變量,將外部變量傳遞給awk
-f scripfile:從腳本文件中讀取awk命令
4.3 awk變量
變量:內(nèi)置和自定義變量,每個變量前加 -v 命令選項
4.3.1 內(nèi)置變量
(1)格式
FS :輸入字段分隔符,默認為空白字符
OFS :輸出字段分隔符,默認為空白字符
RS :輸入記錄分隔符,指定輸入時的換行符,原換行符仍有效
ORS :輸出記錄分隔符,輸出時用指定符號代替換行符
NF :字段數(shù)量,共有多少字段,
 (NF-1)引用倒數(shù)第2列
(NF-1)引用倒數(shù)第2列NR :行號,后可跟多個文件,第二個文件行號繼續(xù)從第一個文件最后行號開始
FNR :各文件分別計數(shù), 行號,后跟一個文件和NR一樣,跟多個文件,第二個文件行號從1開始
FILENAME :當前文件名
ARGC :命令行參數(shù)的個數(shù)
ARGV :數(shù)組,保存的是命令行所給定的各參數(shù),查看參數(shù)
(2)演示
[root@along ~]# cat awkdemo
hello:world
linux:redhat:lalala:hahaha
along:love:youou
[root@along ~]# awk -v FS=':' '{print $1,$2}' awkdemo #FS指定輸入分隔符
hello world
linux redhat
along love
[root@along ~]# awk -v FS=':' -v OFS='---' '{print $1,$2}' awkdemo #OFS指定輸出分隔符
hello---world
linux---redhat
along---love
[root@along ~]# awk -v RS=':' '{print $1,$2}' awkdemo
hello
world linux
redhat
lalala
hahaha along
love
you
[root@along ~]# awk -v FS=':' -v ORS='---' '{print $1,$2}' awkdemo
hello world---linux redhat---along love---
[root@along ~]# awk -F: '{print NF}' awkdemo
2
4
3
[root@along ~]# awk -F: '{print $(NF-1)}' awkdemo #顯示倒數(shù)第2列
hello
lalala
love
[root@along ~]# awk '{print NR}' awkdemo awkdemo1
1
2
3
4
5
[root@along ~]# awk END'{print NR}' awkdemo awkdemo1
5
[root@along ~]# awk '{print FNR}' awkdemo awkdemo1
1
2
3
1
2
[root@along ~]# awk '{print FILENAME}' awkdemo
awkdemo
awkdemo
awkdemo
[root@along ~]# awk 'BEGIN {print ARGC}' awkdemo awkdemo1
3
[root@along ~]# awk 'BEGIN {print ARGV[0]}' awkdemo awkdemo1
awk
[root@along ~]# awk 'BEGIN {print ARGV[1]}' awkdemo awkdemo1
awkdemo
[root@along ~]# awk 'BEGIN {print ARGV[2]}' awkdemo awkdemo1
awkdemo1
4.3.2 自定義變量
自定義變量( 區(qū)分字符大小寫)
(1)-v var=value
① 先定義變量,后執(zhí)行動作print
[root@along ~]# awk -v name="along" -F: '{print name":"$0}' awkdemo
along:hello:world
along:linux:redhat:lalala:hahaha
along:along:love:you
② 在執(zhí)行動作print后定義變量
[root@along ~]# awk -F: '{print name":"$0;name="along"}' awkdemo
:hello:world
along:linux:redhat:lalala:hahaha
along:along:love:you
(2)在program 中直接定義
可以把執(zhí)行的動作放在腳本中,直接調(diào)用腳本 -f
[root@along ~]# cat awk.txt
{name="along";print name,$1}
[root@along ~]# awk -F: -f awk.txt awkdemo
along hello
along linux
along along
4.4 printf命令
比print更強大
4.4.1 格式
(1)格式化輸出
printf "FORMAT", item1,item2, ...
① 必須指定FORMAT
② 不會自動換行,需要顯式給出換行控制符,\n
③ FORMAT 中需要分別為后面每個item 指定格式符
(2)格式符:與item 一一對應
%c: 顯示字符的ASCII碼
%d, %i: 顯示十進制整數(shù)
%e, %E: 顯示科學計數(shù)法數(shù)值
%f :顯示為浮點數(shù),小數(shù) %5.1f,帶整數(shù)、小數(shù)點、整數(shù)共5位,小數(shù)1位,不夠用空格補上
%g, %G :以科學計數(shù)法或浮點形式顯示數(shù)值
%s :顯示字符串;例:%5s最少5個字符,不夠用空格補上,超過5個還繼續(xù)顯示
%u :無符號整數(shù)
%%: 顯示% 自身
(3)修飾符:放在%c[/d/e/f…]之間
#[.#]:第一個數(shù)字控制顯示的寬度;第二個# 表示小數(shù)點后精度,%5.1f
-:左對齊(默認右對齊) %-15s
+:顯示數(shù)值的正負符號 %+d
4.4.2 演示
[root@along ~]# awk -F: '{print $1,$3}' /etc/passwd
root 0
bin 1
---第一列顯示小于20的字符串;第2列顯示整數(shù)并換行
[root@along ~]# awk -F: '{printf "%20s---%u\n",$1,$3}' /etc/passwd
root---0
bin---1
---使用-進行左對齊;第2列顯示浮點數(shù)
[root@along ~]# awk -F: '{printf "%-20s---%-10.3f\n",$1,$3}' /etc/passwd
root ---0.000
bin ---1.000
---使用printf做表格
[root@along ~]# awk -F: 'BEGIN{printf "username userid\n-----------------------------\n"}{printf "%-20s|%-10.3f\n",$1,$3}' /etc/passwd
username userid
-----------------------------
root |0.000
bin |1.000
4.5 操作符
4.5.1 格式

4.5.2 演示
(1)模式匹配符
---查詢以/dev開頭的磁盤信息
[root@along ~]# df -h |awk -F: '$0 ~ /^\/dev/'
/dev/mapper/cl-root 17G 7.3G 9.7G 43% /
/dev/sda1 1014M 121M 894M 12% /boot
---只顯示磁盤使用狀況和磁盤名
[root@along ~]# df -h |awk '$0 ~ /^\/dev/{print $(NF-1)"---"$1}'
43%---/dev/mapper/cl-root
12%---/dev/sda1
---查找磁盤大于40%的
[root@along ~]# df -h |awk '$0 ~ /^\/dev/{print $(NF-1)"---"$1}' |awk -F% '$1 > 40'
43%---/dev/mapper/cl-root
(2)邏輯操作符
[root@along ~]# awk -F: '$3>=0 && $3<=1000 {print $1,$3}' /etc/passwd
root 0
bin 1
[root@along ~]# awk -F: '$3==0 || $3>=1000 {print $1}' /etc/passwd
root
[root@along ~]# awk -F: '!($3==0) {print $1}' /etc/passwd
bin
[root@along ~]# awk -F: '!($0 ~ /bash$/) {print $1,$3}' /etc/passwd
bin 1
daemon 2
(3)條件表達式(三目表達式)
[root@along ~]# awk -F: '{$3 >= 1000?usertype="common user":usertype="sysadmin user";print usertype,$1,$3}' /etc/passwd
sysadmin user root 0
common user along 1000
4.6 awk PATTERN 匹配部分
4.6.1 格式
PATTERN:根據(jù)pattern 條件,過濾匹配的行,再做處理
(1)如果未指定:空模式,匹配每一行
(2)/regular expression/ :僅處理能夠模式匹配到的行,正則,需要用/ / 括起來
(3)relational expression:關(guān)系表達式,結(jié)果為“真”才會被處理
真:結(jié)果為非0值,非空字符串
假:結(jié)果為空字符串或0值
(4)line ranges:行范圍
startline(起始行),endline(結(jié)束行):/pat1/,/pat2/ 不支持直接給出數(shù)字,可以有多段,中間可以有間隔
(5)BEGIN/END 模式
BEGIN{}: 僅在開始處理文件中的文本之前執(zhí)行一次
END{} :僅在文本處理完成之后執(zhí)行
4.6.2 演示
[root@along ~]# awk -F: '{print $1}' awkdemo
hello
linux
along
[root@along ~]# awk -F: '/along/{print $1}' awkdemo
along
[root@along ~]# awk -F: '1{print $1}' awkdemo
hello
linux
along
[root@along ~]# awk -F: '0{print $1}' awkdemo
[root@along ~]# awk -F: '/^h/,/^a/{print $1}' awkdemo
hello
linux
along
[root@along ~]# awk -F: 'BEGIN{print "第一列"}{print $1} END{print "結(jié)束"}' awkdemo
第一列
hello
linux
along
結(jié)束
4.7 awk有意思的案例
[root@along ~]# seq 10
1
2
3
4
5
6
7
8
9
10
---因為i=0,為假,所以不打印
[root@along ~]# seq 10 |awk 'i=0'
---i=1,為真,所以全部打印
[root@along ~]# seq 10 |awk 'i=1'
1
2
3
4
5
6
7
8
9
10
---只打印奇數(shù)行;奇數(shù)行i進入時本身為空,被賦為!i,即不為空,所以打印;偶數(shù)行i進入時本身不為空,被賦為!i,即為空,所以不打印
[root@along ~]# seq 10 |awk 'i=!i'
1
3
5
7
9
---解釋上一個操作,i在奇偶行的值
[root@along ~]# seq 10 |awk '{i=!i;print i}'
1
0
1
0
1
0
1
0
1
0
---只打印偶數(shù)行,是上邊打印奇數(shù)行的取反
[root@along ~]# seq 10 |awk '!(i=!i)'
2
4
6
8
10
---只打印偶數(shù)行;先對i進行賦值,即不為空,剛好和打印奇數(shù)行相反
[root@along ~]# seq 10 |awk -v i=1 'i=!i'
2
4
6
8
10
5、awk高階用法
5.1 awk控制語句—if-else判斷
(1)語法
if(condition){statement;…}[else statement] 雙分支
if(condition1){statement1}else if(condition2){statement2}else{statement3} 多分支
(2)使用場景:對awk 取得的整行或某個字段做條件判斷
(3)演示
[root@along ~]# awk -F: '{if($3>10 && $3<1000)print $1,$3}' /etc/passwd
operator 11
games 1
[root@along ~]# awk -F: '{if($NF=="/bin/bash") print $1,$NF}' /etc/passwd
root /bin/bash
along /bin/bash
---輸出總列數(shù)大于3的行
[root@along ~]# awk -F: '{if(NF>2) print $0}' awkdemo
linux:redhat:lalala:hahaha
along:love:you
---第3列>=1000為Common user,反之是root or Sysuser
[root@along ~]# awk -F: '{if($3>=1000) {printf "Common user: %s\n",$1} else{printf "root or Sysuser: %s\n",$1}}' /etc/passwd
root or Sysuser: root
root or Sysuser: bin
Common user: along
---磁盤利用率超過40的設(shè)備名和利用率
[root@along ~]# df -h|awk -F% '/^\/dev/{print $1}'|awk '$NF > 40{print $1,$NF}'
/dev/mapper/cl-root 43
---test=100和>90為very good; 90>test>60為good; test<60為no pass
[root@along ~]# awk 'BEGIN{ test=100;if(test>90){print "very good"}else if(test>60){ print "good"}else{print "no pass"}}'
very good
[root@along ~]# awk 'BEGIN{ test=80;if(test>90){print "very good"}else if(test>60){ print "good"}else{print "no pass"}}'
good
[root@along ~]# awk 'BEGIN{ test=50;if(test>90){print "very good"}else if(test>60){ print "good"}else{print "no pass"}}'
no pass
5.2 awk控制語句—while循環(huán)
(1)語法
while(condition){statement;…}
注:條件“真”,進入循環(huán);條件“假”, 退出循環(huán)
(2)使用場景
對一行內(nèi)的多個字段逐一類似處理時使用
對數(shù)組中的各元素逐一處理時使用
(3)演示
---以along開頭的行,以:為分隔,顯示每一行的每個單詞和其長度
[root@along ~]# awk -F: '/^along/{i=1;while(i<=NF){print $i,length($i); i++}}' awkdemo
along 5
love 4
you 3
---以:為分隔,顯示每一行的長度大于6的單詞和其長度
[root@along ~]# awk -F: '{i=1;while(i<=NF) {if(length($i)>=6){print $i,length($i)}; i++}}' awkdemo
redhat 6
lalala 6
hahaha 6
---計算1+2+3+...+100=5050
[root@along ~]# awk 'BEGIN{i=1;sum=0;while(i<=100){sum+=i;i++};print sum}'
5050
5.3 awk控制語句—do-while循環(huán)
(1)語法
do {statement;…}while(condition)
意義:無論真假,至少執(zhí)行一次循環(huán)體
(2)計算1+2+3+…+100=5050
[root@along ~]# awk 'BEGIN{sum=0;i=1;do{sum+=i;i++}while(i<=100);print sum}'
5050
5.4 awk控制語句—for循環(huán)
(1)語法
for(expr1;expr2;expr3) {statement;…}
(2)特殊用法:遍歷數(shù)組中的元素
for(var in array) {for-body}
(3)演示
---顯示每一行的每個單詞和其長度
[root@along ~]# awk -F: '{for(i=1;i<=NF;i++) {print$i,length($i)}}' awkdemo
hello 5
world 5
linux 5
redhat 6
lalala 6
hahaha 6
along 5
love 4
you 3
---求男m、女f各自的平均
[root@along ~]# cat sort.txt
xiaoming m 90
xiaohong f 93
xiaohei m 80
xiaofang f 99
[root@along ~]# awk '{m[$2]++;score[$2]+=$3}END{for(i in m){printf "%s:%6.2f\n",i,score[i]/m[i]}}' sort.txt
m: 85.00
f: 96.00
5.5 和shell腳本中較相似的控制語句
5.5.1 switch語句
和shell中的case很像,就不在演示了
switch(expression) {case VALUE1 or /REGEXP/:statement1; case VALUE2 or /REGEXP2/: statement2;...; default: statementn}
5.5.2 break和continue
---奇數(shù)相加
[root@along ~]# awk 'BEGIN{sum=0;for(i=1;i<=100;i++){if(i%2==0)continue;sum+=i}print sum}'
2500
---1+2+...+66
[root@along ~]# awk 'BEGIN{sum=0;for(i=1;i<=100;i++){if(i==66)break;sum+=i}print sum}'
2145
5.5.3 next
next:提前結(jié)束對本行處理而直接進入下一行處理(awk 自身循環(huán))
---只打印偶數(shù)行
[root@along ~]# awk -F: '{if(NR%2!=0) next; print $1,$3}' /etc/passwd
bin 1
adm 3
5.6 awk數(shù)組
5.6.1 關(guān)聯(lián)數(shù)組:array[index-expression]
(1)可使用任意字符串;字符串要使用雙引號括起來
(2)如果某數(shù)組元素事先不存在,在引用時,awk 會自動創(chuàng)建此元素,并將其值初始化為“空串”
(3)若要判斷數(shù)組中是否存在某元素,要使用“index in array”格式進行遍歷
(4)若要遍歷數(shù)組中的每個元素,要使用for 循環(huán):for(var in array) {for-body}
5.6.2 演示
(1)awk使用數(shù)組
[root@along ~]# cat awkdemo2
aaa
bbbb
aaa
123
123
123
---去除重復的行
[root@along ~]# awk '!arr[$0]++' awkdemo2
aaa
bbbb
123
---打印文件內(nèi)容,和該行重復第幾次出現(xiàn)
[root@along ~]# awk '{!arr[$0]++;print $0,arr[$0]}' awkdemo2
aaa 1
bbbb 1
aaa 2
123 1
123 2
123 3
分析:把每行作為下標,第一次進來,相當于print ias…一樣結(jié)果為空,打印空,!取反結(jié)果為1,打印本行,并且++變?yōu)椴豢眨麓芜M來相同的行就是相同的下標,本來上次的值,!取反為空,不打印,++變?yōu)椴豢眨悦看沃貜瓦M來的行都不打印
(2)數(shù)組遍歷
[root@along ~]# awk 'BEGIN{abc["ceo"]="along";abc["coo"]="mayun";abc["cto"]="mahuateng";for(i in abc){print i,abc[i]}}'
coo mayun
ceo along
cto mahuateng
[root@along ~]# awk '{for(i=1;i<=NF;i++)abc[$i]++}END{for(j in abc)print j,abc[j]}' awkdemo2
aaa 2
bbbb 1
123 3
5.6.3 數(shù)值\字符串處理
(1)數(shù)值處理
rand():返回0和1之間一個隨機數(shù),需有個種子 srand(),沒有種子,一直輸出0.237788
演示:
[root@along ~]# awk 'BEGIN{print rand()}'
0.237788
[root@along ~]# awk 'BEGIN{srand(); print rand()}'
0.51692
[root@along ~]# awk 'BEGIN{srand(); print rand()}'
0.189917
---取0-50隨機數(shù)
[root@along ~]# awk 'BEGIN{srand(); print int(rand()*100%50)+1}'
12
[root@along ~]# awk 'BEGIN{srand(); print int(rand()*100%50)+1}'
24
(2)字符串處理:
length([s]) :返回指定字符串的長度
sub(r,s,[t]) :對t 字符串進行搜索r 表示的模式匹配的內(nèi)容,并將第一個匹配的內(nèi)容替換為s
gsub(r,s,[t]) :對t 字符串進行搜索r 表示的模式匹配的內(nèi)容,并全部替換為s 所表示的內(nèi)容
plit(s,array,[r]) :以r 為分隔符,切割字符串s ,并將切割后的結(jié)果保存至array 所表示的數(shù)組中,第一個索引值為1, 第二個索引值為2,…
演示:
[root@along ~]# echo "2008:08:08 08:08:08" | awk 'sub(/:/,"-",$1)'
2008-08:08 08:08:08
[root@along ~]# echo "2008:08:08 08:08:08" | awk 'gsub(/:/,"-",$0)'
2008-08-08 08-08-08
[root@along ~]# echo "2008:08:08 08:08:08" | awk '{split($0,i,":")}END{for(n in i){print n,i[n]}}'
4 08
5 08
1 2008
2 08
3 08 08
5.7 awk自定義函數(shù)
(1)格式:和bash區(qū)別:定義函數(shù)()中需加參數(shù),return返回值不是$?,是相當于echo輸出
function name ( parameter, parameter, ... ) {
statements
return expression
}
(2)演示
[root@along ~]# cat fun.awk
function max(v1,v2) {
v1>v2?var=v1:var=v2
return var
}
BEGIN{a=3;b=2;print max(a,b)}
[root@along ~]# awk -f fun.awk
3
5.8 awk中調(diào)用shell 命令
(1)system 命令
空格是awk 中的字符串連接符,如果system中需要使用awk中的變量可以使用空格分隔,或者說除了awk 的變量外其他一律用"" 引用 起來。
[root@along ~]# awk BEGIN'{system("hostname") }'
along
[root@along ~]# awk 'BEGIN{name="along";system("echo "name)}' 注:"echo " echo后有空格
along
[root@along ~]# awk 'BEGIN{score=100; system("echo your score is " score) }'
your score is 100
(2)awk 腳本
將awk 程序?qū)懗赡_本,直接調(diào)用或執(zhí)行
示例:
[root@along ~]# cat f1.awk
{if($3>=1000)print $1,$3}
[root@along ~]# cat f2.awk
#!/bin/awk -f
{if($3 >= 1000)print $1,$3}
[root@along ~]# chmod +x f2.awk
[root@along ~]# ./f2.awk -F: /etc/passwd
along 1000
(3)向awk腳本傳遞參數(shù)
① 格式:
awkfile var=value var2=value2... Inputfile
注意 :在BEGIN 過程 中不可用。直到 首行輸入完成以后,變量才可用 。可以通過-v 參數(shù),讓awk 在執(zhí)行BEGIN 之前得到變量的值。命令行中每一個指定的變量都需要一個-v
② 示例
[root@along ~]# cat test.awk
#!/bin/awk -f
{if($3 >=min && $3<=max)print $1,$3}
[root@along ~]# chmod +x test.awk
[root@along ~]# ./test.awk -F: min=100 max=200 /etc/passwd
systemd-network 192
6、grep awk sed對比
grep 主要用于搜索某些字符串;
sed,awk 用于處理文本 ;
grep基本是以行為單位處理文本的; 而awk可以做更細分的處理,通過指定分隔符將一行(一條記錄)劃分為多個字段,以字段為單位處理文本。awk中支持C語法,可以有分支條件判斷、循環(huán)語句等,相當于一個小型編程語言。
awk功能比較多是一個編程語言了。 grep功能簡單,就是一個簡單的正則表達式的匹配。 awk的功能依賴于grep。
grep可以理解為主要作用是在一個文件中查找過濾需要的內(nèi)容。awk不是過濾查找,而是文本處理工具,是把一個文件處理成你想要的格式。
AWK的功能是什么?與sed和grep很相似,awk是一種樣式掃描與處理工具。但其功能卻大大強于sed和grep。awk提供了極其強大的功能:它幾乎可以完成grep和sed所能完成的全部工作,同時,它還可以可以進行樣式裝入、流控制、數(shù)學運算符、進程控制語句甚至于內(nèi)置的變量和函數(shù)。它具備了一個完整的語言所應具有的幾乎所有精美特性。實際上,awk的確擁有自己的語言:awk程序設(shè)計語言,awk的三位創(chuàng)建者已將它正式定義為:樣式掃描和處理語言。 使用awk的第一個理由是基于文本的樣式掃描和處理是我們經(jīng)常做的工作,awk所做的工作有些象數(shù)據(jù)庫,但與數(shù)據(jù)庫不同的是,它處理的是文本文件,這些文件沒有專門的存儲格式,普通的人們就能編輯、閱讀、理解和處理它們。而數(shù)據(jù)庫文件往往具有特殊的存儲格式,這使得它們必須用數(shù)據(jù)庫處理程序來處理它們。既然這種類似于數(shù)據(jù)庫的處理工作我們經(jīng)常會遇到,我們就應當找到處理它們的簡便易行的方法,UNIX有很多這方面的工具,例如sed 、grep、sort以及find等等,awk是其中十分優(yōu)秀的一種。
使用awk的第二個理由是awk是一個簡單的工具,當然這是相對于其強大的功能來說的。的確,UNIX有許多優(yōu)秀的工具,例如UNIX天然的開發(fā)工具C語言及其延續(xù)C++就非常的優(yōu)秀。但相對于它們來說,awk完成同樣的功能要方便和簡捷得多。這首先是因為awk提供了適應多種需要的解決方案:從解決簡單問題的awk命令行到復雜而精巧的awk程序設(shè)計語言,這樣做的好處是,你可以不必用復雜的方法去解決本來很簡單的問題。例如,你可以用一個命令行解決簡單的問題,而C不行,即使一個再簡單的程序,C語言也必須經(jīng)過編寫、編譯的全過程。其次,awk本身是解釋執(zhí)行的,這就使得awk程序不必經(jīng)過編譯的過程,同時,這也使得它與shell script程序能夠很好的契合。最后,awk本身較C語言簡單,雖然awk吸收了C語言很多優(yōu)秀的成分,熟悉C語言會對學習awk有很大的幫助,但awk本身不須要會使用C語言——一種功能強大但需要大量時間學習才能掌握其技巧的開發(fā)工具。
使用awk的第三個理由是awk是一個容易獲得的工具。與C和C++語言不同,awk只有一個文件(/bin/awk),而且?guī)缀趺總€版本的UNIX都提供各自版本的awk,你完全不必費心去想如何獲得awk。但C語言卻不是這樣,雖然C語言是UNIX天然的開發(fā)工具,但這個開發(fā)工具卻是單獨發(fā)行的,換言之,你必須為你的UNIX版本的C語言開發(fā)工具單獨付費(當然使用D版者除外),獲得并安裝它,然后你才可以使用它。
基于以上理由,再加上awk強大的功能,我們有理由說,如果你要處理與文本樣式掃描相關(guān)的工作,awk應該是你的第一選擇。在這里有一個可遵循的一般原則:如果你用普通的shell工具或shell script有困難的話,試試awk,如果awk仍不能解決問題,則便用C語言,如果C語言仍然失敗,則移至C++。
sed是一個非交互性文本流編輯器。它編輯文件或標準輸入導出的文本拷貝。sed編輯器按照一次處理 一行的方式來處理文件(或者輸入)并把輸出送到屏幕上。你可以在vi和ex/ed編輯器里識別他的命令。sed把當前正在處理的行保存在一個臨時緩存里,這個緩存叫做模式空間。一但sed完成了對模式空間里的行的處理(即對該行執(zhí)行sed命令),就把模式空間的行送到屏幕上(除非該命令要刪除該行活禁止打印)。處理完該行之后,從模式空間里刪除它,然后把下一行讀入模式空間,進行處理,并顯示。當輸入文件的最后一行處理完后,sed終止。通過把每一行存在一個臨時緩存里并編輯該行,初始文件不會被修改或被破壞。
來源:https://www.cnblogs.com/along21/p/10366886.html
推薦閱讀
