
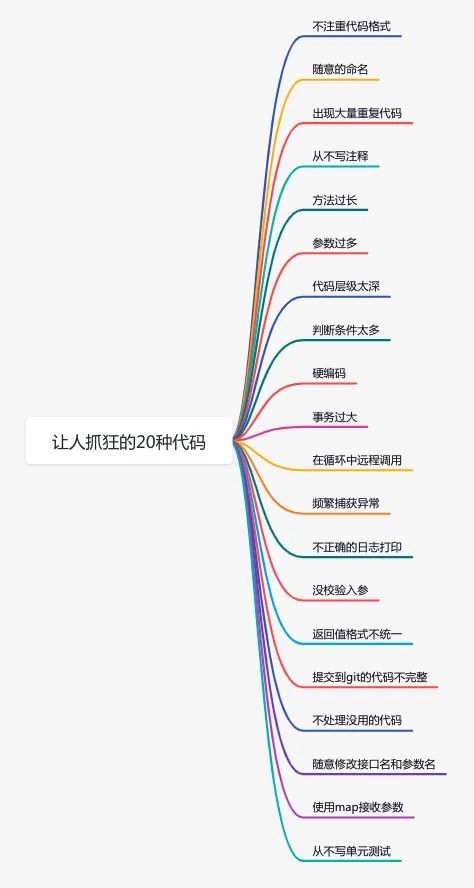
如何寫出讓人抓狂的代碼?
大家好,我是魚皮,今天跟大家分享一篇有趣的文章(作者是我三哥):如何寫出讓人抓狂的代碼?
剛看到這個(gè)標(biāo)題,你可能覺得這篇文章可能是一篇水文(起初我也這么以為)。但看完之后,我很負(fù)責(zé)的告訴你,它是一篇有很多干貨的技術(shù)文。
曾幾何時(shí),你在閱讀別人代碼的時(shí)候,有沒有抓狂,想生氣,想發(fā)火的時(shí)候?
今天就跟大家一起聊聊,這20種我看了會(huì)抓狂的代碼,看看你中招了沒?
1.不注重代碼格式
代碼格式說起來很虛,下面我用幾個(gè)案例演示一下,不注重代碼格式的效果。作為這篇文章的開胃小菜吧。
1.1 空格
有時(shí)候必要的空格沒有加,比如:
@Service
@Slf4j
public class TestService1{
public void test1(){
addLog("test1");
if (condition1){
if (condition2){
if (condition3){
log.info("info:{}",info);
}
}
}
}
}
你看了這段代碼有何感想,有沒有血壓飆升的感覺?
代碼好像揉到一起去了。
那么,如何把血壓降下來呢?
答:加上空格即可。
正解:
@Service
@Slf4j
public class TestService1 {
public void test1() {
addLog("test1");
if (condition1) {
if (condition2) {
if (condition3) {
log.info("info:{}", info);
}
}
}
}
}
只加了一些空格,稍微調(diào)整了一下,這段代碼的層次結(jié)構(gòu)一下子變得非常清晰了。
好吧,我又冷靜下來了。
1.2 換行
寫代碼時(shí),如果有些必要的換行沒有加,可能會(huì)出現(xiàn)這樣的代碼:
public void update(User user) {
if (null != user.getId()) {
User oldUser = userMapper.findUserById(user.getId());
if(null == oldUser)throw new RuntimeException("用戶id不存在");
oldUser.setName(user.getName());oldUser.setAge(user.getAge());oldUser.setAddress(user.getAddress());
userMapper.updateUser(oldUser);
} else { userMapper.insertUser(user);
}
}
看了這段代碼,是不是有點(diǎn)生無可戀的感覺?
簡(jiǎn)單的加點(diǎn)空格優(yōu)化一下:
public void update(User user) {
if (null != user.getId()) {
User oldUser = userMapper.findUserById(user.getId());
if(null == oldUser) {
throw new RuntimeException("用戶id不存在");
}
oldUser.setName(user.getName());
oldUser.setAge(user.getAge());
oldUser.setAddress(user.getAddress());
userMapper.updateUser(oldUser);
} else {
userMapper.insertUser(user);
}
}
代碼邏輯一下子變得清晰了許多。
2.隨意的命名
java中沒有強(qiáng)制規(guī)定參數(shù)、方法、類或者包名該怎么起名。但如果我們沒有養(yǎng)成良好的起名習(xí)慣,隨意起名的話,可能會(huì)出現(xiàn)很多奇怪的代碼。
2.1 有意義的參數(shù)名
有時(shí)候,我們寫代碼時(shí)為了省事(可以少敲幾個(gè)字母),參數(shù)名起得越簡(jiǎn)單越好。假如同事A寫的代碼如下:
int a = 1;
int b = 2;
String c = "abc";
boolean b = false;
一段時(shí)間之后,同事A離職了,同事B接手了這段代碼。
他此時(shí)一臉懵逼,a是什么意思,b又是什么意思,還有c...然后心里一萬個(gè)草泥馬。
給參數(shù)起一個(gè)有意義的名字,是非常重要的事情,避免給自己或者別人埋坑。
正解:
int supplierCount = 1;
int purchaserCount = 2;
String userName = "abc";
boolean hasSuccess = false;
2.2 見名知意
光起有意義的參數(shù)名還不夠,我們不能就這點(diǎn)追求。我們起的參數(shù)名稱最好能夠見名知意,不然就會(huì)出現(xiàn)這樣的情況:
String yongHuMing = "蘇三";
String 用戶Name = "蘇三";
String su3 = "蘇三";
String suThree = "蘇三";
這幾種參數(shù)名看起來是不是有點(diǎn)怪怪的?
為啥不定義成國際上通用的(地球人都能看懂)英文單詞呢?
String userName = "蘇三";
String susan = "蘇三";
上面的這兩個(gè)參數(shù)名,基本上大家都能看懂,減少了好多溝通成本。
所以建議在定義不管是參數(shù)名、方法名、類名時(shí),優(yōu)先使用國際上通用的英文單詞,更簡(jiǎn)單直觀,減少溝通成本。少用漢子、拼音,或者數(shù)字定義名稱。
2.3 參數(shù)名風(fēng)格一致
參數(shù)名其實(shí)有多種風(fēng)格,列如:
//字母全小寫
int suppliercount = 1;
//字母全大寫
int SUPPLIERCOUNT = 1;
//小寫字母 + 下劃線
int supplier_count = 1;
//大寫字母 + 下劃線
int SUPPLIER_COUNT = 1;
//駝峰標(biāo)識(shí)
int supplierCount = 1;
如果某個(gè)類中定義了多種風(fēng)格的參數(shù)名稱,看起來是不是有點(diǎn)雜亂無章?
所以建議類的成員變量、局部變量和方法參數(shù)使用supplierCount,這種駝峰風(fēng)格,即:第一個(gè)字母小寫,后面的每個(gè)單詞首字母大寫。例如:
int supplierCount = 1;
此外,為了好做區(qū)分,靜態(tài)常量建議使用SUPPLIER_COUNT,即:大寫字母 + 下劃線分隔的參數(shù)名。例如:
private static final int SUPPLIER_COUNT = 1;
3.出現(xiàn)大量重復(fù)代碼
ctrl + c 和 ctrl + v可能是程序員使用最多的快捷鍵了。
沒錯(cuò),我們是大自然的搬運(yùn)工。哈哈哈。
在項(xiàng)目初期,我們使用這種工作模式,確實(shí)可以提高一些工作效率,可以少寫(實(shí)際上是少敲)很多代碼。
但它帶來的問題是:會(huì)出現(xiàn)大量的代碼重復(fù)。例如:
@Service
@Slf4j
public class TestService1 {
public void test1() {
addLog("test1");
}
private void addLog(String info) {
if (log.isInfoEnabled()) {
log.info("info:{}", info);
}
}
}
@Service
@Slf4j
public class TestService2 {
public void test2() {
addLog("test2");
}
private void addLog(String info) {
if (log.isInfoEnabled()) {
log.info("info:{}", info);
}
}
}
@Service
@Slf4j
public class TestService3 {
public void test3() {
addLog("test3");
}
private void addLog(String info) {
if (log.isInfoEnabled()) {
log.info("info:{}", info);
}
}
}
在TestService1、TestService2、TestService3類中,都有一個(gè)addLog方法用于添加日志。
本來該功能用得好好的,直到有一天,線上出現(xiàn)了一個(gè)事故:服務(wù)器磁盤滿了。
原因是打印的日志太多,記了很多沒必要的日志,比如:查詢接口的所有返回值,大對(duì)象的具體打印等。
沒辦法,只能將addLog方法改成只記錄debug日志。
于是乎,你需要全文搜索,addLog方法去修改,改成如下代碼:
private void addLog(String info) {
if (log.isDebugEnabled()) {
log.debug("debug:{}", info);
}
}
這里是有三個(gè)類中需要修改這段代碼,但如果實(shí)際工作中有三十個(gè)、三百個(gè)類需要修改,會(huì)讓你非常痛苦。改錯(cuò)了,或者改漏了,都會(huì)埋下隱患,把自己坑了。
為何不把這種功能的代碼提取出來,放到某個(gè)工具類中呢?
@Slf4j
public class LogUtil {
private LogUtil() {
throw new RuntimeException("初始化失敗");
}
public static void addLog(String info) {
if (log.isDebugEnabled()) {
log.debug("debug:{}", info);
}
}
}
然后,在其他的地方,只需要調(diào)用。
@Service
@Slf4j
public class TestService1 {
public void test1() {
LogUtil.addLog("test1");
}
}
如果哪天addLog的邏輯又要改了,只需要修改LogUtil類的addLog方法即可。你可以自信滿滿的修改,不需要再小心翼翼了。
我們寫的代碼,絕大多數(shù)是可維護(hù)性的代碼,而非一次性的。所以,建議在寫代碼的過程中,如果出現(xiàn)重復(fù)的代碼,盡量提取成公共方法。千萬別因?yàn)轫?xiàng)目初期一時(shí)的爽快,而給項(xiàng)目埋下隱患,后面的維護(hù)成本可能會(huì)非常高。
4.從不寫注釋
有時(shí)候,在項(xiàng)目時(shí)間比較緊張時(shí),很多人為了快速開發(fā)完功能,在寫代碼時(shí),經(jīng)常不喜歡寫注釋。
此外,還有些技術(shù)書中說過:好的代碼,不用寫注釋,因?yàn)?code style="font-size: 14px;padding: 2px 4px;border-radius: 4px;margin-right: 2px;margin-left: 2px;background-color: rgba(27, 31, 35, 0.05);font-family: "Operator Mono", Consolas, Monaco, Menlo, monospace;word-break: break-all;color: rgb(40, 202, 113);">代碼即注釋。這也給那些不喜歡寫代碼注釋的人,找了一個(gè)合理的理由。
但我個(gè)人覺得,在國內(nèi)每個(gè)程序員的英文水平都不一樣,思維方式和編碼習(xí)慣也有很大區(qū)別。你要把前人某些復(fù)雜的代碼邏輯真正搞懂,可能需要花費(fèi)大量的時(shí)間。
我們看到spring的核心方法refresh,也是加了很多注釋的:
public void refresh() throws BeansException, IllegalStateException {
synchronized (this.startupShutdownMonitor) {
// Prepare this context for refreshing.
prepareRefresh();
// Tell the subclass to refresh the internal bean factory.
ConfigurableListableBeanFactory beanFactory = obtainFreshBeanFactory();
// Prepare the bean factory for use in this context.
prepareBeanFactory(beanFactory);
try {
// Allows post-processing of the bean factory in context subclasses.
postProcessBeanFactory(beanFactory);
// Invoke factory processors registered as beans in the context.
invokeBeanFactoryPostProcessors(beanFactory);
// Register bean processors that intercept bean creation.
registerBeanPostProcessors(beanFactory);
// Initialize message source for this context.
initMessageSource();
// Initialize event multicaster for this context.
initApplicationEventMulticaster();
// Initialize other special beans in specific context subclasses.
onRefresh();
// Check for listener beans and register them.
registerListeners();
// Instantiate all remaining (non-lazy-init) singletons.
finishBeanFactoryInitialization(beanFactory);
// Last step: publish corresponding event.
finishRefresh();
}
catch (BeansException ex) {
if (logger.isWarnEnabled()) {
logger.warn("Exception encountered during context initialization - " +
"cancelling refresh attempt: " + ex);
}
// Destroy already created singletons to avoid dangling resources.
destroyBeans();
// Reset 'active' flag.
cancelRefresh(ex);
// Propagate exception to caller.
throw ex;
}
finally {
// Reset common introspection caches in Spring's core, since we
// might not ever need metadata for singleton beans anymore...
resetCommonCaches();
}
}
}
如果你寫的代碼完全不寫注釋,可能最近一個(gè)月、三個(gè)月、半年還記得其中的邏輯。但一年、兩年,甚至更久的時(shí)間之后,你確定還能想起當(dāng)初的邏輯,而不需要花費(fèi)大量的時(shí)間去重新看自己的代碼梳理邏輯?
說實(shí)話,不寫注釋,到了項(xiàng)目后期,不光是把自己坑了,還會(huì)坑隊(duì)友。
為什么把這一條單獨(dú)拿出來?
因?yàn)槲矣龅竭^,接過鍋,被坑慘了。
5.方法過長(zhǎng)
我們平時(shí)在寫代碼時(shí),有時(shí)候思路來了,一氣呵成,很快就把功能開發(fā)完了。但也可能會(huì)帶來一個(gè)小問題,就是方法過長(zhǎng)。
偽代碼如下:
public void run() {
List<User> userList = userMapper.getAll();
//經(jīng)過一系列的數(shù)據(jù)過濾
//此處省略了50行代碼
List<User> updateList = //最終獲取到user集合
if(CollectionUtils.isEmpty(updateList)) {
return;
}
for(User user: updateList) {
//經(jīng)過一些復(fù)雜的過期時(shí)間計(jì)算
//此處省略30行代碼
}
//分頁更新用戶的過期時(shí)間
//此處省略20行代碼
//發(fā)mq消息通知用戶
//此處省略30行代碼
}
上面的run方法中包含了多種業(yè)務(wù)邏輯,雖說確實(shí)能夠?qū)崿F(xiàn)完整的業(yè)務(wù)功能,但卻不能稱之為好。
為什么呢?
答:該方法總長(zhǎng)度超過150行,里面的代碼邏輯很雜亂,包含了很多關(guān)聯(lián)性不大的代碼塊。該方法的職責(zé)太不單一了,非常不利于代碼復(fù)用和后期的維護(hù)。
那么,如何優(yōu)化呢?
答:做方法拆分,即把一個(gè)大方法拆分成多個(gè)小方法。
例如:
public void run() {
List<User> userList = userMapper.getAll();
List<User> updateList = filterUser(userList);
if(CollectionUtils.isEmpty(updateList)) {
return;
}
for(User user: updateList) {
clacExpireDay(user);
}
updateUser(updateList);
sendMq(updateList);
}
private List<User> filterUser(List<User> userList) {
//經(jīng)過一系列的數(shù)據(jù)過濾
//此處省略了50行代碼
List<User> updateList = //最終獲取到user集合
return updateList;
}
private void clacExpireDay(User user) {
//經(jīng)過一些復(fù)雜的過期時(shí)間計(jì)算
//此處省略30行代碼
}
private void updateUser(List<User> updateList) {
//分頁更新用戶的過期時(shí)間
//此處省略20行代碼
}
private void sendMq(List<User> updateList) {
//發(fā)mq消息通知用戶
//此處省略30行代碼
}
這樣簡(jiǎn)單的優(yōu)化之后,run方法的代碼邏輯一下子變得清晰了許多,光看它調(diào)用的子方法的名字,都能猜到這些字方法是干什么的。
每個(gè)子方法只專注于自己的事情,別的事情交給其他方法處理,職責(zé)更單一了。
此外,如果此時(shí)業(yè)務(wù)上有一個(gè)新功能,也需要給用戶發(fā)消息,那么上面定義的sendMq方法就能被直接調(diào)用了。豈不是爽歪歪?
換句話說,把大方法按功能模塊拆分成N個(gè)小方法,更有利于代碼的復(fù)用。
順便說一句,Hotspot對(duì)字節(jié)碼超過8000字節(jié)的大方法有JIT編譯限制,超過了限制不會(huì)被編譯。
6.參數(shù)過多
我們平常在定義某個(gè)方法時(shí),可能并沒注意參數(shù)個(gè)數(shù)的問題(其實(shí)是我猜的)。我的建議是方法的參數(shù)不要超過5個(gè)。
先一起看看下面的例子:
public void fun(String a,
String b,
String c,
String d,
String e,
String f) {
...
}
public void client() {
fun("a","b","c","d",null,"f");
}
上面的fun方法中定義了6個(gè)參數(shù),這樣在調(diào)用該方面的所有地方都需要思考一下,這些參數(shù)該怎么傳值,哪些參數(shù)可以為空,哪些參數(shù)不能為空。
方法的入?yún)⑻啵矔?huì)導(dǎo)致該方法的職責(zé)不單一,方法存在風(fēng)險(xiǎn)的概率更大。
那么,如何優(yōu)化參數(shù)過多問題呢?
答:可以將一部分參數(shù)遷移到新方法中。
這個(gè)例子中,可以把參數(shù)d,e,f遷移到otherFun方法。例如:
public Result fun(String a,
String b,
String c) {
...
return result;
}
public void otherFun(Result result,
String d,
String e,
String f) {
...
}
public void client() {
Result result = fun("a","b","c");
otherFun(result, "d", null, "f");
}
這樣優(yōu)化之后,每個(gè)方法的邏輯更單一一些,更有利于方法的復(fù)用。
如果fun中還需要返回參數(shù)a、b、c,給下個(gè)方法繼續(xù)使用,那么代碼可以改為:
public Result fun(String a,
String b,
String c) {
...
Result result = new Result();
result.setA(a);
result.setB(b);
result.setC(c);
return result;
}
在給Result對(duì)象賦值時(shí),這里有個(gè)小技巧,可以使用lombok的@Builder注解,做成鏈?zhǔn)秸{(diào)用。例如:
@NoArgsConstructor
@AllArgsConstructor
@Builder
@Data
public class Result {
private String a;
private String b;
private String c;
}
這樣在調(diào)用的地方,可以這樣賦值:
Result result = Result.builder()
.a("a").b("b").c("c")
.build();
非常直觀明了。
此時(shí),有人可能會(huì)說,ThreadPoolExecutor不也提供了7個(gè)參數(shù)的方法?
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
...
}
沒錯(cuò),不過它是構(gòu)造方法,我們這里主要討論的是普通方法。
7.代碼層級(jí)太深
不知道你有沒有見過類似這樣的代碼:
if (a == 1) {
if(b == 2) {
if(c == 3) {
if(d == 4) {
if(e == 5) {
...
}
...
}
...
}
...
}
...
}
這段代碼中有很多層if判斷,是不是看得人有點(diǎn)眼花繚亂?
有同感的同學(xué),請(qǐng)舉個(gè)手。
如果你沒啥感覺,那么接著往下看:
for(int i=0; i<100;i++) {
for(int j=0; j<50;j++) {
for(int m=0; m<200;m++) {
for(int n=0; n<100;n++) {
for(int k=0; k<50; k++) {
...
}
}
}
}
}
看了這段代碼,你心中可能會(huì)一緊。這么多循環(huán),代碼的性能真的好嗎?
這兩個(gè)例子中的代碼都犯了同一個(gè)錯(cuò)誤,即:代碼層級(jí)太深。
代碼層級(jí)太深導(dǎo)致的問題是代碼變得非常不好維護(hù),不容易理清邏輯,有時(shí)候代碼的性能也可能因此變差。
那么關(guān)鍵問題來了,如何解決代碼層級(jí)較深的問題呢?
對(duì)于if判斷層級(jí)比較多的情況:
if(a!=1) {
...
return;
}
doConditionB();
private void doConditionB() {
if(b!=2) {
...
return;
}
doConditionC();
}
把不滿足條件(a==1)的邏輯先執(zhí)行,先返回。再把滿足條件(a==1)的邏輯單獨(dú)抽取到一個(gè)方法(doConditionB)中。該doConditionB中也會(huì)把不滿足條件(b==2)的邏輯先執(zhí)行,先返回。再把滿足條件(b==2)的邏輯單獨(dú)抽取到一個(gè)方法(doConditionC)中。后面邏輯以此類推。
這種做法是面向防御式編程的一種,即先把不滿足條件的代碼先執(zhí)行,然后才執(zhí)行滿足條件的代碼。此外別忘了,把滿足條件的代碼抽取到一個(gè)新的方法中喔。
對(duì)于for循環(huán)層級(jí)太深的優(yōu)化方案,一般推薦使用map。
例如:
for(Order order:orderList) {
for(OrderDetail detail: detailList) {
if(order.getId().equals(detail.getOrderId())) {
doSamething();
}
}
}
使用map優(yōu)化之后:
Map<Long, List<OrderDetail>> detailMap = detailList.stream().collect(Collectors.groupingBy(OrderDetail::getOrderId));
for(Order order:orderList) {
List<OrderDetail> detailList = detailMap.get(order.getId());
if(CollectionUtils.isNotEmpty) {
doSamething();
}
}
這個(gè)例子中使用map,少了一層循環(huán),代碼效率提升一些。但不是所有的for循環(huán)都能用map替代,要根據(jù)自己實(shí)際情況選擇。
代碼層級(jí)太深,還有其他的場(chǎng)景,比如:方法中return的次數(shù)太多,也會(huì)降低代碼的可讀性。
這種情況,其實(shí)也可能通過面向防御式編程進(jìn)行代碼優(yōu)化。
8.判斷條件太多
我們?cè)趯懘a的時(shí)候,判斷條件是必不可少的。不同的判斷條件,走的代碼邏輯通常會(huì)不一樣。
廢話不多說,先看看下面的代碼。
public interface IPay {
void pay();
}
@Service
public class AliaPay implements IPay {
@Override
public void pay() {
System.out.println("===發(fā)起支付寶支付===");
}
}
@Service
public class WeixinPay implements IPay {
@Override
public void pay() {
System.out.println("===發(fā)起微信支付===");
}
}
@Service
public class JingDongPay implements IPay {
@Override
public void pay() {
System.out.println("===發(fā)起京東支付===");
}
}
@Service
public class PayService {
@Autowired
private AliaPay aliaPay;
@Autowired
private WeixinPay weixinPay;
@Autowired
private JingDongPay jingDongPay;
public void toPay(String code) {
if ("alia".equals(code)) {
aliaPay.pay();
} elseif ("weixin".equals(code)) {
weixinPay.pay();
} elseif ("jingdong".equals(code)) {
jingDongPay.pay();
} else {
System.out.println("找不到支付方式");
}
}
}
PayService類的toPay方法主要是為了發(fā)起支付,根據(jù)不同的code,決定調(diào)用用不同的支付類(比如:aliaPay)的pay方法進(jìn)行支付。
這段代碼有什么問題呢?也許有些人就是這么干的。
試想一下,如果支付方式越來越多,比如:又加了百度支付、美團(tuán)支付、銀聯(lián)支付等等,就需要改toPay方法的代碼,增加新的else...if判斷,判斷多了就會(huì)導(dǎo)致邏輯越來越多?
很明顯,這里違法了設(shè)計(jì)模式六大原則的:開閉原則 和 單一職責(zé)原則。
開閉原則:對(duì)擴(kuò)展開放,對(duì)修改關(guān)閉。就是說增加新功能要盡量少改動(dòng)已有代碼。
單一職責(zé)原則:顧名思義,要求邏輯盡量單一,不要太復(fù)雜,便于復(fù)用。
那么,如何優(yōu)化if...else判斷呢?
答:使用 策略模式+工廠模式。
策略模式定義了一組算法,把它們一個(gè)個(gè)封裝起來, 并且使它們可相互替換。工廠模式用于封裝和管理對(duì)象的創(chuàng)建,是一種創(chuàng)建型模式。
public interface IPay {
void pay();
}
@Service
public class AliaPay implements IPay {
@PostConstruct
public void init() {
PayStrategyFactory.register("aliaPay", this);
}
@Override
public void pay() {
System.out.println("===發(fā)起支付寶支付===");
}
}
@Service
public class WeixinPay implements IPay {
@PostConstruct
public void init() {
PayStrategyFactory.register("weixinPay", this);
}
@Override
public void pay() {
System.out.println("===發(fā)起微信支付===");
}
}
@Service
public class JingDongPay implements IPay {
@PostConstruct
public void init() {
PayStrategyFactory.register("jingDongPay", this);
}
@Override
public void pay() {
System.out.println("===發(fā)起京東支付===");
}
}
public class PayStrategyFactory {
private static Map<String, IPay> PAY_REGISTERS = new HashMap<>();
public static void register(String code, IPay iPay) {
if (null != code && !"".equals(code)) {
PAY_REGISTERS.put(code, iPay);
}
}
public static IPay get(String code) {
return PAY_REGISTERS.get(code);
}
}
@Service
public class PayService3 {
public void toPay(String code) {
PayStrategyFactory.get(code).pay();
}
}
這段代碼的關(guān)鍵是PayStrategyFactory類,它是一個(gè)策略工廠,里面定義了一個(gè)全局的map,在所有IPay的實(shí)現(xiàn)類中注冊(cè)當(dāng)前實(shí)例到map中,然后在調(diào)用的地方通過PayStrategyFactory類根據(jù)code從map獲取支付類實(shí)例即可。
如果加了一個(gè)新的支付方式,只需新加一個(gè)類實(shí)現(xiàn)IPay接口,定義init方法,并且重寫pay方法即可,其他代碼基本上可以不用動(dòng)。
當(dāng)然,消除又臭又長(zhǎng)的if...else判斷,還有很多方法,比如:使用注解、動(dòng)態(tài)拼接類名稱、模板方法、枚舉等等。由于篇幅有限,在這里我就不過多介紹了,更詳細(xì)的內(nèi)容可以看看我的另一篇文章《消除if...else是9條錦囊妙計(jì)》
9.硬編碼
不知道你有沒有遇到過這類需求:
限制批量訂單上傳接口,一次性只能上傳200條數(shù)據(jù)。 在job中分頁查詢用戶,一頁查詢100個(gè)用戶,然后計(jì)算用戶的等級(jí)。
上面例子中的200條數(shù)據(jù)和100個(gè)用戶,很容易硬編碼,即在代碼中把參數(shù)寫死了。
我們以上傳200條數(shù)據(jù)為例:
private static final int MAX_LIMIT = 200;
public void upload(List<Order> orderList) {
if(CollectionUtils.isEmpty(orderList)) {
throw new BusinessException("訂單不能為空");
}
if(orderList.size() > MAX_LIMIT) {
throw new BusinessException("超過單次請(qǐng)求的數(shù)量限制");
}
}
其中MAX_LIMIT被定義成了靜態(tài)常量。
上線之后,你發(fā)現(xiàn)上傳歷史數(shù)據(jù)時(shí)速度太慢了,需要把限制調(diào)大一點(diǎn)。
我擦。。。這種小小的參數(shù)改動(dòng),還需要改源代碼,重新編譯,重新打包,重新部署。。。
但如果你當(dāng)初把這些公共參數(shù),設(shè)置成可配置的,例如:
@Value("${com.susan.maxLimit:200}")
private int maxLimit = 200;
public void upload(List<Order> orderList) {
if(CollectionUtils.isEmpty(orderList)) {
throw new BusinessException("訂單不能為空");
}
if(orderList.size() > maxLimit) {
throw new BusinessException("超過單次請(qǐng)求的數(shù)量限制");
}
}
這樣只需在配置中心(比如:apollo、nocas等)中修改一下配置即可,不用修改源代碼,不用重新編譯,不用重新打包,不用重新部署。
一個(gè)字:爽。
我們?cè)谇捌陂_發(fā)的時(shí)候,寧可多花一分鐘思考一下,這個(gè)參數(shù)后面是否會(huì)被修改,是否可以定義成可配置的參數(shù)。也比后期修改代碼,重新編譯,重新打包,重新上線花的時(shí)間少得多。
10.事務(wù)過大
我們平時(shí)在使用spring框架開發(fā)項(xiàng)目時(shí),喜歡用@Transactional注解聲明事務(wù)。例如:
@Transactional(rollbackFor = Throwable.class)
public void updateUser(User user) {
System.out.println("update");
}
只需在需要使用事務(wù)的方法上,使用@Transactional注解聲明一下,該方法通過AOP就自動(dòng)擁有了事務(wù)的功能。
沒錯(cuò),這種做法給我們帶來了極大的便利,開發(fā)效率更高了。
但也給我們帶來了很多隱患,比如大事務(wù)的問題。我們一起看看下面的這段代碼:
@Transactional(rollbackFor = Throwable.class)
public void updateUser(User user) {
User oldUser = userMapper.getUserById(user.getId());
if(null != oldUser) {
userMapper.update(user);
} else {
userMapper.insert(user);
}
sendMq(user);
}
這段代碼中g(shù)etUserById方法和sendMq方法,在這個(gè)案例中無需使用事務(wù),只有update或insert方法才需要事務(wù)。
所以上面這段代碼的事務(wù)太大了,是整個(gè)方法級(jí)別的事務(wù)。假如sendMq方法是一個(gè)非常耗時(shí)的操作,則可能會(huì)導(dǎo)致整個(gè)updateUser方法的事務(wù)超時(shí),從而出現(xiàn)大事務(wù)問題。
那么,如何解決這個(gè)問題呢?
答:可以使用TransactionTemplate的編程式事務(wù)優(yōu)化代碼。
@Autowired
private TransactionTemplate transactionTemplate;
....
public void updateUser(User user) {
User oldUser = userMapper.getUserById(user.getId());
transactionTemplate.execute((status) => {
if(null != oldUser) {
userMapper.update(user);
} else {
userMapper.insert(user);
}
return Boolean.TRUE;
})
sendMq(user);
}
只有在execute方法中的代碼塊才真正需要事務(wù),其余的方法,可以非事務(wù)執(zhí)行,這樣就能縮小事務(wù)的范圍,避免大事務(wù)。
當(dāng)然使用TransactionTemplate這種編程式事務(wù),縮小事務(wù)范圍,來解決大事務(wù)問題,只是其中一種手段。
如果你想對(duì)大事務(wù)問題,有更深入的了解,可以看看我的另一篇文章《讓人頭痛的大事務(wù)問題到底要如何解決?》
11.在循環(huán)中遠(yuǎn)程調(diào)用
有時(shí)候,我們需要在某個(gè)接口中,遠(yuǎn)程調(diào)用第三方的某個(gè)接口。
比如:在注冊(cè)企業(yè)時(shí),需要調(diào)用天眼查接口,查一下該企業(yè)的名稱和統(tǒng)一社會(huì)信用代碼是否正確。
這時(shí)候在企業(yè)注冊(cè)接口中,不得不先調(diào)用天眼查接口校驗(yàn)數(shù)據(jù)。如果校驗(yàn)失敗,則直接返回。如果校驗(yàn)成功,才允許注冊(cè)。
如果只是一個(gè)企業(yè)還好,但如果某個(gè)請(qǐng)求有10個(gè)企業(yè)需要注冊(cè),是不是要在企業(yè)注冊(cè)接口中,循環(huán)調(diào)用10次天眼查接口才能判斷所有企業(yè)是否正常呢?
public void register(List<Corp> corpList) {
for(Corp corp: corpList) {
CorpInfo info = tianyanchaService.query(corp);
if(null == info) {
throw new RuntimeException("企業(yè)名稱或統(tǒng)一社會(huì)信用代碼不正確");
}
}
doRegister(corpList);
}
這樣做可以,但會(huì)導(dǎo)致整個(gè)企業(yè)注冊(cè)接口性能很差,極容易出現(xiàn)接口超時(shí)問題。
那么,如何解決這類在循環(huán)中調(diào)用遠(yuǎn)程接口的問題呢?
11.1 批量操作
遠(yuǎn)程接口支持批量操作,比如天眼查支持一次性查詢多個(gè)企業(yè)的數(shù)據(jù),這樣就無需在循環(huán)中查詢?cè)摻涌诹恕?/p>
但實(shí)際場(chǎng)景中,有些第三方不愿意提供第三方接口。
11.2 并發(fā)操作
java8以后通過CompleteFuture類,實(shí)現(xiàn)多個(gè)線程查天眼查接口,并且把查詢結(jié)果統(tǒng)一匯總到一起。
具體用法我就不展開了,有興趣的朋友可以看看我的另一篇文章《聊聊接口性能優(yōu)化的11個(gè)小技巧》
12.頻繁捕獲異常
通常情況下,為了在程序中拋出異常時(shí),任然能夠繼續(xù)運(yùn)行,不至于中斷整個(gè)程序,我們可以選擇手動(dòng)捕獲異常。例如:
public void run() {
try {
doSameThing();
} catch (Exception e) {
//ignore
}
doOtherThing();
}
這段代碼可以手動(dòng)捕獲異常,保證即使doSameThing方法出現(xiàn)了異常,run方法也能繼續(xù)執(zhí)行完。
但有些場(chǎng)景下,手動(dòng)捕獲異常被濫用了。
12.1 濫用場(chǎng)景1
不知道你在打印異常日志時(shí),有沒有寫過類似這樣的代碼:
public void run() throws Exception {
try {
doSameThing();
} catch (Exception e) {
log.error(e.getMessage(), e);
throw e;
}
doOtherThing();
}
通過try/catch關(guān)鍵字,手動(dòng)捕獲異常的目的,僅僅是為了記錄錯(cuò)誤日志,在接下來的代碼中,還是會(huì)把該異常拋出。
在每個(gè)拋出異常的地方,都捕獲一下異常,打印日志。
12.2 濫用場(chǎng)景2
在寫controller層接口方法時(shí),為了保證接口有統(tǒng)一的返回值,你有沒有寫過類似這樣的代碼:
@PostMapping("/query")
public List<User> query(@RequestBody List<Long> ids) {
try {
List<User> userList = userService.query(ids);
return Result.ok(userList);
} catch (Exception e) {
log.error(e.getMessage(), e);
return Result.fature(500, "服務(wù)器內(nèi)部錯(cuò)誤");
}
}
在每個(gè)controller層的接口方法中,都加上了上面這種捕獲異常的邏輯。
上述兩種場(chǎng)景中,頻繁的捕獲異常,會(huì)讓代碼性能降低,因?yàn)椴东@異常是會(huì)消耗性能的。
此外,這么多重復(fù)的捕獲異常代碼,看得讓人頭疼。
其實(shí),我們還有更好的選擇。在網(wǎng)關(guān)層(比如:zuul或gateway),有個(gè)統(tǒng)一的異常處理代碼,既可以打印異常日志,也能統(tǒng)一封裝接口返回值,這樣可以減少很多異常被濫用的情況。
13.不正確的日志打印
在我們寫代碼的時(shí)候,打印日志是必不可少的工作之一。
因?yàn)槿罩究梢詭臀覀兛焖俣ㄎ粏栴},判斷代碼當(dāng)時(shí)真正的執(zhí)行邏輯。
但打印日志的時(shí)候也需要注意,不是說任何時(shí)候都要打印日志,比如:
@PostMapping("/query")
public List<User> query(@RequestBody List<Long> ids) {
log.info("request params:{}", ids);
List<User> userList = userService.query(ids);
log.info("response:{}", userList);
return userList;
}
對(duì)于有些查詢接口,在日志中打印出了請(qǐng)求參數(shù)和接口返回值。
咋一看沒啥問題。
但如果ids中傳入值非常多,比如有1000個(gè)。而該接口被調(diào)用的頻次又很高,一下子就會(huì)打印大量的日志,用不了多久就可能把磁盤空間打滿。
如果真的想打印這些日志該怎么辦?
@PostMapping("/query")
public List<User> query(@RequestBody List<Long> ids) {
if (log.isDebugEnabled()) {
log.debug("request params:{}", ids);
}
List<User> userList = userService.query(ids);
if (log.isDebugEnabled()) {
log.debug("response:{}", userList);
}
return userList;
}
使用isDebugEnabled判斷一下,如果當(dāng)前的日志級(jí)別是debug才打印日志。生產(chǎn)環(huán)境默認(rèn)日志級(jí)別是info,在有些緊急情況下,把某個(gè)接口或者方法的日志級(jí)別改成debug,打印完我們需要的日志后,又調(diào)整回去。
方便我們定位問題,又不會(huì)產(chǎn)生大量的垃圾日志,一舉兩得。
14.沒校驗(yàn)入?yún)?/span>
參數(shù)校驗(yàn)是接口必不可少的功能之一,一般情況下,提供給第三方調(diào)用的接口,需要做嚴(yán)格的參數(shù)校驗(yàn)。
以前我們是這樣校驗(yàn)參數(shù)的:
@PostMapping("/add")
public void add(@RequestBody User user) {
if(StringUtils.isEmpty(user.getName())) {
throw new RuntimeException("name不能為空");
}
if(null != user.getAge()) {
throw new RuntimeException("age不能為空");
}
if(StringUtils.isEmpty(user.getAddress())) {
throw new RuntimeException("address不能為空");
}
userService.add(user);
}
需要手動(dòng)寫校驗(yàn)的代碼,如果作為入?yún)⒌膶?shí)體中字段非常多,光是寫校驗(yàn)的代碼,都需要花費(fèi)大量的時(shí)間。而且這些校驗(yàn)代碼,很多都是重復(fù)的,會(huì)讓人覺得惡心。
好消息是使用了hibernate的參數(shù)校驗(yàn)框架validate之后,參數(shù)校驗(yàn)一下子變得簡(jiǎn)單多了。
我們只需要校驗(yàn)的實(shí)體類User中使用validation框架的相關(guān)注解,比如:@NotEmpty、@NotNull等,定義需要校驗(yàn)的字段即可。
@NoArgsConstructor
@AllArgsConstructor
@Data
public class User {
private Long id;
@NotEmpty
private String name;
@NotNull
private Integer age;
@NotEmpty
private String address;
}
然后在controller類上加上@Validated注解,在接口方法上加上@Valid注解。
@Slf4j
@Validated
@RestController
@RequestMapping("/user")
public class UserController {
@Autowired
private UserService userService;
@PostMapping("/add")
public void add(@RequestBody @Valid User user) {
userService.add(user);
}
}
這樣就能自動(dòng)實(shí)現(xiàn)參數(shù)校驗(yàn)的功能。
然而,現(xiàn)在需求改了,需要在User類上增加了一個(gè)參數(shù)Role,它也是必填字段,并且它的roleName和tag字段都不能為空。
但如果我們?cè)谛r?yàn)參數(shù)時(shí),不小心把代碼寫成這樣:
@NoArgsConstructor
@AllArgsConstructor
@Data
public class User {
private Long id;
@NotEmpty
private String name;
@NotNull
private Integer age;
@NotEmpty
private String address;
@NotNull
private Role role;
}
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Role {
@NotEmpty
private String roleName;
@NotEmpty
private String tag;
}
結(jié)果就悲劇了。
你心里可能還樂呵呵的認(rèn)為寫的代碼不錯(cuò),但實(shí)際情況是,roleName和tag字段根本不會(huì)被校驗(yàn)到。
如果傳入?yún)?shù):
{
"name": "tom",
"age":1,
"address":"123",
"role":{}
}
即使role字段傳入的是空對(duì)象,但該接口也會(huì)返回成功。
那么如何解決這個(gè)問題呢?
@NoArgsConstructor
@AllArgsConstructor
@Data
public class User {
private Long id;
@NotEmpty
private String name;
@NotNull
private Integer age;
@NotEmpty
private String address;
@NotNull
@Valid
private Role role;
}
需要在Role字段上也加上@Valid注解。
溫馨的提醒一聲,使用validate框架校驗(yàn)參數(shù)一定要自測(cè),因?yàn)楹苋菀撞瓤印?/p>
15.返回值格式不統(tǒng)一
我之前對(duì)接某個(gè)第三方時(shí),他們有部分接口的返回值結(jié)構(gòu)是這樣的:
{
"ret":0,
"message":null,
"data":[]
}
另一部分接口的返回值結(jié)構(gòu)是這樣的:
{
"code":0,
"msg":null,
"success":true,
"result":[]
}
整得我有點(diǎn)懵逼。
為啥沒有一個(gè)統(tǒng)一的返回值?
我需要給他們的接口寫兩套返回值解析的代碼,后面其他人看到了這些代碼,可能也會(huì)心生疑問,為什么有兩種不同的返回值解析?
唯一的解釋是一些接口是新項(xiàng)目的,另外一些接口是老項(xiàng)目的。
但如果不管是新項(xiàng)目,還是老項(xiàng)目,如果都有一個(gè)統(tǒng)一的對(duì)外網(wǎng)關(guān)服務(wù),由這個(gè)服務(wù)進(jìn)行鑒權(quán)和統(tǒng)一封裝返回值。
{
"code":0,
"message":null,
"data":[]
}
就不會(huì)有返回值結(jié)構(gòu)不一致的問題。
溫馨的提醒一下,業(yè)務(wù)服務(wù)不要捕獲異常,直接把異常拋給網(wǎng)關(guān)服務(wù),由它來統(tǒng)一全局捕獲異常,這樣就能統(tǒng)一異常的返回值結(jié)構(gòu)。
16.提交到git的代碼不完整
我們寫完代碼之后,把代碼提交到gitlab上,也有一些講究。
最最忌諱的是代碼還沒有寫完,因?yàn)橼s時(shí)間(著急下班),就用git把代碼提交了。例如:
public void test() {
String userName="蘇三";
String password=
}
這段代碼中的password變量都沒有定義好,項(xiàng)目一運(yùn)行起來必定報(bào)錯(cuò)。
這種錯(cuò)誤的代碼提交方式,一般是新手會(huì)犯。但還有另一種情況,就是在多個(gè)分支merge代碼的時(shí)候,有時(shí)候會(huì)出問題,merge之后的代碼不能正常運(yùn)行,就被提交了。
好的習(xí)慣是:用git提交代碼之前,一定要在本地運(yùn)行一下,確保項(xiàng)目能正常啟動(dòng)才能提交。
寧可不提交代碼到遠(yuǎn)程倉庫,切勿因?yàn)橐粫r(shí)趕時(shí)間,提交了不完整的代碼,導(dǎo)致團(tuán)隊(duì)的隊(duì)友們項(xiàng)目都啟動(dòng)不了。
17.不處理沒用的代碼
有些時(shí)候,我們?yōu)榱送祽校瑢?duì)有些沒用的代碼不做任何處理。
比如:
@Slf4j
@Service
public class UserService {
@Autowired
private UserMapper userMapper;
public void add(User user) {
System.out.println("add");
}
public void update(User user) {
System.out.println("update");
}
public void query(User user) {
System.out.println("query");
}
}
本來UserService類中的add、update、query方法都在用的。后來,某些功能砍掉了,現(xiàn)在只有add方法真正在用。
某一天,項(xiàng)目組來了一個(gè)新人,接到需求需要在user表加一個(gè)字段,這時(shí)候他是不是要把a(bǔ)dd、update、query方法都仔細(xì)看一遍,評(píng)估一下影響范圍?
后來發(fā)現(xiàn)只有add方法需要改,他心想前面的開發(fā)者為什么不把沒用的代碼刪掉,或者標(biāo)記出來呢?
在java中可以使用@Deprecated表示這個(gè)類或者方法沒在使用了,例如:
@Slf4j
@Service
public class UserService {
@Autowired
private UserMapper userMapper;
public void add(User user) {
System.out.println("add");
}
@Deprecated
public void update(User user) {
System.out.println("update");
}
@Deprecated
public void query(User user) {
System.out.println("query");
}
}
我們?cè)陂喿x代碼時(shí),可以先忽略標(biāo)記了@Deprecated注解的方法。這樣一個(gè)看似簡(jiǎn)單的舉手之勞,可以給自己,或者接手該代碼的人,節(jié)省很多重復(fù)查代碼的時(shí)間。
建議我們把沒用的代碼優(yōu)先刪除掉,因?yàn)間itlab中是有歷史記錄的,可以找回。但如果有些為了兼容調(diào)用方老版本的代碼,不能刪除的情況,建議使用
@Deprecated注解相關(guān)類或者接口。
18.隨意修改接口名和參數(shù)名
不知道你有沒有遇到過這種場(chǎng)景:你寫了一個(gè)接口,本來以為沒人使用,后來覺得接口名或參數(shù)名不對(duì),偷偷把它們改了。比如:
@PostMapping("/query")
public List<User> query(@RequestBody List<Long> ids) {
return userService.query(ids);
}
接口名改了:
@PostMapping("/queryUser")
public List<User> queryUser(@RequestBody List<Long> ids) {
return userService.query(ids);
}
結(jié)果導(dǎo)致其他人的功能報(bào)錯(cuò),原來他已經(jīng)在調(diào)用該接口了。
大意了。。。
所以在修改接口名、參數(shù)名、修改參數(shù)類型、修改參數(shù)個(gè)數(shù)時(shí),一定要先詢問一下相關(guān)同事,有沒有使用該接口,免得以后出現(xiàn)不必要的麻煩。
對(duì)于已經(jīng)在線上使用的接口,盡量不要修改接口名、參數(shù)名、修改參數(shù)類型、修改參數(shù)個(gè)數(shù),還有請(qǐng)求方式,比如:get改成post等。寧可新加一個(gè)接口,也盡量不要影響線上功能。
19.使用map接收參數(shù)
我之前見過有些小伙伴,在代碼中使用map接收參數(shù)的。例如:
@PostMapping("/map")
public void map(@RequestBody Map<String, Object> mapParam){
System.out.println(mapParam);
}
在map方法中使用mapParam對(duì)象接收參數(shù),這種做法確實(shí)很方便,可以接收多種json格式的數(shù)據(jù)。
例如:
{
"id":123,
"name":"蘇三",
"age":18,
"address":"成都"
}
或者:
{
"id":123,
"name":"蘇三",
"age":18,
"address":"成都",
"role": {
"roleName":"角色",
"tag":"t1"
}
}
這段代碼可以毫不費(fèi)勁的接收這兩種格式的參數(shù),so cool。
但同時(shí)也帶來了一個(gè)問題,那就是:參數(shù)的數(shù)據(jù)結(jié)構(gòu)你沒法控制,有可能你知道調(diào)用者傳的json數(shù)據(jù)格式是第一種,還是第二種。但如果你沒有寫好注釋,其他的同事看到這段代碼,可能會(huì)一臉懵逼,map接收的參數(shù)到底是什么東東?
項(xiàng)目后期,這樣的代碼變得非常不好維護(hù)。有些同學(xué)接手前人的代碼,時(shí)不時(shí)吐槽一下,是有原因的。
那么,如果優(yōu)化這種代碼呢?
我們應(yīng)該使用有明確含義的對(duì)象去接收參數(shù),例如:
@PostMapping("/add")
public void add(@RequestBody @Valid User user){
System.out.println(user);
}
其中的User對(duì)象是我們已經(jīng)定義好的對(duì)象,就不會(huì)存在什么歧義了。
20.從不寫單元測(cè)試
因?yàn)轫?xiàng)目時(shí)間實(shí)在太緊了,系統(tǒng)功能都開發(fā)不完,更何況是單元測(cè)試呢?
大部分人不寫單元測(cè)試的原因,可能也是這個(gè)吧。
但我想告訴你的是,不寫單元測(cè)試并不是個(gè)好習(xí)慣。
我見過有些編程高手是測(cè)試驅(qū)動(dòng)開發(fā),他們會(huì)先把單元測(cè)試寫好,再寫具體的業(yè)務(wù)邏輯。
那么,我們?yōu)槭裁匆獙憜卧獪y(cè)試呢?
我們寫的代碼大多數(shù)是可維護(hù)的代碼,很有可能在未來的某一天需要被重構(gòu)。試想一下,如果有些業(yè)務(wù)邏輯非常復(fù)雜,你敢輕易重構(gòu)不?如果有單元測(cè)試就不一樣了,每次重構(gòu)完,跑一次單元測(cè)試,就知道新寫的代碼有沒有問題。
我們新寫的對(duì)外接口,測(cè)試同學(xué)不可能完全知道邏輯,只有開發(fā)自己最清楚。不像頁面功能,可以在頁面上操作。他們?cè)跍y(cè)試接口時(shí),很有可能覆蓋不到位,很多bug測(cè)不出來。
建議由于項(xiàng)目時(shí)間非常緊張,在開發(fā)時(shí)確實(shí)沒有寫單元測(cè)試,但在項(xiàng)目后期的空閑時(shí)間也建議補(bǔ)上。
本文結(jié)合自己的實(shí)際工作經(jīng)驗(yàn),用調(diào)侃的方式,介紹了在編寫代碼的過程中,不太好的地方和一些優(yōu)化技巧,給用需要的朋友們一個(gè)參考。
大家千萬別再寫爛代碼了!
作者:

往期推薦