
救火分享:記一次 K8s 控制平面排障的血淚經(jīng)歷!

集群以及環(huán)境信息的信息:
k8s v1.18.4
3 節(jié)點 Master 均為 8核 16G,50Gi-SSD
差異化配置的 19 節(jié)點 Minion
control-plane 組件 (kube-apiserver,etcd,kube-controller-manager,kube-scheduler) 以 static-pod 的模式進行部署
3 個 kube-apiserver 前端有一個 VIP 進行流量的 LoadBalance
騰訊云的 SSD 性能大概是 130MB/s
故障描述
在2021-9-10下午“詭異”的事情開始出現(xiàn):kubectl 偶爾卡住無法正常 CRUDW 標準資源 (Pod, Node 等),此時已經(jīng)意識到是部分的 kube-apiserver 無法正常工作,然后嘗試分別接入 3 臺 kube-apiserver 所在宿主機,發(fā)現(xiàn)以下不正常的情況:
現(xiàn)場的信息
k8s control-plane kube-apiserver Pod 信息:
$ kubectl get pods -n kube-system kube-apiserver-x.x.x.x -o yaml...containerStatuses:- containerID: docker://xxxxx....lastState:terminated:containerID: docker://yyyyexitCode: 137finishedAt: "2021-09-10T09:29:02Z"reason: OOMKilledstartedAt: "2020-12-09T07:02:23Z"name: kube-apiserverready: truerestartCount: 1started: truestate:running:startedAt: "2021-09-10T09:29:08Z"...
9月10日,kube-apiserver 因為 OOM 被 Kill 過。
周邊監(jiān)控
IaaS 層提供監(jiān)控信息 (control-plane 所在宿主的黑盒監(jiān)控信息):
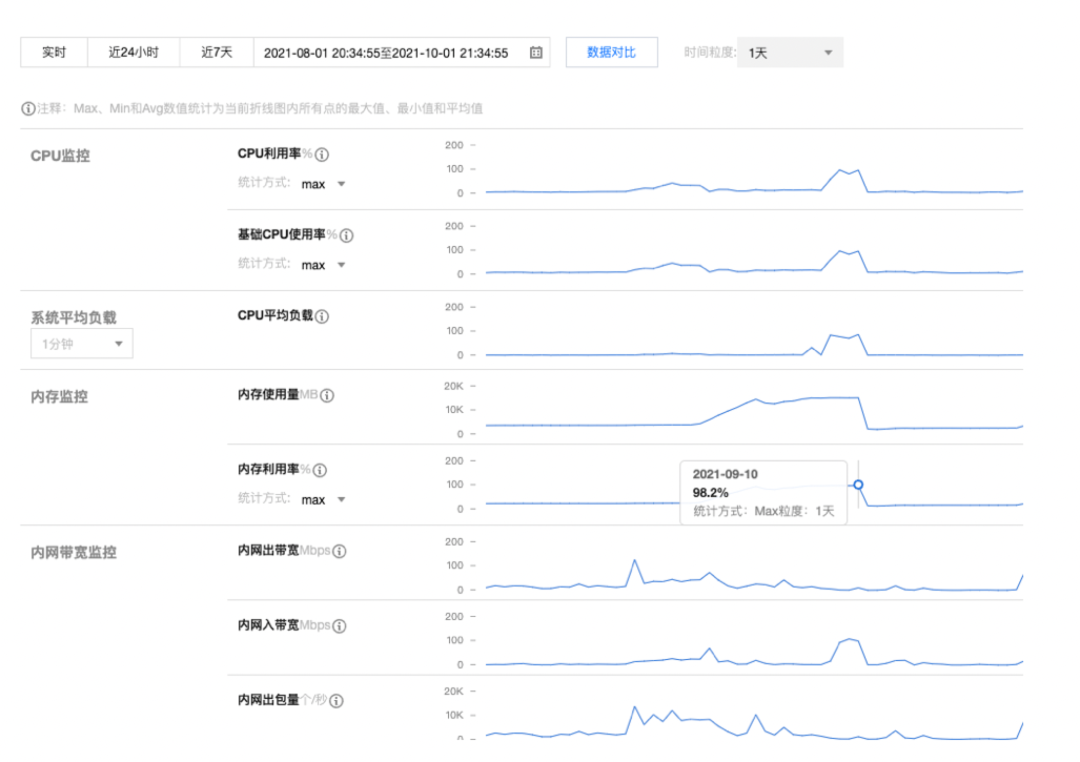
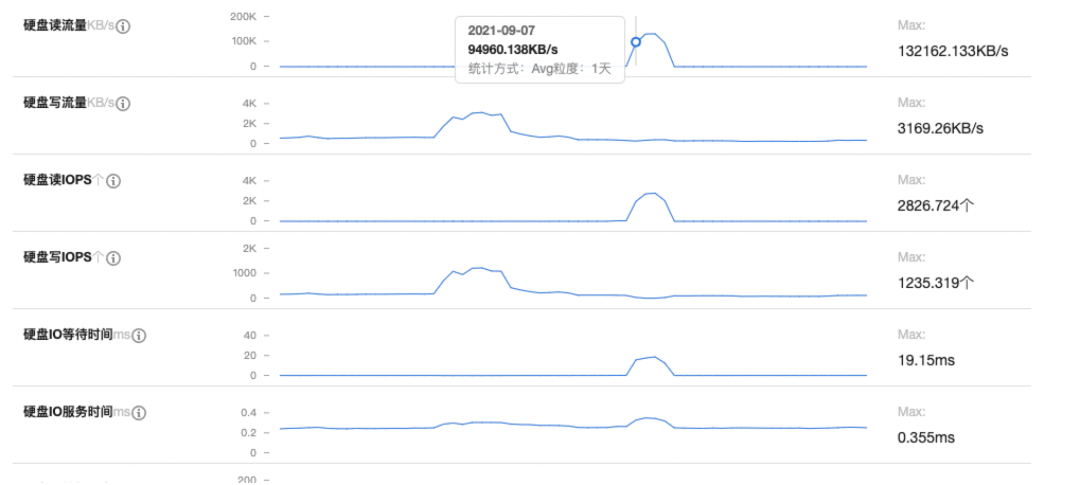
有效信息:
內(nèi)存、CPU、讀取磁盤呈現(xiàn)正相關(guān),并且在9月10日開始明顯下降各方面指標回歸正常
Kube-apiserver Prometheus 的監(jiān)控信息:
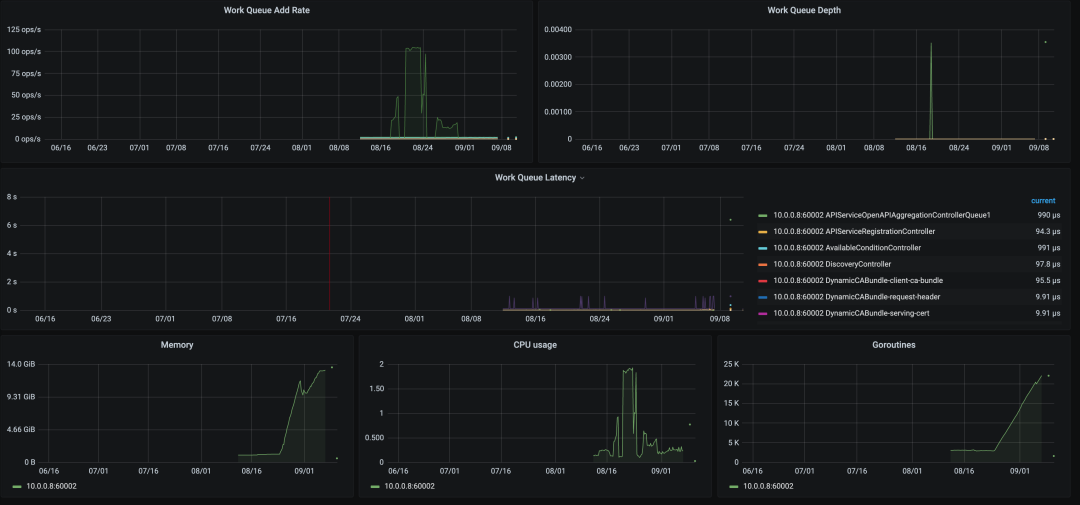
有效信息:
- kube-apiserver 的 IO 出現(xiàn)了問題,Prometheus 在中途的某段事件無法正常的刮取 kube-apiserver 的 metrics 指標
- kube-apiserver 占用的內(nèi)存單調(diào)遞增,內(nèi)部 workqueue 的?
ADD?iops 很高
實時的 Debug 信息
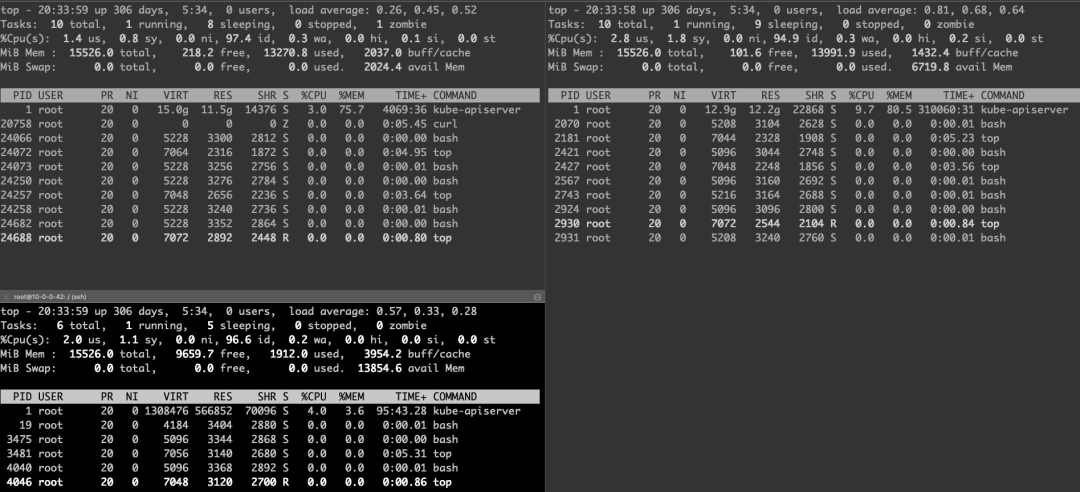
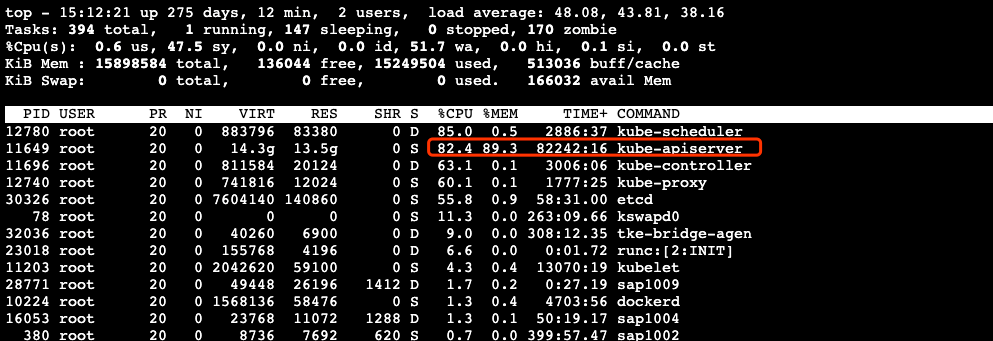
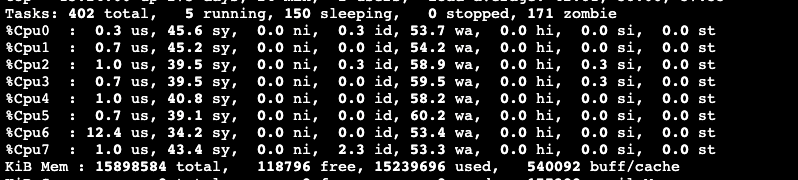
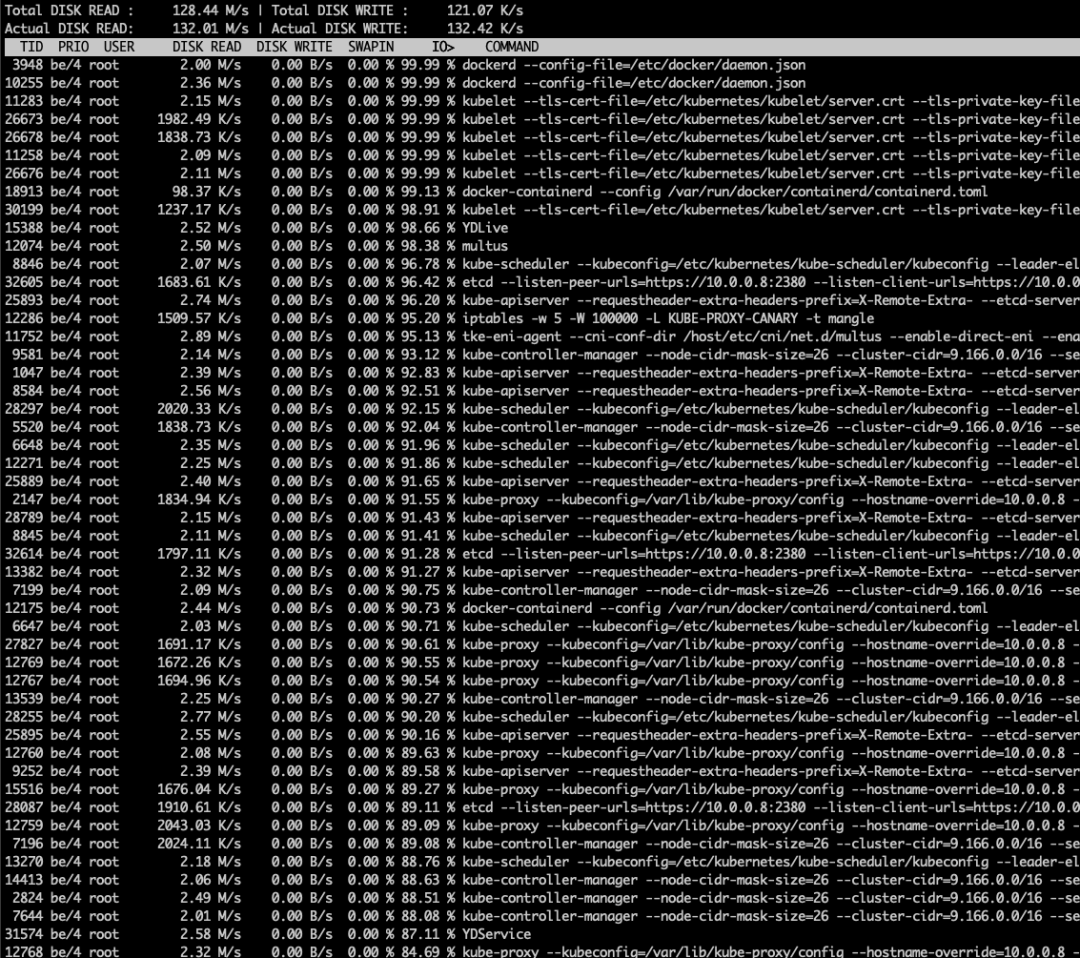
有效信息:
兩個 Master 節(jié)點的內(nèi)存都幾乎被占用了 80%~90% 的樣子
大量的內(nèi)存都被 kube-apiserver 進程吃掉了
有一臺 Master 組件格外特殊,除了內(nèi)存之外,CPU 也已經(jīng)被打滿,并且大量的 CPU 陷入內(nèi)核態(tài),wa 很高
機器上幾乎每個進程都 “ 瘋 “ 了,都在進行大量的讀盤操作,接入的 shell 已經(jīng)基本不可用
唯一內(nèi)存消耗相對較低(當時占用 8Gi)的 Master 節(jié)點上,kube-apiserver 曾經(jīng)被 OOM-Kill 過
一些疑問以及相關(guān)的猜想
為什么 kube-apiserver 消耗大量內(nèi)存?
存在 Client 在進行全量 List 核心資源
etcd 無法提供正常服務(wù),引發(fā) kube-apiserver 無法正常為其他的 control-plane 組件無法提供選主服務(wù),kube-controller-manager, kube-scheduler 不斷重啟,不斷 ListAndWatch 進而打垮整個機器
kube-apiserver 代碼有 bug,存在內(nèi)存泄漏
etcd 集群為何無法正常工作?
- etcd 集群內(nèi)網(wǎng)絡(luò)抖動
- 磁盤性能下降,無法滿足正常的 etcd 工作
- etcd 所在宿主機計算資源匱乏 (CPU,RAM),etcd 只能分配到很少的時間輪片。而代碼中設(shè)置的網(wǎng)絡(luò)描述符的 Deadline 到期
- kube-controller-manager,kube-scheduler 讀取本地的配置文件
- 操作系統(tǒng)內(nèi)存極度緊縮的情況下,會將部分代碼段很大的進程的內(nèi)存頁驅(qū)逐。保證被調(diào)度的進程能夠運行。當被驅(qū)逐的進程再度被調(diào)度的時候會重新讀入內(nèi)存。這樣會導(dǎo)致 I/O 增加
一些日志
kube-apiserver相關(guān):
I0907 07:04:17.611412 1 trace.go:116] Trace[1140445702]: "Get" url:/apis/storage.k8s.io/v1/volumeattachments/csi-b8d912ae5f2cd6d9cfaecc515568c455afdc729fd4c721e4a6ed24ae09d9bcb6,user-agent:kube-controller-manager/v1.18.4 (linux/amd64) kubernetes/f8797eb/system:serviceaccount:kube-system:attachdetach-controller,client:10.0.0.42 (started: 2021-09-07 07:04:16.635225967 +0800 CST m=+23472113.230522917) (total time: 976.1773ms):Trace[1140445702]: [976.164659ms] [976.159045ms] About to write a responseI0907 07:04:17.611478 1 trace.go:116] Trace[630463685]: "Get" url:/apis/storage.k8s.io/v1/volumeattachments/csi-30c942388d7a835b685e5d5a44a15943bfc87b228e3b9ed2fa01ed071fbc1ada,user-agent:kube-controller-manager/v1.18.4 (linux/amd64) kubernetes/f8797eb/system:serviceaccount:kube-system:attachdetach-controller,client:10.0.0.42 (started: 2021-09-07 07:04:16.627643544 +0800 CST m=+23472113.222940496) (total time: 983.823847ms):Trace[630463685]: [983.812225ms] [983.803546ms] About to write a responseI0907 07:04:17.611617 1 trace.go:116] Trace[1538026391]: "Get" url:/apis/storage.k8s.io/v1/volumeattachments/csi-3360a8de64a82e17aa96f373f6dc185489bbc653824b3099c81a6fce754a3f6f,user-agent:kube-controller-manager/v1.18.4 (linux/amd64) kubernetes/f8797eb/system:serviceaccount:kube-system:attachdetach-controller,client:10.0.0.42 (started: 2021-09-07 07:04:16.565151702 +0800 CST m=+23472113.160448667) (total time: 1.046416117s):Trace[1538026391]: [1.046397533s] [1.046390931s] About to write a response# ....N條類似的日志....I0907 07:04:24.171900 1 trace.go:116] Trace[1679666311]: "Get" url:/apis/storage.k8s.io/v1/volumeattachments/csi-b5ee4d68917fbf1262cc0a8047d9c37133a4a766f53f3566c40f868edd8a0bf0,user-agent:kube-controller-manager/v1.18.4 (linux/amd64) kubernetes/f8797eb/system:serviceaccount:kube-system:attachdetach-controller,client:10.0.0.42 (started: 2021-09-07 07:04:17.116692376 +0800 CST m=+23472113.711989328) (total time: 5.467094616s):Trace[1679666311]: [4.69843064s] [4.698422403s] About to write a responseTrace[1679666311]: [5.467093266s] [768.662626ms] Transformed response objectI0907 07:04:24.142154 1 trace.go:116] Trace[2029984150]: "Get" url:/apis/storage.k8s.io/v1/volumeattachments/csi-29407a58f021e9911d3ed9b5745dddfd40e61d64e1ecc62cf71ab9e037f83107,user-agent:kube-controller-manager/v1.18.4 (linux/amd64) kubernetes/f8797eb/system:serviceaccount:kube-system:attachdetach-controller,client:10.0.0.42 (started: 2021-09-07 07:04:17.102181932 +0800 CST m=+23472113.697478883) (total time: 5.50528966s):Trace[2029984150]: [4.704869664s] [4.704865103s] About to write a responseTrace[2029984150]: [5.505288975s] [800.419311ms] Transformed response objectE0907 07:04:37.327057 1 authentication.go:53] Unable to authenticate the request due to an error: [invalid bearer token, context canceled]I0907 07:04:40.391602 1 trace.go:116] Trace[2032502471]: "Update" url:/apis/coordination.k8s.io/v1/namespaces/kube-node-lease/leases/10.0.0.8,user-agent:kubelet/v1.18.4 (linux/amd64) kubernetes/f8797eb,client:10.0.0.8 (started: 2021-09-07 07:04:17.392952999 +0800 CST m=+23472113.988249966) (total time: 20.164329656s):Trace[2032502471]: [286.281637ms] [286.281637ms] About to convert to expected versionTrace[2032502471]: [481.650367ms] [195.36873ms] Conversion doneTrace[2032502471]: [674.825685ms] [193.175318ms] About to store object in databaseTrace[2032502471]: [20.164329656s] [19.489503971s] ENDI0907 07:04:41.502454 1 trace.go:116] Trace[951110924]: "Get" url:/apis/storage.k8s.io/v1/volumeattachments/csi-0938f8852ff15a3937d619216756f9bfa5b0d91c0eb95a881b3caccbf8e87fb2,user-agent:kube-controller-manager/v1.18.4 (linux/amd64) kubernetes/f8797eb/system:serviceaccount:kube-system:attachdetach-controller,client:10.0.0.42 (started: 2021-09-07 07:04:17.29109778 +0800 CST m=+23472113.886395069) (total time: 20.41128212s):Trace[951110924]: [12.839487235s] [12.839478549s] About to write a responseTrace[951110924]: [20.411280569s] [7.571793334s] Transformed response objectW0907 07:10:39.496915 1 clientconn.go:1208] grpc: addrConn.createTransport failed to connect to {https://etcd0:2379 <nil> 0 <nil>}. Err :connection error: desc = "transport: Error while dialing context deadline exceeded". Reconnecting...I0907 07:10:39.514215 1 clientconn.go:882] blockingPicker: the picked transport is not ready, loop back to repickE0907 07:10:39.514473 1 status.go:71] apiserver received an error that is not an metav1.Status: &errors.errorString{s:"context canceled"}E0907 07:10:39.514538 1 status.go:71] apiserver received an error that is not an metav1.Status: &errors.errorString{s:"context canceled"}I0907 07:10:39.514662 1 clientconn.go:882] blockingPicker: the picked transport is not ready, loop back to repickE0907 07:10:39.514679 1 status.go:71] apiserver received an error that is not an metav1.Status: &errors.errorString{s:"context canceled"}E0907 07:10:39.514858 1 status.go:71] apiserver received an error that is not an metav1.Status: &errors.errorString{s:"context canceled"}W0907 07:10:39.514925 1 clientconn.go:1208] grpc: addrConn.createTransport failed to connect to {https://etcd0:2379 <nil> 0 <nil>}. Err :connection error: desc = "transport: Error while dialing context deadline exceeded". Reconnecting...
可以看到對 etcd 的操作耗時越來越慢。并且最后甚至丟失了與 etcd 的連接
etcd日志【已經(jīng)丟失9月7日的日志】:
{"level":"warn","ts":"2021-09-10T17:14:50.559+0800","caller":"embed/config_logging.go:279","msg":"rejected connection","remote-addr":"10.0.0.42:49824","server-name":"","error":"read tcp 10.0.0.8:2380->10.0.0.42:49824: i/o timeout"}{"level":"warn","ts":"2021-09-10T17:14:58.993+0800","caller":"embed/config_logging.go:279","msg":"rejected connection","remote-addr":"10.0.0.6:54656","server-name":"","error":"EOF"}{"level":"warn","ts":"2021-09-10T17:15:03.961+0800","caller":"embed/config_logging.go:279","msg":"rejected connection","remote-addr":"10.0.0.6:54642","server-name":"","error":"EOF"}{"level":"warn","ts":"2021-09-10T17:15:32.253+0800","caller":"embed/config_logging.go:279","msg":"rejected connection","remote-addr":"10.0.0.6:54658","server-name":"","error":"EOF"}{"level":"warn","ts":"2021-09-10T17:15:49.299+0800","caller":"embed/config_logging.go:279","msg":"rejected connection","remote-addr":"10.0.0.42:49690","server-name":"","error":"EOF"}{"level":"warn","ts":"2021-09-10T17:15:55.930+0800","caller":"embed/config_logging.go:279","msg":"rejected connection","remote-addr":"10.0.0.42:49736","server-name":"","error":"EOF"}{"level":"warn","ts":"2021-09-10T17:16:29.446+0800","caller":"embed/config_logging.go:279","msg":"rejected connection","remote-addr":"10.0.0.6:54664","server-name":"","error":"EOF"}{"level":"warn","ts":"2021-09-10T17:16:24.026+0800","caller":"embed/config_logging.go:279","msg":"rejected connection","remote-addr":"10.0.0.42:49696","server-name":"","error":"EOF"}{"level":"warn","ts":"2021-09-10T17:16:36.625+0800","caller":"embed/config_logging.go:279","msg":"rejected connection","remote-addr":"10.0.0.42:49714","server-name":"","error":"EOF"}{"level":"warn","ts":"2021-09-10T17:17:54.241+0800","caller":"embed/config_logging.go:279","msg":"rejected connection","remote-addr":"10.0.0.42:49878","server-name":"","error":"read tcp 10.0.0.8:2380->10.0.0.42:49878: i/o timeout"}{"level":"warn","ts":"2021-09-10T17:18:31.712+0800","caller":"embed/config_logging.go:279","msg":"rejected connection","remote-addr":"10.0.0.42:49728","server-name":"","error":"EOF"}{"level":"warn","ts":"2021-09-10T17:18:31.785+0800","caller":"embed/config_logging.go:279","msg":"rejected connection","remote-addr":"10.0.0.42:49800","server-name":"","error":"EOF"}
可以看出,該節(jié)點的 etcd 與集群中的其他節(jié)點的通信也異常了。無法正常對外提供服務(wù)
深入調(diào)查
查看 kube-apiserver Heap-Profile
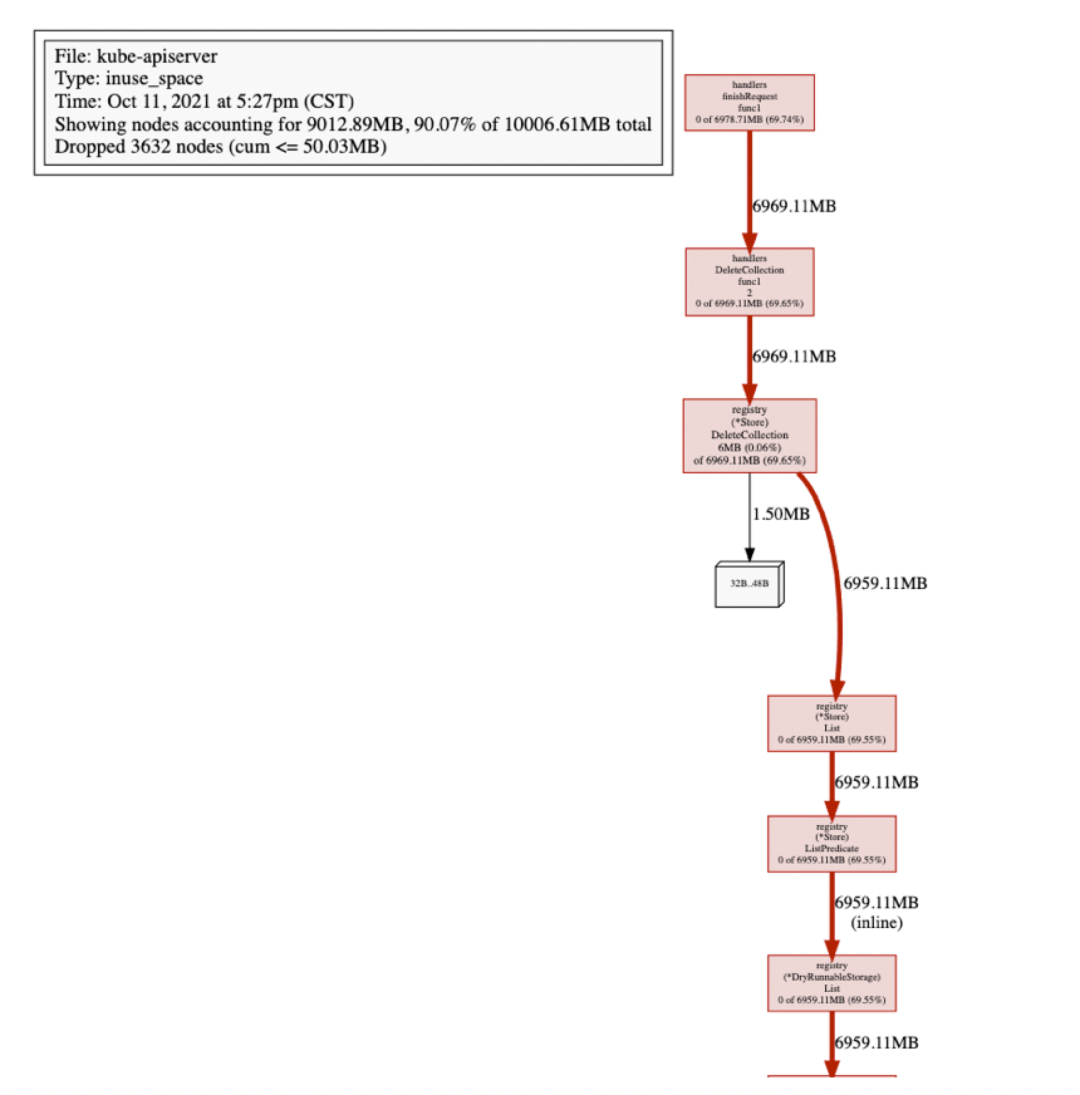
獲取到 kube-apiserver 最近的 Profile 可以發(fā)現(xiàn)大量的內(nèi)存都被 registry(*Store).DeleteCollection 吃掉了。DeleteCollection 會先進行 List 操作,然后并發(fā)刪除每個 Item。瞬間吃掉大量內(nèi)存也在情理之中。也許我這么倒霉,這次抓的時候就正好處于 Delete 的瘋狂調(diào)用期間,休息 10 分鐘,等下再抓一次看看。
怎么回事?怎么 DeleteCollection 還是持有這么多內(nèi)存。此處其實已經(jīng)開始懷疑 kube-apiserver 有 goroutine 泄漏的可能了。
看來 heap 的 Profile 無法提供足夠的信息進行進一步的問題確定,繼續(xù)抓取 kube-apiserver goroutine 的 profile
查看 kube-apiserver goroutine-profile
1.8W goroutine
goroutine 18970952966 [chan send, 429 minutes]:k8s.io/kubernetes/vendor/k8s.io/apiserver/pkg/registry/generic/registry.(*Store).DeleteCollection.func1(0xc00f082ba0, 0xc04e059b90, 0x9, 0x9, 0xc235e37570)--goroutine 18971918521 [chan send, 394 minutes]:k8s.io/kubernetes/vendor/k8s.io/apiserver/pkg/registry/generic/registry.(*Store).DeleteCollection.func1(0xc01f5a7c20, 0xc025cf8750, 0x9, 0x9, 0xc128042620)--goroutine 18975541850 [chan send, 261 minutes]:k8s.io/kubernetes/vendor/k8s.io/apiserver/pkg/registry/generic/registry.(*Store).DeleteCollection.func1(0xc08bb1c780, 0xc095222240, 0x9, 0x9, 0xc128667340)--goroutine 18972733441 [chan send, 363 minutes]:k8s.io/kubernetes/vendor/k8s.io/apiserver/pkg/registry/generic/registry.(*Store).DeleteCollection.func1(0xc015c2c9c0, 0xc0db776240, 0x9, 0x9, 0xc124b0f570)--goroutine 18973170460 [chan send, 347 minutes]:k8s.io/kubernetes/vendor/k8s.io/apiserver/pkg/registry/generic/registry.(*Store).DeleteCollection.func1(0xc07a804c60, 0xc04ee83200, 0x9, 0x9, 0xc23e555c00)--goroutine 18974040729 [chan send, 316 minutes]:k8s.io/kubernetes/vendor/k8s.io/apiserver/pkg/registry/generic/registry.(*Store).DeleteCollection.func1(0xc028d40780, 0xc243ea0cf0, 0x9, 0x9, 0xc14a6be770)--goroutine 18974695712 [chan send, 292 minutes]:k8s.io/kubernetes/vendor/k8s.io/apiserver/pkg/registry/generic/registry.(*Store).DeleteCollection.func1(0xc04573b5c0, 0xc04f0af290, 0x9, 0x9, 0xc1982732d0)--goroutine 18974885774 [chan send, 285 minutes]:k8s.io/kubernetes/vendor/k8s.io/apiserver/pkg/registry/generic/registry.(*Store).DeleteCollection.func1(0xc26065b9e0, 0xc06f025710, 0x9, 0x9, 0xc229945f80)--goroutine 18971511296 [chan send, 408 minutes]:k8s.io/kubernetes/vendor/k8s.io/apiserver/pkg/registry/generic/registry.(*Store).DeleteCollection.func1(0xc021e74480, 0xc0313a54d0, 0x9, 0x9, 0xc1825177a0)--goroutine 18975459144 [chan send, 263 minutes]:k8s.io/kubernetes/vendor/k8s.io/apiserver/pkg/registry/generic/registry.(*Store).DeleteCollection.func1(0xc26cb9d1a0, 0xc17672b440, 0x9, 0x9, 0xc156fcd810)--goroutine 18973661056 [chan send, 331 minutes]:k8s.io/kubernetes/vendor/k8s.io/apiserver/pkg/registry/generic/registry.(*Store).DeleteCollection.func1(0xc2ba3f1680, 0xc19df40870, 0x9, 0x9, 0xc24b888a10)--goroutine 18973633598 [chan send, 331 minutes]:k8s.io/kubernetes/vendor/k8s.io/apiserver/pkg/registry/generic/registry.(*Store).DeleteCollection.func1(0xc24a0ef5c0, 0xc05472a900, 0x9, 0x9, 0xc01ec14af0)--goroutine 18974804879 [chan send, 288 minutes]:k8s.io/kubernetes/vendor/k8s.io/apiserver/pkg/registry/generic/registry.(*Store).DeleteCollection.func1(0xc0863f9ce0, 0xc04fcee090, 0x9, 0x9, 0xc2257a1d50)--goroutine 18974203255 [chan send, 310 minutes]:k8s.io/kubernetes/vendor/k8s.io/apiserver/pkg/registry/generic/registry.(*Store).DeleteCollection.func1(0xc2727ed8c0, 0xc021d4ae10, 0x9, 0x9, 0xc173af3570)# ...還有很多,就不列舉了...
果然大量密集的 goroutine 全部都 Block 在 chan send,并且時間上很密集。DeleteCollection 該接口的調(diào)用一般都是 kube-controller-manager 的 namespace_deleter。如果 kube-apiserver 的接口調(diào)用異常會進行 Backoff,然后繼續(xù)請求,此處的異常是和 kube-apiserver 的通訊沒問題,但是 kube-apiserver 無法正常和 etcd 交互。
查看 kube-controller-manager 的日志
E1027 15:15:01.016712 1 leaderelection.go:320] error retrieving resource lock kube-system/kube-controller-manager: etcdserver: request timed outI1027 15:15:01.950682 1 leaderelection.go:277] failed to renew lease kube-system/kube-controller-manager: timed out waiting for the conditionF1027 15:15:01.950760 1 controllermanager.go:279] leaderelection lostI1027 15:15:01.962210 1 certificate_controller.go:131] Shutting down certificate controller "csrsigning"
雖然沒有輸出調(diào)用 DeleteCollection 相關(guān)的日志,但是 kube-controller-manager 進行 LeaderElection 的 ConfigMap 也無法正常的刷新了。并且報錯也非常明確的指出是 kube-apiserver 請求 etcd 出現(xiàn) timeout。
kube-apiserver DeleteCollection 實現(xiàn)
func (e *Store) DeleteCollection(ctx context.Context, deleteValidation rest.ValidateObjectFunc, options *metav1.DeleteOptions, listOptions *metainternalversion.ListOptions) (runtime.Object, error) {...listObj, err := e.List(ctx, listOptions)if err != nil {return nil, err}items, err := meta.ExtractList(listObj)...wg := sync.WaitGroup{}toProcess := make(chan int, 2*workersNumber)errs := make(chan error, workersNumber+1)go func() {defer utilruntime.HandleCrash(func(panicReason interface{}) {errs <- fmt.Errorf("DeleteCollection distributor panicked: %v", panicReason)})for i := 0; i < len(items); i++ {toProcess <- i}close(toProcess)}()wg.Add(workersNumber)for i := 0; i < workersNumber; i++ {go func() {// panics don't cross goroutine boundariesdefer utilruntime.HandleCrash(func(panicReason interface{}) {errs <- fmt.Errorf("DeleteCollection goroutine panicked: %v", panicReason)})defer wg.Done()for index := range toProcess {...if _, _, err := e.Delete(ctx, accessor.GetName(), deleteValidation, options.DeepCopy()); err != nil && !apierrors.IsNotFound(err) {klog.V(4).InfoS("Delete object in DeleteCollection failed", "object", klog.KObj(accessor), "err", err)errs <- errreturn}}}()}wg.Wait()select {case err := <-errs:return nil, errdefault:return listObj, nil}}
如果e.Delete發(fā)生異常(也就是我們場景下的 etcd 異常)。worker goroutine 將會正常退出,但是任務(wù)分配 goroutine 無法正常退出,Block 在發(fā)送 toProcess chan 的代碼塊中。如果該 Goroutine 無法結(jié)束,那么通過 etcd 的 List 接口獲取到的 items 也無法被 GC,在內(nèi)存中大量堆積,導(dǎo)致 OOM。
總結(jié)
1、排障之前需要對正常有一個比較明確的定位,何謂“正常”?
根據(jù)之前的實踐經(jīng)驗:100Node,1400Pod, 50 Configmap, 300 event。
kube-apiserver消耗的資源大概在 2Gi 的內(nèi)存以及單核心 10% 的計算資源。
2、本次排障過程中大概如下:
通過一些不正常的表現(xiàn),感覺到問題的存在
大概確定引發(fā)故障的組件,通過管理工具獲取該組件相關(guān)的信息
在相關(guān)的監(jiān)控系統(tǒng)中尋找異常發(fā)生的時間,提取相關(guān)的有效信息比如 CPU,RAM,Disk 的消耗
對觸發(fā)故障的原因做假設(shè)
查找相關(guān)組件的日志,Profile 來印證假設(shè)
3、如何防止 control-plane 鏈式崩潰
明確設(shè)置 kube-apiserver 的 CPU 資源內(nèi)存資源的消耗。防止在混部模式下因為 kube-apiserver 消耗大量內(nèi)存資源的前提下影響到 etcd 的正常工作
etcd 集群獨立于 control-plane 其他的組件部署
原文鏈接:https://github.com/k8s-club/k8s-club/blob/main/articles/%E6%8A%93%E8%99%AB%E6%97%A5%E8%AE%B0%20-%20kube-apiserver.md