
MySQL經(jīng)典36問!
大家好,我是大彬~
今天給大家分享MySQL常考的面試題,看看你們能答對(duì)多少
本期MySQL面試題的目錄如下:
事務(wù)的四大特性? 事務(wù)隔離級(jí)別有哪些? 索引 什么是索引? 索引的優(yōu)缺點(diǎn)? 索引的作用? 什么情況下需要建索引? 什么情況下不建索引? 索引的數(shù)據(jù)結(jié)構(gòu) Hash索引和B+樹索引的區(qū)別? 為什么B+樹比B樹更適合實(shí)現(xiàn)數(shù)據(jù)庫索引? 索引有什么分類? 什么是最左匹配原則? 什么是聚集索引? 什么是覆蓋索引? 索引的設(shè)計(jì)原則? 索引什么時(shí)候會(huì)失效? 什么是前綴索引? 常見的存儲(chǔ)引擎有哪些? MyISAM和InnoDB的區(qū)別? MVCC 實(shí)現(xiàn)原理? 快照讀和當(dāng)前讀 共享鎖和排他鎖 大表怎么優(yōu)化? bin log/redo log/undo log bin log和redo log有什么區(qū)別? 講一下MySQL架構(gòu)? 分庫分表 什么是分區(qū)表? 分區(qū)表類型 查詢語句執(zhí)行流程? 更新語句執(zhí)行過程? exist和in的區(qū)別? truncate、delete與drop區(qū)別? having和where的區(qū)別? 什么是MySQL主從同步? 為什么要做主從同步? 樂觀鎖和悲觀鎖是什么? 用過processlist嗎?
事務(wù)的四大特性?
事務(wù)特性ACID:原子性(Atomicity)、一致性(Consistency)、隔離性(Isolation)、持久性(Durability)。
原子性是指事務(wù)包含的所有操作要么全部成功,要么全部失敗回滾。 一致性是指一個(gè)事務(wù)執(zhí)行之前和執(zhí)行之后都必須處于一致性狀態(tài)。比如a與b賬戶共有1000塊,兩人之間轉(zhuǎn)賬之后無論成功還是失敗,它們的賬戶總和還是1000。 隔離性。跟隔離級(jí)別相關(guān),如 read committed,一個(gè)事務(wù)只能讀到已經(jīng)提交的修改。持久性是指一個(gè)事務(wù)一旦被提交了,那么對(duì)數(shù)據(jù)庫中的數(shù)據(jù)的改變就是永久性的,即便是在數(shù)據(jù)庫系統(tǒng)遇到故障的情況下也不會(huì)丟失提交事務(wù)的操作。
事務(wù)隔離級(jí)別有哪些?
先了解下幾個(gè)概念:臟讀、不可重復(fù)讀、幻讀。
臟讀是指在一個(gè)事務(wù)處理過程里讀取了另一個(gè)未提交的事務(wù)中的數(shù)據(jù)。 不可重復(fù)讀是指在對(duì)于數(shù)據(jù)庫中的某行記錄,一個(gè)事務(wù)范圍內(nèi)多次查詢卻返回了不同的數(shù)據(jù)值,這是由于在查詢間隔,另一個(gè)事務(wù)修改了數(shù)據(jù)并提交了。 幻讀是當(dāng)某個(gè)事務(wù)在讀取某個(gè)范圍內(nèi)的記錄時(shí),另外一個(gè)事務(wù)又在該范圍內(nèi)插入了新的記錄,當(dāng)之前的事務(wù)再次讀取該范圍的記錄時(shí),會(huì)產(chǎn)生幻行,就像產(chǎn)生幻覺一樣,這就是發(fā)生了幻讀。
不可重復(fù)讀和臟讀的區(qū)別是,臟讀是某一事務(wù)讀取了另一個(gè)事務(wù)未提交的臟數(shù)據(jù),而不可重復(fù)讀則是讀取了前一事務(wù)提交的數(shù)據(jù)。
幻讀和不可重復(fù)讀都是讀取了另一條已經(jīng)提交的事務(wù),不同的是不可重復(fù)讀的重點(diǎn)是修改,幻讀的重點(diǎn)在于新增或者刪除。
事務(wù)隔離就是為了解決上面提到的臟讀、不可重復(fù)讀、幻讀這幾個(gè)問題。
MySQL數(shù)據(jù)庫為我們提供的四種隔離級(jí)別:
Serializable (串行化):通過強(qiáng)制事務(wù)排序,使之不可能相互沖突,從而解決幻讀問題。 Repeatable read (可重復(fù)讀):MySQL的默認(rèn)事務(wù)隔離級(jí)別,它確保同一事務(wù)的多個(gè)實(shí)例在并發(fā)讀取數(shù)據(jù)時(shí),會(huì)看到同樣的數(shù)據(jù)行,解決了不可重復(fù)讀的問題。 Read committed (讀已提交):一個(gè)事務(wù)只能看見已經(jīng)提交事務(wù)所做的改變。可避免臟讀的發(fā)生。 Read uncommitted (讀未提交):所有事務(wù)都可以看到其他未提交事務(wù)的執(zhí)行結(jié)果。
查看隔離級(jí)別:
select @@transaction_isolation;
設(shè)置隔離級(jí)別:
set session transaction isolation level read uncommitted;
索引
什么是索引?
索引是存儲(chǔ)引擎用于提高數(shù)據(jù)庫表的訪問速度的一種數(shù)據(jù)結(jié)構(gòu)。
索引的優(yōu)缺點(diǎn)?
優(yōu)點(diǎn):
加快數(shù)據(jù)查找的速度 為用來排序或者是分組的字段添加索引,可以加快分組和排序的速度 加快表與表之間連接的速度
缺點(diǎn):
建立索引需要占用物理空間 會(huì)降低表的增刪改的效率,因?yàn)槊看螌?duì)表記錄進(jìn)行增刪改,需要進(jìn)行動(dòng)態(tài)維護(hù)索引,導(dǎo)致增刪改時(shí)間變長
索引的作用?
數(shù)據(jù)是存儲(chǔ)在磁盤上的,查詢數(shù)據(jù)時(shí),如果沒有索引,會(huì)加載所有的數(shù)據(jù)到內(nèi)存,依次進(jìn)行檢索,讀取磁盤次數(shù)較多。有了索引,就不需要加載所有數(shù)據(jù),因?yàn)锽+樹的高度一般在2-4層,最多只需要讀取2-4次磁盤,查詢速度大大提升。
什么情況下需要建索引?
經(jīng)常用于查詢的字段 經(jīng)常用于連接的字段建立索引,可以加快連接的速度 經(jīng)常需要排序的字段建立索引,因?yàn)樗饕呀?jīng)排好序,可以加快排序查詢速度
什么情況下不建索引?
where條件中用不到的字段不適合建立索引表記錄較少 需要經(jīng)常增刪改 參與列計(jì)算的列不適合建索引 區(qū)分度不高的字段不適合建立索引,如性別等
索引的數(shù)據(jù)結(jié)構(gòu)
索引的數(shù)據(jù)結(jié)構(gòu)主要有B+樹和哈希表,對(duì)應(yīng)的索引分別為B+樹索引和哈希索引。InnoDB引擎的索引類型有B+樹索引和哈希索引,默認(rèn)的索引類型為B+樹索引。
B+樹索引
B+ 樹是基于B 樹和葉子節(jié)點(diǎn)順序訪問指針進(jìn)行實(shí)現(xiàn),它具有B樹的平衡性,并且通過順序訪問指針來提高區(qū)間查詢的性能。
在 B+ 樹中,節(jié)點(diǎn)中的 key 從左到右遞增排列,如果某個(gè)指針的左右相鄰 key 分別是 keyi 和 keyi+1,則該指針指向節(jié)點(diǎn)的所有 key 大于等于 keyi 且小于等于 keyi+1。
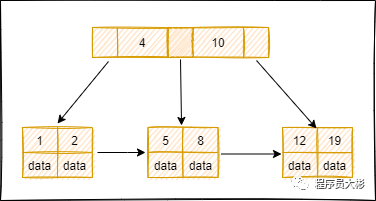
進(jìn)行查找操作時(shí),首先在根節(jié)點(diǎn)進(jìn)行二分查找,找到key所在的指針,然后遞歸地在指針?biāo)赶虻墓?jié)點(diǎn)進(jìn)行查找。直到查找到葉子節(jié)點(diǎn),然后在葉子節(jié)點(diǎn)上進(jìn)行二分查找,找出key所對(duì)應(yīng)的數(shù)據(jù)項(xiàng)。
MySQL 數(shù)據(jù)庫使用最多的索引類型是BTREE索引,底層基于B+樹數(shù)據(jù)結(jié)構(gòu)來實(shí)現(xiàn)。
mysql> show index from blog\G;
*************************** 1. row ***************************
Table: blog
Non_unique: 0
Key_name: PRIMARY
Seq_in_index: 1
Column_name: blog_id
Collation: A
Cardinality: 4
Sub_part: NULL
Packed: NULL
Null:
Index_type: BTREE
Comment:
Index_comment:
Visible: YES
Expression: NULL
哈希索引
哈希索引是基于哈希表實(shí)現(xiàn)的,對(duì)于每一行數(shù)據(jù),存儲(chǔ)引擎會(huì)對(duì)索引列進(jìn)行哈希計(jì)算得到哈希碼,并且哈希算法要盡量保證不同的列值計(jì)算出的哈希碼值是不同的,將哈希碼的值作為哈希表的key值,將指向數(shù)據(jù)行的指針作為哈希表的value值。這樣查找一個(gè)數(shù)據(jù)的時(shí)間復(fù)雜度就是O(1),一般多用于精確查找。
Hash索引和B+樹索引的區(qū)別?
哈希索引不支持排序,因?yàn)楣1硎菬o序的。 哈希索引不支持范圍查找。 哈希索引不支持模糊查詢及多列索引的最左前綴匹配。 因?yàn)楣1碇袝?huì)存在哈希沖突,所以哈希索引的性能是不穩(wěn)定的,而B+樹索引的性能是相對(duì)穩(wěn)定的,每次查詢都是從根節(jié)點(diǎn)到葉子節(jié)點(diǎn)。
為什么B+樹比B樹更適合實(shí)現(xiàn)數(shù)據(jù)庫索引?
由于B+樹的數(shù)據(jù)都存儲(chǔ)在葉子結(jié)點(diǎn)中,葉子結(jié)點(diǎn)均為索引,方便掃庫,只需要掃一遍葉子結(jié)點(diǎn)即可,但是B樹因?yàn)槠浞种ЫY(jié)點(diǎn)同樣存儲(chǔ)著數(shù)據(jù),我們要找到具體的數(shù)據(jù),需要進(jìn)行一次中序遍歷按序來掃,所以B+樹更加適合在區(qū)間查詢的情況,而在數(shù)據(jù)庫中基于范圍的查詢是非常頻繁的,所以通常B+樹用于數(shù)據(jù)庫索引。
B+樹的節(jié)點(diǎn)只存儲(chǔ)索引key值,具體信息的地址存在于葉子節(jié)點(diǎn)的地址中。這就使以頁為單位的索引中可以存放更多的節(jié)點(diǎn)。減少更多的I/O支出。
B+樹的查詢效率更加穩(wěn)定,任何關(guān)鍵字的查找必須走一條從根結(jié)點(diǎn)到葉子結(jié)點(diǎn)的路。所有關(guān)鍵字查詢的路徑長度相同,導(dǎo)致每一個(gè)數(shù)據(jù)的查詢效率相當(dāng)。
索引有什么分類?
1、主鍵索引:名為primary的唯一非空索引,不允許有空值。
2、唯一索引:索引列中的值必須是唯一的,但是允許為空值。唯一索引和主鍵索引的區(qū)別是:唯一約束的列可以為null且可以存在多個(gè)null值。唯一索引的用途:唯一標(biāo)識(shí)數(shù)據(jù)庫表中的每條記錄,主要是用來防止數(shù)據(jù)重復(fù)插入。創(chuàng)建唯一索引的SQL語句如下:
ALTER TABLE table_name
ADD CONSTRAINT constraint_name UNIQUE KEY(column_1,column_2,...);
3、組合索引:在表中的多個(gè)字段組合上創(chuàng)建的索引,只有在查詢條件中使用了這些字段的左邊字段時(shí),索引才會(huì)被使用,使用組合索引時(shí)需遵循最左前綴原則。
4、全文索引:只有在MyISAM引擎上才能使用,只能在CHAR、VARCHAR和TEXT類型字段上使用全文索引。
什么是最左匹配原則?
如果 SQL 語句中用到了組合索引中的最左邊的索引,那么這條 SQL 語句就可以利用這個(gè)組合索引去進(jìn)行匹配。當(dāng)遇到范圍查詢(>、<、between、like)就會(huì)停止匹配,后面的字段不會(huì)用到索引。
對(duì)(a,b,c)建立索引,查詢條件使用 a/ab/abc 會(huì)走索引,使用 bc 不會(huì)走索引。如果查詢條件為a = 1 and b > 2 and c = 3,那么a、b個(gè)字兩段能用到索引,而c無法使用索引,因?yàn)閎字段是范圍查詢,導(dǎo)致后面的字段無法使用索引。
如下圖,對(duì)(a, b) 建立索引,a 在索引樹中是全局有序的,而 b 是全局無序,局部有序(當(dāng)a相等時(shí),會(huì)根據(jù)b進(jìn)行排序)。

當(dāng)a的值確定的時(shí)候,b是有序的。例如a = 1時(shí),b值為1,2是有序的狀態(tài)。當(dāng)執(zhí)行a = 1 and b = 2時(shí)a和b字段能用到索引。而對(duì)于查詢條件a < 4 and b = 2時(shí),a字段能用到索引,b字段則用不到索引。因?yàn)閍的值此時(shí)是一個(gè)范圍,不是固定的,在這個(gè)范圍內(nèi)b的值不是有序的,因此b字段無法使用索引。
什么是聚集索引?
InnoDB使用表的主鍵構(gòu)造主鍵索引樹,同時(shí)葉子節(jié)點(diǎn)中存放的即為整張表的記錄數(shù)據(jù)。聚集索引葉子節(jié)點(diǎn)的存儲(chǔ)是邏輯上連續(xù)的,使用雙向鏈表連接,葉子節(jié)點(diǎn)按照主鍵的順序排序,因此對(duì)于主鍵的排序查找和范圍查找速度比較快。
聚集索引的葉子節(jié)點(diǎn)就是整張表的行記錄。InnoDB 主鍵使用的是聚簇索引。聚集索引要比非聚集索引查詢效率高很多。
對(duì)于InnoDB來說,聚集索引一般是表中的主鍵索引,如果表中沒有顯示指定主鍵,則會(huì)選擇表中的第一個(gè)不允許為NULL的唯一索引。如果沒有主鍵也沒有合適的唯一索引,那么InnoDB內(nèi)部會(huì)生成一個(gè)隱藏的主鍵作為聚集索引,這個(gè)隱藏的主鍵長度為6個(gè)字節(jié),它的值會(huì)隨著數(shù)據(jù)的插入自增。
什么是覆蓋索引?
select的數(shù)據(jù)列只用從索引中就能夠取得,不需要回表進(jìn)行二次查詢,也就是說查詢列要被所使用的索引覆蓋。對(duì)于innodb表的二級(jí)索引,如果索引能覆蓋到查詢的列,那么就可以避免對(duì)主鍵索引的二次查詢。
不是所有類型的索引都可以成為覆蓋索引。覆蓋索引要存儲(chǔ)索引列的值,而哈希索引、全文索引不存儲(chǔ)索引列的值,所以MySQL使用b+樹索引做覆蓋索引。
對(duì)于使用了覆蓋索引的查詢,在查詢前面使用explain,輸出的extra列會(huì)顯示為using index。
比如user_like 用戶點(diǎn)贊表,組合索引為(user_id, blog_id),user_id和blog_id都不為null。
explain select blog_id from user_like where user_id = 13;
explain結(jié)果的Extra列為Using index,查詢的列被索引覆蓋,并且where篩選條件符合最左前綴原則,通過索引查找就能直接找到符合條件的數(shù)據(jù),不需要回表查詢數(shù)據(jù)。
explain select user_id from user_like where blog_id = 1;
explain結(jié)果的Extra列為Using where; Using index, 查詢的列被索引覆蓋,where篩選條件不符合最左前綴原則,無法通過索引查找找到符合條件的數(shù)據(jù),但可以通過索引掃描找到符合條件的數(shù)據(jù),也不需要回表查詢數(shù)據(jù)。

索引的設(shè)計(jì)原則?
索引列的區(qū)分度越高,索引的效果越好。比如使用性別這種區(qū)分度很低的列作為索引,效果就會(huì)很差。 盡量使用短索引,對(duì)于較長的字符串進(jìn)行索引時(shí)應(yīng)該指定一個(gè)較短的前綴長度,因?yàn)檩^小的索引涉及到的磁盤I/O較少,查詢速度更快。 索引不是越多越好,每個(gè)索引都需要額外的物理空間,維護(hù)也需要花費(fèi)時(shí)間。 利用最左前綴原則。
索引什么時(shí)候會(huì)失效?
導(dǎo)致索引失效的情況:
對(duì)于組合索引,不是使用組合索引最左邊的字段,則不會(huì)使用索引 以%開頭的like查詢?nèi)?code style="font-size: 14px;padding: 2px 4px;border-radius: 4px;margin-right: 2px;margin-left: 2px;background-color: rgba(27, 31, 35, 0.05);font-family: "Operator Mono", Consolas, Monaco, Menlo, monospace;word-break: break-all;color: rgb(239, 112, 96);">%abc,無法使用索引;非%開頭的like查詢?nèi)?code style="font-size: 14px;padding: 2px 4px;border-radius: 4px;margin-right: 2px;margin-left: 2px;background-color: rgba(27, 31, 35, 0.05);font-family: "Operator Mono", Consolas, Monaco, Menlo, monospace;word-break: break-all;color: rgb(239, 112, 96);">abc%,相當(dāng)于范圍查詢,會(huì)使用索引 查詢條件中列類型是字符串,沒有使用引號(hào),可能會(huì)因?yàn)轭愋筒煌l(fā)生隱式轉(zhuǎn)換,使索引失效 判斷索引列是否不等于某個(gè)值時(shí) 對(duì)索引列進(jìn)行運(yùn)算 查詢條件使用 or連接,也會(huì)導(dǎo)致索引失效
什么是前綴索引?
有時(shí)需要在很長的字符列上創(chuàng)建索引,這會(huì)造成索引特別大且慢。使用前綴索引可以避免這個(gè)問題。
前綴索引是指對(duì)文本或者字符串的前幾個(gè)字符建立索引,這樣索引的長度更短,查詢速度更快。
創(chuàng)建前綴索引的關(guān)鍵在于選擇足夠長的前綴以保證較高的索引選擇性。索引選擇性越高查詢效率就越高,因?yàn)檫x擇性高的索引可以讓MySQL在查找時(shí)過濾掉更多的數(shù)據(jù)行。
建立前綴索引的方式:
// email列創(chuàng)建前綴索引
ALTER TABLE table_name ADD KEY(column_name(prefix_length));
常見的存儲(chǔ)引擎有哪些?
MySQL中常用的四種存儲(chǔ)引擎分別是:MyISAM、InnoDB、MEMORY、ARCHIVE。MySQL 5.5版本后默認(rèn)的存儲(chǔ)引擎為InnoDB。
InnoDB存儲(chǔ)引擎
InnoDB是MySQL默認(rèn)的事務(wù)型存儲(chǔ)引擎,使用最廣泛,基于聚簇索引建立的。InnoDB內(nèi)部做了很多優(yōu)化,如能夠自動(dòng)在內(nèi)存中創(chuàng)建自適應(yīng)hash索引,以加速讀操作。
優(yōu)點(diǎn):支持事務(wù)和崩潰修復(fù)能力;引入了行級(jí)鎖和外鍵約束。
缺點(diǎn):占用的數(shù)據(jù)空間相對(duì)較大。
適用場(chǎng)景:需要事務(wù)支持,并且有較高的并發(fā)讀寫頻率。
MyISAM存儲(chǔ)引擎
數(shù)據(jù)以緊密格式存儲(chǔ)。對(duì)于只讀數(shù)據(jù),或者表比較小、可以容忍修復(fù)操作,可以使用MyISAM引擎。MyISAM會(huì)將表存儲(chǔ)在兩個(gè)文件中,數(shù)據(jù)文件.MYD和索引文件.MYI。
優(yōu)點(diǎn):訪問速度快。
缺點(diǎn):MyISAM不支持事務(wù)和行級(jí)鎖,不支持崩潰后的安全恢復(fù),也不支持外鍵。
適用場(chǎng)景:對(duì)事務(wù)完整性沒有要求;表的數(shù)據(jù)都會(huì)只讀的。
MEMORY存儲(chǔ)引擎
MEMORY引擎將數(shù)據(jù)全部放在內(nèi)存中,訪問速度較快,但是一旦系統(tǒng)奔潰的話,數(shù)據(jù)都會(huì)丟失。
MEMORY引擎默認(rèn)使用哈希索引,將鍵的哈希值和指向數(shù)據(jù)行的指針保存在哈希索引中。
優(yōu)點(diǎn):訪問速度較快。
缺點(diǎn):
哈希索引數(shù)據(jù)不是按照索引值順序存儲(chǔ),無法用于排序。 不支持部分索引匹配查找,因?yàn)楣K饕鞘褂盟饕械娜績(jī)?nèi)容來計(jì)算哈希值的。 只支持等值比較,不支持范圍查詢。 當(dāng)出現(xiàn)哈希沖突時(shí),存儲(chǔ)引擎需要遍歷鏈表中所有的行指針,逐行進(jìn)行比較,直到找到符合條件的行。
ARCHIVE存儲(chǔ)引擎
ARCHIVE存儲(chǔ)引擎非常適合存儲(chǔ)大量獨(dú)立的、作為歷史記錄的數(shù)據(jù)。ARCHIVE提供了壓縮功能,擁有高效的插入速度,但是這種引擎不支持索引,所以查詢性能較差。
MyISAM和InnoDB的區(qū)別?
是否支持行級(jí)鎖 :
MyISAM只有表級(jí)鎖,而InnoDB支持行級(jí)鎖和表級(jí)鎖,默認(rèn)為行級(jí)鎖。是否支持事務(wù)和崩潰后的安全恢復(fù):
MyISAM不提供事務(wù)支持。而InnoDB提供事務(wù)支持,具有事務(wù)、回滾和崩潰修復(fù)能力。是否支持外鍵:
MyISAM不支持,而InnoDB支持。是否支持MVCC :
MyISAM不支持,InnoDB支持。應(yīng)對(duì)高并發(fā)事務(wù),MVCC比單純的加鎖更高效。MyISAM不支持聚集索引,InnoDB支持聚集索引。
MVCC 實(shí)現(xiàn)原理?
MVCC(Multiversion concurrency control) 就是同一份數(shù)據(jù)保留多版本的一種方式,進(jìn)而實(shí)現(xiàn)并發(fā)控制。在查詢的時(shí)候,通過read view和版本鏈找到對(duì)應(yīng)版本的數(shù)據(jù)。
作用:提升并發(fā)性能。對(duì)于高并發(fā)場(chǎng)景,MVCC比行級(jí)鎖開銷更小。
MVCC 實(shí)現(xiàn)原理如下:
MVCC 的實(shí)現(xiàn)依賴于版本鏈,版本鏈?zhǔn)峭ㄟ^表的三個(gè)隱藏字段實(shí)現(xiàn)。
DB_TRX_ID:當(dāng)前事務(wù)id,通過事務(wù)id的大小判斷事務(wù)的時(shí)間順序。DB_ROLL_PRT:回滾指針,指向當(dāng)前行記錄的上一個(gè)版本,通過這個(gè)指針將數(shù)據(jù)的多個(gè)版本連接在一起構(gòu)成undo log版本鏈。DB_ROLL_ID:主鍵,如果數(shù)據(jù)表沒有主鍵,InnoDB會(huì)自動(dòng)生成主鍵。
每條表記錄大概是這樣的:

使用事務(wù)更新行記錄的時(shí)候,就會(huì)生成版本鏈,執(zhí)行過程如下:
用排他鎖鎖住該行; 將該行原本的值拷貝到 undo log,作為舊版本用于回滾;修改當(dāng)前行的值,生成一個(gè)新版本,更新事務(wù)id,使回滾指針指向舊版本的記錄,這樣就形成一條版本鏈。
下面舉個(gè)例子方便大家理解。
1、初始數(shù)據(jù)如下,其中DB_ROW_ID和DB_ROLL_PTR為空。

2、事務(wù)A對(duì)該行數(shù)據(jù)做了修改,將age修改為12,效果如下:

3、之后事務(wù)B也對(duì)該行記錄做了修改,將age修改為8,效果如下:
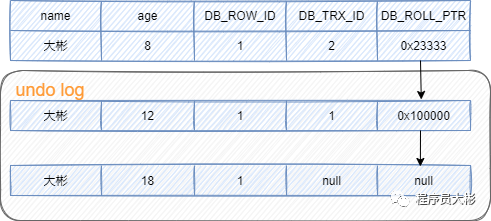
4、此時(shí)undo log有兩行記錄,并且通過回滾指針連在一起。
接下來了解下read view的概念。
read view可以理解成將數(shù)據(jù)在每個(gè)時(shí)刻的狀態(tài)拍成“照片”記錄下來。在獲取某時(shí)刻t的數(shù)據(jù)時(shí),到t時(shí)間點(diǎn)拍的“照片”上取數(shù)據(jù)。
在read view內(nèi)部維護(hù)一個(gè)活躍事務(wù)鏈表,表示生成read view的時(shí)候還在活躍的事務(wù)。這個(gè)鏈表包含在創(chuàng)建read view之前還未提交的事務(wù),不包含創(chuàng)建read view之后提交的事務(wù)。
不同隔離級(jí)別創(chuàng)建read view的時(shí)機(jī)不同。
read committed:每次執(zhí)行select都會(huì)創(chuàng)建新的read_view,保證能讀取到其他事務(wù)已經(jīng)提交的修改。
repeatable read:在一個(gè)事務(wù)范圍內(nèi),第一次select時(shí)更新這個(gè)read_view,以后不會(huì)再更新,后續(xù)所有的select都是復(fù)用之前的read_view。這樣可以保證事務(wù)范圍內(nèi)每次讀取的內(nèi)容都一樣,即可重復(fù)讀。
read view的記錄篩選方式
前提:DATA_TRX_ID 表示每個(gè)數(shù)據(jù)行的最新的事務(wù)ID;up_limit_id表示當(dāng)前快照中的最先開始的事務(wù);low_limit_id表示當(dāng)前快照中的最慢開始的事務(wù),即最后一個(gè)事務(wù)。

如果 DATA_TRX_ID<up_limit_id:說明在創(chuàng)建read view時(shí),修改該數(shù)據(jù)行的事務(wù)已提交,該版本的記錄可被當(dāng)前事務(wù)讀取到。如果 DATA_TRX_ID>=low_limit_id:說明當(dāng)前版本的記錄的事務(wù)是在創(chuàng)建read view之后生成的,該版本的數(shù)據(jù)行不可以被當(dāng)前事務(wù)訪問。此時(shí)需要通過版本鏈找到上一個(gè)版本,然后重新判斷該版本的記錄對(duì)當(dāng)前事務(wù)的可見性。如果 up_limit_id<=DATA_TRX_ID<low_limit_i:需要在活躍事務(wù)鏈表中查找是否存在ID為 DATA_TRX_ID的值的事務(wù)。如果存在,因?yàn)樵诨钴S事務(wù)鏈表中的事務(wù)是未提交的,所以該記錄是不可見的。此時(shí)需要通過版本鏈找到上一個(gè)版本,然后重新判斷該版本的可見性。 如果不存在,說明事務(wù)trx_id 已經(jīng)提交了,這行記錄是可見的。
總結(jié):InnoDB 的MVCC是通過 read view 和版本鏈實(shí)現(xiàn)的,版本鏈保存有歷史版本記錄,通過read view 判斷當(dāng)前版本的數(shù)據(jù)是否可見,如果不可見,再從版本鏈中找到上一個(gè)版本,繼續(xù)進(jìn)行判斷,直到找到一個(gè)可見的版本。
快照讀和當(dāng)前讀
表記錄有兩種讀取方式。
快照讀:讀取的是快照版本。普通的
SELECT就是快照讀。通過mvcc來進(jìn)行并發(fā)控制的,不用加鎖。當(dāng)前讀:讀取的是最新版本。
UPDATE、DELETE、INSERT、SELECT … LOCK IN SHARE MODE、SELECT … FOR UPDATE是當(dāng)前讀。
快照讀情況下,InnoDB通過mvcc機(jī)制避免了幻讀現(xiàn)象。而mvcc機(jī)制無法避免當(dāng)前讀情況下出現(xiàn)的幻讀現(xiàn)象。因?yàn)楫?dāng)前讀每次讀取的都是最新數(shù)據(jù),這時(shí)如果兩次查詢中間有其它事務(wù)插入數(shù)據(jù),就會(huì)產(chǎn)生幻讀。
下面舉個(gè)例子說明下:
1、首先,user表只有兩條記錄,具體如下:

2、事務(wù)a和事務(wù)b同時(shí)開啟事務(wù)start transaction;
3、事務(wù)a插入數(shù)據(jù)然后提交;
insert into user(user_name, user_password, user_mail, user_state) values('tyson', 'a', 'a', 0);
4、事務(wù)b執(zhí)行全表的update;
update user set user_name = 'a';
5、事務(wù)b然后執(zhí)行查詢,查到了事務(wù)a中插入的數(shù)據(jù)。(下圖左邊是事務(wù)b,右邊是事務(wù)a。事務(wù)開始之前只有兩條記錄,事務(wù)a插入一條數(shù)據(jù)之后,事務(wù)b查詢出來是三條數(shù)據(jù))

以上就是當(dāng)前讀出現(xiàn)的幻讀現(xiàn)象。
那么MySQL是如何避免幻讀?
在快照讀情況下,MySQL通過 mvcc來避免幻讀。在當(dāng)前讀情況下,MySQL通過 next-key來避免幻讀(加行鎖和間隙鎖來實(shí)現(xiàn)的)。
next-key包括兩部分:行鎖和間隙鎖。行鎖是加在索引上的鎖,間隙鎖是加在索引之間的。
Serializable隔離級(jí)別也可以避免幻讀,會(huì)鎖住整張表,并發(fā)性極低,一般不會(huì)使用。
共享鎖和排他鎖
SELECT 的讀取鎖定主要分為兩種方式:共享鎖和排他鎖。
select * from table where id<6 lock in share mode;--共享鎖
select * from table where id<6 for update;--排他鎖
這兩種方式主要的不同在于LOCK IN SHARE MODE多個(gè)事務(wù)同時(shí)更新同一個(gè)表單時(shí)很容易造成死鎖。
申請(qǐng)排他鎖的前提是,沒有線程對(duì)該結(jié)果集的任何行數(shù)據(jù)使用排它鎖或者共享鎖,否則申請(qǐng)會(huì)受到阻塞。在進(jìn)行事務(wù)操作時(shí),MySQL會(huì)對(duì)查詢結(jié)果集的每行數(shù)據(jù)添加排它鎖,其他線程對(duì)這些數(shù)據(jù)的更改或刪除操作會(huì)被阻塞(只能讀操作),直到該語句的事務(wù)被commit語句或rollback語句結(jié)束為止。
SELECT... FOR UPDATE 使用注意事項(xiàng):
for update僅適用于innodb,且必須在事務(wù)范圍內(nèi)才能生效。根據(jù)主鍵進(jìn)行查詢,查詢條件為 like或者不等于,主鍵字段產(chǎn)生表鎖。根據(jù)非索引字段進(jìn)行查詢,會(huì)產(chǎn)生表鎖。
大表怎么優(yōu)化?
某個(gè)表有近千萬數(shù)據(jù),查詢比較慢,如何優(yōu)化?
當(dāng)MySQL單表記錄數(shù)過大時(shí),數(shù)據(jù)庫的性能會(huì)明顯下降,一些常見的優(yōu)化措施如下:
限定數(shù)據(jù)的范圍。比如:用戶在查詢歷史信息的時(shí)候,可以控制在一個(gè)月的時(shí)間范圍內(nèi); 讀寫分離:經(jīng)典的數(shù)據(jù)庫拆分方案,主庫負(fù)責(zé)寫,從庫負(fù)責(zé)讀; 通過分庫分表的方式進(jìn)行優(yōu)化,主要有垂直拆分和水平拆分。
bin log/redo log/undo log
MySQL日志主要包括查詢?nèi)罩尽⒙樵內(nèi)罩尽⑹聞?wù)日志、錯(cuò)誤日志、二進(jìn)制日志等。其中比較重要的是 bin log(二進(jìn)制日志)和 redo log(重做日志)和 undo log(回滾日志)。
bin log
bin log是MySQL數(shù)據(jù)庫級(jí)別的文件,記錄對(duì)MySQL數(shù)據(jù)庫執(zhí)行修改的所有操作,不會(huì)記錄select和show語句,主要用于恢復(fù)數(shù)據(jù)庫和同步數(shù)據(jù)庫。
redo log
redo log是innodb引擎級(jí)別,用來記錄innodb存儲(chǔ)引擎的事務(wù)日志,不管事務(wù)是否提交都會(huì)記錄下來,用于數(shù)據(jù)恢復(fù)。當(dāng)數(shù)據(jù)庫發(fā)生故障,innoDB存儲(chǔ)引擎會(huì)使用redo log恢復(fù)到發(fā)生故障前的時(shí)刻,以此來保證數(shù)據(jù)的完整性。將參數(shù)innodb_flush_log_at_tx_commit設(shè)置為1,那么在執(zhí)行commit時(shí)會(huì)將redo log同步寫到磁盤。
undo log
除了記錄redo log外,當(dāng)進(jìn)行數(shù)據(jù)修改時(shí)還會(huì)記錄undo log,undo log用于數(shù)據(jù)的撤回操作,它保留了記錄修改前的內(nèi)容。通過undo log可以實(shí)現(xiàn)事務(wù)回滾,并且可以根據(jù)undo log回溯到某個(gè)特定的版本的數(shù)據(jù),實(shí)現(xiàn)MVCC。
bin log和redo log有什么區(qū)別?
bin log會(huì)記錄所有日志記錄,包括InnoDB、MyISAM等存儲(chǔ)引擎的日志;redo log只記錄innoDB自身的事務(wù)日志。bin log只在事務(wù)提交前寫入到磁盤,一個(gè)事務(wù)只寫一次;而在事務(wù)進(jìn)行過程,會(huì)有redo log不斷寫入磁盤。bin log是邏輯日志,記錄的是SQL語句的原始邏輯;redo log是物理日志,記錄的是在某個(gè)數(shù)據(jù)頁上做了什么修改。
講一下MySQL架構(gòu)?

MySQL主要分為 Server 層和存儲(chǔ)引擎層:
Server 層:主要包括連接器、查詢緩存、分析器、優(yōu)化器、執(zhí)行器等,所有跨存儲(chǔ)引擎的功能都在這一層實(shí)現(xiàn),比如存儲(chǔ)過程、觸發(fā)器、視圖,函數(shù)等,還有一個(gè)通用的日志模塊 binglog 日志模塊。 存儲(chǔ)引擎:主要負(fù)責(zé)數(shù)據(jù)的存儲(chǔ)和讀取。server 層通過api與存儲(chǔ)引擎進(jìn)行通信。
Server 層基本組件
連接器: 當(dāng)客戶端連接 MySQL 時(shí),server層會(huì)對(duì)其進(jìn)行身份認(rèn)證和權(quán)限校驗(yàn)。 查詢緩存: 執(zhí)行查詢語句的時(shí)候,會(huì)先查詢緩存,先校驗(yàn)這個(gè) sql 是否執(zhí)行過,如果有緩存這個(gè) sql,就會(huì)直接返回給客戶端,如果沒有命中,就會(huì)執(zhí)行后續(xù)的操作。 分析器: 沒有命中緩存的話,SQL 語句就會(huì)經(jīng)過分析器,主要分為兩步,詞法分析和語法分析,先看 SQL 語句要做什么,再檢查 SQL 語句語法是否正確。 優(yōu)化器: 優(yōu)化器對(duì)查詢進(jìn)行優(yōu)化,包括重寫查詢、決定表的讀寫順序以及選擇合適的索引等,生成執(zhí)行計(jì)劃。 執(zhí)行器: 首先執(zhí)行前會(huì)校驗(yàn)該用戶有沒有權(quán)限,如果沒有權(quán)限,就會(huì)返回錯(cuò)誤信息,如果有權(quán)限,就會(huì)根據(jù)執(zhí)行計(jì)劃去調(diào)用引擎的接口,返回結(jié)果。
分庫分表
當(dāng)單表的數(shù)據(jù)量達(dá)到1000W或100G以后,優(yōu)化索引、添加從庫等可能對(duì)數(shù)據(jù)庫性能提升效果不明顯,此時(shí)就要考慮對(duì)其進(jìn)行切分了。切分的目的就在于減少數(shù)據(jù)庫的負(fù)擔(dān),縮短查詢的時(shí)間。
數(shù)據(jù)切分可以分為兩種方式:垂直劃分和水平劃分。
垂直劃分
垂直劃分?jǐn)?shù)據(jù)庫是根據(jù)業(yè)務(wù)進(jìn)行劃分,例如購物場(chǎng)景,可以將庫中涉及商品、訂單、用戶的表分別劃分出成一個(gè)庫,通過降低單庫的大小來提高性能。同樣的,分表的情況就是將一個(gè)大表根據(jù)業(yè)務(wù)功能拆分成一個(gè)個(gè)子表,例如商品基本信息和商品描述,商品基本信息一般會(huì)展示在商品列表,商品描述在商品詳情頁,可以將商品基本信息和商品描述拆分成兩張表。

優(yōu)點(diǎn):行記錄變小,數(shù)據(jù)頁可以存放更多記錄,在查詢時(shí)減少I/O次數(shù)。
缺點(diǎn):
主鍵出現(xiàn)冗余,需要管理冗余列; 會(huì)引起表連接JOIN操作,可以通過在業(yè)務(wù)服務(wù)器上進(jìn)行join來減少數(shù)據(jù)庫壓力; 依然存在單表數(shù)據(jù)量過大的問題。
水平劃分
水平劃分是根據(jù)一定規(guī)則,例如時(shí)間或id序列值等進(jìn)行數(shù)據(jù)的拆分。比如根據(jù)年份來拆分不同的數(shù)據(jù)庫。每個(gè)數(shù)據(jù)庫結(jié)構(gòu)一致,但是數(shù)據(jù)得以拆分,從而提升性能。

優(yōu)點(diǎn):?jiǎn)螏欤ū恚┑臄?shù)據(jù)量得以減少,提高性能;切分出的表結(jié)構(gòu)相同,程序改動(dòng)較少。
缺點(diǎn):
分片事務(wù)一致性難以解決 跨節(jié)點(diǎn) join性能差,邏輯復(fù)雜數(shù)據(jù)分片在擴(kuò)容時(shí)需要遷移
什么是分區(qū)表?
分區(qū)表是一個(gè)獨(dú)立的邏輯表,但是底層由多個(gè)物理子表組成。
當(dāng)查詢條件的數(shù)據(jù)分布在某一個(gè)分區(qū)的時(shí)候,查詢引擎只會(huì)去某一個(gè)分區(qū)查詢,而不是遍歷整個(gè)表。在管理層面,如果需要?jiǎng)h除某一個(gè)分區(qū)的數(shù)據(jù),只需要?jiǎng)h除對(duì)應(yīng)的分區(qū)即可。
分區(qū)表類型
按照范圍分區(qū)。
CREATE?TABLE?test_range_partition(
???????id?INT?auto_increment,
???????createdate?DATETIME,
???????primary?key?(id,createdate)
???)?
???PARTITION?BY?RANGE?(TO_DAYS(createdate)?)?(
??????PARTITION?p201801?VALUES?LESS?THAN?(?TO_DAYS('20180201')?),
??????PARTITION?p201802?VALUES?LESS?THAN?(?TO_DAYS('20180301')?),
??????PARTITION?p201803?VALUES?LESS?THAN?(?TO_DAYS('20180401')?),
??????PARTITION?p201804?VALUES?LESS?THAN?(?TO_DAYS('20180501')?),
??????PARTITION?p201805?VALUES?LESS?THAN?(?TO_DAYS('20180601')?),
??????PARTITION?p201806?VALUES?LESS?THAN?(?TO_DAYS('20180701')?),
??????PARTITION?p201807?VALUES?LESS?THAN?(?TO_DAYS('20180801')?),
??????PARTITION?p201808?VALUES?LESS?THAN?(?TO_DAYS('20180901')?),
??????PARTITION?p201809?VALUES?LESS?THAN?(?TO_DAYS('20181001')?),
??????PARTITION?p201810?VALUES?LESS?THAN?(?TO_DAYS('20181101')?),
??????PARTITION?p201811?VALUES?LESS?THAN?(?TO_DAYS('20181201')?),
??????PARTITION?p201812?VALUES?LESS?THAN?(?TO_DAYS('20190101')?)
???);
在/var/lib/mysql/data/可以找到對(duì)應(yīng)的數(shù)據(jù)文件,每個(gè)分區(qū)表都有一個(gè)使用#分隔命名的表文件:
???-rw-r-----?1?MySQL?MySQL????65?Mar?14?21:47?db.opt
???-rw-r-----?1?MySQL?MySQL??8598?Mar?14?21:50?test_range_partition.frm
???-rw-r-----?1?MySQL?MySQL?98304?Mar?14?21:50?test_range_partition#P#p201801.ibd
???-rw-r-----?1?MySQL?MySQL?98304?Mar?14?21:50?test_range_partition#P#p201802.ibd
???-rw-r-----?1?MySQL?MySQL?98304?Mar?14?21:50?test_range_partition#P#p201803.ibd
...
list分區(qū)
對(duì)于List分區(qū),分區(qū)字段必須是已知的,如果插入的字段不在分區(qū)時(shí)枚舉值中,將無法插入。
create?table?test_list_partiotion
???(
???????id?int?auto_increment,
???????data_type?tinyint,
???????primary?key(id,data_type)
???)partition?by?list(data_type)
???(
???????partition?p0?values?in?(0,1,2,3,4,5,6),
???????partition?p1?values?in?(7,8,9,10,11,12),
???????partition?p2?values?in?(13,14,15,16,17)
???);
hash分區(qū)
可以將數(shù)據(jù)均勻地分布到預(yù)先定義的分區(qū)中。
create?table?test_hash_partiotion
???(
???????id?int?auto_increment,
???????create_date?datetime,
???????primary?key(id,create_date)
???)partition?by?hash(year(create_date))?partitions?10;
查詢語句執(zhí)行流程?
查詢語句的執(zhí)行流程如下:權(quán)限校驗(yàn)、查詢緩存、分析器、優(yōu)化器、權(quán)限校驗(yàn)、執(zhí)行器、引擎。
舉個(gè)例子,查詢語句如下:
select * from user where id > 1 and name = '大彬';
首先檢查權(quán)限,沒有權(quán)限則返回錯(cuò)誤; MySQL8.0以前會(huì)查詢緩存,緩存命中則直接返回,沒有則執(zhí)行下一步; 詞法分析和語法分析。提取表名、查詢條件,檢查語法是否有錯(cuò)誤; 兩種執(zhí)行方案,先查 id > 1還是name = '大彬',優(yōu)化器根據(jù)自己的優(yōu)化算法選擇執(zhí)行效率最好的方案;校驗(yàn)權(quán)限,有權(quán)限就調(diào)用數(shù)據(jù)庫引擎接口,返回引擎的執(zhí)行結(jié)果。
更新語句執(zhí)行過程?
更新語句執(zhí)行流程如下:分析器、權(quán)限校驗(yàn)、執(zhí)行器、引擎、redo log(prepare狀態(tài))、binlog、redo log(commit狀態(tài))
舉個(gè)例子,更新語句如下:
update user set name = '大彬' where id = 1;
先查詢到 id 為1的記錄,有緩存會(huì)使用緩存。 拿到查詢結(jié)果,將 name 更新為大彬,然后調(diào)用引擎接口,寫入更新數(shù)據(jù),innodb 引擎將數(shù)據(jù)保存在內(nèi)存中,同時(shí)記錄 redo log,此時(shí)redo log進(jìn)入prepare狀態(tài)。執(zhí)行器收到通知后記錄 binlog,然后調(diào)用引擎接口,提交redo log為commit狀態(tài)。更新完成。
為什么記錄完redo log,不直接提交,而是先進(jìn)入prepare狀態(tài)?
假設(shè)先寫redo log直接提交,然后寫binlog,寫完redo log后,機(jī)器掛了,binlog日志沒有被寫入,那么機(jī)器重啟后,這臺(tái)機(jī)器會(huì)通過redo log恢復(fù)數(shù)據(jù),但是這個(gè)時(shí)候binlog并沒有記錄該數(shù)據(jù),后續(xù)進(jìn)行機(jī)器備份的時(shí)候,就會(huì)丟失這一條數(shù)據(jù),同時(shí)主從同步也會(huì)丟失這一條數(shù)據(jù)。
exist和in的區(qū)別?
exists用于對(duì)外表記錄做篩選。exists會(huì)遍歷外表,將外查詢表的每一行,代入內(nèi)查詢進(jìn)行判斷。當(dāng)exists里的條件語句能夠返回記錄行時(shí),條件就為真,返回外表當(dāng)前記錄。反之如果exists里的條件語句不能返回記錄行,條件為假,則外表當(dāng)前記錄被丟棄。
select a.* from A awhere exists(select 1 from B b where a.id=b.id)
in是先把后邊的語句查出來放到臨時(shí)表中,然后遍歷臨時(shí)表,將臨時(shí)表的每一行,代入外查詢?nèi)ゲ檎摇?/p>
select * from Awhere id in(select id from B)
子查詢的表比較大的時(shí)候,使用exists可以有效減少總的循環(huán)次數(shù)來提升速度;當(dāng)外查詢的表比較大的時(shí)候,使用in可以有效減少對(duì)外查詢表循環(huán)遍歷來提升速度。
truncate、delete與drop區(qū)別?
相同點(diǎn):
truncate和不帶where子句的delete、以及drop都會(huì)刪除表內(nèi)的數(shù)據(jù)。drop、truncate都是DDL語句(數(shù)據(jù)定義語言),執(zhí)行后會(huì)自動(dòng)提交。
不同點(diǎn):
truncate 和 delete 只刪除數(shù)據(jù)不刪除表的結(jié)構(gòu);drop 語句將刪除表的結(jié)構(gòu)被依賴的約束、觸發(fā)器、索引; 一般來說,執(zhí)行速度: drop > truncate > delete。
having和where的區(qū)別?
二者作用的對(duì)象不同, where子句作用于表和視圖,having作用于組。where在數(shù)據(jù)分組前進(jìn)行過濾,having在數(shù)據(jù)分組后進(jìn)行過濾。
什么是MySQL主從同步?
主從同步使得數(shù)據(jù)可以從一個(gè)數(shù)據(jù)庫服務(wù)器復(fù)制到其他服務(wù)器上,在復(fù)制數(shù)據(jù)時(shí),一個(gè)服務(wù)器充當(dāng)主服務(wù)器(master),其余的服務(wù)器充當(dāng)從服務(wù)器(slave)。
因?yàn)閺?fù)制是異步進(jìn)行的,所以從服務(wù)器不需要一直連接著主服務(wù)器,從服務(wù)器甚至可以通過撥號(hào)斷斷續(xù)續(xù)地連接主服務(wù)器。通過配置文件,可以指定復(fù)制所有的數(shù)據(jù)庫,某個(gè)數(shù)據(jù)庫,甚至是某個(gè)數(shù)據(jù)庫上的某個(gè)表。
為什么要做主從同步?
讀寫分離,使數(shù)據(jù)庫能支撐更大的并發(fā)。 在主服務(wù)器上生成實(shí)時(shí)數(shù)據(jù),而在從服務(wù)器上分析這些數(shù)據(jù),從而提高主服務(wù)器的性能。 數(shù)據(jù)備份,保證數(shù)據(jù)的安全。
樂觀鎖和悲觀鎖是什么?
數(shù)據(jù)庫中的并發(fā)控制是確保在多個(gè)事務(wù)同時(shí)存取數(shù)據(jù)庫中同一數(shù)據(jù)時(shí)不破壞事務(wù)的隔離性和統(tǒng)一性以及數(shù)據(jù)庫的統(tǒng)一性。樂觀鎖和悲觀鎖是并發(fā)控制主要采用的技術(shù)手段。
悲觀鎖:假定會(huì)發(fā)生并發(fā)沖突,在查詢完數(shù)據(jù)的時(shí)候就把事務(wù)鎖起來,直到提交事務(wù)。實(shí)現(xiàn)方式:使用數(shù)據(jù)庫中的鎖機(jī)制。 樂觀鎖:假設(shè)不會(huì)發(fā)生并發(fā)沖突,只在提交操作時(shí)檢查是否數(shù)據(jù)是否被修改過。給表增加 version字段,在修改提交之前檢查version與原來取到的version值是否相等,若相等,表示數(shù)據(jù)沒有被修改,可以更新,否則,數(shù)據(jù)為臟數(shù)據(jù),不能更新。實(shí)現(xiàn)方式:樂觀鎖一般使用版本號(hào)機(jī)制或CAS算法實(shí)現(xiàn)。
用過processlist嗎?
show processlist 或 show full processlist 可以查看當(dāng)前 MySQL 是否有壓力,正在運(yùn)行的SQL,有沒有慢SQL正在執(zhí)行。返回參數(shù)如下:
id:線程ID,可以用 kill id殺死某個(gè)線程db:數(shù)據(jù)庫名稱 user:數(shù)據(jù)庫用戶 host:數(shù)據(jù)庫實(shí)例的IP command:當(dāng)前執(zhí)行的命令,比如 Sleep,Query,Connect等time:消耗時(shí)間,單位秒 state:執(zhí)行狀態(tài),主要有以下狀態(tài): Sleep,線程正在等待客戶端發(fā)送新的請(qǐng)求Locked,線程正在等待鎖Sending data,正在處理SELECT查詢的記錄,同時(shí)把結(jié)果發(fā)送給客戶端Kill,正在執(zhí)行kill語句,殺死指定線程Connect,一個(gè)從節(jié)點(diǎn)連上了主節(jié)點(diǎn)Quit,線程正在退出Sorting for group,正在為GROUP BY做排序Sorting for order,正在為ORDER BY做排序info:正在執(zhí)行的 SQL語句
- END -
學(xué)習(xí)路上,難免遇到很多坑,為方便大家交流技術(shù)問題,我建了技術(shù)交流群,想進(jìn)群的小伙伴可以添加我的微信號(hào)『 i_am_dabin 』或者掃描下方的二維碼加我微信,我拉你進(jìn)群,一起學(xué)習(xí)成長!
往期推薦
