
MySQL 16 問(wèn)!
鏈接:https://blog.csdn.net/weixin_41645135/article/details/123676215


1.數(shù)據(jù)庫(kù)三大范式是什么?
第一范式:每個(gè)列都不可以再拆分。
第二范式:在第一范式的基礎(chǔ)上,非主鍵列完全依賴于主鍵,而不能是依賴于主鍵的一部分。
第三范式:在第二范式的基礎(chǔ)上,非主鍵列只依賴于主鍵,不依賴于其他非主鍵。
在設(shè)計(jì)數(shù)據(jù)庫(kù)結(jié)構(gòu)的時(shí)候,要盡量遵守三范式,如果不遵守,必須有足夠的理由。
比如性能。事實(shí)上我們經(jīng)常會(huì)為了性能而妥協(xié)數(shù)據(jù)庫(kù)的設(shè)計(jì)。
2.mysql有關(guān)權(quán)限的表都有哪幾個(gè)?
MySQL服務(wù)器通過(guò)權(quán)限表來(lái)控制用戶對(duì)數(shù)據(jù)庫(kù)的訪問(wèn),權(quán)限表存放在mysql數(shù)據(jù)庫(kù)里,由mysql_install_db腳本初始化。
這些權(quán)限表分別user,db,table_priv,columns_priv和host。
user權(quán)限表:記錄允許連接到服務(wù)器的用戶帳號(hào)信息,里面的權(quán)限是全局級(jí)的。
db權(quán)限表:記錄各個(gè)帳號(hào)在各個(gè)數(shù)據(jù)庫(kù)上的操作權(quán)限。
table_priv權(quán)限表:記錄數(shù)據(jù)表級(jí)的操作權(quán)限。
columns_priv權(quán)限表:記錄數(shù)據(jù)列級(jí)的操作權(quán)限。
host權(quán)限表:配合db權(quán)限表對(duì)給定主機(jī)上數(shù)據(jù)庫(kù)級(jí)操作權(quán)限作更細(xì)致的控制。
這個(gè)權(quán)限表不受GRANT和REVOKE語(yǔ)句的影響。
3. 事務(wù)的四大特性(ACID)介紹一下?
原子性:事務(wù)是最小的執(zhí)行單位,不允許分割。事務(wù)的原子性確保動(dòng)作要么全部完成,要么完全不起作用;
一致性:執(zhí)行事務(wù)前后,數(shù)據(jù)保持一致,多個(gè)事務(wù)對(duì)同一個(gè)數(shù)據(jù)讀取的結(jié)果是相同的;
隔離性:并發(fā)訪問(wèn)數(shù)據(jù)庫(kù)時(shí),一個(gè)用戶的事務(wù)不被其他事務(wù)所干擾,各并發(fā)事務(wù)之間數(shù)據(jù)庫(kù)是獨(dú)立的;
持久性:一個(gè)事務(wù)被提交之后。它對(duì)數(shù)據(jù)庫(kù)中數(shù)據(jù)的改變是持久的,即使數(shù)據(jù)庫(kù)發(fā)生故障也不應(yīng)該對(duì)其有任何影響。
4.索引設(shè)計(jì)的原則是什么?
適合索引的列是出現(xiàn)在where子句中的列,或者連接子句中指定的列
基數(shù)較小的類,索引效果較差,沒(méi)有必要在此列建立索引
使用短索引,如果對(duì)長(zhǎng)字符串列進(jìn)行索引,應(yīng)該指定一個(gè)前綴長(zhǎng)度,這樣能夠節(jié)省大量索引空間
不要過(guò)度索引,索引需要額外的磁盤空間,并降低寫操作的性能。在修改表內(nèi)容的時(shí)候,索引會(huì)進(jìn)行更新甚至重構(gòu),索引列越多,這個(gè)時(shí)間就會(huì)越長(zhǎng)。所以只保持需要的索引有利于查詢即可。
5.SQL語(yǔ)句主要分為哪幾類?
數(shù)據(jù)定義語(yǔ)言DDL(Data Ddefinition Language)CREATE,DROP,ALTER主要為以上操作 即對(duì)邏輯結(jié)構(gòu)等有操作的,其中包括表結(jié)構(gòu),視圖和索引。
數(shù)據(jù)查詢語(yǔ)言DQL(Data Query Language)SELECT 這個(gè)較為好理解 即查詢操作,以select關(guān)鍵字。各種簡(jiǎn)單查詢,連接查詢等 都屬于DQL。
數(shù)據(jù)操縱語(yǔ)言DML(Data Manipulation Language)INSERT,UPDATE,DELETE主要為以上操作 即對(duì)數(shù)據(jù)進(jìn)行操作的,對(duì)應(yīng)上面所說(shuō)的查詢操作 DQL與DML共同構(gòu)建了多數(shù)初級(jí)程序員常用的增刪改查操作。而查詢是較為特殊的一種 被劃分到DQL中。
數(shù)據(jù)控制功能DCL(Data Control Language)GRANT,REVOKE,COMMIT,ROLLBACK 主要為以上操作 即對(duì)數(shù)據(jù)庫(kù)安全性完整性等有操作的,可以簡(jiǎn)單的理解為權(quán)限控制等。
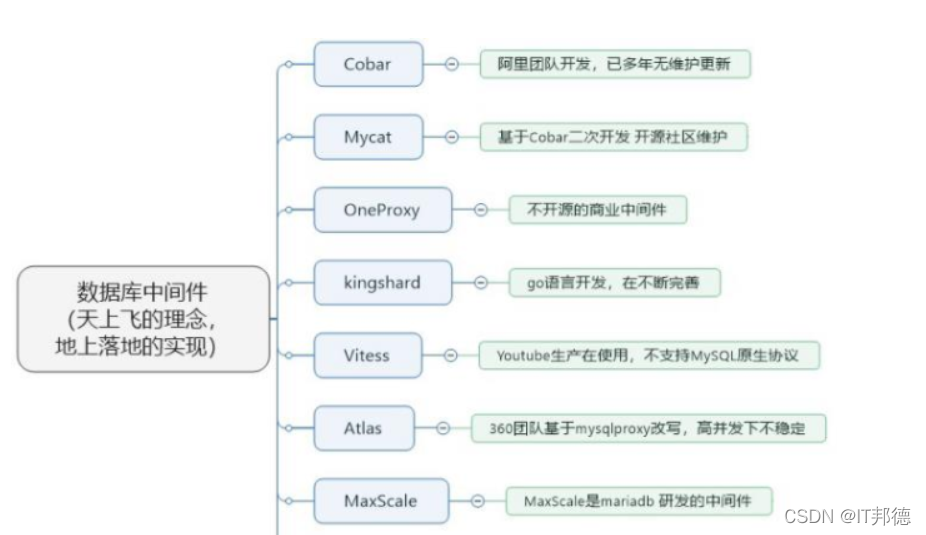
6.MySQL分庫(kù)分表的目的是?
分庫(kù)分表就是為了 解決由于數(shù)據(jù)量過(guò)大而導(dǎo)致數(shù)據(jù)庫(kù)性能降低的問(wèn)題,將原來(lái)獨(dú)立的數(shù)據(jù)庫(kù)拆分成若干數(shù)據(jù)庫(kù)組成,將數(shù)據(jù)大表拆分成若干數(shù)據(jù)表組成,使得單一數(shù)據(jù)庫(kù)、單一數(shù)據(jù)表的數(shù)據(jù)量變小,從而達(dá)到提升數(shù)據(jù)庫(kù)性能的目的。
分庫(kù)分表常用的中間件如下:
7. 什么是死鎖?怎么解決?
死鎖是指兩個(gè)或多個(gè)事務(wù)在同一資源上相互占用,并請(qǐng)求鎖定對(duì)方的資源,從而導(dǎo)致惡性循環(huán)的現(xiàn)象。
常見(jiàn)的解決死鎖的方法:
如果不同程序會(huì)并發(fā)存取多個(gè)表,盡量約定以相同的順序訪問(wèn)表,可以大大降低死鎖機(jī)會(huì)。
在同一個(gè)事務(wù)中,盡可能做到一次鎖定所需要的所有資源,減少死鎖產(chǎn)生概率;
對(duì)于非常容易產(chǎn)生死鎖的業(yè)務(wù)部分,可以嘗試使用升級(jí)鎖定顆粒度,通過(guò)表級(jí)鎖定來(lái)減少死鎖產(chǎn)生的概率;如果業(yè)務(wù)處理不好可以用分布式事務(wù)鎖或者使用樂(lè)觀鎖。
8. 什么是臟讀?幻讀?不可重復(fù)讀?
臟讀(Drity Read):某個(gè)事務(wù)已更新一份數(shù)據(jù),另一個(gè)事務(wù)在此時(shí)讀取了同一份數(shù)據(jù),由于某些原因,前一個(gè)RollBack了操作,則后一個(gè)事務(wù)所讀取的數(shù)據(jù)就會(huì)是不正確的。
不可重復(fù)讀(Non-repeatable read):在一個(gè)事務(wù)的兩次查詢之中數(shù)據(jù)不一致,這可能是兩次查詢過(guò)程中間插入了一個(gè)事務(wù)更新的原有的數(shù)據(jù)。
幻讀(Phantom Read):在一個(gè)事務(wù)的兩次查詢中數(shù)據(jù)筆數(shù)不一致,例如有一個(gè)事務(wù)查詢了幾列(Row)數(shù)據(jù),而另一個(gè)事務(wù)卻在此時(shí)插入了新的幾列數(shù)據(jù),先前的事務(wù)在接下來(lái)的查詢中,就會(huì)發(fā)現(xiàn)有幾列數(shù)據(jù)是它先前所沒(méi)有的。
9.視圖有哪些特點(diǎn)?
視圖的特點(diǎn)如下: 視圖的列可以來(lái)自不同的表,是表的抽象和在邏輯意義上建立的新關(guān)系。
視圖是由基本表(實(shí)表)產(chǎn)生的表(虛表)。視圖的建立和刪除不影響基本表。
對(duì)視圖內(nèi)容的更新(添加,刪除和修改)直接影響基本表。
當(dāng)視圖來(lái)自多個(gè)基本表時(shí),不允許添加和刪除數(shù)據(jù)。
視圖的操作包括創(chuàng)建視圖,查看視圖,刪除視圖和修改視圖。
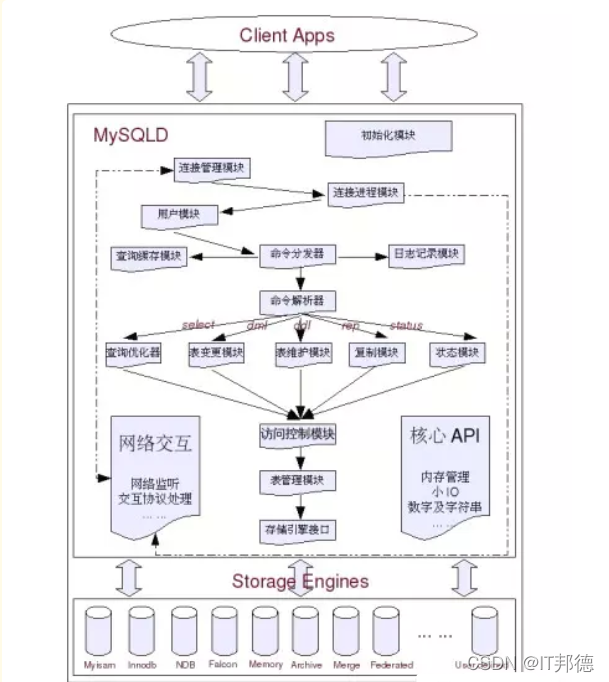
10.SQL的生命周期?
應(yīng)用服務(wù)器與數(shù)據(jù)庫(kù)服務(wù)器建立一個(gè)連接
數(shù)據(jù)庫(kù)進(jìn)程拿到請(qǐng)求sql
解析并生成執(zhí)行計(jì)劃,執(zhí)行
讀取數(shù)據(jù)到內(nèi)存并進(jìn)行邏輯處理
通過(guò)步驟一的連接,發(fā)送結(jié)果到客戶端
關(guān)掉連接,釋放資源
11.主鍵使用自增ID還是UUID?
推薦使用自增ID,不要使用UUID。因?yàn)樵贗nnoDB存儲(chǔ)引擎中,主鍵索引是作為聚簇索引存在的,也就是說(shuō),主鍵索引的B+樹(shù)葉子節(jié)點(diǎn)上存儲(chǔ)了主鍵索引以及全部的數(shù)據(jù)(按照順序),如果主鍵索引是自增ID,那么只需要不斷向后排列即可,如果是UUID,由于到來(lái)的ID與原來(lái)的大小不確定,會(huì)造成非常多的數(shù)據(jù)插入,數(shù)據(jù)移動(dòng),然后導(dǎo)致產(chǎn)生很多的內(nèi)存碎片,進(jìn)而造成插入性能的下降。
總之,在數(shù)據(jù)量大一些的情況下,用自增主鍵性能會(huì)好一些。關(guān)于主鍵是聚簇索引,如果沒(méi)有主鍵,InnoDB會(huì)選擇一個(gè)唯一鍵來(lái)作為聚簇索引,如果沒(méi)有唯一鍵,會(huì)生成一個(gè)隱式的主鍵。
12.MySQL數(shù)據(jù)庫(kù)cpu飆升到100%的話怎么處理?
當(dāng) cpu 飆升到 100%時(shí),先用操作系統(tǒng)命令 top 命令觀察是不是 mysqld 占用導(dǎo)致的,如果不是,找出占用高的進(jìn)程,并進(jìn)行相關(guān)處理。如果是 mysqld 造成的, show processlist,看看里面跑的 session 情況,是不是有消耗資源的 sql 在運(yùn)行。找出消耗高的 sql,看看執(zhí)行計(jì)劃是否準(zhǔn)確,index 是否缺失,或者實(shí)在是數(shù)據(jù)量太大造成。
一般來(lái)說(shuō),肯定要 kill 掉這些線程(同時(shí)觀察 cpu 使用率是否下降),等進(jìn)行相應(yīng)的調(diào)整(比如說(shuō)加索引、改 sql、改內(nèi)存參數(shù))之后,再重新跑這些 SQL。
也有可能是每個(gè) sql 消耗資源并不多,但是突然之間,有大量的 session 連進(jìn)來(lái)導(dǎo)致 cpu 飆升,這種情況就需要跟應(yīng)用一起來(lái)分析為何連接數(shù)會(huì)激增,再做出相應(yīng)的調(diào)整,比如說(shuō)限制連接數(shù)等。
13.MySQL主從復(fù)制解決了哪些問(wèn)題?
主從復(fù)制的作用是主數(shù)據(jù)庫(kù)出現(xiàn)問(wèn)題,可以切換到從數(shù)據(jù)庫(kù),可以進(jìn)行數(shù)據(jù)庫(kù)層面的讀寫分離,可以在從數(shù)據(jù)庫(kù)上進(jìn)行日常備份。
數(shù)據(jù)分布:隨意開(kāi)始或停止復(fù)制,并在不同地理位置分布數(shù)據(jù)備份
負(fù)載均衡:降低單個(gè)服務(wù)器的壓力
高可用和故障切換:幫助應(yīng)用程序避免單點(diǎn)失敗
升級(jí)測(cè)試:可以用更高版本的MySQL作為從庫(kù)
14.什么是MySQL的GTID?
TID(Global Transaction ID,全局事務(wù)ID)是全局事務(wù)標(biāo)識(shí)符,是一個(gè)已提交事務(wù)的編號(hào),并且是一個(gè)全局唯一的編號(hào)。
GTID是從MySQL 5.6版本開(kāi)始在主從復(fù)制方面推出的重量級(jí)特性。
GTID實(shí)際上是由UUID+TID組成的。其中UUID是一個(gè)MySQL實(shí)例的唯一標(biāo)識(shí)。
GTID代表了該實(shí)例上已經(jīng)提交的事務(wù)數(shù)量,并且隨著事務(wù)提交單調(diào)遞增。
GTID有如下幾點(diǎn)作用:
根據(jù)GTID可以知道事務(wù)最初是在哪個(gè)實(shí)例上提交的。
GTID的存在方便了Replication的Failover。
因?yàn)椴挥孟駛鹘y(tǒng)模式復(fù)制那樣去找master_log_file和master_log_pos。基于GTID搭建主從復(fù)制更加簡(jiǎn)單,確保每個(gè)事務(wù)只會(huì)被執(zhí)行一次。
15.MySQL常用的備份工具有哪些?
常用備份工具mysql復(fù)制
邏輯備份(mysqldump,mydumper)
物理備份(copy,xtrabackup)
備份工具差異對(duì)比
mysql復(fù)制相對(duì)于其他的備份來(lái)說(shuō),得到的備份數(shù)據(jù)比較實(shí)時(shí)。
邏輯備份:分表比較容易。
mysqldump備份數(shù)據(jù)時(shí)是將所有sql語(yǔ)句整合在同一個(gè)文件中;
mydumper備份數(shù)據(jù)時(shí)是將SQL語(yǔ)句按照表拆分成單個(gè)的sql文件,每個(gè)sql文件對(duì)應(yīng)一個(gè)完整的表。
物理備份:拷貝即可用,速度快。
copy:直接拷貝文件到數(shù)據(jù)目錄下,可能引起表?yè)p壞或者數(shù)據(jù)不一致。
xtrabackup對(duì)于innodb表是不需要鎖表的,對(duì)于myisam表仍然需要鎖表。
16.MySQL備份計(jì)劃如何制定
視庫(kù)的大小來(lái)定,一般來(lái)說(shuō) 100G 內(nèi)的庫(kù),可以考慮使用 mysqldump 來(lái)做,因?yàn)?mysqldump更加輕巧靈活,備份時(shí)間選在業(yè)務(wù)低峰期,可以每天進(jìn)行都進(jìn)行全量備份(mysqldump 備份出來(lái)的文件比較小,壓縮之后更小)。
100G 以上的庫(kù),可以考慮用 xtranbackup 來(lái)做,備份速度明顯要比 mysqldump 要快。
一般是選擇一周一個(gè)全備,其余每天進(jìn)行增量備份,備份時(shí)間為業(yè)務(wù)低峰期。
推薦閱讀:
最近 Github 上爆火的 Chrome 生產(chǎn)力神器 Omni 是什么鬼?
5T技術(shù)資源大放送!包括但不限于:C/C++,Linux,Python,Java,PHP,人工智能,單片機(jī),樹(shù)莓派,等等。在公眾號(hào)內(nèi)回復(fù)「1024」,即可免費(fèi)獲取!