
MySQL 高頻 100 問
點擊上方“Java金融”,選擇“設為星標”
后臺回復"888"獲取bat面試題集
本文主要受眾為開發(fā)人員,所以不涉及到MySQL的服務部署等操作,且內(nèi)容較多,大家準備好耐心和瓜子礦泉水.前一陣系統(tǒng)的學習了一下MySQL,也有一些實際操作經(jīng)驗,偶然看到一篇和MySQL相關的面試文章,發(fā)現(xiàn)其中的一些問題自己也回答不好,雖然知識點大部分都知道,但是無法將知識串聯(lián)起來.因此決定搞一個MySQL靈魂100問,試著用回答問題的方式,讓自己對知識點的理解更加深入一點.此文不會事無巨細的從select的用法開始講解mysql,主要針對的是開發(fā)人員需要知道的一些MySQL的知識點
hash索引進行等值查詢更快(一般情況下),但是卻無法進行范圍查詢.
hash索引不支持使用索引進行排序,原理同上.
hash索引不支持模糊查詢以及多列索引的最左前綴匹配.原理也是因為hash函數(shù)的不可預測.AAAA和AAAAB的索引沒有相關性.
hash索引任何時候都避免不了回表查詢數(shù)據(jù),而B+樹在符合某些條件(聚簇索引,覆蓋索引等)的時候可以只通過索引完成查詢.
hash索引雖然在等值查詢上較快,但是不穩(wěn)定.性能不可預測,當某個鍵值存在大量重復的時候,發(fā)生hash碰撞,此時效率可能極差.而B+樹的查詢效率比較穩(wěn)定,對于所有的查詢都是從根節(jié)點到葉子節(jié)點,且樹的高度較低.
select age from employee where age < 20的查詢時,在索引的葉子節(jié)點上,已經(jīng)包含了age信息,不會再次進行回表查詢.使用不等于查詢
列參與了數(shù)學運算或者函數(shù)
在字符串like時左邊是通配符.類似于'%aaa'.
當mysql分析全表掃描比使用索引快的時候不使用索引.
當使用聯(lián)合索引,前面一個條件為范圍查詢,后面的即使符合最左前綴原則,也無法使用索引.
事務相關
臟讀: A事務讀取到了B事務未提交的內(nèi)容,而B事務后面進行了回滾.
不可重復讀: 當設置A事務只能讀取B事務已經(jīng)提交的部分,會造成在A事務內(nèi)的兩次查詢,結(jié)果竟然不一樣,因為在此期間B事務進行了提交操作.
幻讀: A事務讀取了一個范圍的內(nèi)容,而同時B事務在此期間插入了一條數(shù)據(jù).造成"幻覺".
未提交讀(READ UNCOMMITTED)
已提交讀(READ COMMITTED)
REPEATABLE READ(可重復讀)
SERIALIZABLE(可串行化)
表結(jié)構(gòu)設計
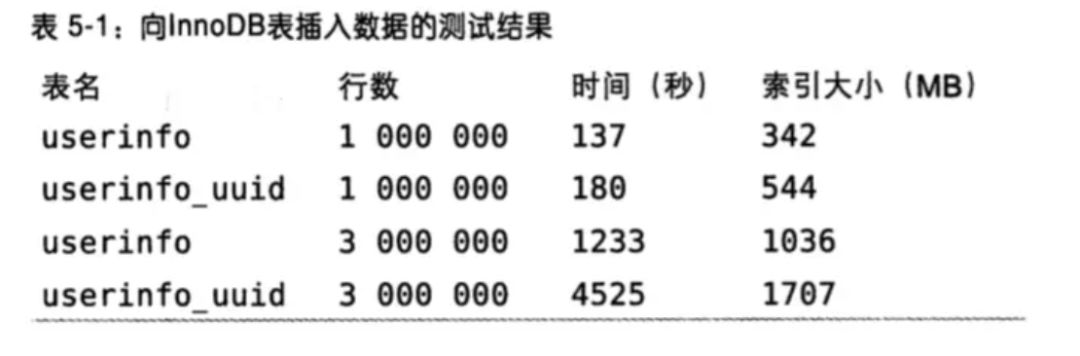
If you define a PRIMARY KEY on your table, InnoDB uses it as the clustered index.
If you do not define a PRIMARY KEY for your table, MySQL picks the first UNIQUE index that has only NOT NULL columns as the primary key and InnoDB uses it as the clustered index.
NULL columns require additional space in the rowto record whether their values are NULL. For MyISAM tables, each NULL columntakes one bit extra, rounded up to the nearest byte.
存儲引擎相關
InnoDB和MyISAM有什么區(qū)別?
InnoDB支持事物,而MyISAM不支持事物
InnoDB支持行級鎖,而MyISAM支持表級鎖
InnoDB支持MVCC, 而MyISAM不支持
InnoDB支持外鍵,而MyISAM不支持
InnoDB不支持全文索引,而MyISAM支持。
零散問題
char(10)的空間,那么無論實際存儲多少內(nèi)容.該字段都占用10個字符,而varchar是變長的statement模式下,記錄單元為語句.即每一個sql造成的影響會記錄.由于sql的執(zhí)行是有上下文的,因此在保存的時候需要保存相關的信息,同時還有一些使用了函數(shù)之類的語句無法被記錄復制.
row級別下,記錄單元為每一行的改動,基本是可以全部記下來但是由于很多操作,會導致大量行的改動(比如alter table),因此這種模式的文件保存的信息太多,日志量太大.
mixed. 一種折中的方案,普通操作使用statement記錄,當無法使用statement的時候使用row.
數(shù)據(jù)庫層面,這也是我們主要集中關注的(雖然收效沒那么大)
類似于
select * from table where age > 20 limit 1000000,10這種查詢其實也是有可以優(yōu)化的余地的.這條語句需要load1000000數(shù)據(jù)然后基本上全部丟棄,只取10條當然比較慢.
我們可以修改為
select * from table where id in (select id from table where age > 20 limit 1000000,10)這樣雖然也load了一百萬的數(shù)據(jù),但是由于索引覆蓋,要查詢的所有字段都在索引中,所以速度會很快.
同時如果ID連續(xù)的好,我們還可以
select * from table where id > 1000000 limit 10,效率也是不錯的優(yōu)化的可能性有許多種,但是核心思想都一樣,就是減少load的數(shù)據(jù).
從需求的角度減少這種請求….主要是不做類似的需求(直接跳轉(zhuǎn)到幾百萬頁之后的具體某一頁.只允許逐頁查看或者按照給定的路線走,這樣可預測,可緩存)以及防止ID泄漏且連續(xù)被人惡意攻擊.

首先分析語句,看看是否load了額外的數(shù)據(jù),可能是查詢了多余的行并且拋棄掉了,可能是加載了許多結(jié)果中并不需要的列,對語句進行分析以及重寫.
分析語句的執(zhí)行計劃,然后獲得其使用索引的情況,之后修改語句或者修改索引,使得語句可以盡可能的命中索引.
如果對語句的優(yōu)化已經(jīng)無法進行,可以考慮表中的數(shù)據(jù)量是否太大,如果是的話可以進行橫向或者縱向的分表.
id-摘要-內(nèi)容.而系統(tǒng)中的展示形式是刷新出一個列表,列表中僅包含標題和摘要id-摘要,id-內(nèi)容.當用戶點擊詳情,那主鍵再來取一次內(nèi)容即可.而增加的存儲量只是很小的主鍵字段.代價很小.