
ChatRWKV 學(xué)習(xí)筆記和使用指南
 在這里插入圖片描述0x0. 前言
在這里插入圖片描述0x0. 前言
Receptance Weighted Key Value(RWKV)是pengbo提出的一個(gè)新的語(yǔ)言模型架構(gòu),它使用了線性的注意力機(jī)制,把Transformer的高效并行訓(xùn)練與RNN的高效推理相結(jié)合,使得模型在訓(xùn)練期間可以并行,并在推理的時(shí)候保持恒定的計(jì)算和內(nèi)存復(fù)雜度。目前RWKV的社區(qū)已經(jīng)非常火了,我們從huggingface上可以看到RWKV已經(jīng)訓(xùn)練了多個(gè)百億參數(shù)的模型,特別是RWKV World模型支持世界所有語(yǔ)言的生成+對(duì)話+任務(wù)+代碼,功能十分全面。此外還有很多開(kāi)發(fā)者基于RWKV的微調(diào)模型。
 在部署方面RWKV社區(qū)也取得了長(zhǎng)足的發(fā)展,例如ChatRWKV,rwkv.cpp,RWKV-Runner,rwkv-cpp-cuda,同時(shí)包括mlc-llm,tgi等都支持了RWKV相關(guān)模型,社區(qū)進(jìn)展非常快。本文嘗試從ChatRWKV項(xiàng)目入門學(xué)習(xí)一下RWKV。
在部署方面RWKV社區(qū)也取得了長(zhǎng)足的發(fā)展,例如ChatRWKV,rwkv.cpp,RWKV-Runner,rwkv-cpp-cuda,同時(shí)包括mlc-llm,tgi等都支持了RWKV相關(guān)模型,社區(qū)進(jìn)展非常快。本文嘗試從ChatRWKV項(xiàng)目入門學(xué)習(xí)一下RWKV。
RWKV論文原文:https://arxiv.org/abs/2305.13048
0x1. 學(xué)習(xí)資料這里列出一些我看到的學(xué)習(xí)資料,方便感興趣的讀者學(xué)習(xí):
- [雙字] 在{Transformer}時(shí)代, {RWKV}是RNN的[文藝復(fù)興]--論文詳解(https://www.bilibili.com/video/BV11N411C76z/?spm_id_from=333.337.search-card.all.click&vd_source=4dffb0fbabed4311f4318e8c6d253a10)
- 野心勃勃的RNN——RWKV語(yǔ)言模型及其100行代碼極簡(jiǎn)實(shí)現(xiàn)(https://zhuanlan.zhihu.com/p/620469303)
- github倉(cāng)庫(kù)(https://github.com/BlinkDL/RWKV-LM)
- rwkv論文原理解讀(https://www.zhihu.com/question/602564718)
- RWKV的微調(diào)教學(xué),以及RWKV World:支持世界所有語(yǔ)言的生成+對(duì)話+任務(wù)+代碼(https://zhuanlan.zhihu.com/p/638326262)
- RWKV:用RNN達(dá)到Transformer性能,且支持并行模式和長(zhǎng)程記憶,既快又省顯存,已在14B參數(shù)規(guī)模檢驗(yàn)(https://zhuanlan.zhihu.com/p/599150009)
- 談?wù)?RWKV 系列的 prompt 設(shè)計(jì),模型選擇,解碼參數(shù)設(shè)置(https://zhuanlan.zhihu.com/p/639629050)
- RWKV進(jìn)展:一鍵生成論文,純CPU高速INT4,純CUDA脫離pytorch,ctx8192不耗顯存不變慢(https://zhuanlan.zhihu.com/p/626083366)
- 開(kāi)源1.5/3/7B中文小說(shuō)模型:顯存3G就能跑7B模型,幾行代碼即可調(diào)用(https://zhuanlan.zhihu.com/p/609154637)
- 發(fā)布幾個(gè)RWKV的Chat模型(包括英文和中文)7B/14B歡迎大家玩(https://zhuanlan.zhihu.com/p/618011122)
- 實(shí)例:手寫 CUDA 算子,讓 Pytorch 提速 20 倍(某特殊算子)(https://zhuanlan.zhihu.com/p/476297195)
- BlinkDL/RWKV-World-7B gradio demo(https://huggingface.co/spaces/BlinkDL/RWKV-World-7B/tree/main)
- ChatRWKV(有可用貓娘模型!)微調(diào)/部署/使用/訓(xùn)練資源合集(https://zhuanlan.zhihu.com/p/616351661)
- pengbo的專欄(https://www.zhihu.com/people/bopengbopeng/posts)
原理推薦看第一個(gè)和第二個(gè)鏈接,其它的有選擇觀看,我這里就以ChatRWKV項(xiàng)目的解析為例來(lái)入門RWKV。
0x2. RWKV in 150 lines下面這個(gè)文件 https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_in_150_lines.py 以150行代碼實(shí)現(xiàn)了RWKV-4-Pile-430M這個(gè)模型,是學(xué)習(xí)RWKV的最佳代碼,所以讓這一節(jié)就是來(lái)逐步解析一下這個(gè)代碼。分析代碼之前先對(duì)RWKV這個(gè)名字的含義和組成RWKV模型2個(gè)關(guān)鍵的元素Time Mixing和Channel Mixing簡(jiǎn)單描述一下,詳細(xì)的原理還是請(qǐng)參考原始論文和第一節(jié)學(xué)習(xí)資料的第一個(gè)視頻鏈接和第四個(gè)原理和公式詳解的文字鏈接。
0x2.1 RWKV名字含義
論文中對(duì)名字有說(shuō)明:
- R: Receptance vector acting as the acceptance of past information. 類似于LSTM的“門控單元”
- W: Weight is the positional weight decay vector. A trainable model parameter. 可學(xué)習(xí)的位置權(quán)重衰減向量,什么叫“位置權(quán)重衰減”看下面的公式(14)
- K: Key is a vector analogous to K in traditional attention. 與傳統(tǒng)自注意力機(jī)制
- V : Value is a vector analogous to V in traditional attention. 與傳統(tǒng)自注意力機(jī)制相同
0x2.2 RWKV模型架構(gòu)
RWKV模型由一系列RWKV Block模塊堆疊而成,RWKV Block的結(jié)構(gòu)如下圖所示: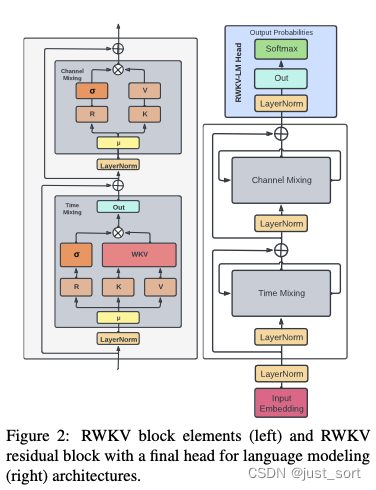
RWKV Block又主要由Time Mixing和Channel Mixing組成。
Time Mixing模塊的公式定義如下:
這里的表示當(dāng)前時(shí)刻,看成當(dāng)前的token,而看成前一個(gè)token,、、的計(jì)算與傳統(tǒng)Attention機(jī)制類似,通過(guò)將當(dāng)前輸入token與前一時(shí)刻輸入token做線性插值,體現(xiàn)了recurrence的特性。然后的計(jì)算則是對(duì)應(yīng)注意力機(jī)制的實(shí)現(xiàn),這個(gè)實(shí)現(xiàn)也是一個(gè)過(guò)去時(shí)刻信息與當(dāng)前時(shí)刻信息的線性插值,注意到這里是指數(shù)形式并且當(dāng)前token和之前的所有token都有一個(gè)指數(shù)衰減求和的關(guān)系,也正是因?yàn)檫@樣讓擁有了線性attention的特性。
然后RWKV模型里面除了使用Time Mixing建模這種Token間的關(guān)系之外,在Token內(nèi)對(duì)應(yīng)的隱藏層維度上RWKV也進(jìn)行了建模,即通過(guò)Channel Mixing模塊。
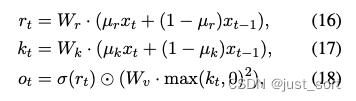 在這里插入圖片描述
在這里插入圖片描述
Channel Mixing的意思就是在特征維度上做融合。假設(shè)特征向量維度是d,那么每一個(gè)維度的元素都要接收其他維度的信息,來(lái)更新它自己。特征向量的每個(gè)維度就是一個(gè)“channel”(通道)。
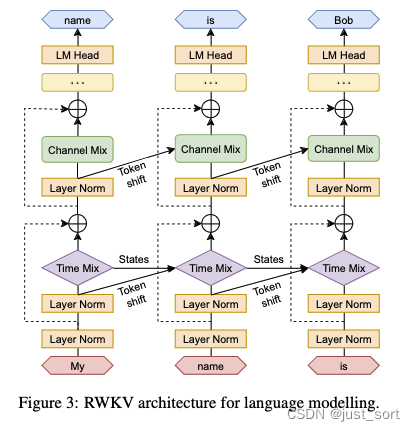
下圖展示了RWKV模型整體的結(jié)構(gòu):
 在這里插入圖片描述
在這里插入圖片描述
這里提到的token shift就是上面對(duì)r, k, v計(jì)算的時(shí)候類似于卷積滑窗的過(guò)程。然后我們可以看到當(dāng)前的token不僅僅剋呀通過(guò)Time Mixing的token shit和隱藏狀態(tài)States(即)和之前的token建立聯(lián)系,也可以通過(guò)Channel Mixing的token shift和之前的token建立聯(lián)系,類似于擁有了全局感受野。
0x2.3 RWKV_in_150_lines.py 解析
初始化部分
首先來(lái)看RWKV模型初始化部分以及最開(kāi)始的一些準(zhǔn)備工作:
########################################################################################################
# The RWKV Language Model - https://github.com/BlinkDL/RWKV-LM
########################################################################################################
# 導(dǎo)入庫(kù)
import numpy as np
# 這行代碼設(shè)置了numpy數(shù)組的打印格式,其中precision=4表示小數(shù)點(diǎn)后保留4位,
# suppress=True表示抑制小數(shù)點(diǎn)的科學(xué)計(jì)數(shù)法表示,linewidth=200表示每行的字符寬度為200。
np.set_printoptions(precision=4, suppress=True, linewidth=200)
import types, torch
from torch.nn import functional as F
from tokenizers import Tokenizer
# 加載一個(gè)分詞器
tokenizer = Tokenizer.from_file("20B_tokenizer.json")
# 使用types.SimpleNamespace()創(chuàng)建一個(gè)簡(jiǎn)單的命名空間對(duì)象args,并為其設(shè)置以下屬性:
args = types.SimpleNamespace()
# 模型的路徑。
args.MODEL_NAME = '/fsx/BlinkDL/HF-MODEL/rwkv-4-pile-430m/RWKV-4-Pile-430M-20220808-8066'
args.n_layer = 24 # 模型的層數(shù)。
args.n_embd = 1024 # 模型的嵌入維度。
# 定義了需要續(xù)寫的字符串,描述了科學(xué)家在西藏的一個(gè)偏遠(yuǎn)山谷中發(fā)現(xiàn)了一群會(huì)說(shuō)流利中文的龍的情況。
context = "\nIn a shocking finding, scientist discovered a herd of dragons living in a remote, previously unexplored valley, in Tibet. Even more surprising to the researchers was the fact that the dragons spoke perfect Chinese."
NUM_TRIALS = 3 # 嘗試生成文本的次數(shù)。
LENGTH_PER_TRIAL = 100 # 每次嘗試生成的文本長(zhǎng)度。
TEMPERATURE = 1.0 # 控制生成文本的隨機(jī)性的參數(shù)。值越大,生成的文本越隨機(jī);值越小,生成的文本越確定。
TOP_P = 0.85 # 在生成文本時(shí),只考慮累積概率超過(guò)此值的詞匯。
########################################################################################################
class RWKV_RNN(torch.jit.ScriptModule):
def __init__(self, args):
super().__init__()
# 將傳入的args參數(shù)賦值給類的屬性args。
self.args = args
# 將模型設(shè)置為評(píng)估模式,這意味著模型中的dropout和batchnorm將被禁用。
self.eval() # set torch to inference mode
# 從指定路徑加載模型權(quán)重,并確保權(quán)重被加載到CPU上。
w = torch.load(args.MODEL_NAME + '.pth', map_location='cpu')
# 這幾行代碼對(duì)加載的權(quán)重進(jìn)行了處理。它們檢查權(quán)重的鍵名,并根據(jù)鍵名對(duì)權(quán)重進(jìn)行不同的操作。
for k in w.keys():
if '.time_' in k: w[k] = w[k].squeeze()
if '.time_decay' in k: w[k] = -torch.exp(w[k].float()) # the real time decay is like e^{-e^x}
else: w[k] = w[k].float() # convert to f32 type
# 創(chuàng)建一個(gè)新的命名空間對(duì)象,并將其賦值給self.w。
self.w = types.SimpleNamespace() # set self.w from w
# 在self.w中創(chuàng)建一個(gè)名為blocks的字典。
self.w.blocks = {}
# for k in w.keys(): - 遍歷字典w的所有鍵。注釋中的例子
# "blocks.0.att.time_first" => self.w.blocks[0].att.time_first"
# 說(shuō)明了代碼的目標(biāo):將點(diǎn)分隔的鍵轉(zhuǎn)換為嵌套的屬性訪問(wèn)。
for k in w.keys(): # example: "blocks.0.att.time_first" => self.w.blocks[0].att.time_first
parts = k.split('.') # 使用.作為分隔符將鍵k分割成多個(gè)部分,并將結(jié)果存儲(chǔ)在parts列表中。
last = parts.pop() # 從parts列表中彈出最后一個(gè)元素并存儲(chǔ)在last中。這將是要設(shè)置的屬性的名稱。
# 初始化一個(gè)變量here,它將用于遍歷或創(chuàng)建self.w中的嵌套命名空間。
here = self.w
# 遍歷parts列表中的每個(gè)部分。
for p in parts:
# 檢查當(dāng)前部分p是否是數(shù)字。
if p.isdigit():
p = int(p)
# 如果當(dāng)前數(shù)字鍵p不在here中,則在here中為其創(chuàng)建一個(gè)新的命名空間。
if p not in here: here[p] = types.SimpleNamespace()
# 更新here以指向新創(chuàng)建的或已存在的命名空間。
here = here[p]
# 如果當(dāng)前部分p不是數(shù)字。
else:
# 如果here沒(méi)有名為p的屬性,則為其創(chuàng)建一個(gè)新的命名空間。
if not hasattr(here, p): setattr(here, p, types.SimpleNamespace())
here = getattr(here, p)
setattr(here, last, w[k])
這部分除了準(zhǔn)備一些模型執(zhí)行需要的超參數(shù)之外,還對(duì)RWKV模型進(jìn)行了初始化,值得注意的是在初始化過(guò)程中會(huì)加載RWKV模型的權(quán)重到w這個(gè)字典里面,然后遍歷字典w的所有鍵。注釋中的例子"blocks.0.att.time_first" => self.w.blocks[0].att.time_first" 說(shuō)明了代碼的目標(biāo):將點(diǎn)分隔的鍵轉(zhuǎn)換為嵌套的屬性訪問(wèn)。后面推理的時(shí)候?qū)?huì)直接訪問(wèn)self.w這個(gè)處理之后的權(quán)重對(duì)象。
RWKV 模型通道融合函數(shù)(Channel mixing)
@torch.jit.script_method
def channel_mixing(self, x, state, i:int, time_mix_k, time_mix_r, kw, vw, rw):
xk = x * time_mix_k + state[5*i+0] * (1 - time_mix_k)
xr = x * time_mix_r + state[5*i+0] * (1 - time_mix_r)
state[5*i+0] = x
r = torch.sigmoid(rw @ xr)
k = torch.square(torch.relu(kw @ xk)) # square relu, primer paper
return r * (vw @ k)
參考Channel Mixing的公式來(lái)看:
在這里插入圖片描述
在channel_mixing函數(shù)里面,對(duì)應(yīng)當(dāng)前token的詞嵌入向量,表示前一個(gè)token的詞嵌入向量。剩下的變量都是RWKV的可學(xué)習(xí)參數(shù)。然后代碼里面會(huì)動(dòng)態(tài)更新state,讓總是當(dāng)前token的前一個(gè)token的詞嵌入。
RWKV Time mixing函數(shù)
@torch.jit.script_method
def time_mixing(self, x, state, i:int, time_mix_k, time_mix_v, time_mix_r, time_first, time_decay, kw, vw, rw, ow):
xk = x * time_mix_k + state[5*i+1] * (1 - time_mix_k)
xv = x * time_mix_v + state[5*i+1] * (1 - time_mix_v)
xr = x * time_mix_r + state[5*i+1] * (1 - time_mix_r)
state[5*i+1] = x
r = torch.sigmoid(rw @ xr)
k = kw @ xk
v = vw @ xv
aa = state[5*i+2]
bb = state[5*i+3]
pp = state[5*i+4]
ww = time_first + k
qq = torch.maximum(pp, ww)
e1 = torch.exp(pp - qq)
e2 = torch.exp(ww - qq)
a = e1 * aa + e2 * v
b = e1 * bb + e2
wkv = a / b
ww = pp + time_decay
qq = torch.maximum(ww, k)
e1 = torch.exp(ww - qq)
e2 = torch.exp(k - qq)
state[5*i+2] = e1 * aa + e2 * v
state[5*i+3] = e1 * bb + e2
state[5*i+4] = qq
return ow @ (r * wkv)
仍然是要對(duì)照公式來(lái)看:
然后這里有一個(gè)trick,就是對(duì)的計(jì)算可以寫成RNN的遞歸形式: 這樣上面的公式就很清晰了,還需要注意的是在實(shí)現(xiàn)的時(shí)候由于有exp的存在,為了保證數(shù)值穩(wěn)定性實(shí)現(xiàn)的時(shí)候減去了每個(gè)公式涉及到的e的指數(shù)部分的Max。
這樣上面的公式就很清晰了,還需要注意的是在實(shí)現(xiàn)的時(shí)候由于有exp的存在,為了保證數(shù)值穩(wěn)定性實(shí)現(xiàn)的時(shí)候減去了每個(gè)公式涉及到的e的指數(shù)部分的Max。
關(guān)于RWKV 的attention部分()計(jì)算如果你有細(xì)節(jié)不清楚,建議觀看一下這個(gè)視頻:解密RWKV線性注意力的進(jìn)化過(guò)程(https://www.bilibili.com/video/BV1zW4y1D7Qg/?spm_id_from=333.337.search-card.all.click&vd_source=4dffb0fbabed4311f4318e8c6d253a10) 。
RWKV model forward函數(shù)
# 定義forward方法,它接受兩個(gè)參數(shù):token和state。
def forward(self, token, state):
# 這是一個(gè)上下文管理器,確保在此代碼塊中不會(huì)計(jì)算任何梯度。
# 這通常用于評(píng)估模式,以提高性能并避免不必要的計(jì)算。
with torch.no_grad():
# 如果state為None,則初始化state為一個(gè)全零張量。
# 其形狀由self.args.n_layer和self.args.n_embd確定。
if state == None:
state = torch.zeros(self.args.n_layer * 5, self.args.n_embd)
# 遍歷每一層,并將state的特定位置設(shè)置為-1e30(表示負(fù)無(wú)窮大)。
for i in range(self.args.n_layer): state[5*i+4] = -1e30 # -infinity
# 使用token索引self.w.emb.weight,獲取詞嵌入向量。
x = self.w.emb.weight[token]
# 對(duì)獲取的詞嵌入向量x應(yīng)用層歸一化。
x = self.layer_norm(x, self.w.blocks[0].ln0)
for i in range(self.args.n_layer):
att = self.w.blocks[i].att # 獲取當(dāng)前層的注意力參數(shù)
# 這些行使用time_mixing方法對(duì)x進(jìn)行處理,并將結(jié)果加到x上。
x = x + self.time_mixing(self.layer_norm(x, self.w.blocks[i].ln1), state, i,
att.time_mix_k, att.time_mix_v, att.time_mix_r, att.time_first, att.time_decay,
att.key.weight, att.value.weight, att.receptance.weight, att.output.weight)
ffn = self.w.blocks[i].ffn # 獲取當(dāng)前層的前饋網(wǎng)絡(luò)參數(shù)。
# 使用channel_mixing方法對(duì)x進(jìn)行處理,并將結(jié)果加到x上。
x = x + self.channel_mixing(self.layer_norm(x, self.w.blocks[i].ln2), state, i,
ffn.time_mix_k, ffn.time_mix_r,
ffn.key.weight, ffn.value.weight, ffn.receptance.weight)
# 對(duì)x應(yīng)用最后的層歸一化,并與self.w.head.weight進(jìn)行矩陣乘法。
x = self.w.head.weight @ self.layer_norm(x, self.w.ln_out)
return x.float(), state
從這里可以看到RWKV的state只和層數(shù)和嵌入層維度有關(guān)系,和序列長(zhǎng)度是無(wú)關(guān)的,這是推理時(shí)相比于RNN的核心優(yōu)點(diǎn)。
采樣函數(shù)
# 這段代碼是一個(gè)用于生成隨機(jī)樣本的函數(shù)。
# 這是一個(gè)函數(shù)定義,函數(shù)名為 sample_logits,接受三個(gè)參數(shù) out、temperature
# 和 top_p,其中 temperature 默認(rèn)值為 1.0,top_p 默認(rèn)值為 0.8。
def sample_logits(out, temperature=1.0, top_p=0.8):
# 這行代碼使用 softmax 函數(shù)對(duì) out 進(jìn)行操作,將輸出轉(zhuǎn)換為概率分布。
# dim=-1 表示在最后一個(gè)維度上進(jìn)行 softmax 操作。.numpy() 將結(jié)果轉(zhuǎn)換為 NumPy 數(shù)組。
probs = F.softmax(out, dim=-1).numpy()
# 這行代碼使用 NumPy 的 np.sort 函數(shù)對(duì)概率分布進(jìn)行排序,
# 并通過(guò) [::-1] 實(shí)現(xiàn)降序排列。結(jié)果保存在 sorted_probs 變量中。
sorted_probs = np.sort(probs)[::-1]
# 這行代碼計(jì)算累積概率,使用 NumPy 的 np.cumsum 函數(shù)對(duì) sorted_probs
# 進(jìn)行累加操作。結(jié)果保存在 cumulative_probs 變量中。
cumulative_probs = np.cumsum(sorted_probs)
# 這行代碼通過(guò)比較 cumulative_probs 是否大于 top_p 來(lái)找到概率分布中的截?cái)帱c(diǎn)。
# np.argmax 返回第一個(gè)滿足條件的索引,float() 將其轉(zhuǎn)換為浮點(diǎn)數(shù)并保存在 cutoff 變量中。
cutoff = float(sorted_probs[np.argmax(cumulative_probs > top_p)])
# 這行代碼將低于 cutoff 的概率值設(shè)為 0,即將概率分布中小于截?cái)帱c(diǎn)的概率置零。
probs[probs < cutoff] = 0
# 這段代碼根據(jù) temperature 的取值對(duì)概率分布進(jìn)行調(diào)整。
# 如果 temperature 不等于 1.0,則將概率分布的每個(gè)元素取倒數(shù)的 1.0 / temperature 次冪。
if temperature != 1.0:
probs = probs.pow(1.0 / temperature)
# 這行代碼將概率分布?xì)w一化,確保所有概率的總和為 1。
probs = probs / np.sum(probs)
# 這行代碼使用 np.random.choice 函數(shù)根據(jù)概率分布 probs 生成一個(gè)隨機(jī)樣本,
# a=len(probs) 表示可選的樣本范圍為 probs 的長(zhǎng)度,p=probs 表示每個(gè)樣本被選中的概率。
out = np.random.choice(a=len(probs), p=probs)
# 函數(shù)返回生成的隨機(jī)樣本。
return out
這個(gè)函數(shù)的作用是根據(jù)給定的概率分布 out 生成一個(gè)隨機(jī)樣本,通過(guò)調(diào)整溫度 temperature 和頂部概率 top_p 來(lái)控制生成的樣本的多樣性和穩(wěn)定性。
生成文本的流程
# 打印使用 CPU 加載模型的信息,其中 args.MODEL_NAME 是模型名稱。
print(f'\nUsing CPU. Loading {args.MODEL_NAME} ...')
# 創(chuàng)建一個(gè)名為 model 的 RWKV_RNN 模型實(shí)例,參數(shù)為 args。
model = RWKV_RNN(args)
# 打印預(yù)處理上下文信息的提示,提示使用的是較慢的版本。然后初始化 init_state 為 None。
print(f'\nPreprocessing context (slow version. see v2/rwkv/model.py for fast version)')
init_state = None
# 對(duì)上下文進(jìn)行分詞編碼,并使用模型的 forward 方法逐個(gè)處理分詞編碼的 tokens,
# 將結(jié)果保存在 init_out 和 init_state 中。
for token in tokenizer.encode(context).ids:
init_out, init_state = model.forward(token, init_state)
# 使用循環(huán)進(jìn)行多次試驗(yàn)(NUM_TRIALS 次)。
for TRIAL in range(NUM_TRIALS):
# 在每次試驗(yàn)的開(kāi)始打印試驗(yàn)信息和上下文。創(chuàng)建一個(gè)空列表 all_tokens 用于保存生成的 tokens。
print(f'\n\n--[ Trial {TRIAL} ]-----------------', context, end="")
all_tokens = []
# 初始化變量 out_last 為 0,out 和 state 分別為 init_out 和 init_state 的克隆。
out_last = 0
out, state = init_out.clone(), init_state.clone()
# 在每個(gè)試驗(yàn)中,使用循環(huán)生成 LENGTH_PER_TRIAL 個(gè) tokens。
for i in range(LENGTH_PER_TRIAL):
# 調(diào)用 sample_logits 函數(shù)生成一個(gè)隨機(jī) token,并將其添加到 all_tokens 列表中。
token = sample_logits(out, TEMPERATURE, TOP_P)
all_tokens += [token]
# 使用 tokenizer.decode 將 all_tokens[out_last:] 解碼為文本,
# 并檢查解碼結(jié)果是否包含無(wú)效的 utf-8 字符('\ufffd')。如果結(jié)果有效,則將其打印出來(lái)。
tmp = tokenizer.decode(all_tokens[out_last:])
if '\ufffd' not in tmp: # only print when we have a valid utf-8 string
print(tmp, end="", flush=True)
out_last = i + 1
# 調(diào)用模型的 forward 方法,將生成的 token 和當(dāng)前的狀態(tài)傳遞給模型,獲取更新的 out 和 state。
out, state = model.forward(token, state)
print('\n')
這段代碼的目的是使用 RWKV_RNN 模型生成文本,模型通過(guò) sample_logits 函數(shù)生成隨機(jī) token,然后將其傳遞給模型進(jìn)行預(yù)測(cè),并根據(jù)預(yù)測(cè)結(jié)果生成下一個(gè) token,不斷重復(fù)這個(gè)過(guò)程直到生成指定數(shù)量的 tokens。生成的文本會(huì)被打印出來(lái)。
0x3. ChatRWKV v2聊天系統(tǒng)邏輯實(shí)現(xiàn)解析ChatRWKV的README中提到v2版本實(shí)現(xiàn)了一些新功能,建議我們使用,v2版本的代碼在 https://github.com/BlinkDL/ChatRWKV/tree/main/v2 。我們這一節(jié)就對(duì)這部分的代碼做一個(gè)解讀。
chat.py解析
https://github.com/BlinkDL/ChatRWKV/blob/main/v2/chat.py是ChatRWKV v2的核心實(shí)現(xiàn),我們直接來(lái)看這個(gè)文件。
########################################################################################################
# The RWKV Language Model - https://github.com/BlinkDL/RWKV-LM
########################################################################################################
# os、copy、types、gc、sys:這些是Python標(biāo)準(zhǔn)庫(kù),
# 用于操作系統(tǒng)功能、對(duì)象復(fù)制、類型管理、垃圾回收和系統(tǒng)特定的參數(shù)和函數(shù)。
import os, copy, types, gc, sys
current_path = os.path.dirname(os.path.abspath(__file__))
sys.path.append(f'{current_path}/../rwkv_pip_package/src')
import numpy as np
# prompt_toolkit中的prompt:用于構(gòu)建命令行界面的庫(kù)。
from prompt_toolkit import prompt
# 腳本嘗試根據(jù)傳遞給腳本的命令行參數(shù)設(shè)置CUDA_VISIBLE_DEVICES環(huán)境變量。
try:
os.environ["CUDA_VISIBLE_DEVICES"] = sys.argv[1]
except:
pass
# 調(diào)用np.set_printoptions()函數(shù)設(shè)置NumPy數(shù)組的打印選項(xiàng)。它配置精度、抑制小值和輸出行的最大寬度。
np.set_printoptions(precision=4, suppress=True, linewidth=200)
args = types.SimpleNamespace()
# 腳本打印有關(guān)ChatRWKV版本的信息。
print('\n\nChatRWKV v2 https://github.com/BlinkDL/ChatRWKV')
import torch
# 針對(duì)PyTorch設(shè)置了幾個(gè)配置,以優(yōu)化其在GPU上的性能。
torch.backends.cudnn.benchmark = True
torch.backends.cudnn.allow_tf32 = True
torch.backends.cuda.matmul.allow_tf32 = True
# 有一些被注釋的行代表不同的設(shè)置,可以嘗試優(yōu)化性能。這些設(shè)置與PyTorch的即時(shí)編譯(JIT)和融合有關(guān)。
# Tune these below (test True/False for all of them) to find the fastest setting:
# torch._C._jit_set_profiling_executor(True)
# torch._C._jit_set_profiling_mode(True)
# torch._C._jit_override_can_fuse_on_cpu(True)
# torch._C._jit_override_can_fuse_on_gpu(True)
# torch._C._jit_set_texpr_fuser_enabled(False)
# torch._C._jit_set_nvfuser_enabled(False)
########################################################################################################
#
# 有一些注釋解釋了不同的模型精度選項(xiàng)(fp16、fp32、bf16、xxxi8)及其影響。
# fp16 = good for GPU (!!! DOES NOT support CPU !!!)
# fp32 = good for CPU
# bf16 = less accuracy, supports some CPUs
# xxxi8 (example: fp16i8) = xxx with int8 quantization to save 50% VRAM/RAM, slightly less accuracy
#
# Read https://pypi.org/project/rwkv/ for Strategy Guide
#
########################################################################################################
這段代碼設(shè)置了必要的依賴項(xiàng),配置了GPU使用環(huán)境,并提供了有關(guān)RWKV語(yǔ)言模型及其精度選項(xiàng)的信息。
# 這個(gè)變量用于設(shè)置模型推理的策略。在代碼中有幾個(gè)不同的策略選項(xiàng)被注釋掉了,
# 而實(shí)際選擇的策略是 'cuda fp16',表示使用CUDA加速并使用半精度浮點(diǎn)數(shù)進(jìn)行計(jì)算。
# args.strategy = 'cpu fp32'
args.strategy = 'cuda fp16'
# args.strategy = 'cuda:0 fp16 -> cuda:1 fp16'
# args.strategy = 'cuda fp16i8 *10 -> cuda fp16'
# args.strategy = 'cuda fp16i8'
# args.strategy = 'cuda fp16i8 -> cpu fp32 *10'
# args.strategy = 'cuda fp16i8 *10+'
# 這兩個(gè)變量設(shè)置了環(huán)境變量。RWKV_JIT_ON 控制是否啟用即時(shí)編譯(JIT),
# RWKV_CUDA_ON 控制是否編譯CUDA內(nèi)核。在代碼中,RWKV_CUDA_ON 被設(shè)置為0,即不編譯CUDA內(nèi)核。
os.environ["RWKV_JIT_ON"] = '1' # '1' or '0', please use torch 1.13+ and benchmark speed
os.environ["RWKV_CUDA_ON"] = '0' # '1' to compile CUDA kernel (10x faster), requires c++ compiler & cuda libraries
# 這個(gè)變量設(shè)置了聊天系統(tǒng)使用的語(yǔ)言,可以選擇英語(yǔ)('English')、中文('Chinese')或日語(yǔ)('Japanese')。
CHAT_LANG = 'English' # English // Chinese // more to come
# 這個(gè)變量設(shè)置了模型的名稱和路徑。根據(jù)選擇的語(yǔ)言不同,會(huì)有不同的模型名稱被設(shè)置。
# 模型名稱指定了模型文件的位置,以及其他一些相關(guān)信息。
# Download RWKV models from https://huggingface.co/BlinkDL
# Use '/' in model path, instead of '\'
# Use convert_model.py to convert a model for a strategy, for faster loading & saves CPU RAM
if CHAT_LANG == 'English':
args.MODEL_NAME = '/fsx/BlinkDL/HF-MODEL/rwkv-4-raven/RWKV-4-Raven-14B-v12-Eng98%-Other2%-20230523-ctx8192'
# args.MODEL_NAME = '/fsx/BlinkDL/HF-MODEL/rwkv-4-raven/RWKV-4-Raven-7B-v12-Eng98%-Other2%-20230521-ctx8192'
# args.MODEL_NAME = '/fsx/BlinkDL/HF-MODEL/rwkv-4-pile-14b/RWKV-4-Pile-14B-20230313-ctx8192-test1050'
elif CHAT_LANG == 'Chinese': # Raven系列可以對(duì)話和 +i 問(wèn)答。Novel系列是小說(shuō)模型,請(qǐng)只用 +gen 指令續(xù)寫。
args.MODEL_NAME = '/fsx/BlinkDL/HF-MODEL/rwkv-4-raven/RWKV-4-Raven-7B-v12-Eng49%-Chn49%-Jpn1%-Other1%-20230530-ctx8192'
# args.MODEL_NAME = '/fsx/BlinkDL/HF-MODEL/rwkv-4-world/RWKV-4-World-CHNtuned-3B-v1-20230625-ctx4096'
# args.MODEL_NAME = '/fsx/BlinkDL/HF-MODEL/rwkv-4-novel/RWKV-4-Novel-7B-v1-ChnEng-20230426-ctx8192'
elif CHAT_LANG == 'Japanese':
# args.MODEL_NAME = '/fsx/BlinkDL/HF-MODEL/rwkv-4-raven/RWKV-4-Raven-14B-v8-EngAndMore-20230408-ctx4096'
args.MODEL_NAME = '/fsx/BlinkDL/HF-MODEL/rwkv-4-raven/RWKV-4-Raven-7B-v10-Eng89%-Jpn10%-Other1%-20230420-ctx4096'
# -1.py for [User & Bot] (Q&A) prompt
# -2.py for [Bob & Alice] (chat) prompt
# 這個(gè)變量設(shè)置了模型的名稱和路徑。根據(jù)選擇的語(yǔ)言不同,會(huì)有不同的模型名稱被設(shè)置。
# 模型名稱指定了模型文件的位置,以及其他一些相關(guān)信息。
PROMPT_FILE = f'{current_path}/prompt/default/{CHAT_LANG}-2.py'
# 代碼中還包含了一些其他參數(shù)的設(shè)置,如聊天長(zhǎng)度的限制、生成文本的參數(shù)(溫度、top-p值等)、重復(fù)懲罰等。
CHAT_LEN_SHORT = 40
CHAT_LEN_LONG = 150
FREE_GEN_LEN = 256
# For better chat & QA quality: reduce temp, reduce top-p, increase repetition penalties
# Explanation: https://platform.openai.com/docs/api-reference/parameter-details
# 這個(gè)變量用于控制生成文本的溫度。通過(guò)調(diào)整溫度值,可以控制生成文本的隨機(jī)性和多樣性。
# 在代碼中設(shè)置為1.2,表示較高的溫度,可以增加生成文本的多樣性。
GEN_TEMP = 1.2 # It could be a good idea to increase temp when top_p is low
# 這個(gè)變量用于控制生成文本的top-p值。Top-p是一種生成文本的策略,
# 它限制了生成文本中概率最高的單詞的累積概率。
# 通過(guò)減小top-p值,可以提高生成文本的準(zhǔn)確性和一致性。在代碼中設(shè)置為0.5,表示較低的top-p值。
GEN_TOP_P = 0.5 # Reduce top_p (to 0.5, 0.2, 0.1 etc.) for better Q&A accuracy (and less diversity)
# 這兩個(gè)變量分別控制生成文本中重復(fù)內(nèi)容的懲罰權(quán)重。
# GEN_alpha_presence 控制了存在性懲罰的權(quán)重,即生成文本中重復(fù)內(nèi)容的懲罰程度。
# GEN_alpha_frequency 控制了頻率懲罰的權(quán)重,即生成文本中連續(xù)重復(fù)內(nèi)容的懲罰程度。
# 在代碼中,它們都被設(shè)置為0.4。
GEN_alpha_presence = 0.4 # Presence Penalty
GEN_alpha_frequency = 0.4 # Frequency Penalty
# 這個(gè)變量控制了重復(fù)懲罰的衰減率。通過(guò)減小衰減率,可以使重復(fù)懲罰在生成文本的后續(xù)部分逐漸減弱。
# 在代碼中設(shè)置為0.996。
GEN_penalty_decay = 0.996
# 這個(gè)變量設(shè)置了一些標(biāo)點(diǎn)符號(hào),用于表示要避免在生成文本中重復(fù)的內(nèi)容。
# 在代碼中,它包含了中文的逗號(hào)、冒號(hào)、問(wèn)號(hào)和感嘆號(hào)。
AVOID_REPEAT = ',:?!'
# 這個(gè)變量用于將輸入分成多個(gè)塊,以節(jié)省顯存(VRAM)。在代碼中設(shè)置為256。
CHUNK_LEN = 256 # split input into chunks to save VRAM (shorter -> slower)
# 這個(gè)變量包含了模型的名稱和路徑。根據(jù)代碼中的注釋,可以看到有幾個(gè)不同的模型路徑被設(shè)置。
# 根據(jù)具體情況,會(huì)選擇其中一個(gè)模型路徑。
# args.MODEL_NAME = '/fsx/BlinkDL/HF-MODEL/rwkv-4-world/RWKV-4-World-CHNtuned-0.1B-v1-20230617-ctx4096'
# args.MODEL_NAME = '/fsx/BlinkDL/HF-MODEL/rwkv-4-world/RWKV-4-World-CHNtuned-0.4B-v1-20230618-ctx4096'
# args.MODEL_NAME = '/fsx/BlinkDL/HF-MODEL/rwkv-4-world/RWKV-4-World-3B-v1-20230619-ctx4096'
if args.MODEL_NAME.endswith('/'): # for my own usage
if 'rwkv-final.pth' in os.listdir(args.MODEL_NAME):
args.MODEL_NAME = args.MODEL_NAME + 'rwkv-final.pth'
else:
latest_file = sorted([x for x in os.listdir(args.MODEL_NAME) if x.endswith('.pth')], key=lambda x: os.path.getctime(os.path.join(args.MODEL_NAME, x)))[-1]
args.MODEL_NAME = args.MODEL_NAME + latest_file
這段代碼相當(dāng)于配置文件,來(lái)設(shè)置RWKV聊天系統(tǒng)的運(yùn)行參數(shù)和模型信息。根據(jù)選擇的語(yǔ)言不同,會(huì)加載相應(yīng)的模型,并設(shè)置相應(yīng)的參數(shù)。
########################################################################################################
# 這行代碼用于打印一個(gè)字符串,包含了 CHAT_LANG、args.strategy 和 PROMPT_FILE 的值。
# 它會(huì)在控制臺(tái)輸出當(dāng)前的語(yǔ)言、策略和提示文件的信息。
print(f'\n{CHAT_LANG} - {args.strategy} - {PROMPT_FILE}')
# 導(dǎo)入 RWKV 模型
from rwkv.model import RWKV
# 這行代碼導(dǎo)入了 PIPELINE 工具,用于處理模型的輸入和輸出。
from rwkv.utils import PIPELINE
# 用于加載提示文件的內(nèi)容并返回相應(yīng)的變量。
def load_prompt(PROMPT_FILE):
# 該函數(shù)首先創(chuàng)建了一個(gè)空的字典 variables,然后使用 open 函數(shù)打開(kāi) PROMPT_FILE 文件。
variables = {}
# 下來(lái),使用 exec 函數(shù)將文件內(nèi)容編譯并執(zhí)行,將結(jié)果存儲(chǔ)在 variables 字典中。
with open(PROMPT_FILE, 'rb') as file:
exec(compile(file.read(), PROMPT_FILE, 'exec'), variables)
# 然后,從 variables 字典中獲取了 user、bot、interface 和 init_prompt 的值。
# init_prompt 被處理為一個(gè)列表,去除了多余的空格和換行符,并在開(kāi)頭和結(jié)尾添加了換行符。
# 最后,函數(shù)返回獲取的變量。
user, bot, interface, init_prompt = variables['user'], variables['bot'], variables['interface'], variables['init_prompt']
init_prompt = init_prompt.strip().split('\n')
for c in range(len(init_prompt)):
init_prompt[c] = init_prompt[c].strip().strip('\u3000').strip('\r')
init_prompt = '\n' + ('\n'.join(init_prompt)).strip() + '\n\n'
return user, bot, interface, init_prompt
# Load Model
# 這行代碼用于打印一個(gè)字符串,指示正在加載模型,并輸出 args.MODEL_NAME 的值。
print(f'Loading model - {args.MODEL_NAME}')
# 這行代碼創(chuàng)建了一個(gè) RWKV 模型對(duì)象,使用指定的模型路徑 args.MODEL_NAME 和策略 args.strategy。
model = RWKV(model=args.MODEL_NAME, strategy=args.strategy)
# 根據(jù) args.MODEL_NAME 的值,選擇了不同的分詞器和特殊標(biāo)記。
# 如果模型路徑中包含 'world/' 或 '-World-',則使用 "rwkv_vocab_v20230424" 的分詞器,
# 并設(shè)置了 END_OF_TEXT 和 END_OF_LINE 的值。
# 否則,使用 current_path(當(dāng)前路徑)和 "20B_tokenizer.json" 的分詞器,
# 并設(shè)置了 END_OF_TEXT、END_OF_LINE 和 END_OF_LINE_DOUBLE 的值。
if 'world/' in args.MODEL_NAME or '-World-' in args.MODEL_NAME:
pipeline = PIPELINE(model, "rwkv_vocab_v20230424")
END_OF_TEXT = 0
END_OF_LINE = 11
else:
pipeline = PIPELINE(model, f"{current_path}/20B_tokenizer.json")
END_OF_TEXT = 0
END_OF_LINE = 187
END_OF_LINE_DOUBLE = 535
# pipeline = PIPELINE(model, "cl100k_base")
# END_OF_TEXT = 100257
# END_OF_LINE = 198
# 這行代碼創(chuàng)建了一個(gè)空的列表 model_tokens,用于存儲(chǔ)模型的輸入token。
model_tokens = []
model_state = None
# 這行代碼創(chuàng)建了一個(gè)空的列表 AVOID_REPEAT_TOKENS,用于存儲(chǔ)避免重復(fù)的標(biāo)記。
AVOID_REPEAT_TOKENS = []
for i in AVOID_REPEAT:
# 在循環(huán)內(nèi)部,將當(dāng)前元素 i 使用 pipeline.encode 函數(shù)進(jìn)行編碼,
# 并將結(jié)果添加到 AVOID_REPEAT_TOKENS 列表中。
# 這樣,AVOID_REPEAT_TOKENS 列表中存儲(chǔ)了避免重復(fù)的token的編碼。
dd = pipeline.encode(i)
assert len(dd) == 1
AVOID_REPEAT_TOKENS += dd
這段代碼的主要功能是加載和配置RWKV模型,并準(zhǔn)備生成文本所需的參數(shù)和工具。繼續(xù)解析:
########################################################################################################
# 這是一個(gè)函數(shù)定義,用于以RNN模式運(yùn)行RWKV模型生成文本。
def run_rnn(tokens, newline_adj = 0):
# 這行代碼聲明在函數(shù)內(nèi)部使用全局變量 model_tokens 和 model_state。
global model_tokens, model_state
# 將輸入的token列表轉(zhuǎn)換為整數(shù)類型。
tokens = [int(x) for x in tokens]
# 將輸入的標(biāo)記列表添加到全局變量 model_tokens 中。
model_tokens += tokens
# print(f'### model ###\n{tokens}\n[{pipeline.decode(model_tokens)}]')
# 當(dāng)token列表的長(zhǎng)度大于0時(shí),執(zhí)行以下操作:
while len(tokens) > 0:
# 使用模型的前向傳播函數(shù) model.forward 對(duì)token列表的前
# CHUNK_LEN 個(gè)token進(jìn)行推理,并更新模型狀態(tài)。
out, model_state = model.forward(tokens[:CHUNK_LEN], model_state)
# 將token列表更新為剩余的token。
tokens = tokens[CHUNK_LEN:]
# 將輸出概率向量中的換行符標(biāo)記 END_OF_LINE 的概率增加 newline_adj,用于調(diào)整換行的概率。
out[END_OF_LINE] += newline_adj # adjust \n probability
# 如果模型最后一個(gè)標(biāo)記在避免重復(fù)標(biāo)記列表 AVOID_REPEAT_TOKENS 中,執(zhí)行以下操作:
if model_tokens[-1] in AVOID_REPEAT_TOKENS:
# 將輸出概率向量中模型最后一個(gè)標(biāo)記對(duì)應(yīng)的概率設(shè)置為一個(gè)極小的值,用于避免模型生成重復(fù)的標(biāo)記。
out[model_tokens[-1]] = -999999999
return out
all_state = {}
# 這是一個(gè)函數(shù)定義,用于保存模型狀態(tài)和token列表。
def save_all_stat(srv, name, last_out):
# 創(chuàng)建保存狀態(tài)的鍵名。
n = f'{name}_{srv}'
all_state[n] = {} # 創(chuàng)建一個(gè)空的字典,用于保存模型狀態(tài)和token列表。
all_state[n]['out'] = last_out # 將最后的輸出概率向量保存到字典中。
all_state[n]['rnn'] = copy.deepcopy(model_state) # 將深拷貝后的模型狀態(tài)保存到字典中。
all_state[n]['token'] = copy.deepcopy(model_tokens) # 將深拷貝后的token列表保存到字典中。
# 這是一個(gè)函數(shù)定義,用于加載保存的模型狀態(tài)和標(biāo)記列表。
def load_all_stat(srv, name):
# 這行代碼聲明在函數(shù)內(nèi)部使用全局變量 model_tokens 和 model_state。
global model_tokens, model_state
# 獲取保存狀態(tài)的鍵名。
n = f'{name}_{srv}'
# 將保存的模型狀態(tài)深拷貝給全局變量 model_state。
model_state = copy.deepcopy(all_state[n]['rnn'])
# 將保存的token列表深拷貝給全局變量 model_tokens。
model_tokens = copy.deepcopy(all_state[n]['token'])
return all_state[n]['out']
# Model only saw '\n\n' as [187, 187] before, but the tokenizer outputs [535] for it at the end
# 這是一個(gè)函數(shù)定義,用于修復(fù)token列表。
def fix_tokens(tokens):
# 根據(jù)模型路徑是否包含 'world/' 或 '-World-',執(zhí)行以下操作:
if 'world/' in args.MODEL_NAME or '-World-' in args.MODEL_NAME:
# 如果是,則返回原始的標(biāo)記列表 tokens,無(wú)需修復(fù)。
return tokens
# 如果不是,則檢查標(biāo)記列表的最后一個(gè)標(biāo)記是否為 END_OF_LINE_DOUBLE,
# 如果是,則將標(biāo)記列表中的最后一個(gè)標(biāo)記替換為 END_OF_LINE 重復(fù)兩次。
if len(tokens) > 0 and tokens[-1] == END_OF_LINE_DOUBLE:
tokens = tokens[:-1] + [END_OF_LINE, END_OF_LINE]
return tokens
########################################################################################################
這段代碼定義了以RNN模式運(yùn)行RWKV的函數(shù)以及保存和恢復(fù)模型狀態(tài)的函數(shù),最后還定義了一個(gè)修復(fù)tokens的工具函數(shù)用于對(duì)world模型和其它模型分別進(jìn)行處理,繼續(xù)解析:
########################################################################################################
# Run inference
print(f'\nRun prompt...') # 打印提示信息 "Run prompt..."。
# 調(diào)用 load_prompt 函數(shù)加載提示文件,將返回的用戶、機(jī)器人、界面和初始提示內(nèi)容
# 分別賦值給變量 user、bot、interface 和 init_prompt。
user, bot, interface, init_prompt = load_prompt(PROMPT_FILE)
# 調(diào)用 fix_tokens 函數(shù)修復(fù)初始提示內(nèi)容的標(biāo)記列表,并將修復(fù)后的標(biāo)記列表傳遞給 run_rnn 函數(shù)進(jìn)行推理。
# 將生成的輸出概率向量賦值給變量 out。
out = run_rnn(fix_tokens(pipeline.encode(init_prompt)))
# 調(diào)用 save_all_stat 函數(shù)保存模型狀態(tài)和標(biāo)記列表,鍵名為 'chat_init',值為 out。
save_all_stat('', 'chat_init', out)
# 執(zhí)行垃圾回收和清空GPU緩存的操作。
gc.collect()
torch.cuda.empty_cache()
# 創(chuàng)建一個(gè)服務(wù)器列表 srv_list,其中包含一個(gè)名為 'dummy_server' 的服務(wù)器。
srv_list = ['dummy_server']
# 遍歷服務(wù)器列表,對(duì)于每個(gè)服務(wù)器,調(diào)用 save_all_stat 函數(shù)保存模型狀態(tài)和token列表,
# 鍵名包含服務(wù)器名和 'chat',值為 out。
for s in srv_list:
save_all_stat(s, 'chat', out)
# 定義一個(gè)名為 reply_msg 的函數(shù),該函數(shù)接受一個(gè)參數(shù) msg,并打印機(jī)器人、界面和回復(fù)消息。
def reply_msg(msg):
print(f'{bot}{interface} {msg}\n')
# 這段代碼定義了一個(gè)名為 on_message 的函數(shù),用于處理接收到的消息。
def on_message(message):
# 聲明在函數(shù)內(nèi)部使用全局變量 model_tokens、model_state、user、bot、interface 和 init_prompt。
global model_tokens, model_state, user, bot, interface, init_prompt
# 將字符串 'dummy_server' 賦值給變量 srv。
srv = 'dummy_server'
# 將接收到的消息中的轉(zhuǎn)義字符 '\\n' 替換為換行符 '\n',并去除首尾空白字符,將結(jié)果賦值給變量 msg。
msg = message.replace('\\n','\n').strip()
x_temp = GEN_TEMP
x_top_p = GEN_TOP_P
# 如果消息中包含 -temp=,執(zhí)行以下操作:
# a. 從消息中提取 -temp= 后面的值,并將其轉(zhuǎn)換為浮點(diǎn)數(shù)類型賦值給 x_temp。
# 從消息中移除 -temp= 部分。
if ("-temp=" in msg):
x_temp = float(msg.split("-temp=")[1].split(" ")[0])
msg = msg.replace("-temp="+f'{x_temp:g}', "")
# print(f"temp: {x_temp}")
if ("-top_p=" in msg):
x_top_p = float(msg.split("-top_p=")[1].split(" ")[0])
msg = msg.replace("-top_p="+f'{x_top_p:g}', "")
# print(f"top_p: {x_top_p}")
# 如果 x_temp 小于等于 0.2,將其設(shè)置為 0.2。
if x_temp <= 0.2:
x_temp = 0.2
# 如果 x_temp 大于等于 5,將其設(shè)置為 5。
if x_temp >= 5:
x_temp = 5
# 如果 x_top_p 小于等于 0,將其設(shè)置為 0。
if x_top_p <= 0:
x_top_p = 0
# 去除消息首尾空白字符。
msg = msg.strip()
# 如果消息等于 '+reset':
if msg == '+reset':
# 加載保存的初始模型狀態(tài)并將其保存為 out。
out = load_all_stat('', 'chat_init')
# 保存模型狀態(tài)和token列表。
save_all_stat(srv, 'chat', out)
# 調(diào)用 reply_msg 函數(shù)打印回復(fù)消息 "Chat reset."。
reply_msg("Chat reset.")
return
# use '+prompt {path}' to load a new prompt
# 如果消息以 '+prompt ' 開(kāi)頭
elif msg[:8].lower() == '+prompt ':
# 打印 "Loading prompt..."。
print("Loading prompt...")
try:
# 提取消息中 'prompt ' 后面的內(nèi)容作為提示文件路徑,并將其賦值給變量 PROMPT_FILE。
PROMPT_FILE = msg[8:].strip()
# 加載提示文件,將返回的用戶、機(jī)器人、界面和初始提示內(nèi)容分別賦值給變量
# user、bot、interface 和 init_prompt。
user, bot, interface, init_prompt = load_prompt(PROMPT_FILE)
# 對(duì)prompt編碼和推理
out = run_rnn(fix_tokens(pipeline.encode(init_prompt)))
# 保存模型狀態(tài)和token列表。
save_all_stat(srv, 'chat', out)
# 打印 "Prompt set up."。
print("Prompt set up.")
gc.collect()
torch.cuda.empty_cache()
except:
# 捕獲異常,打印 "Path error."。
print("Path error.")
# 如果消息以 '+gen '、'+i '、'+qa '、'+qq '、'+++' 或 '++' 開(kāi)頭,執(zhí)行以下操作:
elif msg[:5].lower() == '+gen ' or msg[:3].lower() == '+i ' or msg[:4].lower() == '+qa ' or msg[:4].lower() == '+qq ' or msg.lower() == '+++' or msg.lower() == '++':
if msg[:5].lower() == '+gen ':
# 提取消息中 'gen ' 后面的內(nèi)容作為新的提示內(nèi)容,并將其賦值給變量 new。
new = '\n' + msg[5:].strip()
# print(f'### prompt ###\n[{new}]')
# 將模型狀態(tài)和標(biāo)記列表重置為空。
model_state = None
model_tokens = []
# 運(yùn)行RNN模型進(jìn)行推理,生成回復(fù)的輸出概率向量,并將其保存為 out。
out = run_rnn(pipeline.encode(new))
# 保存模型狀態(tài)和token列表。
save_all_stat(srv, 'gen_0', out)
elif msg[:3].lower() == '+i ':
# 提取消息中 'i ' 后面的內(nèi)容作為新的指令,并將其賦值給變量 msg。
msg = msg[3:].strip().replace('\r\n','\n').replace('\n\n','\n')
# 替換指令中的換行符,將 '\r\n' 替換為 '\n',將連續(xù)的兩個(gè)換行符 '\n\n' 替換為單個(gè)換行符 '\n'。
# 構(gòu)建新的提示內(nèi)容 new,包括指令和響應(yīng)模板。
new = f'''
Below is an instruction that describes a task. Write a response that appropriately completes the request.
# Instruction:
{msg}
# Response:
'''
# print(f'### prompt ###\n[{new}]')
# 將模型狀態(tài)和token列表重置為空。
model_state = None
model_tokens = []
# 運(yùn)行RNN模型進(jìn)行推理,生成回復(fù)的輸出概率向量,并將其保存為 out。
out = run_rnn(pipeline.encode(new))
# 保存模型狀態(tài)和token列表。
save_all_stat(srv, 'gen_0', out)
elif msg[:4].lower() == '+qq ':
# 提取消息中 'qq ' 后面的內(nèi)容作為新的問(wèn)題,構(gòu)建新的提示內(nèi)容 new,包括問(wèn)題和回答模板。
new = '\nQ: ' + msg[4:].strip() + '\nA:'
# print(f'### prompt ###\n[{new}]')
# 將模型狀態(tài)和token列表重置為空。
model_state = None
model_tokens = []
# 運(yùn)行RNN模型進(jìn)行推理,生成回復(fù)的輸出概率向量,并將其保存為 out。
out = run_rnn(pipeline.encode(new))
# 保存模型狀態(tài)和token列表。
save_all_stat(srv, 'gen_0', out)
elif msg[:4].lower() == '+qa ':
# 加載保存的初始模型狀態(tài)并將其保存為 out。
out = load_all_stat('', 'chat_init')
# 提取消息中 'qa ' 后面的內(nèi)容作為真實(shí)消息,并將其賦值給變量 real_msg。
real_msg = msg[4:].strip()
# 構(gòu)建新的提示內(nèi)容 new,包括用戶、界面、真實(shí)消息和機(jī)器人。
new = f"{user}{interface} {real_msg}\n\n{bot}{interface}"
# print(f'### qa ###\n[{new}]')
# 運(yùn)行RNN模型進(jìn)行推理,生成回復(fù)的輸出概率向量,并將其保存為 out。
out = run_rnn(pipeline.encode(new))
# 保存模型狀態(tài)和token列表。
save_all_stat(srv, 'gen_0', out)
elif msg.lower() == '+++':
try:
# 加載保存的模型狀態(tài) gen_1 并將其保存為 out。
out = load_all_stat(srv, 'gen_1')
# 保存模型狀態(tài)和token列表。
save_all_stat(srv, 'gen_0', out)
except:
return
elif msg.lower() == '++':
try:
# 加載保存的模型狀態(tài) gen_0 并將其保存為 out。
out = load_all_stat(srv, 'gen_0')
except:
return
# 將變量 begin 設(shè)置為 model_tokens 的長(zhǎng)度。
begin = len(model_tokens)
# 將變量 out_last 設(shè)置為 begin。
out_last = begin
# 創(chuàng)建一個(gè)空字典 occurrence。
occurrence = {}
# 循環(huán) FREE_GEN_LEN+100 次,其中 FREE_GEN_LEN 是一個(gè)常量,代表自由生成的長(zhǎng)度。
for i in range(FREE_GEN_LEN+100):
# 遍歷字典 occurrence 中的鍵。
for n in occurrence:
# 將 out[n] 減去一個(gè)計(jì)算得到的重復(fù)懲罰項(xiàng)。
out[n] -= (GEN_alpha_presence + occurrence[n] * GEN_alpha_frequency)
# 使用 pipeline.sample_logits 函數(shù)根據(jù)概率向量 out 生成一個(gè)標(biāo)記,并將其賦值給 token。
token = pipeline.sample_logits(
out,
temperature=x_temp,
top_p=x_top_p,
)
# 如果 token 等于 END_OF_TEXT,跳出內(nèi)層循環(huán)。
if token == END_OF_TEXT:
break
# 遍歷字典 occurrence 中的鍵。將 occurrence[xxx] 乘以一個(gè)常量 GEN_penalty_decay
for xxx in occurrence:
occurrence[xxx] *= GEN_penalty_decay
# 如果 token 不在 occurrence 中,將 occurrence[token] 設(shè)置為 1。
if token not in occurrence:
occurrence[token] = 1
else:
# 否則+1,表示這個(gè)token重復(fù)次數(shù)+1
occurrence[token] += 1
# 如果 msg[:4].lower() == '+qa ',調(diào)用 run_rnn 函數(shù),
# 傳遞 [token] 作為參數(shù),并將返回值賦值給變量 out。
if msg[:4].lower() == '+qa ':# or msg[:4].lower() == '+qq ':
out = run_rnn([token], newline_adj=-2)
else:
# 調(diào)用 run_rnn 函數(shù),傳遞 [token] 作為參數(shù),并將返回值賦值給變量 out。
out = run_rnn([token])
# 使用 pipeline.decode 函數(shù)將 model_tokens[out_last:] 解碼為字符串,并將結(jié)果賦值給 xxx。
xxx = pipeline.decode(model_tokens[out_last:])
# 如果字符串 '\ufffd' 不在 xxx 中
if '\ufffd' not in xxx: # avoid utf-8 display issues
# 打印 xxx,并刷新輸出緩沖區(qū)。
print(xxx, end='', flush=True)
# 將 out_last 設(shè)置為 begin + i + 1。
out_last = begin + i + 1
# 如果 i 大于等于 FREE_GEN_LEN,跳出外層循環(huán)。
if i >= FREE_GEN_LEN:
break
print('\n')
# send_msg = pipeline.decode(model_tokens[begin:]).strip()
# print(f'### send ###\n[{send_msg}]')
# reply_msg(send_msg)
# 調(diào)用 save_all_stat 函數(shù),將參數(shù) srv、'gen_1' 和 out 傳遞給它。
save_all_stat(srv, 'gen_1', out)
else:
# 如果 msg.lower() == '+'
if msg.lower() == '+':
try:
# 嘗試加載狀態(tài)信息 load_all_stat(srv, 'chat_pre')。
out = load_all_stat(srv, 'chat_pre')
except:
return
else:
# 加載狀態(tài)信息 load_all_stat(srv, 'chat'),并將結(jié)果賦值給變量 out。
out = load_all_stat(srv, 'chat')
# 對(duì)消息 msg 進(jìn)行處理,去除首尾空格,替換換行符,
msg = msg.strip().replace('\r\n','\n').replace('\n\n','\n')
# 并構(gòu)造新的消息字符串 new,其中包括用戶和機(jī)器人的標(biāo)識(shí)符。
new = f"{user}{interface} {msg}\n\n{bot}{interface}"
# print(f'### add ###\n[{new}]')
# 調(diào)用 run_rnn 函數(shù),傳遞 pipeline.encode(new) 作為參數(shù),并將返回值賦值給變量 out。
out = run_rnn(pipeline.encode(new), newline_adj=-999999999)
# 將生成的狀態(tài)信息 out 保存為 'chat_pre' 的狀態(tài)信息。
save_all_stat(srv, 'chat_pre', out)
# 這里開(kāi)始的內(nèi)容和上一個(gè)elif里面的基本一致,就不重復(fù)解析了
begin = len(model_tokens)
out_last = begin
print(f'{bot}{interface}', end='', flush=True)
occurrence = {}
for i in range(999):
if i <= 0:
newline_adj = -999999999
elif i <= CHAT_LEN_SHORT:
newline_adj = (i - CHAT_LEN_SHORT) / 10
elif i <= CHAT_LEN_LONG:
newline_adj = 0
else:
newline_adj = min(3, (i - CHAT_LEN_LONG) * 0.25) # MUST END THE GENERATION
for n in occurrence:
out[n] -= (GEN_alpha_presence + occurrence[n] * GEN_alpha_frequency)
token = pipeline.sample_logits(
out,
temperature=x_temp,
top_p=x_top_p,
)
# if token == END_OF_TEXT:
# break
for xxx in occurrence:
occurrence[xxx] *= GEN_penalty_decay
if token not in occurrence:
occurrence[token] = 1
else:
occurrence[token] += 1
out = run_rnn([token], newline_adj=newline_adj)
out[END_OF_TEXT] = -999999999 # disable <|endoftext|>
xxx = pipeline.decode(model_tokens[out_last:])
if '\ufffd' not in xxx: # avoid utf-8 display issues
print(xxx, end='', flush=True)
out_last = begin + i + 1
send_msg = pipeline.decode(model_tokens[begin:])
if '\n\n' in send_msg:
send_msg = send_msg.strip()
break
# send_msg = pipeline.decode(model_tokens[begin:]).strip()
# if send_msg.endswith(f'{user}{interface}'): # warning: needs to fix state too !!!
# send_msg = send_msg[:-len(f'{user}{interface}')].strip()
# break
# if send_msg.endswith(f'{bot}{interface}'):
# send_msg = send_msg[:-len(f'{bot}{interface}')].strip()
# break
# print(f'{model_tokens}')
# print(f'[{pipeline.decode(model_tokens)}]')
# print(f'### send ###\n[{send_msg}]')
# reply_msg(send_msg)
save_all_stat(srv, 'chat', out)
########################################################################################################
總的來(lái)看,這段代碼是一個(gè)循環(huán),用于ChatRWKV系統(tǒng)生成回復(fù)消息和更新?tīng)顟B(tài)信息。它根據(jù)輸入消息和模型的狀態(tài)信息進(jìn)行一個(gè)RNN模式的推理,生成一個(gè)回復(fù)的token和一個(gè)新的狀態(tài),然后將生成的回復(fù)顯示出來(lái),生成的狀態(tài)則可以在下一次生成中繼續(xù)使用。代碼還包括處理特殊命令以及加載和保存狀態(tài)信息的邏輯。
0x3. ChatRWKV v2聊天系統(tǒng)指南- 直接說(shuō)話:聊天,用 + 換個(gè)回答
- reset: 通過(guò)發(fā)送+reset消息,您可以重置聊天。
- 加載新的提示: 使用+prompt {path}可以加載一個(gè)新的提示,其中{path}是提示文件的路徑。
- 消息類型:
- +gen {text}: 基于{text}生成新的內(nèi)容。
- +i {instruction}: 根據(jù)給定的指令{instruction}產(chǎn)生一個(gè)響應(yīng)。
- +qq {question}: 對(duì)于給定的問(wèn)題{question},生成一個(gè)答案。
- +qa {text}: 將{text}作為一個(gè)問(wèn)題,并生成一個(gè)答案。
- +++: 繼續(xù)寫下去。
- ++: 換個(gè)寫法。
除了這些指令之外,還可以調(diào)整生成參數(shù):
- -temp=: 調(diào)整生成的溫度。溫度影響生成文本的隨機(jī)性。較高的溫度將導(dǎo)致更多的隨機(jī)輸出,而較低的溫度將導(dǎo)致更確定的輸出。
- -top_p=: 調(diào)整Top-P采樣。Top-P采樣是選擇詞匯中概率最高的一部分詞進(jìn)行采樣的方法。
這篇文章還有一些ChatRWKV v2系統(tǒng)的模型實(shí)現(xiàn)部分,tokenizer部分都沒(méi)有解析到,但目前篇幅已經(jīng)比較多了,希望留到下次解析。enjoy ChatRWKV v2!