
Systrace 學(xué)習(xí)筆記

和你一起終身學(xué)習(xí),這里是程序員Android
經(jīng)典好文推薦,通過閱讀本文,您將收獲以下知識點:
一、Systrace 簡介
二、Systrace 預(yù)備知識
三、Why 60 fps
四、SystemServer 解讀
五、SurfaceFlinger 解讀
六、Input 解讀
七、Vsync 解讀
八、Vsync-App :基于 Choreographer 的渲染機制詳解
九、MainThread 和 RenderThread 解讀
十、Binder 和鎖競爭解讀
十一、Triple Buffer 解讀
十二、CPU Info 解讀
前言
本文為學(xué)習(xí)systrace所做筆記、心得,學(xué)習(xí)資源為高兄的Systrace系列文章:Android Systrace 基礎(chǔ)知識。
一、Systrace 簡介
Systrace 是什么?
Android4.1 中新增的性能數(shù)據(jù)采樣和分析工具,它可以按模塊、按服務(wù)、按系統(tǒng)等來手收集數(shù)據(jù),使開發(fā)者可以根據(jù)systrace展示的數(shù)據(jù)來對系統(tǒng)進行優(yōu)化。
Systrace使用流程:
手機準備好你要進行抓取的界面
點擊開始抓取(命令行的話就是開始執(zhí)行命令)
手機上開始操作(不要太長時間)
設(shè)定好的時間到了之后,會將生成 Trace.html 文件,使用 Chrome 將這個文件打開進行分析
二、 Systrace 預(yù)備知識
狀態(tài)不同的線程:
綠色 --> 運行中 Running
對于在CPU上執(zhí)行的進程,需要查看其運行時間、是否跑在該跑的核上、頻率是否夠等。
藍色 --> 可運行 Runnable
對于在等待序列中的進程,需要查看是否有過多任務(wù)在等待、等待時間是否過長等。
白色 --> 休眠中 Sleeping
這里一般是在等事件驅(qū)動。
橘色 --> 不可中斷的睡眠態(tài)_IO_Block Uninterruptible Sleep | WakeKill - Block I/O
線程在I / O上被阻塞或等待磁盤操作完成。
紫色 --> 不可中斷的睡眠態(tài) Uninterruptible Sleep
線程在另一個內(nèi)核操作(通常是內(nèi)存管理)上被阻塞。
進程喚醒信息分析:
抓住從Sleeping --> Runnable的進程,利用systrace找到是誰喚醒的它,又是為什么花了這么久才喚醒。
信息區(qū)數(shù)據(jù)解析:
點擊不同的位置,選擇不同的slice信息展示。
快捷鍵使用:
W : 放大 Systrace , 放大可以更好地看清局部細節(jié)
S : 縮小 Systrace, 縮小以查看整體
A : 左移
D : 右移
M : 高亮選中當前鼠標點擊的段(這個比較常用,可以快速標識出這個方法的左右邊界和執(zhí)行時間,方便上下查看)
數(shù)字鍵1 : 切換到 Selection 模式 , 這個模式下鼠標可以點擊某一個段查看其詳細信息, 一般打開 Systrace 默認就是這個模式 , 也是最常用的一個模式 , 配合 M 和 ASDW 可以做基本的操作
數(shù)字鍵2 : 切換到 Pan 模式 , 這個模式下長按鼠標可以左右拖動, 有時候會用到
數(shù)字鍵3 : 切換到 Zoom 模式 , 這個模式下長按鼠標可以放大和縮小, 有時候會用到
數(shù)字鍵4 : 切換到 Timing 模式 , 這個模式下主要是用來衡量時間的,比如選擇一個起點, 選擇一個終點, 查看起點和終點這中間的操作所花費的時間.
三、Why 60 fps
軟件的渲染率和硬件的刷新率要一起搭配,才能做到用戶使用時足夠流暢。
為什么手機的屏幕刷新率不能太高呢?
限于手機電池、硬軟件的技術(shù),目前移動設(shè)備上使用的60HZ,也就是60幀每秒,雖然在硬件和軟件上,都能做到120HZ的刷新率,但是單位時間內(nèi)高刷新次數(shù)也會帶來高消耗,而移動端設(shè)備是不可能隨時充著電的,所以手機屏幕的刷新率現(xiàn)在還不能太高,當然未來肯定能行。
四、 SystemServer 解讀
窗口動畫:
啟動流程:點擊App時,首先Launcher會啟動一個StartingWindow,等App中啟動頁面的第一幀繪制好了,就會馬上從Launcher切換回App的窗口動畫。

ActivityManagerService:
AMS 相關(guān)的 Trace 一般會用 TRACE_TAG_ACTIVITY_MANAGER 這個 TAG,在 Systrace 中的名字是 ActivityManager。
WindowManagerService:
一般會用 TRACE_TAG_WINDOW_MANAGER 這個 TAG,在 Systrace 中 WindowManagerService 在 SystemServer 中多在 對應(yīng)的 Binder 中出現(xiàn)。
Input:
主要是由 InputReader 和 InputDispatcher 這兩個 Native 線程組成。
Binder:
SystemServer 由于提供大量的基礎(chǔ)服務(wù),所以進程間的通信非常繁忙,且大部分通信都是通過 Binder 。
HandlerThread:
BackgroundThread,許多對性能沒有要求的任務(wù),一般都會放到 BackgroundThread 中去執(zhí)行。
ServiceThread:
ServiceThread 繼承自 HandlerThread。
UIThread、IoThread、DisplayThread、AnimationThread、FgThread、SurfaceAnimationThread都是繼承自 ServiceThread,分別實現(xiàn)不同的功能,根據(jù)線程功能不同,其線程優(yōu)先級也不同。
每個 Thread 都有自己的 Looper 、Thread 和 MessageQueue,互相不會影響。Android 系統(tǒng)根據(jù)功能,會使用不同的 Thread 來完成。
五、 SurfaceFlinger 解讀
SurfaceFlinger:
作用:合成圖像的,將APP要畫的圖像處理后顯示在硬件上;
觸發(fā):收到vsync信號后,開始已幀的形式繪圖;
流程:當VSYNC 信號到達 --> 遍歷層列表,以尋找新的緩沖區(qū) --> 有新的緩沖區(qū),獲取該緩沖區(qū);沒有,使用以前獲取的緩沖區(qū) --> 收集完畢后,詢問HWC如何合成。
流程圖如下:

App --> BufferQueue:
App與BufferQueue交互流程:收到vsync信號后,應(yīng)用主線程(UI Thread)被喚醒,主線程處理完數(shù)據(jù)后,會喚醒應(yīng)用渲染線程RenderThread同步數(shù)據(jù),RenderThread會從BufferQueue取出一個Buffer,然后往Buffer寫入具體的 drawcall,完成后再將有數(shù)據(jù)的Buffer還給BufferQueue。
BufferQueue --> Surface Flinger:
思考后認為,App是不斷往BufferQueue里面丟數(shù)據(jù)的,而vsync信號的發(fā)送與前面無關(guān),就是系統(tǒng)提醒Surface Flinger可以畫圖了,那Surface Flinger就馬上去BufferQueue取數(shù)據(jù),然后畫圖。
Surface Flinger --> HWC:
這部分在文章中說明程度不夠,目前只知道HWC是會根據(jù)SurfaceFlinger提供的信息來提供顯示的方案——用于確定通過可用硬件來合成緩沖區(qū)的最有效方法。
六 Input 解讀
當用戶點開手機屏幕后,會做什么?用戶會點擊進入想看的頁面、滑動切換的頁面、點擊后退按鈕返回上一個以及按下Home鍵返回桌面,這些事件在安卓系統(tǒng)中都是以Message的形式傳遞,而上述這些操作,都屬于InputMessage范疇,都是Input事件。
Input事件包含:
觸摸事件(Down、Up、Move)
Key 事件(Home Key 、 Back Key)
本節(jié)主要描述當用戶按下屏幕后,觸發(fā)的流程是怎么樣的。
流程中主要和這些內(nèi)容有關(guān):InputReader、InputDispatcher、OutboundQueue、WaitQueue、PendingInputEventQueue、deliverInputEvent和InputResponse 。
流程如下:
用戶按下屏幕 --> InputReader讀取Input事件,將其放入InboundQueue中,喚醒InputDispatcher線程 --> InputDispatcher從InboundQueue取出事件,依次對注冊了Input事件的所有App(進程)做出以下操作:1. 派發(fā)給的OntboundQueue,2. 記錄到各個App的WaitQueue --> InputDispatcher通過直接喚醒、Binder的方式將主線程UI Thread喚醒 --> UI Thread處理完成后,會將WaitQueue 里面的Input事件刪除。
可以通過指令:adb shell dumpsys input獲得一些重要的信息,如Device、InputReader、Inputdispatcher等等。
七、Vsync 解讀
Vsync是什么?
Vsync是信號,用來控制App渲染圖像、SurfaceFlinger合成圖像的節(jié)奏。Vsync可以由硬件或軟件產(chǎn)生,主要是由硬件HWC生成。
Vsync的流程:
HWC產(chǎn)生Vsync --> DispSync將Vsync生成Vsync-app和Vsync-sf --> 收到信號后,launcher的UI Thread負責將圖像放入緩存,SF的UI Thread負責將緩存中的數(shù)據(jù)展示
從 App 繪制到屏幕顯示,分為下面幾個階段:
第一階段:App 在收到 Vsync-App 的時候,在主線程進行 measure、layout、draw(構(gòu)建 DisplayList , 里面包含 OpenGL 渲染需要的命令及數(shù)據(jù)) 。這里對應(yīng)的 Systrace 中的主線程 doFrame 操作;

image.png
第二階段:CPU 將數(shù)據(jù)上傳(共享或者拷貝)給 GPU, 這里 ARM 設(shè)備 內(nèi)存一般是 GPU 和 CPU 共享內(nèi)存。這里對應(yīng)的 Systrace 中的渲染線程的 flush drawing commands 操作;

image.png
第三階段:通知 GPU 渲染,真機一般不會阻塞等待 GPU 渲染結(jié)束,CPU 通知結(jié)束后就返回繼續(xù)執(zhí)行其他任務(wù),使用 Fence 機制輔助 GPU CPU 進行同步操作;
第四 階段:swapBuffers,并通知 SurfaceFlinger 圖層合成。這里對應(yīng)的 Systrace 中的渲染線程的 eglSwapBuffersWithDamageKHR 操作;
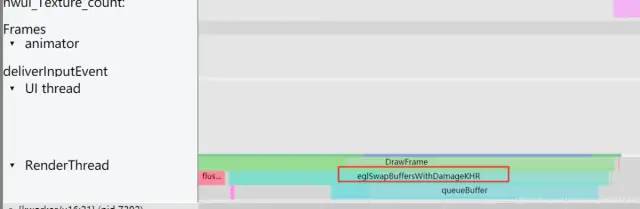
image.png
第五階段:SurfaceFlinger 開始合成圖層,如果之前提交的 GPU 渲染任務(wù)沒結(jié)束,則等待 GPU 渲染完成,再合成(Fence 機制),合成依然是依賴 GPU,不過這就是下一個任務(wù)了.這里對應(yīng)的 Systrace 中的 SurfaceFlinger 主線程的 onMessageReceived 操作(包括 handleTransaction、handleMessageInvalidate、handleMessageRefresh)SurfaceFlinger 在合成的時候,會將一些合成工作委托給 Hardware Composer,從而降低來自 OpenGL 和 GPU 的負載,只有 Hardware Composer 無法處理的圖層,或者指定用 OpenGL 處理的圖層,其他的 圖層偶會使用 Hardware Composer 進行合成;
第六階段 :最終合成好的數(shù)據(jù)放到屏幕對應(yīng)的 Frame Buffer 中,固定刷新的時候就可以看到了。
收到Vsync信號時,會發(fā)生什么?

App和SF同時收到Vsync信號(在vsync-offset = 0時);
App開始對這一幀的Buffer進行渲染,SF開始對上一幀的Buffer進行合成;
Vsync Offset是什么?
Vsync Offset是指,讓App和SF收到Vsync信號有一個時間間隔,而非同時收到。
為什么要有Vsync Offset?
因為如果Offset默認為0,那么SF收到Vsync信號后,合成的是上一幀App繪制的數(shù)據(jù),如果我們讓Offset不為0,那么可以做到當App繪制完這一幀的數(shù)據(jù)后,再讓SF去合成這一幀的數(shù)據(jù),用戶就能提前看到一幀的動畫。但是難以確定Offset的時間,很難做到合成繪制當前幀動畫。
HW_Vsync
參考博主的文章,可以知道HW_Vsync并不會一直開啟,而會使用DispSync線程模擬硬件信號,通過3到32個HW_Vsync模擬出SW_Vsync,只要收到的Present Fence沒有超過誤差,HW_VSYNC 就會關(guān)掉,使用SW_Vsync,不然會繼續(xù)接收HW_VSYNC 計算 SW_VSYNC 的值,直到誤差小于threshold。
不是每次申請 Vsync 都會由硬件產(chǎn)生 Vsync,只有此次請求 vsync 的時間距離上次合成時間大于 500ms,才會通知 hwc,請求 HW_VSYNC。
八、 Vsync-App :基于 Choreographer 的渲染機制詳解
Choreographer 扮演 Android 渲染鏈路中承上啟下的角色:
承上:負責接收和處理 App 的各種更新消息和回調(diào),等到 Vsync 到來的時候統(tǒng)一處理。比如集中處理 Input(主要是 Input 事件的處理) 、Animation(動畫相關(guān))、Traversal(包括 measure、layout、draw 等操作) ,判斷卡頓掉幀情況,記錄 CallBack 耗時等
啟下:負責請求和接收 Vsync 信號。接收 Vsync 事件回調(diào)(通過 FrameDisplayEventReceiver.onVsync );請求 Vsync(FrameDisplayEventReceiver.scheduleVsync) .
九、MainThread 和 RenderThread 解讀
主線程和渲染線程一幀的工作流程:
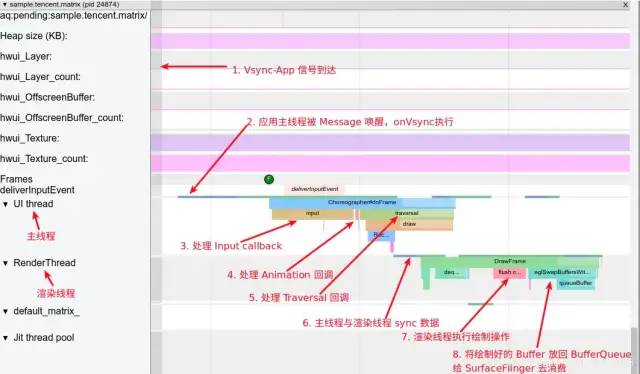
image.png
主線程處于 Sleep 狀態(tài),等待 Vsync 信號
Vsync 信號到來,主線程被喚醒,Choreographer 回調(diào) FrameDisplayEventReceiver.onVsync 開始一幀的繪制
處理 App 這一幀的 Input 事件(如果有的話)
處理 App 這一幀的 Animation 事件(如果有的話)
處理 App 這一幀的 Traversal 事件(如果有的話)
主線程與渲染線程同步渲染數(shù)據(jù),同步結(jié)束后,主線程結(jié)束一幀的繪制,可以繼續(xù)處理下一個 Message(如果有的話,IdleHandler 如果不為空,這時候也會觸發(fā)處理),或者進入 Sleep 狀態(tài)等待下一個 Vsync
渲染線程首先需要從 BufferQueue 里面取一個 Buffer(dequeueBuffer) , 進行數(shù)據(jù)處理之后,調(diào)用 OpenGL 相關(guān)的函數(shù),真正地進行渲染操作,然后將這個渲染好的 Buffer 還給 BufferQueue (queueBuffer) , SurfaceFlinger 在 Vsync-SF 到了之后,將所有準備好的 Buffer 取出進行合成(這個流程在講 SurfaceFlinger 的時候會提到)
硬件加速是什么:
硬件加速是指在計算機中通過把計算量非常大的工作分配給專門的硬件硬件)來處理以減輕中央處理器的工作量之技術(shù)。
就是CPU把工作分給GPU和APU了。
硬件加速流程:
1.CPU從文件系統(tǒng)里讀出原始數(shù)據(jù)(DirectSHow的源濾鏡),分離出壓縮的視頻數(shù)據(jù)(分離器)。放在系統(tǒng)內(nèi)存中。GPU、APU不運行。
2.CPU把壓縮音視頻數(shù)據(jù)交給GPU、APU, 這時總線上開始忙了,壓縮數(shù)據(jù)從系統(tǒng)內(nèi)存拷貝到顯卡上的顯存里和聲卡上的聲存里(如果有的話)。
3.CPU要求GPU、APU開始硬件解碼,CPU不運行,GPU、APU開始忙。當然CPU會定期查詢一下GPU、APU忙的怎么樣了。
4.GPU、APU開始用自己的電路解碼視頻數(shù)據(jù)(已經(jīng)在顯、聲存里了),解壓后的數(shù)據(jù)還是放在顯聲存里面。
5.音視頻數(shù)據(jù)剛解碼完成以后還不能立刻拿去播放,因為還需要后期處理,如deinterlace, 3:2pulldown,多普勒效應(yīng),等等。GPU、APU再用自己的后期處理電路來進行處理。
6.后期處理以后的未壓縮數(shù)據(jù)拿去播放, GPU再開始忙視頻的縮放,亮度,gamma等事情。CPU還是閑。
7.GPU、APU終于忙完了,下面的視頻數(shù)據(jù)在哪里?通知CPU,GPU、APU先歇會。CPU又開始忙了,回到第1步。
CPU拿到視頻、音頻數(shù)據(jù)后,拷貝給GPU、APU拿去做處理和顯示,并且CPU會不斷監(jiān)聽GPU和APU的進度。
軟件繪制:
安卓系統(tǒng)默認開啟硬件加速,我們可以針對某個App,關(guān)閉App的硬件加速。關(guān)閉后,CPU不會再將數(shù)據(jù)傳遞給GPU渲染,而是會直接調(diào)用 libSkia 來進行渲染,systrace中軟件加速如圖所示:
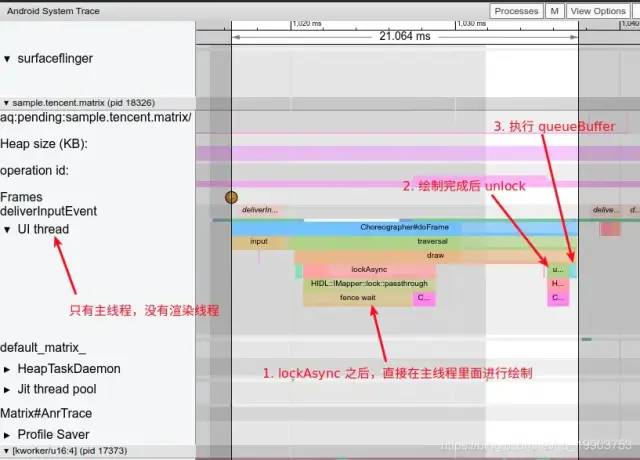
與硬件加速對比,主線程執(zhí)行的時間變長了,更容易出現(xiàn)卡頓,同時幀與幀之間的空閑間隔也變短了,使得其他 Message 的執(zhí)行時間被壓縮。
硬件加速時,主線程和渲染線程的分工:
主線程負責處理進程 Message、處理 Input 事件、處理 Animation 邏輯、處理 Measure、Layout、Draw ,更新 DIsplayList ,但是不涉及 SurfaceFlinger 打交道;
渲染線程負責渲染渲染相關(guān)的工作,一部分工作也是 CPU 來完成的,一部分操作是調(diào)用 OpenGL 函數(shù)來完成的。
當啟動硬件加速后,在 Measure、Layout、Draw 的 Draw 這個環(huán)節(jié),Android 使用 DisplayList 進行繪制而非直接使用 CPU 繪制每一幀。DisplayList 是一系列繪制操作的記錄,抽象為 RenderNode 類,這樣間接的進行繪制操作的優(yōu)點如下
DisplayList 可以按需多次繪制而無須同業(yè)務(wù)邏輯交互
特定的繪制操作(如 translation, scale 等)可以作用于整個 DisplayList 而無須重新分發(fā)繪制操作
當知曉了所有繪制操作后,可以針對其進行優(yōu)化:例如,所有的文本可以一起進行繪制一次
可以將對 DisplayList 的處理轉(zhuǎn)移至另一個線程(也就是 RenderThread)
主線程在 sync 結(jié)束后可以處理其他的 Message,而不用等待 RenderThread 結(jié)束
十、Binder 和鎖競爭解讀
Binder是什么?
Binder是解決安卓系統(tǒng)中進程通訊的工具。
Systrace中,和Binder相關(guān)的進程通信是怎么表現(xiàn)的?
在打開systrace圖像右上角View Options的Flow events后,可以看到binder跨進程通訊的步驟,下面兩張圖顯示了,開啟binder調(diào)用 --> 獲得對端進程響應(yīng) --> binder調(diào)用返回的流程。
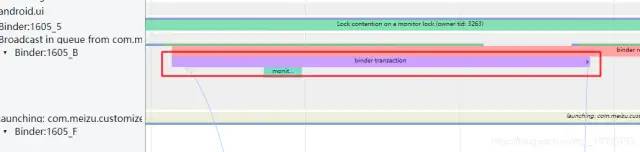
Systrace顯示鎖的信息:
在systrace中我們可以看到一些線程下面的執(zhí)行方法:monitor contention with owner xxxxx。
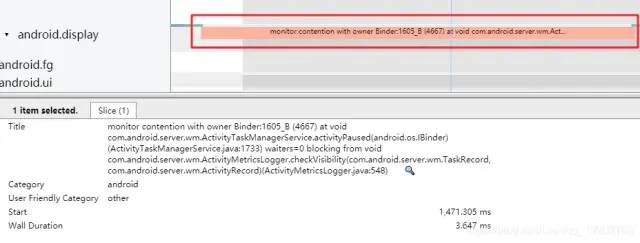
點開這類方法,可以發(fā)現(xiàn)執(zhí)行這段方法的線程是會處于一段sleeping的狀態(tài)的,原因是拿不到鎖資源,在鎖池等待其他線程釋放鎖資源。
在Slive信息中,我們可以發(fā)現(xiàn)該線程正在和鎖持有的對象Binder:1605_B (4667)競爭著,并且在這個線程去競爭前,總共還有waiters = 0個線程也在鎖池等待,而鎖目前主人正在執(zhí)行的同步方法是com.android.server.wm.ActivityTaskManagerService.activityPaused(android.os.IBinder),代碼位于(ActivityTaskManagerService.java:1733),而該線程正在等待的同步方法是void com.android.server.wm.ActivityMetricsLogger.checkVisibility(com.android.server.wm.TaskRecord, com.android.server.wm.ActivityRecord),代碼位于(ActivityMetricsLogger.java:548)。
十一、Triple Buffer 解讀
掉幀:
App端掉幀:當App進程的UI Thread和Render Thread在收到Vsync信號后,執(zhí)行所花的時間超過16.6毫秒,那么在App端就發(fā)生了掉幀,不過由于triple buffer的存在,可能不會掉幀;
SurfaceFlinger端判斷掉幀:如果在vsync信號來到的時候,SF的Buffer里面是0,那么就是掉幀了,而且這是用戶能看得到的掉幀,也可以在systrace上看到Vsync-sf在收到信號后沒有發(fā)生變化;
邏輯掉幀:在畫面顯示時,不僅僅只是和每一幀顯示的數(shù)據(jù)有關(guān),還和相鄰幀的步長有關(guān)系,如果相鄰幀的步長沒有規(guī)范到一個固定的范圍內(nèi),用戶也會感覺到明顯的卡頓而systrace看不出來。
triple buffer:
在triple buffer中有3個buffer可以使用,CPU、GPU和SF各用一個,當triple buffer發(fā)生掉幀后,是可以減少后續(xù)掉幀的情況的,流程圖如下所示。

triple buffer的作用:
緩解掉幀;
減少主線程和渲染線程等待時間;
降低 GPU 和 SurfaceFlinger 瓶頸。
十二、CPU Info 解讀
在systrace中,可以通過展開CPU那一欄的方式,查看CPU在運行時的狀態(tài)、頻率變化情況、任務(wù)執(zhí)行情況、大小核的調(diào)度情況、CPU Boost 調(diào)度情況。
CPU的核心架構(gòu):
非大小核架構(gòu),只有2個或4個核心的時候,會用同樣的核心;
大小核架構(gòu),八個核心中由大核和小核組成,如4個小核心 + 4個大核心;
大中小核架構(gòu),八個核心中由大核、中核和小核組成,如4個小核心 + 3個中核心 + 1個大核心;
綁核:
將固定線程綁定在某個核心上,如將重要的、工作量大的線程綁定在大核,不重要、工作量小的線程綁定在小核。
綁核的三種方式:
配置 CPUset,按照類型將某一類任務(wù)限制到具體的CPU或CPU組中運行;
配置 affinity,使用指令設(shè)置任務(wù)跑在具體的CPU核心上;
調(diào)度算法。
鎖頻:
將CPU的核心鎖定頻率,方式:設(shè)置最高頻率 = 最低頻率
CPU狀態(tài):
如圖所示,CPU狀態(tài)有4種。

下面是摘抄的其他平臺的支持 C0-C4 的處理器的狀態(tài)和功耗狀態(tài),Android 中不同的平臺表現(xiàn)不一致,大家可以做一下參考
C0 狀態(tài)(激活)
這是 CPU 最大工作狀態(tài),在此狀態(tài)下可以接收指令和處理數(shù)據(jù)
所有現(xiàn)代處理器必須支持這一功耗狀態(tài)
C1 狀態(tài)(掛起)
可以通過執(zhí)行匯編指令“ HLT (掛起)”進入這一狀態(tài)
喚醒時間超快!(快到只需 10 納秒!)
可以節(jié)省 70% 的 CPU 功耗
所有現(xiàn)代處理器都必須支持這一功耗狀態(tài)
C2 狀態(tài)(停止允許)
處理器時鐘頻率和 I/O 緩沖被停止
換言之,處理器執(zhí)行引擎和 I/0 緩沖已經(jīng)沒有時鐘頻率
在 C2 狀態(tài)下也可以節(jié)約 70% 的 CPU 和平臺能耗
從 C2 切換到 C0 狀態(tài)需要 100 納秒以上
C3 狀態(tài)(深度睡眠)
總線頻率和 PLL 均被鎖定
在多核心系統(tǒng)下,緩存無效
在單核心系統(tǒng)下,內(nèi)存被關(guān)閉,但緩存仍有效可以節(jié)省 70% 的 CPU 功耗,但平臺功耗比 C2 狀態(tài)下大一些
喚醒時間需要 50 微妙
原文鏈接:https://blog.csdn.net/qq_19903753/article/details/108108972
友情推薦:
至此,本篇已結(jié)束。轉(zhuǎn)載網(wǎng)絡(luò)的文章,小編覺得很優(yōu)秀,歡迎點擊閱讀原文,支持原創(chuàng)作者,如有侵權(quán),懇請聯(lián)系小編刪除,歡迎您的建議與指正。同時期待您的關(guān)注,感謝您的閱讀,謝謝!
點個在看,方便您使用時快速查找!