
面試官:InnoDB解決幻讀的方案了解么?
最近要在公司內做一次技術分享,思來想去不知道該分享些什么,最后在朋友的提示下,準備分享一下MySQL的InnoDB引擎下的事務幻讀問題與解決方案--LBCC&MVCC。經過好幾天的熬夜通宵,終于把這部分的內容捋清楚了。至于為什么說是InnoDB呢?因為MyISAM引擎是不支持事務的。
事務
概念
一個事情由 n 個單元組成,這 n 個單元在執(zhí)行過程中,要么同時成功,要么同時失敗,這就把 n 個單元放在了一個事務之中。舉個簡單的例子:在不考慮試題正確與否的前提下,一張試卷由多個題目構成,當你答完題交給老師的時候是將一整張試卷交給老師,而不是將每道題單獨交給老師,在這里試卷就可以理解成一個事務。
事務的特性:ACID
A:原子性(Atomicity),原子性是指事務是一個不可分割的工作單位,事務中的操作,要么都發(fā)生,要么都不發(fā)生。
例:假設你在購物車里添加了兩件衣服:上衣和褲子,當你把兩件衣服作為一個訂單提交支付的時候,要么兩件衣服一起支付成功,要么都失敗,不可能存在上衣付完錢了,褲子還沒付完的情況,反之亦然。
C:一致性(Consistency),在一個事務中,事務前后數(shù)據的完整性必須保持一致。
例:假設用戶 A 和用戶 B 兩者的錢加起來一共是 200,那么不管 A 和 B 之間如何轉賬,轉幾次賬,事務結束后兩個用戶的錢相加起來應該還得是 200,這就是事務的一致性。
I:隔離性(Isolation),存在于多個事務中,事務的隔離性是指多個用戶并發(fā)訪問數(shù)據庫時,一個用戶的事務不能被其它用戶的事務所干擾,多個并發(fā)事務之間數(shù)據要相互隔離。
例:對于任意兩個并發(fā)的事務 T1 和 T2,在事務 T1 看來,T2 要么在 T1 開始之前就已經結束,要么在 T1 結束之后才開始,這樣每個事務都感覺不到有其他事務在并發(fā)地執(zhí)行。
D:持久性(Durability),持久性是指一個事務一旦被提交,它對數(shù)據庫中數(shù)據的改變就是永久性的,接下來即使數(shù)據庫發(fā)生故障也不應該對其有任何影響。
例:我們在操作數(shù)據庫時,事務提交或者回滾都會直接改變數(shù)據庫中的值。
事務的操作
在使用事務之前,首先我們要開啟事務,我們可以通過start或者begin命令開啟事務;如果我們想提交事務可以手動執(zhí)行commit命令,如果我們想回滾事務,可以執(zhí)行rollback命令。
注:在MySQL中事務的提交是默認開啟的,可以執(zhí)行show variables like 'autocommit'命令查看,如果是ON則證明自動提交已經開啟,如果為OFF則需要手動提交。
隔離性引發(fā)的并發(fā)問題
1)臟讀:B 事務讀取到了 A 事務尚未提交的數(shù)據;
2)不可重復讀:B 事務讀到了 A 事務已經提交的數(shù)據,即 B 事務在 A 事務提交之前和提交之后讀取到的數(shù)據內容不一致(AB 事務操作的是同一條數(shù)據);
3)幻讀/虛讀:B 事務讀到了 A 事務已經提交的數(shù)據,即 A 事務執(zhí)行插入操作,B 事務在 A 事務前后讀到的數(shù)據數(shù)量不一致。
事務的隔離級別
為了解決以上隔離性引發(fā)的并發(fā)問題,數(shù)據庫提供了事物的隔離機制。
read uncommitted(讀未提交): 一個事務還沒提交時,它做的變更就能被別的事務看到,讀取尚未提交的數(shù)據,哪個問題都不能解決; read committed(讀已提交):一個事務提交之后,它做的變更才會被其他事務看到,讀取已經提交的數(shù)據,可以解決臟讀 ---- oracle默認的;repeatable read(可重復讀):一個事務執(zhí)行過程中看到的數(shù)據,總是跟這個事務在啟動時看到的數(shù)據是一致的,可以解決臟讀和不可重復讀 --- mysql默認的;serializable(串行化):顧名思義是對于同一行記錄,“寫”會加“寫鎖”,“讀”會加“讀鎖”。當出現(xiàn)讀寫鎖沖突的時候,后訪問的事務必須等前一個事務執(zhí)行完成,才能繼續(xù)執(zhí)行。可以解決臟讀、不可重復讀和虛讀---相當于鎖表。
雖然serializable級別可以解決所有的數(shù)據庫并發(fā)問題,但是它會在讀取的每一行數(shù)據上都加鎖,這就可能導致大量的超時和鎖競爭問題,從而導致效率下降。所以我們在實際應用中也很少使用serializable,只有在非常需要確保數(shù)據的一致性而且可以接受沒有并發(fā)的情況下,才考慮采用該級別。
LBCC&MVCC
InnoDB默認的事務隔離級別是repeatable read(后文中用簡稱 RR),它為了解決該隔離級別下的幻讀的并發(fā)問題,提出了LBCC和MVCC兩種方案。其中LBCC解決的是當前讀情況下的幻讀,MVCC解決的是普通讀(快照讀)的幻讀。至于什么是當前讀,什么是快照讀,將在下文中給出答案。
LBCC
LBCC是Lock-Based Concurrent Control的簡稱,意思是基于鎖的并發(fā)控制。在InnoDB中按鎖的模式來分的話可以分為共享鎖(S)、排它鎖(X)和意向鎖,其中意向鎖又分為意向共享鎖(IS)和意向排它鎖(IX)(此處先不做介紹,后期會專門出篇文章講一下InnoDB和Myisam引擎的鎖);如果按照鎖的算法來分的話又分為記錄鎖(Record Locks)、間隙鎖(Gap Locks)和臨鍵鎖(Next-key Locks)。其中臨鍵鎖就可以用來解決 RR 下的幻讀問題。那么什么是臨鍵鎖呢?繼續(xù)往下看。
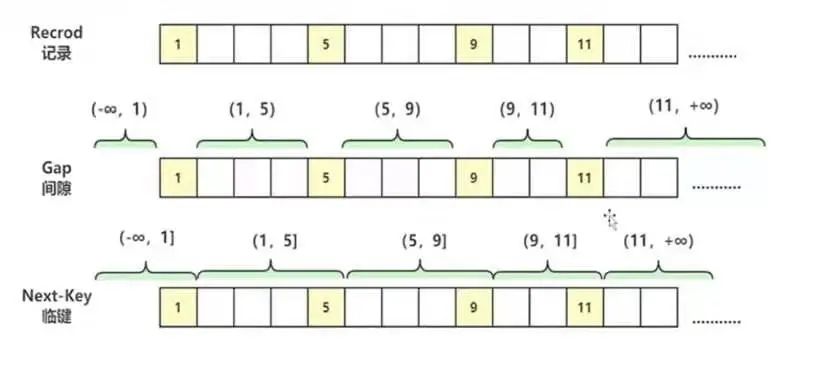
我們將數(shù)據庫中存儲的每一行數(shù)據稱為記錄。則上圖中 1、5、9、11 分別代表 id 為當前數(shù)的記錄。對于鍵值在條件范圍內但不存在的記錄,叫做間隙(GAP)。則上圖中的(-∞,1)、(1,5)...(11,+∞)為數(shù)據庫中存在的間隙。而(-∞,1]、(1,5]...(11,+∞)我們稱之為臨鍵,即左開右閉的集合。
記錄鎖(Record Locks)
對表中的行記錄加鎖,叫做記錄鎖,簡稱行鎖。可以使用sql語句select ... for update來開啟鎖,select語句必須為精準匹配(=),不能為范圍匹配,且匹配列字段必須為唯一索引或者主鍵列。也可以通過對查詢條件為主鍵索引或唯一索引的數(shù)據行進行UPDATE操作來添加記錄鎖。
記錄鎖存在于包括主鍵索引在內的唯一索引中,鎖定單條索引記錄。
間隙鎖(GAP Locks)
對上面說到的間隙加鎖即為間隙鎖。間隙鎖是對范圍加鎖,但不包括已存在的索引項。可以使用sql語句select ... for update來開啟鎖,select語句為范圍查詢,匹配列字段為索引項,且沒有數(shù)據返回;或者select語句為等值查詢,匹配字段為唯一索引,也沒有數(shù)據返回。
間隙鎖有一個比較致命的弱點,就是當鎖定一個范圍鍵值之后,即使某些不存在的鍵值也會被無辜的鎖定,而造成在鎖定的時候無法插入鎖定鍵值范圍內的任何數(shù)據。在某些場景下這可能會對性能造成很大的危害。以下是加鎖之后,插入操作的例子:
select * from user where id > 15 for update;
//插入失敗,因為id20大于15,不難理解
insert into user values(20,'20');
//插入失敗,原因是間隙鎖鎖的是記錄間隙,而不是sql,也就是說`select`語句的鎖范圍是(11,+∞),而13在這個區(qū)間中,所以也失敗。
insert into user values(13,'13');
GAP Locks只存在于 RR 隔離級別下,它鎖住的是間隙內的數(shù)據。加完鎖之后,間隙中無法插入其他記錄,并且鎖的是記錄間隙,而非sql語句。間隙鎖之間都不存在沖突關系。
打開間隙鎖設置: 以通過命令show variables like 'innodb_locks_unsafe_for_binlog';來查看 innodb_locks_unsafe_for_binlog 是否禁用。innodb_locks_unsafe_for_binlog默認值為 OFF,即啟用間隙鎖。因為此參數(shù)是只讀模式,如果想要禁用間隙鎖,需要修改 my.cnf(windows 是my.ini) 重新啟動才行。
#在 my.cnf 里面的[mysqld]添加
[mysqld]
innodb_locks_unsafe_for_binlog = 1
臨鍵鎖(Next-Key Locks)
當我們對上面的記錄和間隙共同加鎖時,添加的便是臨鍵鎖(左開右閉的集合加鎖)。為了防止幻讀,臨鍵鎖阻止特定條件的新記錄的插入,因為插入時要獲取插入意向鎖,與已持有的臨鍵鎖沖突。可以使用sql語句select ... for update來開啟鎖,select語句為范圍查詢,匹配列字段為索引項,且有數(shù)據返回;或者select語句為等值查詢,匹配列字段為索引項,不管有沒有數(shù)據返回。
插入意向鎖并非意向鎖,而是一種特殊的間隙鎖。
總結
如果查詢沒有命中索引,則退化為表鎖; 如果等值查詢唯一索引且命中唯一一條記錄,則退化為行鎖; 如果等值查詢唯一索引且沒有命中記錄,則退化為臨近結點的間隙鎖; 如果等值查詢非唯一索引且沒有命中記錄,退化為臨近結點的間隙鎖(包括結點也被鎖定);如果命中記錄,則鎖定所有命中行的臨鍵鎖,并同時鎖定最大記錄行下一個區(qū)間的間隙鎖。 如果范圍查詢唯一索引或查詢非唯一索引且命中記錄,則鎖定所有命中行的臨鍵鎖 ,并同時鎖定最大記錄行下一個區(qū)間的間隙鎖。 如果范圍查詢索引且沒有命中記錄,退化為臨近結點的間隙鎖(包括結點也被鎖定)。
當前讀
當前讀(Locking Read)也稱鎖定讀,讀取當前數(shù)據的最新版本,而且讀取到這個數(shù)據之后會對這個數(shù)據加鎖,防止別的事務更改即通過next-key鎖(行鎖+gap 鎖)來解決當前讀的問題。在進行寫操作的時候就需要進行“當前讀”,讀取數(shù)據記錄的最新版本,包含以下SQL類型:select ... lock in share mode 、select ... for update、update 、delete 、insert。
MVCC
LBCC是基于鎖的并發(fā)控制,因為鎖的粒度過大,會導致性能的下降,因此提出了比LBCC性能更優(yōu)越的方法MVCC。MVCC是Multi-Version Concurremt Control的簡稱,意思是基于多版本的并發(fā)控制協(xié)議,通過版本號,避免同一數(shù)據在不同事務間的競爭,只存在于InnoDB引擎下。它主要是為了提高數(shù)據庫的并發(fā)讀寫性能,不用加鎖就能讓多個事務并發(fā)讀寫。MVCC的實現(xiàn)依賴于:三個隱藏字段、Undo log和Read View,其核心思想就是:只能查找事務 id 小于等于當前事務 ID 的行;只能查找刪除時間大于等于當前事務 ID 的行,或未刪除的行。接下來讓我們從源碼級別來分析下MVCC。
隱藏列
MySQL中會為每一行記錄生成隱藏列,接下來就讓我們了解一下這幾個隱藏列吧。
(1)DB_TRX_ID:事務 ID,是根據事務產生時間順序自動遞增的,是獨一無二的。如果某個事務執(zhí)行過程中對該記錄執(zhí)行了增、刪、改操作,那么InnoDB存儲引擎就會記錄下該條事務的 id。
(2)DB_ROLL_PTR:回滾指針,本質上就是一個指向記錄對應的undo log的一個指針,大小為 7 個字節(jié),InnoDB 便是通過這個指針找到之前版本的數(shù)據。該行記錄上所有舊版本,在undo log中都通過鏈表的形式組織。
(3)DB_ROW_ID:行標識(隱藏單調自增 ID),如果表沒有主鍵,InnoDB 會自動生成一個隱藏主鍵,大小為 6 字節(jié)。如果數(shù)據表沒有設置主鍵,會以它產生聚簇索引。
(4)實際還有一個刪除 flag 隱藏字段,既記錄被更新或刪除并不代表真的刪除,而是刪除 flag 變了。
undo log
每當我們要對一條記錄做改動時(這里的改動可以指 INSERT、DELETE、UPDATE),都需要把回滾時所需的東西記錄下來, 比如:
Insert undo log :插入一條記錄時,至少要把這條記錄的主鍵值記下來,之后回滾的時候只需要把這個主鍵值對應的記錄刪掉就好了。 Delete undo log:刪除一條記錄時,至少要把這條記錄中的內容都記下來,這樣之后回滾時再把由這些內容組成的記錄插入到表中就好了。 Update undo log:修改一條記錄時,至少要把修改這條記錄前的舊值都記錄下來,這樣之后回滾時再把這條記錄更新為舊值就好了。 InnoDB把這些為了回滾而記錄的這些東西稱之為undo log。這里需要注意的一點是,由于查詢操作(SELECT)并不會修改任何用戶記錄,所以在查詢操作執(zhí)行時,并不需要記錄相應的undo log。
每次對記錄進行改動都會記錄一條 undo 日志,每條 undo 日志也都有一個DB_ROLL_PTR屬性,可以將這些 undo 日志都連起來,串成一個鏈表,形成版本鏈。版本鏈的頭節(jié)點就是當前記錄最新的值。
例
先插入一條記錄,假設該記錄的事務 id 為 80,那么此刻該條記錄的示意圖如下所示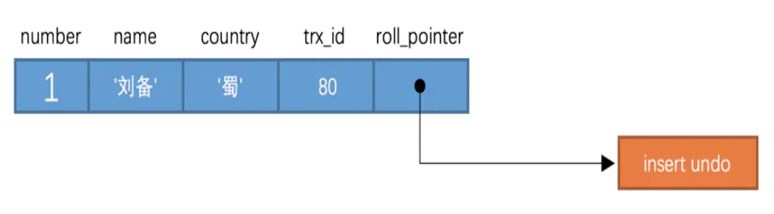 實際上
實際上insert undo只在事務回滾時起作用,當事務提交后,該類型的 undo 日志就沒用了,它占用的Undo Log Segment也會被系統(tǒng)回收。接著繼續(xù)執(zhí)行 sql 操作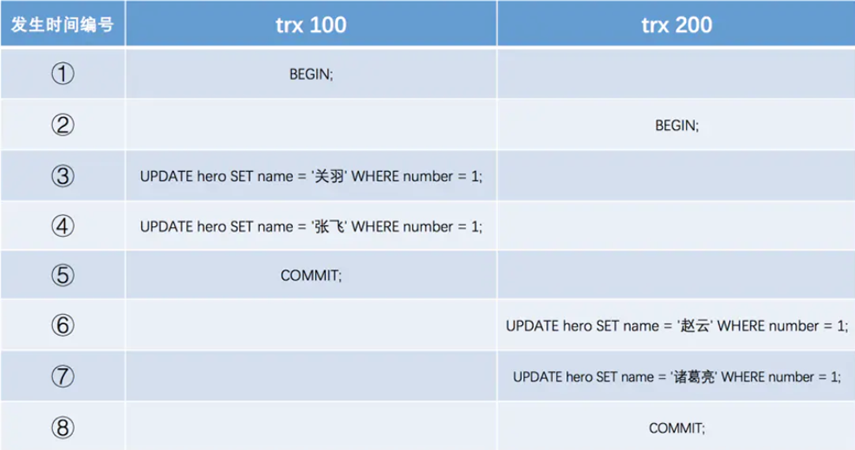 其版本鏈如下
其版本鏈如下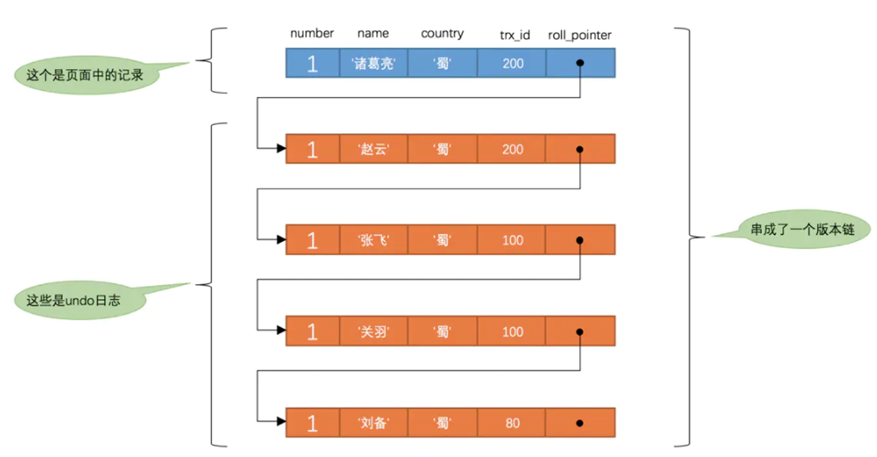
很多人以為
undo log用于將數(shù)據庫物理的恢復到執(zhí)行語句或者事務之前的樣子,其實并非如此,undo log是邏輯日志,只是將數(shù)據庫邏輯的恢復到原來的樣子。因為在多并發(fā)系統(tǒng)中,你把一個頁中的數(shù)據物理的恢復到原來的樣子,可能會影響其他的事務。
Read View
在可重復讀隔離級別下,我們可以把每一次普通的select查詢(不加for update語句)當作一次快照讀,而快照便是進行select的那一刻,生成的當前數(shù)據庫系統(tǒng)中所有未提交的事務 id 數(shù)組(數(shù)組里最小的id為min_id)和已經創(chuàng)建的最大事務id(max_id)的集合,即我們所說的一致性視圖readview。在進行快照讀的過程中要根據一定的規(guī)則將版本鏈中每個版本的事務id與readview進行匹配查詢我們需要的結果。
快照讀是不會看到別的事務插入的數(shù)據的。因此,幻讀在“當前讀”下才會出現(xiàn)。快照讀的實現(xiàn)是基于多版本并發(fā)控制,即MVCC,可以認為MVCC是行鎖的一個變種,但它在很多情況下,避免了加鎖操作,降低了開銷;既然是基于多版本,即快照讀可能讀到的并不一定是數(shù)據的最新版本,而有可能是之前的歷史版本。MVCC只在 READ COMMITTED 和 REPEATABLE READ兩個隔離級別下工作,其他兩個隔離級別不和MVCC不兼容。因為READ UNCOMMITTED總是讀取最新的數(shù)據行,而不是符合當前事務版本的數(shù)據行,而SERIALIZABLE 則會對所有讀取的行都加鎖。事務的快照時間點(即下文中說到的Read View的生成時間)是以第一個select來確認的。所以即便事務先開始,但是select在后面的事務的update之類的語句后進行,那么它是可以獲取前面的事務的對應的數(shù)據。
RC 和 RR 隔離級別下的快照讀和當前讀:RC 隔離級別下,快照讀和當前讀結果一樣,都是讀取已提交的最新;RR 隔離級別下,當前讀結果是其他事務已經提交的最新結果,快照讀是讀當前事務之前讀到的結果。RR 下創(chuàng)建快照讀的時機決定了讀到的版本。
對于使用 RC 和 RR 隔離級別的事務來說,都必須保證讀到已經提交了的事務修改過的記錄,也就是說假如另一個事務已經修改了記錄但是尚未提交,是不能直接讀取最新版本的記錄的。核心問題就是:需要判斷一下版本鏈中的哪個版本是當前事務可見的。為此,InnoDB提出了一個Read View的概念。
Read View就是事務進行快照讀(普通select查詢)操作的時候生產的一致性讀視圖,在該事務執(zhí)行的快照讀的那一刻,會生成數(shù)據庫系統(tǒng)當前的一個快照,它由執(zhí)行查詢時所有未提交的事務 id 數(shù)組(數(shù)組里最小的 id 為min_id)和已經創(chuàng)建的最大事務 id(max_id)組成,查詢的數(shù)據結果需要跟read view做對比從而得到快照結果。
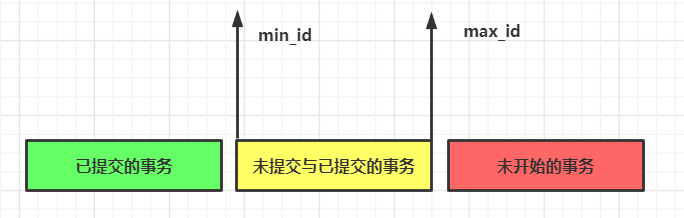
版本鏈比對規(guī)則:
如果落在綠色部分(trx_id<min_id),表示這個版本是已經提交的事務生成的,這個數(shù)據是可見的; 如果落在紅色部分(trx_id>max_id),表示這個版本是由將來啟動的事務生成的,是肯定不可見的; 如果落在黃色部分(min_id<=trx_id<=max_id),那就包含兩種情況:a.若 row 的 trx_id 在數(shù)組中,表示這個版本是由還沒提交的事務生成的,不可見;如果是自己的事務,則是可見的;b.若 row 的 trx_id 不在數(shù)組中,表示這個版本是已經提交了的事務生成的,可見。
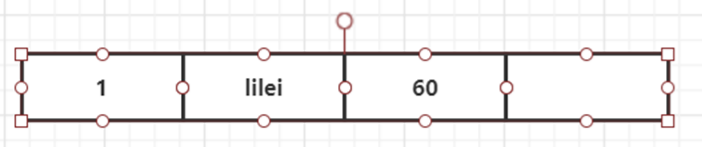
光說不練假把式,接下來就讓我們用例子來演示一下:首先我們要準備兩張表,一張test和一張account表,然后我們以account的undo log來畫版本鏈,準備數(shù)據和原始記錄圖如下
//test表中數(shù)據
id=1,c1='11';
id=5,c1='22';
//account表數(shù)據
id=1,name=‘lilei’;
 如下圖,我們將按照里面的順序執(zhí)行
如下圖,我們將按照里面的順序執(zhí)行sql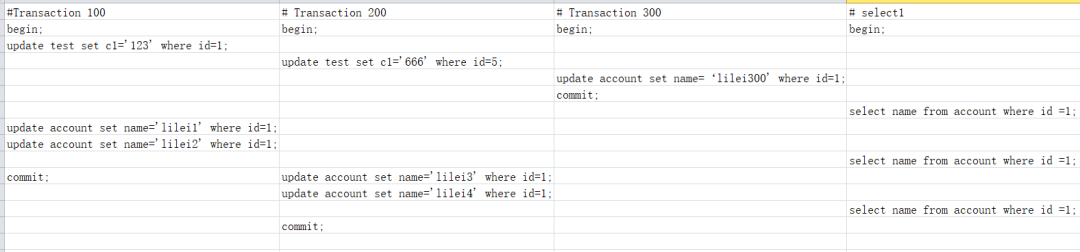 當我們執(zhí)行到第 7 行的
當我們執(zhí)行到第 7 行的select的語句時,會生成readview[100,200],300,版本鏈如圖所示: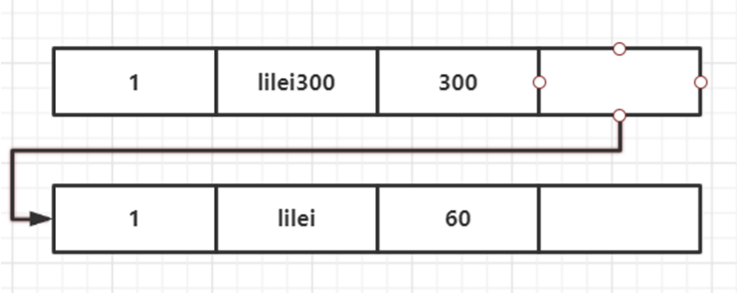 此時我們查詢到的數(shù)據為
此時我們查詢到的數(shù)據為lilei300。我們首先要拿最新版本的數(shù)據trx_id=300來readview中匹配,落在黃色區(qū)間內,一看該數(shù)據已經提交了,所以是可見的。繼續(xù)往下執(zhí)行,當執(zhí)行到第 10 行的select語句時,因為trx_id=100并未提交,所以版本鏈依然為readview[100,200],300,版本鏈如圖所示: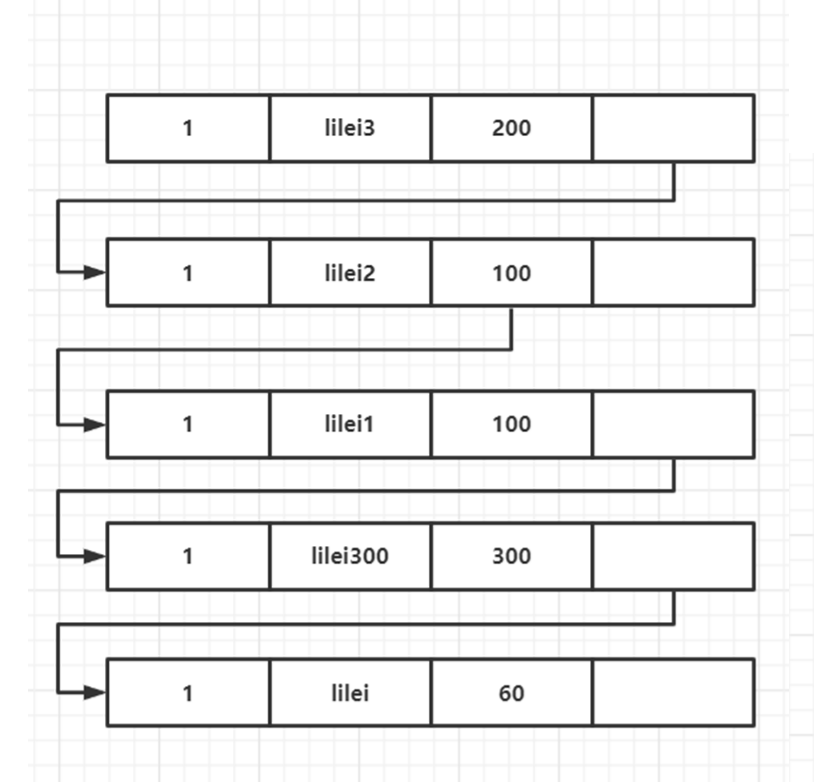 此時我們查詢到的數(shù)據為
此時我們查詢到的數(shù)據為lilei300。我們按上邊操作,從最新版本依次往下匹配,我們首先要拿最新版本的數(shù)據trx_id=100來readview中匹配,落在黃色區(qū)間內,一看該數(shù)據在未提交的數(shù)組中,且不是自己的事務,所以是不可見的;然后我們選擇前一個版本的數(shù)據,結果同上;繼續(xù)向上找,當找到trx_id=300的數(shù)據時,會落在黃色區(qū)間,且是提交的,所以數(shù)據可見。繼續(xù)往下執(zhí)行,當執(zhí)行到第 13 行的select語句時,此時盡管trx_id=100已經提交了,因為是InnoDB的 RR 模式,所以readview不會更改,仍為readview[100,200],300,版本鏈如圖所示: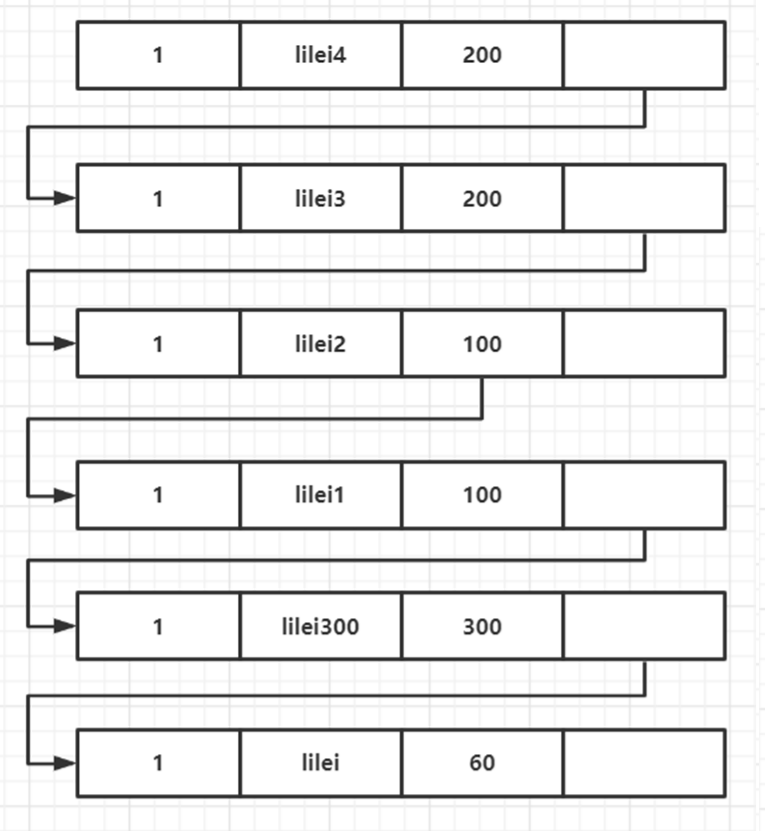 此時我們查詢到的數(shù)據為
此時我們查詢到的數(shù)據為lilei300。原因同上邊的步驟,不再贅述。
當執(zhí)行
update語句時,都是先讀后寫的,而這個讀,是當前讀,只能讀當前的值,跟readview查找時的快照讀區(qū)分開。
剛才演示的是InnoDB下的 RR 模式,接下來我們簡單說一下 RC 模式,上文中提到的 RC 模式的數(shù)據讀都是讀最新的即當前讀,所以 readview 是實時生成的,執(zhí)行語句如圖所示: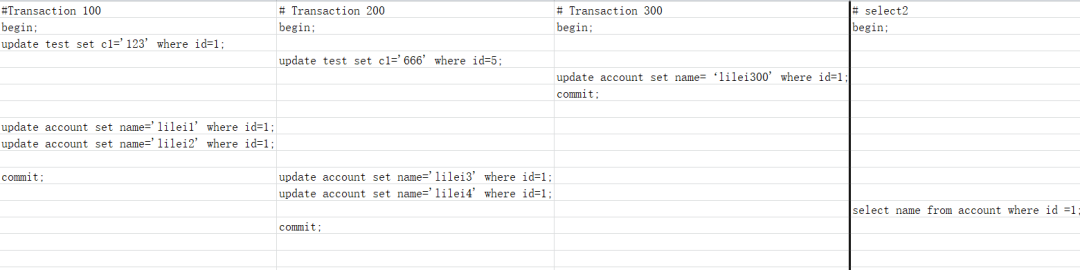 當我們執(zhí)行到第 13 行的
當我們執(zhí)行到第 13 行的select的語句時,會生成readview[200],300,版本鏈還和之前一樣,此時我們查詢到的數(shù)據為lilei2。原因和上邊講的 RR 模式下的比對規(guī)則相同。
此處我們演示的是update的情況,對于刪除的情況可以認為是update的特殊情況,會將版本鏈上最新的數(shù)據復制一份,然后將trx_id改成刪除操作的trx_id,同時在該條記錄的頭信息(record header)里的(deleted_flag)標記位上寫上true,來表示當前記錄已經被刪除,在查詢時按照上邊的規(guī)則查到對應的記錄,如果delete_flag標記位為true,意味著記錄已被刪除,則不返回數(shù)據。
大家應該還關心一個問題,即undo log什么時候刪除呢?系統(tǒng)會判斷,沒有比這個undo log更早的read view的時候,undo log會被刪除。所以這里也就是為什么我們建議你盡量不要使用長事務的原因。長事務意味著系統(tǒng)里面會存在很老的事務視圖。由于這些事務隨時可能訪問數(shù)據庫里面的任何數(shù)據,所以這個事務提交之前,數(shù)據庫里面它可能用到的回滾記錄都必須保留,這就會導致大量占用存儲空間。
推薦?? :1049天,100K!簡單復盤!
推薦?? :年薪 40W Java 開發(fā)是什么水平?
推薦?? :Github掘金計劃:Github上的一些優(yōu)質項目搜羅