
【NLP】NLP中的對(duì)抗訓(xùn)練
對(duì)抗訓(xùn)練本質(zhì)是為了提高模型的魯棒性,一般情況下在傳統(tǒng)訓(xùn)練的基礎(chǔ)上,添加了對(duì)抗訓(xùn)練是可以進(jìn)一步提升效果的,在比賽打榜、調(diào)參時(shí)是非常重要的一個(gè)trick。對(duì)抗訓(xùn)練在CV領(lǐng)域內(nèi)非常常用,那么在NLP領(lǐng)域如何使用呢?本文簡(jiǎn)單總結(jié)幾種常用的對(duì)抗訓(xùn)練方法。作者?|?王嘉寧@華師數(shù)據(jù)學(xué)院??
整理?|?NewBeeNLP??
https://blog.csdn.net/qq_36426650/article/details/122807916
對(duì)抗訓(xùn)練旨在對(duì)原始輸入樣本 上施加擾動(dòng) ,得到對(duì)抗樣本后用其進(jìn)行訓(xùn)練:
公式理解:
- 最大化擾動(dòng):挑選一個(gè)能使得模型產(chǎn)生更大損失(梯度較大)的擾動(dòng)量,作為攻擊;
- 最小化損失:根據(jù)最大的擾動(dòng)量,添加到輸入樣本后,朝著最小化含有擾動(dòng)的損失(梯度下降)方向更新參數(shù);
這個(gè)被構(gòu)造出來(lái)的“對(duì)抗樣本”并不能具體對(duì)應(yīng)到某個(gè)單詞,因此,反過(guò)來(lái)在推理階段是沒有辦法通過(guò)修改原始輸入得到這樣的對(duì)抗樣本。
對(duì)抗訓(xùn)練有兩個(gè)作用,一是 提高模型對(duì)惡意攻擊的魯棒性 ,二是 提高模型的泛化能力 。
在CV任務(wù),根據(jù)經(jīng)驗(yàn)性的結(jié)論,對(duì)抗訓(xùn)練往往會(huì)使得模型在非對(duì)抗樣本上的表現(xiàn)變差,然而神奇的是,在NLP任務(wù)中,模型的泛化能力反而變強(qiáng)了。
常用的幾種對(duì)抗訓(xùn)練方法有FGSM、FGM、PGD、FreeAT、YOPO、FreeLB、SMART。本文暫時(shí)只介紹博主常用的3個(gè)方法,分別是 FGM 、 PGD 和 FreeLB 。具體實(shí)現(xiàn)時(shí),不同的對(duì)抗方法會(huì)有差異,但是 從訓(xùn)練速度和代碼編輯難易程度的角度考慮,推薦使用FGM和迭代次數(shù)較少的PGD 。
一、FGM算法
- 首先計(jì)算輸入樣本 (通常為word embedding)的損失函數(shù)以及在 處的梯度:;
- 計(jì)算在輸入樣本的擾動(dòng)量:,其中 為超參數(shù),默認(rèn)取1.0;
- 得到對(duì)抗樣本:;
- 根據(jù)得到的對(duì)抗樣本,再次喂入模型中,計(jì)算損失,并累積梯度;
- 恢復(fù)原始的word embedding,接著下一個(gè)batch。
FGM的代碼量很少,只需要自行實(shí)現(xiàn)簡(jiǎn)單的類即可:
import?torch
class?FGM():
????def?__init__(self,?model):
????????self.model?=?model
????????self.backup?=?{}?#?用于保存模型擾動(dòng)前的參數(shù)
????def?attack(
????????self,?
????????epsilon=1.,?
????????emb_name='word_embeddings'?#?emb_name表示模型中embedding的參數(shù)名
????):
????????'''
????????生成擾動(dòng)和對(duì)抗樣本
????????'''
????????for?name,?param?in?self.model.named_parameters():?#?遍歷模型的所有參數(shù)?
????????????if?param.requires_grad?and?emb_name?in?name:?#?只取word?embedding層的參數(shù)
????????????????self.backup[name]?=?param.data.clone()?#?保存參數(shù)值
????????????????norm?=?torch.norm(param.grad)?#?對(duì)參數(shù)梯度進(jìn)行二范式歸一化
????????????????if?norm?!=?0?and?not?torch.isnan(norm):?#?計(jì)算擾動(dòng),并在輸入?yún)?shù)值上添加擾動(dòng)
????????????????????r_at?=?epsilon?*?param.grad?/?norm
????????????????????param.data.add_(r_at)
????def?restore(
????????self,?
????????emb_name='word_embeddings'?#?emb_name表示模型中embedding的參數(shù)名
????):
????????'''
????????恢復(fù)添加擾動(dòng)的參數(shù)
????????'''
????????for?name,?param?in?self.model.named_parameters():?#?遍歷模型的所有參數(shù)
????????????if?param.requires_grad?and?emb_name?in?name:??#?只取word?embedding層的參數(shù)
????????????????assert?name?in?self.backup
????????????????param.data?=?self.backup[name]?#?重新加載保存的參數(shù)值
????????self.backup?=?{}
在訓(xùn)練時(shí),只需要額外添加5行代碼:
fgm?=?FGM(model)?#?(#1)初始化
for?batch_input,?batch_label?in?data:
????loss?=?model(batch_input,?batch_label)?#?正常訓(xùn)練
????loss.backward()?#?反向傳播,得到正常的grad
????#?對(duì)抗訓(xùn)練
????fgm.attack()?#?(#2)在embedding上添加對(duì)抗擾動(dòng)
????loss_adv?=?model(batch_input,?batch_label)?#?(#3)計(jì)算含有擾動(dòng)的對(duì)抗樣本的loss
????loss_adv.backward()?#?(#4)反向傳播,并在正常的grad基礎(chǔ)上,累加對(duì)抗訓(xùn)練的梯度
????fgm.restore()?#?(#5)恢復(fù)embedding參數(shù)
????#?梯度下降,更新參數(shù)
????optimizer.step()
????model.zero_grad()
二、PGD算法
Project Gradient Descent(PGD)是一種迭代攻擊算法,相比于普通的FGM 僅做一次迭代,PGD是做多次迭代,每次走一小步,每次迭代都會(huì)將擾動(dòng)投射到規(guī)定范圍內(nèi)。形式化描述為:
其中 為擾動(dòng)約束空間(一個(gè)半徑為 的球體),原始的輸入樣本對(duì)應(yīng)的初識(shí)點(diǎn)為球心,避免擾動(dòng)超過(guò)球面。迭代多次后,保證擾動(dòng)在一定范圍內(nèi),如下圖所示: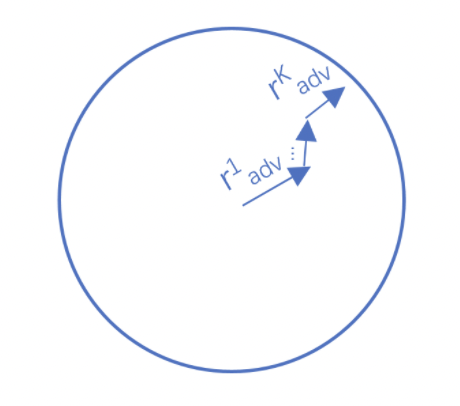
代碼實(shí)現(xiàn)如下所示:
import?torch
class?PGD():
????def?__init__(self,?model):
????????self.model?=?model
????????self.emb_backup?=?{}
????????self.grad_backup?=?{}
????def?attack(self,?epsilon=1.,?alpha=0.3,?emb_name='word_embeddings',?is_first_attack=False):
????????for?name,?param?in?self.model.named_parameters():
????????????if?param.requires_grad?and?emb_name?in?name:
????????????????if?is_first_attack:
????????????????????self.emb_backup[name]?=?param.data.clone()
????????????????norm?=?torch.norm(param.grad)
????????????????if?norm?!=?0?and?not?torch.isnan(norm):
????????????????????r_at?=?alpha?*?param.grad?/?norm
????????????????????param.data.add_(r_at)
????????????????????param.data?=?self.project(name,?param.data,?epsilon)
????def?restore(self,?emb_name='word_embeddings'):
????????for?name,?param?in?self.model.named_parameters():
????????????if?param.requires_grad?and?emb_name?in?name:?
????????????????assert?name?in?self.emb_backup
????????????????param.data?=?self.emb_backup[name]
????????self.emb_backup?=?{}
????def?project(self,?param_name,?param_data,?epsilon):
????????r?=?param_data?-?self.emb_backup[param_name]
????????if?torch.norm(r)?>?epsilon:
????????????r?=?epsilon?*?r?/?torch.norm(r)
????????return?self.emb_backup[param_name]?+?r
????def?backup_grad(self):
????????for?name,?param?in?self.model.named_parameters():
????????????if?param.requires_grad:
????????????????self.grad_backup[name]?=?param.grad.clone()
????def?restore_grad(self):
????????for?name,?param?in?self.model.named_parameters():
????????????if?param.requires_grad:
????????????????param.grad?=?self.grad_backup[name]
pgd?=?PGD(model)
K?=?3
for?batch_input,?batch_label?in?data:
????#?正常訓(xùn)練
????loss?=?model(batch_input,?batch_label)
????loss.backward()?#?反向傳播,得到正常的grad
????pgd.backup_grad()
????#?累積多次對(duì)抗訓(xùn)練——每次生成對(duì)抗樣本后,進(jìn)行一次對(duì)抗訓(xùn)練,并不斷累積梯度
????for?t?in?range(K):
????????pgd.attack(is_first_attack=(t==0))?#?在embedding上添加對(duì)抗擾動(dòng),?first?attack時(shí)備份param.data
????????if?t?!=?K-1:
????????????model.zero_grad()
????????else:
????????????pgd.restore_grad()
????????loss_adv?=?model(batch_input,?batch_label)
????????loss_adv.backward()?#?反向傳播,并在正常的grad基礎(chǔ)上,累加對(duì)抗訓(xùn)練的梯度
????pgd.restore()?#?恢復(fù)embedding參數(shù)
????#?梯度下降,更新參數(shù)
????optimizer.step()
????model.zero_grad()
三、FreeLB算法
FreeLB針對(duì)PGD的多次迭代訓(xùn)練的問(wèn)題進(jìn)行了改進(jìn):
- PGD是迭代 次擾動(dòng)后取最后一次擾動(dòng)的梯度更新參數(shù),F(xiàn)reeLB是取 次迭代中的平均梯度(將 次迭代轉(zhuǎn)換為類似一個(gè)虛擬的batch)。
- 對(duì)抗訓(xùn)練和dropout不能同時(shí)使用;
具體的算法流程為:
很明顯找到FreeLB與PGD的區(qū)別在于累積的方式:
-
FreeLB:通過(guò)對(duì) K K K 次梯度的平均累積作為擾動(dòng)更新
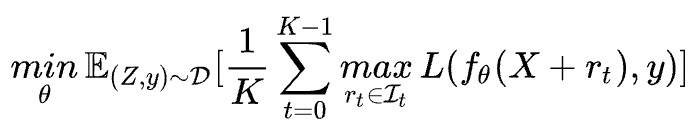
-
PGD:只取最后一次的梯度進(jìn)行更新
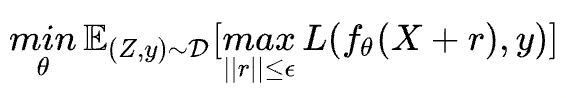
實(shí)現(xiàn)流程如下圖所示: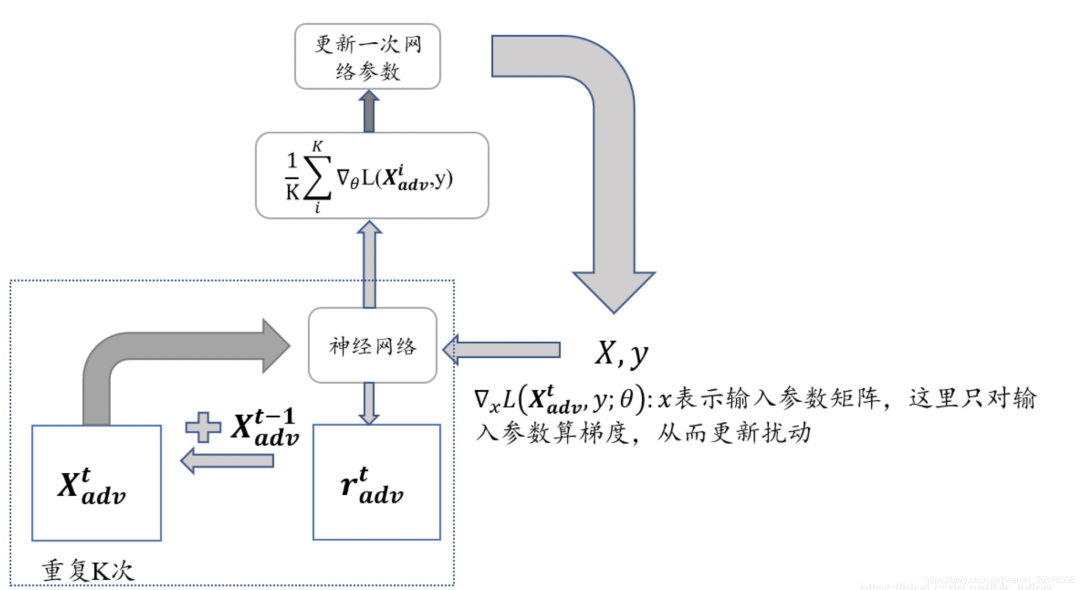
其他對(duì)抗訓(xùn)練方法,以及更為詳細(xì)的理論講解,可參考文末參考文獻(xiàn)。
本文參考資料
[1]一文搞懂NLP中的對(duì)抗訓(xùn)練FGSM/FGM/PGD/FreeAT/YOPO/FreeLB/SMART: https://zhuanlan.zhihu.com/p/103593948
[2]NLP --- >對(duì)抗學(xué)習(xí):從FGM, PGD到FreeLB: https://blog.csdn.net/chencas/article/details/103551852/
[3]【煉丹技巧】功守道:NLP中的對(duì)抗訓(xùn)練 + PyTorch實(shí)現(xiàn): https://zhuanlan.zhihu.com/p/91269728
[4]對(duì)抗學(xué)習(xí)總結(jié):FGSM->FGM->PGD->FreeAT, YOPO ->FreeLb->SMART->LookAhead->VAT: https://blog.csdn.net/weixin_36378508/article/details/116131036
往期
精彩
回顧
- 適合初學(xué)者入門人工智能的路線及資料下載
- (圖文+視頻)機(jī)器學(xué)習(xí)入門系列下載
- 機(jī)器學(xué)習(xí)及深度學(xué)習(xí)筆記等資料打印
- 《統(tǒng)計(jì)學(xué)習(xí)方法》的代碼復(fù)現(xiàn)專輯
- 機(jī)器學(xué)習(xí)交流qq群955171419,加入微信群請(qǐng) 掃碼