
NLP(四十六)對(duì)抗訓(xùn)練的一次嘗試
??初次聽說對(duì)抗訓(xùn)練是在一次實(shí)體識(shí)別比賽的賽后分享中,當(dāng)時(shí)的一些概念,比如Focal Loss、對(duì)抗訓(xùn)練、模型融合、數(shù)據(jù)增強(qiáng)等都讓我感到新奇,之后筆者自己也做了很多這方面的嘗試。本文將分享筆者對(duì)于對(duì)抗訓(xùn)練(FGM)的一次嘗試。
什么是對(duì)抗訓(xùn)練?
??提到“對(duì)抗”,相信大多數(shù)人的第一反應(yīng)都是CV中的對(duì)抗生成網(wǎng)絡(luò) (GAN),殊不知,其實(shí)對(duì)抗也可以作為一種防御機(jī)制,并且經(jīng)過簡(jiǎn)單的修改,便能用在NLP任務(wù)上,提高模型的泛化能力。GAN之父Ian Goodfellow在15年的ICLR論文《Explaining and Harnessing Adversarial Examples》中第一次提出了對(duì)抗訓(xùn)練這個(gè)概念,簡(jiǎn)而言之,就是在原始輸入樣本x上加一個(gè)擾動(dòng)radv,得到對(duì)抗樣本后,用其進(jìn)行訓(xùn)練。這在CV領(lǐng)域比較好理解,部分圖片本身就是自帶噪聲的,比如手抖、光線不佳等,這就是天然的對(duì)抗樣本,它們?cè)谀P陀?xùn)練的時(shí)候就是負(fù)樣本,這些樣本的加入能提升模型的魯棒性。比如下面的經(jīng)典例子:
抗訓(xùn)練的經(jīng)典例子")
從上面的例子中,我們可以看到一張置信度為55.7%的panda圖片在加入了很小的隨機(jī)擾動(dòng)后,模型竟然識(shí)別為了gibbon。
??對(duì)抗訓(xùn)練的一般原理可以用下面的最大最小化公式來體現(xiàn):

其中D代表訓(xùn)練集,x代表輸入,y代表標(biāo)簽,θ是模型參數(shù),L(x,y;θ)是單個(gè)樣本的loss,Δx是對(duì)抗擾動(dòng),Ω是擾動(dòng)空間。Ω是擾動(dòng)空間,Δx是對(duì)抗擾動(dòng),一般擾動(dòng)空間都比較小,避免對(duì)原來樣本的破壞。在訓(xùn)練集合D,選擇合適的對(duì)抗擾動(dòng)來使得當(dāng)個(gè)樣本的loss達(dá)到最大,同時(shí),外層(
E(x,y))就是對(duì)神經(jīng)網(wǎng)絡(luò)的模型參數(shù)θ進(jìn)行優(yōu)化,使其最小化。這頗有一點(diǎn)攻與守的味道,有了隨機(jī)擾動(dòng)的加入,樣本的loss要盡可能大,而訓(xùn)練的模型loss要盡可能小,從而使得模型有了更強(qiáng)的魯棒性,避免樣本的小擾動(dòng)就造成模型推理的結(jié)果偏差。FGM
??FGM(Fast Gradient Method)是對(duì)抗學(xué)習(xí)的一種實(shí)現(xiàn)方式,可以與FGSM(Fast Gradient Sign Method)一起談?wù)摗?duì)于隨機(jī)擾動(dòng)Δx,F(xiàn)GM與FGSM的實(shí)現(xiàn)公式如下:
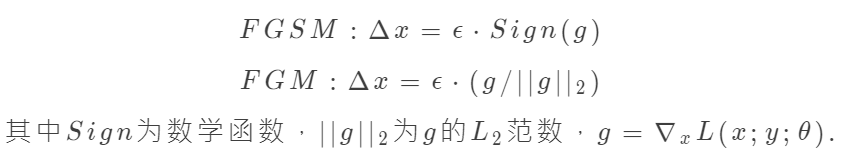
從上面的公式上可以看出,其增大樣本loss的辦法是使得樣本x在梯度方向變大。
??CV領(lǐng)域中,上面的FGM公式比較容易實(shí)現(xiàn),因?yàn)閳D片的向量表示我們可以認(rèn)為是連續(xù)的實(shí)數(shù),而在NLP中,一般字或詞的表示為One-hot向量,不好直接進(jìn)行樣本擾動(dòng)。一種簡(jiǎn)單的想法是在word Embedding向量的時(shí)候進(jìn)行擾動(dòng)。Embedding層的輸出是直接取自于Embedding參數(shù)矩陣的,因此我們可以直接對(duì)Embedding參數(shù)矩陣進(jìn)行擾動(dòng)。這樣得到的對(duì)抗樣本的多樣性會(huì)少一些(因?yàn)椴煌瑯颖镜耐粋€(gè)token共用了相同的擾動(dòng)),但仍然能起到正則化的作用,而且這樣實(shí)現(xiàn)起來容易得多。
??我們不必自己動(dòng)手去實(shí)現(xiàn)上述的FGM,蘇建林在bert4keras工具中已經(jīng)實(shí)現(xiàn)了FGM的腳本,可以參考:https://github.com/bojone/keras_adversarial_training,這是Keras框架下的實(shí)現(xiàn)。而瓦特蘭蒂斯在博客【煉丹技巧】功守道:NLP中的對(duì)抗訓(xùn)練 + PyTorch實(shí)現(xiàn)中給出了Torch框架下的FGM實(shí)現(xiàn)。兩者使用起來都非常方便。
??下面將介紹筆者使用FGM在keras-bert模塊中的實(shí)驗(yàn)。
實(shí)驗(yàn)結(jié)果
??筆者使用keras-bert模塊實(shí)現(xiàn)了命名實(shí)體識(shí)別、文本多分類、文本多標(biāo)簽分類任務(wù),如下:
??我們將對(duì)比在同樣的模型參數(shù)下,相同數(shù)據(jù)集在使用FGM前后的模型評(píng)估指標(biāo)的對(duì)比:
人民日?qǐng)?bào)實(shí)體識(shí)別任務(wù)(評(píng)估指標(biāo)為micro avg f1-score)
| - | 訓(xùn)練1 | 訓(xùn)練2 | 訓(xùn)練3 | avg |
|---|---|---|---|---|
| 使用FGM前 | 0.9276 | 0.9217 | 0.9252 | 0.9248 |
| 使用FGM后 | 0.9287 | 0.9273 | 0.9294 | 0.9285 |