
當代研究生應當掌握的5種Pytorch并行訓練方法(單機多卡)
點擊上方“小白學視覺”,選擇加"星標"或“置頂”
重磅干貨,第一時間送達 
導讀
利用PyTorch,作者編寫了不同加速庫在ImageNet上的單機多卡使用示例,方便讀者取用。
又到適宜劃水的周五啦,機器在學習,人很無聊。在打開 b 站 “學習” 之前看著那空著一半的顯卡決定寫點什么喂飽它們~因此,從 V100-PICE/V100/K80 中各拿出 4 張卡,試驗一下哪種分布式學習庫速度最快!這下終于能把剩下的顯存吃完啦,又是老師的勤奮好學生啦(我真是個小機靈鬼)!
Take-Away
筆者使用 PyTorch 編寫了不同加速庫在 ImageNet 上的使用示例(單機多卡),需要的同學可以當作 quickstart 將需要的部分 copy 到自己的項目中(Github 請點擊下面鏈接):
1、簡單方便的 nn.DataParallel
https://github.com/tczhangzhi/pytorch-distributed/blob/master/dataparallel.py
2、使用 torch.distributed 加速并行訓練
https://github.com/tczhangzhi/pytorch-distributed/blob/master/distributed.py
3、使用 torch.multiprocessing 取代啟動器
https://github.com/tczhangzhi/pytorch-distributed/blob/master/multiprocessing_distributed.py
4、使用 apex 再加速
https://github.com/tczhangzhi/pytorch-distributed/blob/master/apex_distributed.py
5、horovod 的優(yōu)雅實現(xiàn)
https://github.com/tczhangzhi/pytorch-distributed/blob/master/horovod_distributed.py
這里,筆者記錄了使用 4 塊 Tesla V100-PICE 在 ImageNet 進行了運行時間的測試,測試結果發(fā)現(xiàn) Apex 的加速效果最好,但與 Horovod/Distributed 差別不大,平時可以直接使用內置的 Distributed。Dataparallel 較慢,不推薦使用。(后續(xù)會補上 V100/K80 上的測試結果,穿插了一些試驗所以中斷了)
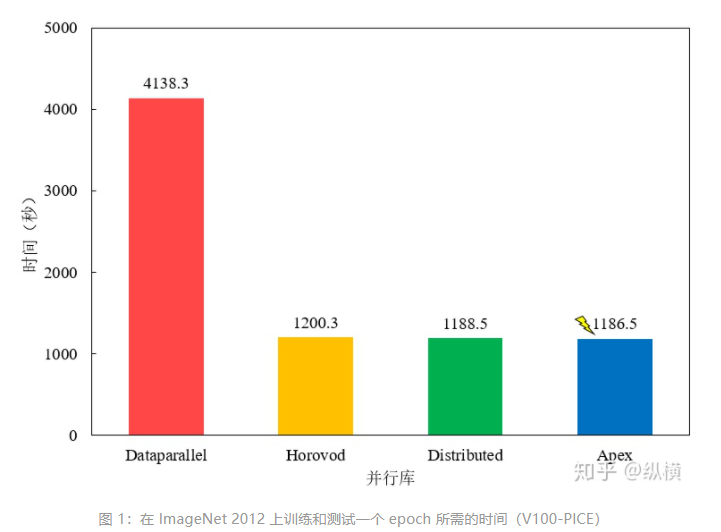
簡要記錄一下不同庫的分布式訓練方式,當作代碼的 README(我真是個小機靈鬼)~
簡單方便的 nn.DataParallel
DataParallel 可以幫助我們(使用單進程控)將模型和數據加載到多個 GPU 中,控制數據在 GPU 之間的流動,協(xié)同不同 GPU 上的模型進行并行訓練(細粒度的方法有 scatter,gather 等等)。
DataParallel 使用起來非常方便,我們只需要用 DataParallel 包裝模型,再設置一些參數即可。需要定義的參數包括:參與訓練的 GPU 有哪些,device_ids=gpus;用于匯總梯度的 GPU 是哪個,output_device=gpus[0] 。DataParallel 會自動幫我們將數據切分 load 到相應 GPU,將模型復制到相應 GPU,進行正向傳播計算梯度并匯總:
model= nn.DataParallel(model.cuda(), device_ids=gpus, output_device=gpus[0])值得注意的是,模型和數據都需要先 load 進 GPU 中,DataParallel 的 module 才能對其進行處理,否則會報錯:
# 這里要 model.cuda()model = nn.DataParallel(model.cuda(), device_ids=gpus, output_device=gpus[0])for epoch in range(100):for batch_idx, (data, target) in enumerate(train_loader):# 這里要 images/target.cuda()images = images.cuda(non_blocking=True)target = target.cuda(non_blocking=True)...output = model(images)loss = criterion(output, target)...optimizer.zero_grad()loss.backward()optimizer.step()
# main.pyimport torchimport torch.distributed as distgpus = [0, 1, 2, 3]:{}'.format(gpus[0]))train_dataset = ...train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=...)model = ...model = nn.DataParallel(model.to(device), device_ids=gpus, output_device=gpus[0])optimizer = optim.SGD(model.parameters())for epoch in range(100):for batch_idx, (data, target) in enumerate(train_loader):images = images.cuda(non_blocking=True)target = target.cuda(non_blocking=True)...output = model(images)loss = criterion(output, target)...optimizer.zero_grad()loss.backward()optimizer.step()
python main.py使用 torch.distributed 加速并行訓練
在 pytorch 1.0 之后,官方終于對分布式的常用方法進行了封裝,支持 all-reduce,broadcast,send 和 receive 等等。通過 MPI 實現(xiàn) CPU 通信,通過 NCCL 實現(xiàn) GPU 通信。官方也曾經提到用 DistributedDataParallel 解決 DataParallel 速度慢,GPU 負載不均衡的問題,目前已經很成熟了~
parser = argparse.ArgumentParser()parser.add_argument('--local_rank', default=-1, type=int,help='node rank for distributed training')args = parser.parse_args()print(args.local_rank)
dist.init_process_group(backend='nccl')train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=..., sampler=train_sampler)
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.local_rank])torch.cuda.set_device(args.local_rank)model.cuda()for epoch in range(100):for batch_idx, (data, target) in enumerate(train_loader):images = images.cuda(non_blocking=True)target = target.cuda(non_blocking=True)...output = model(images)loss = criterion(output, target)...optimizer.zero_grad()loss.backward()optimizer.step()
# main.pyimport torchimport argparseimport torch.distributed as distparser = argparse.ArgumentParser()default=-1, type=int,help='node rank for distributed training')args = parser.parse_args()='nccl')torch.cuda.set_device(args.local_rank)train_dataset = ...train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=..., sampler=train_sampler)model = ...model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.local_rank])optimizer = optim.SGD(model.parameters())for epoch in range(100):for batch_idx, (data, target) in enumerate(train_loader):images = images.cuda(non_blocking=True)target = target.cuda(non_blocking=True)...output = model(images)loss = criterion(output, target)...optimizer.zero_grad()loss.backward()optimizer.step()
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 main.py使用 torch.multiprocessing 取代啟動器
有的同學可能比較熟悉 torch.multiprocessing,也可以手動使用 torch.multiprocessing 進行多進程控制。繞開 torch.distributed.launch 自動控制開啟和退出進程的一些小毛病~
import torch.multiprocessing as mpmp.spawn(main_worker, nprocs=4, args=(4, myargs))
def main_worker(proc, ngpus_per_node, args):='nccl', init_method='tcp://127.0.0.1:23456', world_size=4, rank=gpu)torch.cuda.set_device(args.local_rank)train_dataset = ...train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=..., sampler=train_sampler)model = ...model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.local_rank])optimizer = optim.SGD(model.parameters())for epoch in range(100):for batch_idx, (data, target) in enumerate(train_loader):images = images.cuda(non_blocking=True)target = target.cuda(non_blocking=True)...output = model(images)loss = criterion(output, target)...optimizer.zero_grad()loss.backward()optimizer.step()
dist.init_process_group(backend='nccl', init_method='tcp://127.0.0.1:23456', world_size=4, rank=gpu)# main.pyimport torchimport torch.distributed as distimport torch.multiprocessing as mpnprocs=4, args=(4, myargs))def main_worker(proc, ngpus_per_node, args):='nccl', init_method='tcp://127.0.0.1:23456', world_size=4, rank=gpu)torch.cuda.set_device(args.local_rank)train_dataset = ...train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=..., sampler=train_sampler)model = ...model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.local_rank])optimizer = optim.SGD(model.parameters())for epoch in range(100):for batch_idx, (data, target) in enumerate(train_loader):images = images.cuda(non_blocking=True)target = target.cuda(non_blocking=True)...output = model(images)loss = criterion(output, target)...optimizer.zero_grad()loss.backward()optimizer.step()
python main.py使用 Apex 再加速
Apex 是 NVIDIA 開源的用于混合精度訓練和分布式訓練庫。Apex 對混合精度訓練的過程進行了封裝,改兩三行配置就可以進行混合精度的訓練,從而大幅度降低顯存占用,節(jié)約運算時間。此外,Apex 也提供了對分布式訓練的封裝,針對 NVIDIA 的 NCCL 通信庫進行了優(yōu)化。
from apex import ampmodel, optimizer = amp.initialize(model, optimizer)
from apex.parallel import DistributedDataParallelmodel = DistributedDataParallel(model)# # torch.distributed# model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.local_rank])# model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.local_rank], output_device=args.local_rank)
with amp.scale_loss(loss, optimizer) as scaled_loss:scaled_loss.backward()
# main.pyimport torchimport argparseimport torch.distributed as distfrom apex.parallel import DistributedDataParallelparser = argparse.ArgumentParser()parser.add_argument('--local_rank', default=-1, type=int,help='node rank for distributed training')args = parser.parse_args()dist.init_process_group(backend='nccl')torch.cuda.set_device(args.local_rank)train_dataset = ...train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=..., sampler=train_sampler)model = ...model, optimizer = amp.initialize(model, optimizer)model = DistributedDataParallel(model, device_ids=[args.local_rank])optimizer = optim.SGD(model.parameters())for epoch in range(100):for batch_idx, (data, target) in enumerate(train_loader):images = images.cuda(non_blocking=True)target = target.cuda(non_blocking=True)...output = model(images)loss = criterion(output, target)optimizer.zero_grad()with amp.scale_loss(loss, optimizer) as scaled_loss:scaled_loss.backward()optimizer.step()
UDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 main.pyHorovod 的優(yōu)雅實現(xiàn)
Horovod 是 Uber 開源的深度學習工具,它的發(fā)展吸取了 Facebook "Training ImageNet In 1 Hour" 與百度 "Ring Allreduce" 的優(yōu)點,可以無痛與 PyTorch/Tensorflow 等深度學習框架結合,實現(xiàn)并行訓練。
import horovod.torch as hvdhvd.local_rank()
hvd.init()train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=..., sampler=train_sampler)
hvd.broadcast_parameters(model.state_dict(), root_rank=0)hvd.DistributedOptimizer(optimizer, named_parameters=model.named_parameters(), compression=hvd.Compression.fp16)torch.cuda.set_device(args.local_rank)for epoch in range(100):for batch_idx, (data, target) in enumerate(train_loader):images = images.cuda(non_blocking=True)target = target.cuda(non_blocking=True)...output = model(images)loss = criterion(output, target)...optimizer.zero_grad()loss.backward()optimizer.step()
# main.pyimport torchimport horovod.torch as hvdhvd.init()torch.cuda.set_device(hvd.local_rank())train_dataset = ...train_sampler = torch.utils.data.distributed.DistributedSampler(num_replicas=hvd.size(), rank=hvd.rank())train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=..., sampler=train_sampler)model = ...model.cuda()optimizer = optim.SGD(model.parameters())optimizer = hvd.DistributedOptimizer(optimizer, named_parameters=model.named_parameters())root_rank=0)for epoch in range(100):for batch_idx, (data, target) in enumerate(train_loader):images = images.cuda(non_blocking=True)target = target.cuda(non_blocking=True)...output = model(images)loss = criterion(output, target)...optimizer.zero_grad()loss.backward()optimizer.step()
CUDA_VISIBLE_DEVICES=0,1,2,3 horovodrun -np 4 -H localhost:4 --verbose python main.py尾注
下載1:OpenCV-Contrib擴展模塊中文版教程
在「小白學視覺」公眾號后臺回復:擴展模塊中文教程,即可下載全網第一份OpenCV擴展模塊教程中文版,涵蓋擴展模塊安裝、SFM算法、立體視覺、目標跟蹤、生物視覺、超分辨率處理等二十多章內容。
下載2:Python視覺實戰(zhàn)項目52講 在「小白學視覺」公眾號后臺回復:Python視覺實戰(zhàn)項目,即可下載包括圖像分割、口罩檢測、車道線檢測、車輛計數、添加眼線、車牌識別、字符識別、情緒檢測、文本內容提取、面部識別等31個視覺實戰(zhàn)項目,助力快速學校計算機視覺。
下載3:OpenCV實戰(zhàn)項目20講 在「小白學視覺」公眾號后臺回復:OpenCV實戰(zhàn)項目20講,即可下載含有20個基于OpenCV實現(xiàn)20個實戰(zhàn)項目,實現(xiàn)OpenCV學習進階。
交流群
歡迎加入公眾號讀者群一起和同行交流,目前有SLAM、三維視覺、傳感器、自動駕駛、計算攝影、檢測、分割、識別、醫(yī)學影像、GAN、算法競賽等微信群(以后會逐漸細分),請掃描下面微信號加群,備注:”昵稱+學校/公司+研究方向“,例如:”張三 + 上海交大 + 視覺SLAM“。請按照格式備注,否則不予通過。添加成功后會根據研究方向邀請進入相關微信群。請勿在群內發(fā)送廣告,否則會請出群,謝謝理解~