
PyTorch多GPU并行訓(xùn)練方法及問(wèn)題整理

極市導(dǎo)讀
?本文詳細(xì)地介紹了在PyTorch中進(jìn)行單機(jī)多卡并行訓(xùn)練和多機(jī)多GPU訓(xùn)練的方法,并給出了幾個(gè)常見(jiàn)問(wèn)題的解決方案。
1.單機(jī)多卡并行訓(xùn)練
1.1.torch.nn.DataParallel
os.environ['CUDA_VISIBLE_DEVICES']來(lái)限制使用的GPU個(gè)數(shù), 例如我要使用第0和第3編號(hào)的GPU, 那么只需要在程序中設(shè)置:os.environ['CUDA_VISIBLE_DEVICES'] = '0,3'
model = nn.DataParallel(model)model = model.cuda()
inputs = inputs.cuda()labels = labels.cuda()
model = Model(input_size, output_size)if torch.cuda.device_count() > 1:print("Let's use", torch.cuda.device_count(), "GPUs!")# dim = 0 [30, xxx] -> [10, ...], [10, ...], [10, ...] on 3 GPUsmodel = nn.DataParallel(model)model.to(device)
DataParallel的內(nèi)部代碼, 我們就可以發(fā)現(xiàn), 其實(shí)是一樣的:class DataParallel(Module):def __init__(self, module, device_ids=None, output_device=None, dim=0):super(DataParallel, self).__init__()if not torch.cuda.is_available():self.module = moduleself.device_ids = []returnif device_ids is None:device_ids = list(range(torch.cuda.device_count()))if output_device is None:output_device = device_ids[0]
device_ids的話, 程序會(huì)自動(dòng)找到這個(gè)機(jī)器上面可以用的所有的顯卡, 然后用于訓(xùn)練. 但是因?yàn)槲覀兦懊媸褂?code style="font-size: 14px;word-wrap: break-word;padding: 2px 4px;border-radius: 4px;margin: 0 2px;color: #1e6bb8;background-color: rgba(27,31,35,.05);font-family: Operator Mono, Consolas, Monaco, Menlo, monospace;word-break: break-all;">os.environ['CUDA_VISIBLE_DEVICES']限定了這個(gè)程序可以使用的顯卡, 所以這個(gè)地方程序如果自己獲取的話, 獲取到的其實(shí)就是我們上面設(shè)定的那幾個(gè)顯卡.os.environ['CUDA_VISIBLE_DEVICES']對(duì)可以使用的顯卡進(jìn)行限定之后, 顯卡的實(shí)際編號(hào)和程序看到的編號(hào)應(yīng)該是不一樣的, 例如上面我們?cè)O(shè)定的是os.environ['CUDA_VISIBLE_DEVICES']="0,2", 但是程序看到的顯卡編號(hào)應(yīng)該被改成了'0,1', 也就是說(shuō)程序所使用的顯卡編號(hào)實(shí)際上是經(jīng)過(guò)了一次映射之后才會(huì)映射到真正的顯卡編號(hào)上面的, 例如這里的程序看到的1對(duì)應(yīng)實(shí)際的21.2.如何平衡DataParallel帶來(lái)的顯存使用不平衡的問(wèn)題
DistributedDataParallel來(lái)代替 DataParallel(實(shí)際上DistributedDataParallel顯存分配的也不是很平衡), 但是從某些角度來(lái)說(shuō), DataParallel使用起來(lái)確實(shí)比較方便, 而且最近使用 DistributedDataParallel 遇到一些小問(wèn)題. 所以這里提供一個(gè)解決顯存使用不平衡問(wèn)題的方案:DataParallel 類之后進(jìn)行了改寫(xiě):class BalancedDataParallel(DataParallel):def __init__(self, gpu0_bsz, *args, **kwargs):self.gpu0_bsz = gpu0_bszsuper().__init__(*args, **kwargs)...
BalancedDataParallel 類使用起來(lái)和 DataParallel 類似, 下面是一個(gè)示例代碼:my_net = MyNet()my_net = BalancedDataParallel(gpu0_bsz // acc_grad, my_net, dim=0).cuda()
batch_szie = 8gpu0_bsz = 2acc_grad = 1my_net = MyNet()my_net = BalancedDataParallel(gpu0_bsz // acc_grad, my_net, dim=0).cuda()
batch_szie = 16gpu0_bsz = 4acc_grad = 2my_net = MyNet()my_net = BalancedDataParallel(gpu0_bsz // acc_grad, my_net, dim=0).cuda()
1.3.torch.nn.parallel.DistributedDataParallel
DistributedDataParallel來(lái)代替DataParallel, 據(jù)說(shuō)是因?yàn)?code style="font-size: 14px;word-wrap: break-word;padding: 2px 4px;border-radius: 4px;margin: 0 2px;color: #1e6bb8;background-color: rgba(27,31,35,.05);font-family: Operator Mono, Consolas, Monaco, Menlo, monospace;word-break: break-all;">DistributedDataParallel比DataParallel運(yùn)行的更快, 然后顯存分屏的更加均衡. 而且DistributedDataParallel功能更加強(qiáng)悍, 例如分布式的模型(一個(gè)模型太大, 以至于無(wú)法放到一個(gè)GPU上運(yùn)行, 需要分開(kāi)到多個(gè)GPU上面執(zhí)行). 只有DistributedDataParallel支持分布式的模型像單機(jī)模型那樣可以進(jìn)行多機(jī)多卡的運(yùn)算.當(dāng)然具體的怎么個(gè)情況, 建議看官方文檔.os.environ['CUDA_VISIBLE_DEVICES'], 然后再進(jìn)行下面的步驟.torch.distributed.init_process_group(backend='nccl', init_method='tcp://localhost:23456', rank=0, world_size=1)
torch.distributed.init_process_group(backend="nccl")model = DistributedDataParallel(model) # device_ids will include all GPU devices by default
main.py, 可以使用如下的方法進(jìn)行(參考1 參考2):python -m torch.distributed.launch main.py
--local_rank, 否則運(yùn)行還是會(huì)出錯(cuò)的。DataParallel很類似了.model = model.cuda()model = nn.parallel.DistributedDataParallel(model)
model加載到GPU, 然后才能使用DistributedDataParallel進(jìn)行分發(fā), 之后的使用和DataParallel就基本一樣了2.多機(jī)多gpu訓(xùn)練
2.1.初始化
torch.distributed.init_process_group()進(jìn)行初始化. torch.distributed.init_process_group()包含四個(gè)常用的參數(shù)backend: 后端, 實(shí)際上是多個(gè)機(jī)器之間交換數(shù)據(jù)的協(xié)議init_method: 機(jī)器之間交換數(shù)據(jù), 需要指定一個(gè)主節(jié)點(diǎn), 而這個(gè)參數(shù)就是指定主節(jié)點(diǎn)的world_size: 介紹都是說(shuō)是進(jìn)程, 實(shí)際就是機(jī)器的個(gè)數(shù), 例如兩臺(tái)機(jī)器一起訓(xùn)練的話, world_size就設(shè)置為2rank: 區(qū)分主節(jié)點(diǎn)和從節(jié)點(diǎn)的, 主節(jié)點(diǎn)為0, 剩余的為了1-(N-1), N為要使用的機(jī)器的數(shù)量, 也就是world_size
2.1.1.初始化backend
backend, 也就是俗稱的后端, 在pytorch的官方教程中提供了以下這些后端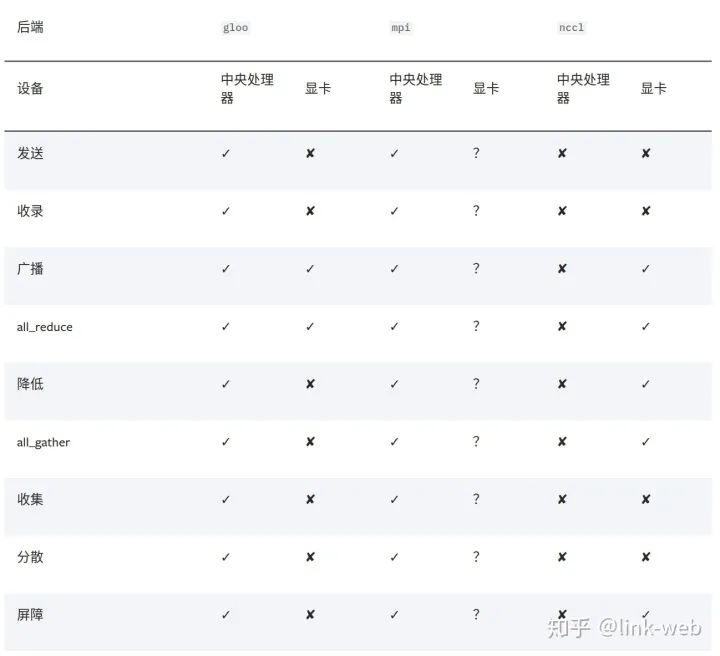
gloo, 因?yàn)楸碇锌梢钥吹?gloo對(duì)cpu的支持是最好的, 然后如果使用gpu進(jìn)行分布式計(jì)算, 建議使用nccl, 實(shí)際測(cè)試中我也感覺(jué)到, 當(dāng)使用gpu的時(shí)候, nccl的效率是高于gloo的. 根據(jù)博客和官網(wǎng)的態(tài)度, 好像都不怎么推薦在多gpu的時(shí)候使用mpinccl和gloo一般會(huì)自己尋找網(wǎng)絡(luò)接口, 但是某些時(shí)候, 比如我測(cè)試用的服務(wù)器, 不知道是系統(tǒng)有點(diǎn)古老, 還是網(wǎng)卡比較多, 需要自己手動(dòng)設(shè)置. 設(shè)置的方法也比較簡(jiǎn)單, 在Python的代碼中, 使用下面的代碼進(jìn)行設(shè)置就行:import os# 以下二選一, 第一個(gè)是使用gloo后端需要設(shè)置的, 第二個(gè)是使用nccl需要設(shè)置的os.environ['GLOO_SOCKET_IFNAME'] = 'eth0'os.environ['NCCL_SOCKET_IFNAME'] = 'eth0'
ifconfig, 然后找到那個(gè)帶自己ip地址的就是了, 我見(jiàn)過(guò)的一般就是em0, eth0, esp2s0之類的, 當(dāng)然具體的根據(jù)你自己的填寫(xiě). 如果沒(méi)裝ifconfig, 輸入命令會(huì)報(bào)錯(cuò), 但是根據(jù)報(bào)錯(cuò)提示安裝一個(gè)就行了.2.1.2.初始化init_method
init_method的方法有兩種, 一種是使用TCP進(jìn)行初始化, 另外一種是使用共享文件系統(tǒng)進(jìn)行初始化2.1.2.1.使用TCP初始化
import torch.distributed as distdist.init_process_group(backend, init_method='tcp://10.1.1.20:23456',rank=rank, world_size=world_size)
tcp://ip:端口號(hào), 首先ip地址是你的主節(jié)點(diǎn)的ip地址, 也就是rank參數(shù)為0的那個(gè)主機(jī)的ip地址, 然后再選擇一個(gè)空閑的端口號(hào), 這樣就可以初始化init_method了.2.1.2.2.使用共享文件系統(tǒng)初始化
import torch.distributed as distdist.init_process_group(backend, init_method='file:///mnt/nfs/sharedfile',rank=rank, world_size=world_size)
2.1.3.初始化rank和world_size
rank值不同, 但是主機(jī)的rank必須為0, 而且使用init_method的ip一定是rank為0的主機(jī), 其次world_size是你的主機(jī)數(shù)量, 你不能隨便設(shè)置這個(gè)數(shù)值, 你的參與訓(xùn)練的主機(jī)數(shù)量達(dá)不到world_size的設(shè)置值時(shí), 代碼是不會(huì)執(zhí)行的.2.1.4.初始化中一些需要注意的地方
argparse模塊(命令行參數(shù)的形式)輸入, 不建議寫(xiě)死在代碼中, 也不建議使用pycharm之類的IDE進(jìn)行代碼的運(yùn)行, 強(qiáng)烈建議使用命令行直接運(yùn)行.distributed.py:python distributed.py -bk nccl -im tcp://10.10.10.1:12345 -rn 0 -ws 2
rank為0, 同時(shí)設(shè)置了使用兩個(gè)主機(jī), 在從節(jié)點(diǎn)運(yùn)行的時(shí)候, 輸入的代碼是下面這樣:python distributed.py -bk nccl -im tcp://10.10.10.1:12345 -rn 1 -ws 2
rank的值, 其他的值一律不得修改, 否則程序就卡死了初始化到這里也就結(jié)束了.2.2.數(shù)據(jù)的處理-DataLoader
torch.utils.data.distributed.DistributedSampler來(lái)規(guī)避數(shù)據(jù)傳輸?shù)膯?wèn)題. 首先看下面的代碼:print("Initialize Dataloaders...")# Define the transform for the data. Notice, we must resize to 224x224 with this dataset and model.transform = transforms.Compose([transforms.Resize(224),transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])# Initialize Datasets. STL10 will automatically download if not presenttrainset = datasets.STL10(root='./data', split='train', download=True, transform=transform)valset = datasets.STL10(root='./data', split='test', download=True, transform=transform)# Create DistributedSampler to handle distributing the dataset across nodes when training# This can only be called after torch.distributed.init_process_group is called# 這一句就是和平時(shí)使用有點(diǎn)不一樣的地方train_sampler = torch.utils.data.distributed.DistributedSampler(trainset)# Create the Dataloaders to feed data to the training and validation stepstrain_loader = torch.utils.data.DataLoader(trainset, batch_size=batch_size, shuffle=(train_sampler is None), num_workers=workers, pin_memory=False, sampler=train_sampler)val_loader = torch.utils.data.DataLoader(valset, batch_size=batch_size, shuffle=False, num_workers=workers, pin_memory=False)
trainset送到了DistributedSampler中創(chuàng)造了一個(gè)train_sampler, 然后在構(gòu)造train_loader的時(shí)候, 參數(shù)中傳入了一個(gè)sampler=train_sampler. 使用這些的意圖是, 讓不同節(jié)點(diǎn)的機(jī)器加載自己本地的數(shù)據(jù)進(jìn)行訓(xùn)練, 也就是說(shuō)進(jìn)行多機(jī)多卡訓(xùn)練的時(shí)候, 不再是從主節(jié)點(diǎn)分發(fā)數(shù)據(jù)到各個(gè)從節(jié)點(diǎn), 而是各個(gè)從節(jié)點(diǎn)自己從自己的硬盤(pán)上讀取數(shù)據(jù).DistributedSampler來(lái)創(chuàng)造一個(gè)sampler提供給DataLoader, sampler的作用自定義一個(gè)數(shù)據(jù)的編號(hào), 然后讓DataLoader按照這個(gè)編號(hào)來(lái)提取數(shù)據(jù)放入到模型中訓(xùn)練, 其中sampler參數(shù)和shuffle參數(shù)不能同時(shí)指定, 如果這個(gè)時(shí)候還想要可以隨機(jī)的輸入數(shù)據(jù), 我們可以在DistributedSampler中指定shuffle參數(shù), 具體的可以參考官網(wǎng)的api, 拉到最后就是DistributedSampler2.3.模型的處理
DistributedDataParallelmodel = model.cuda()model = nn.parallel.DistributedDataParallel(model)
2.4.模型的保存與加載
def demo_checkpoint(rank, world_size):setup(rank, world_size)# setup devices for this process, rank 1 uses GPUs [0, 1, 2, 3] and# rank 2 uses GPUs [4, 5, 6, 7].n = torch.cuda.device_count() // world_sizedevice_ids = list(range(rank * n, (rank + 1) * n))model = ToyModel().to(device_ids[0])# output_device defaults to device_ids[0]ddp_model = DDP(model, device_ids=device_ids)loss_fn = nn.MSELoss()optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)CHECKPOINT_PATH = tempfile.gettempdir() + "/model.checkpoint"if rank == 0:# All processes should see same parameters as they all start from same# random parameters and gradients are synchronized in backward passes.# Therefore, saving it in one process is sufficient.torch.save(ddp_model.state_dict(), CHECKPOINT_PATH)# Use a barrier() to make sure that process 1 loads the model after process# 0 saves it.dist.barrier()# configure map_location properlyrank0_devices = [x - rank * len(device_ids) for x in device_ids]device_pairs = zip(rank0_devices, device_ids)map_location = {'cuda:%d' % x: 'cuda:%d' % y for x, y in device_pairs}ddp_model.load_state_dict(torch.load(CHECKPOINT_PATH, map_location=map_location))optimizer.zero_grad()outputs = ddp_model(torch.randn(20, 10))labels = torch.randn(20, 5).to(device_ids[0])loss_fn = nn.MSELoss()loss_fn(outputs, labels).backward()optimizer.step()# Use a barrier() to make sure that all processes have finished reading the# checkpointdist.barrier()if rank == 0:os.remove(CHECKPOINT_PATH)cleanup()
dist.barrier(), 這個(gè)是來(lái)自torch.distributed.barrier(), 根據(jù)pytorch的官網(wǎng)的介紹, 這個(gè)函數(shù)的功能是同步所有的進(jìn)程, 直到整組(也就是所有節(jié)點(diǎn)的所有GPU)到達(dá)這個(gè)函數(shù)的時(shí)候, 才會(huì)執(zhí)行后面的代碼, 看上面的代碼, 可以看到, 在保存模型的時(shí)候, 是只找rank為0的點(diǎn)保存模型, 然后在加載模型的時(shí)候, 首先得讓所有的節(jié)點(diǎn)同步一下, 然后給所有的節(jié)點(diǎn)加載上模型, 然后在進(jìn)行下一步的時(shí)候, 還要同步一下, 保證所有的節(jié)點(diǎn)都讀完了模型. 雖然我不清楚這樣做的意義是什么, 但是官網(wǎng)說(shuō)不這樣做會(huì)導(dǎo)致一些問(wèn)題, 我并沒(méi)有實(shí)際操作, 不發(fā)表意見(jiàn)。rank=0的節(jié)點(diǎn), 然后我看在論壇上, 有人也會(huì)保存所有節(jié)點(diǎn)的模型, 然后進(jìn)行計(jì)算, 至于保存哪些, 我并沒(méi)有做實(shí)驗(yàn), 所以并不清楚到底哪種最好。推薦閱讀

評(píng)論
圖片
表情