
綜述:基于點云的自動駕駛3D目標檢測和分類方法

極市導讀
本文基于現(xiàn)有的自動駕駛中利用3D點云數(shù)據(jù)進行目標檢測的文獻,從數(shù)據(jù)特征提取和目標檢測模型等方面對不同技術(shù)進行比較。 >>加入極市CV技術(shù)交流群,走在計算機視覺的最前沿

參考論文:Point-Cloud based 3D Object Detection and Classification Methods for Self-Driving Applications: A Survey and Taxonomy
Abstract
在深度學習技術(shù)的影響下,自動駕駛已經(jīng)成為未來發(fā)展的中心,自2010年,圍繞自動駕駛技術(shù)的研究快速發(fā)展,出現(xiàn)了眾多新穎的目標檢測技術(shù).最初開始人們檢測圖像數(shù)據(jù)中的對象,近期出現(xiàn)了利用3D點云數(shù)據(jù)(激光雷達可以更準確地檢測車輛周圍環(huán)境)進行目標檢測的技術(shù).本文基于現(xiàn)有的自動駕駛中利用3D點云數(shù)據(jù)進行目標檢測的文獻,從數(shù)據(jù)特征提取和目標檢測模型等方面對不同技術(shù)進行比較.
Introduction
根據(jù)世衛(wèi)(WHO)統(tǒng)計每年因為交通事故造成的死亡或殘疾的人數(shù)達5千萬人數(shù).而通過自動駕駛技術(shù)不僅可以大幅度降低車禍的死亡人數(shù),還可以提高車輛運行效率.自動駕駛車輛要從周圍環(huán)境中收集關(guān)鍵信息(行人、車輛、自行車等),預測他們未來的狀態(tài).
目前自動駕駛車輛主要使用LiDAR(激光雷達),如表1所示,LiDAR可以精確測量傳感器與周圍障礙物之間的距離,同時提供豐富的幾何信息、形狀和比例信息.但也有其他傳感解決方案已在自動駕駛環(huán)境中進行了多種用途的探索.例如,基于相機的解決方案可以提供高密度像素強度信息優(yōu)勢,但缺乏距離信息的缺點,而3D相機又有成本昂貴以及對光照條件要求嚴格的缺點.
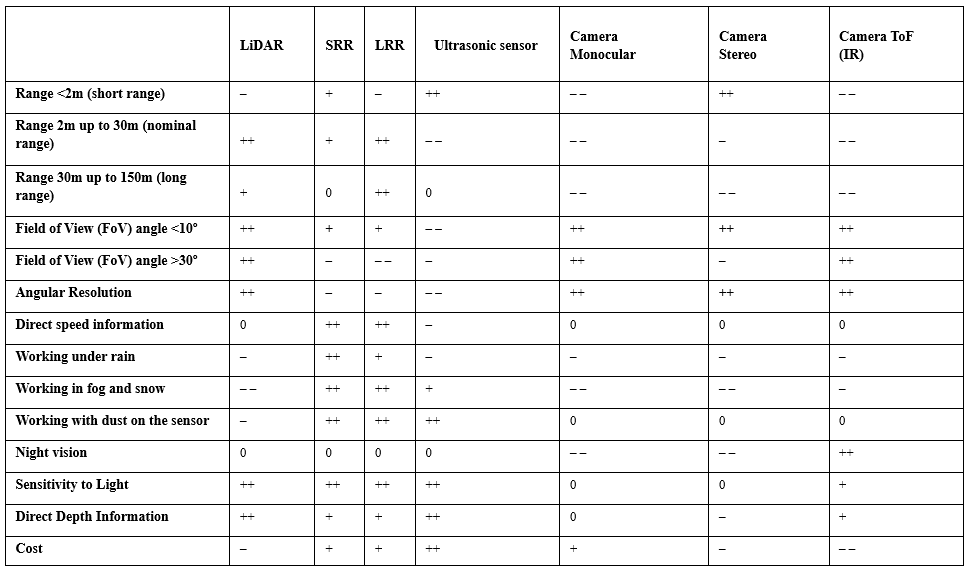
(++)完全適應的傳感器;(+)性能良好的傳感器;(?) 傳感器可能符合標準,但可能存在缺點;(? ?) 傳感器,可用于適應和額外的重型治療;(0)傳感器不能滿足標準或不適用;
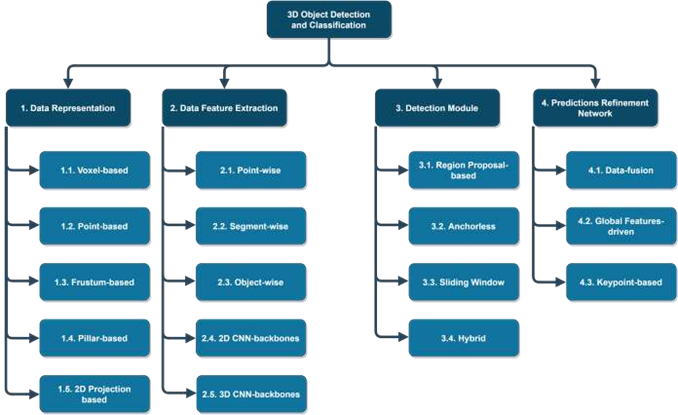
接下來,我們將目標檢測的各種貢獻分為Data Representation、Data Feature Extraction、Detection Module和Prediction Refinement Network四大類,如圖1所示.
Point-based保留了點云的全部信息,如PointNet使用Point-based數(shù)據(jù)提取局部和全局特征.Voxel-based損失了部分點云位置信息,基于Voxel-based的特征提取有助于提高特征提取網(wǎng)絡的計算效率和減少內(nèi)存需求.基于Frustum-based的網(wǎng)絡有Frustum PointNet[46],Frustum ConvNet[47] andSIFRNet[48].PointPillars使用Pillar-based將將點云組織成垂直的柱狀,從而排除z坐標,例如PointPillars[49].除了使用三維體素表示外,一些方法(正視圖FV、 range view 、鳥瞰圖BEV)將信息壓縮到二維投影中,以減少三維激光雷達數(shù)據(jù)的高計算量.目標檢測模型中最關(guān)鍵的任務是提取特征,保證最佳的特征學習能力是至關(guān)重要的,
Data Feature Extraction有如下幾種: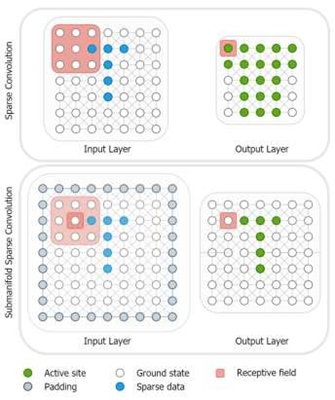
圖4.稀疏卷積(SC)和子流形稀疏卷積(VSC). Object-Wise利用成熟的二維目標檢測,用于過濾點云和檢測圖像中的對象,然后得到的二維邊界用于三維對象的邊界框.Convolutional Neural Networks中包含2D Backbone、3D Backbone,在三維空間中直接應用卷積將在計算上效率低下,并將嚴重增加計算量和模型的推理時間,因為三維表示處理自然比二維表示要長,更重要的是點云是稀疏的.因此,直接使用三維表示看起來是一項非常耗時的任務.而使用稀疏卷積(SC)和子流形稀疏卷積(VSC)來處理稀疏數(shù)據(jù),可以有效地提取特征和更快的運行時間.
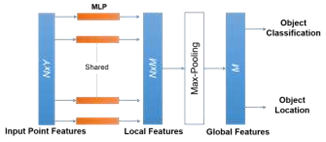
PointNet[37]和PointNet++[38]是最著名的point-wise特征提取器.如下圖所示,PointNet用于幾何特征提取和對象分類,但由于每個點都單獨學習特征,忽略點間的關(guān)系,因此在捕獲相鄰點之間的局部結(jié)構(gòu)信息方面存在嚴重的局限性.
基于point-wise的方案對象檢測時間較長,因此引入了segment-wise.例如 VoxelNet [25], Second [29], Voxel-FPN [32], and HVNet [62].首先用體素構(gòu)造點云,然后使用圖3所示的特征提取器,允許網(wǎng)絡提取低維特征(對象邊緣、每個體素).與point-wise相比,segment-wise 可以應用 voxels pillars frustums
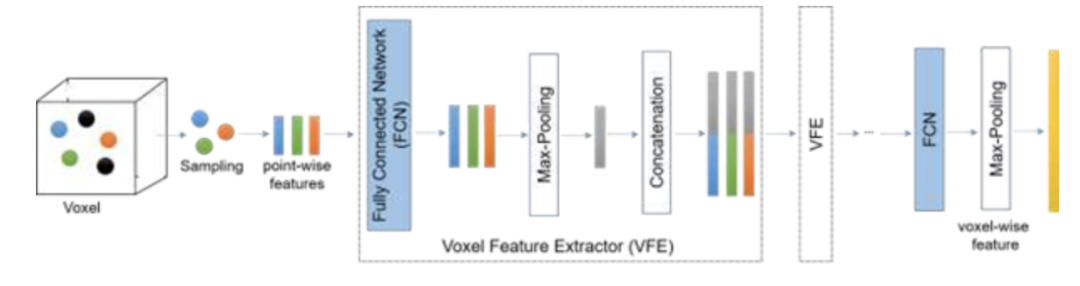
圖3.體素特征提取網(wǎng)絡的結(jié)構(gòu)
三維目標檢測模型中的特征提取方法
三維目標檢測模型中的特征提取方法,其中,檢測過程可能使用單級或雙級架構(gòu)來學習全局特征,單級架構(gòu)和雙級的架構(gòu)通用表示如圖5所示.表2總結(jié)了目標檢測模型采用的特征提取方法.
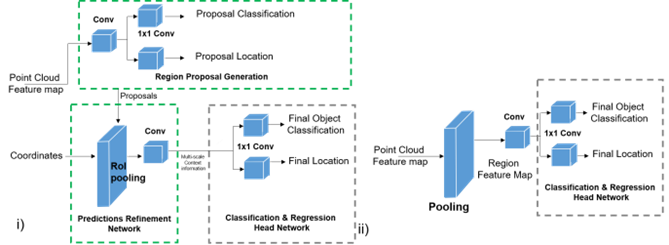
圖5.i)雙級檢測器結(jié)構(gòu)和 ii)單級檢測器結(jié)構(gòu)的通用表示
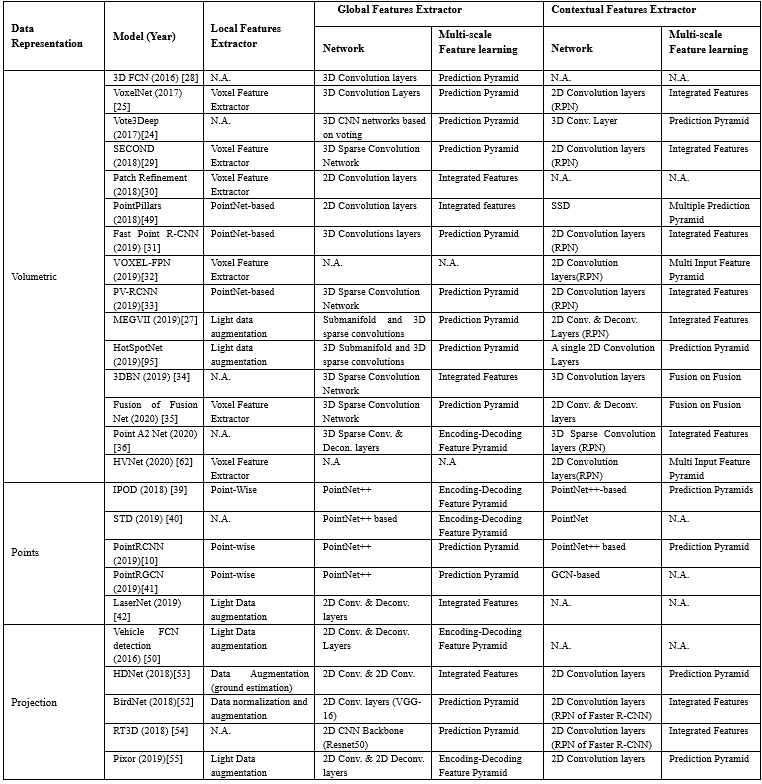
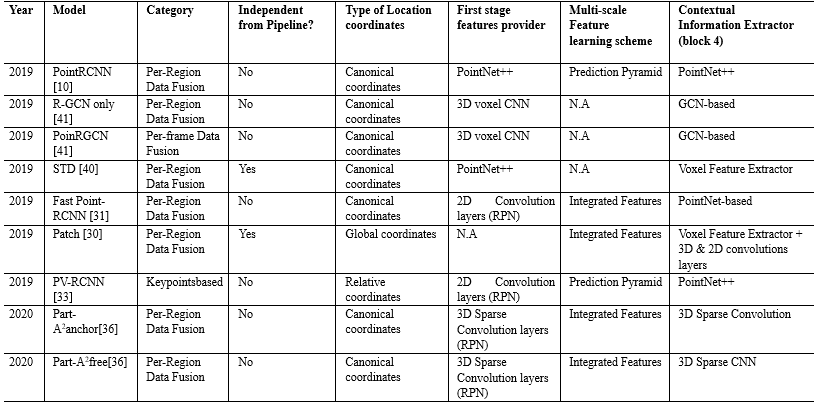
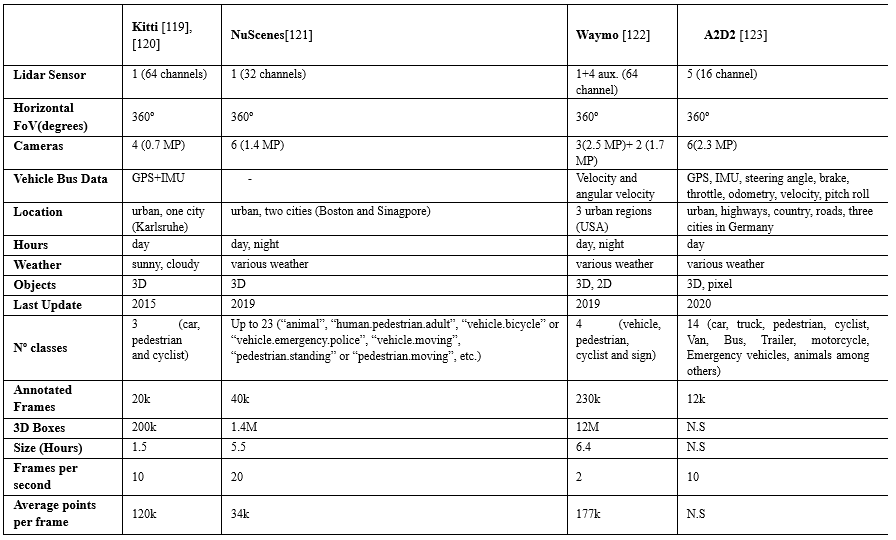
下面,我們將在多種設(shè)置的環(huán)境下收集的數(shù)據(jù)進行比較,并分析了它們構(gòu)成.例如,在 Waymo數(shù)據(jù)集上,大約有6.1M標記的車輛,只有2.98M標記的行人和騎自行車的人.KITTI基準由7.481k訓練圖像和7.518k測試圖像以及相應的點云組成,這些點云總共包括80.256k標記對象.這些基準還包括不同的類別,例如,KITTI包括3個類別:汽車、行人和自行車,而nuScenes包括23個類別的對象.
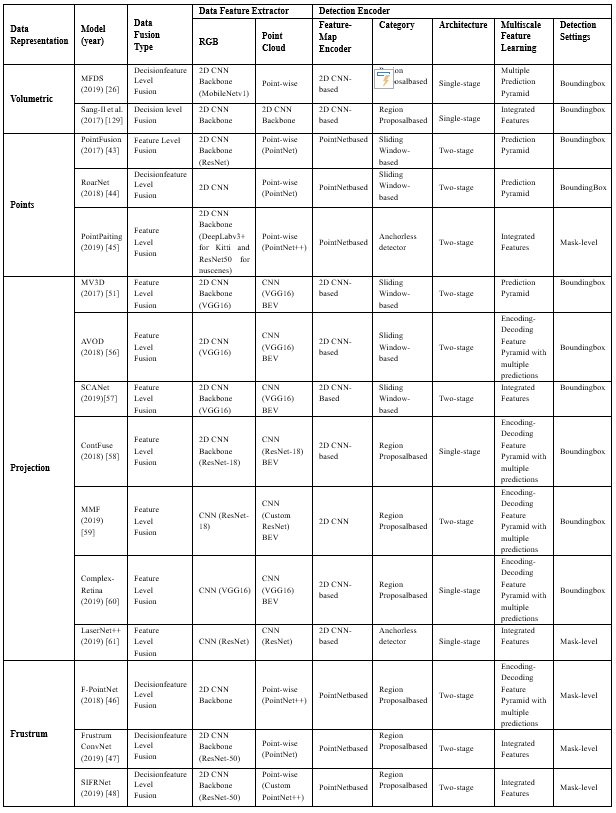
接下來無人駕駛車輛的目標模型的選擇,其中大多數(shù)項目使用 RPN結(jié)構(gòu),以及使用PointNet或PointNet++執(zhí)行實例或?qū)ο蠓指钊蝿?如表5所示.
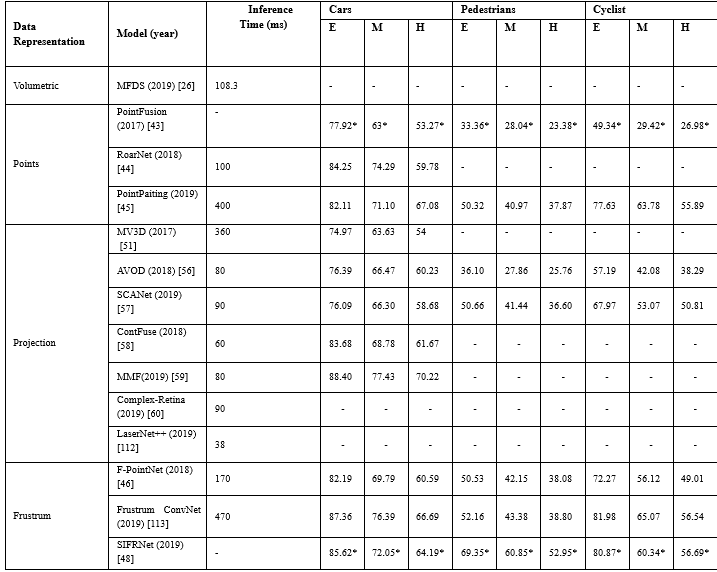
由于基于融合的方法依賴于兩種不同類型的數(shù)據(jù)集,因此它們之間的同步和校準非常重要.如表6所示,這些方法總體上取得了較好的性能效果;然而,模型[45]、[46]、[51]、[113]計算效率低下,推理時間超過170ms,與僅使用激光雷達的方法相比,這些解決方案的運行速度很慢.盡管這些方法取得了良好的性能結(jié)果,但是他們嚴重依賴現(xiàn)成的2D物體檢測,不能接受利用3D信息生成更精確的邊界框.
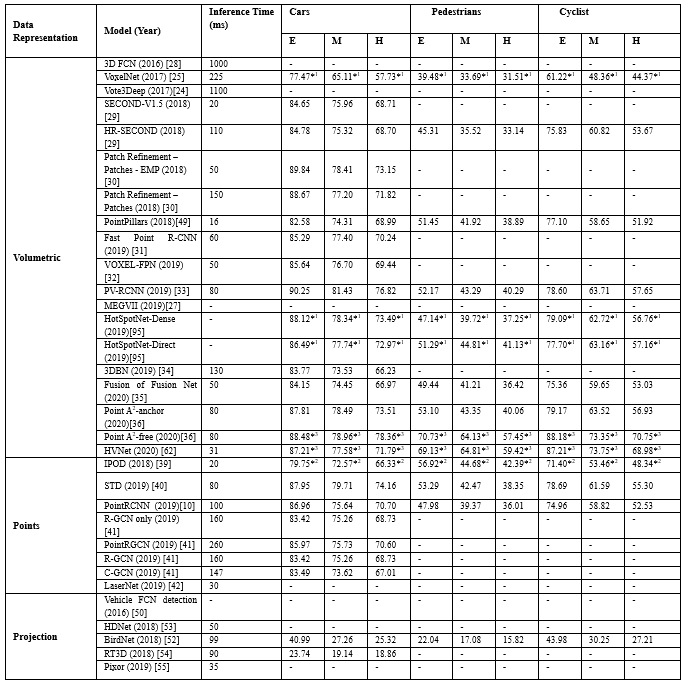
如表7所示,大多數(shù)模型使用單階段架構(gòu),與雙階段模型相比單階段模型速度更快,但實現(xiàn)的3D目標檢測性能較低,然而,最近 Point-RCNN[10],Fast Point R-CNN[31]等通過實現(xiàn)第二階段,顯著提高了3D檢測性能.這是因為模型的各個階段可以單獨訓練和評估,并且可以執(zhí)行額外的增強技術(shù),而且特征的多尺度、不同特征的聚合有利于提高3維目標檢測的性能.
總結(jié)
近年來,隨著3D傳感技術(shù)和計算技術(shù)的發(fā)展,用于目標檢測的深度學習模型的數(shù)據(jù)集得以擴展.本文對比分析了目前最先進的目標檢測方法,以滿足LiDAR或基于融合LiDAR的解決方案.除了對現(xiàn)有的不同方法進行系統(tǒng)研究外,還發(fā)現(xiàn)了一些存在的問題,如模型的可解釋性、復雜的感知場景、小物體或遮擋物體、正負不平衡采樣等,仍然是自動駕駛3維目標檢測的主要挑戰(zhàn).這些問題表明,盡管在自動駕駛目標檢測方面取得了最新進展,如無錨點檢測器、一級和兩級檢測器的組合以提高檢測精度和改進后處理NMS,代表了對現(xiàn)有模型的一些改進.對模型在不同階段的理解是解決問題的根本.最后總結(jié)了基于深度學習的LiDAR點云方法的一些挑戰(zhàn)和未來工作的可能方向.
如果覺得有用,就請分享到朋友圈吧!
公眾號后臺回復“83”獲取朱思語:基于深度學習的視覺稠密建圖和定位~

# 極市原創(chuàng)作者激勵計劃 #
