
3D目標檢測綜述:從數(shù)據(jù)集到2D和3D方法

極市導讀
?本文概述性地總結(jié)了一些當前最佳的目標檢測相關(guān)的研究。主要內(nèi)容包括目標檢測任務常用的數(shù)據(jù)格式,目標檢測與2D目標檢測相關(guān)的技術(shù)以及概括性的討論3D目標檢測這一主題。?>>加入極市CV技術(shù)交流群,走在計算機視覺的最前沿
目標檢測一直是計算機視覺領域中一大難題。近日,來自阿爾伯塔大學的研究者對目標檢測領域的近期發(fā)展進行了綜述,涵蓋常見數(shù)據(jù)格式和數(shù)據(jù)集、2D 目標檢測方法和 3D 目標檢測方法。

論文地址:https://arxiv.org/abs/2010.15614
目標檢測任務的目標是找到圖像中的所有感興趣區(qū)域,并確定這些區(qū)域的位置和類別。由于目標具有許多不同的外觀、形狀和姿態(tài),再加上光線、遮擋和成像過程中其它因素的干擾,目標檢測一直以來都是計算機視覺領域中一大挑戰(zhàn)性難題。
本文將概述性地總結(jié)一些當前最佳的目標檢測相關(guān)研究。第 2 節(jié)將簡要介紹目標檢測任務常用的數(shù)據(jù)格式,同時還會給出一些著名的數(shù)據(jù)集。
然后會概述一些預處理方法。第 3 節(jié)會介紹與 2D 目標檢測相關(guān)的技術(shù),包括傳統(tǒng)方法和深度學習方法。最后第 4 節(jié)會概括性地討論 3D 目標檢測這一主題。
2 數(shù)據(jù)格式
2.1 數(shù)據(jù)集
在計算機圖形學中,深度圖(Depth Map)是包含場景中目標表面與視點之間距離信息的圖像或圖像通道。深度圖類似于灰度圖像,只不過深度圖中每個像素都是傳感器與目標之間的實際距離。一般來說,RGB 圖像和深度圖是同時采集的,因此兩者的像素之間存在一一對應關(guān)系。RGB-D 格式的數(shù)據(jù)集包括 Pascal VOC、COCO、ImageNet 等。
雷達數(shù)據(jù)對目標檢測問題也很有用。雷達數(shù)據(jù)的收集方式是:先向目標表面發(fā)射聲波,然后使用反射信息來計算目標的速度以及與目標的距離。但是,僅靠雷達可無法收集到用于檢測和分類的信息,因此不同類型數(shù)據(jù)的融合是非常重要的。
點云數(shù)據(jù)是三維坐標系中的一組向量。這些向量通常用 X、Y、Z 的三維坐標表示,是一種常用的外表面形狀表示方式。不僅如此,除了由 (X,Y,Z) 表示的幾何位置信息之外,每個點云還可能包含 RGB 顏色像素、灰度值、深度和法線。大多數(shù)點云數(shù)據(jù)都由 3D 掃描設備生成,比如激光雷達(2D/3D)、立體相機和 TOF(飛行時間)相機。這些設備可自動測量目標表面上大量點的信息,然后以 .LAS 和 .LAZ 這兩種標準文件格式輸出點云。這些點云數(shù)據(jù)是由掃描設備采集的。在用于訓練的數(shù)據(jù)集中,除了點云數(shù)據(jù),還有相應的 RGB 圖像。這類數(shù)據(jù)集包括 KITTI [4]、nuScenes [5]、Waymo Open [6] 等。
本文將使用 nuScenes 數(shù)據(jù)集來訓練和評估模型。nuScenes 數(shù)據(jù)集來自 nuTonomy,是一個大規(guī)模自動駕駛數(shù)據(jù)集,其中的數(shù)據(jù)進行了 3D 目標標注。與其它很多數(shù)據(jù)集相比,nuScenes 數(shù)據(jù)集不僅規(guī)模更大,目標標注更多,而且還提供了整套傳感器套件,包括激光雷達、聲波雷達、GPS 和 IMU。圖 1 展示了 nuScenes 中一個激光雷達點云的示例。

圖 1:nuScenes 中的激光雷達點云示例。
2.2 預處理
盡管數(shù)據(jù)集中的圖像質(zhì)量很高,但在實際應用中,天氣等因素都可能影響圖像的質(zhì)量,并因此降低檢測準確率。近期提出的一些用于交通場景的去霧算法可以解決這類問題。比如 [8] 提出了一種基于伽馬校正和引導濾波的去霧算法:先使用伽馬校正方法在去霧之前校正圖像,然后再在校正后圖像上執(zhí)行三種不同尺度的引導濾波過程,過濾后的圖像再使用 Retinex 模型修改,最后使用加權(quán)融合得到去霧的結(jié)果。通過此方法得到的去霧圖像具有更高的對比度和顏色一致性。Wang [9] 重點研究了如何解決霧濃度分布不均的問題。根據(jù)波長與霧濃度的關(guān)系,他們針對交通監(jiān)控圖像構(gòu)建了一個與波長相關(guān)的物理成像模型。然后,再根據(jù)波長與顏色的相關(guān)性,他們又基于最大模糊相關(guān)圖切割設計了一種透射率估計算法。
除了提升圖像質(zhì)量之外,人們也常使用相機校準來確定圖像在 3D 空間中的位置。盡管相機校準這一問題已得到廣泛研究,但大多數(shù)校準方法都會固定相機位置并使用某個已知的校準模式。Basu [10] 提出了一種使用場景中的清晰邊緣自動校準相機的方法,該方法可移動相機且無需事先定義一種模式。
除了上述問題之外,某些數(shù)據(jù)集還存在嚴重的類別不平衡問題,比如 nuScenes 數(shù)據(jù)集。[11] 提出了一種有效解決該問題的方法,并在這個新數(shù)據(jù)集上取得了優(yōu)秀表現(xiàn)。他們首先使用數(shù)據(jù)增強策略,然后使用一些經(jīng)過改進的 3D 特征提取網(wǎng)絡,最后改進訓練流程和對損失的評估,進而實現(xiàn)整體性能的提升。
3 2D目標檢測
3.1 傳統(tǒng)方法
傳統(tǒng)的目標檢測算法通常基于不同類型的特征描述子。方向梯度直方圖(HOG)[12] 就是其中一種著名的描述子,它統(tǒng)計在已定位的圖像部分中梯度方向的出現(xiàn)次數(shù)。HOG 特征結(jié)合 SVM 分類器的方法已在目標檢測領域得到廣泛應用,在行人檢測方面尤其成功。
特征檢測在傳統(tǒng)方法中尤其重要。近些年,出現(xiàn)了很多特征提取方面的有趣研究。
霍夫變換(Hough transform)是圖像處理過程中一種識別圖像中幾何形狀的基本方法。舉個例子,針對人臉跟蹤問題,[13] 使用了一種基于梯度的霍夫變換來定位眼睛虹膜的位置。但是,對于非單視點(SVP)標準的圖像,這樣的變換無法直接用于特征識別。[14] 提出了一種解決該問題的數(shù)學模型。
雷登變換(Radon Transform)[15] 在醫(yī)學影像處理方面應用廣泛,它也可用于識別任務。[16] 使用雷登變換來進行視覺手勢識別,得到了很不錯的識別率。
Yin [17] 提出了一種跟蹤鼻子形狀的方法,以前的研究通常會忽略這個特征。這一研究使用面積增長方法來確定鼻子所在的區(qū)域,而鼻尖和鼻翼的形狀則是通過預定義模板分別提取。最后,再使用提取出的特征指示人臉跟蹤的效果。
一旦檢測到相關(guān)特征,就使用 Kanade–Lucas–Tomasi(KLT)等特征跟蹤器跟蹤下一幀中的特征。2005 年時,有作者 [18] 提出了一種方法,即使用高斯拉普拉斯算子(Laplace of Gaussian)和高斯加權(quán)函數(shù)來提升會受噪聲影響的 KLT 跟蹤性能。該加權(quán)函數(shù)耦合了邊緣特征,從而得到了一種用于選取最優(yōu)加權(quán)函數(shù)的確定性公式。這種方法僅會增加少量計算時間,但卻為跟蹤性能帶來極大提升。
有時候,除了特征提取,還會涉及到圖像分割。[19] 描述了一種方法,即使用梯度向量流 - 蛇(GVF snake)模型來提取相關(guān)輪廓。通過加入邊緣檢測和使用氣道 CT 切片先驗知識的蛇位移(snake shifting)技術(shù),作者對原始 GVF - 蛇方法進行了改進,得到了更好的結(jié)果。這一技術(shù)可能也很有用。
另一個問題則來自相機移動,隨著收集數(shù)據(jù)的設備類型的增多,來自移動相機的數(shù)據(jù)也越來越多。至于背景消除問題,很多方法在靜止相機采集的數(shù)據(jù)上表現(xiàn)優(yōu)良,比如在事先知道每幀中前景和背景有較大距離的前提下,聚類可以在一次迭代中完成,而且僅需兩個聚類,[20] 能在背景消除任務上取得較高的準確率。但是,如果相機在移動,難度就會大得多。[21] 首先使用了魯棒型主成分分析(RPCA)來提取背景運動,其假設背景場景可以描述為一種低秩矩陣,然后將幀分割為子像素以提升將光流轉(zhuǎn)換為運動的幅度和角度的準確率,由此改善結(jié)果。
3.2 深度學習方法
目標識別是指與識別圖像或視頻中目標相關(guān)的任務,旨在找到圖像中所有相關(guān)目標并確定其 2D 位置。
現(xiàn)今,目標檢測領域的深度學習方法主要分為兩大類:兩階段式目標檢測算法和單階段式目標檢測算法。前者是先由算法生成一系列候選邊界框作為樣本,然后再通過卷積神經(jīng)網(wǎng)絡分類這些樣本。后者則是直接將目標邊界定位問題轉(zhuǎn)換成回歸問題,其中不涉及生成候選邊界框。兩種方法的區(qū)別也導致其性能也不同。前者在檢測準確率和定位準確率方面更優(yōu),而后者勝在算法速度。
此外,通用框架也主要有兩種。
第一種是兩階段框架。這類框架首先生成候選區(qū)域(region proposal),然后將其分類成不同的目標類別,所以這也被稱為「基于區(qū)域的方法」。這類模型主要包括 R-CNN [22]、Fast R-CNN [23]、Faster R-CNN [24]、基于區(qū)域的全卷積網(wǎng)絡(R-FCN)等。
在單階段框架中,模型將目標檢測任務視為一個統(tǒng)一的端到端回歸問題。在這類框架中,圖像會被縮放到同一尺寸,并以網(wǎng)格形式均等劃分。如果目標的中心位于某個網(wǎng)格單元中,該網(wǎng)格就負責預測目標。通過這種方式,模型僅需處理圖像一次就能得到位置和分類結(jié)果。單階段框架主要包括 MultiBox [26]、YOLO [27]、單次多框檢測器(SSD)[28]。相比于第一類框架,這種框架通常結(jié)構(gòu)更簡單,檢測速度也更快。
4 3D目標檢測
這一節(jié)將簡要討論與 3D 目標檢測相關(guān)的工作,這里基于不同的數(shù)據(jù)信息將這些研究工作分為了三大類別。
4.1 使用 RGB 圖像的目標檢測
RGB 圖像包含充足的語義信息,因此非常適合目標檢測。圖 2 展示了一個使用 2D 圖像檢測目標的示例。3D-GCK [29] 等方法僅使用單目 RGB 圖像就能實現(xiàn)實時的汽車檢測:它首先預測 2D 邊界框,然后使用神經(jīng)網(wǎng)絡來估計缺失的深度信息,將 2D 邊界框提升到 3D 空間。
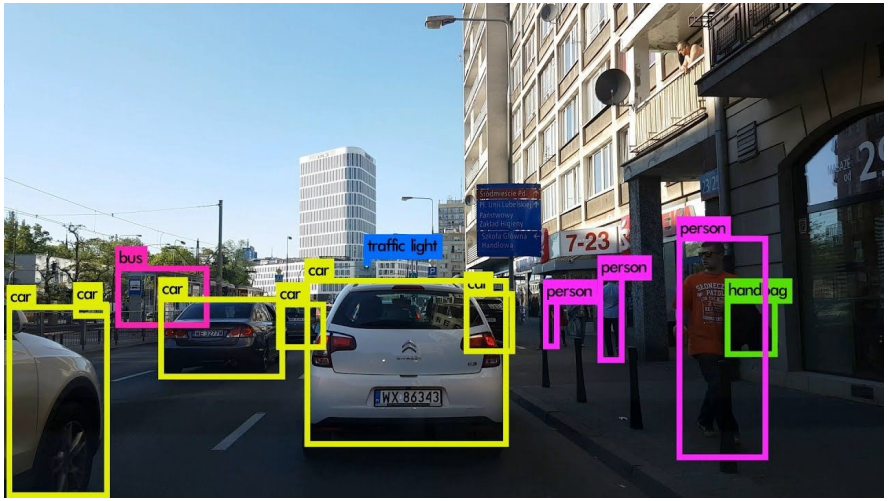
圖 2:使用 2D 圖像的目標檢測示例。
近期一項研究 [30] 使用了 RGB-D 傳感器,但只使用了灰度信息來識別無紋理的目標。它首先將傳感器獲得的 RGB 圖像轉(zhuǎn)換成灰度圖像,然后再分割背景和前景。在移除噪聲后,再使用 5 個分類模型執(zhí)行特征提取,最終預測出目標的類別。
4.2 使用點云的目標檢測
僅使用點云數(shù)據(jù)的分類網(wǎng)絡主要有兩種。第一種是直接使用三維點云數(shù)據(jù)。這類方法沒有信息丟失的問題,但是由于 3D 數(shù)據(jù)非常復雜,所以往往計算成本較高。第二種方法則是將點云處理成二維數(shù)據(jù),這可以降低計算量,但不可避免地會丟失原始數(shù)據(jù)的一些特征。圖 3 給出了一個使用 3D 激光雷達點云數(shù)據(jù)執(zhí)行檢測的例子。
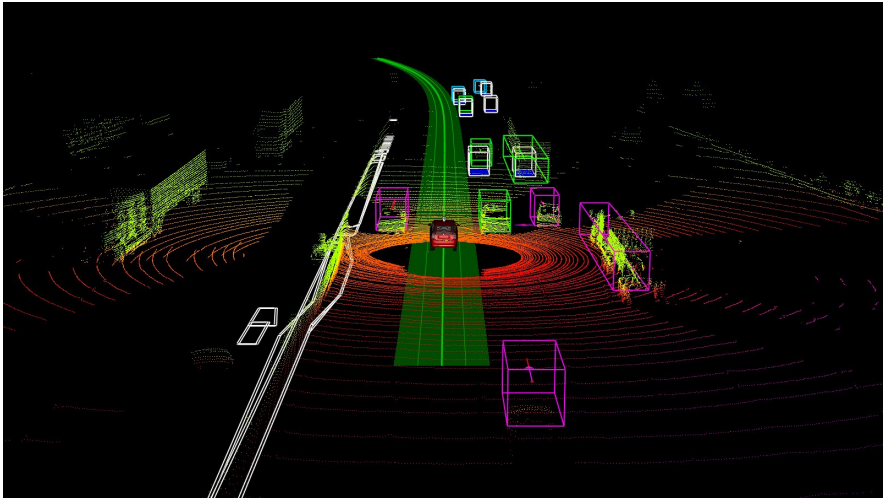 圖 3:通過 YOLO 使用 3D 點云的目標檢測示例。
圖 3:通過 YOLO 使用 3D 點云的目標檢測示例。
將點云處理成二維數(shù)據(jù)的方法有很多。Jansen [31] 提出從多個 2D 角度表示 3D 點云。在其數(shù)據(jù)預處理階段,通過取點云圖像的中心作為原點,并通過旋轉(zhuǎn)固定的弧度角來截取 64 張不同角度的點云圖像。這種方法能在一定程度上減少信息損失,因為其中加入了額外的旋轉(zhuǎn),并在分類階段使用了許多實例。[32] 等研究則是將點云投射到一個圓柱面上,以盡可能多地保留信息。
BirdNet+ [33] 是基于目標檢測框架 BirdNet [34] 的改進版。BirdNet+ 為基于激光雷達數(shù)據(jù)的 3D 目標檢測提供了一種端到端的解決方案。它用到了鳥瞰視角表征,這是從激光雷達點云轉(zhuǎn)換而來的帶有三個通道的 2D 結(jié)構(gòu),依賴于一個兩階段架構(gòu)來獲取面向 3D 的邊界框。
近期,[35] 提出了一種計算高效的端到端式魯棒型點云對齊和目標識別方法,該方法使用了無監(jiān)督深度學習,并被命名為深度點云映射網(wǎng)絡(DPC-MN)。該模型的訓練無需標簽,而且能高效地實現(xiàn)從 3D 點云表征到 2D 視角的映射函數(shù)。
4.3 結(jié)合 RGB 圖像與點云的目標檢測
Frustum PointNets [36] 同時使用 RGB 圖像和激光雷達點云數(shù)據(jù)來執(zhí)行 3D 目標檢測。該算法使用成熟的 2D 目標檢測器來縮小搜索空間。它是通過從圖像檢測器得到的 2D 邊界框來提取 3D 邊界視錐,然后再在經(jīng)過 3D 視錐修整過的 3D 空間中執(zhí)行 3D 目標實例分割。
MV3D [37] 也同時使用 RGB 圖像和激光雷達點云數(shù)據(jù)作為輸入,它是將 3D 點云投影成鳥瞰圖和正視圖。鳥瞰圖表征是通過高度、強度和密度編碼的,而正視圖則是將點云投影到一個圓柱面上生成的。鳥瞰圖可用于生成 3D 先驗邊界框,然后將該 3D 先驗邊界框投影到前視圖和圖像上,這三個輸入生成一個特征圖。該方法采用 ROI 池化來將三個特征圖整合到同一個維度。整合后的數(shù)據(jù)再在網(wǎng)絡上進行融合,然后輸出分類結(jié)果和邊界框。

圖 4:使用 MV3D 的目標檢測示例。
推薦閱讀
