
決策樹算法原理及應(yīng)用(詳細(xì)版)
決策樹是一種樹形結(jié)構(gòu),其中每個(gè)內(nèi)部節(jié)點(diǎn)表示一個(gè)屬性上的測試,每個(gè)分支代表一個(gè)測試輸出,每個(gè)葉節(jié)點(diǎn)代表一種類別。
決策樹是一種十分常用的分類方法,本文主要內(nèi)容:
C4.5算法簡介 算法描述 屬性選擇度量 算法剪枝 異常數(shù)據(jù)處理 代碼示例
1. C4.5算法簡介
C4.5是一系列用在機(jī)器學(xué)習(xí)和數(shù)據(jù)挖掘的分類問題中的算法。它的目標(biāo)是監(jiān)督學(xué)習(xí):給定一個(gè)數(shù)據(jù)集,其中的每一個(gè)元組都能用一組屬性值來描述,每一個(gè)元組屬于一個(gè)互斥的類別中的某一類。C4.5的目標(biāo)是通過學(xué)習(xí),找到一個(gè)從屬性值到類別的映射關(guān)系,并且這個(gè)映射能用于對新的類別未知的實(shí)體進(jìn)行分類。
C4.5由J.Ross Quinlan在ID3的基礎(chǔ)上提出的。ID3算法用來構(gòu)造決策樹。決策樹是一種類似流程圖的樹結(jié)構(gòu),其中每個(gè)內(nèi)部節(jié)點(diǎn)(非樹葉節(jié)點(diǎn))表示在一個(gè)屬性上的測試,每個(gè)分枝代表一個(gè)測試輸出,而每個(gè)樹葉節(jié)點(diǎn)存放一個(gè)類標(biāo)號(hào)。一旦建立好了決策樹,對于一個(gè)未給定類標(biāo)號(hào)的元組,跟蹤一條有根節(jié)點(diǎn)到葉節(jié)點(diǎn)的路徑,該葉節(jié)點(diǎn)就存放著該元組的預(yù)測。決策樹的優(yōu)勢在于不需要任何領(lǐng)域知識(shí)或參數(shù)設(shè)置,適合于探測性的知識(shí)發(fā)現(xiàn)。
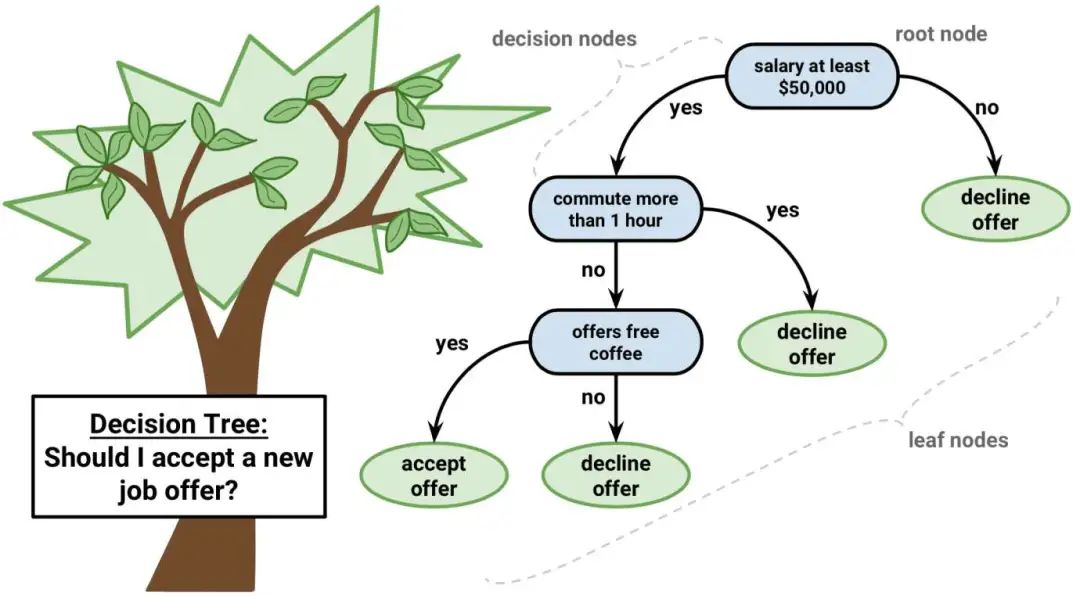
從ID3算法中衍生出了C4.5和CART兩種算法,這兩種算法在數(shù)據(jù)挖掘中都非常重要。下圖就是一棵典型的C4.5算法對數(shù)據(jù)集產(chǎn)生的決策樹。
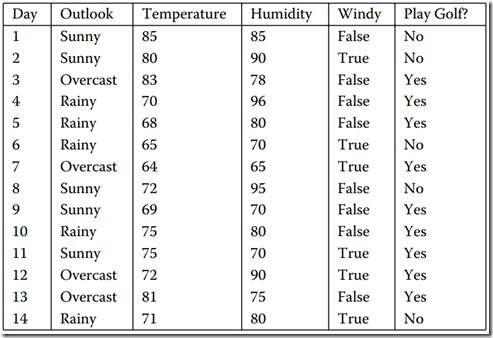
數(shù)據(jù)集如下圖所示,它表示的是天氣情況與去不去打高爾夫球之間的關(guān)系。
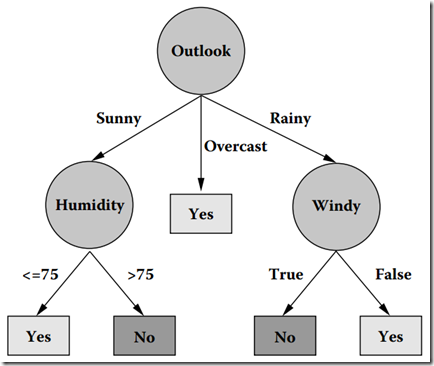
在數(shù)據(jù)集上通過C4.5生成的決策樹如下:
2. 算法描述
C4.5并不一個(gè)算法,而是一組算法—C4.5,非剪枝C4.5和C4.5規(guī)則。下圖中的偽代碼將給出C4.5的基本工作流程:
Function?C4.5(R:包含連續(xù)屬性的無類別屬性集合,C:類別屬性,S:訓(xùn)練集)??
Begin??
???If?S為空,返回一個(gè)值為Failure的單個(gè)節(jié)點(diǎn);??
???If?S是由相同類別屬性值的記錄組成,??
??????返回一個(gè)帶有該值的單個(gè)節(jié)點(diǎn);??
???If?R為空,則返回一個(gè)單節(jié)點(diǎn),其值為在S的記錄中找出的頻率最高的類別屬性值;??
???[注意未出現(xiàn)錯(cuò)誤則意味著是不適合分類的記錄];??
??For?所有的屬性R(Ri)?Do??
????????If?屬性Ri為連續(xù)屬性,則??
????????Begin??
???????????sort(Ri屬性值)
???????????將Ri的最小值賦給A1:??
?????????????將Ri的最大值賦給Am;??
???????????For?j?From?1?To?m-1?Do?Aj=(A1+Aj+1)/2;??
???????????將Ri點(diǎn)的基于Aj(1<=j<=m-1劃分的最大信息增益屬性(Ri,S)賦給A;??
????????End;??
??將R中屬性之間具有最大信息增益的屬性(D,S)賦給D;??
??將屬性D的值賦給{dj/j=1,2...m};??
??將分別由對應(yīng)于D的值為dj的記錄組成的S的子集賦給{sj/j=1,2...m};??
??返回一棵樹,其根標(biāo)記為D;樹枝標(biāo)記為d1,d2...dm;??
??再分別構(gòu)造以下樹:??
??C4.5(R-{D},C,S1),C4.5(R-{D},C,S2)...C4.5(R-{D},C,Sm);??
End?C4.5
我們可能有疑問,一個(gè)元組(數(shù)據(jù)集)本身有很多屬性,我們怎么知道首先要對哪個(gè)屬性進(jìn)行判斷,接下來要對哪個(gè)屬性進(jìn)行判斷?換句話說,在上圖中,我們怎么知道第一個(gè)要測試的屬性是Outlook,而不是Windy?其實(shí),能回答這些問題的一個(gè)概念就是屬性選擇度量。
3. 屬性選擇度量
屬性選擇度量又稱分裂規(guī)則,因?yàn)樗鼈儧Q定給定節(jié)點(diǎn)上的元組如何分裂。屬性選擇度量提供了每個(gè)屬性描述給定訓(xùn)練元組的秩評(píng)定,具有最好度量得分的屬性被選作給定元組的分裂屬性。目前比較流行的屬性選擇度量有--信息增益、增益率和Gini指標(biāo)。
信息增益
信息增益實(shí)際上是ID3算法中用來進(jìn)行屬性選擇度量的。它選擇具有最高信息增益的屬性來作為節(jié)點(diǎn)N的分裂屬性。該屬性使結(jié)果劃分中的元組分類所需信息量最小。對D中的元組分類所需的期望信息為下式:
Info(D)又稱為熵。現(xiàn)在假定按照屬性A劃分D中的元組,且屬性A將D劃分成v個(gè)不同的類。在該劃分之后,為了得到準(zhǔn)確的分類還需要的信息由下面的式子度量:
信息增益定義為原來的信息需求(即僅基于類比例)與新需求(即對A劃分之后得到的)之間的差,即:
我想很多人看到這個(gè)地方都覺得不是很好理解,所以我自己的研究了文獻(xiàn)中關(guān)于這一塊的描述,也對比了上面的三個(gè)公式,下面說說我自己的理解。
一般說來,對于一個(gè)具有多個(gè)屬性的元組,用一個(gè)屬性就將它們完全分開幾乎不可能,否則的話,決策樹的深度就只能是2了。從這里可以看出,一旦我們選擇一個(gè)屬性A,假設(shè)將元組分成了兩個(gè)部分A1和A2,由于A1和A2還可以用其它屬性接著再分,所以又引出一個(gè)新的問題:接下來我們要選擇哪個(gè)屬性來分類?對D中元組分類所需的期望信息是Info(D)。
那么同理,當(dāng)我們通過A將D劃分成v個(gè)子集,之后,我們要對的元組進(jìn)行分類,需要的期望信息就是,而一共有v個(gè)類,所以對v個(gè)集合再分類,需要的信息就是公式(2)了。由此可知,如果公式(2)越小,是不是意味著我們接下來對A分出來的幾個(gè)集合再進(jìn)行分類所需要的信息就越小?而對于給定的訓(xùn)練集,實(shí)際上Info(D)已經(jīng)固定了,所以選擇信息增益最大的屬性作為分裂點(diǎn)。
但是,使用信息增益的話其實(shí)是有一個(gè)缺點(diǎn),那就是它偏向于具有大量值的屬性。什么意思呢?就是說在訓(xùn)練集中,某個(gè)屬性所取的不同值的個(gè)數(shù)越多,那么越有可能拿它來作為分裂屬性。例如一個(gè)訓(xùn)練集中有10個(gè)元組,對于某一個(gè)屬相A,它分別取1-10這十個(gè)數(shù),如果對A進(jìn)行分裂將會(huì)分成10個(gè)類,那么對于每一個(gè)類,從而式(2)為0,該屬性劃分所得到的信息增益(3)最大,但是很顯然,這種劃分沒有意義。
信息增益率
正是基于此,ID3后面的C4.5采用了信息增益率這樣一個(gè)概念。信息增益率使用“分裂信息”值將信息增益規(guī)范化。分類信息類似于Info(D),定義如下:
這個(gè)值表示通過將訓(xùn)練數(shù)據(jù)集D劃分成對應(yīng)于屬性A測試的v個(gè)輸出的v個(gè)劃分產(chǎn)生的信息。信息增益率定義:
選擇具有最大增益率的屬性作為分裂屬性。
Gini指標(biāo)
Gini指標(biāo)在CART中使用。Gini指標(biāo)度量數(shù)據(jù)劃分或訓(xùn)練元組集D的不純度,定義為:
這里通過下面的數(shù)據(jù)集(均為離散值,對于連續(xù)值,下面有詳細(xì)介紹)看下信息增益率節(jié)點(diǎn)選擇:
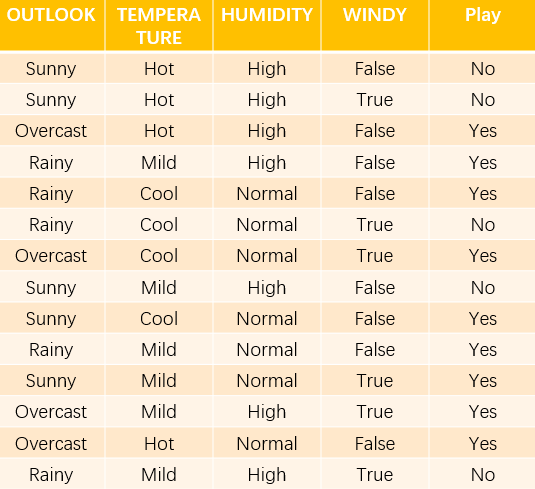
上面的訓(xùn)練集有4個(gè)屬性,即屬性集合A={OUTLOOK, TEMPERATURE, HUMIDITY, WINDY}; 而類標(biāo)簽有2個(gè),即類標(biāo)簽集合C={Yes, No},分別表示適合戶外運(yùn)動(dòng)和不適合戶外運(yùn)動(dòng),其實(shí)是一個(gè)二分類問題。
數(shù)據(jù)集D包含14個(gè)訓(xùn)練樣本,其中屬于類別“Yes”的有9個(gè),屬于類別“No”的有5個(gè),則計(jì)算其信息熵:即公式(1)的值:
下面對屬性集中每個(gè)屬性分別計(jì)算信息熵,如下所示:
根據(jù)上面的數(shù)據(jù),我們可以計(jì)算選擇第一個(gè)根結(jié)點(diǎn)所依賴的信息增益值,計(jì)算如下所示:
接下來,我們計(jì)算分裂信息度量SplitInfo,此處記為H(V):
OUTLOOK屬性
屬性OUTLOOK有3個(gè)取值,其中Sunny有5個(gè)樣本、Rainy有5個(gè)樣本、Overcast有4個(gè)樣本,則:
TEMPERATURE屬性
屬性TEMPERATURE有3個(gè)取值,其中Hot有4個(gè)樣本、Mild有6個(gè)樣本、Cool有4個(gè)樣本,則:
HUMIDITY屬性
屬性HUMIDITY有2個(gè)取值,其中Normal有7個(gè)樣本、High有7個(gè)樣本,則:
WINDY屬性
屬性WINDY有2個(gè)取值,其中True有6個(gè)樣本、False有8個(gè)樣本,則:
根據(jù)上面計(jì)算結(jié)果,我們可以計(jì)算信息增益率,如下所示:
根據(jù)計(jì)算得到的信息增益率進(jìn)行選擇屬性集中的屬性作為決策樹結(jié)點(diǎn),對該結(jié)點(diǎn)進(jìn)行分裂。從上面的信息增益率IGR可知OUTLOOK的信息增益率最大,所以我們選其作為第一個(gè)節(jié)點(diǎn)。
4.算法剪枝
在決策樹的創(chuàng)建時(shí),由于數(shù)據(jù)中的噪聲和離群點(diǎn),許多分枝反映的是訓(xùn)練數(shù)據(jù)中的異常。剪枝方法是用來處理這種過分?jǐn)M合數(shù)據(jù)的問題。通常剪枝方法都是使用統(tǒng)計(jì)度量,剪去最不可靠的分枝。剪枝一般分兩種方法:先剪枝和后剪枝。
先剪枝
先剪枝方法中通過提前停止樹的構(gòu)造(比如決定在某個(gè)節(jié)點(diǎn)不再分裂或劃分訓(xùn)練元組的子集)而對樹剪枝。一旦停止,這個(gè)節(jié)點(diǎn)就變成樹葉,該樹葉可能取它持有的子集最頻繁的類作為自己的類。先剪枝有很多方法,比如:
當(dāng)決策樹達(dá)到一定的高度就停止決策樹的生長; 到達(dá)此節(jié)點(diǎn)的實(shí)例具有相同的特征向量,而不必一定屬于同一類,也可以停止生長; 到達(dá)此節(jié)點(diǎn)的實(shí)例個(gè)數(shù)小于某個(gè)閾值的時(shí)候也可以停止樹的生長,不足之處是不能處理那些數(shù)據(jù)量比較小的特殊情況; 計(jì)算每次擴(kuò)展對系統(tǒng)性能的增益,如果小于某個(gè)閾值就可以讓它停止生長。先剪枝有個(gè)缺點(diǎn)就是視野效果問題,也就是說在相同的標(biāo)準(zhǔn)下,也許當(dāng)前擴(kuò)展不能滿足要求,但更進(jìn)一步擴(kuò)展又能滿足要求。這樣會(huì)過早停止決策樹的生長。
后剪枝
它由完全成長的樹剪去子樹而形成。通過刪除節(jié)點(diǎn)的分枝并用樹葉來替換它。樹葉一般用子樹中最頻繁的類別來標(biāo)記。后剪枝一般有兩種方法:
基于誤判的剪枝
這個(gè)思路很直接,完全的決策樹不是過度擬合么,我再搞一個(gè)測試數(shù)據(jù)集來糾正它。對于完全決策樹中的每一個(gè)非葉子節(jié)點(diǎn)的子樹,我們嘗試著把它替換成一個(gè)葉子節(jié)點(diǎn),該葉子節(jié)點(diǎn)的類別我們用子樹所覆蓋訓(xùn)練樣本中存在最多的那個(gè)類來代替,這樣就產(chǎn)生了一個(gè)簡化決策樹,然后比較這兩個(gè)決策樹在測試數(shù)據(jù)集中的表現(xiàn),如果簡化決策樹在測試數(shù)據(jù)集中的錯(cuò)誤比較少,并且該子樹里面沒有包含另外一個(gè)具有類似特性的子樹(所謂類似的特性,指的就是把子樹替換成葉子節(jié)點(diǎn)后,其測試數(shù)據(jù)集誤判率降低的特性),那么該子樹就可以替換成葉子節(jié)點(diǎn)。該算法以bottom-up的方式遍歷所有的子樹,直至沒有任何子樹可以替換使得測試數(shù)據(jù)集的表現(xiàn)得以改進(jìn)時(shí),算法就可以終止。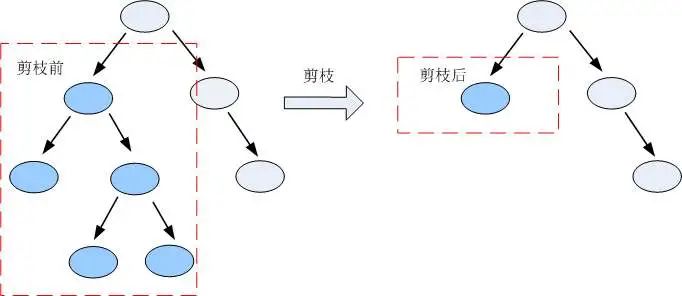
悲觀剪枝
第一種方法很直接,但是需要一個(gè)額外的測試數(shù)據(jù)集,能不能不要這個(gè)額外的數(shù)據(jù)集呢?為了解決這個(gè)問題,于是就提出了悲觀剪枝。悲觀剪枝就是遞歸得估算每個(gè)內(nèi)部節(jié)點(diǎn)所覆蓋樣本節(jié)點(diǎn)的誤判率。剪枝后該內(nèi)部節(jié)點(diǎn)會(huì)變成一個(gè)葉子節(jié)點(diǎn),該葉子節(jié)點(diǎn)的類別為原內(nèi)部節(jié)點(diǎn)的最優(yōu)葉子節(jié)點(diǎn)所決定。然后比較剪枝前后該節(jié)點(diǎn)的錯(cuò)誤率來決定是否進(jìn)行剪枝。該方法和前面提到的第一種方法思路是一致的,不同之處在于如何估計(jì)剪枝前分類樹內(nèi)部節(jié)點(diǎn)的錯(cuò)誤率。
把一顆子樹(具有多個(gè)葉子節(jié)點(diǎn))的分類用一個(gè)葉子節(jié)點(diǎn)來替代的話,在訓(xùn)練集上的誤判率肯定是上升的,但是在新數(shù)據(jù)上不一定。于是我們需要把子樹的誤判計(jì)算加上一個(gè)經(jīng)驗(yàn)性的懲罰因子。對于一顆葉子節(jié)點(diǎn),它覆蓋了個(gè)樣本,其中有E個(gè)錯(cuò)誤,那么該葉子節(jié)點(diǎn)的錯(cuò)誤率為:
這個(gè)0.5就是懲罰因子,那么一顆子樹,它有L個(gè)葉子節(jié)點(diǎn),那么該子樹的誤判率估計(jì)為:
這樣的話,我們可以看到一顆子樹雖然具有多個(gè)子節(jié)點(diǎn),但由于加上了懲罰因子,所以子樹的誤判率計(jì)算未必占到便宜。剪枝后內(nèi)部節(jié)點(diǎn)變成了葉子節(jié)點(diǎn),其誤判個(gè)數(shù)J也需要加上一個(gè)懲罰因子,變成J+0.5。那么子樹是否可以被剪枝就取決于剪枝后的錯(cuò)誤J+0.5在
的標(biāo)準(zhǔn)誤差內(nèi)。對于樣本的誤差率e,我們可以根據(jù)經(jīng)驗(yàn)把它估計(jì)成各種各樣的分布模型,比如是二項(xiàng)式分布,或者正態(tài)分布。
那么一棵樹對于一個(gè)數(shù)據(jù)來說,錯(cuò)誤分類一個(gè)樣本值為1,正確分類一個(gè)樣本值為0,該樹錯(cuò)誤分類的概率(誤判率)為(可以通過公式(7)統(tǒng)計(jì)出來),那么樹的誤判次數(shù)就是二項(xiàng)分布,我們可以估計(jì)出該樹的誤判次數(shù)均值和標(biāo)準(zhǔn)差:
其中,
把子樹替換成葉子節(jié)點(diǎn)后,該葉子的誤判次數(shù)也是一個(gè)伯努利分布,其中N是到達(dá)該葉節(jié)點(diǎn)的數(shù)據(jù)個(gè)數(shù),其概率誤判率為(J+0.5)/N,因此葉子節(jié)點(diǎn)的誤判次數(shù)均值為:
使用訓(xùn)練數(shù)據(jù),子樹總是比替換為一個(gè)葉節(jié)點(diǎn)后產(chǎn)生的誤差小,但是使用校正后有誤差計(jì)算方法卻并非如此,當(dāng)子樹的誤判個(gè)數(shù)大過對應(yīng)葉節(jié)點(diǎn)的誤判個(gè)數(shù)一個(gè)標(biāo)準(zhǔn)差之后,就決定剪枝:
這個(gè)條件就是剪枝的標(biāo)準(zhǔn)。
實(shí)例剪枝
通俗點(diǎn)講,就是看剪枝后的錯(cuò)誤率會(huì)不會(huì)變得很大(比剪枝前的錯(cuò)誤率加上其標(biāo)準(zhǔn)差還大),如果剪枝后的錯(cuò)誤率變得很高,則不剪枝,否則就剪枝。下面通過一個(gè)具體的實(shí)例來看一下到底是如何剪枝的。
例如:這是一個(gè)子決策樹,其中,,,,為非葉子節(jié)點(diǎn),,,,,,為葉子節(jié)點(diǎn),這里我們可以看出來N=樣本總和80,其中A類55個(gè)樣本,B類25個(gè)樣本。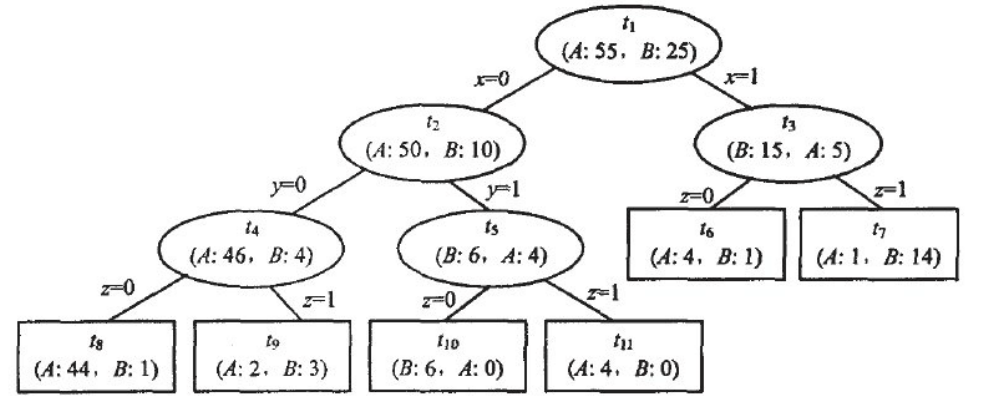
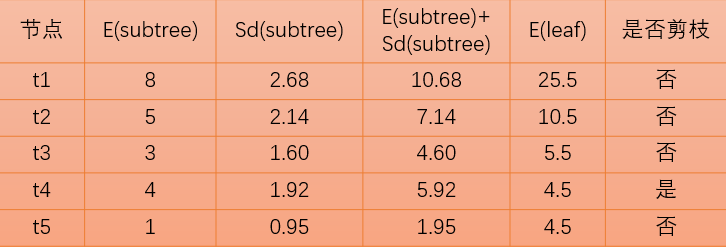 此時(shí),只有節(jié)點(diǎn)滿足剪枝標(biāo)準(zhǔn),我們就可以把節(jié)點(diǎn)剪掉,即直接把換成葉子節(jié)點(diǎn)
此時(shí),只有節(jié)點(diǎn)滿足剪枝標(biāo)準(zhǔn),我們就可以把節(jié)點(diǎn)剪掉,即直接把換成葉子節(jié)點(diǎn)A。
但是并不一定非要大一個(gè)標(biāo)準(zhǔn)差,該方法被擴(kuò)展成基于理想置信區(qū)間(confidence intervals, CI)的剪枝方法,該方法將葉節(jié)點(diǎn)的錯(cuò)誤率e建模成為服從二項(xiàng)分布的隨機(jī)變量.
對于一個(gè)置信區(qū)間閾值CI,存在一個(gè)上界,使得以的概率成立(對于C4.5算法中默認(rèn)的CI值為0.25),若,則剪枝。更近一步,我們可以用正態(tài)分布來逼近e(只要N足夠大),基于這些約束條件,C4.5算法的期望誤差的上界(一般用Wilson score interval)為:
式中z的選擇是基于理想置信區(qū)間,假設(shè)z是一個(gè)擁有零均值和單位方差的正態(tài)隨機(jī)變量,也就是N(0,1).為什么選取Wilson score interval作為上界,主要因?yàn)樵撋辖缭谏贅颖净蛘叽嬖跇O端概率情況下的數(shù)據(jù)集都能有一些很好的性質(zhì)。
5. 異常數(shù)據(jù)處理
數(shù)據(jù)預(yù)處理是指在主要的處理以前對數(shù)據(jù)進(jìn)行的一些處理。比如講連續(xù)數(shù)據(jù)如何離散化,對缺失值,異常值如何處理,等等。
連續(xù)數(shù)據(jù)的處理
離散化處理:將連續(xù)型的屬性變量進(jìn)行離散化處理,形成決策樹的訓(xùn)練集,分三步:
1.?把需要處理的樣本(對應(yīng)根節(jié)點(diǎn))或樣本子集(對應(yīng)子樹)按照連續(xù)變量的大小從小到大進(jìn)行排序;
2.?假設(shè)該屬性對應(yīng)的不同的屬性值一共有N個(gè),那么總共有N-1個(gè)可能的候選分割閾值點(diǎn),每個(gè)候選的分割閾值點(diǎn)的值為上述排序后的屬性值中兩兩前后連續(xù)元素的中點(diǎn);
3.?用信息增益率選擇最佳劃分
對于缺失值的處理
缺失值:在某些情況下,可供使用的數(shù)據(jù)可能缺少某些屬性的值。例如(x, y)是樣本集S中的一個(gè)訓(xùn)練實(shí)例,。但是其屬性Fi的值未知。
處理策略:
1.?處理缺少屬性值的一種策略是賦給它結(jié)點(diǎn)t所對應(yīng)的訓(xùn)練實(shí)例中該屬性的最常見值
2.?另外一種更復(fù)雜的策略是為Fi的每個(gè)可能值賦予一個(gè)概率。例如,給定一個(gè)布爾屬性Fi,如果結(jié)點(diǎn)t包含6個(gè)已知和4個(gè)的實(shí)例,那么的概率是0.6,而的概率是0.4。于是,實(shí)例x的60%被分配到的分支,40%被分配到另一個(gè)分支。這些片斷樣例(fractional examples)的目的是計(jì)算信息增益,另外,如果有第二個(gè)缺少值的屬性必須被測試,這些樣例可以在后繼的樹分支中被進(jìn)一步細(xì)分。(C4.5中使用)
3.?簡單處理策略就是丟棄這些樣本
C4.5算法優(yōu)缺點(diǎn)
優(yōu)點(diǎn):產(chǎn)生的分類規(guī)則易于理解且準(zhǔn)確率較高。
缺點(diǎn):在構(gòu)造樹的過程中,需要對數(shù)據(jù)集進(jìn)行多次的順序掃描和排序,因而導(dǎo)致算法的低效。
6. 代碼示例
該代碼在數(shù)據(jù)集iris上用R語言進(jìn)行運(yùn)行,前提需要先安裝"RWeka", "party","partykit"這三個(gè)安裝包。即運(yùn)行下面代碼:
install.package("RWeka")
install.package("party")
install.package("partykit")
然后運(yùn)行下面例子代碼:
library(RWeka)
library(party)
library(partykit)
data(iris)
ml<-J48(Species~.,data=iris)
plot(ml)
代碼與結(jié)果分析:
代碼中前三行加載包不解釋,第4行加載數(shù)據(jù)集iris,第5行調(diào)用Weka中的函數(shù)J48(即C4.5),參數(shù)應(yīng)用很明顯,Species為因變量,其余為自變量,數(shù)據(jù)集為iris。構(gòu)建的修剪樹見下:

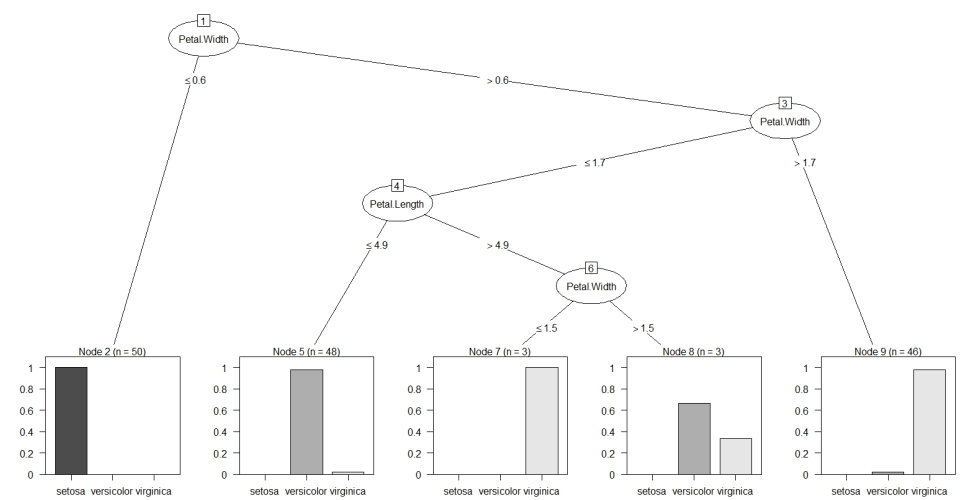
其中,結(jié)果第一行是花瓣的寬度小于等于0.6,有setosa花50個(gè)樣本,大于0.6的情況下,看花瓣的寬度是否大于1.7等等,對照樹形結(jié)構(gòu)圖會(huì)更容易理解,相信聰明的你能夠看懂。關(guān)于樹形結(jié)果圖中最后五個(gè)柱狀圖的橫坐標(biāo)表示:花的種類,列表示分類的的準(zhǔn)確率。下面最后兩行表示的是葉子節(jié)點(diǎn)的個(gè)數(shù)以及樹的大小(總共多少個(gè)節(jié)點(diǎn))。
至此,我們從C4.5算法簡介,算法描述,屬性選擇度量,算法剪枝,異常數(shù)據(jù)處理和代碼示例六大方面進(jìn)行了學(xué)習(xí),希望對大家有所幫助。
?點(diǎn)個(gè)贊再走唄?