
3種常見(jiàn)的集成學(xué)習(xí)決策樹(shù)算法及原理

集成學(xué)習(xí)

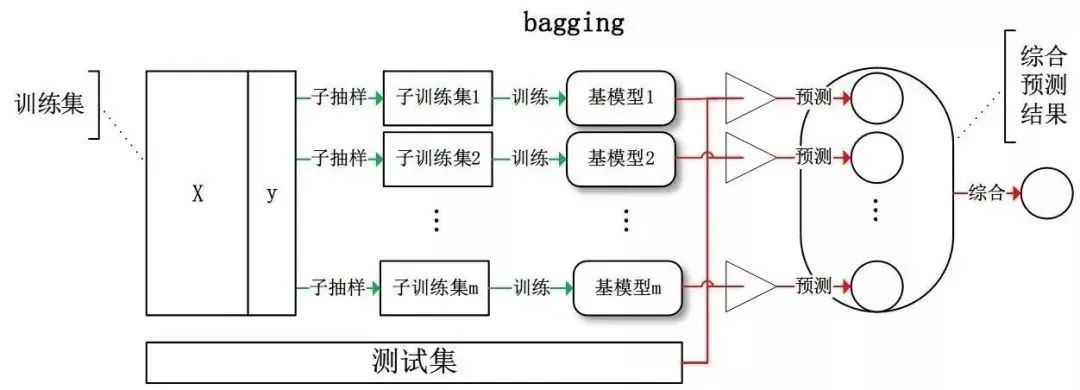
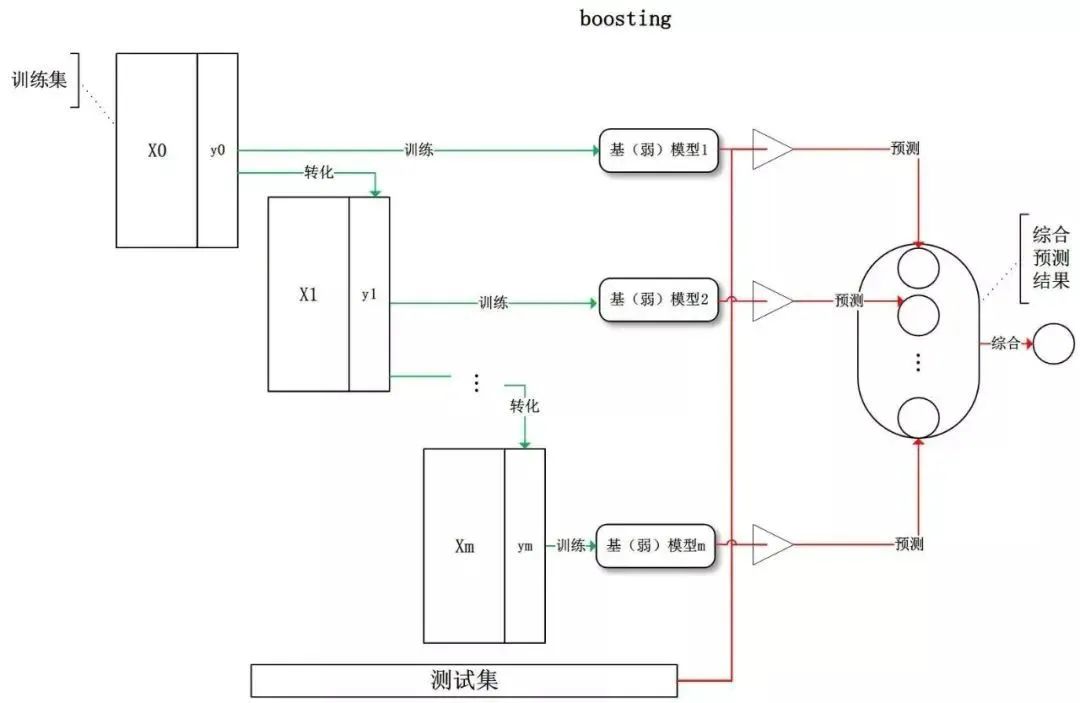
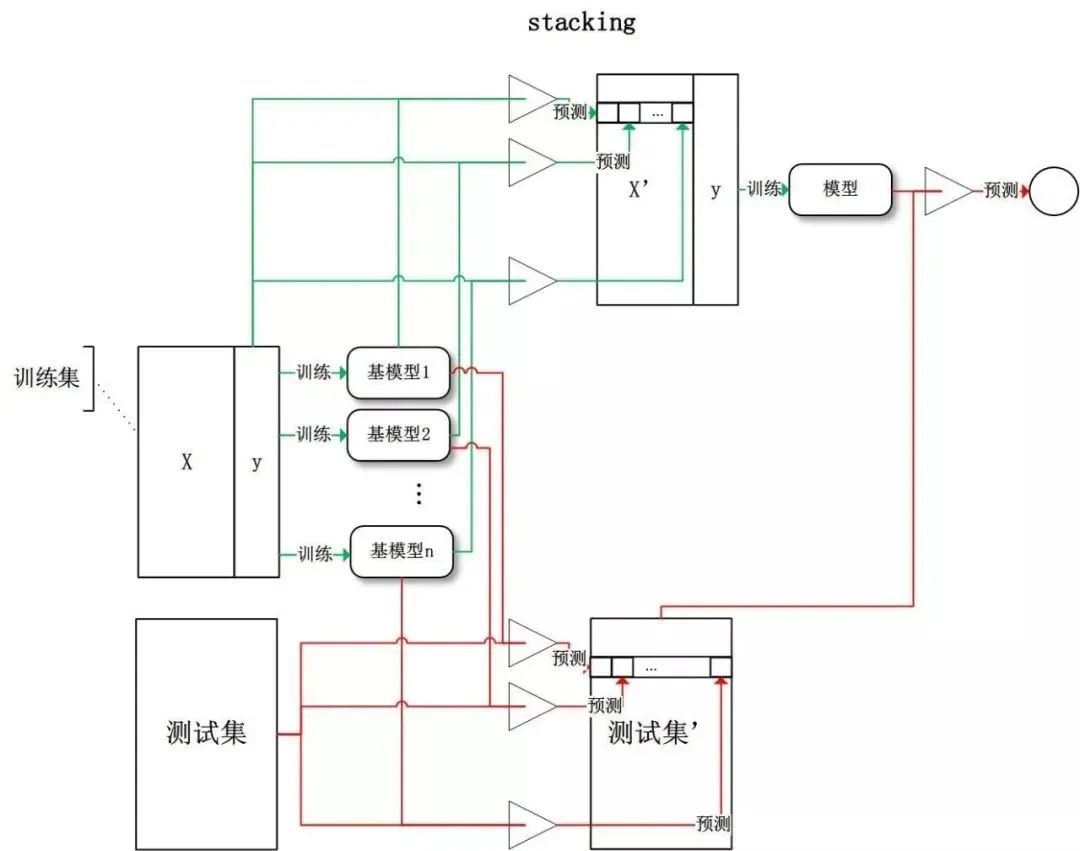
那么,為什么集成學(xué)習(xí)會(huì)好于單個(gè)學(xué)習(xí)器呢?原因可能有三:
訓(xùn)練樣本可能無(wú)法選擇出最好的單個(gè)學(xué)習(xí)器,由于沒(méi)法選擇出最好的學(xué)習(xí)器,所以干脆結(jié)合起來(lái)一起用;
假設(shè)能找到最好的學(xué)習(xí)器,但由于算法運(yùn)算的限制無(wú)法找到最優(yōu)解,只能找到次優(yōu)解,采用集成學(xué)習(xí)可以彌補(bǔ)算法的不足;
可能算法無(wú)法得到最優(yōu)解,而集成學(xué)習(xí)能夠得到近似解。比如說(shuō)最優(yōu)解是一條對(duì)角線,而單個(gè)決策樹(shù)得到的結(jié)果只能是平行于坐標(biāo)軸的,但是集成學(xué)習(xí)可以去擬合這條對(duì)角線。
偏差與方差
上節(jié)介紹了集成學(xué)習(xí)的基本概念,這節(jié)我們主要介紹下如何從偏差和方差的角度來(lái)理解集成學(xué)習(xí)。
2.1 集成學(xué)習(xí)的偏差與方差
偏差(Bias)描述的是預(yù)測(cè)值和真實(shí)值之差;方差(Variance)描述的是預(yù)測(cè)值作為隨機(jī)變量的離散程度。放一場(chǎng)很經(jīng)典的圖:
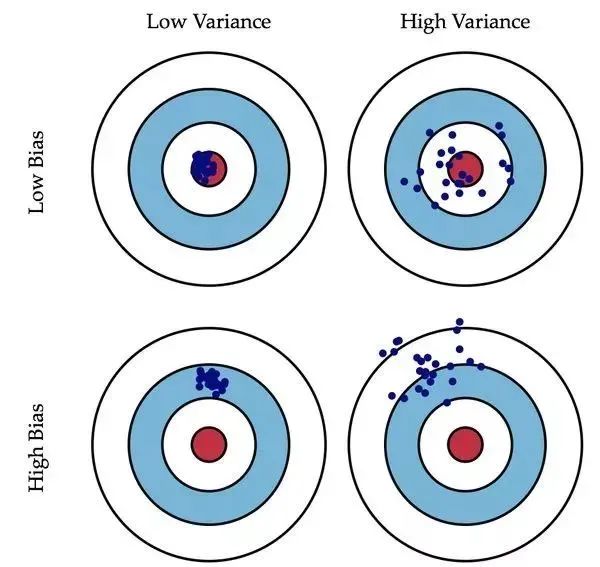
偏差:描述樣本擬合出的模型的預(yù)測(cè)結(jié)果的期望與樣本真實(shí)結(jié)果的差距,要想偏差表現(xiàn)的好,就需要復(fù)雜化模型,增加模型的參數(shù),但這樣容易過(guò)擬合,過(guò)擬合對(duì)應(yīng)上圖的 High Variance,點(diǎn)會(huì)很分散。低偏差對(duì)應(yīng)的點(diǎn)都打在靶心附近,所以喵的很準(zhǔn),但不一定很穩(wěn); 方差:描述樣本上訓(xùn)練出來(lái)的模型在測(cè)試集上的表現(xiàn),要想方差表現(xiàn)的好,需要簡(jiǎn)化模型,減少模型的復(fù)雜度,但這樣容易欠擬合,欠擬合對(duì)應(yīng)上圖 High Bias,點(diǎn)偏離中心。低方差對(duì)應(yīng)就是點(diǎn)都打的很集中,但不一定是靶心附近,手很穩(wěn),但不一定瞄的準(zhǔn)。
整體模型的期望等于基模型的期望,這也就意味著整體模型的偏差和基模型的偏差近似。
整體模型的方差小于等于基模型的方差,當(dāng)且僅當(dāng)相關(guān)性為 1 時(shí)取等號(hào),隨著基模型數(shù)量增多,整體模型的方差減少,從而防止過(guò)擬合的能力增強(qiáng),模型的準(zhǔn)確度得到提高。但是,模型的準(zhǔn)確度一定會(huì)無(wú)限逼近于 1 嗎?并不一定,當(dāng)基模型數(shù)增加到一定程度時(shí),方差公式第一項(xiàng)的改變對(duì)整體方差的作用很小,防止過(guò)擬合的能力達(dá)到極限,這便是準(zhǔn)確度的極限了。
整體模型的方差等于基模型的方差,如果基模型不是弱模型,其方差相對(duì)較大,這將導(dǎo)致整體模型的方差很大,即無(wú)法達(dá)到防止過(guò)擬合的效果。因此,Boosting 框架中的基模型必須為弱模型。
此外 Boosting 框架中采用基于貪心策略的前向加法,整體模型的期望由基模型的期望累加而成,所以隨著基模型數(shù)的增多,整體模型的期望值增加,整體模型的準(zhǔn)確度提高。
我們可以使用模型的偏差和方差來(lái)近似描述模型的準(zhǔn)確度;
對(duì)于 Bagging 來(lái)說(shuō),整體模型的偏差與基模型近似,而隨著模型的增加可以降低整體模型的方差,故其基模型需要為強(qiáng)模型;
對(duì)于 Boosting 來(lái)說(shuō),整體模型的方差近似等于基模型的方差,而整體模型的偏差由基模型累加而成,故基模型需要為弱模型。
Random Forest
隨機(jī)選擇樣本(放回抽樣); 隨機(jī)選擇特征; 構(gòu)建決策樹(shù); 隨機(jī)森林投票(平均)。
在數(shù)據(jù)集上表現(xiàn)良好,相對(duì)于其他算法有較大的優(yōu)勢(shì) 易于并行化,在大數(shù)據(jù)集上有很大的優(yōu)勢(shì); 能夠處理高維度數(shù)據(jù),不用做特征選擇。
AdaBoost
初始化訓(xùn)練樣本的權(quán)值分布,每個(gè)樣本具有相同權(quán)重; 訓(xùn)練弱分類器,如果樣本分類正確,則在構(gòu)造下一個(gè)訓(xùn)練集中,它的權(quán)值就會(huì)被降低;反之提高。用更新過(guò)的樣本集去訓(xùn)練下一個(gè)分類器; 將所有弱分類組合成強(qiáng)分類器,各個(gè)弱分類器的訓(xùn)練過(guò)程結(jié)束后,加大分類誤差率小的弱分類器的權(quán)重,降低分類誤差率大的弱分類器的權(quán)重。
分類精度高; 可以用各種回歸分類模型來(lái)構(gòu)建弱學(xué)習(xí)器,非常靈活; 不容易發(fā)生過(guò)擬合。
對(duì)異常點(diǎn)敏感,異常點(diǎn)會(huì)獲得較高權(quán)重。
GBDT

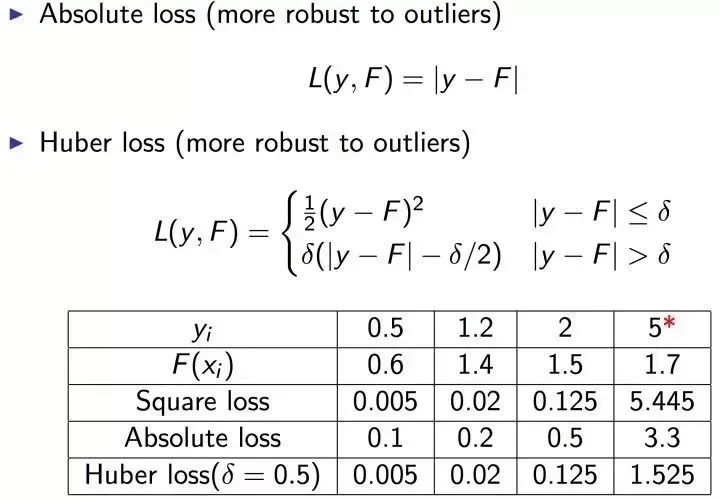
可以自動(dòng)進(jìn)行特征組合,擬合非線性數(shù)據(jù); 可以靈活處理各種類型的數(shù)據(jù)。
對(duì)異常點(diǎn)敏感。
都是 Boosting 家族成員,使用弱分類器; 都使用前向分布算法;
迭代思路不同:Adaboost 是通過(guò)提升錯(cuò)分?jǐn)?shù)據(jù)點(diǎn)的權(quán)重來(lái)彌補(bǔ)模型的不足(利用錯(cuò)分樣本),而 GBDT 是通過(guò)算梯度來(lái)彌補(bǔ)模型的不足(利用殘差); 損失函數(shù)不同:AdaBoost 采用的是指數(shù)損失,GBDT 使用的是絕對(duì)損失或者 Huber 損失函數(shù);