分享一個能夠?qū)懺诤啔v里的企業(yè)級數(shù)據(jù)挖掘?qū)崙?zhàn)項目
↑↑↑關(guān)注后"星標"簡說Python
人人都可以簡單入門Python、爬蟲、數(shù)據(jù)分析 簡說Python推薦 來源:數(shù)據(jù)STUDIO 作者:云朵君
導(dǎo)讀: 大家好,我是云朵君,最近有很多小伙伴留言說,想要我分享一些數(shù)據(jù)挖掘?qū)崙?zhàn)案例。今天就來給大家分享一個這么一個項目。本次數(shù)據(jù)挖掘主要目的是理清楚數(shù)據(jù)挖掘的一般過程與基本方法,并沒有進行太過復(fù)雜的挖掘分析,或許會存在很多分析不夠深入的情況,歡迎各位大佬交流討論。文章較長,建議點贊、收藏轉(zhuǎn)發(fā)閱讀。
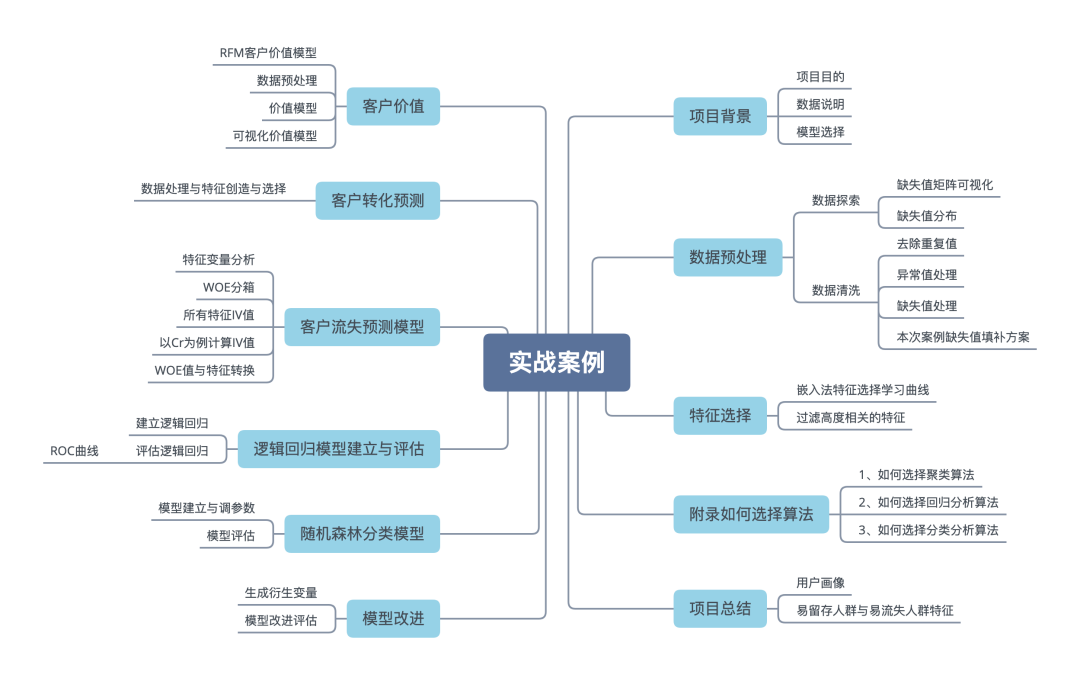
app客戶流失及客戶行為偏好分析(僅供參考)20**年*月 - 20**年*月
分類信息app,通過數(shù)據(jù)挖掘分析影響用戶流失的關(guān)鍵因素、深入了解用戶行為偏好以此做出調(diào)整,提升客戶留存率,增強客戶黏性,并通過隨機森林算法預(yù)測客戶流失,通過特征創(chuàng)造使模型分數(shù)提高2個百分點。
項目內(nèi)容:
探索數(shù)據(jù)分布,缺失情況,針對性的進行缺失值填補,對于缺失較少的重要特征選擇隨機森林缺失填補法,使用3sigma、箱型圖分析等對異常值進行處理,對分類型變量進行編碼。 使用方差過濾、F檢驗過濾掉一部分特征,進行WOE分箱,對每個特征分箱結(jié)果進行可視化,分析每個特征分箱情況并以此分析 用戶行為偏好,使用各個特征的IV值進一步篩選特征。 訓(xùn)練隨機森林模型,模型調(diào)參、評估,輸出模型,以此模型對用戶流失進行預(yù)測,以便針對性地挽留用戶。訓(xùn)練邏輯回歸模型,通過其算法可解釋性強的特點(特征系數(shù))來對用戶流失關(guān)鍵因素進行闡述。 使用工具:
python、pandas、numpy、matplotlib、seaborn、sklearn庫
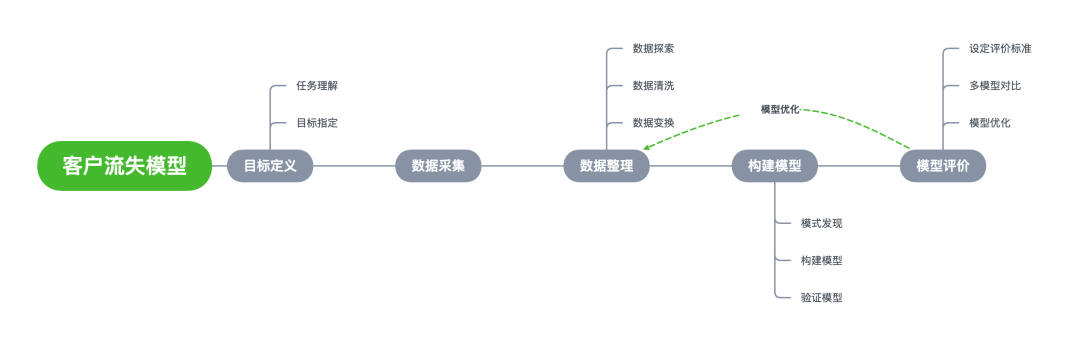
在做一個數(shù)據(jù)挖掘項目前,需要預(yù)先擬好主要思路,比如目標是什么,先做什么,再做什么,有哪些注意事項等等。
本次案例內(nèi)容,包括數(shù)據(jù)、代碼均可在公眾號「簡說Python」后臺回復(fù)【實戰(zhàn)項目】獲取!
項目背景
項目目的
深入了解用戶畫像及行為偏好,挖掘出影響用戶流失的關(guān)鍵因素,并通過算法預(yù)測客戶訪問的轉(zhuǎn)化結(jié)果,從而更好地完善產(chǎn)品設(shè)計、提升用戶體驗!
數(shù)據(jù)說明
此次數(shù)據(jù)是攜程用戶一周的訪問數(shù)據(jù),為保護客戶隱私,已經(jīng)將數(shù)據(jù)經(jīng)過了脫敏,和實際商品的訂單量、瀏覽量、轉(zhuǎn)化率等有一些差距,不影響問題的可解性。
模型選擇
本次項目主要從三個方面來分析,客戶流失、客戶轉(zhuǎn)化和客戶價值。
客戶流失
目標變量label表示是否流失,是0-1二分類問題,目的是需要挖掘出關(guān)鍵因素,擬選用邏輯回歸做模型訓(xùn)練及預(yù)測。
客戶轉(zhuǎn)化
預(yù)測客戶轉(zhuǎn)化率,是連續(xù)型變量預(yù)測問題,擬選擇集成數(shù)模型--隨機森林回歸。
客戶價值
為了更加細致的挖掘客戶價值,選擇RFM客戶價值模型進行分析。
數(shù)據(jù)預(yù)處理
數(shù)據(jù)探索
具體理論可以參見Python數(shù)據(jù)分析之?dāng)?shù)據(jù)探索分析(EDA)。
缺失值矩陣可視化
缺失值可視化兩種思路,定性化和定量化兩個思路。直接定性觀察整體缺失情況,即用第三方模塊missingno繪制矩陣圖,下圖中白色部分為缺失值。
import missingno as msno
msno.matrix(data)

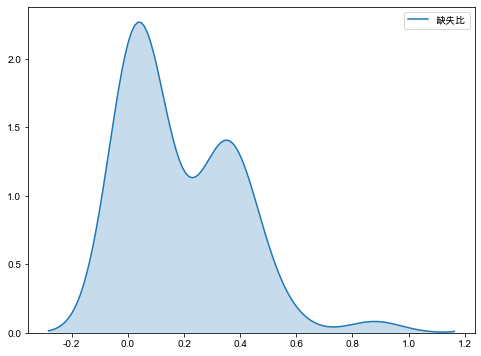
缺失值分布
另一個是定量化分析,即計算每個字段的缺失值比例,通過核密度估計圖繪制缺失值分布圖。
右下圖可見缺失值分布是雙峰分布,第一高峰在0左右,表明大部分數(shù)據(jù)是完整的或僅存在少部分缺失。第二高峰在30%~40%左右,因此對于缺失值的處理,需要根據(jù)不同缺失情況定制不同的缺失值處理方案。
import seaborn as sns
sns.kdeplot(null['缺失比'],shade=True)
經(jīng)過一系列探索分析,本次數(shù)據(jù)有以下特點:
689945條記錄, 49個特征 兩個標簽,一個分類標簽,一個連續(xù)型標簽 數(shù)據(jù)缺失嚴重 存在多個偏態(tài),需與業(yè)務(wù)人員溝通,以便更好地處理 無重復(fù)值
數(shù)據(jù)清洗
數(shù)據(jù)清洗主要包括去除重復(fù)值、處理缺失值、處理異常值、?成衍生變量等操作。其中處理順序根據(jù)實際處理過程涉及的問題而定,這里的順序僅供參考。
去除重復(fù)值
對于一般模型影響不大,但對于回歸模型?言,容易導(dǎo)致回歸系數(shù)標準誤降低,使得對應(yīng)p值減?。重復(fù)值過多,樣本隨機誤差降低,造成參數(shù)的貢獻程度會被高估。本案例沒有重復(fù)值,可以略過。
異常值處理
首先處理異常值,最低酒店定價有小于0的,有等于1的值,明顯屬于異常值。異常值處理方法較多,常見有直接刪除,當(dāng)缺失值處理等等,本例中,我們用蓋帽法處理此異常值。
# 定義蓋帽法函數(shù)
def block_lower(x):
# x是輸?入的Series對象,替換1%分位數(shù)
ql = x.quantile(.01)
out = x.mask(x<ql,ql)
return(out)
def block_upper(x):
# x是輸?入的Series對象,l替換99%分位數(shù)
qu = x.quantile(.99)
out = x.mask(x>qu,qu)
return(out)
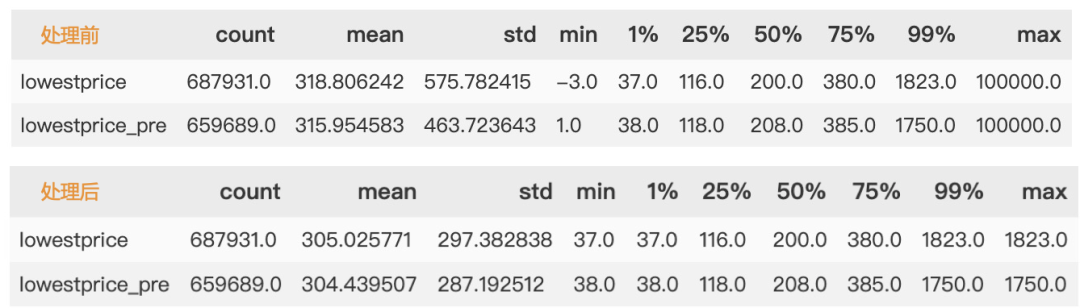
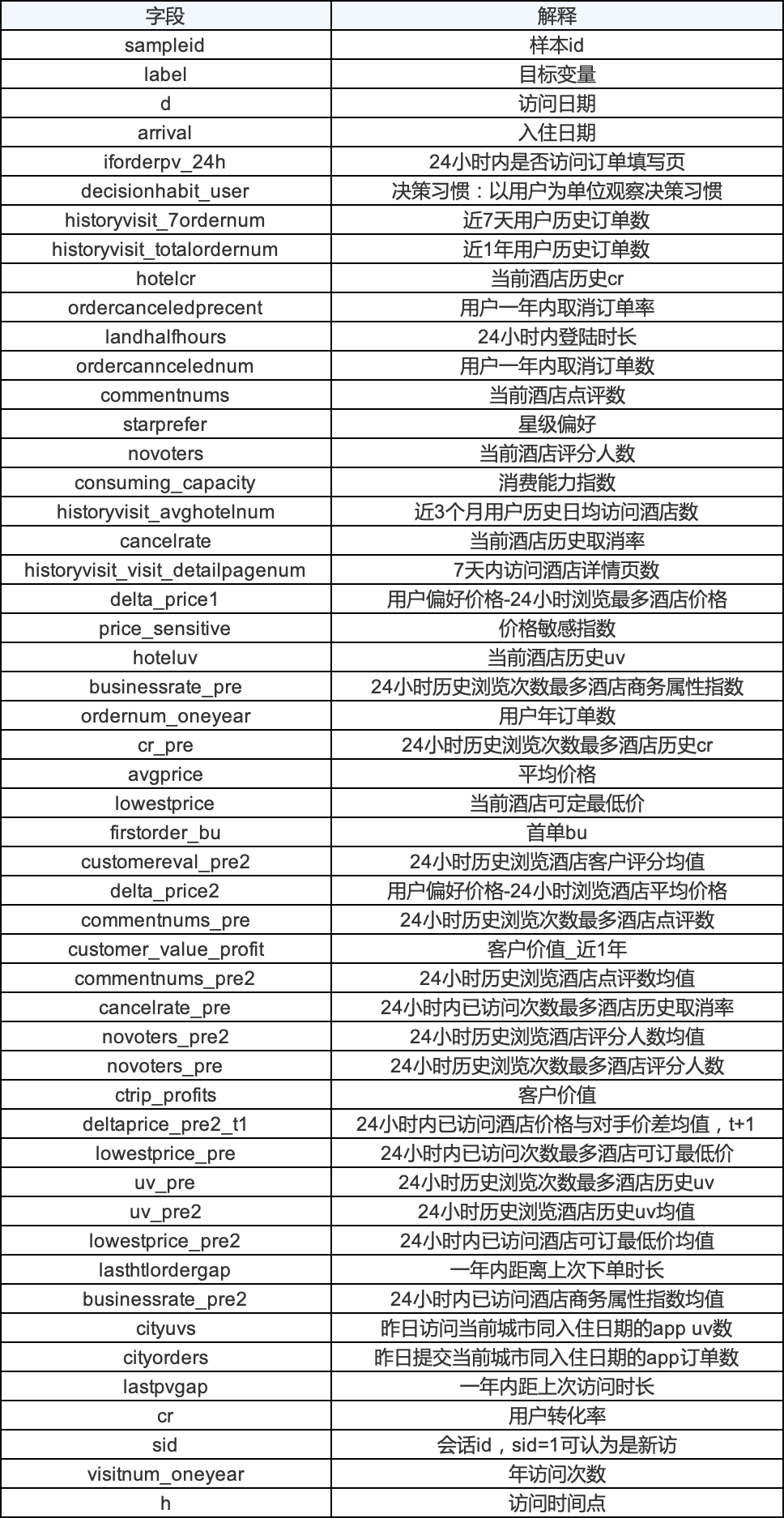
lowestprice: 當(dāng)前酒店可定最低價
lowestprice_pre: 24小時內(nèi)已訪問次數(shù)最多酒店可訂最低價
缺失值處理
可以參見缺失值處理,本次案例缺失值填補方案。
分類型變量用 眾數(shù)填補含有負數(shù)的特征用 中值填補方差大于100的連續(xù)型變量用 中值填補缺失35%用 常數(shù) -1 填充單獨做一類其余變量用 均值填補超過80% 直接刪除變量
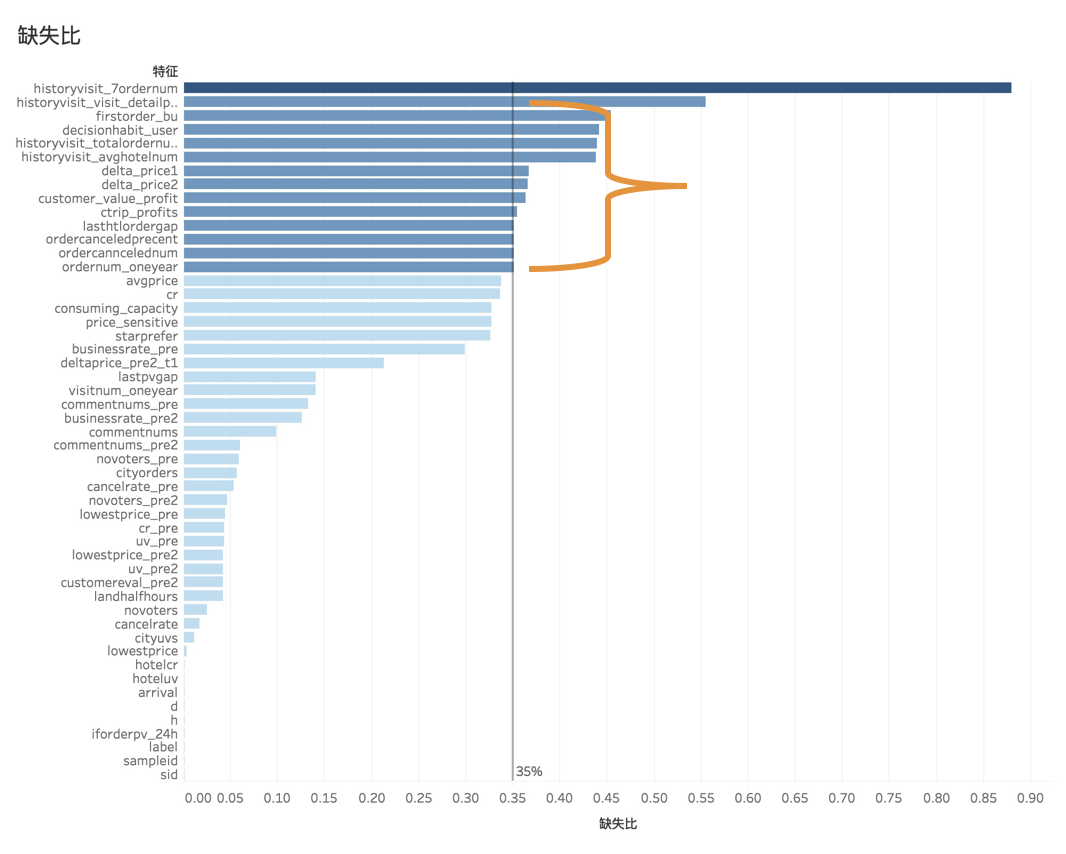
特征選擇
本次選用簡單粗暴的方差過濾、F_檢驗、 以及嵌入法特征選擇,利用樹模型的特征重要性輸出結(jié)合模型效果,選擇對模型貢獻最大的那個幾個變量。事實證明,此方法效果明顯,最后成功選擇出8個特征。
| 方法 | 說明 |
|---|---|
| 方差過濾 | 方差等于0 的直接過濾,結(jié)果無過濾特征 |
| F_檢驗 | 過濾沒有相關(guān)性的變量。pvalues_f < 0.01 直接過濾,過濾掉6個特征 |
| 嵌入法特征選擇 | 經(jīng)過選擇,等到貢獻最大的8個特征 |
嵌入法特征選擇學(xué)習(xí)曲線
利用隨機森林特征重要性屬性feature_importances_定義閾值范圍,以嵌入選擇模型SelectFromModel為基礎(chǔ),通過交叉驗證cross_val_score得到每個閾值下模型得分情況。
繪制得到學(xué)習(xí)曲線如下圖所示,在閾值為0.0295956時,模型精確度得分最高--
# 主要代碼
X_embedded = SelectFromModel(RFC_clf,
threshold=i).fit_transform(Xtrain,Ytrain)
val = cross_val_score(RFC_clf,
X_embedded,
Ytrain,cv=5).mean()
score.append(val)
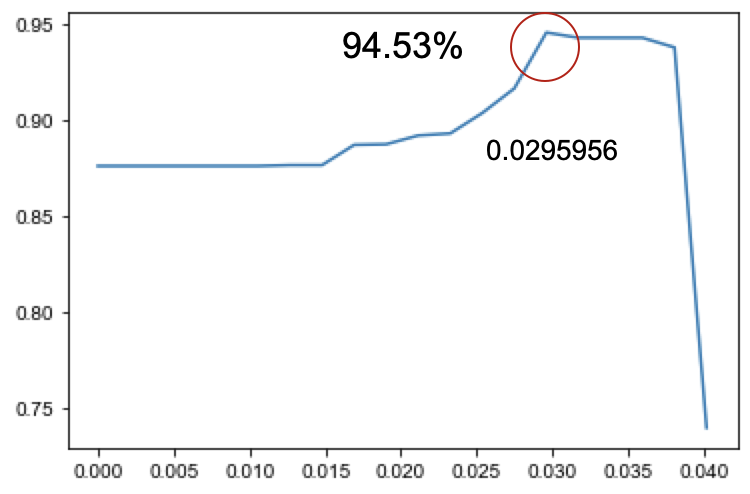
過濾高度相關(guān)的特征
熱圖用于特征間的相關(guān)性分析,通過繪制熱圖,分析發(fā)現(xiàn)有以下兩個高度相關(guān)的變量,最終刪除特征cityuvs。
cityuvs:昨日訪問當(dāng)前城市同入住日期的app uv數(shù)cityorders昨日提交當(dāng)前城市同入住日期的app訂單數(shù)
sns.heatmap(Xtrain_new.corr(),
annot=True,linewidths=1)
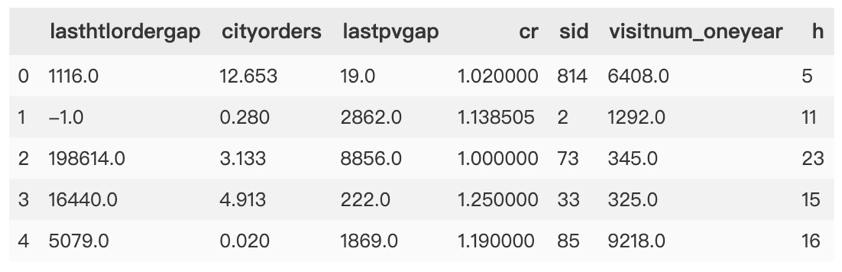
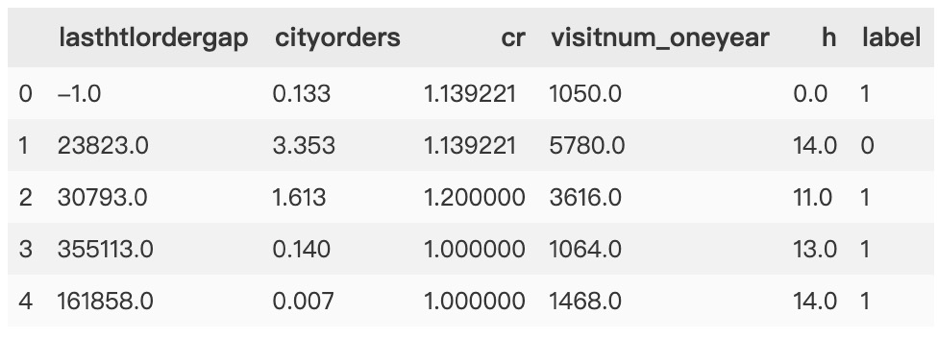
經(jīng)過數(shù)據(jù)預(yù)處理及特征選擇后,最終得到如下數(shù)據(jù):
客戶流失預(yù)測模型
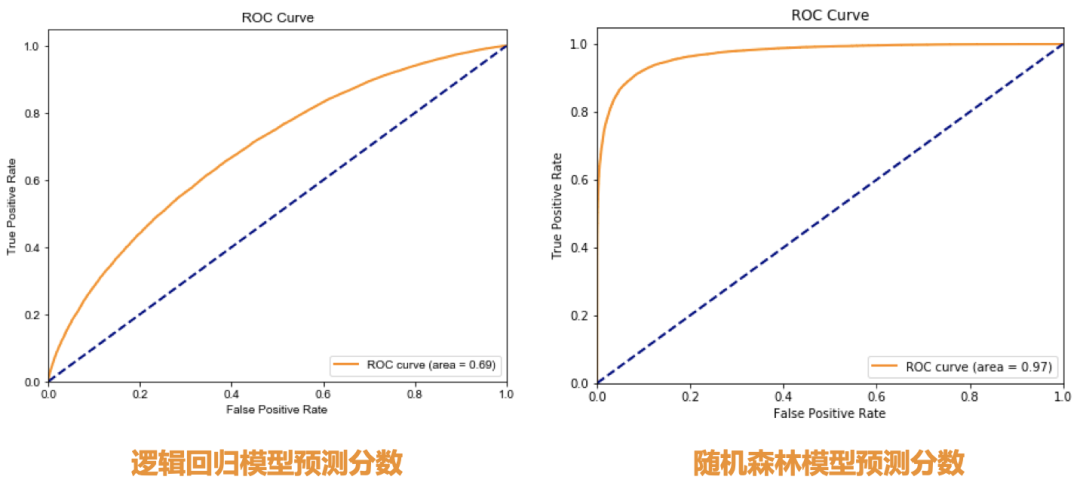
客戶流失預(yù)測模型的實現(xiàn)方法屬于分類算法,常用算法包括邏輯回歸、支持向量機、隨機森林等。這里總結(jié)了下模型選擇的一些參考,見文末附錄。
大部分情況下,流失客戶的樣本分類是少數(shù)類,需要注意處理樣本不均衡問題。
經(jīng)過數(shù)據(jù)預(yù)處理后,我們決定利用邏輯回歸了解用戶畫像及行為偏好,挖掘出影響用戶流失的關(guān)鍵因素,并輔以隨機森林分類器進行預(yù)測客戶流失。
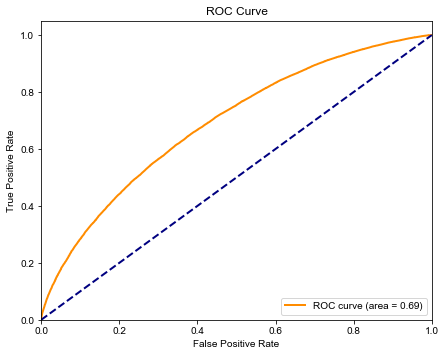
需要知道關(guān)鍵因素,要求模型需要有很好的可解釋性,因此選用邏輯回歸模型。但從模型評價結(jié)果(ROC曲線面積)來看,邏輯回歸并不是很理想。
若需要同時追求模型預(yù)測精確度,則選取集成模型或其他強學(xué)習(xí)模型。這里選用大家熟知的隨機森林分類器。
特征變量分析
在將數(shù)據(jù)用于模型訓(xùn)練之前,需要先對變量進行深入分析。分析變量間是否存在高度相關(guān)性,連續(xù)性變量是否需要離散化,離散變量是否需要編碼等等。
ax = plt.figure(figsize=(8,15))
for i in range(len(train_data.columns[:-1])):
ax.add_subplot(8,1,i+1)
sns.kdeplot(train_data.iloc[:,i],shade=True)
plt.title(l_[i])
plt.tight_layout();
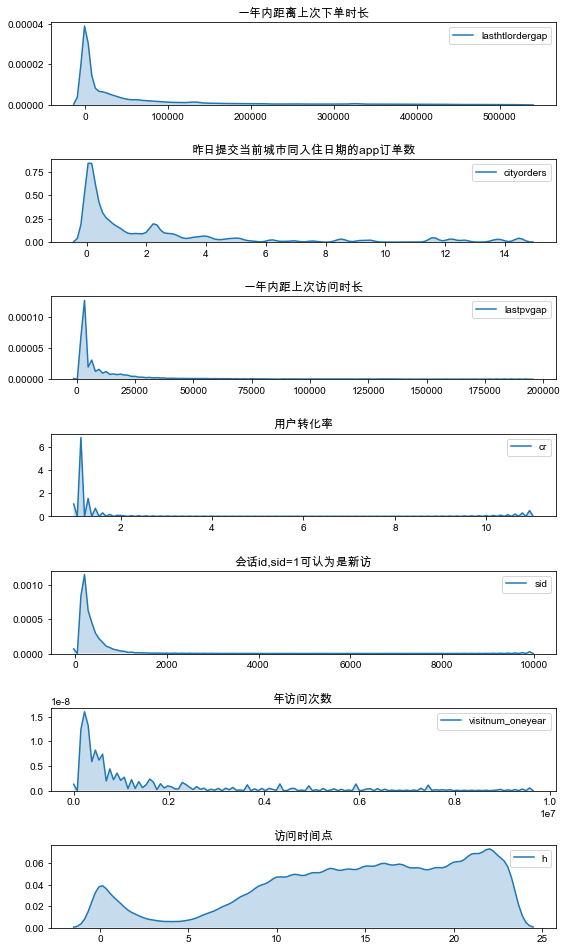
不難發(fā)現(xiàn),除訪問時間點外,特征均成右偏分布。因此將連續(xù)型、分類型變量做分箱處理,此處我們選用WEO分箱處理。
WOE分箱
WOE(Weight of Evidence) 好樣本比壞樣本的比例的對數(shù)。
WOE編碼: 追求組間差異大、組內(nèi)差異小、必須要有好壞兩種分類。
WOE對于一個箱子來說,WOE越大,代表好樣本越多。
每個箱子, 在這個特征上箱子的個數(shù)。是這個箱內(nèi)的標簽為0的樣本占整個特征中所有標簽為0的?。 代表了特征對預(yù)測函數(shù)的貢獻度。
為什么要引?分箱
分箱的本質(zhì),其實就是離散化連續(xù)變量。
評分結(jié)果需要有一定的穩(wěn)定性 分類型變量: 個數(shù)比較少就可以不作處理,如果取值過多會導(dǎo)致"變量膨脹"
分箱的要求
不需要分箱變量: 對于分類型變量如果取值較少,?般?需分箱 分箱結(jié)果的有序性: 對于有序型變量(數(shù)值型、有序離散型) 分箱的平衡性: 嚴格情況下,每?個箱?的占比不能相差太大。?般要求占比最小的箱?不低于5% 分箱的單調(diào)性: 嚴格情況下,有序型變量分箱后每個箱?的壞樣本率與箱子呈單調(diào)關(guān)系
分箱的個數(shù): 5個以內(nèi),5-7個比較合適
分箱優(yōu)缺點:
優(yōu)點: 穩(wěn)定、缺失值處理理、異常值處理理、不需要歸一化 缺點: 有信息丟失、需要再進?一次編碼
常?的分箱?法
有監(jiān)督: 決策樹分箱法、卡?分箱 無監(jiān)督: 等距、等深、聚類
我們總結(jié)出一個特征進行分箱的步驟:
我們?先把連續(xù)型變量分成?組數(shù)量較多的分類型變量,?如,將幾萬個樣本分成100組,或50組(盡量有監(jiān)督的分箱) 確保每?組中都要包含兩種類別的樣本,否則IV值會?法計算 我們對相鄰的組進?卡方檢驗,卡方檢驗的P值很大的組進?合并,直到數(shù)據(jù)中的組數(shù)?于設(shè)定的N箱為止 我們讓?個特征分別分成[2,3,4.....20]箱,觀察每個分箱個數(shù)下的IV值如何變化,找出最適合的分箱個數(shù) 分箱完畢后,我們計算每個箱的WOE值,觀察分箱效果
這些步驟都完成后,我們可以對各個特征都進行分箱,然后觀察每個特征的IV值,以此來挑選特征。下?我們就對每個x生成?個對象、記錄IV值、生成WOE圖。此處代碼需要運??定義函數(shù)所在?件,若有需要,可關(guān)注「數(shù)據(jù)STUDIO」并回復(fù)【210514】獲取哦!每個x變量運行結(jié)果如下。
特征IV值
計算每個變量的IV值,并排序后繪制條形圖。通過對比分析并去掉IV值最小,即對模型基本沒有貢獻的兩個特征——sid, lastpvgap。
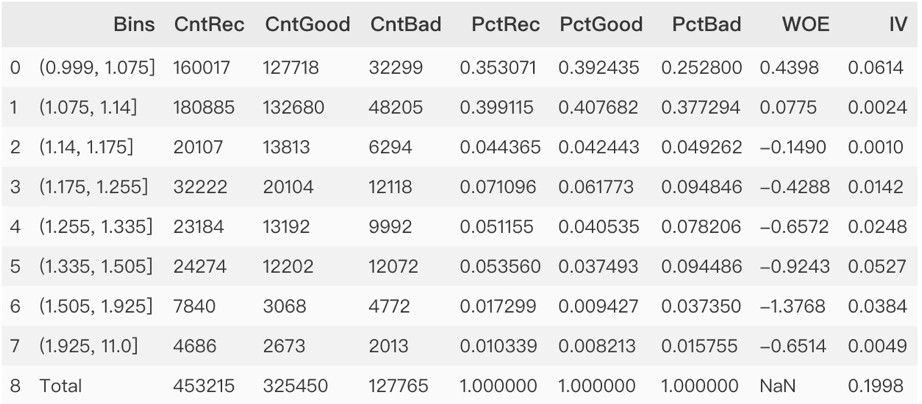
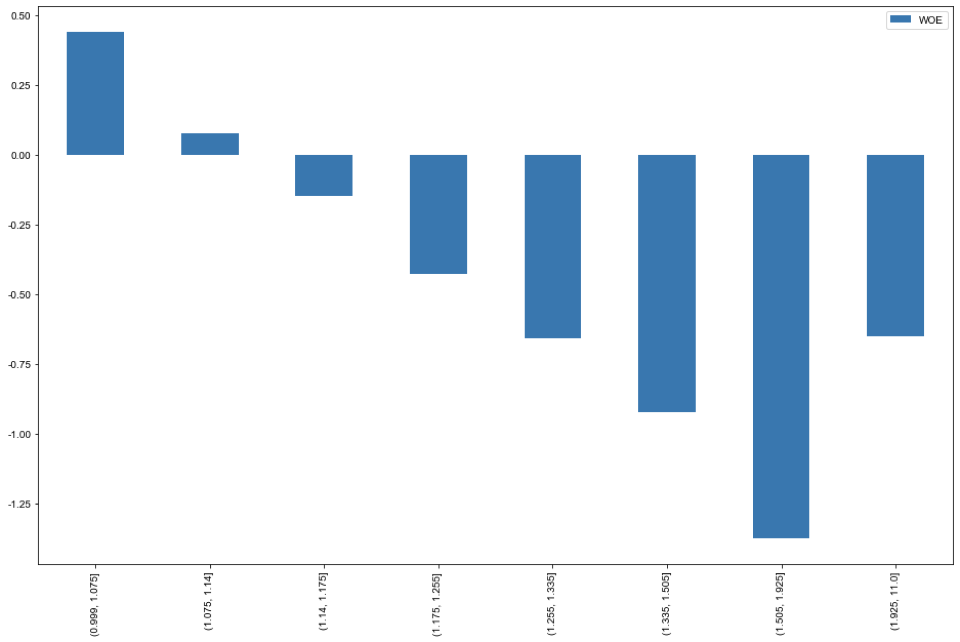
計算Cr的IV值
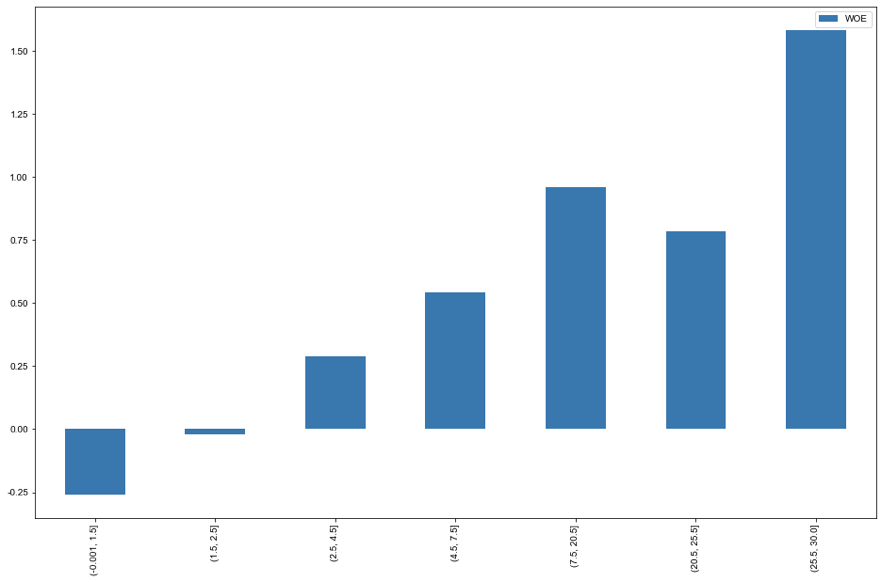
以計算用戶轉(zhuǎn)化率為例,進行WOE分箱并計算對應(yīng)的IV值。通過分析得到如下結(jié)論。
用戶轉(zhuǎn)化率在小于1.14%時用戶留存較多。隨著用戶轉(zhuǎn)化率增大時,流失用戶流失增大,但注意在大于1.925%往上,客戶留存在變多。
Lasthtlordergap 一年內(nèi)距上次下單時長
一年內(nèi)距上次下單時長在(2.5,1327)區(qū)間內(nèi)轉(zhuǎn)化結(jié)果最差,隨著時間延長,流失風(fēng)險降低,需要關(guān)注兩次下單時間間隔較長的用戶。
H 訪問時間點
訪問時間點在上午時,客戶留存效果并不好,在晚上7點后訪問的客戶,流失率少,且隨著時間點推移,留存在明顯增大,在凌晨時仍存在留存客戶優(yōu)勢。
Cityorders 昨日提交當(dāng)前城市同入住app訂單數(shù)
昨日提交當(dāng)前城市同入住app訂單數(shù)在第5箱(2.25,2.294)區(qū)間內(nèi)留存結(jié)果最好。
除第5箱外,客戶留存結(jié)果隨著訂單數(shù)增加而逐漸降低,在大于0.37時,留存客戶少于流失客戶,客戶流失風(fēng)險較大。
visitnum_oneyear 年訪問次數(shù)
年訪問次數(shù)在61650前期有較小的浮動,在大于61650時出現(xiàn)高峰 。只有訪問次數(shù)高到一定程度時(超過15000),該特征才能較明顯的客戶留存。
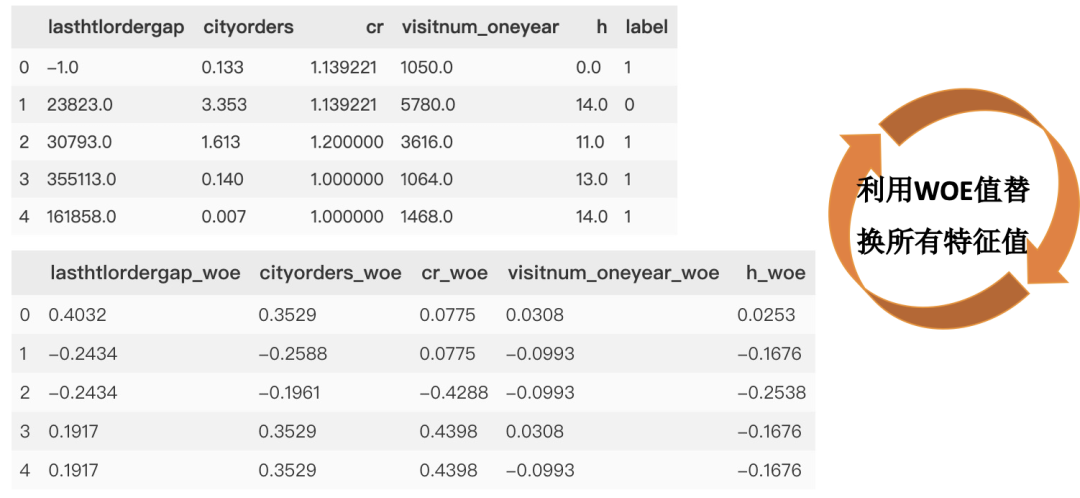
WOE值與特征轉(zhuǎn)換
得到每個變量的WOE值,將所有特征值換成對應(yīng)的WOE值。
邏輯回歸模型建立與評估
特征工程完畢后建立邏輯回歸模型,并利用召回率,假正率,ROC曲線評估模型。
建立邏輯回歸
from sklearn.linear_model import LogisticRegression
LR = LogisticRegression().fit(X_train,Y_train)
并計算各特征系數(shù)與截距:

評估邏輯回歸
并計算在訓(xùn)練集和測試集分數(shù)分別如下:
| LR.score(X_train,Y_train) | LR.score(X_test,Y_test) | |
|---|---|---|
| score | 0.728283 | 0.726898 |
core metrics
+-------+----------+-----------+--------+-------+
| auc | accuracy | precision | recall | f1 |
+-------+----------+-----------+--------+-------+
| 0.675 | 0.727 | 0.741 | 0.951 | 0.833 |
+-------+----------+-----------+--------+-------+
ROC曲線
from sklearn.metrics import auc,accuracy_score,recall_score,f1_score
y_score = LR.predict_proba(X_test) # 隨機森林
fpr, tpr, thresholds = roc_curve(Y_test, y_score[:, 1])
roc_auc = auc(fpr, tpr)
def drawRoc(roc_auc,fpr,tpr):
plt.plot(fpr, tpr, color='darkorange', lw=2, label='ROC curve (area = %0.2f)' % roc_auc)
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
drawRoc(roc_auc, fpr, tpr)
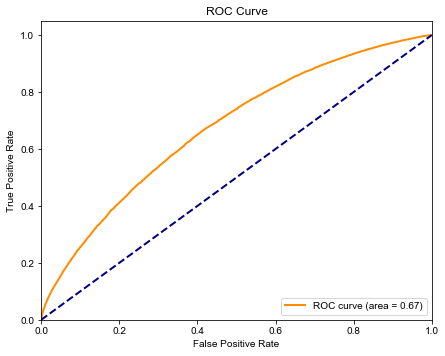
模型改進
我們發(fā)現(xiàn)邏輯回歸ROC較低,我們試圖從特征角度上來改進模型。
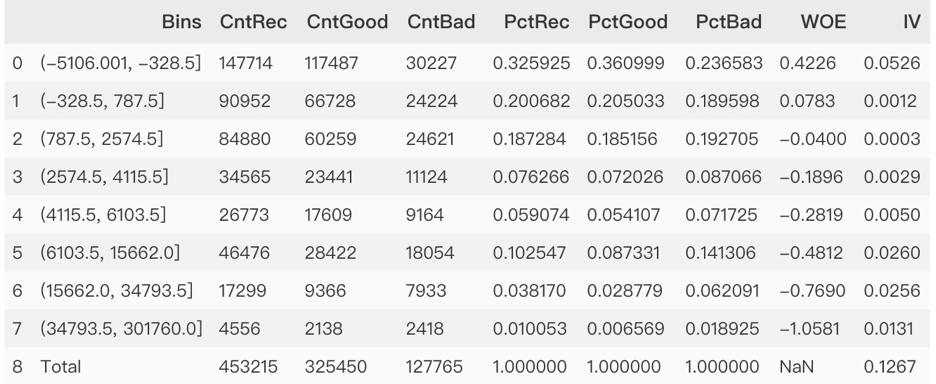
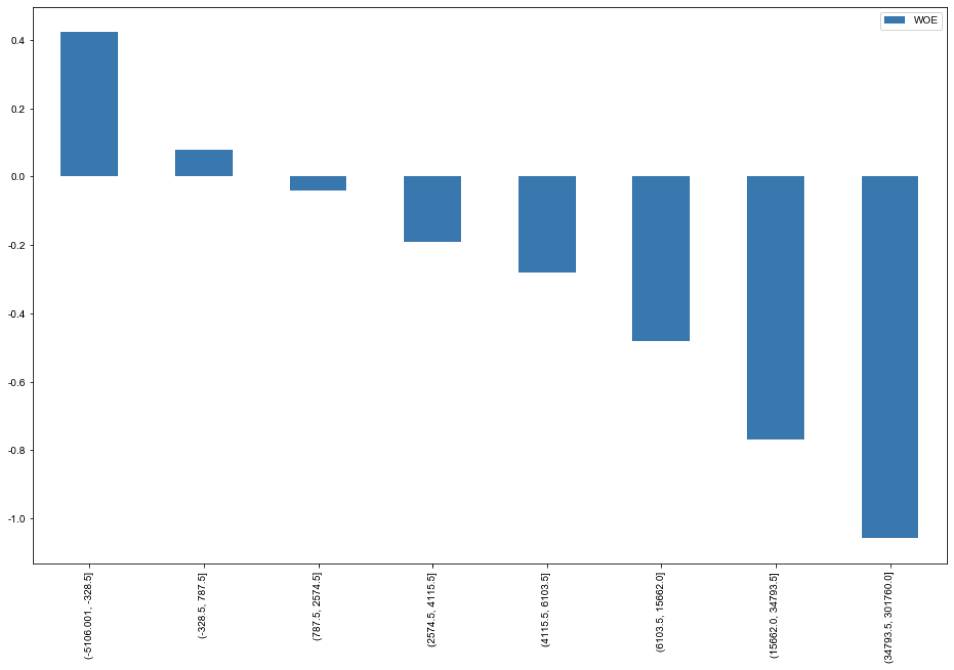
生成衍生變量
M = ordernum_oneyear * avgprice
ordernum_oneyear 用戶年訂單數(shù)
avgprice 平均價格
我們將平均價格和年訂單量相乘得到年消費,發(fā)現(xiàn)客戶年消費越多,流失越多。
將生產(chǎn)的衍射變量進行WOE分箱。
從IV值看:此特征對標簽有較大的貢獻度; 從客戶箱子來看,總體呈現(xiàn)單調(diào)遞減,客戶年消費越多,流失風(fēng)險越大。
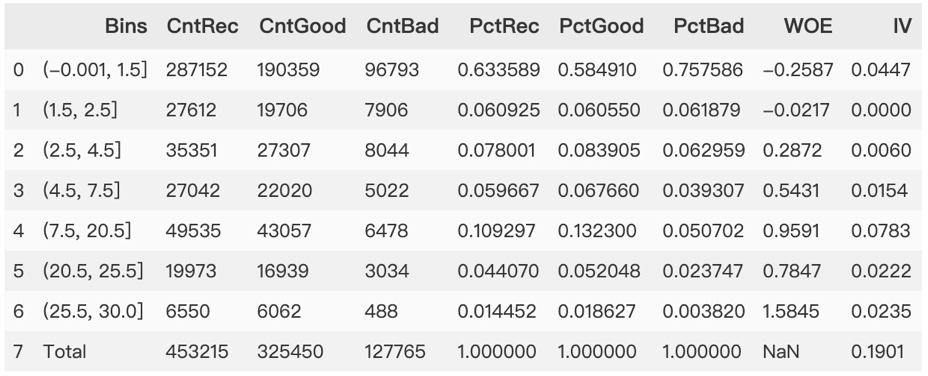
d : 訪問日期
arrival :入住日期
此時想到一開始我們之間將日期時間刪除處理,現(xiàn)在將其處理后帶入模型看看什么效果。
用入住日期減去訪問日期得到間隔日期delta,發(fā)現(xiàn)客戶在入住前很早就訪問,留存率會很大。
將生產(chǎn)的衍射變量進行WOE分箱。
從IV值看:此特征對標簽有較大的貢獻度; 從客戶箱子來看,總體呈現(xiàn)單調(diào)遞增,客戶瀏覽日期距離入住日期越久,流失越少。
模型改進評估
建立邏輯回歸
并計算各特征系數(shù)與截距:

評估邏輯回歸
計算在訓(xùn)練集和測試集分數(shù)分別如下:
| LR.score(X_train,Y_train) | LR.score(X_test,Y_test) | |
|---|---|---|
| score | 0.732319 | 0.731017 |
core metrics
+--------+----------+-----------+--------+-------+
| auc | accuracy | precision | recall | f1 |
+--------+----------+-----------+--------+-------+
| 0.6895 | 0.731 | 0.745 | 0.949 | 0.835 |
+--------+----------+-----------+--------+-------+
經(jīng)生成兩個衍生變量后,邏輯回歸模型ROC得分提高2個百分點。
隨機森林分類模型
模型建立與調(diào)參數(shù)
隨機森林分類器目的是輔助預(yù)測客戶流失,因此利用清洗好的數(shù)據(jù)直接利用網(wǎng)格搜索進行調(diào)參數(shù):
n_estimators = range(10, 201, 10)
max_depth= range(3, 21,1)
min_samples_split= range(2, 22, 1)
min_samples_leaf = range(1, 12, 1)
n_estimators = range(10, 201, 10)
得到最佳參數(shù)組合為
model = RFC(n_estimators=180
,max_depth=20
,min_samples_leaf=1
,min_samples_split=2
,random_state=0)
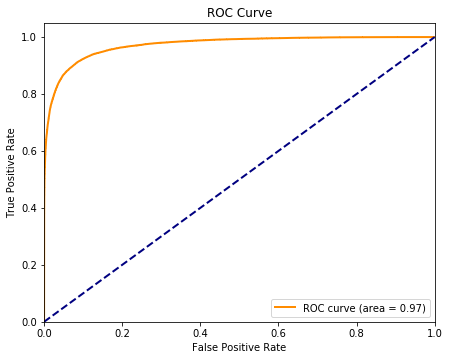
模型評估
最后隨機森林分類器在保證未出現(xiàn)過擬合的情況下,ROC曲線面積達到0.97。
客戶價值
接下來,為了進一步挖掘客戶價值,提升用戶體驗,我們運用了RFM客戶價值模型。
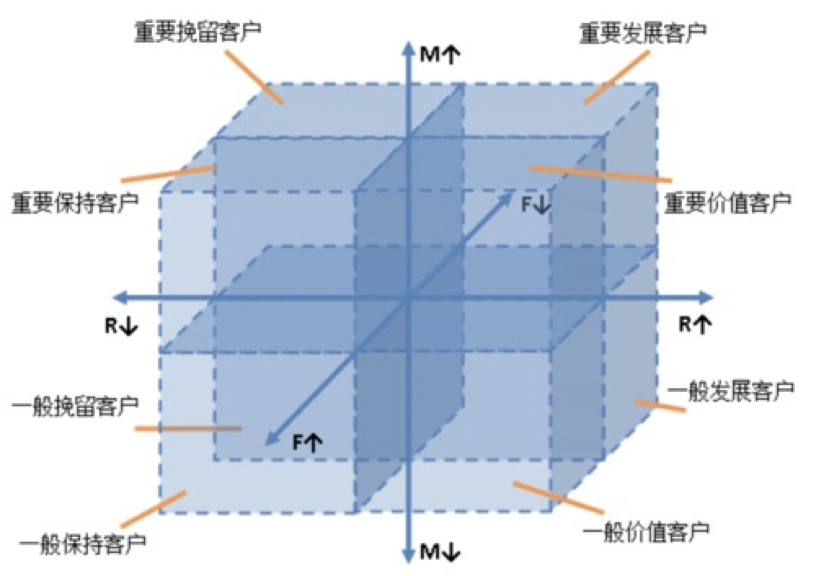
RFM客戶價值模型
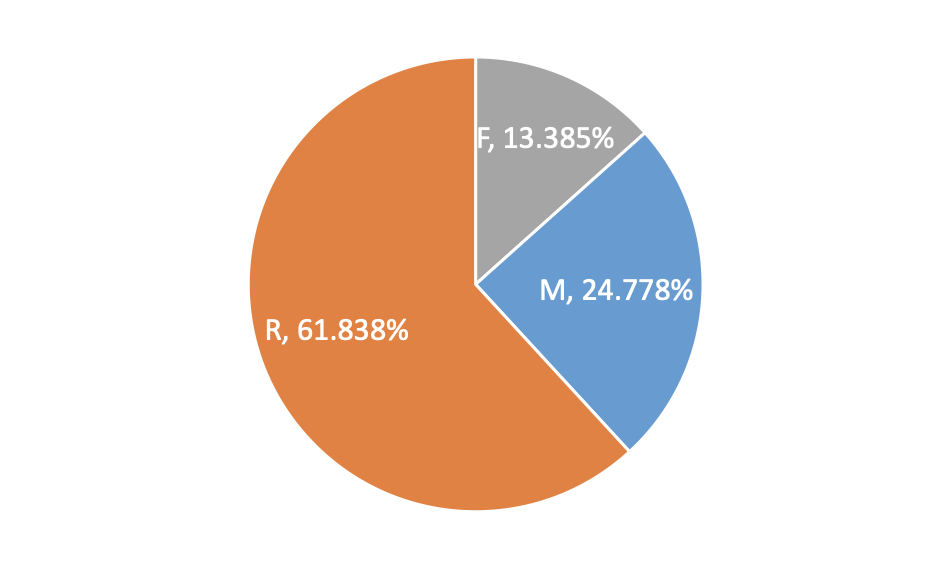
根據(jù)客戶價值模型,我們定義一年內(nèi)距離上次下單時長為R,年訂單量為F,平均價格為M。
客戶價值度用來評估用戶的價值情況,是區(qū)分客戶價值的重要模型和參考依據(jù),也是衡量不同營銷效果的關(guān)鍵指標之一。價值度模型一般基于交易行為產(chǎn)生,衡量的是有實體轉(zhuǎn)化價值的行為。
RFM模型是根據(jù)客戶最近一次購買時間R(Recency)、購買頻率 F(Frequency)、購買金額M(Monetary)計算得出RFM得分,通過這 三個維度來評估客戶的訂單活躍價值,常用來做客戶分群或價值區(qū)分。
RFM模型基于一個固定時間點來做模型分析,因此今天做的RFM得分跟7天前做的結(jié)果可能不一樣,原因是每個客戶在不同的時間節(jié)點所得到的數(shù)據(jù)不同。
得到 RFM 得分后的思路
基于3個維度做用戶群體劃分和解讀,對用戶價值做分析。 基于匯總得分評估所有會員的價值價值,做活躍度排名。 作為維度輸入和其他維度一起做輸入變量,為數(shù)據(jù)挖掘和分析建模提高基礎(chǔ)。
數(shù)據(jù)預(yù)處理
在特征選擇方面,我們在之前的特征基礎(chǔ)上添加了一些我們認為與客戶價值有關(guān)的變量。對特征進行缺失值分析得到:

同樣對數(shù)據(jù)進行深入探索,因為本次價值模型無需劃分測試集和訓(xùn)練集,又數(shù)據(jù)量足夠多,因此我們直接將有缺失值的記錄刪除。
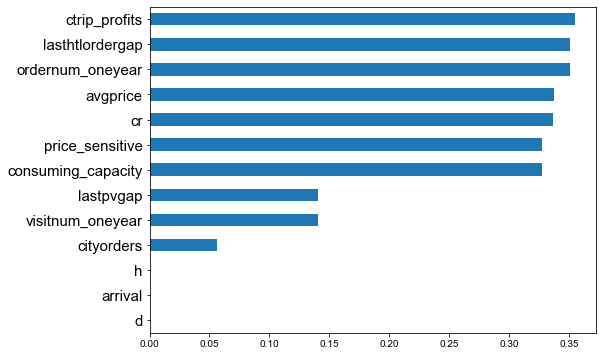
價值模型
以客戶轉(zhuǎn)化率做目標變量,利用隨機森林回歸模型計算出各價值指標權(quán)重,然后分布計算出每個用戶的RFM得分,分別以權(quán)重加和,及標簽組合來表示價值得分。本次RFM模型構(gòu)建方法僅供參考!
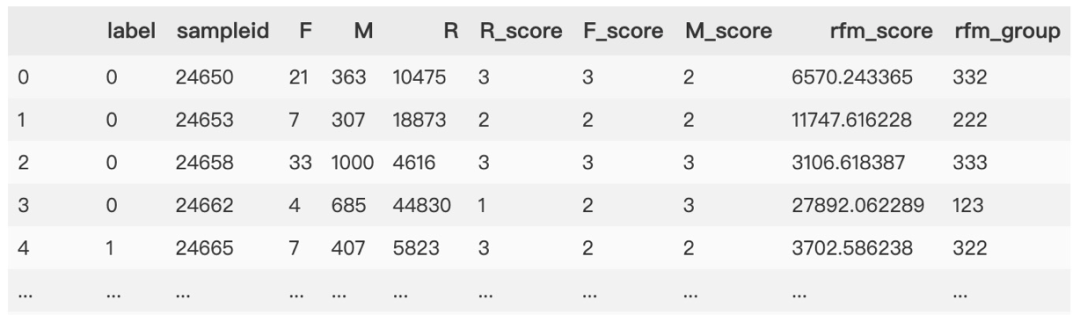
另外,為了體現(xiàn)流失客戶及留存客戶優(yōu)勢比,參照最優(yōu)分箱公式,創(chuàng)造了一個類別,以-1表示。其計算方法是:
第一步:以RFM分群和標簽聚合,分別對客戶id計數(shù),以及RFM得分求和
groupby(['rfm\_group','label'])
第二步:對留存和流失客戶求差。就是用不同類別的個數(shù)總和求差,乘以 RFM得分總和求差取對數(shù)
groupby(['rfm\_group','label'])
當(dāng)然,這里是我參數(shù)優(yōu)勢比的原理創(chuàng)造的計算公式,其實用價值及是否合理,還需跟業(yè)務(wù)結(jié)合。這里僅作參考。
number(-1) = (number_0 -number_1)\*log(sum(rfm_score)_0/sum(rfm_score)_1)
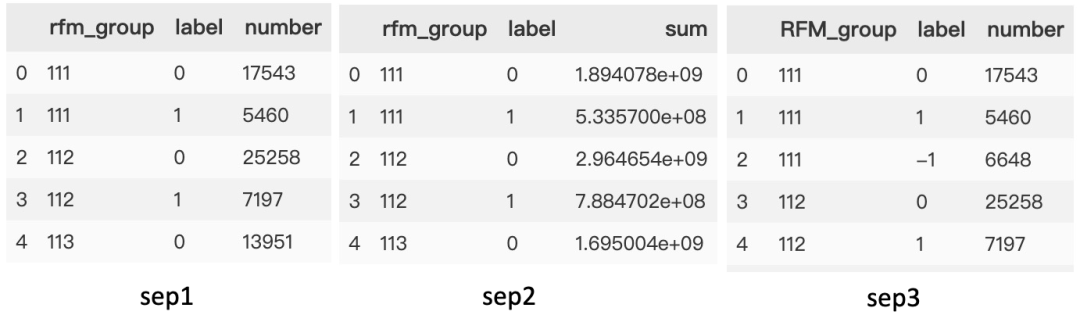
可視化價值模型
標簽 0 是留存用戶,標簽 1 是流失用戶,標簽 -1 是留存減流失乘以優(yōu)勢比。
# 顯示圖形
bar3d = Bar3D("", width=900, height=600)
range_color = ['#313695', '#4575b4', '#74add1', '#abd9e9', '#e0f3f8', '#ffffbf',
'#fee090', '#fdae61', '#f46d43', '#d73027', '#a50026']
bar3d.add(
"rfm分組結(jié)果", "", "",
[d.tolist() for d in data_display.values],
is_visualmap=True,
visual_range=[0, data_display['number'].max()],
visual_range_color=range_color,
grid3d_width=200,
grid3d_height=80,
grid3d_depth=80
)
bar3d我們可以看到在以R就是一年內(nèi)距離上次下單時長為軸,其兩端留存和流失客戶均很多,且 R 等于 1 就是距離時間越久,客戶流失就越少,與我們用WOE分箱分析結(jié)果一致。
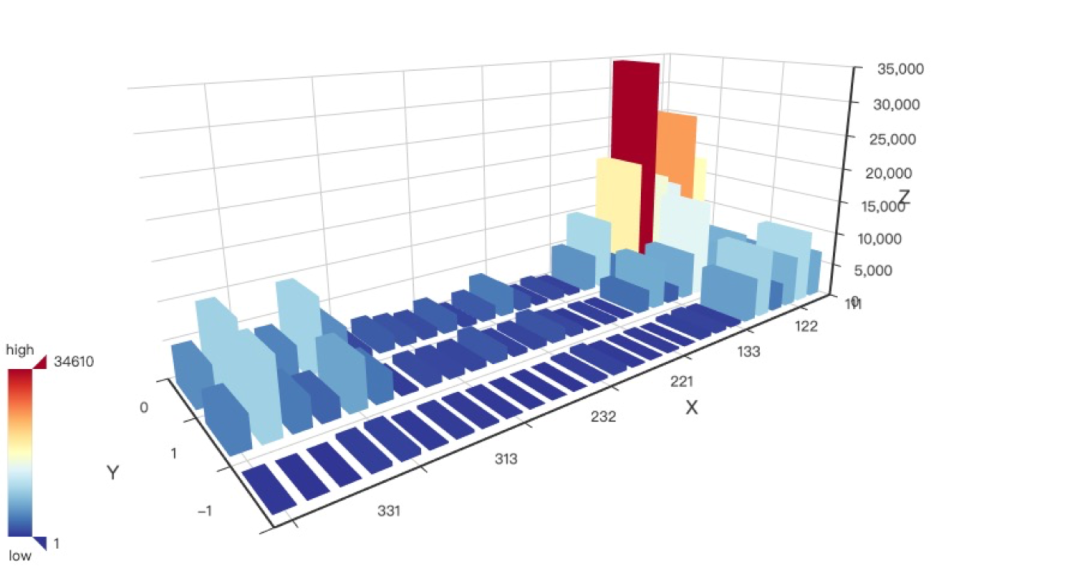
客戶轉(zhuǎn)化預(yù)測
由上面分析報告可知,影響客戶流失的兩大因素:
用戶轉(zhuǎn)化率 一年內(nèi)距離上次下單時長
因此我們以客戶轉(zhuǎn)化率為目標標簽,進行進一步預(yù)測分析。
數(shù)據(jù)處理與特征創(chuàng)造與選擇
數(shù)據(jù)處理特征創(chuàng)造等類同于前面步驟,在這里就不贅述了。
在缺失值處理方面不同的是,我們直接將 cr 缺失的記錄直接刪除了,這樣處理的原因是,一是剩余數(shù)據(jù)量較多,足夠隨機森林預(yù)測。二是隨機森林以后實用袋外數(shù)據(jù)進行模型評估。
以連續(xù)特征 cr 客戶轉(zhuǎn)化率作為目標標簽,利用隨機森林回歸器輸出特征重要性來選擇出使得模型分數(shù)最高的那幾個特征。本次選擇出了13個對模型貢獻度較大特征。
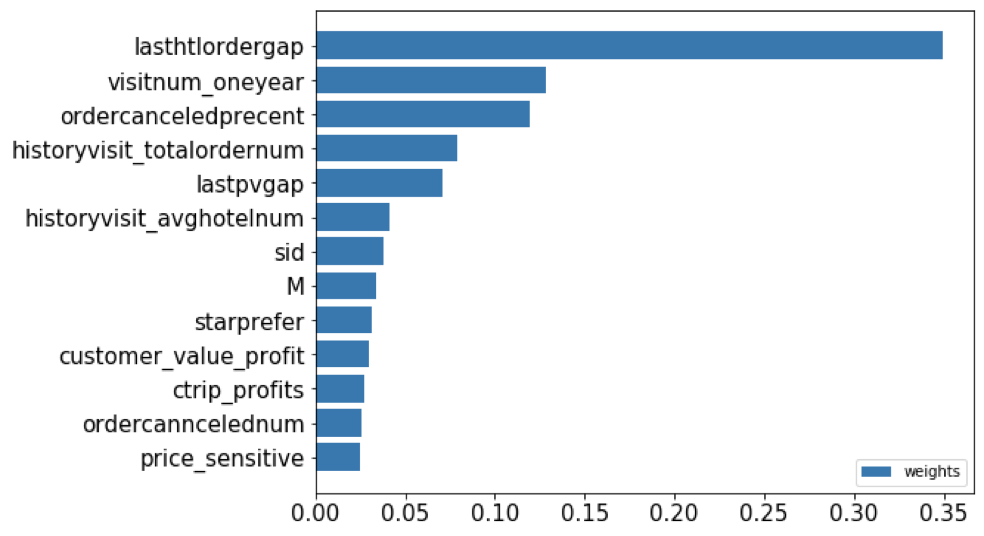
我可以看到排名第一的仍然是一年內(nèi)距離上次下單時間對用戶轉(zhuǎn)化率的影響最高。
相比對客戶流失影響的特征,多了歷史訂單數(shù),歷史取消訂單數(shù)及星級偏好,客戶價值等。
模型訓(xùn)練與調(diào)參數(shù)
運用網(wǎng)格搜索方法對隨機森林分類器進行調(diào)參,得到最佳參數(shù):(這里注意調(diào)參時間較長,小伙伴們可以嘗試運用貝葉斯優(yōu)化調(diào)參方法)
model = RFR(n_estimators=180
,max_depth=25
,min_samples_leaf=1
,min_samples_split=2
,random_state=0
)
因此得到該模型,在測試集預(yù)測得分92.26%。最后可以保存模型以供模型部署使用。
項目總結(jié)
我們使用了邏輯回歸模型和客戶價值模型對客戶流失進行深入挖掘,找出了影響客戶流失的關(guān)鍵因素:
用戶轉(zhuǎn)化率——用戶轉(zhuǎn)化率大時,流失用戶占比反而在逐漸增大。
一年內(nèi)距上次下單時長——一年內(nèi)距上次下單時長在(2.5,1327)區(qū)間內(nèi)最容易流失,但時間越久的,約容易留存。
訪問時間點——白天訪問轉(zhuǎn)化率低,晚上7點后訪問客戶更易轉(zhuǎn)化。
昨日提交當(dāng)前城市同入住app 訂單數(shù) —— 訂單數(shù)越大,客戶流失風(fēng)險越大, 但在(2.25,2.294)區(qū)間內(nèi)轉(zhuǎn)化結(jié)果最好。
創(chuàng)造的特征M,delta
M客戶年花費越大,流失風(fēng)險越大。delta隨著訪問日期與入住日期距離越近,客戶更易流失,也就是沒怎么訪問就入住的酒店,相比而言,在入住之前就有關(guān)注酒店的客戶,黏性就越大。
用戶畫像
我們總結(jié)出易流失人群和留存客戶人群特征,對客戶進行一個簡單的畫像。針對易流失人群,推薦具體業(yè)務(wù)可以從三個維度將本次分析結(jié)果落地。
時間維度,如訪問時間維度,下單間隔維度 數(shù)量維度,如訪問量,訂單量等 價格維度,價格敏感度,客戶年消費金額等
易留存人群特征
一年內(nèi)距上次下單時長在(1,1.075)區(qū)間
用戶轉(zhuǎn)化率在( 1,1.075 )區(qū)間
訪問時間在晚上
訂單數(shù)在2.294以下
年訪問次數(shù)超過15003
年消費越小
入住日期與訪問日期間隔越長
易流失人群特征
一年內(nèi)距上次下單時長在(2.5,1327)區(qū)間
用戶轉(zhuǎn)化率在(1.505,1.925)區(qū)間
訪問時間在上午
App訂單數(shù)在2.61以上
年訪問次數(shù)在小于15000
年消費越大
入住日期與訪問日期間隔越短
附錄如何選擇算法
如何選擇聚類算法
如果數(shù)據(jù)集是高維的 —— 譜聚類,它是子空間劃分的一種。 如果數(shù)據(jù)是中小規(guī)模: 100萬以內(nèi) —— K_Means 100萬以上 —— MiniBatchKMeans(每類抽取一部分樣本聚類,精度下降,速度提高) 數(shù)據(jù)集中有噪聲(離群點) —— 基于密度的帶有噪聲的 DBSCAN 。 如果追求更高的分類準確性,選擇譜聚類比K_Means準確性更好。
如何選擇回歸分析算法
數(shù)據(jù)集本身結(jié)構(gòu)簡單、分布規(guī)律有明顯線性關(guān)系——簡單線性回歸,基于最小二乘法的普通線性回歸。 自變量數(shù)量少或降維后得到了二維變量(包括預(yù)測變量)——直接使用散點圖,發(fā)現(xiàn)自變量和因變量之間的相互關(guān)系,然后再選擇最佳回歸方法 自變量間有較強共線性關(guān)系——嶺回歸,L2正則化,對多重共線性靈活處理的方法 如果噪聲較多——推薦主成分回歸,通過對參與回歸的主成分的合理選擇,可以去掉噪聲;各個主成分相互正交,解決多元回歸共線性問題。 高維度變量下——正則化回歸方法,Lasso、Ridge、ElasticNet。降維、逐步回歸 可使用交叉驗證做多個模型的效果對比,驗證多個算法 注重模型的可解釋性—— 線性回歸、邏輯回歸、對數(shù)回歸、二項式或多項式回歸 集成或組合方法——加權(quán)、均值等方法確定最終輸出結(jié)果(一旦確認來多個方法,又不確定取舍)
如何選擇分類分析算法
文本文類——樸素貝葉斯 訓(xùn)練集較小——樸素貝葉斯、支持向量機,高偏差低方差低分類算法,不容易過擬合 訓(xùn)練集較大——基本都適用 關(guān)注模型等計算時間和模型易用性——不用支持向量機和人工神經(jīng)網(wǎng)絡(luò) 重視算法準確性——支持向量機、GBDT、XGBoost、Adaboost等基于Boosting等集成方法 重視算法穩(wěn)定性或模型魯棒性——隨機森林、組合投票模型等基于Bagging的集成方法 預(yù)得到預(yù)測結(jié)果的概率信息,基于預(yù)測概率做進一步應(yīng)用——邏輯回歸 擔(dān)心離群點或數(shù)據(jù)不可分并且需要清晰的決策規(guī)則——決策樹
如此干貨,點贊支持。
--END--
掃碼即可加我微信
觀看朋友圈,獲取最新學(xué)習(xí)資源
簡說Python 投稿規(guī)則及激勵
規(guī)則:必須是自己的原創(chuàng)文章,和Python相關(guān)技術(shù)文章,形式不限制(文字、圖文、漫畫等),字數(shù)800+,在微信公眾號首發(fā)。
激勵
根據(jù)文章內(nèi)容 字數(shù) 分為兩種基礎(chǔ)和深度
基礎(chǔ)文章:每投稿兩篇可以獲得技術(shù)相關(guān)圖書一本 從書單里選
深度文章:每1k字50-100元(代碼不算)
額外激勵
文章閱讀量超過2000,激勵50元
文章被同量級大號轉(zhuǎn)載次數(shù)5次及以上,激勵100元
長期投稿作者還有額外激勵,技術(shù)能力可以的,還可以一起做項目,接私活,內(nèi)推等。
學(xué)習(xí)更多: 整理了我開始分享學(xué)習(xí)筆記到現(xiàn)在超過250篇優(yōu)質(zhì)文章,涵蓋數(shù)據(jù)分析、爬蟲、機器學(xué)習(xí)等方面,別再說不知道該從哪開始,實戰(zhàn)哪里找了
“點贊”傳統(tǒng)美德不能丟