
基于opencv提取圖片中的文字
點(diǎn)擊上方“小白學(xué)視覺(jué)”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時(shí)間送達(dá)
本文轉(zhuǎn)自|OpenCV學(xué)堂 TEXT擴(kuò)展模塊概述

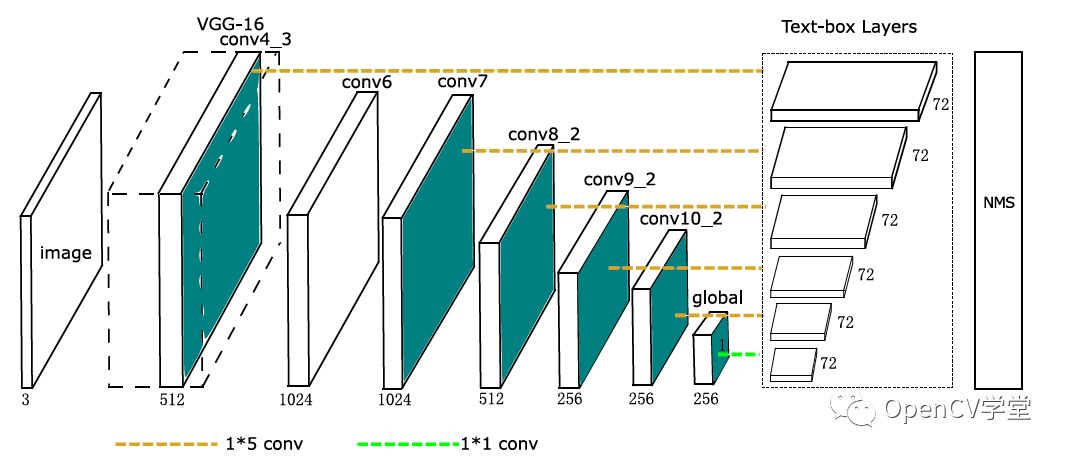
OpenCV在TEXT擴(kuò)展模塊中支持場(chǎng)景文字識(shí)別,最早的場(chǎng)景文字檢測(cè)是基于級(jí)聯(lián)檢測(cè)器實(shí)現(xiàn),OpenCV中早期的場(chǎng)景文字檢測(cè)是基于極值區(qū)域文本定位與識(shí)別、最新的OpenCV3.4.x之后的版本添加了卷積神經(jīng)網(wǎng)絡(luò)實(shí)現(xiàn)場(chǎng)景文字檢測(cè),后者的準(zhǔn)確性與穩(wěn)定性比前者有了很大的改觀,不再是雞肋算法,是可以應(yīng)用到實(shí)際場(chǎng)景中的。值得一提的是基于CNN實(shí)現(xiàn)場(chǎng)景文字檢測(cè)算法OpenCV中采用了是華中科技大學(xué)貢獻(xiàn)的模型,模型結(jié)構(gòu)如下:
基于極值區(qū)域文本定位的方法實(shí)現(xiàn)場(chǎng)景文字檢測(cè)演示如下:
def cascade_classfier_text_detect():
img = cv.imread("D:/images/cover_01.jpg")
vis = img.copy()
# Extract channels to be processed individually
channels = cv.text.computeNMChannels(img)
cn = len(channels)-1
for c in range(0,cn):
channels.append((255-channels[c]))
# Apply the default cascade classifier to each independent channel (could be done in parallel)
print("Extracting Class Specific Extremal Regions from "+str(len(channels))+" channels ...")
print(" (...) this may take a while (...)")
for channel in channels:
erc1 = cv.text.loadClassifierNM1('trained_classifierNM1.xml')
er1 = cv.text.createERFilterNM1(erc1,16,0.00015,0.13,0.2,True,0.1)
erc2 = cv.text.loadClassifierNM2('trained_classifierNM2.xml')
er2 = cv.text.createERFilterNM2(erc2,0.5)
regions = cv.text.detectRegions(channel,er1,er2)
rects = cv.text.erGrouping(img,channel,[r.tolist() for r in regions])
#Visualization
for r in range(0,np.shape(rects)[0]):
rect = rects[r]
cv.rectangle(vis, (rect[0],rect[1]), (rect[0]+rect[2],rect[1]+rect[3]), (255, 0, 0), 2)
cv.rectangle(vis, (rect[0],rect[1]), (rect[0]+rect[2],rect[1]+rect[3]), (0, 0, 255), 1)
#Visualization
cv.imshow("Text detection result", vis)
cv.imwrite("D:/test_detection_demo_02.png", vis)
cv.waitKey(0)
基于卷積神經(jīng)網(wǎng)絡(luò)模型實(shí)現(xiàn)場(chǎng)景文字檢測(cè)演示如下:
def cnn_text_detect():
image = cv.imread("D:/images/cover_01.jpg")
cv.imshow("input", image)
result = image.copy()
detector = cv.text.TextDetectorCNN_create("textbox.prototxt", "TextBoxes_icdar13.caffemodel")
boxes, scores = detector.detect(image);
threshold = 0.5
for r in range(np.shape(boxes)[0]):
if scores[r] > threshold:
rect = boxes[r]
cv.rectangle(result, (rect[0], rect[1]), (rect[0] + rect[2], rect[1] + rect[3]), (255, 0, 0), 2)
cv.imshow("Text detection result", result)
cv.waitKey()
cv.waitKey(0)
cv.destroyAllWindows()
基于極值區(qū)域文本定位


基于卷積神經(jīng)網(wǎng)絡(luò)檢測(cè)

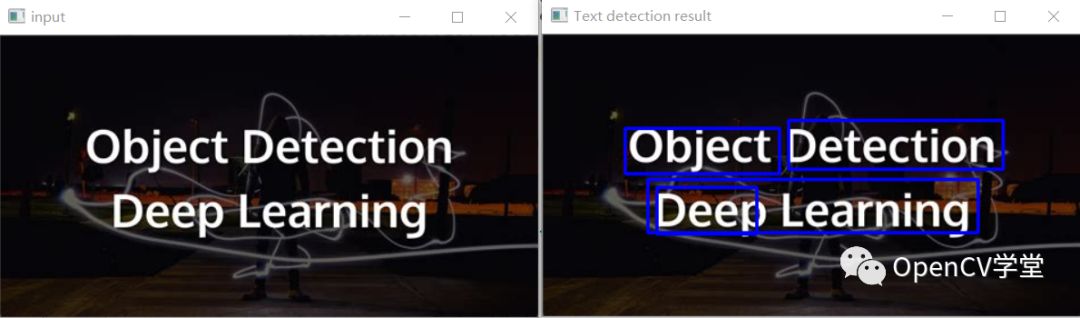
對(duì)比發(fā)現(xiàn),明顯基于卷積神經(jīng)網(wǎng)絡(luò)的方法更加的靠譜!所以請(qǐng)使用TEXT模塊中的卷積神經(jīng)網(wǎng)絡(luò)實(shí)現(xiàn)場(chǎng)景文字檢測(cè)。
好消息,小白學(xué)視覺(jué)團(tuán)隊(duì)的知識(shí)星球開(kāi)通啦,為了感謝大家的支持與厚愛(ài),團(tuán)隊(duì)決定將價(jià)值149元的知識(shí)星球現(xiàn)時(shí)免費(fèi)加入。各位小伙伴們要抓住機(jī)會(huì)哦!

交流群
歡迎加入公眾號(hào)讀者群一起和同行交流,目前有SLAM、三維視覺(jué)、傳感器、自動(dòng)駕駛、計(jì)算攝影、檢測(cè)、分割、識(shí)別、醫(yī)學(xué)影像、GAN、算法競(jìng)賽等微信群(以后會(huì)逐漸細(xì)分),請(qǐng)掃描下面微信號(hào)加群,備注:”昵稱+學(xué)校/公司+研究方向“,例如:”張三 + 上海交大 + 視覺(jué)SLAM“。請(qǐng)按照格式備注,否則不予通過(guò)。添加成功后會(huì)根據(jù)研究方向邀請(qǐng)進(jìn)入相關(guān)微信群。請(qǐng)勿在群內(nèi)發(fā)送廣告,否則會(huì)請(qǐng)出群,謝謝理解~