
如何 提取圖片中的文字?這款Python 庫(kù) 4行代碼搞定!

來源? |?Python大數(shù)據(jù)分析
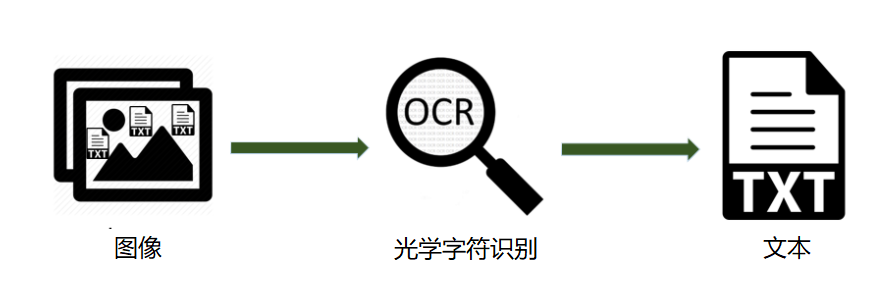
OCR是什么?
有一款軟件叫掃描全能王,想必一些小伙伴聽過,這是一個(gè)OCR集成軟件,可以將圖像內(nèi)容掃描成文字。
所以說,OCR作用是對(duì)文本資料的圖像文件進(jìn)行分析識(shí)別處理,獲取文字及版面信息。
OCR的全稱叫作“Optical Character Recognition”,即光學(xué)字符識(shí)別。
這算是生活里最常見、最有用的AI應(yīng)用技術(shù)之一。
細(xì)心觀察便可發(fā)現(xiàn),身邊到處都是OCR的身影,文檔掃描、車牌識(shí)別、證件識(shí)別、銀行卡識(shí)別、票據(jù)識(shí)別等等。
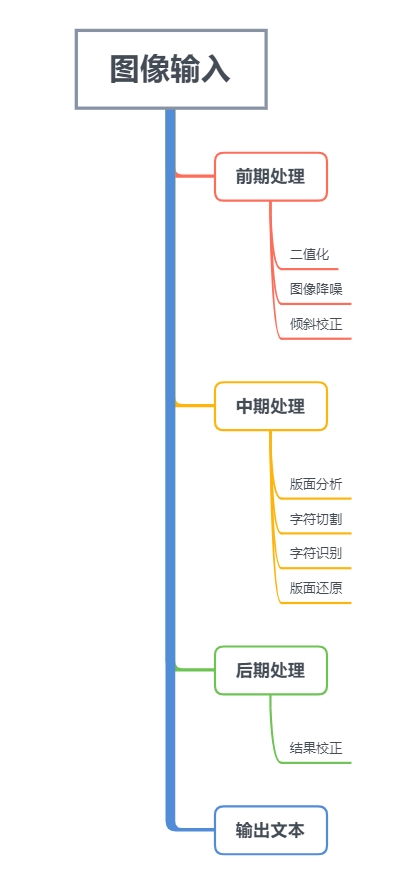
OCR本質(zhì)是圖像識(shí)別,其包含兩大關(guān)鍵技術(shù):文本檢測(cè)和文字識(shí)別。
先將圖像中的特征的提取并檢測(cè)目標(biāo)區(qū)域,之后對(duì)目標(biāo)區(qū)域的的字符進(jìn)行分割和分類。
關(guān)于EasyOCR
Python中有一個(gè)不錯(cuò)的OCR庫(kù)-EasyOCR,在GitHub已有9700star。它可以在python中調(diào)用,用來識(shí)別圖像中的文字,并輸出為文本。
?https://github.com/JaidedAI/EasyOCR
?

EasyOCR支持超過80種語(yǔ)言的識(shí)別,包括英語(yǔ)、中文(簡(jiǎn)繁)、阿拉伯文、日文等,并且該庫(kù)在不斷更新中,未來會(huì)支持更多的語(yǔ)言。
安裝EasyOCR
安裝過程比較簡(jiǎn)單,使用pip或者conda安裝。
pip?install?easyocr
如果用的PyPl源,安裝起來可能會(huì)耽誤些時(shí)間,建議大家用清華源安裝,幾十秒就能安裝好。
使用方法
EasyOCR的用法非常簡(jiǎn)單,分為三步:
1.創(chuàng)建識(shí)別對(duì)象; 2.讀取并識(shí)別圖像; 3.導(dǎo)出文本。
我們先來舉個(gè)簡(jiǎn)單的例子。
找一張路標(biāo)圖片,保存到電腦:
接著擼代碼:
#?導(dǎo)入easyocr
import?easyocr
#?創(chuàng)建reader對(duì)象
reader?=?easyocr.Reader(['ch_sim','en'])?
#?讀取圖像
result?=?reader.readtext('test.jpg')
#?結(jié)果
result
輸出結(jié)果: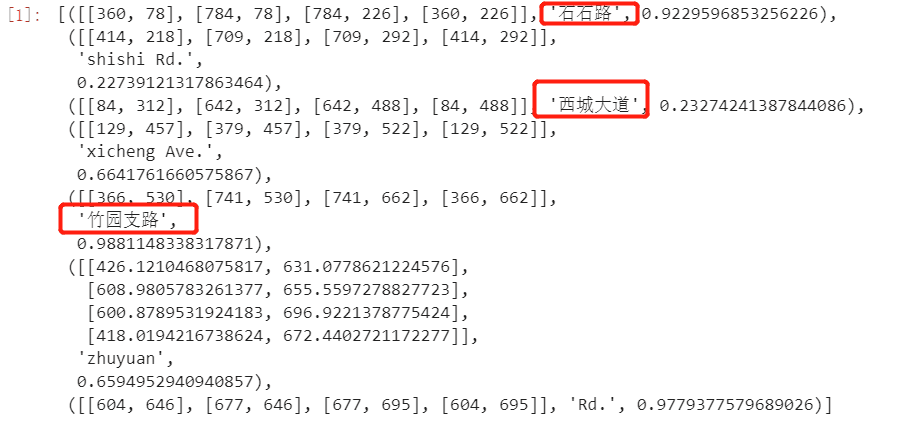
可以看到路標(biāo)上的三個(gè)路名以及拼音都識(shí)別出來了!
識(shí)別的結(jié)果包含在元組里,元組由三部分組成:邊框坐標(biāo)、文本、識(shí)別概率。
「關(guān)于語(yǔ)言:」
這段代碼有一段參數(shù)['ch_sim','en'],這是要識(shí)別的語(yǔ)言列表,因?yàn)槁放评镉兄形暮陀⑽模粤斜砝锾砑恿薱h_sim(簡(jiǎn)體中文)、en(英文)。
可以一次傳遞多種語(yǔ)言,但并非所有語(yǔ)言都可以一起使用。英語(yǔ)與每種語(yǔ)言兼容,共享公共字符的語(yǔ)言通常相互兼容。
前文我們給出了EasyOCR支持的語(yǔ)言列表,并附有參數(shù)代號(hào)。
「關(guān)于圖像文件:」
上面?zhèn)魅肓讼鄬?duì)路徑'test.jpg',還可以傳遞OpenCV圖像對(duì)象(numpy數(shù)組)、圖像字節(jié)文件、圖像URL。
再讀取一張文字較多的新聞稿圖片:
#?導(dǎo)入easyocr
import?easyocr
#?創(chuàng)建reader對(duì)象
reader?=?easyocr.Reader(['ch_sim','en'])?
#?讀取圖像
result?=?reader.readtext('test1.jpg')
#?結(jié)果
result

識(shí)別文字的準(zhǔn)確率還是很高的,接下來對(duì)文字部分進(jìn)行抽取。
for?i?in?result:
????word?=?i[1]
????print(word)
輸出:
小結(jié)
該開源庫(kù)是作者研究了幾篇論文,復(fù)現(xiàn)出來的成果,真是一位實(shí)干家。
檢測(cè)部分使用了CRAFT算法,識(shí)別模型為CRNN,它由3個(gè)主要組件組成:特征提取,序列標(biāo)記(LSTM)和解碼(CTC)。整個(gè)深度學(xué)習(xí)過程基于Pytorch實(shí)現(xiàn)。
作者一直在完善EasyOCR,后續(xù)計(jì)劃一方面擴(kuò)展支持更多的語(yǔ)言,爭(zhēng)取覆蓋全球80%~90%的人口;另一方面支持手寫識(shí)別,并提高處理速度。