
大道至簡!深度解讀CVPR2021論文RepVGG!
 點(diǎn)藍(lán)色字關(guān)注“機(jī)器學(xué)習(xí)算法工程師”
點(diǎn)藍(lán)色字關(guān)注“機(jī)器學(xué)習(xí)算法工程師”
設(shè)為星標(biāo),干貨直達(dá)!
AI編輯:我是小將
本文作者:Jack Chen
https://zhuanlan.zhihu.com/p/353697121
本文已由原作者授權(quán)轉(zhuǎn)載
前 言:
repVGG絕對可以算得上2020年在backbone方面有很大影響力的工作,其核心思想是:通過結(jié)構(gòu)重參數(shù)化思想,讓訓(xùn)練網(wǎng)絡(luò)的多路結(jié)構(gòu)(多分支模型訓(xùn)練時(shí)的優(yōu)勢——性能高)轉(zhuǎn)換為推理網(wǎng)絡(luò)的單路結(jié)構(gòu)(模型推理時(shí)的好處——速度快、省內(nèi)存)),結(jié)構(gòu)中均為3x3的卷積核,同時(shí),計(jì)算庫(如CuDNN,Intel MKL)和硬件針對3x3卷積有深度的優(yōu)化,最終可以使網(wǎng)絡(luò)有著高效的推理速率(其實(shí)TensorRT在構(gòu)建engine階段,對模型進(jìn)行重構(gòu),底層也是應(yīng)用了卷積合并,多分支融合思想,來使得模型最終有著高性能的推理速率)。
背 景:
早起我們在設(shè)計(jì)網(wǎng)絡(luò)時(shí),為了獲得高性能網(wǎng)絡(luò)結(jié)構(gòu),不斷進(jìn)行嘗試和摸索之后,得到了以下可以顯著增長網(wǎng)絡(luò)性能的結(jié)構(gòu):
(1)多分支結(jié)構(gòu):第一次出現(xiàn)多分支結(jié)構(gòu)應(yīng)該是在Inception中(如果不是,請各位指正),就獲得了高性能收益,加上不同分支應(yīng)用不同卷積核,能獲得不同感受野,后續(xù)出現(xiàn)的ResNet,其殘差結(jié)構(gòu)也是多路結(jié)構(gòu)。但是需要注意的是:多路結(jié)構(gòu)需要保存中間結(jié)果,顯存占有量會(huì)明顯增高,只有到多路融合時(shí),顯存會(huì)會(huì)降低。這里如下圖所示:
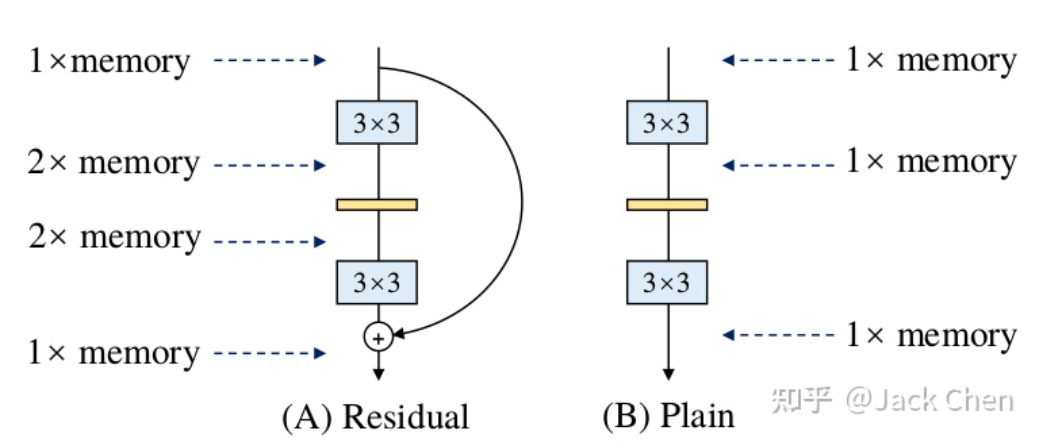
同時(shí),由ShuffleNet論文中提到的網(wǎng)絡(luò)高效推理法則:模型分支越少,速度越快。所以,可想而知,多分支結(jié)果雖然會(huì)帶來高性能收益,但是,顯存占用明顯增加,且模型推理速度會(huì)一定程度降低,這在工業(yè)場景上是不實(shí)用的。
(2)性能優(yōu)異組件:隨著不斷嘗試于探索,出現(xiàn)了很多性能優(yōu)異的網(wǎng)絡(luò)組件,比如深度可分離卷積,分組卷積等等,這些都可以顯著增加網(wǎng)絡(luò)性能,但是,我們也知道,就拿group conv來說,當(dāng)group越多是,我們知道網(wǎng)絡(luò)性能會(huì)越好,但是,其MAC(內(nèi)存訪問成本)也會(huì)顯著增大,最終導(dǎo)致模型變慢,深度可分離卷積雖然可以顯著降低FLOPs,但是其MAC也會(huì)增加,最終導(dǎo)致模型速度變慢。
這就引發(fā)了一個(gè)矛盾,既然多分支結(jié)構(gòu)和性能優(yōu)異的組件能顯著提高模型性能,但是,又會(huì)最終導(dǎo)致模型在推理時(shí)速度變慢且還非常耗內(nèi)存,這非常不利于工業(yè)場景(尤其實(shí)在算力受限的情況下)。這種問題該怎么解決呢?
方案:
想要使網(wǎng)絡(luò)具有高性能,又要有高效推理速度,怎么才能解決這個(gè)問題?repVGG給了我們答案:結(jié)構(gòu)重參數(shù)化思想,也即訓(xùn)練時(shí)盡量用多分支結(jié)構(gòu)來提升網(wǎng)絡(luò)性能,而推理時(shí),采用利用結(jié)構(gòu)重參數(shù)化思想,將其變?yōu)閱温方Y(jié)構(gòu),這樣,顯存占用少,推理速度又快。
backbone:
作者最終選擇將VGG作為backbone,這里為什么要選擇這么古董的玩意兒呢,而不是選擇現(xiàn)在主流的ResNet架構(gòu)?主要是基于以下三點(diǎn)考慮:
1. 速度快:
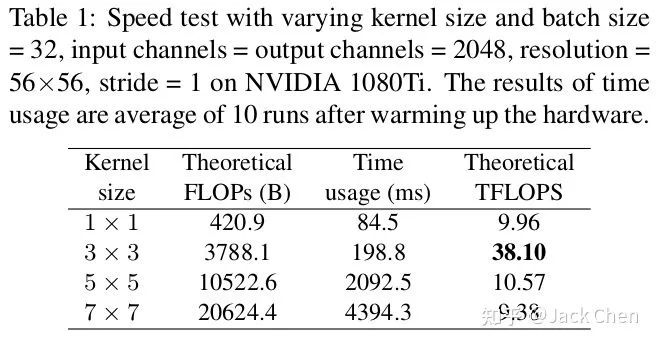
我們都知道,VGG幾乎都是由3x3卷積堆疊而成,而現(xiàn)在加速庫比如NVIDIA的cudNN,Intel的MKL和相關(guān)硬件對3x3的卷積核有非常好的性能優(yōu)化,而在VGG中,幾乎都是conv3x3。因此,利用現(xiàn)有加速庫,會(huì)得到更好的性能優(yōu)化,從下表就就可以看出,在相同channels、input_size和batchsize條件下,不同卷積核的FLOPs和TFLOPs和用時(shí),可以看出,3x3卷積非常快。在GPU上,3x3卷積的計(jì)算密度(理論運(yùn)算量(Theoretical FLOPs ÷ Time usage)除以所用時(shí)間)可達(dá)1x1和5x5卷積的4倍。
2. 節(jié)省內(nèi)存:
VGG是一個(gè)直筒性單路結(jié)構(gòu),由上述分析可知,單路結(jié)構(gòu)會(huì)占有更少的內(nèi)存,因?yàn)椴恍枰4嫫渲虚g結(jié)果,同時(shí),單路架構(gòu)非常快,因?yàn)?span style="font-weight: 600;">并行度高。同樣的計(jì)算量,大而整的運(yùn)算效率遠(yuǎn)超小而碎的運(yùn)算。
3. 靈活性好:
多分支結(jié)構(gòu)會(huì)引入網(wǎng)絡(luò)結(jié)構(gòu)的約束,比如Resnet的殘差結(jié)構(gòu)要求輸入和卷積出來的張量維度要一致(這樣才能相加),這種約束導(dǎo)致網(wǎng)絡(luò)不易延伸拓展,也一定程度限制了通道剪枝。對應(yīng)的單路結(jié)構(gòu)就比較友好,非常容易改變各層的寬度,這樣剪枝后也能得到很好的加速比。
RepVGG主體部分只有一種算子: conv3x3+ReLU。在設(shè)計(jì)專用芯片時(shí),給定芯片尺寸或造價(jià),我們可以集成海量的3x3卷積-ReLU計(jì)算單元來達(dá)到很高的效率。別忘了,單路架構(gòu)省內(nèi)存的特性也可以幫我們少做存儲(chǔ)單元。
綜上所述,我們提出regVGG結(jié)構(gòu),如下圖所示:
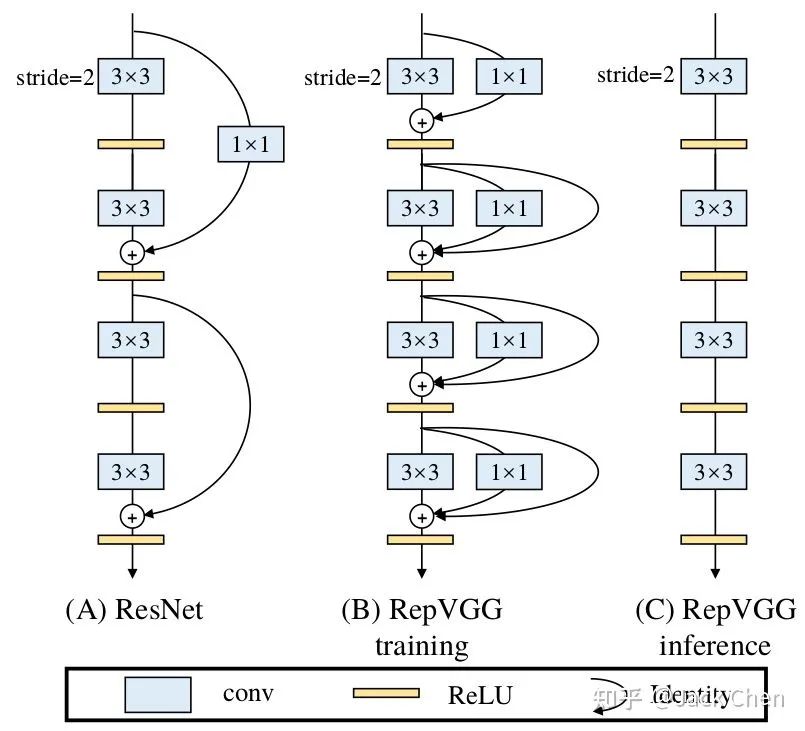
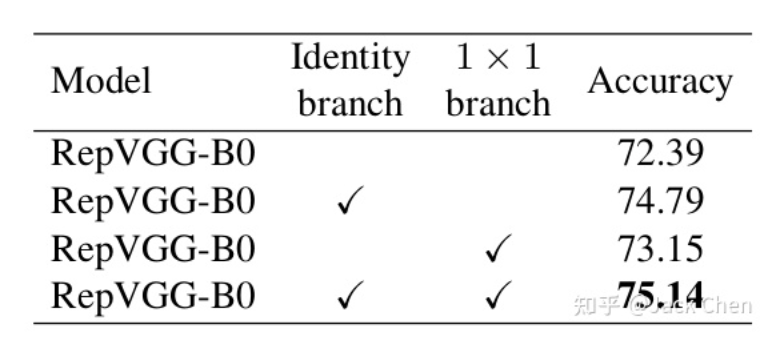
可以看到,我們在原始VGG基礎(chǔ)上,引入和殘差分支和1x1卷積分支,為了后續(xù)重參數(shù)化成單路結(jié)構(gòu),我們調(diào)整了分支放置的位置,沒有進(jìn)行跨層連接,而是直接連了過去,后續(xù)的對比試驗(yàn)也證明了殘差分支和conv_1x1均能增加網(wǎng)絡(luò)性能,如下圖所示:
多路模型(train)轉(zhuǎn)換單路模型(test)
網(wǎng)絡(luò)在訓(xùn)練完畢后,怎樣將多路模型轉(zhuǎn)化為單路模型,最終部署到終端,這應(yīng)該是本文的核心,如下圖所示:
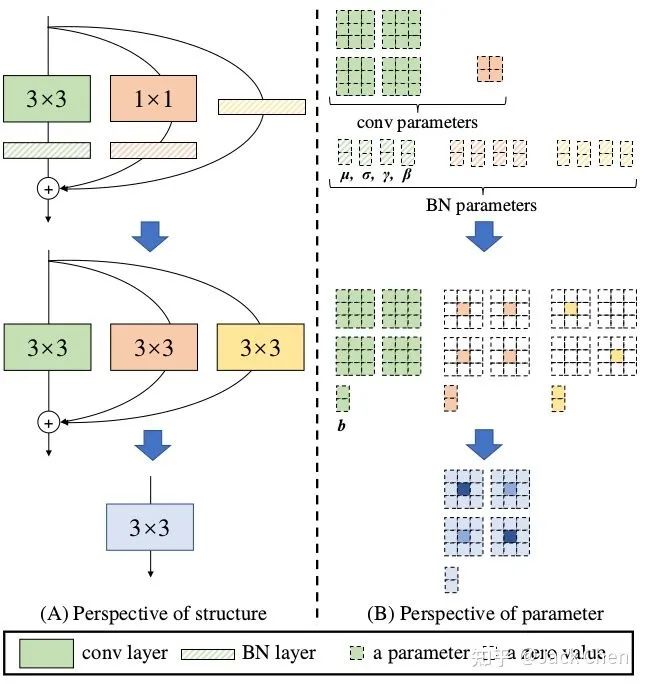
上述過程就是將train好的multi_path model 轉(zhuǎn)換為single_path model,從而最終在推理時(shí)達(dá)到高性能。上面訓(xùn)練過程用到的模型涉及到三路:常規(guī)的conv_3x3,conv_1x1,identity,且這三路每一路都跟著BN層,下面仔細(xì)講解這三路是怎樣合并成一個(gè)conv_3x3單元的。
1. 卷積層和BN層合并:
repVGG中大量運(yùn)用conv+BN層,我們知道將層合并,減少層數(shù)能提升網(wǎng)絡(luò)性能,下面的推理是conv帶有bias的過程:

這其實(shí)就是一個(gè)卷積層,只不過權(quán)重考慮了BN的參數(shù) 我們令:

最終的融合結(jié)果即為:
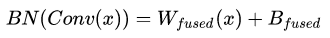
相關(guān)融合代碼如下圖所示:
def _fuse_bn_tensor(self, branch):
if branch is None:
return 0, 0
if isinstance(branch, nn.Sequential):
kernel = branch.conv.weight
running_mean = branch.bn.running_mean
running_var = branch.bn.running_var
gamma = branch.bn.weight
beta = branch.bn.bias
eps = branch.bn.eps
else:
...
std = (running_var + eps).sqrt()
t = (gamma / std).reshape(-1, 1, 1, 1)
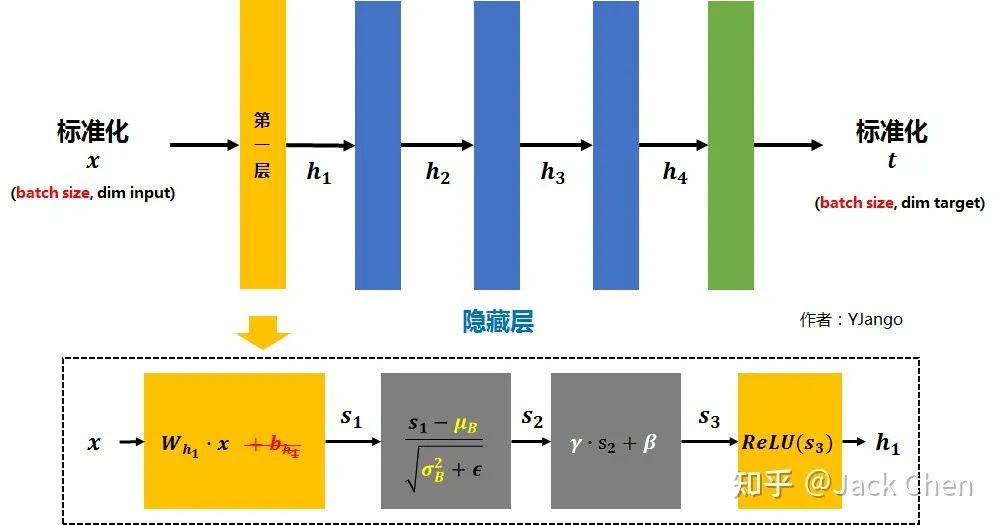
return kernel * t, beta - running_mean * gamma / std上述融合過程是conv帶有bias的,現(xiàn)在一般帶有BN的conv幾乎已經(jīng)不帶bias了,已經(jīng)將其與BN層中的β進(jìn)行合并,帶有BN層的conv+bn計(jì)算過程如下圖所示:
2. conv_3x3和conv_1x1合并
這里為了詳細(xì)說明下,假設(shè)輸入特征圖特征圖尺寸為(1, 2, 3, 3),輸出特征圖尺寸與輸入特征圖尺寸相同,且stride=1,下面展示是conv_3x3的卷及過程:
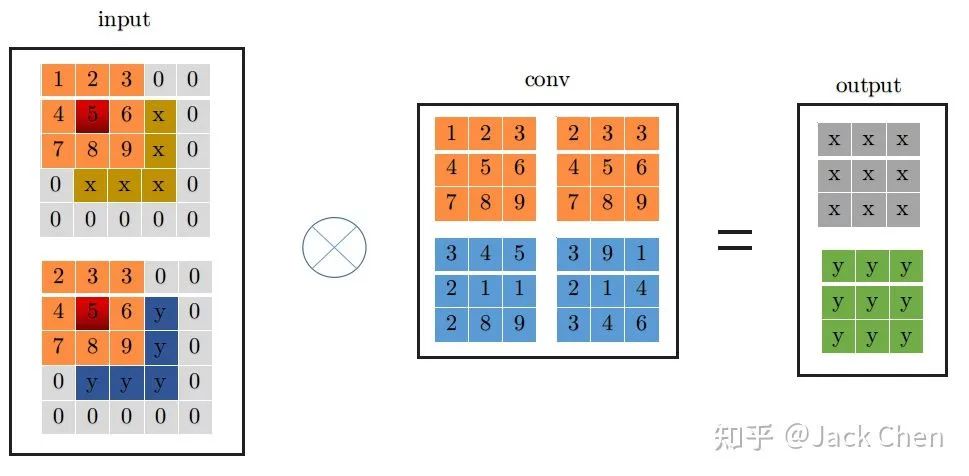
conv_3x3卷積過程大家都很熟悉,看上圖一目了然,首先將特征圖進(jìn)行pad=kernel_size//2,然后從左上角開始(上圖中紅色位置)做卷積運(yùn)算,最終得到右邊output輸出。下面是conv_1x1卷積過程:
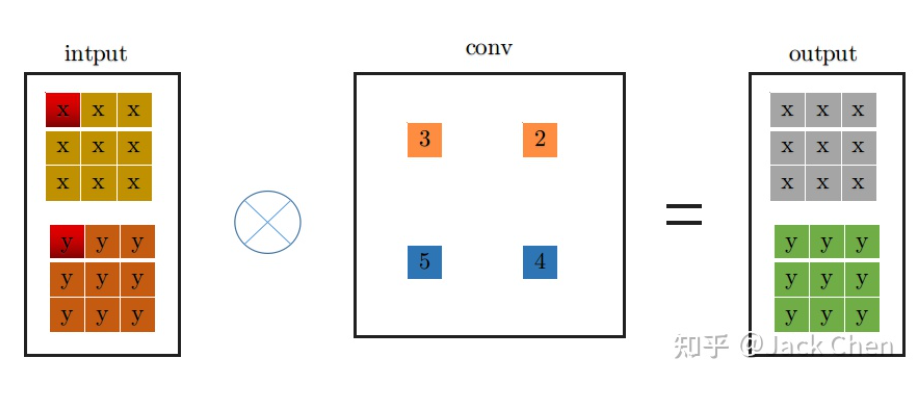
同理,conv_1x1跟conv_3x3卷積過程一樣,從上圖中左邊input中紅色位置開始進(jìn)行卷積,得到右邊的輸出,觀察conv_1x1和conv_3x3的卷積過程,可以發(fā)現(xiàn)他們都是從input中紅色起點(diǎn)位置開始,走過相同的路徑,因此,將conv_3x3和conv_1x1進(jìn)行融合,只需要將conv_1x1卷積核padding成conv_3x3的形式,然后于conv_3x3相加,再與特征圖做卷積(這里依據(jù)卷積的可加性原理)即可,也就是conv_1x1的卷積過程變成如下形式:
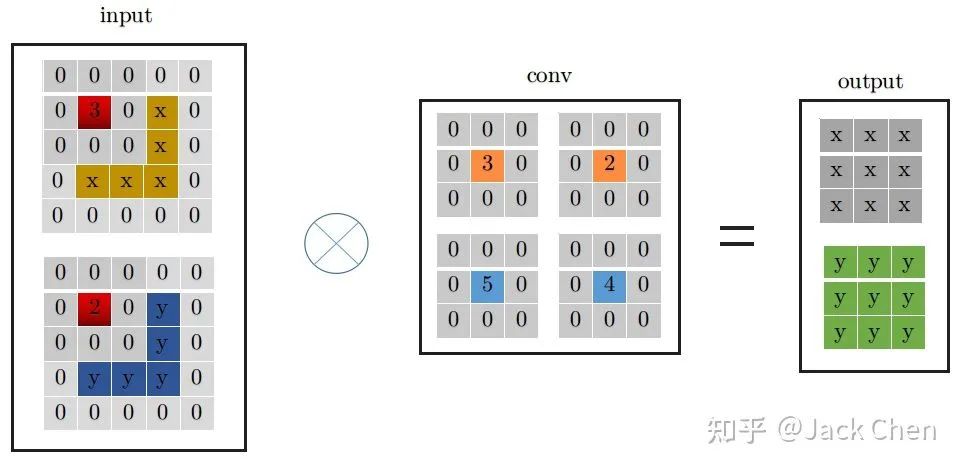
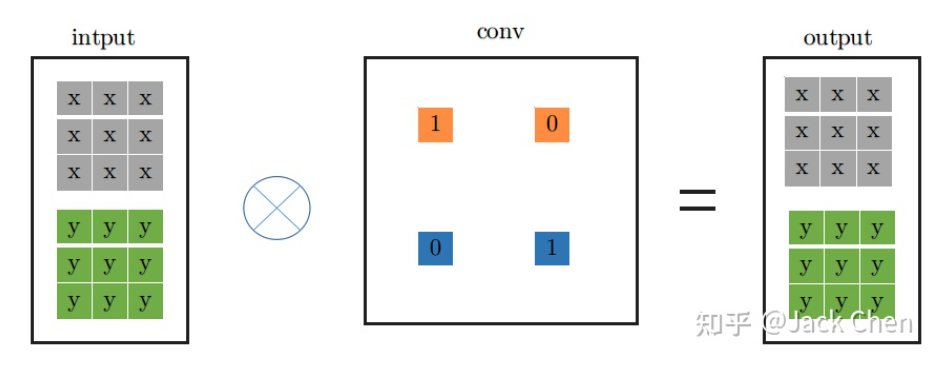
3. identity 等效為特殊權(quán)重的卷積層
identity層就是輸入直接等于輸出,也即input中每個(gè)通道每個(gè)元素直接輸出到output中對應(yīng)的通道,用一個(gè)什么樣的卷積層來等效這個(gè)操作呢,我們知道,卷積操作必須涉及要將每個(gè)通道加起來然后輸出的,然后又要保證input中的每個(gè)通道每個(gè)元素等于output中,從這一點(diǎn),我們可以從PWconv想到,只要令當(dāng)前通道的卷積核參數(shù)為1,其余的卷積核參數(shù)為0,就可以做到;從DWconv中可以想到,用conv_1x1卷積且卷積核權(quán)重為1,就能保證每次卷積不改變輸入,因此,identity可以等效成如下的conv_1x1的卷積形式:
從上面的分析,我們進(jìn)一步可以將indentity -> conv_1x1 -> conv_3x3的形式,如下所示:
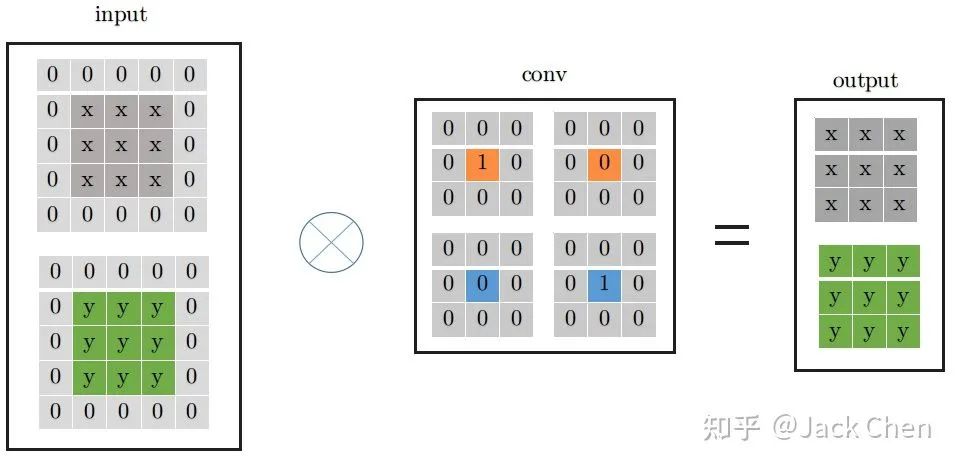
上述過程就是對應(yīng)論文中所屬的下述從step1到step2的變換過程,涉及conv于BN層融合,conv_1x1與identity轉(zhuǎn)化為等價(jià)的conv_3x3的形式:
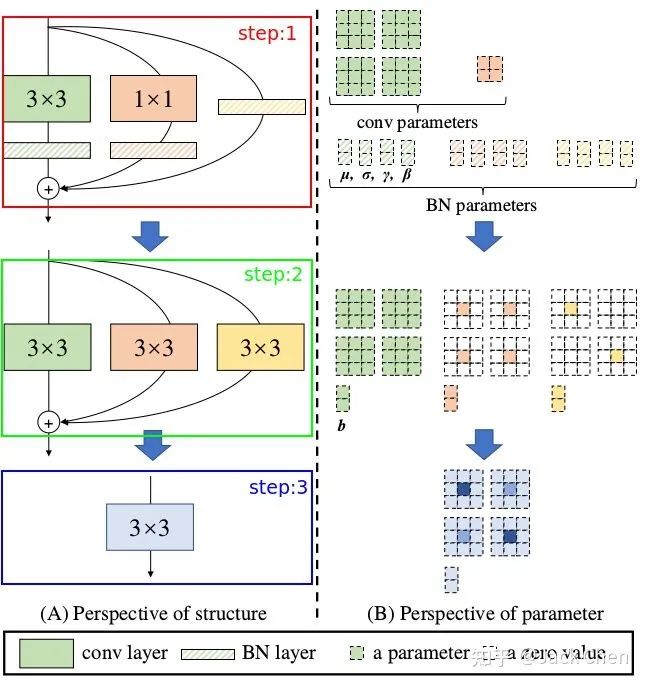
結(jié)構(gòu)重參數(shù)化的最后一步也就是上圖中step2 -> step3, 這一步就是利用卷積可加性原理,將三個(gè)分支的卷積層和bias對應(yīng)相加組成最終一個(gè)conv_3x3的形式即可。
感想:
repVGG總的來說,是一篇非常棒的關(guān)于backbone工作,將常規(guī)的工作思路:train model -> deploy model,轉(zhuǎn)換為:train model -> redefine model -> deploy model,我猜測與TensorRT在根據(jù)train model構(gòu)建高效率的inference engine思路一樣,tensorRT對模型進(jìn)行加速,也是在模型進(jìn)行優(yōu)化和等效變換,看下述模型:
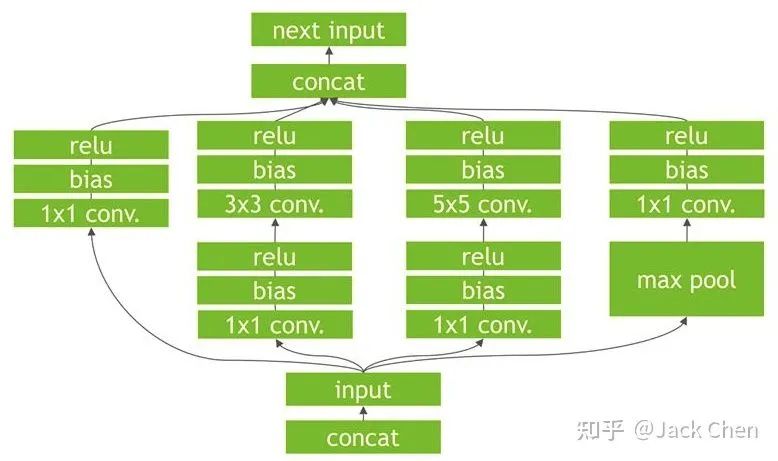
可以看到上圖中很多零散的OP節(jié)點(diǎn),我們知道OP越多,會(huì)導(dǎo)致網(wǎng)絡(luò)推理越慢,因?yàn)椋琧udnn是一個(gè)動(dòng)態(tài)庫,對于每個(gè)op,程序運(yùn)行時(shí)都是需要在.so庫(Win系統(tǒng)下是.dll)找到對應(yīng)的實(shí)現(xiàn),因?yàn)闀?huì)導(dǎo)致推理變慢。
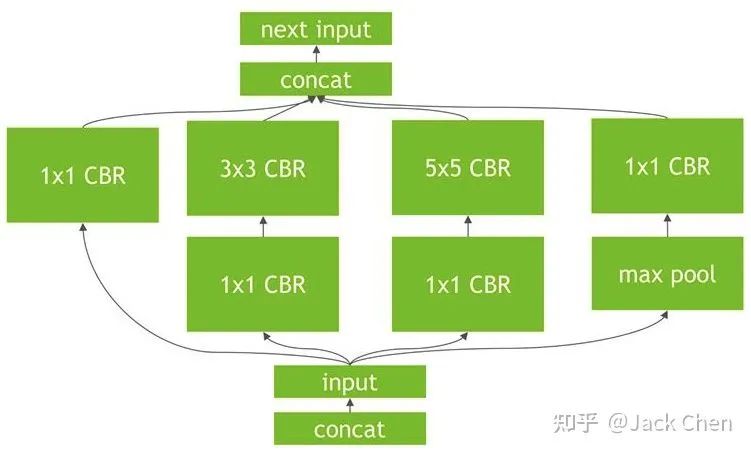
TensorRT的優(yōu)化如上圖,將CONV+BN+ReLU層進(jìn)行合并(也稱之為*垂直融合*),至于為什么上圖中寫的是bias而不是BN層,這是因?yàn)椋瑤в蠦N的層的conv的實(shí)現(xiàn),其bias和BN層的beta項(xiàng)進(jìn)行合并了。
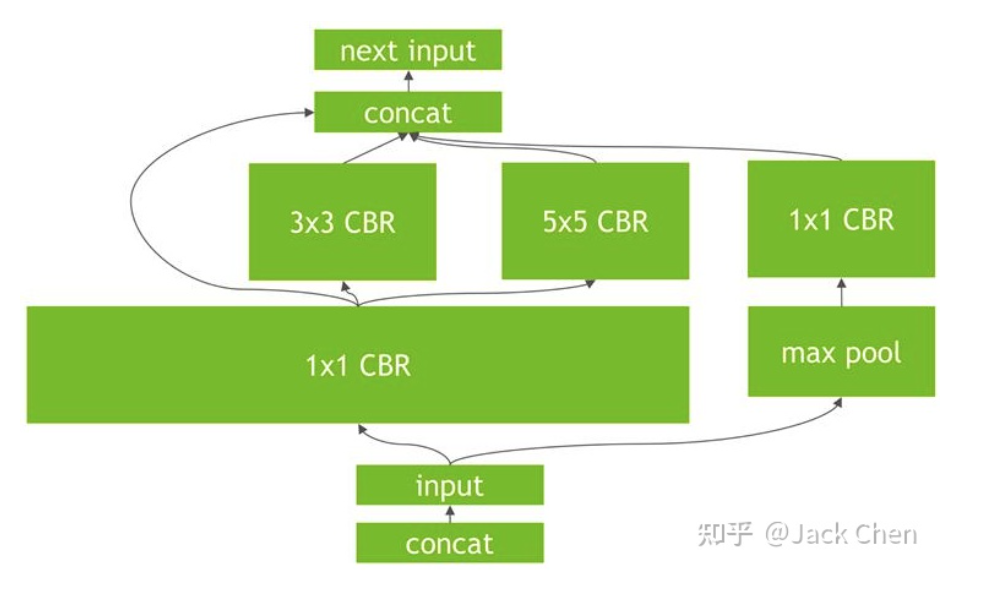
進(jìn)一步的發(fā)現(xiàn),TensorRT會(huì)繼續(xù)做合并優(yōu)化處理,在上圖的基礎(chǔ)上,你會(huì)發(fā)現(xiàn)conv_1*1被合并成了一個(gè)超級(jí)大的層。這里是水平融合機(jī)制,也即在同一個(gè)level層面上的相同操作進(jìn)行融合。
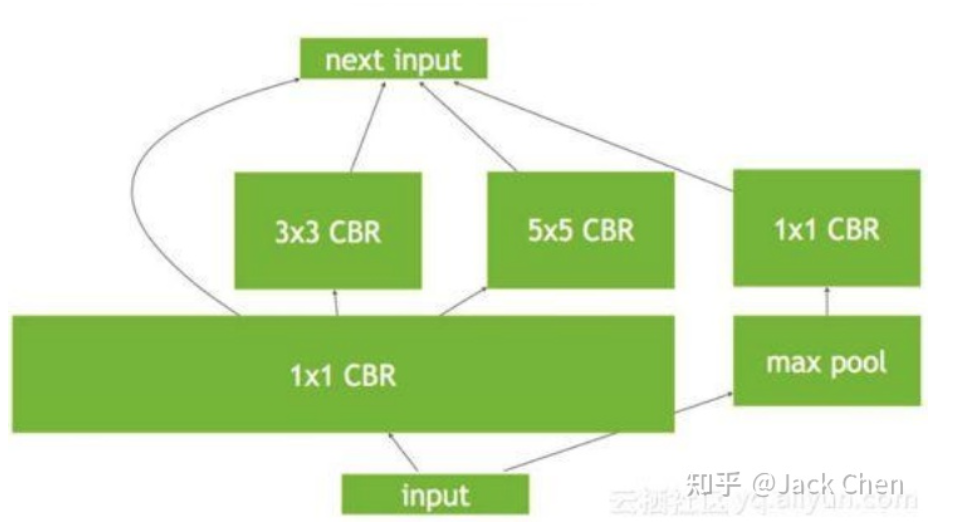
最后,進(jìn)一步取消一些沒必要的層,比如concat操作。
對于模型加速和模型等效以及部署加速工作,repVGG給了我們很多啟發(fā),此外,丁霄漢大佬的另外一篇優(yōu)秀論文:arxiv.org/pdf/1908.0393, ACNet,后續(xù)會(huì)深入研究這篇論文。
參考文獻(xiàn):
[1]. 鄭澤康:圖解RepVGG
[2]. https://zhuanlan.zhihu.com/p/344324470

推薦閱讀
谷歌提出Meta Pseudo Labels,刷新ImageNet上的SOTA!
漲點(diǎn)神器FixRes:兩次超越ImageNet數(shù)據(jù)集上的SOTA
SWA:讓你的目標(biāo)檢測模型無痛漲點(diǎn)1% AP
CondInst:性能和速度均超越Mask RCNN的實(shí)例分割模型
mmdetection最小復(fù)刻版(十一):概率Anchor分配機(jī)制PAA深入分析
MMDetection新版本V2.7發(fā)布,支持DETR,還有YOLOV4在路上!
無需tricks,知識(shí)蒸餾提升ResNet50在ImageNet上準(zhǔn)確度至80%+
不妨試試MoCo,來替換ImageNet上pretrain模型!
mmdetection最小復(fù)刻版(七):anchor-base和anchor-free差異分析
mmdetection最小復(fù)刻版(四):獨(dú)家yolo轉(zhuǎn)化內(nèi)幕
機(jī)器學(xué)習(xí)算法工程師
一個(gè)用心的公眾號(hào)
