
干貨:ARM架構(gòu)代碼移植實(shí)戰(zhàn)分享
經(jīng)歷過2個(gè)項(xiàng)目的業(yè)務(wù)代碼從X86服務(wù)器遷移到aarch64泰山服務(wù)器上,以前沒有相關(guān)經(jīng)驗(yàn)摸索了好久,踩了很多坑,現(xiàn)在遷移工作也差不多收尾了,Taishan服務(wù)器上跑比X86的溜多了。寫了一篇代碼遷移經(jīng)驗(yàn)總結(jié),歡迎大家參考。
編程語(yǔ)言簡(jiǎn)介
按照翻譯方式的不同,高級(jí)語(yǔ)言通常可以分為兩類:一類是編譯翻譯,一類是解釋翻譯,分別對(duì)應(yīng)著編譯型語(yǔ)言和解釋型語(yǔ)言。
1.編譯型語(yǔ)言
典型的如C、C++語(yǔ)言,都屬于編譯型語(yǔ)言,源代碼到執(zhí)行的過程概括如圖1-1所示。C/C++編譯好的程序是機(jī)器指令,由操作系統(tǒng)加載到存儲(chǔ)器(一般為內(nèi)存)后由CPU直接執(zhí)行。
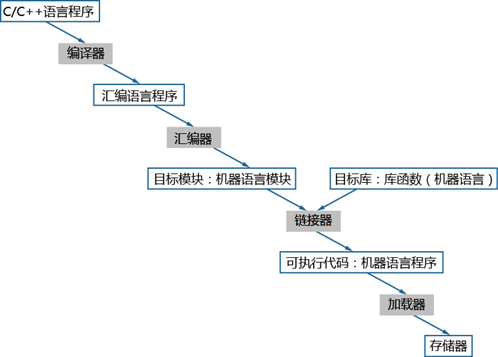
圖 編譯型語(yǔ)言執(zhí)行過程
基于編譯型語(yǔ)言開發(fā)的應(yīng)用程序,例如C/C++語(yǔ)言應(yīng)用程序,其編譯后得到可執(zhí)行程序,可執(zhí)行程序執(zhí)行時(shí)依賴的指令是CPU架構(gòu)相關(guān)的。因此,基于x86架構(gòu)編譯的C/C++語(yǔ)言應(yīng)用程序,無法直接在TaiShan服務(wù)器運(yùn)行,需要進(jìn)行移植編譯,移植編譯過程中遇到的問題可以參考第2、3章提供的方法解決。
2.解釋型語(yǔ)言
典型的如Java、Python語(yǔ)言,都屬于解釋型語(yǔ)言,源代碼到執(zhí)行的過程概括如圖1-2所示。Java/Python編譯好的程序是平臺(tái)無關(guān)的字節(jié)碼,由虛擬機(jī)解釋執(zhí)行,虛擬機(jī)完成平臺(tái)差異的屏蔽。
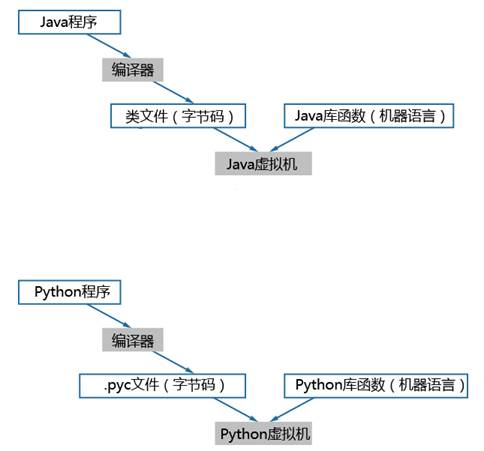
圖 解釋型語(yǔ)言執(zhí)行過程
基于解釋型語(yǔ)言開發(fā)的應(yīng)用程序,是CPU架構(gòu)不相關(guān)的,例如Java、Python,將這類應(yīng)用程序移植到TaiShan服務(wù)器,無需修改和重新編譯,按照與x86一致的方式部署和運(yùn)行應(yīng)用程序即可。
Java應(yīng)用程序jar包內(nèi),可能包含基于C/C++語(yǔ)言開發(fā)的so庫(kù)文件,這類so庫(kù)需要移植編譯,移植編譯so庫(kù)遇到的問題可以參考第2、3章提供的方法解決,使用編譯得到的so庫(kù)重新打包jar包。
準(zhǔn)備工作
C/C++程序移植需要安裝編譯器,推薦使用gcc7.3及以上版本(最低不低于4.8.5),下載安裝參考鏈接:
gcc7.3版本下載地址:
http://ftp.gnu.org/gnu/gcc/gcc-7.3.0/
安裝步驟參考:https://gcc.gnu.org/install/
移植相關(guān)問題處理-編譯腳本移植類問題
1.1 -m64編譯選項(xiàng)
現(xiàn)象描述
告警信息:gcc:error: unrecognized command line option ‘-m64’
可能原因
-m64是x86 64位應(yīng)用編譯選項(xiàng),m64選項(xiàng)設(shè)置int為32bits及l(fā)ong、指針為64 bits,為AMD的x86 64架構(gòu)生成代碼。在ARM64平臺(tái)無法支持。
處理步驟
將ARM64平臺(tái)對(duì)應(yīng)的編譯選項(xiàng)設(shè)置為-mabi=lp64。
1.2 char數(shù)據(jù)類型的符號(hào)
現(xiàn)象描述
告警信息:warning:comparison is always false due to limitedrange of data type
可能原因
char變量在不同CPU架構(gòu)下默認(rèn)符號(hào)不一致,在x86架構(gòu)下為signed char,在ARM64平臺(tái)為unsigned char,移植時(shí)需要指定char變量為signed char。
處理步驟
在編譯選項(xiàng)中加入“-fsigned-char”選項(xiàng),指定ARM64平臺(tái)下的char為有符號(hào)數(shù)。
源碼修改類問題
2.1 代碼中匯編指令需要重寫
現(xiàn)象描述
ARM的匯編語(yǔ)言與x86完全不同,需要重寫,涉及使用嵌入?yún)R編的代碼,都需要針對(duì)ARM進(jìn)行配套修改。
處理步驟
需要重新實(shí)現(xiàn)匯編代碼段。
示例:
在x86架構(gòu)下:

在ARM64平臺(tái)下,使用gcc內(nèi)置函數(shù)實(shí)現(xiàn):

2.2 替換x86 CRC32匯編指令
現(xiàn)象描述
編譯錯(cuò)誤:unknownmnemonic `crc32q\' -- `crc32q (x3),x2\'或operand 1 should be an integer register -- `crc32b (x1),x0\'
或unrecognizedcommand line option ‘-msse4.2’。
可能原因
x86使用的是crc32b和crc32q匯編指令完成CRC32C校驗(yàn)值計(jì)算功能,而ARM64平臺(tái)使用crc32cb、crc32ch、crc32cw、crc32cx 4個(gè)匯編指令完成CRC32C校驗(yàn)值計(jì)算功能。
處理步驟
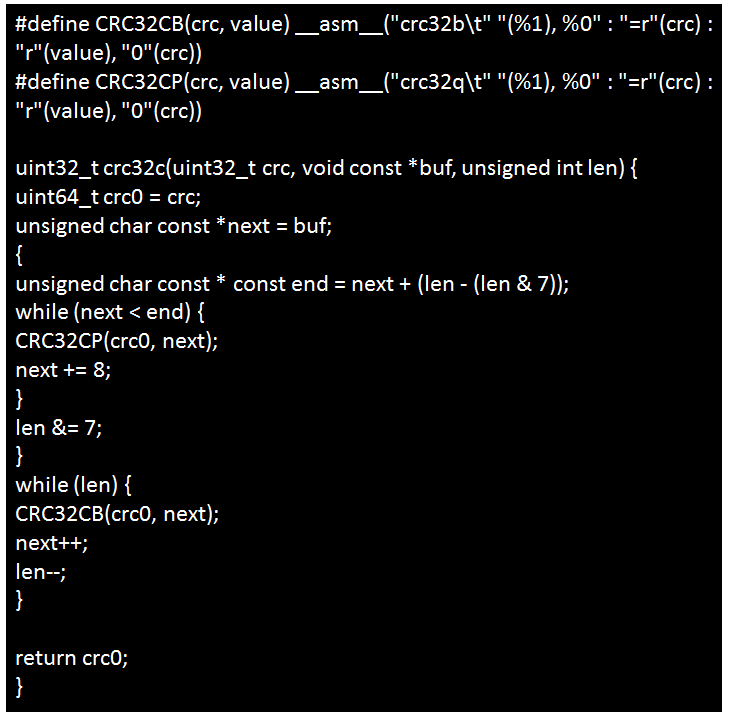
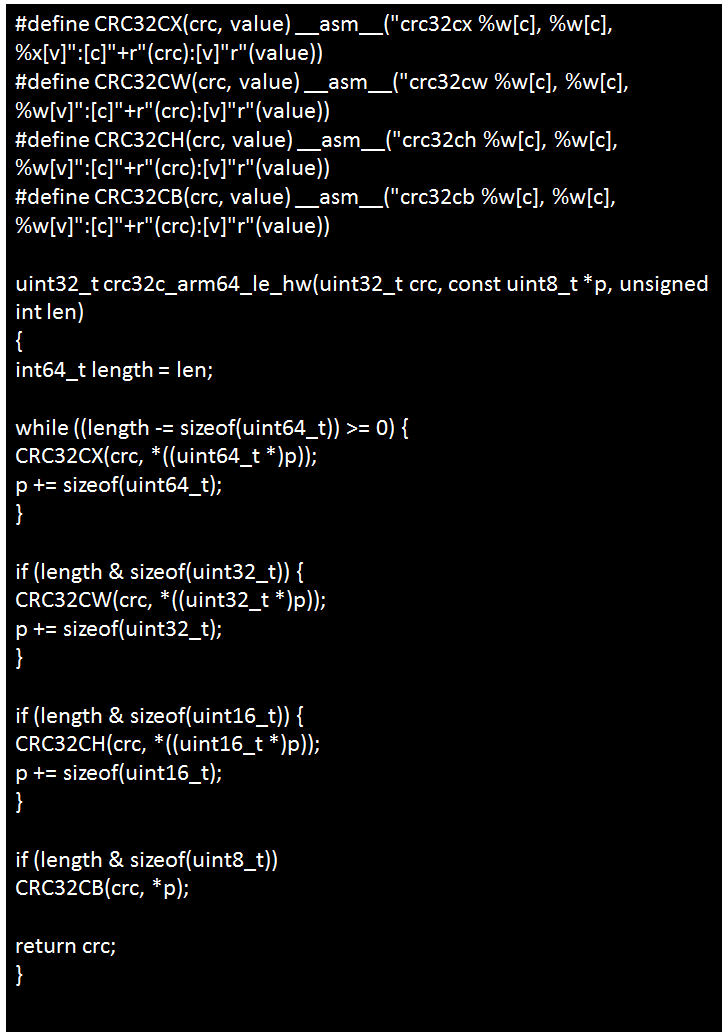
請(qǐng)使用crc32cb、crc32ch、crc32cw、crc32cx取代x86的CRC32系列匯編指令,替換方法如表所示,并在編譯時(shí)添加編譯參數(shù)-mcpu=generic+crc。

示例:
在x86下的實(shí)現(xiàn):
在ARM64平臺(tái)下的實(shí)現(xiàn):
2.3? 替換x86 bswap匯編指令
現(xiàn)象描述
編譯報(bào)錯(cuò):Error:unknown mnemonic `bswap\' -- `bswap x3\'。
可能原因
bswap是x86的字節(jié)序反序指令,需替換為ARM64的rev指令。
處理步驟
x86指令實(shí)現(xiàn)的bswap如下:

替換為ARM64指令后如下:

2.4? 替換x86 rep匯編指令
現(xiàn)象描述
編譯報(bào)錯(cuò):unknownmnemonic `rep` -- `rep`。
可能原因
rep為x86的重復(fù)執(zhí)行指令,需替換為ARM64的rept指令。
處理步驟
替換方法如下:
替換前:

替換后:
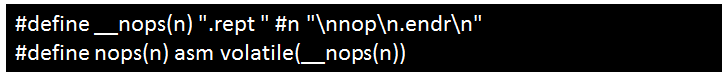
2.5 快速移植內(nèi)聯(lián)SSE/SSE2應(yīng)用
現(xiàn)象描述
部分應(yīng)用采用了gcc封裝的用SSE/SSE2實(shí)現(xiàn)的函數(shù),但是gcc目前沒有提供對(duì)應(yīng)的ARM64平臺(tái)版本,需要實(shí)現(xiàn)對(duì)應(yīng)函數(shù)。
處理步驟
目前已有開源代碼實(shí)現(xiàn)了部分ARM64平臺(tái)的函數(shù),代碼下載地址:https://github.com/open-estuary/sse2neon.git
使用方法如下:
步驟 1 ??將下載項(xiàng)目中的SSE2NEON.h文件拷貝到待移植項(xiàng)目中。
步驟 2 ??在源文件中刪除如下代碼。

步驟 3? ?在源代碼中包含頭文件SSE2NEON.h
----結(jié)束
2.6 弱內(nèi)存序?qū)е鲁绦驁?zhí)行結(jié)果和預(yù)期不一致
現(xiàn)象描述
弱內(nèi)存序?qū)е鲁绦驁?zhí)行結(jié)果和預(yù)期不一致。
可能原因
ARM64平臺(tái)是弱內(nèi)存序,原理如下:
1. 同一份數(shù)據(jù),在cache里面存在多份,需要CPU之間進(jìn)行同步。

2. 代碼編寫順序和執(zhí)行順序可能不一樣。

CPU內(nèi)部是流水線執(zhí)行,在執(zhí)行到x=1時(shí),如果x在內(nèi)存,那么CPU就會(huì)等待x導(dǎo)入到cache,在等待的過程中如果y已經(jīng)在cache中了,那么CPU會(huì)執(zhí)行y=1,這樣就導(dǎo)致后面的語(yǔ)句先執(zhí)行。
對(duì)系統(tǒng)的影響
· 影響無鎖編程的代碼。
·?對(duì)于使用信號(hào)量機(jī)制寫的互斥代碼,因?yàn)樾盘?hào)量函數(shù)已經(jīng)帶了內(nèi)存屏障的指令,所以無影響。
處理步驟
找到使用無鎖編程的代碼,檢查是否用內(nèi)存屏障指令保證了數(shù)據(jù)的一致性。
使用內(nèi)存屏障指令保證對(duì)共享數(shù)據(jù)的訪問和預(yù)期一致。
示例:

2.7 對(duì)結(jié)構(gòu)體中的變量進(jìn)行原子操作時(shí)程序異常coredump
現(xiàn)象描述
程序調(diào)用原子操作函數(shù)對(duì)結(jié)構(gòu)體中的變量進(jìn)行原子操作,程序coredump,堆棧如下:

可能原因
ARM64平臺(tái)對(duì)變量的原子操作、鎖操作等用到了ldaxr、stlxr等指令,這些指令要求變量地址必須按變量長(zhǎng)度對(duì)齊,否則執(zhí)行指令會(huì)觸發(fā)異常,導(dǎo)致程序coredump。
一般是因?yàn)榇a中對(duì)結(jié)構(gòu)體進(jìn)行強(qiáng)制字節(jié)對(duì)齊,導(dǎo)致變量地址不在對(duì)齊位置上,對(duì)這些變量進(jìn)行原子操作、鎖操作等會(huì)觸發(fā)問題。
處理步驟
代碼中搜索“#pragmapack”關(guān)鍵字(該宏改變了編譯器默認(rèn)的對(duì)齊方式),找到使用了字節(jié)對(duì)齊的結(jié)構(gòu)體,如果結(jié)構(gòu)體中變量會(huì)被作為原子操作、自旋鎖、互斥鎖、信號(hào)量、讀寫鎖的輸入?yún)?shù),則需要修改代碼保證這些變量按變量長(zhǎng)度對(duì)齊。
2.8?核數(shù)目硬編碼
TaiShan服務(wù)器相對(duì)于x86服務(wù)器,CPU核數(shù)會(huì)有變化,如果模塊代碼針對(duì)處理器core數(shù)目硬編碼,則會(huì)造成無法充分利用系統(tǒng)能力的情況,例如CPU核的利用率差異大或者綁核出現(xiàn)跨numa的情況。
處理步驟
您可以通過搜索代碼中的綁核接口(sched_setaffinity)來排查綁核的實(shí)現(xiàn)是否存在CPU核數(shù)硬編碼的情況。
如果存在,則根據(jù)TaiShan服務(wù)器實(shí)際核數(shù)進(jìn)行修改,消除硬編碼,可通過接口(sysconf(_SC_NPROCESSORS_CONF))來獲取實(shí)際核數(shù)再進(jìn)行綁核。
?
2.9?雙精度浮點(diǎn)型轉(zhuǎn)整型時(shí)數(shù)據(jù)溢出,與X86平臺(tái)表現(xiàn)不一致
現(xiàn)象描述
C/C++雙精度浮點(diǎn)型數(shù)轉(zhuǎn)整型數(shù)據(jù)時(shí),如果超出了整型的取值范圍,TaiShan平臺(tái)的表現(xiàn)與x86平臺(tái)的表現(xiàn)不同。

可能原因
在兩個(gè)平臺(tái)下,是兩套CPU架構(gòu),其中的算數(shù)邏輯單元的實(shí)現(xiàn)可能會(huì)有差異,操作系統(tǒng)、編譯器的實(shí)現(xiàn)都會(huì)有所不同。x86(指令集)中的浮點(diǎn)到整型的轉(zhuǎn)換指令,定義了一個(gè)indefinite integer value——“不確定數(shù)值”(64bit:0x8000000000000000),大多數(shù)情況下x86平臺(tái)確實(shí)都在遵循這個(gè)原則,但是在從double向無符號(hào)整型轉(zhuǎn)換時(shí),又出現(xiàn)了不同的結(jié)果。鯤鵬的處理則非常清晰和簡(jiǎn)單,在上溢出或下溢出時(shí),保留整型能表示的最大值或最小值,開發(fā)者并不會(huì)面對(duì)不確定或無法預(yù)期的結(jié)果。
處理步驟
參考如下數(shù)據(jù)轉(zhuǎn)換的表格,調(diào)整代碼中的實(shí)現(xiàn):
double數(shù)據(jù)向long轉(zhuǎn)換:

double數(shù)據(jù)向unsigned long轉(zhuǎn)換:

double數(shù)據(jù)向int轉(zhuǎn)換:

double數(shù)據(jù)向unsigned int轉(zhuǎn)換:

編譯優(yōu)化項(xiàng)
4.1 gcc編譯器優(yōu)化浮點(diǎn)運(yùn)算精度
現(xiàn)象描述
編譯優(yōu)化選項(xiàng)設(shè)置-O2級(jí)別及以上時(shí),相同的浮點(diǎn)數(shù)乘加運(yùn)算在x86平臺(tái)和ARM64平臺(tái)的運(yùn)算結(jié)果,在小數(shù)點(diǎn)后16位存在差異。
可能原因
ARM64平臺(tái)編譯優(yōu)化選項(xiàng)設(shè)置為-O2級(jí)別及以上,進(jìn)行浮點(diǎn)數(shù)的乘加運(yùn)算(a+=b*c),運(yùn)算結(jié)果的精度只能精確到小數(shù)點(diǎn)后16位。在配置-O2選項(xiàng)時(shí),gcc使用融合指令fmadd完成乘加運(yùn)算,而不是fadd和fmul。
fmadd將浮點(diǎn)數(shù)的乘法和加法看成不可分的一個(gè)操作,不對(duì)中間結(jié)果進(jìn)行舍入,從而導(dǎo)致計(jì)算結(jié)果有所差別。
對(duì)系統(tǒng)的影響
編譯優(yōu)化選項(xiàng)設(shè)置-O2級(jí)別及以上時(shí),浮點(diǎn)乘加運(yùn)算的性能有提升,但是運(yùn)算的精度受到影響。
處理步驟
添加編譯選項(xiàng)-ffp-contract=off可以關(guān)閉該優(yōu)化。
4.2 增加編譯選項(xiàng)匹配Kunpeng處理器架構(gòu),提升性能
在編譯時(shí)增加編譯選項(xiàng)指定處理器架構(gòu)為armv8,使編譯器按照Kunpeng處理器的架構(gòu)和微架構(gòu)生成可執(zhí)行程序,提升性能。
處理步驟
編譯選項(xiàng)中添加-march=armv8-a。
4.3 增加編譯選項(xiàng)匹配Kunpeng處理器流水線,提升性能
如果使用了gcc 9.1以上的版本,在編譯時(shí)增加編譯選項(xiàng)指定使用tsv110流水線,使編譯器按照Kunpeng處理器的流水線編排指令執(zhí)行順序,充分利用流水線的指令集并行,提升性能。
處理步驟
編譯選項(xiàng)中添加 -mtune=tsv110。