
NAS的挑戰(zhàn)和解決方案-一份全面的綜述
【GiantPandaCV導讀】上一篇中,筆者翻譯了國外一篇介紹Automl和NAS的博客,點這里回顧。這一篇是筆者對《A Comprehensive Survey of Nerual Architecture Search: Challenges and Solutions》這篇論文進行翻譯和解讀,這是2020年剛剛發(fā)到arxiv上的有關(guān)NAS的綜述,內(nèi)容比較多,30頁152篇參考文獻。對初學者來說,可以當作一個學習的目錄,閱讀文中提到的論文。文末用思維導圖總結(jié)了整篇文章脈絡,可以用來速覽。
【內(nèi)容速覽】你可能感興趣的內(nèi)容:
NAS是什么?由什么組成?常用算法是什么? Add操作要比concate操作更加有效。 寬而淺的單元(采用channel個數(shù)多,但層數(shù)不多)在訓練過程中更容易收斂,但是缺點是泛化性能很差。 能根據(jù)網(wǎng)絡前幾個epoch的表現(xiàn)就確定這個網(wǎng)絡是否能夠取得更高性能的預測器(性能預測)。 根據(jù)候選網(wǎng)絡結(jié)構(gòu)的表示就可以預測這個模型未來的表現(xiàn)(性能預測)。 分類的backbone和其他任務比如檢測是存在一定gap的,最好的方式并不一定是微調(diào),而可能是改變網(wǎng)絡架構(gòu)。
1. 背景
2. NAS介紹
3. 早期NAS的特征
3.1 全局搜索
3.2 從頭搜索
4. 優(yōu)化策略
4.1 模塊搜索策略
4.2 連續(xù)的搜索空間
4.3 網(wǎng)絡架構(gòu)重復利用
4.4 不完全訓練
5. 性能對比
6. 未來的方向
7. 結(jié)語
8. 參考文獻
1. 背景
深度學習在很多領(lǐng)域都取得了巨大的突破和進展。這是由于深度學習具有的強大的自動化特征提取的能力。而網(wǎng)絡結(jié)構(gòu)的設計對數(shù)據(jù)的特征的表征和最終模型的表現(xiàn)起到了至關(guān)重要的作用。
為了獲取數(shù)據(jù)的更好的特征表示,研究人員設計了多種多樣的復雜的網(wǎng)絡架構(gòu),而網(wǎng)絡結(jié)構(gòu)的設計是嚴重依賴于研究人員的先驗知識和經(jīng)驗。同時網(wǎng)絡結(jié)構(gòu)的設計也很難跳出原有思考模式并設計出一個最優(yōu)的網(wǎng)絡。萌新很難根據(jù)自己的實際任務和需求對網(wǎng)絡結(jié)構(gòu)進行合理的修改。
一個很自然的想法就是盡可能減少人工的干預,讓算法能夠自動尋找最合適的網(wǎng)絡架構(gòu),這就是網(wǎng)絡搜索NAS提出的背景。
近些年很多有關(guān)NAS的優(yōu)秀的工作層出不窮,分別從不同的角度來提升NAS算法。為了讓初學者更好的進行NAS相關(guān)的研究,一個全面而系統(tǒng)的有關(guān)NAS的綜述很重要。
文章組織方式:
早期NAS算法的特點。
總結(jié)早期NAS算法中存在的問題。
給出隨后的NAS算法對以上問題提出的解決方案。
對以上算法繼續(xù)分析、對比、總結(jié)。
給出NAS未來可能的發(fā)展方向。
2. NAS介紹
NAS-神經(jīng)網(wǎng)絡架構(gòu)搜索,其作用就是取代人工的網(wǎng)絡架構(gòu)設計,在這個過程中盡可能減少人工的干預。
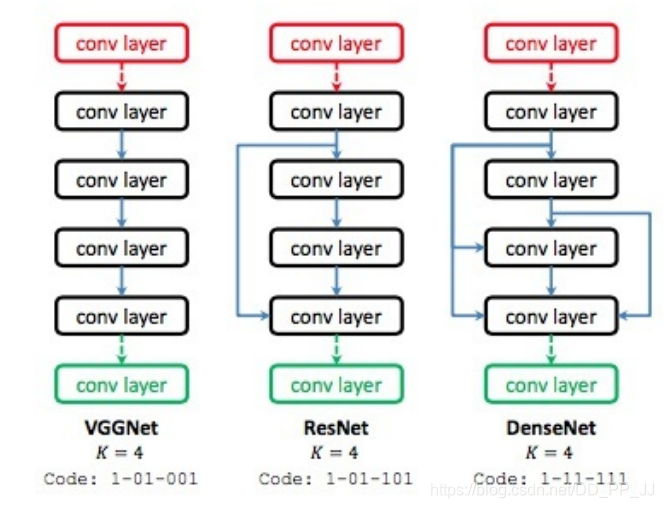
人工設計的網(wǎng)絡如ResNet、DenseNet、VGG等結(jié)構(gòu),實際上也是采用了以下組件組裝而成的:
identity
卷積層(3x3、5x5、7x7)
深度可分離卷積
空洞卷積
組卷積
池化層
Global Average Pooling
其他
如果對網(wǎng)絡結(jié)構(gòu)的設計進行建模的話,希望通過搜索的方法得到最優(yōu)的網(wǎng)絡結(jié)構(gòu),這時就需要NAS了。
NAS需要在有限的計算資源達到最好的效果,同時盡可能將更多的步驟自動化。在設計NAS算法的過程通常要考慮幾個因素:
search space 如何定義搜索空間 search strategy 搜索的策略 evaluation strategy 評估的策略
3. 早期NAS的特征
早期的NAS的結(jié)構(gòu)如下圖所示:
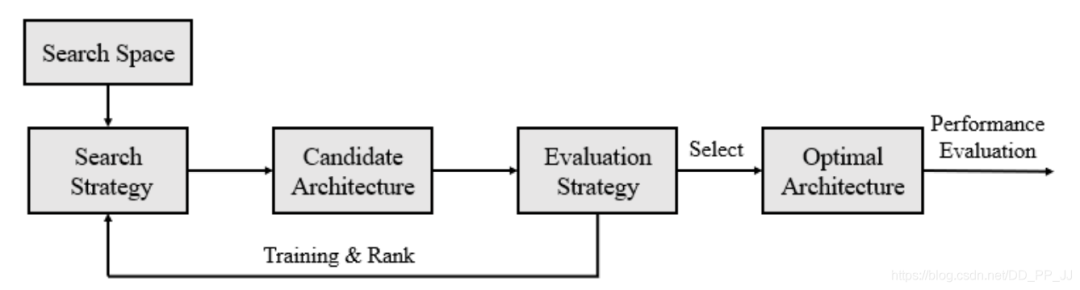
找一些預定義的操作集合(eg 卷積、池化等)這些集合構(gòu)成了Search Space搜索空間。 采用一定的搜索策略來獲取大量的候選網(wǎng)絡結(jié)構(gòu)。 在訓練集訓練這些網(wǎng)絡,并且在驗證集測試得到這些候選網(wǎng)絡的準確率。 這些候選網(wǎng)絡的準確率會對搜索策略進行反饋,從而可以調(diào)整搜索策略來獲得新一輪的候選網(wǎng)絡。重復這個過程。 當終止條件達到(eg:準確率達到某個閾值),搜索就會停下來,這樣就可以找到準確率最高對應的網(wǎng)絡架構(gòu)。 在測試集上測試最好的網(wǎng)絡架構(gòu)的準確率。
下面介紹的幾個網(wǎng)絡都是遵從以上的結(jié)構(gòu)進行設計的:
1. NAS-RL
NAS-RL發(fā)現(xiàn)神經(jīng)網(wǎng)絡的結(jié)構(gòu)可以用一個變長字符串來描述,這樣的話就可以使用RNN來作為一個控制器生成一個這樣的字符串,然后使用強化學習算法來優(yōu)化控制器,通過這種方法得到最終最優(yōu)的網(wǎng)絡架構(gòu)。
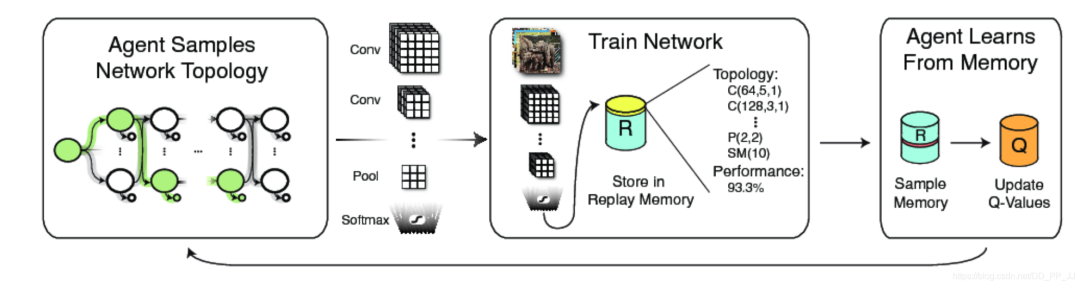
2. MetaQNN
MetaQNN將選擇網(wǎng)絡架構(gòu)的過程看作馬爾可夫決策過程,用Q-learning來記錄得到的獎勵,通過這樣的方法得到最優(yōu)的網(wǎng)絡架構(gòu)。
3. Large-scale Evolution
Large-scale Evolution目標是使用進化算法(Evolutionary Algorithms)來學習一個最優(yōu)的網(wǎng)絡架構(gòu)。使用一個最簡單的網(wǎng)絡結(jié)構(gòu)來初始化種群,通過交叉、突變等方法來選擇最優(yōu)種群。
4. GeNet
GeNet也采用了進化算法,提出了一個新的神經(jīng)網(wǎng)絡架構(gòu)編碼機制,用定長的二進制串來表征一個網(wǎng)絡的結(jié)構(gòu)。GeNet隨機初始化一組個體,使用預選定義好的基因操作(將二進制串看作一個個體的基因)來修改二進制串進而產(chǎn)生新的個體,從而最終選擇出具有競爭力的個體作為最終的網(wǎng)絡架構(gòu)。
總結(jié)一下早期的NAS的特征:
全局搜索策略:早期NAS采用的策略是搜索整個網(wǎng)絡的全局,這就意味著NAS需要在非常大的搜索空間中搜索出一個最優(yōu)的網(wǎng)絡結(jié)構(gòu)。搜索空間越大,計算的代價也就越大。 離散的搜索空間:早期NAS的搜索空間都是離散的,不管是用變長字符串也好,還是用二進制串來表示,他們的搜索空間都是離散的,如果無法連續(xù),那就意味著無法計算梯度,也無法利用梯度策略來調(diào)整網(wǎng)絡模型架構(gòu)。 從頭開始搜索:每個模型都是從頭訓練的,這樣將無法充分利用現(xiàn)存的網(wǎng)絡模型的結(jié)構(gòu)和已經(jīng)訓練得到的參數(shù)。
3.1 全局搜索
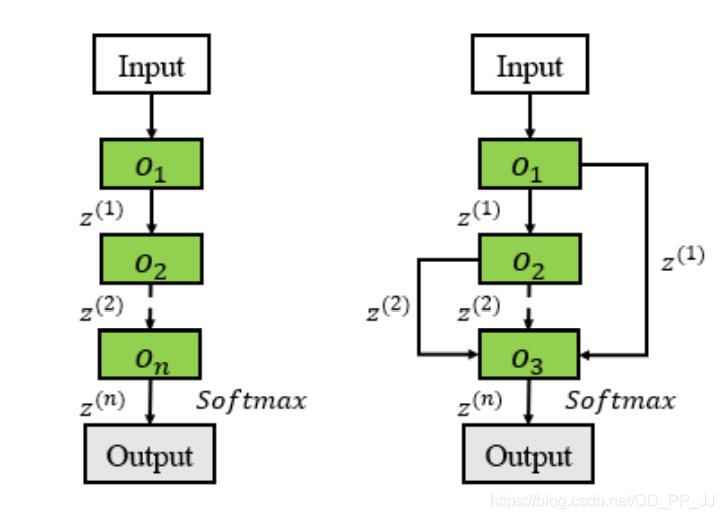
全局搜索一般采用了以上兩種常見的搜索形式,左側(cè)圖是最簡單的一個鏈式結(jié)構(gòu);右側(cè)圖在其之上添加了skip connection。MNASNet吸取了人工設計的經(jīng)驗,希望搜索多個按順序連接的段(segment)組成的網(wǎng)絡結(jié)構(gòu),其中每個段都具有各自重復的結(jié)構(gòu)。
“注記:跳轉(zhuǎn)連接往往可以采用多種方式進行特征融合,常見的有add, concate等。作者在文中提到了實驗證明,add操作要比concate操作更加有效(原文:the sum operation is better than the merge operation)所以在NAS中,通常采用Add的方法進行特征融合操作。
3.2 從頭搜索
早期NAS中,從頭開始搜索也是一個較為常見的搜索策略。NAS-RL將網(wǎng)絡架構(gòu)表達為一個可變長的字符串,采用RNN作為控制器來生成這個可變長字符串,根據(jù)該串可以得到一個相對應的神經(jīng)網(wǎng)絡的架構(gòu),采用強化學習作為搜索的策略對網(wǎng)絡搜索方式進行調(diào)整。
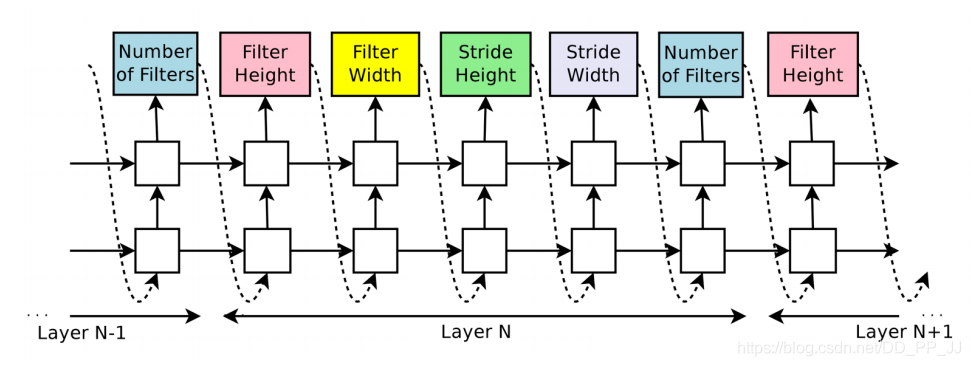
MetaQNN考慮訓練一個Agent/Actor來讓其在搜索空間中按照順序選擇神經(jīng)網(wǎng)絡的架構(gòu)。MetaQNN將這個選擇過程看作馬爾可夫決策過程,使用Q-learning作為搜索策略進而調(diào)整Agent/Actor所決定執(zhí)行的動作。
“圖源:https://bowenbaker.github.io/metaqnn/
GeNet也采用了將網(wǎng)絡架構(gòu)編碼的方式,提出了用二進制編碼來表達網(wǎng)絡的架構(gòu)。這個二進制編碼串被視為這個網(wǎng)絡個體的DNA,這樣可以通過交叉、編譯等操作,產(chǎn)生新的網(wǎng)絡架構(gòu),使用進化算法得到最優(yōu)個體,也就是最好的網(wǎng)絡架構(gòu)。
Large-scale Evolution只用了一個單層的、無卷積操作的模型作為初始的進化個體,然后使用進化學習方法來進化種群,如下圖所示:
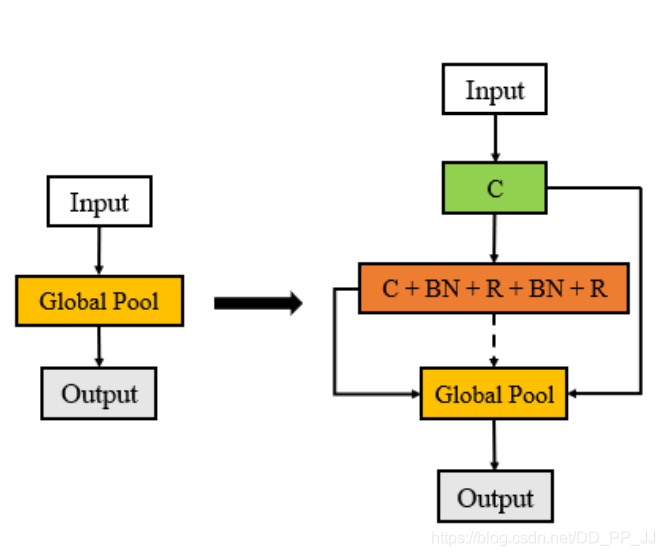
可以看到,最初的個體僅僅使用了一個全局池化來構(gòu)建模型,隨后的個體中,可以再加入卷積、BN、激活函數(shù)等組件,構(gòu)成下一代的種群。
4. 優(yōu)化策略
以上是早期NAS中的操作,這部分主要從模塊搜索策略、連續(xù)搜索空間、網(wǎng)絡的循環(huán)利用和不完全訓練這幾點分別展開。
4.1 模塊搜索策略
搜索空間的設計非常重要,不僅決定了搜索空間的大小,還決定了模型表現(xiàn)的上限。搜索完整的模型的搜索空間過大,并且存在泛化性能不強的問題。也就是說在一個數(shù)據(jù)集上通過NAS得到的最優(yōu)模型架構(gòu),在另外一個數(shù)據(jù)集上往往不是最優(yōu)的。
所以引入了模塊化的搜索策略,基于單元模塊進行搜索可以減少NAS搜索空間的復雜度。只需要搜索單元,然后就可以通過重復堆疊這些單元來構(gòu)成最終的網(wǎng)絡架構(gòu)。基于單元的模塊搜索方法的擴展性要強于全局搜索,不僅如此,模型的表現(xiàn)也更加出色。與全局搜索空間相比,基于單元的搜索空間更加緊湊、靈活。NASNet是最先開始探索單元化搜索的,其中提出了兩種模塊:Normal Cell和Reduction Cell。
Normal Cell也就是正常模塊,用于提取特征,但是這個單元不能改變特征圖的空間分辨率。 Reduction Cell和池化層類似,用于減少特征圖的空間分辨率。
整體網(wǎng)絡架構(gòu)就應該是Normal Cell+Reduction Cell+Normal Cell...這樣的組合,如下圖所示:
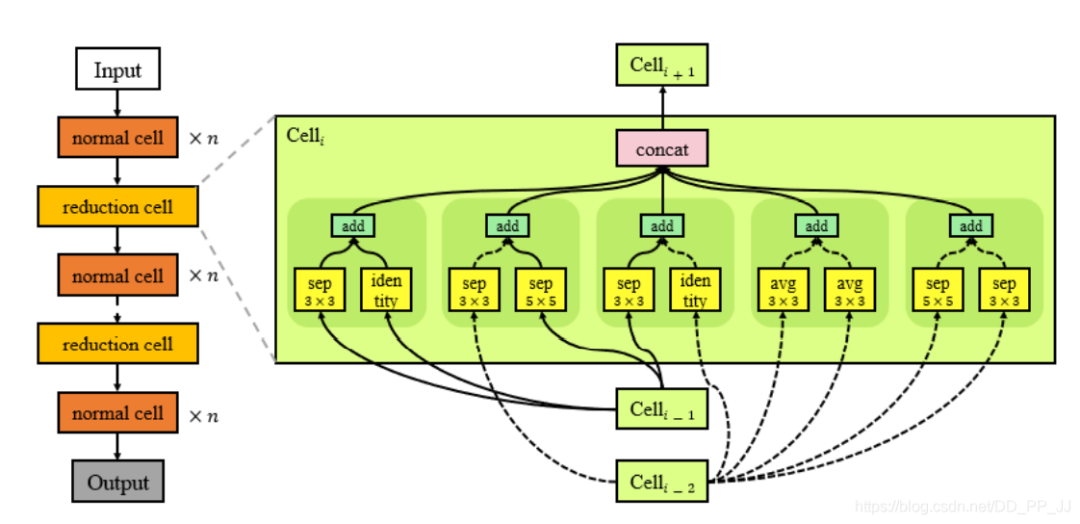
左側(cè)展示了兩種cell,有圖展示的是其中一個ReductionCell搜索得到的模塊內(nèi)結(jié)構(gòu)。
在ENAS中,繼承了NASNet這種基于單元搜索的搜索空間,并通過實驗證明了這種空間是非常有效的。
之后的改進有:
使用單元操作來取代reduction cell(reduction cell往往比較簡單,沒有必要搜索,采用下采樣的單元操作即可,如下圖Dpp-Net的結(jié)構(gòu))下圖Dpp-Net中采用了密集連接。
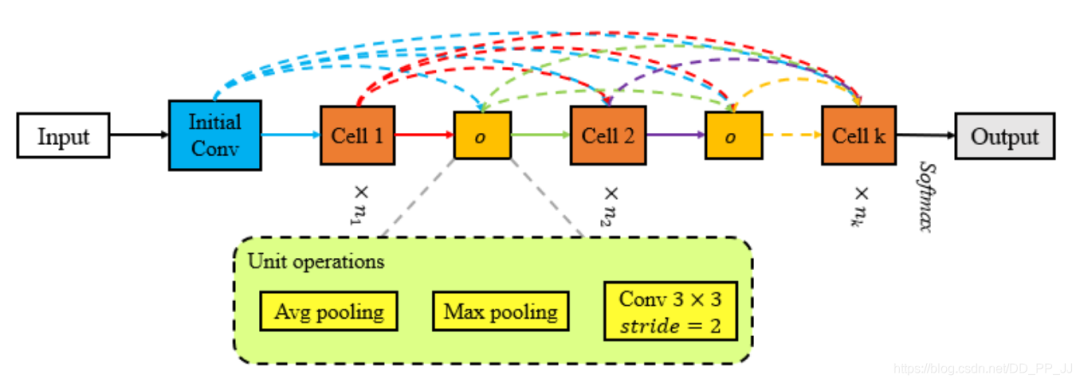
Block-QNN中直接采用池化操作來取代Reduction cell Hierarchical-EAS中使用了3x3的kernel size, 以2為stride的卷積來替代Reduction Cell。 Dpp-Net采用平均池化操作取代Reduction Cell。同時采取了Dense連接+考慮了多目標優(yōu)化問題。 在視頻任務:SNAS使用了Lx3x3,stride=1,2,2的maxpooling取代Reduction Cell。 在分割任務:AutoDispNet提出了一個自動化的架構(gòu)搜索技術(shù)來優(yōu)化大規(guī)模U-Net類似的encoder-decoder的架構(gòu)。所以需要搜索三種:normal、reduction、upsampling。
“注記:通過研究這些搜索得到的單元模塊,可以得到以下他們的共性:由于現(xiàn)存的連接模式,寬而淺的單元(采用channel個數(shù)多,但層數(shù)不多)在訓練過程中更容易收斂,并且更容易搜索,但是缺點是泛化性能很差。
4.2 連續(xù)的搜索空間
NASNet使用強化學習算法需要2000個GPU days才能在CIFAR-10數(shù)據(jù)集上獲得最好的網(wǎng)絡架構(gòu)。AmoebaNet使用進化算法需要3150個GPU days才能完成。這些基于RL、EA(進化算法)、貝葉斯優(yōu)化、SMBO(基于順序模型的優(yōu)化)、MCTS(蒙特卡洛搜索樹)的主流的搜索算法被看作一個在離散空間中的黑盒優(yōu)化問題。
DAS將離散的網(wǎng)絡架構(gòu)空間變?yōu)檫B續(xù)可微分的形式,然后使用梯度優(yōu)化技術(shù)來搜索網(wǎng)絡架構(gòu)。其主要集中于搜索卷積層的超參數(shù)如:filter size,通道個數(shù)和卷積分組情況。
MaskConnect發(fā)現(xiàn)現(xiàn)有的基于單元的網(wǎng)絡架構(gòu)通常是在兩個模塊之間采用了預定義好連接方法,比如,一個模塊要和這個模塊之前的所有模塊都進行連接。MaskConnect認為這種方法可能并不是最優(yōu)的,采用了一種梯度的方法來控制模塊之間的連接。
但是以上方法僅限于微調(diào)特定的網(wǎng)絡架構(gòu)。
為了解決以上問題,DARTS將離散的搜索空間松弛到了連續(xù)的空間,這樣就可以使用梯度的方法來有效的優(yōu)化搜索空間。DARTS 也采用了和NASNet一致的基于單元的搜索空間,并進一步做了一個歸一化操作。這些單元就可以看成一個有向不循環(huán)圖。每個單元有兩個輸入節(jié)點和一個輸出節(jié)點。對于卷積的單元來說,輸入單元就是前兩個單元的輸出。
規(guī)定一組符號來表達DARTS網(wǎng)絡:
中間節(jié)點代表潛在的特征表達,并且和每個之前的節(jié)點都通過一個有向邊操作。對一個離散的空間來說,每個中繼節(jié)點可以這樣表達:
x代表feature map,o代表計算操作
在DARTS中,通過一個類似softmax來松弛所有可能的操作,這樣就將離散搜索空間轉(zhuǎn)化為連續(xù)的搜索空間問題。
代表的是一系列候選操作;代表的是有向邊上的操作的參數(shù);
通過以上過程就可以將搜索網(wǎng)絡架構(gòu)的問題轉(zhuǎn)化為一個對連續(xù)變量進行優(yōu)化的過程。搜索完成之后,需要選擇最有可能的操作 邊上的操作,而其他操作將會被丟棄:
這樣DARTS就相當于在求解一個二次優(yōu)化問題,在優(yōu)化網(wǎng)絡權(quán)重的同時還需要優(yōu)化混合操作(也就是)
代表驗證集上的Loss, 代表訓練集上的Loss。其中是高層變量,是底層變量,通過同時優(yōu)化這個網(wǎng)絡,將會獲得最優(yōu)的, 然后最終網(wǎng)絡結(jié)構(gòu)的獲取是通過離散化操作完成的的。具體流程可以結(jié)合下圖理解:
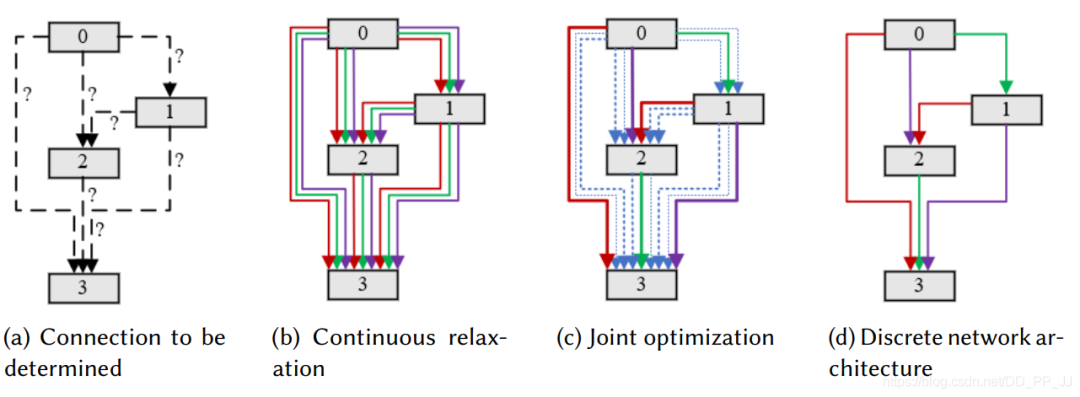
NAO選擇將整個網(wǎng)絡結(jié)構(gòu)進行編碼,將原先離散的網(wǎng)絡架構(gòu)映射為連續(xù)的嵌入編碼(encoder過程)。然后使用梯度優(yōu)化方法去優(yōu)化模型表現(xiàn)預測器(performance predictor)的輸出,從而獲得最優(yōu)的嵌入編碼。最后用一個解碼器來離散化最優(yōu)的嵌入編碼,變成一個最優(yōu)的網(wǎng)絡架構(gòu)(decoder過程)。
DARTS和NAO是同一段時期提出來的算法,都存在一個問題:訓練完成以后,將已經(jīng)收斂的父代網(wǎng)絡使用argmax進行離散化,得到派生的子代網(wǎng)絡,這個離散化的過程帶來的偏差bias會影響模型的表現(xiàn),所以還需要對子代網(wǎng)絡進行重新訓練。由于父代網(wǎng)絡已經(jīng)在驗證集中進行了測試,是最優(yōu)模型。因此父代網(wǎng)絡和派生的子代網(wǎng)絡表現(xiàn)相差越少越好,這樣最終得到的子代網(wǎng)絡表現(xiàn)才能盡可能更好。
為解決以上問題,SNAS首先使用了強化學習中的延遲獎勵,并且分析了為什么延遲獎勵會導致收斂速度變慢的問題。然后SNAS提出重建NAS的方法來理論上繞開延遲獎勵的問題,并且同時采用了連續(xù)化網(wǎng)絡參數(shù)的方法,這樣網(wǎng)絡操作(network operation)的參數(shù)和網(wǎng)絡架構(gòu)的參數(shù)就可以使用梯度方法同時進行優(yōu)化。
在SNAS、DARTS等算法中,搜索的過程中,所有可行的路徑都存在耦合關(guān)系。盡管SNAS減少了派生的子網(wǎng)絡和父代網(wǎng)絡之間的差異,SNAS在驗證階段依然需要選擇其中一條路徑。
為此,DATA開發(fā)了一個EGS估計器(Ensemble Gumbel-Softmax),其功能是將不同路徑的關(guān)系進行解耦,然后就可以讓不同路徑之間梯度的無縫遷移。
I-DARTS指出了基于Softmax方法的松弛方法可能導致DARTS變成一個"局部模型"。當前DARTS設計是:每個節(jié)點都和之前的所有節(jié)點連接,在離散化以后得到的模型,每兩個節(jié)點之間必有一條邊連接。I-DARTS認為這種設計并沒有理論依據(jù)并且限制了DARTS的搜索空間。
I-DARTS解決方案是同時考慮所有的輸入節(jié)點,看下面示意圖:
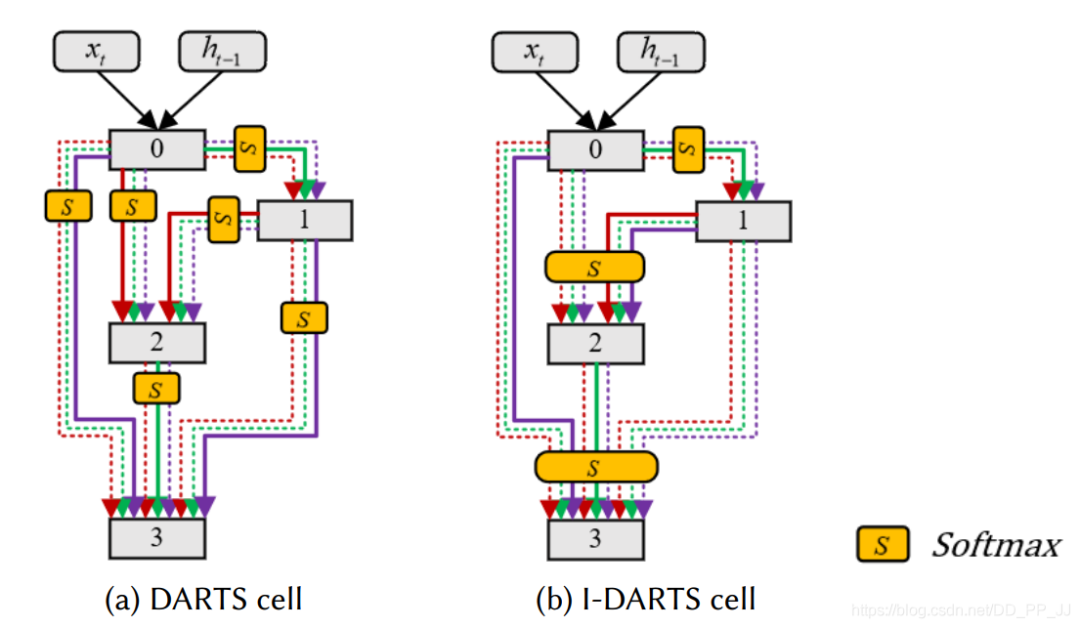
可以看到,DARTS的softmax是操作在每兩個節(jié)點之間,I-DARTS做出的改進對一個節(jié)點所有的輸入都是用一個Softmax來統(tǒng)一,這樣最終結(jié)果就不是每兩個節(jié)點之間都需要有一個邊。這樣可以讓模型具有更強的靈活性。
P-DARTS發(fā)現(xiàn)DARTS存在搜索和驗證的網(wǎng)絡架構(gòu)存在巨大的gap:DARTS本身會占用很大的計算資源,所以在搜索階段只能搜索淺網(wǎng)絡。在驗證階段,DARTS會將淺層的網(wǎng)絡堆疊起來從而形成一個深層網(wǎng)絡。兩個階段訓練的網(wǎng)絡存在gap,所以P-DARTS提出了一個采用漸進的搜索策略,在訓練過程中逐步增加網(wǎng)絡的深度,同時根據(jù)混合操作的權(quán)重逐漸減少候選操作集合的大小來防止計算量爆炸。為了解決這個過程中出現(xiàn)的搜索不穩(wěn)定的問題,P-DARTS引入了正則化防止算法過于偏向skip-connect。
GDAS(百度CVPR19)發(fā)現(xiàn)同時優(yōu)化不同的子操作會導致訓練不穩(wěn)定,有些子操作可能是競爭關(guān)系,直接相加會抵消。所以GDAS提出了采樣器得到subgraph,每次迭代的更新只對subgraph進行即可。通過這個操作可以讓識別率基本不變的情況下,搜索速度加快5倍。
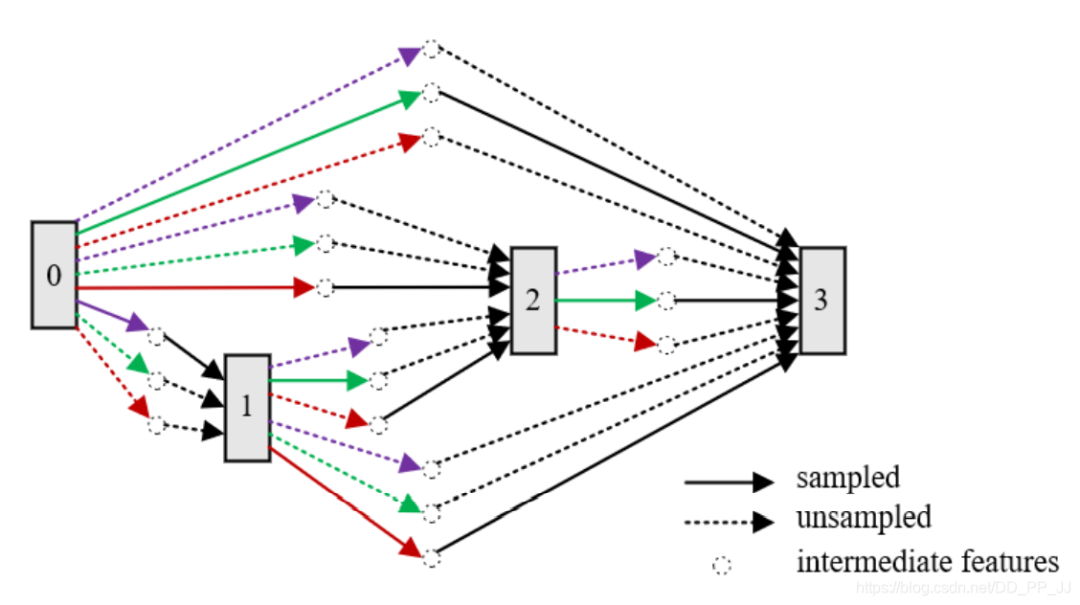
上圖是GDAS的示意圖,只有黑色實線代表這個路徑被sample到了,在這個迭代中,只需要訓練這個subgraph即可。
PC-DARTS致力于減少顯存占用、提高搜索效率,進行快速的大batch搜索。設計了基于channel的采樣機制,每次只有一部分channel會用來進行訓練。但是這樣會帶來不穩(wěn)定的問題,于是提出edge normalization,搜索過程中通過學習edge-level超參數(shù)來減少不確定性。
除了以上工作,還有很多工作都是基于DARTS進行改進的,DARTS由于其簡單而優(yōu)雅的結(jié)構(gòu),相關(guān)研究非常豐富,組成了NAS的一個重要研究方向。
4.3 網(wǎng)絡架構(gòu)重復利用
早期的NAS通常采用的方法是從頭開始訓練,這種方法從某種角度來講,可以增加模型的搜索的自由度,很有可能能夠設計出一個效果很棒的網(wǎng)絡架構(gòu)。但是,從頭訓練也會帶來讓搜索的時間復雜度上升,因為其并沒有利用到前線已經(jīng)設計好的網(wǎng)絡架構(gòu)權(quán)重,未充分利用這部分先驗知識。
一個新的想法是將已有的人工設計的網(wǎng)絡架構(gòu)作為起始點,然后以此為基礎使用NAS方法進行搜索,這樣可以以更小的計算代價獲得一個更有希望的模型架構(gòu)。
以上想法就可以看作是Network Transform或者Knowledge Transform(知識遷移)。
Net2Net對知識遷移基礎進行了詳盡的研究,提出了一個“功能保留轉(zhuǎn)換”(Function-perserving Transformation)的方法來實現(xiàn)對模型參數(shù)的重復利用,可以極大地加速訓練新的、更大的網(wǎng)絡結(jié)構(gòu)。
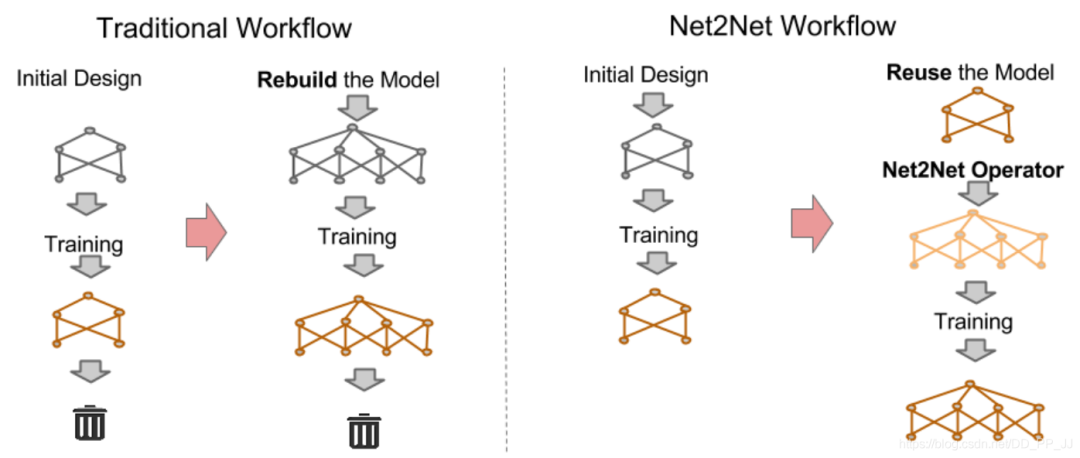
其中主要有Net2WiderNet和Net2DeeperNet,兩個變換可以讓模型變得更寬更深。
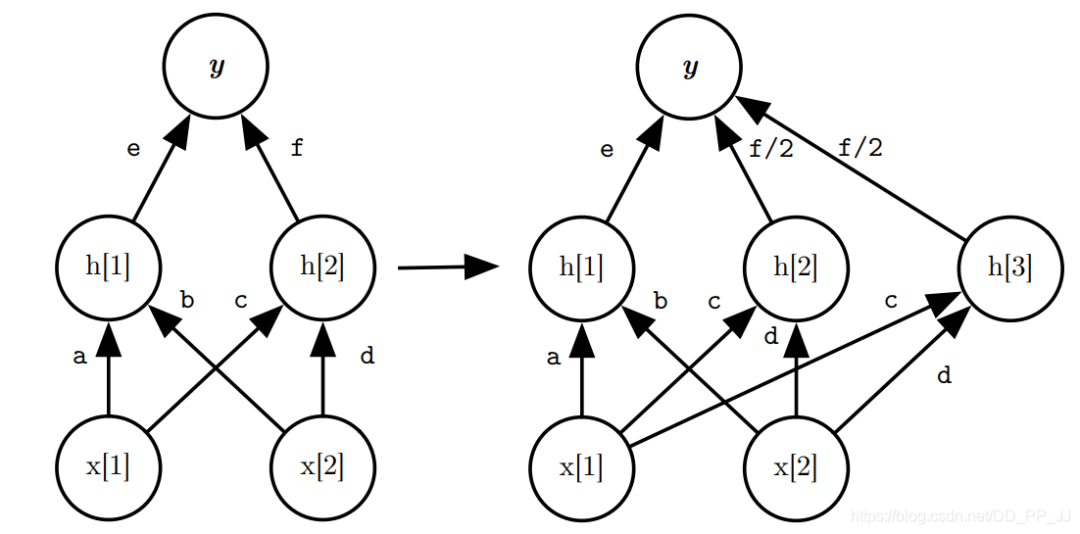
Wider就是隨機從已有節(jié)點中選擇一個節(jié)點復制其權(quán)重,如上圖右側(cè)的h3選擇復制了h2的參數(shù)。對于輸出節(jié)點來說,需要把我們選擇的節(jié)點的值都除以2,這樣就完成了全連接層的恒等替換。(卷積層類似)

Deeper就是加深網(wǎng)絡,對全連接層來說,利用一個單位矩陣做權(quán)值,添加一個和上一個全連接層維度完全相同的全連接層,把前一個全連接層的權(quán)重復制過來,得到更深的網(wǎng)絡。
基于Net2Net,Efficient Architecture Search(EAS)進行了改進,使用強化學習的Agent作為元控制器(meta-controller),其作用是通過“功能保留轉(zhuǎn)換”增加深度或者寬度。
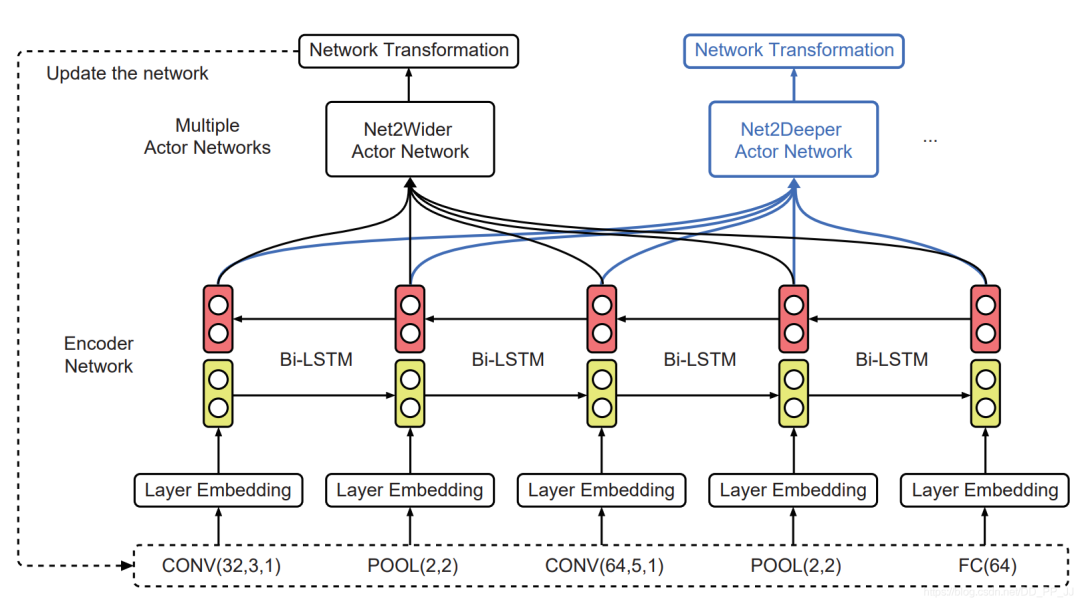
Bi-LSTM就是mata-controller,用來學習底層表達的特征,輸出結(jié)果被送到Net2Wider Actor 和 Net2Deeper Actor用于判斷對模型進行加深或者加寬的操作。
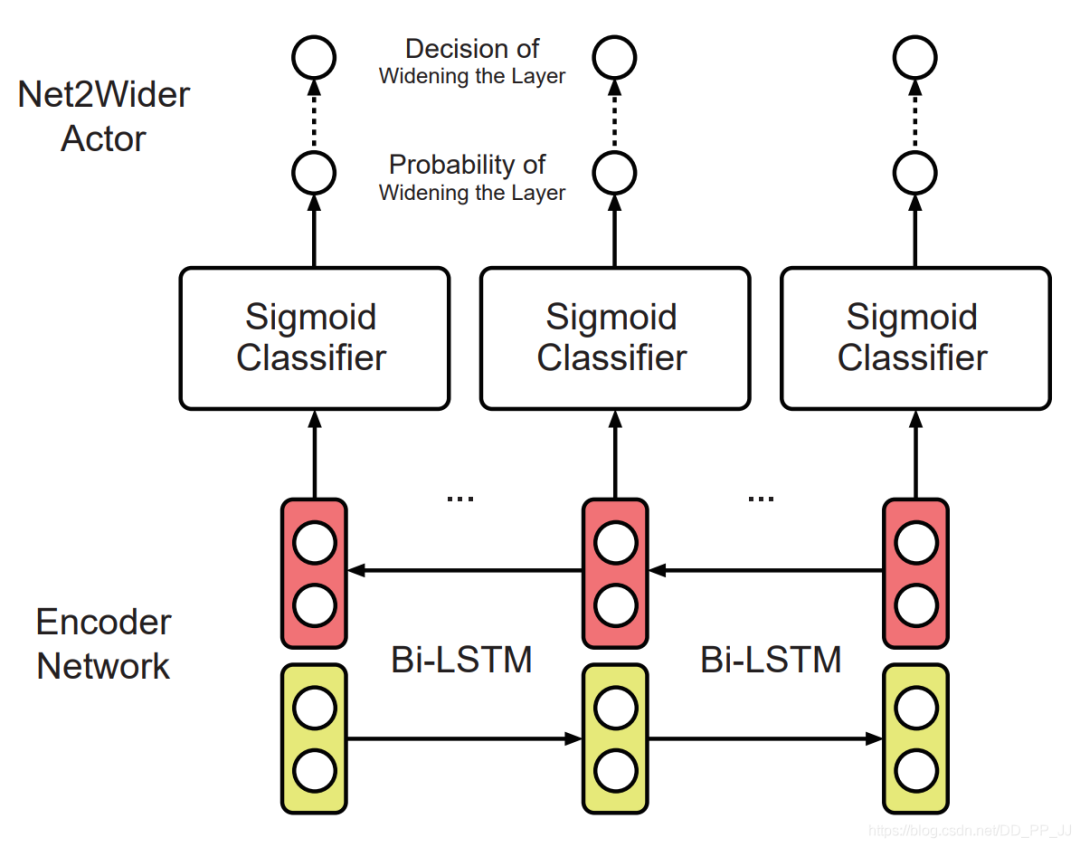
Net2Wider Actor使用共享的Sigmoid分類器基于Encoder輸出結(jié)果來決定是否去加寬每個層。
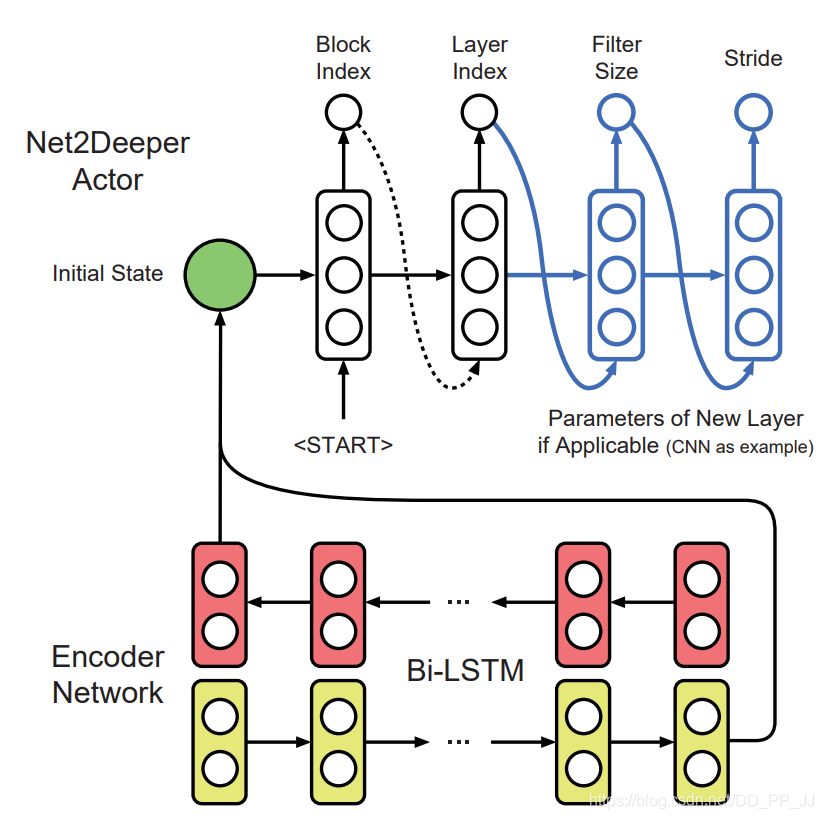
Net2Deeper Actor使用循環(huán)神經(jīng)網(wǎng)絡來順序的決定是否添加一個新的層和對應的網(wǎng)絡參數(shù)。
N2N Learning中沒有使用加寬或者加深的操作,而是考慮通過移除層或者縮小層來壓縮教師網(wǎng)絡。利用強化學習對網(wǎng)絡進行裁剪,從Layer Removal和Layer Shrinkage兩個維度進行裁剪,第一個代表是否進行裁剪,第二個是對一層中的參數(shù)進行裁剪。
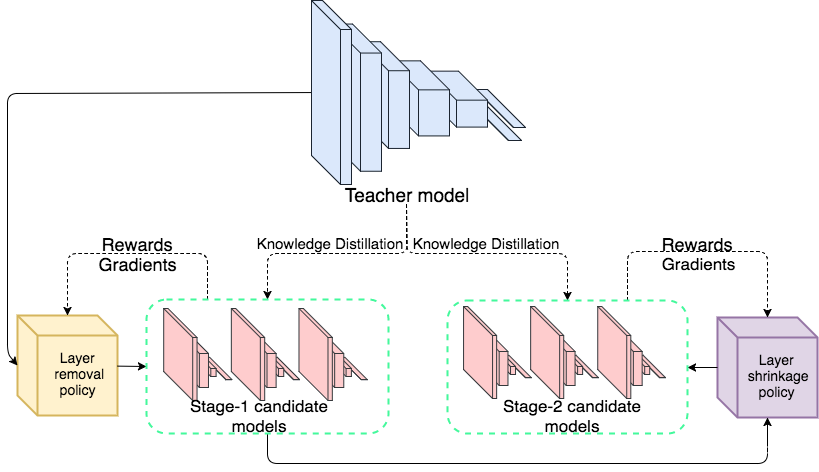
首先使用layer removal操作 然后使用layer shrinkage操作 使用強化學習來探索搜索空間 使用知識蒸餾的方法訓練每個生成得到的網(wǎng)絡架構(gòu)。 最終得到一個局部最優(yōu)的學生網(wǎng)絡。
該方法可以達到10倍數(shù)的壓縮率。
Path-level EAS實現(xiàn)了Path level(一個模塊之內(nèi)的路徑path)的網(wǎng)絡轉(zhuǎn)換。這種想法主要是來源于很多人工設計的多分支網(wǎng)絡架構(gòu)的成功,比如ResNet、Inception系列網(wǎng)絡都使用到了多分支架構(gòu)。Path-level EAS通過用使用多分枝操作替換單個層來完成路徑級別的轉(zhuǎn)換,其中主要有分配策略和合并策略。
分配策略包括Replication和Split:
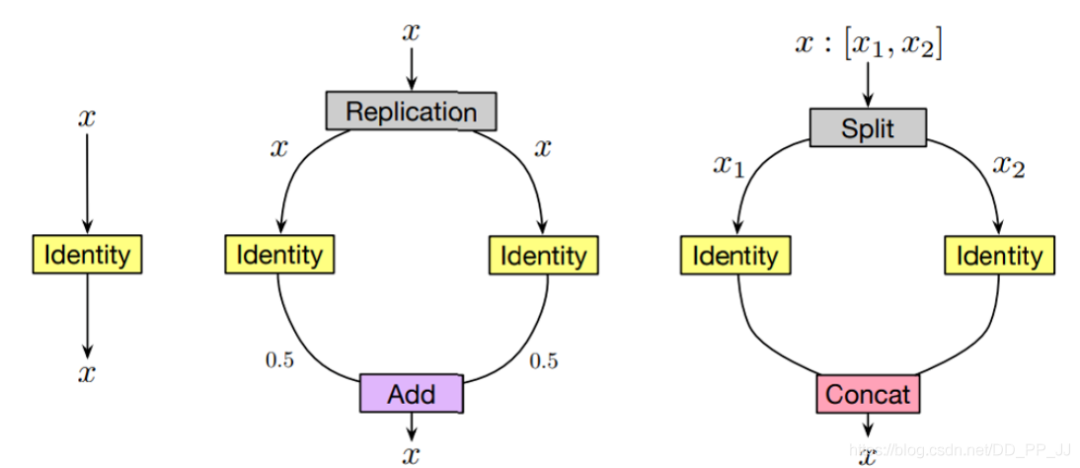
Replication就是將輸入x復制兩份,分別操作以后將得到的結(jié)果除以2再相加得到輸出。 Split就是將x按照維度切成兩份,分別操作以后,將得到的結(jié)果concate到一起。
合并策略包括:add和concatenation
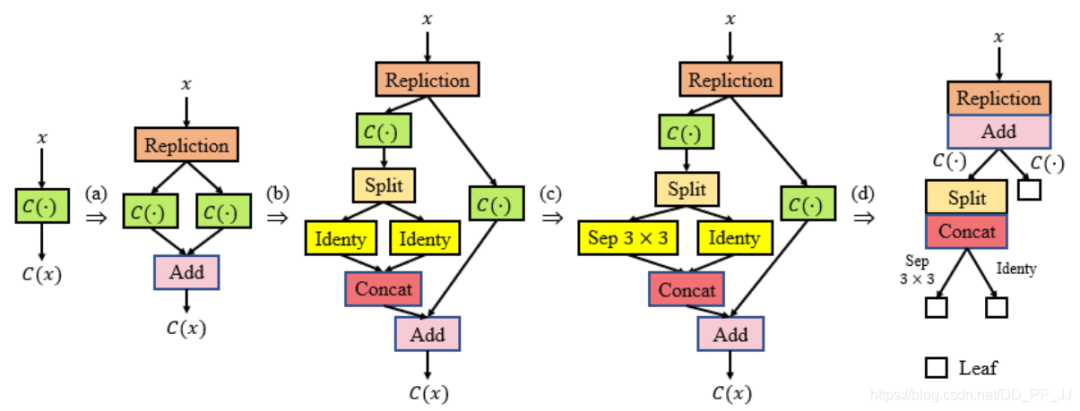
上圖描述的是Path-level EAS的示意圖:
(a)使用了Replication策略
(b)使用了Split策略
(c)將一個恒等映射替換為可分離3x3卷積
(d)表達了(c)中的網(wǎng)絡結(jié)構(gòu)的樹狀結(jié)構(gòu)。
另一個類似的工作,NASH-Net基于Net2Net更進一步提出了四種網(wǎng)絡變形的方法。NASH-Net可以同一個預訓練的模型,使用四種網(wǎng)絡形變方法來生成一系列子網(wǎng)絡,對這些子網(wǎng)絡進行一段時間的訓練以后,找到最好的子網(wǎng)絡。然后從這個子網(wǎng)絡開始,使用基于爬山的神經(jīng)網(wǎng)絡架構(gòu)搜索方法(Neural Architecture Search by Hill-Climbing)來得到最好的網(wǎng)絡架構(gòu)。
之前的網(wǎng)絡通常研究的是圖像分類的骨干網(wǎng)絡,針對分割或者檢測問題的網(wǎng)絡一般無法直接使用分類的骨干,需要針對任務類型進行專門設計。盡管已經(jīng)有一些方法用于探索分割和檢測的骨干網(wǎng)絡了,比如Auto-Deeplab、DetNas等,但是這些方法依然需要預訓練,并且計算代價很高。
FNA(Fast Neural Network Adaptation)提出了一個可以以近乎0代價,將網(wǎng)絡的架構(gòu)和參數(shù)遷移到一個新的任務中。FNA首先需要挑選一個人工設計的網(wǎng)絡作為種子網(wǎng)絡,在其操作集合中將這個種子網(wǎng)絡擴展成一個超網(wǎng)絡,然后使用NAS方法(如DARTS,ENAS,AmoebaNet-A)來調(diào)整網(wǎng)絡架構(gòu)得到目標網(wǎng)絡架構(gòu)。然后使用種子網(wǎng)絡將參數(shù)映射到超網(wǎng)絡和目標網(wǎng)絡進行參數(shù)的初始化。最終目標網(wǎng)絡是在目標任務上進行微調(diào)后的結(jié)果。整個流程如下圖所示:
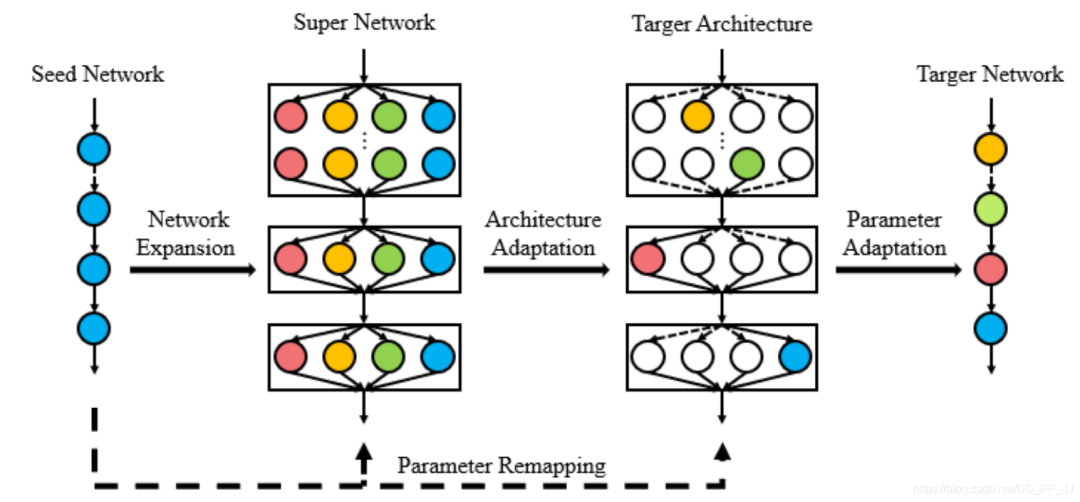
“ps: 分類backbone和其他任務是有一定gap的,FNA認為通過微調(diào)神經(jīng)網(wǎng)絡帶來的收益不如調(diào)整網(wǎng)絡結(jié)構(gòu)帶來的收益)
4.4 不完全訓練
NAS的核心一句話來概括就是使用搜索策略來比較一系列候選網(wǎng)絡結(jié)構(gòu)的模型表現(xiàn)找到其中最好的網(wǎng)絡架構(gòu)。所以如何評判候選網(wǎng)絡也是一個非常重要的問題。
早期的NAS方法就是將候選網(wǎng)絡進行完全的訓練,然后在驗證集上測試候選網(wǎng)絡架構(gòu)的表現(xiàn)。由于候選網(wǎng)絡的數(shù)目非常龐大,這種方法耗時太長。隨后有一些方法被提了出來:
NAS-RL采用了并行和異步的方法來加速候選網(wǎng)絡的訓練 MetaQNN在第一個epoch訓練完成以后就使用預測器來決定是否需要減少learning rate并重新訓練。 Large-scale Evolution方法讓突變的子網(wǎng)絡盡可能繼承父代網(wǎng)絡,對于突變的結(jié)構(gòu)變化較大的子網(wǎng)絡來說,就很難繼承父代的參數(shù),就需要強制重新訓練。
4.4.1 權(quán)重共享
上面的方法中,上一代已經(jīng)訓練好的網(wǎng)絡的參數(shù)直接被廢棄掉了,沒有隨后的網(wǎng)絡充分利用,ENAS首次提出了參數(shù)共享的方法,ENAS認為NAS中的候選網(wǎng)絡可以被認為是一個從超網(wǎng)絡結(jié)構(gòu)中抽取得到的有向無環(huán)子圖
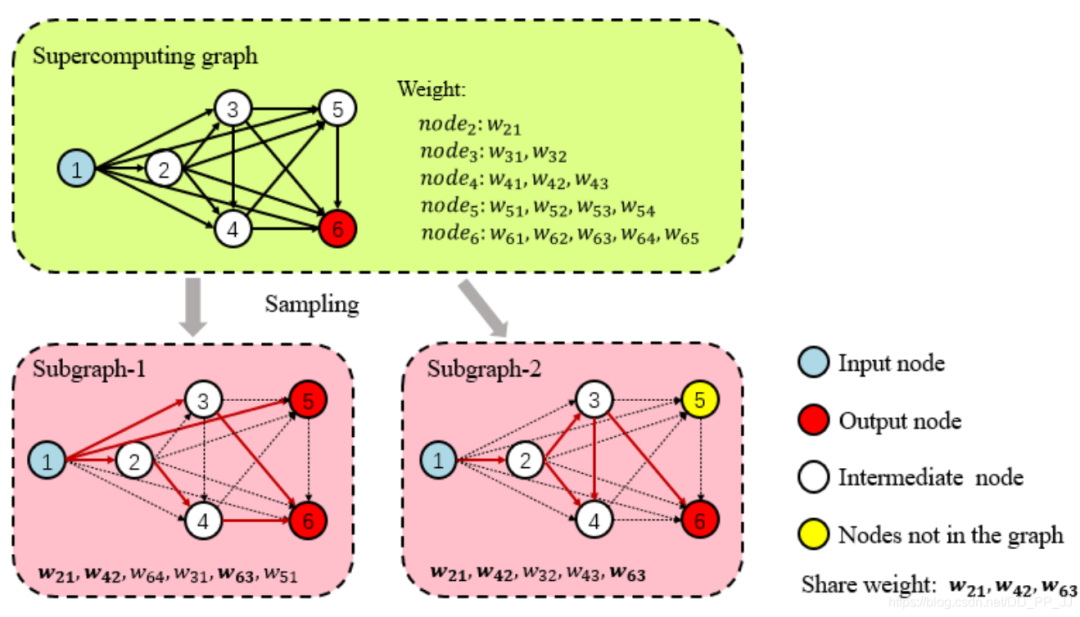
超網(wǎng)絡結(jié)構(gòu)就如上圖綠色框部分所示,是節(jié)點和此節(jié)點之前所有節(jié)點進行連接,然后形成的網(wǎng)絡。兩個紅色框就是從超網(wǎng)絡結(jié)構(gòu)中采樣得到的一個單向無環(huán)圖,這兩個子網(wǎng)絡共享的權(quán)重也就很容易找到。這樣ENAS就可以強制所有子網(wǎng)絡都共享相同的參數(shù)。
然后ENAS使用LSTM作為一個控制器在超網(wǎng)絡結(jié)構(gòu)中找到最優(yōu)子網(wǎng)絡結(jié)構(gòu)。通過這種方法,可以避免讓每個子網(wǎng)絡從頭開始訓練,可以更好地提高網(wǎng)絡的搜索效率。
CAS(Continual and Multi-Task Architecture Search)基于ENAS探索了多任務網(wǎng)絡架構(gòu)搜索問題,可以擴展NAS在不同的數(shù)據(jù)集進行遷移學習的能力。CAS引入了一個新的連續(xù)架構(gòu)搜索方法來解決連續(xù)學習過程中的遺忘問題,從而可以繼承上個任務中的經(jīng)驗,這對于多任務學習來說非常有幫助(感覺可以一定程度上避免過擬合)。
AutoGAN首先將GAN的思想引入NAS,并且使用了Inception Score作為強化學習的獎勵值,使用ENAS中的參數(shù)共享和動態(tài)重設來加速搜索過程。訓練過程中引入了Progressive GAN的技巧,逐漸的實現(xiàn)NAS。
OFA(Once for all)使用了一個彈性Kernel機制來滿足多平臺部署的應用需求和不同平臺的視覺需求的多樣性。小的kernel會和大的kernel共享權(quán)重。在網(wǎng)絡層面,OFA優(yōu)先訓練大的網(wǎng)絡,然后小的網(wǎng)絡會共享大網(wǎng)絡的權(quán)重,這樣可以加速訓練的效率。
此外,基于one-shot的方法也使用到了權(quán)重共享的思想。SMASH提出訓練一個輔助的HyperNet,然后用它來為其他候選網(wǎng)絡架構(gòu)來生成權(quán)重。此外,SMASH對利用上了訓練早期的模型表現(xiàn),為排序候選網(wǎng)絡結(jié)構(gòu)提供了有意義的指導建議。
One-Shot Models這篇文章討論了SMASH中的HyperNetwork和ENAS中的RL Controller的必要性,并認為不需要以上兩者就可以得到一個很好的結(jié)果。
Graph HyperNetwork(GHN)推薦使用計算圖來表征網(wǎng)絡結(jié)構(gòu),然后使用GNN來完成網(wǎng)絡架構(gòu)搜索。GHN可以通過圖模型來預測所有的自由權(quán)重,因此GHN要比SMASH效果更好,預測精度更加準確。
典型的one-shot NAS需要從HyperNet中通過權(quán)重共享的方式采樣得到一系列候選網(wǎng)絡,然后進行評估找到最好的網(wǎng)絡架構(gòu)。STEN提出從這些采樣得到的候選網(wǎng)絡中很難找到最好的架構(gòu),這是因為共享的權(quán)重與可學習的網(wǎng)絡架構(gòu)的參數(shù)緊密耦合。這些偏差會導致可學習的網(wǎng)絡架構(gòu)的參數(shù)偏向于簡單的網(wǎng)絡,并且導致候選網(wǎng)絡的良好率很低。因為簡單的網(wǎng)絡收斂速度要比復雜網(wǎng)絡要快,所以會導致HyperNet中的參數(shù)是偏向于完成簡單的網(wǎng)絡架構(gòu)。
STEN提出了使用一個均勻的隨機訓練策略來平等的對待每一個候選網(wǎng)絡,這樣他們可以被充分訓練來得到更加準確的驗證集表現(xiàn)。此外,STEN還使用了評價器來學習候選網(wǎng)絡具有較低驗證損失的概率,這樣極大地提升了候選網(wǎng)絡的優(yōu)秀率。
《Evaluating the search phase of neural architecture search》也認為ENAS中的權(quán)重共享策略會導致NAS很難搜索得到最優(yōu)的網(wǎng)絡架構(gòu)。此外,F(xiàn)airNAS的研究和《 Improving One-shot NAS by Suppressing the Posterior Fading》中顯示基于參數(shù)共享方法的網(wǎng)絡結(jié)構(gòu)很難被充分訓練,會導致候選網(wǎng)絡架構(gòu)不準確的排序。
在DARTS、FBNet、ProxyLessNas這種同時優(yōu)化超網(wǎng)絡權(quán)重和網(wǎng)絡參數(shù)的方法,會在子模型之間引入偏差。為了這個目的,DNA( Blockwisely Supervised Neural Architecture Search with Knowledge Distillation)提出將神經(jīng)網(wǎng)絡結(jié)構(gòu)劃分為互不影響的block,利用蒸餾的思想,引入教師模型來引導網(wǎng)絡搜索的方向。通過網(wǎng)絡搜索空間獨立分塊的權(quán)重共享訓練,降低了共享權(quán)重帶來的表征偏移的問題。
GDAS-NSAS也是希望提升one-shot Nas的權(quán)重共享機制,提出了一個NSAS的損失函數(shù)來解決多模型遺忘(當使用權(quán)重共享機制訓練的時候,在訓練一個新的網(wǎng)絡架構(gòu)的時候,上一個網(wǎng)絡架構(gòu)的表現(xiàn)會變差)的問題。
可微分的NAS使用了類似的權(quán)重共享策略,比如DARTS選擇訓練一個超網(wǎng)絡,然后選擇最好的子網(wǎng)絡。ENAS這類方法則是訓練從超網(wǎng)絡中采樣得到的子網(wǎng)絡
4.4.2 訓練至收斂
在NAS中,是否有必要將每個候選網(wǎng)絡都訓練至收斂呢?答案是否定的。
為了更快的分析當前模型的有效性,研究人員可以根據(jù)學習曲線來判斷當前模型是否有繼續(xù)訓練下去的價值。如果被判定為沒有繼續(xù)訓練的價值,就應該及早終止,盡可能節(jié)約計算資源和減少訓練時間。
那么NAS也應該采取相似的策略,對于沒有潛力的模型,應及早停止訓練;對于有希望的網(wǎng)絡結(jié)構(gòu)則應該讓其進行充分的訓練。
《Speeding up automatic hyperparameter optimization of deep neural networks by extrapolation of learning curves》一文中就提出了使用概率性方法來模擬網(wǎng)絡的學習曲線。但是這種方法需要長時間的前期學習才能準確的模擬和預測學習曲線。
《Learning curve prediction with Bayesian neural networks》改進了上述方法,學習曲線的概率模型可以跨超參數(shù)設置,采用成熟的學習曲線提高貝葉斯神經(jīng)網(wǎng)絡的性能。
以上方法是基于部分觀測到的早期性能進行預測學習曲線,然后設計對應的機器學習模型來完成這個任務。為了更好的模擬人類專家,《Accelerating neural architecture search using performance prediction》首先將NAS和學習曲線預測結(jié)合到了一起,建立了一個標準的頻率回歸模型,從網(wǎng)絡結(jié)構(gòu)、超參數(shù)和早期學習曲線得到對應的最簡單的特征。利用這些特征對頻率回歸模型進行訓練,然后結(jié)合早期訓練經(jīng)驗預測網(wǎng)絡架構(gòu)最終驗證集的性能。
PNAS中也用到了性能預測。為了避免訓練和驗證所有的子網(wǎng)絡,PNAS提出了一個預測器函數(shù),基于前期表現(xiàn)進行學習,然后使用預測器來評估所有的候選模型,選擇其中topk個模型,然后重復以上過程直到獲取到了足夠數(shù)量的模型。
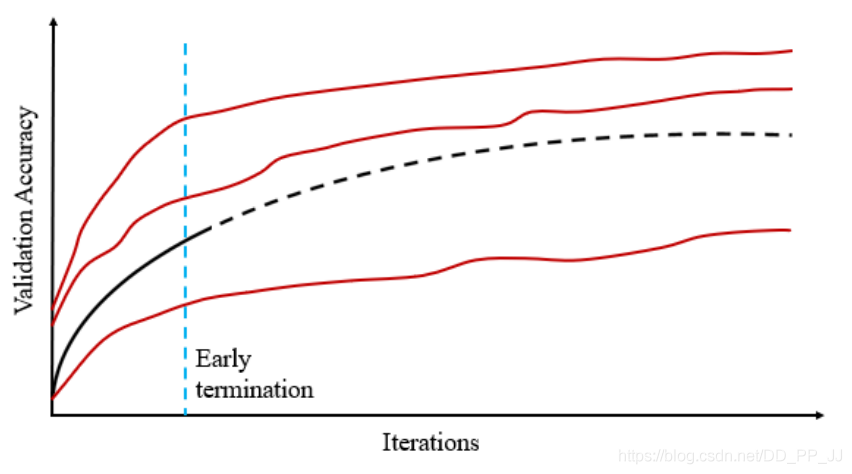
上圖就是一個示意圖,在早停點停止以后,預測器可以預測網(wǎng)絡隨后的狀態(tài),得到預測的學習曲線。
NAO將網(wǎng)絡架構(gòu)的連續(xù)表示作為編碼器輸入,將性能預測器作為梯度上升的優(yōu)化目標。通過最大化性能預測器f的輸出,就可以獲得最佳網(wǎng)絡結(jié)構(gòu)的連續(xù)表示。最終使用解碼器來得到最終的離散的網(wǎng)絡架構(gòu)。
MdeNAS提出了一個性能排序假說:訓練前期就表現(xiàn)出色的模型,往往在收斂以后會得到一個很好的結(jié)果。MdeNAS做了很多實驗來驗證這個假說,通過候選網(wǎng)絡框架的初期表現(xiàn)就可以得到相對的性能排序,可以加速搜索過程。
5. 性能對比
這一節(jié)主要是對主流的NAS方法進行比較,同時報告各自采用的優(yōu)化策略。這些策略包括:
reinforcement learning(RL) evolutionary algorithm(EA) gradient optimization(GO) random search(RS) sequential model-based optimization(SMBO)
實際上NAS之間的性能對比非常困難,原因如下:
缺少baseline(通常隨機搜索策略會被認為是一個強有力的baseline) 預處理、超參數(shù)、搜索空間、trick等不盡相同
CIFAR10上結(jié)果對比:
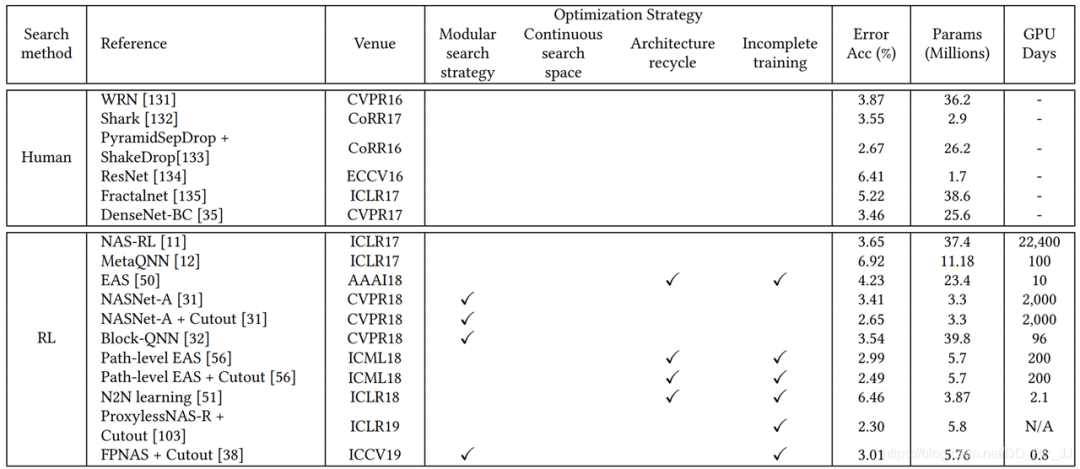
Human是從人工設計的網(wǎng)絡中挑選了幾個代表作為錯誤率和參數(shù)量的對照。
RL代表使用強化學習方法進行網(wǎng)絡結(jié)構(gòu)搜索, 方法中包括了上文提到的NAS-RL、EAS、NASNet等方法,綜合來看還是FPNAS效果最好。
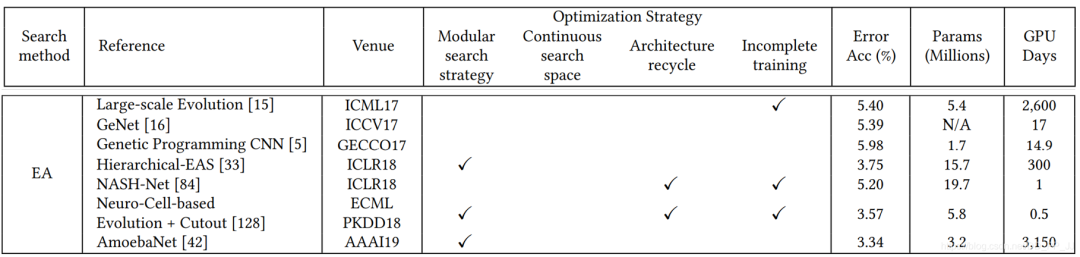
可以看到進化算法普遍用的GPU時間比較高,不過NASH-Net和Evolution用時很少的情況下也能達到不錯的表現(xiàn)。
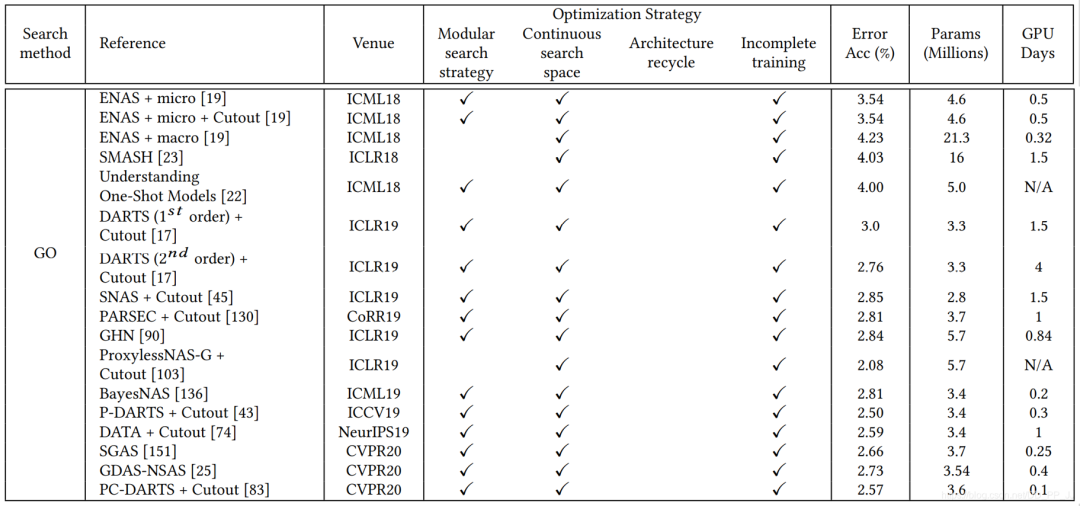
這部分算法主要是以DARTS、ENAS為代表的,所用的GPU days普遍比較低,效果很好。
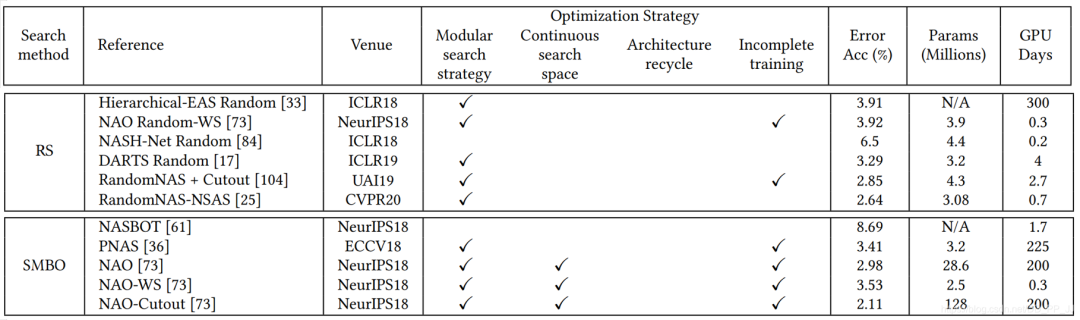
上圖展示的是分別是隨機搜索的方法和基于順序模型的優(yōu)化策略的效果。
ImageNet上的結(jié)果對比:
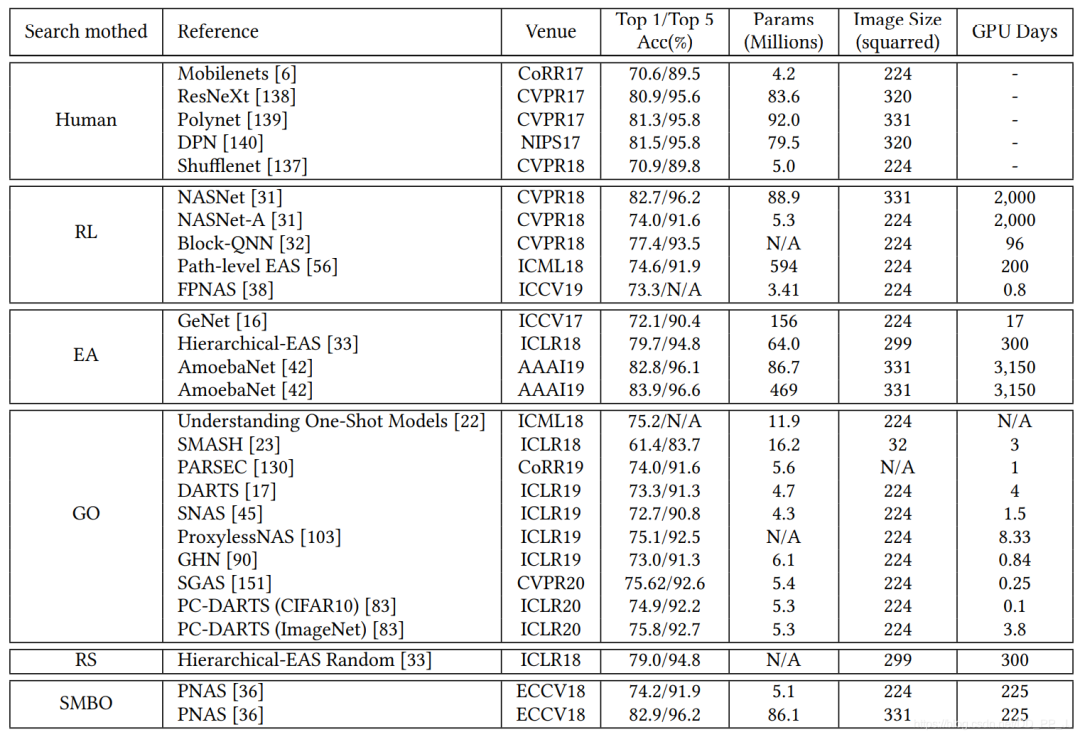
通過對比以上兩個表格,可以得到以下結(jié)論:
模塊化搜索策略應用非常廣泛,因為可以減低搜索空間的復雜度, 但是并沒有證據(jù)表明模塊化搜索就一定要比全局搜索最終性能要好。 不完全訓練策略也是用很多,讓候選網(wǎng)絡rank的過程變得非常有效率。 基于梯度的優(yōu)化方法(如DARTS)與其他策略相比,可以減少搜索的代價,有很多工作都是基于DARTS進行研究的。 隨機搜索策略也達成了非常有競爭力的表現(xiàn),但是相對而言這方面工作比較少。 遷移學習的技術(shù)在這里應用比較廣泛,先在小數(shù)據(jù)集進行搜索(被稱為代理任務),然后在大的數(shù)據(jù)集上遷移。 ProxyLessNas也研究了如何直接在大型數(shù)據(jù)集上直接進行搜索的方法。
6. 未來的方向
人工設計的網(wǎng)絡在很多領(lǐng)域都取得了突破性進展,比如圖像識別、機器翻譯、語義分割、目標檢測、視頻理解等。盡管NAS方面的研究非常豐富,但是與人工設計的網(wǎng)絡相比,NAS還處于研究的初級階段。當前的NAS主要集中于提升圖像分類的準確率,減少模型搜索的時間,讓NAS盡可能地平民化(甚至單卡也能訓)。
此外,一個合適的baseline對NAS來說非常重要,可以防止NAS研究的搜索策略淹沒在各種增強技術(shù),正則化技術(shù)和搜索空間設計的trick。NAS目前的搜索策略相對集中于基于梯度策略的方法,但這種方法還有許多的理論上的缺陷,還需要進一步發(fā)展。
早期NAS的設計目標就是盡可能減少人工干預(比如Large-scale Evolution),讓算法自動的決定網(wǎng)絡進化的方向,但是這種方法往往會需要大量的計算資源,讓普通的研究者難以承受。所以隨后的NAS開始討論如何盡可能減少搜索空間的同時提升網(wǎng)絡的性能(比如NASNet使用模塊化搜索策略來減小搜索代價)。模塊化搜索確實極大的減小了搜索空間,但是也限制了網(wǎng)絡設計的自由度,在這個過程中,并不能確定,模塊化搜索是否限制了最優(yōu)模型的產(chǎn)生。網(wǎng)絡架構(gòu)設計的自由度和搜索的代價是對立的,所以未來一定會有很多工作來平衡這兩者并得到一個不錯的性能。
RobNet提出了使用NAS方法得到很多候選網(wǎng)絡,并分析這些結(jié)構(gòu)中表現(xiàn)好的和表現(xiàn)差的模型之間的結(jié)構(gòu)差異。一個可行的方案就是分析有希望的模型架構(gòu),并提高這種架構(gòu)在搜索空間中的比例,降低性能差模型的比例,這樣就可以逐步縮小搜索空間。
NAS另外一個廣受批判的問題就是缺乏baseline和可共享的實驗性協(xié)議,因此NAS算法之間的對比就非常困難。雖然隨即搜索算法被認為是一個強有力的baseline,但是相關(guān)工作仍然不夠充分。《Evaluating the search phase of neural architecture search》一文就支持了當前最優(yōu)的NAS算法甚至是能達到和隨機搜索相近的性能,這應該引起相關(guān)研究人員的警覺。因此,需要更多的消融實驗來證明其有效性,并且研究人員應該更加注意分析NAS設計中到底哪部分起到了關(guān)鍵性作用。單純的堆trick而達到較高的性能是應該被批判的。
還有一個需要注意的問題就是權(quán)重共享,盡管這個策略可以提高NAS搜索算法的效率,但是越來越多的證據(jù)和研究表明權(quán)重共享策略會導致次優(yōu)的候選網(wǎng)絡架構(gòu)排名。這會導致NAS幾乎不可能在搜索空間中找到最優(yōu)的模型。
NAS目前主流研究方向都集中于圖像分類和降低搜索代價,其他更復雜的網(wǎng)絡架構(gòu)設計,比如多目標架構(gòu)搜索、網(wǎng)絡遷移、模型壓縮、目標檢測和圖像分割等領(lǐng)域都沒有足夠的工作開展。
短期來看,NAS的出現(xiàn)令人激動,但是目前,NAS仍處于發(fā)展的初級階段,還需要更多的理論指導和實驗性分析。想要用NAS來完全取代人工設計網(wǎng)絡還需要更多的研究和更堅實的理論基礎。
7. 結(jié)語
這篇文章讀了大概有一周,文章涉及到的內(nèi)容非常多,NAS的分支比較復雜,每個分支都有很多出色的工作和理論。由于筆者自身水平有限,正在學習這方面的內(nèi)容,有些地方翻譯的內(nèi)容難免理解上存在偏差,可能并不到位,歡迎批評指正。
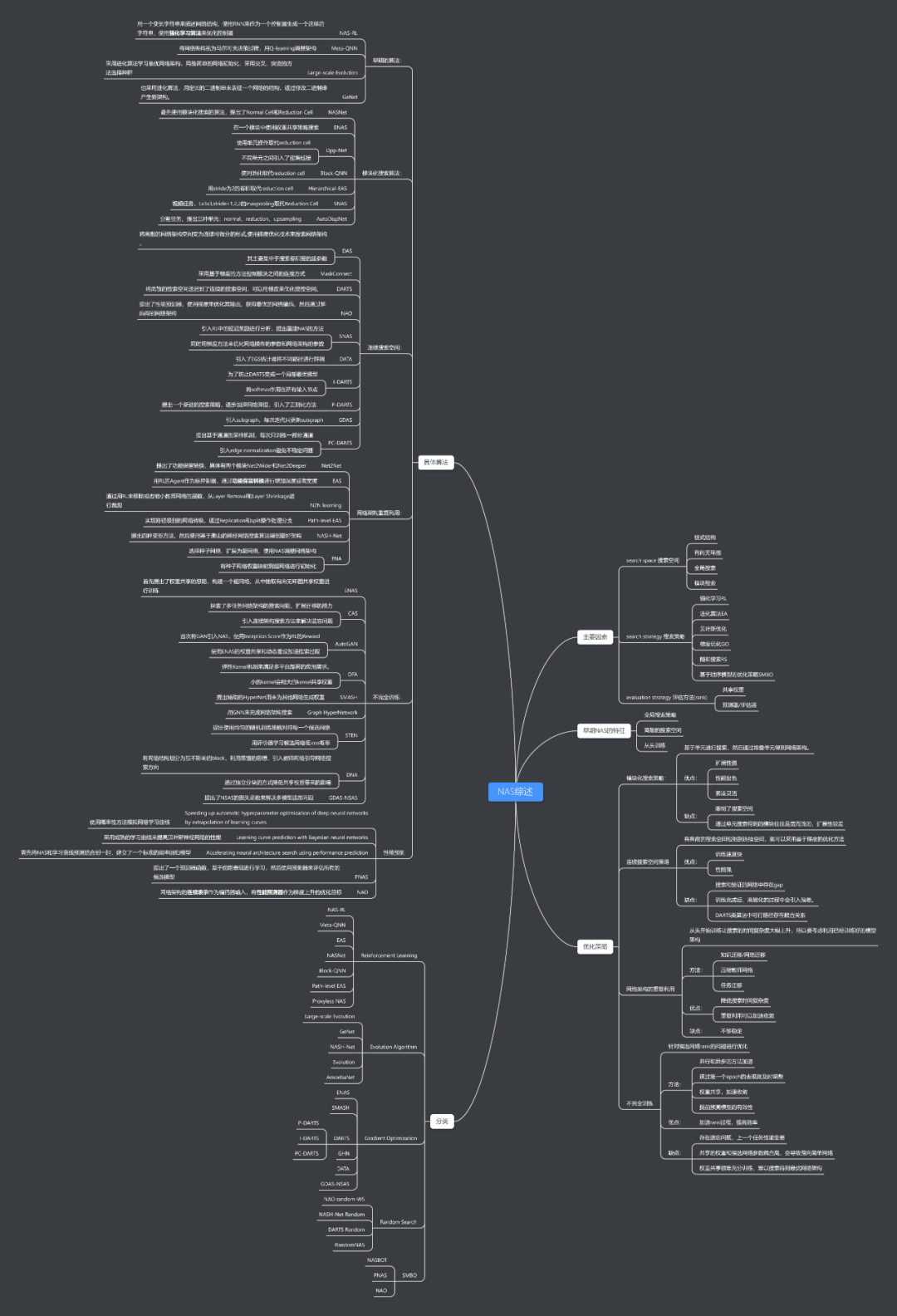
通讀完以后,感覺在腦子中并沒有形成非常鮮明的框架,并且文章中涉及到的論文用一兩段話是很難講明白的,所以這篇文章相當于一個NAS的指導手冊,在入門之前可以閱讀一下,留下各個算法的印象,然后根據(jù)文章提供的論文列表進行閱讀。待讀完一定數(shù)量的論文以后,再回過頭來通讀,相信應該能串聯(lián)起來。為了讓文章更清晰,根據(jù)文章內(nèi)容整理了一個思維導圖:
8. 參考文獻
https://arxiv.org/abs/2006.02903
https://www.cc.gatech.edu/classes/AY2021/cs7643_fall/slides/L22_nas.pdf
https://www.media.mit.edu/projects/architecture-selection-for-deep-neural-networks/overview/
https://blog.csdn.net/cFarmerReally/article/details/80927981
https://cloud.tencent.com/developer/article/1470080
Net2Net: http://xxx.itp.ac.cn/pdf/1511.05641
EAS:https://arxiv.org/abs/1707.04873
E2E learning: https://blog.csdn.net/weixin_30602505/article/details/98228471
Path-level EAS: https://blog.csdn.net/cFarmerReally/article/details/80887271
FNA:https://zhuanlan.zhihu.com/p/219774377
AmoebaNet: https://blog.csdn.net/vectorquantity/article/details/108625172
ENAS:https://zhuanlan.zhihu.com/p/35339663
歡迎加入GiantPandaCV交流群,可以添加筆者微信入群