
一份最新的、全面的NLP文本分類綜述|模型&代碼&技巧

Paper:Deep Learning Based Text Classification: A Comprehensive Review(Computer Science, Mathematics-ArXiv)2020
Link:https://arxiv.org/pdf/2004.03705.pdf
這是一份最新的、全面的NLP文本分類綜述,也是在你入門之后,想要進(jìn)一步挖掘、深入閱讀自己感興趣的領(lǐng)域方向的一份指南。
文本討論的基于深度學(xué)習(xí)的模型在各種文本分類任務(wù)(包括情感分析,新聞分類,問題回答和自然語言推理)已經(jīng)超越了基于經(jīng)典機(jī)器學(xué)習(xí)的方法。
TL; DR
提供了150多個用于文本分類的深度學(xué)習(xí)模型的詳細(xì)概述,它們的技術(shù)貢獻(xiàn),相似性和優(yōu)勢。 介紹了使用深度學(xué)習(xí)模型構(gòu)建文本分類器的方法。 給出了如何給自己的任務(wù)選擇最佳的神經(jīng)網(wǎng)絡(luò)模型的建議。 總結(jié)了40多個流行的文本分類數(shù)據(jù)集。 在16個主流的基準(zhǔn)上進(jìn)行深度學(xué)習(xí)模型性能的定量分析。 討論了基于深度學(xué)習(xí)的文本分類現(xiàn)存的挑戰(zhàn)和未來的方向。
其他關(guān)鍵詞和短語:文本分類,情感分析,問題解答,新聞分類,深度學(xué)習(xí),自然語言推理,主題分類。
1 文本分類任務(wù)
情感分析 新聞分類 主題分析 問答系統(tǒng) 自然語言推斷(NLI)
2 用于文本分類的深度學(xué)習(xí)模型
本節(jié)回顧了用于文本分類任務(wù)提出的150多種DL(深度學(xué)習(xí))模型。根據(jù)模型結(jié)構(gòu)將這些模型分為幾大類:
前饋網(wǎng)絡(luò)。將文本視為詞袋。 基于RNN的模型。將文本視為一系列單詞,旨在捕獲文本單詞依存關(guān)系和文本結(jié)構(gòu)。 基于CNN的模型。經(jīng)過訓(xùn)練,可以識別文本分類的文本模式(例如關(guān)鍵短語)。 膠囊網(wǎng)絡(luò)(Capsule networks)。解決了CNN在池化操作時所帶來的信息丟失問題。 注意力機(jī)制。可有效識別文本中的相關(guān)單詞,并已成為開發(fā)DL模型的有用工具。 內(nèi)存增強(qiáng)網(wǎng)絡(luò)(Memory-augmented)。將神經(jīng)網(wǎng)絡(luò)與某種外部存儲器結(jié)合在一起,該模型可以讀取和寫入。 圖神經(jīng)網(wǎng)絡(luò)。旨在捕獲自然語言的內(nèi)部圖結(jié)構(gòu),例如句法和語義解析樹。 暹羅神經(jīng)網(wǎng)絡(luò)(Siamese)。專門用于文本匹配,這是文本分類的特殊情況。 混合模型(Hybrid models)。結(jié)合了注意力,RNN,CNN等以捕獲句子和文檔的局部和全局特征。 Transformers。比RNN擁有更多并行處理,從而可以使用GPU高效的(預(yù))訓(xùn)練非常大的語言模型。 監(jiān)督學(xué)習(xí)之外的建模技術(shù),包括使用自動編碼器和對抗訓(xùn)練的無監(jiān)督學(xué)習(xí),以及強(qiáng)化學(xué)習(xí)。
更多詳細(xì)模型內(nèi)容請看原論文。讀者應(yīng)該對基本的DL模型有一定的了解,Goodfellow等人也給讀者推薦了DL教科書,了解更多詳情看[1]。
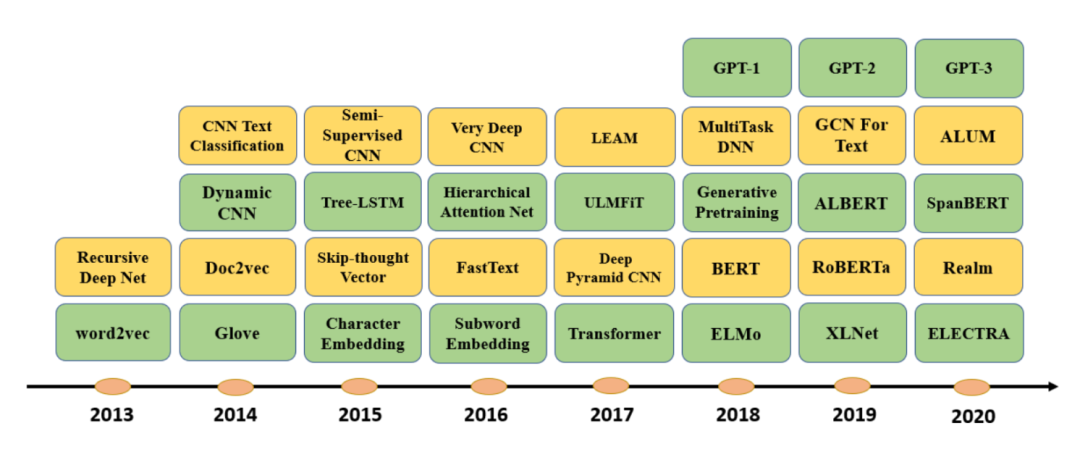
3 如何給自己的任務(wù)選擇最佳的神經(jīng)網(wǎng)絡(luò)模型
對于文本分類任務(wù)來說最佳的神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)是什么?這取決于目標(biāo)任務(wù)和領(lǐng)域,領(lǐng)域內(nèi)標(biāo)簽的可用性,應(yīng)用程序的延遲和容量限制等,這些導(dǎo)致選擇差異會很大。盡管毫無疑問,開發(fā)一個文本分類器是反復(fù)試錯的過程,但通過在公共基準(zhǔn)(例如GLUE [2])上分析最近的結(jié)果,我們提出了以下方法來簡化該過程,該過程包括五個步驟:
選擇PLM(PLM,pretraining language model預(yù)訓(xùn)練語言模型):使用PLM可以顯著改善所有流行的文本分類任務(wù),并且自動編碼的PLM(例如BERT或RoBERTa)通常比自回歸PLM(例如OpenAI GPT)更好。Hugging face擁有為各種任務(wù)開發(fā)的豐富的PLM倉庫。 領(lǐng)域適應(yīng)性:大多數(shù)PLM在通用領(lǐng)域的文本語料庫(例如Web)上訓(xùn)練。如果目標(biāo)領(lǐng)域與通用的領(lǐng)域有很大的不同,我們可以考慮使用領(lǐng)域內(nèi)的數(shù)據(jù),不斷地預(yù)訓(xùn)練該P(yáng)LM來調(diào)整PLM。對于具有大量未標(biāo)記文本的領(lǐng)域數(shù)據(jù),例如生物醫(yī)學(xué),從頭開始進(jìn)行語言模型的預(yù)先訓(xùn)練也可能是一個不錯的選擇[3]。 特定于任務(wù)的模型設(shè)計。給定輸入文本,PLM在上下文表示中產(chǎn)生向量序列。然后,在頂部添加一個或多個特定任務(wù)的層,以生成目標(biāo)任務(wù)的最終輸出。特定任務(wù)層的體系結(jié)構(gòu)的選擇取決于任務(wù)的性質(zhì),例如,需要捕獲文本的語言結(jié)構(gòu)。比如,前饋神經(jīng)網(wǎng)絡(luò)將文本視為詞袋,RNN可以捕獲單詞順序,CNN擅長識別諸如關(guān)鍵短語之類的模式,注意力機(jī)制可以有效地識別文本中的相關(guān)單詞,而暹羅神經(jīng)網(wǎng)絡(luò)則可以用于文本匹配任務(wù),如果自然語言的圖形結(jié)構(gòu)(例如,分析樹)對目標(biāo)任務(wù)有用,那么GNN可能是一個不錯的選擇。 特定于任務(wù)的微調(diào)整。根據(jù)領(lǐng)域內(nèi)標(biāo)簽的可用性,可以使用固定的PLM單獨(dú)訓(xùn)練特定任務(wù)的層,也可以與PLM一起訓(xùn)練特定任務(wù)的層。如果需要構(gòu)建多個相似的文本分類器(例如,針對不同領(lǐng)域的新聞分類器),則多任務(wù)微調(diào)[23]是利用相似領(lǐng)域的標(biāo)記數(shù)據(jù)的好選擇。 模型壓縮。PLM成本很高。它們通常需要通過例如知識蒸餾[4,5]進(jìn)行壓縮,以滿足實(shí)際應(yīng)用中的延遲和容量限制。
4 文本分類的主流數(shù)據(jù)集
根據(jù)主要目標(biāo)任務(wù)將各種文本分類數(shù)據(jù)集分為情感分析,新聞分類,主題分類,問答系統(tǒng)和NLI自然語言推斷等類別。
情感分析數(shù)據(jù)集
Yelp。Yelp [6]數(shù)據(jù)集包含兩種情感分類任務(wù)的數(shù)據(jù)。一種是檢測細(xì)粒度的標(biāo)簽,稱為Yelp-5。另一個預(yù)測負(fù)面和正面情緒,被稱為“ Yelp評論極性”或“ Yelp-2”。Yelp-5每個類別有650,000個訓(xùn)練樣本和50,000個測試樣本,Yelp-2包含560,000個訓(xùn)練樣本和38,000個針對積極和消極類的測試樣本。 IMDb。IMDB數(shù)據(jù)集[7]是為電影評論的二分類情感分類任務(wù)而開發(fā)的。IMDB由相等數(shù)量的正面和負(fù)面評論組成。它在訓(xùn)練和測試集之間平均分配,每個測試集有25,000條評論。 電影評論(Movie Review)。電影評論(MR)數(shù)據(jù)集[8]是電影評論的集合,其目的是檢測與特定評論相關(guān)的情緒并確定其是負(fù)面還是正面的。它包括10,662個句子,帶有負(fù)面和正面的樣本。通常使用10倍交叉驗證和隨機(jī)拆分來對此數(shù)據(jù)集進(jìn)行測試。 SST。斯坦福情感樹庫(SST)數(shù)據(jù)集[9]是MR的擴(kuò)展版本。有兩個版本可用,一個帶有細(xì)粒度標(biāo)簽(五類),另一個帶有二分類的標(biāo)簽,分別稱為SST-1和SST-2。SST-1包含11855條電影評論,分為8544個訓(xùn)練樣本,1101個開發(fā)樣本和2210個測試樣本。SST-2分為三組,分別為訓(xùn)練集,開發(fā)集和測試集,大小分別為6,920、872和1,821。 MPQA。多視角問答(MPQA)數(shù)據(jù)集[10]是具有兩個類別標(biāo)簽的觀點(diǎn)語料庫。MPQA包含從與各種新聞來源相關(guān)的新聞文章中提取的10606個句子,這是一個不平衡的數(shù)據(jù)集,包含3,311個肯定文檔和7,293個否定文檔。 亞馬遜Amazon。這是從亞馬遜網(wǎng)站[11]收集的熱門產(chǎn)品評論集。它包含用于二分類和多類(5類)分類的標(biāo)簽。Amazon二進(jìn)制分類數(shù)據(jù)集包含3,600,000條和40萬條評論,分別用于培訓(xùn)和測試。亞馬遜5級分類數(shù)據(jù)集(Amazon-5)分別包含3,000,000條評論和650,000條關(guān)于訓(xùn)練和測試的評論。
新聞分類數(shù)據(jù)集
AGNews。AGNews數(shù)據(jù)集[12]是學(xué)術(shù)新聞搜索引擎ComeToMyHead從2000多個新聞源收集的新聞文章的集合。該數(shù)據(jù)集包括120,000個訓(xùn)練樣本和7,600個測試樣本。每個樣本都是帶有四類標(biāo)簽的短文本。 20個新聞組。20個新聞組數(shù)據(jù)集[13]是張貼在20個不同主題上的新聞組文檔的集合。此數(shù)據(jù)集的各種版本用于文本分類,文本聚類等等。最受歡迎的版本之一包含18,821個文檔,該文檔在所有主題中平均分類。 搜狗新聞。搜狗新聞數(shù)據(jù)集[14]是搜狗CA和搜狗CS新聞?wù)Z料的混合。新聞的分類標(biāo)簽由URL中的域名決定。例如,URL為http://sports.sohu.com的新聞被歸為體育類。 路透社新聞Reuters。Reuters-21578數(shù)據(jù)集[15]是用于文本分類的最廣泛使用的數(shù)據(jù)收集之一,它是從1987年建立了路透社金融新聞專線。ApteMod是Reuters-21578的多類版本,具有10,788個文檔。它有90個課程,7,769個培訓(xùn)文檔和3,019個測試文檔。從路透社數(shù)據(jù)集的子集派生的其他數(shù)據(jù)集包括R8,R52,RCV1和RCV1-v2。為新聞分類開發(fā)的其他數(shù)據(jù)集包括:Bing新聞[16],BBC [17],Google新聞[18]。
主題分類數(shù)據(jù)集
DBpedia。DBpedia數(shù)據(jù)集[19]是大規(guī)模的多語言知識庫,它是根據(jù)Wikipedia中最常用的信息框創(chuàng)建的。DBpedia每月發(fā)布一次,并且在每個發(fā)行版中添加或刪除一些類和屬性。DBpedia最受歡迎的版本包含560,000個訓(xùn)練樣本和70,000個測試樣本,每個樣本都帶有14類標(biāo)簽。 Ohsumed。Ohsumed集合[20]是MEDLINE數(shù)據(jù)庫的子集。總計包含7,400個文檔。每個文檔都是醫(yī)學(xué)摘要,用從23種心血管疾病類別中選擇的一個或多個類別來標(biāo)記。 EUR-Lex。EUR-Lex數(shù)據(jù)集[21]包含不同類型的文檔,它們根據(jù)幾種正交分類方案進(jìn)行索引,以允許多個搜索設(shè)施。該數(shù)據(jù)集的最流行版本基于歐盟法律的不同方面,有19,314個文檔和3,956個類別。 WOS。Web Of Science(WOS)數(shù)據(jù)集[22]是可從以下網(wǎng)站獲取的已發(fā)表論文的數(shù)據(jù)和元數(shù)據(jù)的集合Web of Science,是世界上最受信任的發(fā)行商獨(dú)立的全球引文數(shù)據(jù)庫。WOS已發(fā)布三個版本:WOS-46985,WOS-11967和WOS-5736。WOS-46985是完整的數(shù)據(jù)集。WOS-11967和WOS-5736是WOS-46985的兩個子集。 PubMed。PubMed [23]是由美國國家醫(yī)學(xué)圖書館為醫(yī)學(xué)和生物科學(xué)論文開發(fā)的搜索引擎,其中包含文檔集合。每個文檔都標(biāo)有MeSH集的類,而MeSH集是PubMed中使用的標(biāo)簽集。摘要中的每個句子均使用以下類別之一標(biāo)記其摘要中的角色:背景,目標(biāo),方法,結(jié)果或結(jié)論。 其他用于主題分類的數(shù)據(jù)集包括PubMed 200k RCT [24],Irony(由anno組成)來自社交新聞網(wǎng)站reddit的注解,Twitter數(shù)據(jù)集(用于推文的主題分類,arXivcollection)[25],僅舉幾例。
QA問答數(shù)據(jù)集
SQuAD。Stanford問答數(shù)據(jù)集(SQuAD)[26]是從Wikipedia文章派生的問題-答案對的集合。在SQuAD中,問題的正確答案可以是給定文本中的任何令牌序列。由于問題和答案是由人類通過眾包產(chǎn)生的,因此它比其他一些問答數(shù)據(jù)集更具多樣性。SQuAD 1.1包含536篇文章中的107,785個問題-答案對。最新版本的SQuAD2.0將SQuAD1.1中的100,000個問題與超過50,000個由反抗工作者以對抗形式寫的對抗性問題相結(jié)合[27] 。 MS MARCO。此數(shù)據(jù)集由Microsoft[28]發(fā)布。不像SQuAD那樣所有的問題都是由編輯產(chǎn)生的;在MS MARCO中,所有的問題都是使用必應(yīng)搜索引擎從用戶的查詢和真實(shí)的網(wǎng)絡(luò)文檔中抽取的。MS MARCO的一些回答是有創(chuàng)造力的。因此,該數(shù)據(jù)集可用于生成QA系統(tǒng)的開發(fā)。 TREC-QA。TREC-QA [29]是用于QA研究的最受歡迎和研究最多的數(shù)據(jù)集之一。該數(shù)據(jù)集有兩個版本,稱為TREC-6和TREC-50。TREC-6分為6個類別的問題,而TREC-50則為20個類別。對于這兩個版本,訓(xùn)練和測試數(shù)據(jù)集分別包含5,452和500個問題。 WikiQA。WikiQA數(shù)據(jù)集[30]由一組問題-答案對組成,它們被收集并注釋以用于開放域QA研究。該數(shù)據(jù)集還包含沒有正確答案的問題,使研究人員可以評估答案觸發(fā)模型。 Quora。Quora數(shù)據(jù)庫[31]用于釋義識別(檢測重復(fù)的問題)。為此,作者提出了Quora數(shù)據(jù)的子集,該子集包含超過40萬個問題對。為每個問題對分配一個二進(jìn)制值,指示兩個問題是否相同。其他質(zhì)量檢查數(shù)據(jù)集包括對抗生成情況(SWAG)[32],WikiQA [30],SelQA [33]。
NLI數(shù)據(jù)集
SNLI。斯坦福自然語言推理(SNLI)數(shù)據(jù)集[34]被廣泛用于NLI。該數(shù)據(jù)集由550,152、10,000和10,000個句子對組成,分別用于訓(xùn)練,開發(fā)和測試。每對使用三個標(biāo)簽之一進(jìn)行注釋:中立,包含,矛盾。 Multi-NLI。多體裁自然語言推理(MNLI)數(shù)據(jù)集[35]是一個433k句子對的集合,這些句子對帶有文本包含標(biāo)簽。語料庫是SNLI的擴(kuò)展,涵蓋了廣泛的口語和書面語體裁,并支持獨(dú)特的跨體裁概括評估 SICK。包含構(gòu)詞知識的句子數(shù)據(jù)集(SICK)[36]包含大約10,000個英語句子對,并用三個標(biāo)簽進(jìn)行注釋:蘊(yùn)涵,矛盾和中立。 MSRP。MicrosoftResearch Paraphrase(MSRP)數(shù)據(jù)集[37]通常用于文本相似性任務(wù)。MSRP包括用于訓(xùn)練的4,076個樣本和用于測試的1,725個樣本。每個樣本都是一個句子對,并帶有二進(jìn)制標(biāo)記,指示兩個句子是否為釋義。其他NLI數(shù)據(jù)集包括語義文本相似性(STS)[38],RTE [39],SciTail [40],僅舉幾例。
5 實(shí)驗性能分析
在本節(jié)中,我們首先描述一組通常用于評估文本分類模型性能的指標(biāo),然后根據(jù)流行的基準(zhǔn)對一組基于DL的文本分類模型的性能進(jìn)行定量分析。
文本分類的流行評估指標(biāo)
準(zhǔn)確性和錯誤率(Accuracy and Error Rate)。這些是評估分類模型質(zhì)量的主要指標(biāo)。令TP,F(xiàn)P,TN,F(xiàn)N分別表示真積極,假積極,真消極和假消極。分類精度和錯誤率在等式中定義如下:
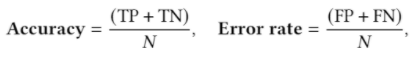
??是樣本總數(shù)。顯然,我們的 Error Rate= 1-Accuracy 。
精度/召回率/ F1分?jǐn)?shù)(Precision / Recall / F1 score)。這些也是主要指標(biāo),在不平衡的測試集中比準(zhǔn)確性或錯誤率更常用,例如,大多數(shù)測試樣品都帶有一個類別標(biāo)簽。二進(jìn)制分類的精度和召回率定義為3. F1分?jǐn)?shù)是精度和查全率的調(diào)和平均值,如等式。3. F1分?jǐn)?shù)在1(最佳精度和召回率)達(dá)到最佳值,在0達(dá)到最差值
 對于多類別分類問題,我們始終可以為每個類別標(biāo)簽計算精度和召回率,并分析類別標(biāo)簽上的各個性能,或者對這些值取平均值以獲取整體精度和召回率。
對于多類別分類問題,我們始終可以為每個類別標(biāo)簽計算精度和召回率,并分析類別標(biāo)簽上的各個性能,或者對這些值取平均值以獲取整體精度和召回率。
Exact Match(EM)。精確匹配度量標(biāo)準(zhǔn)是問答系統(tǒng)的一種流行度量標(biāo)準(zhǔn),它可以測量與任何一個基本事實(shí)答案均精確匹配的預(yù)測百分比。EM是用于SQuAD的主要指標(biāo)之一。 Mean Reciprocal Rank(MRR)。MRR通常用于評估NLP任務(wù)中的排名算法的性能,例如查詢文檔排名和QA。MRR在等式中定義。在圖4中,??是所有可能答案的集合,,是真相答案的排名位置。
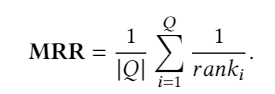 其他廣泛使用的指標(biāo)包括平均精度Mean Average Precision(MAP),曲線下面積 Area Under Curve(AUC),錯誤發(fā)現(xiàn)率False DiscoveryRate,錯誤遺漏率False Omission Rate,僅舉幾例。
其他廣泛使用的指標(biāo)包括平均精度Mean Average Precision(MAP),曲線下面積 Area Under Curve(AUC),錯誤發(fā)現(xiàn)率False DiscoveryRate,錯誤遺漏率False Omission Rate,僅舉幾例。
定量結(jié)果
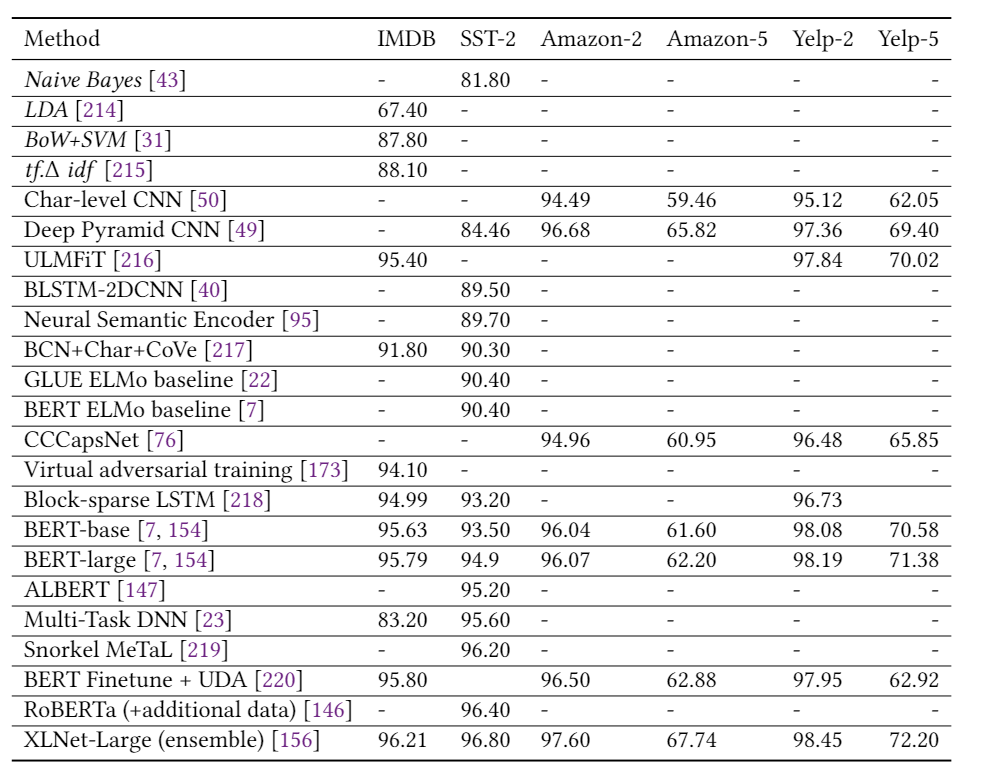
我們將先前討論的幾種算法在流行的TC基準(zhǔn)上的性能列表化。在每個表中,除了一組代表性的DL模型的結(jié)果之外,我們還使用非深度學(xué)習(xí)模型來介紹結(jié)果,該模型不是現(xiàn)有技術(shù)而是在DL時代之前被廣泛用作基準(zhǔn)。我們可以看到,在所有這些任務(wù)中,DL模型的使用帶來了顯著的改進(jìn)。
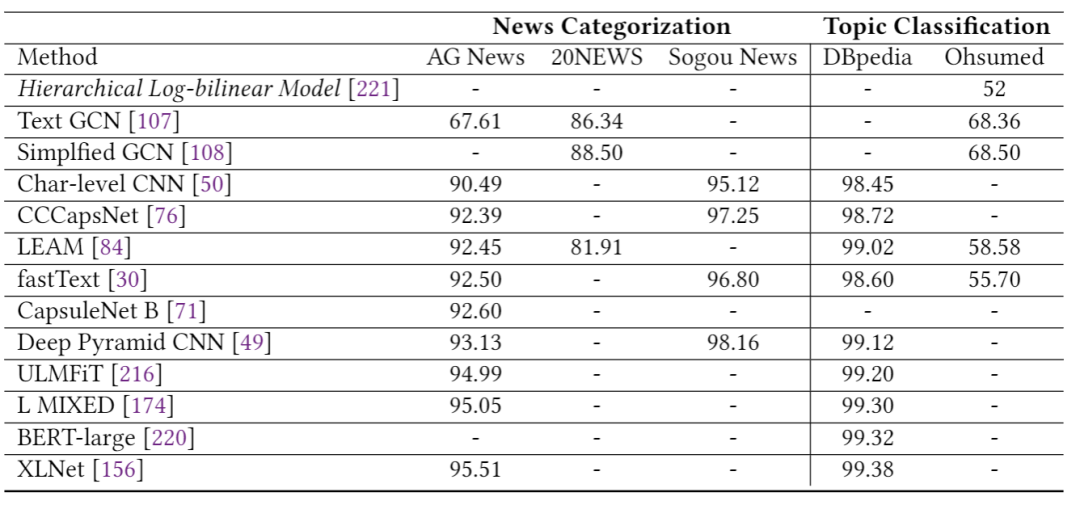
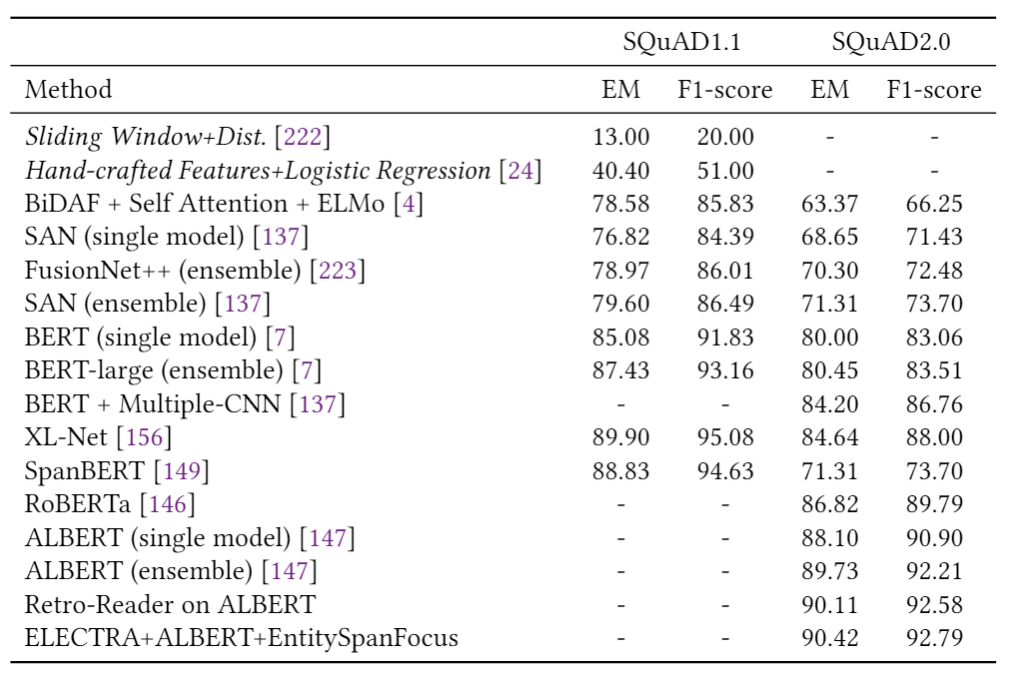
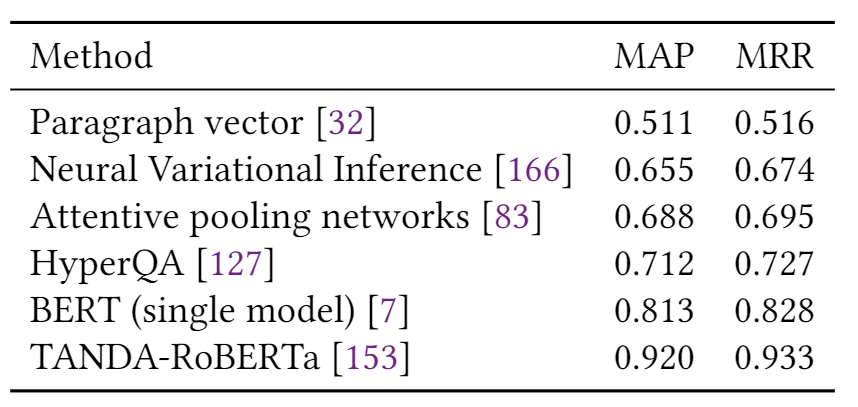
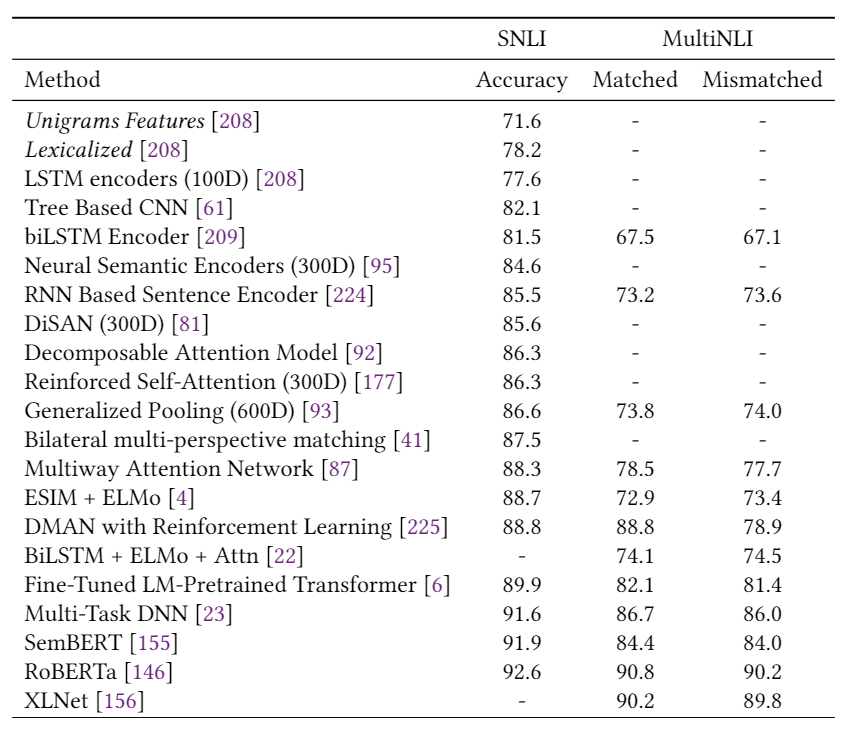
表1總結(jié)了第2節(jié)中描述的模型在多個情感分析數(shù)據(jù)集上的結(jié)果,包括Yelp,IMDB,SST和Amazon。我們可以看到,自從引入第一個基于DL的情感分析模型以來,準(zhǔn)確性得到了顯著提高,例如,相對減少的分類誤差(在SST-2上約為78%)。 表2報告了三個新聞分類數(shù)據(jù)集的性能(即AG新聞,20-新聞,搜狗新聞)和兩個主題分類數(shù)據(jù)集(即DBpedia和Ohsummed)。觀察到與情緒分析相似的趨勢。 表3和表4分別顯示了一些DL模型在SQuAD和WikiQA上的性能。值得注意的是,這兩個數(shù)據(jù)集的顯著性能提升都?xì)w功于BERT的使用。 表5給出了兩個NLI數(shù)據(jù)集(即SNLI和MNLI)的結(jié)果。在過去的5年中,我們觀察到兩個數(shù)據(jù)集的性能都有穩(wěn)定的提高。
6 挑戰(zhàn)與機(jī)遇
在過去的幾年中,借助DL模型,文本分類取得了很大的進(jìn)步。已經(jīng)提出了一些新穎的思路(例如神經(jīng)嵌入,注意力機(jī)制,自我注意力,Transformer,BERT和XLNet),這些思想導(dǎo)致了過去十年的快速發(fā)展。盡管取得了進(jìn)展,但仍有挑戰(zhàn)需要解決。本節(jié)介紹了其中一些挑戰(zhàn),并討論了可以幫助推動該領(lǐng)域發(fā)展的研究方向。
針對更具挑戰(zhàn)性任務(wù)的新數(shù)據(jù)集。盡管近年來已收集了許多常見的文本分類任務(wù)的大規(guī)模數(shù)據(jù)集,但仍需要針對更具挑戰(zhàn)性的文本分類任務(wù)的新數(shù)據(jù)集,例如具有多步推理的QA,針對多語言文檔的文本分類,用于極長的文檔的文本分類。 對常識知識進(jìn)行建模。將常識整合到DL模型中具有潛在地提高模型性能的能力,這幾乎與人類利用常識執(zhí)行不同任務(wù)的方式相同。例如,配備常識性知識庫的QA系統(tǒng)可以回答有關(guān)現(xiàn)實(shí)世界的問題。常識知識還有助于解決信息不完整的情況下的問題。人工智能系統(tǒng)使用廣泛持有的關(guān)于日常對象或概念的信念,可以以與人們類似的方式基于對未知數(shù)的“默認(rèn)”假設(shè)進(jìn)行推理。盡管已經(jīng)對該思想進(jìn)行了情感分類研究,但仍需要進(jìn)行大量研究以探索如何在DL模型中有效地建模和使用常識知識。 不可預(yù)測的DL模型。雖然DL模型在具有挑戰(zhàn)性的基準(zhǔn)上取得了可喜的性能,但是其中大多數(shù)模型都是無法解釋的。例如,為什么一個模型在一個數(shù)據(jù)集上勝過另一個模型,而在其他數(shù)據(jù)集上
本文部分素材來源于網(wǎng)絡(luò),如有侵權(quán),聯(lián)系刪除。
回顧精品內(nèi)容
推薦系統(tǒng)
1、干貨 | 基于用戶的協(xié)同過濾推薦算法原理和實(shí)現(xiàn)
2、超詳細(xì)丨推薦系統(tǒng)架構(gòu)與算法流程詳解
機(jī)器學(xué)習(xí)
自然語言處理(NLP)
1、AI自動評審論文,CMU這個工具可行嗎?我們用它評審了下Transformer論文
2、Transformer強(qiáng)勢闖入CV界秒殺CNN,靠的到底是什么"基因"
計算機(jī)視覺(CV)
1、9個小技巧讓您的PyTorch模型訓(xùn)練裝上“渦輪增壓”...
GitHub開源項目:
1、火爆GitHub!3.6k Star,中文版可視化神器現(xiàn)身
2、兩次霸榜GitHub!這個神器不寫代碼也可以完成AI算法訓(xùn)練
3、OCR神器現(xiàn)世,Star 8.4K,霸榜GitHub
每周推薦:
1、本周優(yōu)秀開源項目分享:無腦套用格式、開源模板最高10萬贊
2、本周優(yōu)秀開源項目分享:YOLOv4的Pytorch存儲庫、用pytorch增強(qiáng)圖像數(shù)據(jù)等7大項目
七月在線學(xué)員面經(jīng)分享:
1、 雙非應(yīng)屆生拿下大廠NLP崗40萬offer:面試經(jīng)驗與路線圖分享
2、轉(zhuǎn)行NLP拿下40萬offer:分享我面試中遇到的54道面試題(含參考答案)
3、NLP面試干貨分享:從自考本科 在職碩士到BAT年薪80萬