
ICCV2021目標(biāo)檢測:主動(dòng)學(xué)習(xí)框架較大提升目標(biāo)檢測精度
點(diǎn)擊下方“AI算法與圖像處理”,一起進(jìn)步!
重磅干貨,第一時(shí)間送達(dá)
計(jì)算機(jī)視覺研究院專欄
作者:Edison_G
新框架優(yōu)于基于單模型的方法,并且以一小部分計(jì)算成本與基于多模型的方法相媲美! 論文下載地址:https://arxiv.org/pdf/2103.16130.pdf

1
概括
2
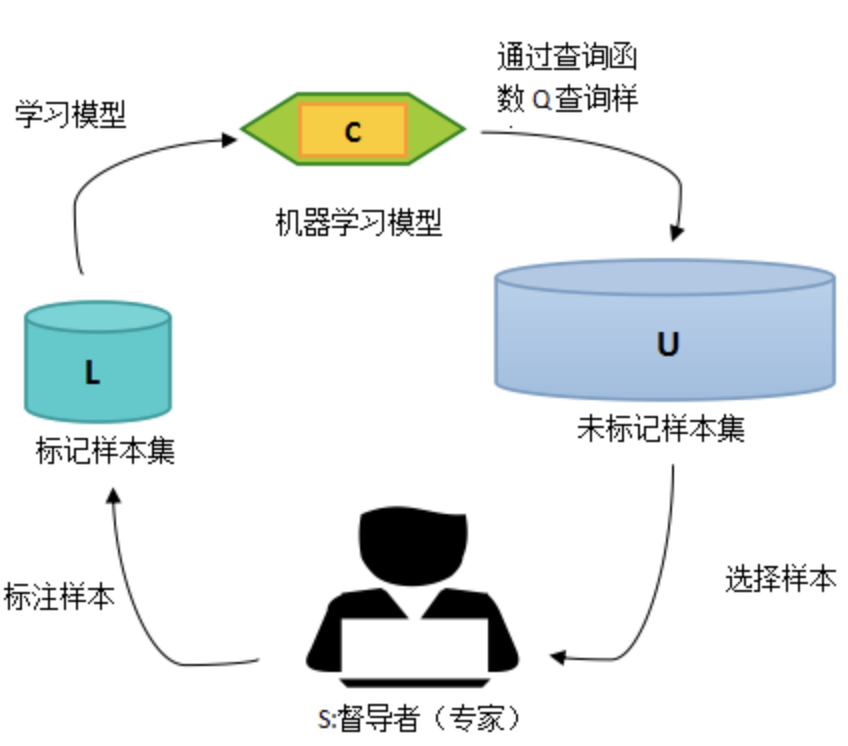
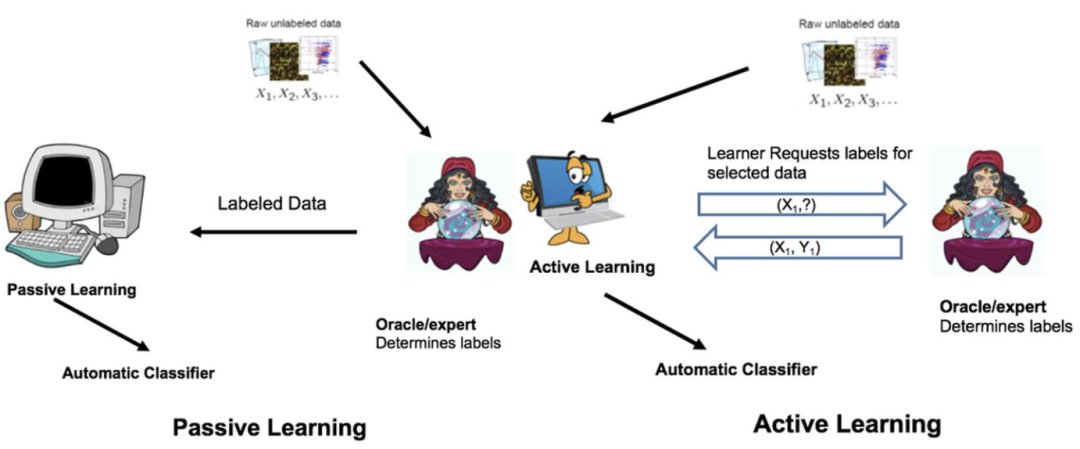
背景
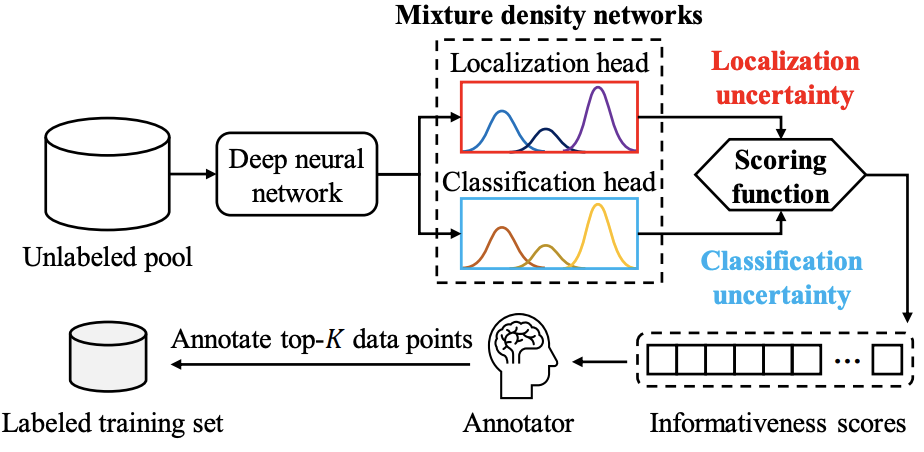
3
新框架
用于目標(biāo)檢測的深度主動(dòng)學(xué)習(xí)最近引起了人們的興趣。 [Scalable active learning for object detection]的工作訓(xùn)練神經(jīng)網(wǎng)絡(luò)的集合,然后選擇由某個(gè)獲取函數(shù)定義的具有最高分?jǐn)?shù)的樣本,即熵或互信息。并發(fā)工作探索了類似的方向,但通過 MC-dropout來近似不確定性。[Active learning for deep detection neural networks]的工作提出了一種計(jì)算像素分?jǐn)?shù)并使用它們來選擇信息樣本的方法。另一種方法[Deep active learning for object detection]提出了通過committee paradigm的查詢來選擇要查詢的圖像集。[Active learning for convolutional neural networks: A core-set approach]的工作使用特征空間來選擇數(shù)據(jù)集中的代表性樣本,在目標(biāo)檢測中達(dá)到了良好的性能。[Localization-aware active learning for object detection]給出了不同的解決方案,其中作者定義了兩個(gè)不同的分?jǐn)?shù):定位緊密度,即區(qū)域候選和最終預(yù)測之間的重疊比;當(dāng)輸入圖像被噪聲破壞時(shí),基于預(yù)測目標(biāo)位置的變化的定位穩(wěn)定性。在所有情況下,選擇得分最高的圖像進(jìn)行標(biāo)記。[Learning loss for active learning]的最先進(jìn)方法提供了一種啟發(fā)式但優(yōu)雅的解決方案,同時(shí)優(yōu)于其他基于單一模型的方法。在訓(xùn)練期間,該方法學(xué)習(xí)預(yù)測每個(gè)樣本的目標(biāo)損失。在主動(dòng)學(xué)習(xí)階段,它選擇標(biāo)記具有最高預(yù)測損失的樣本。
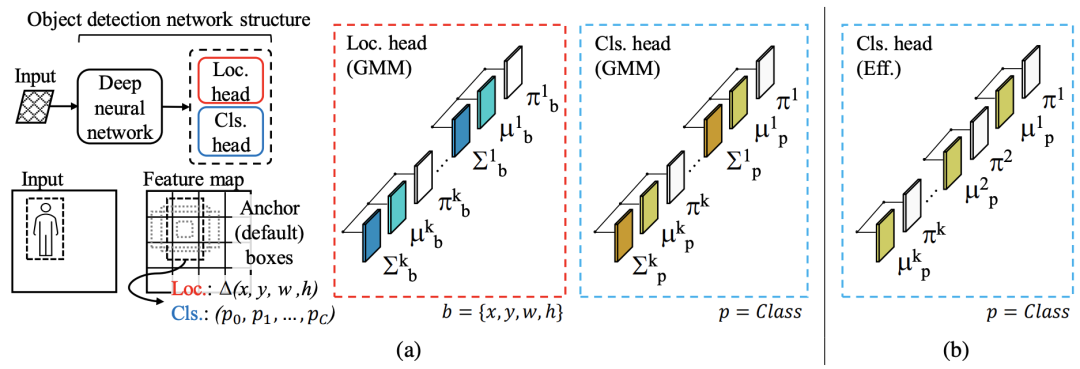
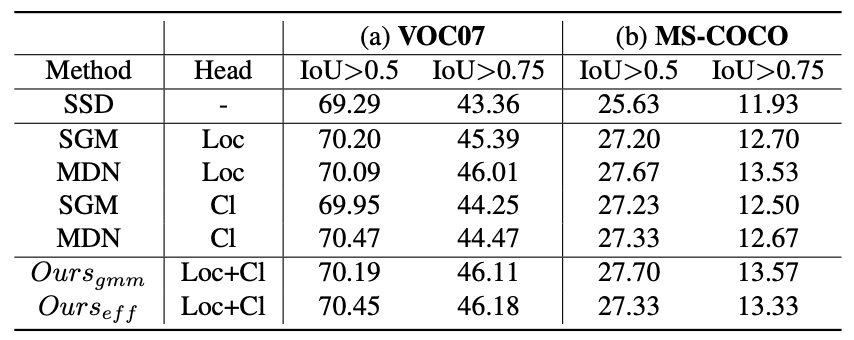
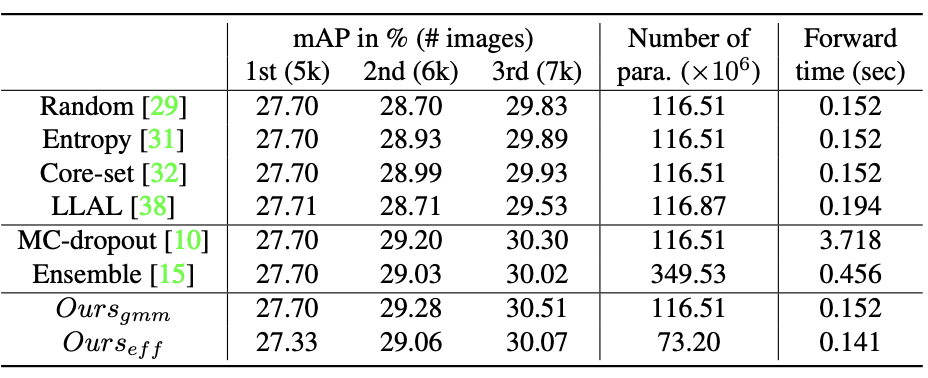
為了預(yù)測輸出值的概率分布,新方法涉及修改網(wǎng)絡(luò)的最后一層,因此導(dǎo)致參數(shù)數(shù)量增加,尤其是在分類頭中。研究者專注于通過減少分類頭中的參數(shù)數(shù)量來提高算法的效率,如上圖b。
4
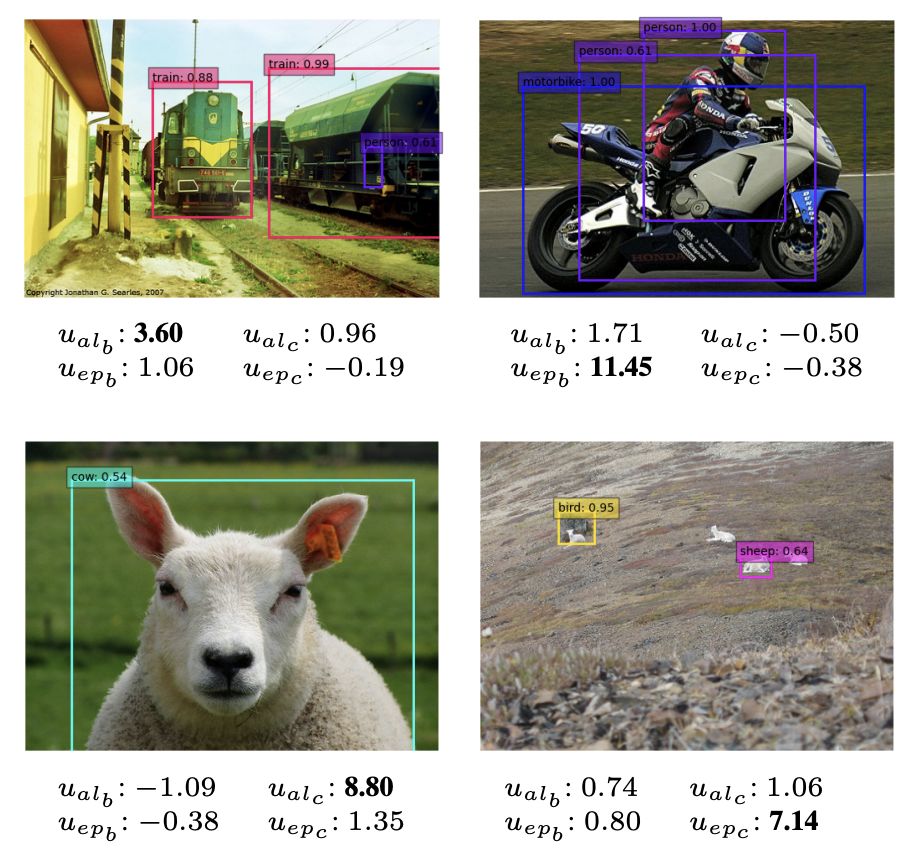
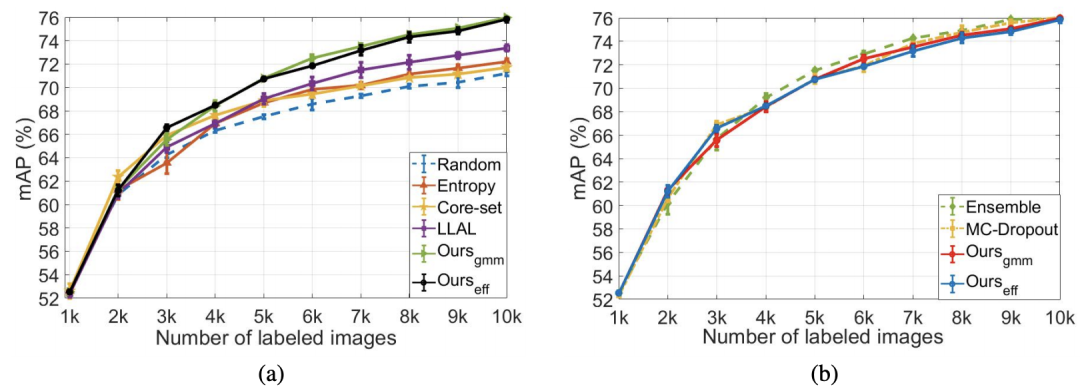
實(shí)驗(yàn)及可視化


努力分享優(yōu)質(zhì)的計(jì)算機(jī)視覺相關(guān)內(nèi)容,歡迎關(guān)注:
個(gè)人微信(如果沒有備注不拉群!) 請(qǐng)注明:地區(qū)+學(xué)校/企業(yè)+研究方向+昵稱
下載1:何愷明頂會(huì)分享
在「AI算法與圖像處理」公眾號(hào)后臺(tái)回復(fù):何愷明,即可下載。總共有6份PDF,涉及 ResNet、Mask RCNN等經(jīng)典工作的總結(jié)分析
下載2:終身受益的編程指南:Google編程風(fēng)格指南
在「AI算法與圖像處理」公眾號(hào)后臺(tái)回復(fù):c++,即可下載。歷經(jīng)十年考驗(yàn),最權(quán)威的編程規(guī)范!
下載3 CVPR2021 在「AI算法與圖像處理」公眾號(hào)后臺(tái)回復(fù):CVPR,即可下載1467篇CVPR 2020論文 和 CVPR 2021 最新論文
點(diǎn)亮  ,告訴大家你也在看
,告訴大家你也在看