
機(jī)器學(xué)習(xí)算法的隨機(jī)數(shù)據(jù)生成
點(diǎn)擊上方“小白學(xué)視覺”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時(shí)間送達(dá) 
在學(xué)習(xí)機(jī)器學(xué)習(xí)算法的過程中,我們經(jīng)常需要數(shù)據(jù)來驗(yàn)證算法,調(diào)試參數(shù)。但是找到一組十分合適某種特定算法類型的數(shù)據(jù)樣本卻不那么容易。還好numpy, scikit-learn都提供了隨機(jī)數(shù)據(jù)生成的功能,我們可以自己生成適合某一種模型的數(shù)據(jù),用隨機(jī)數(shù)據(jù)來做清洗,歸一化,轉(zhuǎn)換,然后選擇模型與算法做擬合和預(yù)測(cè)。下面對(duì)scikit-learn和numpy生成數(shù)據(jù)樣本的方法做一個(gè)總結(jié)。
完整代碼參見github:
https://github.com/ljpzzz/machinelearning/blob/master/mathematics/random_data_generation.ipynb
目錄
1. numpy隨機(jī)數(shù)據(jù)生成API
2. scikit-learn隨機(jī)數(shù)據(jù)生成API介紹
3. scikit-learn隨機(jī)數(shù)據(jù)生成實(shí)例
1. numpy隨機(jī)數(shù)據(jù)生成API
numpy比較適合用來生產(chǎn)一些簡(jiǎn)單的抽樣數(shù)據(jù)。API都在random類中,常見的API有:
1) rand(d0, d1, ..., dn) 用來生成d0×d1×...dn維的數(shù)組 。數(shù)組的值在[0,1)之間
例如: np.random.rand(3,2,2),輸出如下3×2×2的數(shù)組
array([[[ 0.49042678, 0.60643763],
[ 0.18370487, 0.10836908]],
[[ 0.38269728, 0.66130293],
[ 0.5775944 , 0.52354981]],
[[ 0.71705929, 0.89453574],
[ 0.36245334, 0.37545211]]])
2) randn((d0, d1, ..., dn) 也是用來生成d0xd1x...dn維的數(shù)組。不過數(shù)組的值服從N(0,1)的標(biāo)準(zhǔn)正態(tài)分布。
例如:np.random.randn(3,2),輸出如下3x2的數(shù)組,這些值是N(0,1)的抽樣數(shù)據(jù)。
array([[-0.5889483 , -0.34054626],
[-2.03094528, -0.21205145],
[-0.20804811, -0.97289898]])
如果需要服從 的正態(tài)分布,只需要在randn上每個(gè)生成的值x上做變換
的正態(tài)分布,只需要在randn上每個(gè)生成的值x上做變換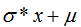 即可 。
即可 。
例如: 2*np.random.randn(3,2) + 1,輸出如下3x2的數(shù)組,這些值是N(1,4)的抽樣數(shù)據(jù)。
array([[ 2.32910328, -0.677016 ],
[-0.09049511, 1.04687598],
[ 2.13493001, 3.30025852]])
3) randint(low[, high, size]),生成隨機(jī)的大小為size的數(shù)據(jù),size可以為整數(shù),為矩陣維數(shù),或者張量的維數(shù)。值位于半開區(qū)間 [low, high)。
例如:np.random.randint(3, size=[2,3,4])返回維數(shù)維2x3x4的數(shù)據(jù),取值范圍為最大值為3的整數(shù)。
array([[[2, 1, 2, 1],
[0, 1, 2, 1],
[2, 1, 0, 2]],
[[0, 1, 0, 0],
[1, 1, 2, 1],
[1, 0, 1, 2]]])
再比如: np.random.randint(3, 6, size=[2,3]) 返回維數(shù)為2x3的數(shù)據(jù)。取值范圍為[3,6).
array([[4, 5, 3],
[3, 4, 5]])
4) random_integers(low[, high, size]),和上面的randint類似,區(qū)別在于取值范圍是閉區(qū)間[low, high]。
5) random_sample([size]),返回隨機(jī)的浮點(diǎn)數(shù),在半開區(qū)間 [0.0, 1.0)。如果是其他區(qū)間[a,b),可以加以轉(zhuǎn)換(b - a) * random_sample([size]) + a
例如: (5-2)*np.random.random_sample(3)+2 返回[2,5)之間的3個(gè)隨機(jī)數(shù)。
array([ 2.87037573, 4.33790491, 2.1662832 ])
2. scikit-learn隨機(jī)數(shù)據(jù)生成API介紹
scikit-learn生成隨機(jī)數(shù)據(jù)的API都在datasets類之中,和numpy比起來,可以用來生成適合特定機(jī)器學(xué)習(xí)模型的數(shù)據(jù)。常用的API有:
1) 用make_regression生成回歸模型的數(shù)據(jù)
2) 用make_hastie_10_2,make_classification或者make_multilabel_classification生成分類模型數(shù)據(jù)
3) 用make_blobs生成聚類模型數(shù)據(jù)
4) 用make_gaussian_quantiles生成分組多維正態(tài)分布的數(shù)據(jù)
3. scikit-learn隨機(jī)數(shù)據(jù)生成實(shí)例
3.1 回歸模型隨機(jī)數(shù)據(jù)
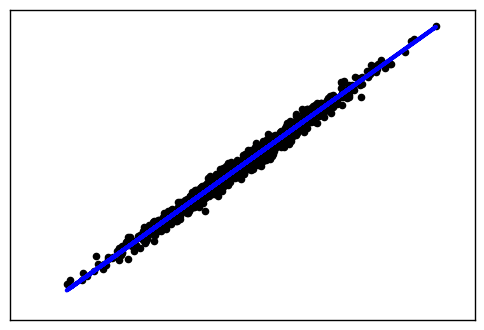
這里我們使用make_regression生成回歸模型數(shù)據(jù)。幾個(gè)關(guān)鍵參數(shù)有n_samples(生成樣本數(shù)), n_features(樣本特征數(shù)),noise(樣本隨機(jī)噪音)和coef(是否返回回歸系數(shù))。例子代碼如下:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets.samples_generator import make_regression
# X為樣本特征,y為樣本輸出, coef為回歸系數(shù),共1000個(gè)樣本,每個(gè)樣本1個(gè)特征
X, y, coef =make_regression(n_samples=1000, n_features=1,noise=10, coef=True)
# 畫圖
plt.scatter(X, y, color='black')
plt.plot(X, X*coef, color='blue',linewidth=3)
plt.xticks(())
plt.yticks(())
plt.show()
輸出的圖如下:
3.2 分類模型隨機(jī)數(shù)據(jù)
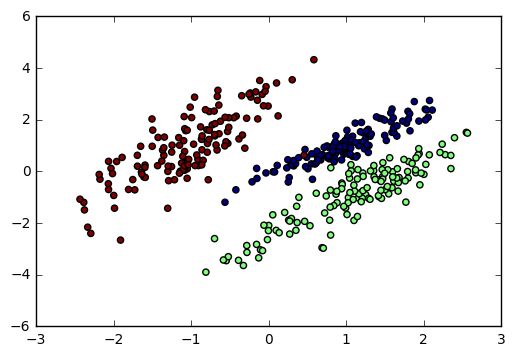
這里我們用make_classification生成三元分類模型數(shù)據(jù)。幾個(gè)關(guān)鍵參數(shù)有n_samples(生成樣本數(shù)), n_features(樣本特征數(shù)), n_redundant(冗余特征數(shù))和n_classes(輸出的類別數(shù)),例子代碼如下:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets.samples_generator import make_classification
# X1為樣本特征,Y1為樣本類別輸出, 共400個(gè)樣本,每個(gè)樣本2個(gè)特征,輸出有3個(gè)類別,沒有冗余特征,每個(gè)類別一個(gè)簇
X1, Y1 = make_classification(n_samples=400, n_features=2, n_redundant=0,
n_clusters_per_class=1, n_classes=3)
plt.scatter(X1[:, 0], X1[:, 1], marker='o', c=Y1)
plt.show()
輸出的圖如下:
3.3 聚類模型隨機(jī)數(shù)據(jù)
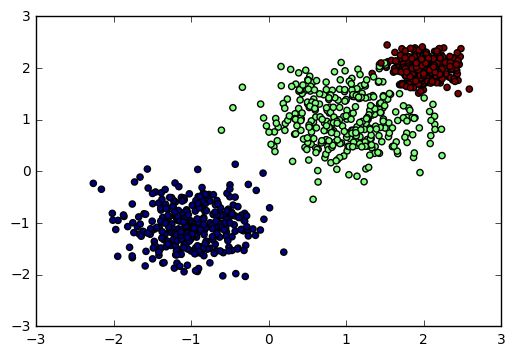
這里我們用make_blobs生成聚類模型數(shù)據(jù)。幾個(gè)關(guān)鍵參數(shù)有n_samples(生成樣本數(shù)), n_features(樣本特征數(shù)),centers(簇中心的個(gè)數(shù)或者自定義的簇中心) 和 cluster_std(簇?cái)?shù)據(jù)方差,代表簇的聚合程度)。例子如下:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets.samples_generator import make_blobs
# X為樣本特征,Y為樣本簇類別, 共1000個(gè)樣本,每個(gè)樣本2個(gè)特征,共3個(gè)簇,簇中心在[-1,-1], [1,1], [2,2], 簇方差分別為[0.4, 0.5, 0.2]
X, y = make_blobs(n_samples=1000, n_features=2, centers=[[-1,-1], [1,1], [2,2]], cluster_std=[0.4, 0.5, 0.2])
plt.scatter(X[:, 0], X[:, 1], marker='o', c=y)
plt.show()
輸出的圖如下:
3.4 分組正態(tài)分布混合數(shù)據(jù)
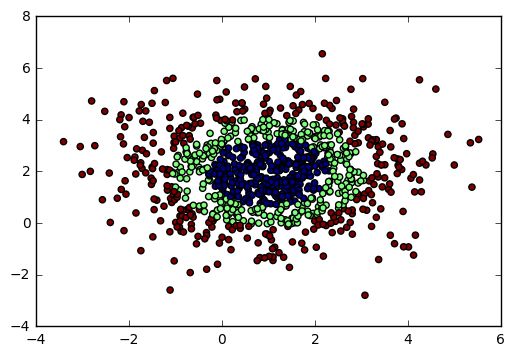
我們用make_gaussian_quantiles生成分組多維正態(tài)分布的數(shù)據(jù)。幾個(gè)關(guān)鍵參數(shù)有n_samples(生成樣本數(shù)), n_features(正態(tài)分布的維數(shù)),mean(特征均值),cov(樣本協(xié)方差的系數(shù)), n_classes(數(shù)據(jù)在正態(tài)分布中按分位數(shù)分配的組數(shù))。例子如下:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_gaussian_quantiles
#生成2維正態(tài)分布,生成的數(shù)據(jù)按分位數(shù)分成3組,1000個(gè)樣本,2個(gè)樣本特征均值為1和2,協(xié)方差系數(shù)為2
X1, Y1 = make_gaussian_quantiles(n_samples=1000, n_features=2, n_classes=3, mean=[1,2],cov=2)
plt.scatter(X1[:, 0], X1[:, 1], marker='o', c=Y1)
輸出圖如下:
以上就是生產(chǎn)隨機(jī)數(shù)據(jù)的一個(gè)總結(jié),希望可以幫到學(xué)習(xí)機(jī)器學(xué)習(xí)算法的朋友們。
下載1:OpenCV-Contrib擴(kuò)展模塊中文版教程
在「小白學(xué)視覺」公眾號(hào)后臺(tái)回復(fù):擴(kuò)展模塊中文教程,即可下載全網(wǎng)第一份OpenCV擴(kuò)展模塊教程中文版,涵蓋擴(kuò)展模塊安裝、SFM算法、立體視覺、目標(biāo)跟蹤、生物視覺、超分辨率處理等二十多章內(nèi)容。
下載2:Python視覺實(shí)戰(zhàn)項(xiàng)目52講 在「小白學(xué)視覺」公眾號(hào)后臺(tái)回復(fù):Python視覺實(shí)戰(zhàn)項(xiàng)目,即可下載包括圖像分割、口罩檢測(cè)、車道線檢測(cè)、車輛計(jì)數(shù)、添加眼線、車牌識(shí)別、字符識(shí)別、情緒檢測(cè)、文本內(nèi)容提取、面部識(shí)別等31個(gè)視覺實(shí)戰(zhàn)項(xiàng)目,助力快速學(xué)校計(jì)算機(jī)視覺。
下載3:OpenCV實(shí)戰(zhàn)項(xiàng)目20講 在「小白學(xué)視覺」公眾號(hào)后臺(tái)回復(fù):OpenCV實(shí)戰(zhàn)項(xiàng)目20講,即可下載含有20個(gè)基于OpenCV實(shí)現(xiàn)20個(gè)實(shí)戰(zhàn)項(xiàng)目,實(shí)現(xiàn)OpenCV學(xué)習(xí)進(jìn)階。
交流群
歡迎加入公眾號(hào)讀者群一起和同行交流,目前有SLAM、三維視覺、傳感器、自動(dòng)駕駛、計(jì)算攝影、檢測(cè)、分割、識(shí)別、醫(yī)學(xué)影像、GAN、算法競(jìng)賽等微信群(以后會(huì)逐漸細(xì)分),請(qǐng)掃描下面微信號(hào)加群,備注:”昵稱+學(xué)校/公司+研究方向“,例如:”張三 + 上海交大 + 視覺SLAM“。請(qǐng)按照格式備注,否則不予通過。添加成功后會(huì)根據(jù)研究方向邀請(qǐng)進(jìn)入相關(guān)微信群。請(qǐng)勿在群內(nèi)發(fā)送廣告,否則會(huì)請(qǐng)出群,謝謝理解~