
機(jī)器學(xué)習(xí)算法-隨機(jī)森林之理論概述
前面我們用 3 條推文從理論和代碼角度講述了決策樹(shù)的概念和粗暴生成。
機(jī)器學(xué)習(xí)算法-隨機(jī)森林之決策樹(shù)R 代碼從頭暴力實(shí)現(xiàn)(3)
機(jī)器學(xué)習(xí)算法-隨機(jī)森林之決策樹(shù)R 代碼從頭暴力實(shí)現(xiàn)(2)
機(jī)器學(xué)習(xí)算法 - 隨機(jī)森林之決策樹(shù)初探(1)
隨機(jī)森林的算法概述
決策樹(shù)我們應(yīng)該都暴力的理解了,下面我們看隨機(jī)森林。
隨機(jī)森林實(shí)際是一堆決策樹(shù)的組合(正如其名,樹(shù)多了就是森林了)。
這是一個(gè)簡(jiǎn)化版的理解,實(shí)際上要復(fù)雜一些。具體怎么做的呢?
假設(shè)有一個(gè)數(shù)據(jù)集包含n個(gè)樣品, p個(gè)變量,也就是一個(gè)n X p的矩陣,采用下面的算法獲得一系列的決策樹(shù):
從數(shù)據(jù)集中有放回地取出
n個(gè)樣品作為訓(xùn)練集,訓(xùn)練1棵決策樹(shù)。假如數(shù)據(jù)集有
6個(gè)樣品[a,b,c,d,e],第一次有放回地取出6個(gè)樣品可能是[a,a,c,d,d,e],第二次有放回地取出6個(gè)樣品可能是[a,c,c,d,e,e]。每棵樹(shù)的訓(xùn)練集是不完全相同的,每個(gè)訓(xùn)練集內(nèi)部包含重復(fù)樣本。
這一步稱為
Bagging (Bootstrap aggregating) 自助聚合。每棵決策樹(shù)構(gòu)建時(shí),通常隨機(jī)抽取
m (m<m在選擇每一層節(jié)點(diǎn)時(shí)不變。每棵決策樹(shù)野蠻生長(zhǎng),不剪枝。
重復(fù)第
1,2,3步t次,獲得t棵決策樹(shù)。
通過(guò)聚合t棵決策樹(shù)做出最終決策:
分類問(wèn)題:
選擇
t棵決策樹(shù)中支持最多的類作為最終分類 (服從多數(shù),majority vote)回歸問(wèn)題:
計(jì)算
t棵決策樹(shù)預(yù)測(cè)的數(shù)值的均值作為最終預(yù)測(cè)值
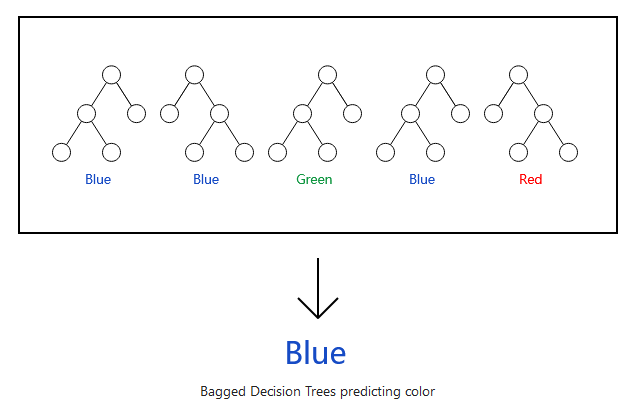
為什么要這么做呢?
在數(shù)據(jù)科學(xué)中,很大數(shù)目的相對(duì)不相關(guān)的模型的群體決策優(yōu)于任何單個(gè)模型的決策。
隨機(jī)森林的錯(cuò)誤率取決于兩個(gè)因素:
不同樹(shù)之間的相關(guān)性越高,則錯(cuò)誤率越大。
這要求
m盡可能小。每個(gè)決策樹(shù)的分類強(qiáng)度越大,則錯(cuò)誤率越小。
這要求
m盡可能大。
m通常為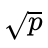 或
或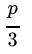 。也可以通過(guò)
。也可以通過(guò)oob (out-of-bag) error rate (自助聚合錯(cuò)誤率)進(jìn)行迭代調(diào)參選擇分類效果最好的m。
隨機(jī)森林工作機(jī)制
通過(guò)有放回采樣的方式構(gòu)建訓(xùn)練集時(shí),通常有1/3的樣品沒(méi)有被選中。這些樣品可以用來(lái)估計(jì)該訓(xùn)練集獲得的決策樹(shù)的分類錯(cuò)誤率 (OOB), 也可以用來(lái)評(píng)估變量的重要性。
每棵決策樹(shù)構(gòu)建好后,用所有的數(shù)據(jù)作為輸入獲得每個(gè)樣品在每個(gè)決策樹(shù)的分類結(jié)果,然后計(jì)算每一對(duì)樣品 (c1, c2)之間的相似度 (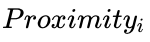 )。如果兩個(gè)樣品分類到相同的分類節(jié)點(diǎn),它們彼此的相似性加一。最終的相似度除以決策樹(shù)的總數(shù) (
)。如果兩個(gè)樣品分類到相同的分類節(jié)點(diǎn),它們彼此的相似性加一。最終的相似度除以決策樹(shù)的總數(shù) (t)目獲得任意一對(duì)樣品標(biāo)準(zhǔn)化后的的相似度值。這個(gè)值可后續(xù)用于缺失值填充、異常樣品鑒定和對(duì)數(shù)據(jù)進(jìn)行低維可視化。(i表示第i棵樹(shù))
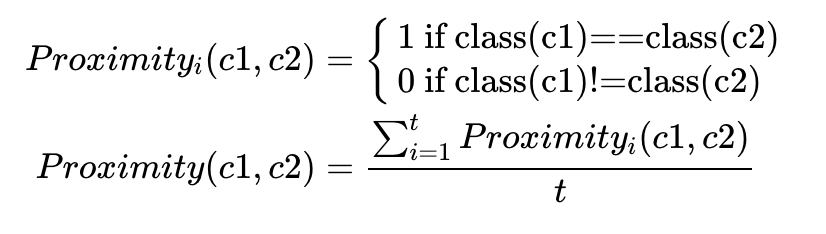
oob (out-of-bag) error rate (聚合錯(cuò)誤率)
應(yīng)用隨機(jī)森林時(shí),無(wú)需交叉驗(yàn)證或額外的測(cè)試集來(lái)評(píng)估錯(cuò)誤率,而是在構(gòu)建隨機(jī)森林時(shí),可自行評(píng)估:
每一個(gè)決策樹(shù)構(gòu)建時(shí)使用到的樣本是不同的。
因?yàn)槭怯蟹呕氐仉S機(jī)采樣,在構(gòu)建每棵樹(shù)時(shí),大約
1/3的樣品不會(huì)被用到。這些沒(méi)有被抽樣到用于構(gòu)建決策樹(shù)的樣品用來(lái)測(cè)試該決策樹(shù)的分類能力。
理論上每個(gè)樣品在
1/3的決策樹(shù)中可作為測(cè)試樣品獲得一個(gè)分類結(jié)果和分類錯(cuò)誤率。聚合每個(gè)沒(méi)有被抽樣到的樣品在所有其不被用于訓(xùn)練集構(gòu)建的決策樹(shù)的分類結(jié)果作為該樣品的最終分類結(jié)果,與數(shù)據(jù)的原始分類一致則是分類正確,否則是分類錯(cuò)誤。
所有分類錯(cuò)誤的樣品除以總樣品即為構(gòu)建的隨機(jī)森林模型的錯(cuò)誤率。
(
i表示第i棵樹(shù))

確定分類的關(guān)鍵變量
對(duì)于每一棵隨機(jī)決策樹(shù),統(tǒng)計(jì)其分類OOB數(shù)據(jù)集中所有樣品正確分類的次數(shù) ?(O)。隨機(jī)排列OOB數(shù)據(jù)集中變量m的值,再用該決策樹(shù)分類,統(tǒng)計(jì)所有樣品被正確分類的次數(shù) (P)。這兩個(gè)次數(shù)的差值(O-P)即為變量m在單棵決策樹(shù)的分類重要性得分 (CS, classification score),其在所有分類樹(shù)中的均值即為該變量的整體重要性得分 (ACS, avraged classification score)。

通過(guò)大量數(shù)據(jù)測(cè)試發(fā)現(xiàn),同一個(gè)變量不同決策樹(shù)獲得的CS的相關(guān)性很低,可以認(rèn)為是彼此獨(dú)立的。隨后按照常規(guī)方式計(jì)算所有CS的標(biāo)準(zhǔn)差,ACS/CS獲得Z-score值。假設(shè)Z-score服從正態(tài)分布,根據(jù)Z-score估計(jì)該變量的重要性程度。
如果變量數(shù)目很多,只在第一次用所有變量評(píng)估,后續(xù)只評(píng)估第一次選出的最重要的一部分變量。
篩選關(guān)鍵分類變量的另一個(gè)指標(biāo) Gini importance
Gini impurity得分是確定決策樹(shù)每一層級(jí)節(jié)點(diǎn)和閾值的一個(gè)評(píng)判標(biāo)準(zhǔn)。每個(gè)變量 (m)貢獻(xiàn)的Gini impurity的降低程度(GD(m))可以作為該變量重要性的一個(gè)評(píng)價(jià)標(biāo)準(zhǔn)。變量(m)在所有樹(shù)中的GD(m)之和獲得的變量重要性評(píng)估與上面通過(guò)隨機(jī)置換數(shù)據(jù)獲得的變量評(píng)估結(jié)果通常是一致的。
變量互作 Interactions
變量互作定義為,一個(gè)決策樹(shù)通過(guò)變量m做了決策后的子節(jié)點(diǎn)可以更容易或更不容易通過(guò)變量k做決策。如果變量m與變量k相關(guān),按m決策后,再按k決策就不容易分割因?yàn)橐呀?jīng)被m分割了。
這也是基于兩個(gè)變量m和k是獨(dú)立的這一假設(shè)。通常通過(guò)每個(gè)變量作為決策節(jié)點(diǎn)時(shí)計(jì)算出的Gini impurity得分 (g(m)或 g(k),得分越低說(shuō)明決策分割效果越少)作為評(píng)價(jià)依據(jù)。他們的差值g(m) - g(k)即為變量m和k的互作值,這個(gè)值越大,說(shuō)明基于變量m分割后更有利于基于變量k分割。
相似性 Proximities
每棵決策樹(shù)構(gòu)建好后,用所有的數(shù)據(jù)評(píng)估決策樹(shù),然后計(jì)算每一對(duì)樣品之間的相似度。如果兩個(gè)樣品分類到相同的分類節(jié)點(diǎn),它們彼此的相似性加一。最終的相似度除以決策樹(shù)的總數(shù)目獲得任意一對(duì)樣品標(biāo)準(zhǔn)化后的的相似度值 (具體見(jiàn)前面的公式)。這些值構(gòu)成一個(gè)n X n (n為總樣品數(shù))的矩陣。這個(gè)值可后續(xù)用于缺失值填充、異常樣品鑒定和對(duì)數(shù)據(jù)進(jìn)行低維可視化。
如果數(shù)據(jù)集較大,n X n的矩陣可能需要消耗比較多內(nèi)存。這是可以使用n X t的矩陣來(lái)存儲(chǔ) (t是隨機(jī)森林中決策樹(shù)的數(shù)目)。用戶也可以指定每個(gè)樣品只保留最相似的nrnn個(gè)樣本,以加快運(yùn)算速度。
如果有測(cè)試數(shù)據(jù)集,測(cè)試集中的樣品也可以與訓(xùn)練集中的樣品計(jì)算兩兩相似度。
降維展示 Scaling
樣品i和j的相似度定義為prox(i,j),這是一個(gè)不大于1的正數(shù) (具體見(jiàn)前面公式)。1-prox(i,kj)則是樣品i和j的歐式距離。這樣就構(gòu)成一個(gè)最大為n X n的距離矩陣。
隨后就可以通過(guò)MDS方式計(jì)算其內(nèi)積,求解特征值和特征向量。可類比于PCA分析,獲得幾個(gè)新的展示維度。通常繪制第1,2維就可以比較好的展示樣品的分布。
原型 Prototypes
Prototypes是一種展示變量與分類關(guān)系的方式。對(duì)第j類,選擇基于相似性獲得的K近鄰樣品中落在j類最多的樣品。這k個(gè)樣品中,計(jì)算每個(gè)變量的中位數(shù)、第一四分位數(shù)和第三四分位數(shù)。這個(gè)中位數(shù)就是class j的原型 (prototype), 第一四分位數(shù)和第三四分位數(shù)則是原型的置信范圍。對(duì)于第二個(gè)原型,按之前的步驟計(jì)算,只是不考慮上一步用到的k的樣品。輸出原型時(shí),如果是連續(xù)變量,則用原型值減去第5分位數(shù)并除以第95分位數(shù)和第5分位數(shù)的差值。如果是區(qū)域變量,原型就是出現(xiàn)次數(shù)最多的值。
訓(xùn)練集中的缺失值填充 Missing value replacement for the training set
隨機(jī)森林有兩種方式填充缺失值。
第一種方式速度快。如果某個(gè)樣品屬于
class j,其變量m值缺失,如果變量m的值是數(shù)值型,則用class j中所有樣品的變量m的值的中位數(shù)作為填充值;如果變量m的值是分類型,則用class j中所有樣品出現(xiàn)次數(shù)最多的變量m的值作為填充值;第二種方式需要更多計(jì)算量但可以給出更好的結(jié)果,即便是存在大量缺失數(shù)據(jù)時(shí)。它只通過(guò)訓(xùn)練集填充缺失值。首先對(duì)缺失值做一個(gè)粗略的、非精確的填充。然后計(jì)算隨機(jī)森林和樣本相似性。
定義樣品i的變量m的值為v(m,i),如果變量m為連續(xù)性數(shù)值變量,則其填充值為其它樣品中變量m的值與該樣品與樣品i的相似性的乘積的均值 (n1是變量m不為缺失值的樣品)。如果變量m為分類型變量, 則替換其為所有樣品最頻繁出現(xiàn)的值(計(jì)算頻率時(shí)需要用根據(jù)每個(gè)樣品與樣品i的相似性進(jìn)行加權(quán))。
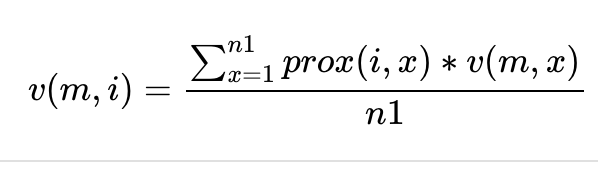
隨后使用填充后的數(shù)據(jù)集迭代構(gòu)建隨機(jī)森林模型,計(jì)算新的填充值并且繼續(xù)迭代,通常4-6次迭代即可。
替換測(cè)試集中的缺失值 Missing value replacement for the test set
取決于測(cè)試集是否自帶樣品標(biāo)簽(分類屬性)有兩種方式可以用于缺失值替換。
如果測(cè)試集有標(biāo)簽,訓(xùn)練集中計(jì)算出的填充值直接用于測(cè)試集填充。
如果測(cè)試集沒(méi)有標(biāo)簽,則測(cè)試集中的每個(gè)樣品都重復(fù)
n_class次 (n_class為總的分類數(shù))。第一次重復(fù)的樣品設(shè)置其標(biāo)簽為
class 1,并用class 1的對(duì)應(yīng)值填充。第二次重復(fù)的樣品設(shè)置其標(biāo)簽為
class 2,并用class 2的對(duì)應(yīng)值填充。
這個(gè)重復(fù)后的測(cè)試集用構(gòu)建好的隨機(jī)森林模型進(jìn)行分類。在某個(gè)樣品的所有重復(fù)中,獲得最多分類的class則是該樣品的標(biāo)簽,缺失值也根據(jù)對(duì)應(yīng)class填充。
標(biāo)簽有誤的樣品 Mislabeled cases
訓(xùn)練集通常是人為判斷設(shè)定的標(biāo)簽。在一些領(lǐng)域,誤標(biāo)記會(huì)常出現(xiàn)。很多誤標(biāo)記的樣本可以通過(guò)異常值檢測(cè)的方式鑒定出。
異常值 Outliers
異常樣本定義為需要從主數(shù)據(jù)集中移除的樣本。從數(shù)據(jù)上來(lái)說(shuō),異常樣品就是與其它所有樣品相似性 (proximity)都很低的樣品。通常為了縮小計(jì)算量,異常樣品是從每個(gè)分類內(nèi)部計(jì)算鑒定的。class j的一個(gè)異常樣本就是在class j中某一個(gè)或多個(gè)與其它樣本相似性很低的樣本。
class j中的樣品 n與class j中其它樣品(k)的平均相似性定義為
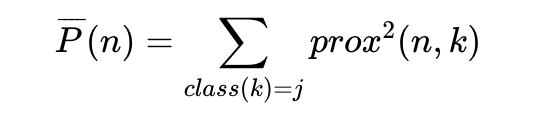
樣品n是否為異常樣品的度量方式為
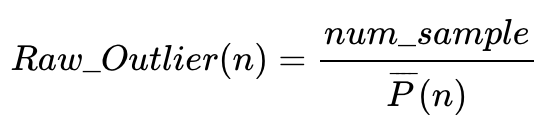
The raw outlier measure for case n is defined as
如果平均相似度較低,這個(gè)度量值就會(huì)很高。計(jì)算這一組數(shù)據(jù) (class j中每個(gè)樣本 (J1, J2, Jn)與其它樣本的平均相似度)的中位數(shù)和絕對(duì)偏差。每個(gè)平均相似度值減去中位數(shù)除以絕對(duì)偏差即獲得最終的異常值度量標(biāo)準(zhǔn)。
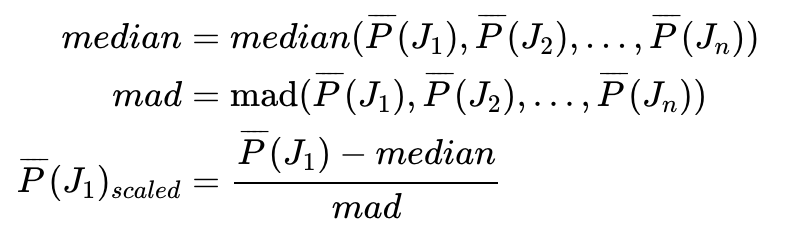
無(wú)監(jiān)督聚類 Unsupervised learning
無(wú)監(jiān)督聚類問(wèn)題中,每個(gè)樣品有一些度量值但都沒(méi)有分類標(biāo)簽(分類問(wèn)題)或響應(yīng)變量(回歸問(wèn)題)。這類問(wèn)題沒(méi)有優(yōu)化的標(biāo)準(zhǔn),通常只能獲得模糊的結(jié)論。最常見(jiàn)的應(yīng)用是對(duì)數(shù)據(jù)進(jìn)行聚類,能聚成幾類,每一類是否意義明確。
在隨機(jī)森林中,所有原始數(shù)據(jù)都視為來(lái)源于class 1, 然后構(gòu)建一個(gè)相同大小的合成數(shù)據(jù)集都視為來(lái)源于class 2。第二個(gè)合成數(shù)據(jù)集通過(guò)對(duì)原始數(shù)據(jù)進(jìn)行單變量 (univariate distribution)隨機(jī)采樣構(gòu)建。合成數(shù)據(jù)集每個(gè)樣品構(gòu)建方式舉例如下:
樣品第一個(gè)變量的值從該變量在
n個(gè)樣品中的值隨機(jī)抽取一個(gè)。樣品第二個(gè)變量的值從該變量在
n個(gè)樣品中的值隨機(jī)抽取一個(gè)。以此類推
因此,Class 2數(shù)據(jù)有著獨(dú)立的隨機(jī)變量數(shù)據(jù)分布,并且每個(gè)變量的數(shù)據(jù)分布與原始矩陣的對(duì)應(yīng)變量一致。Class 2數(shù)據(jù)打亂了原始數(shù)據(jù)的依賴結(jié)構(gòu)。現(xiàn)在全體數(shù)據(jù)就有了兩個(gè)分類,可以應(yīng)用隨機(jī)森林算法構(gòu)建模型。
如果這兩類數(shù)據(jù)的oob誤分類率為40%或更高,說(shuō)明隨機(jī)森林the x -variables look too much like independent variables to random forests。變量的依賴在分組上貢獻(xiàn)不大。如果誤分類率低,則說(shuō)明變量依賴發(fā)揮了重要作用。
把無(wú)標(biāo)簽數(shù)據(jù)集改造為包含兩個(gè)分類的數(shù)據(jù)集給我們一些好處。缺失值可以有效填充。可以鑒定出異常樣品。可以評(píng)估變量的重要性。可以做降維分析(如果原始數(shù)據(jù)有標(biāo)簽,非監(jiān)督的降維 (`scaling)通常能保留下原始分類的結(jié)構(gòu))。最大的一個(gè)好處是使得聚類成為了可能。
平衡預(yù)測(cè)錯(cuò)誤 ?Balancing prediction error
在一些數(shù)據(jù)集,不同分類的預(yù)測(cè)錯(cuò)誤是很不均衡的。一些分類預(yù)測(cè)錯(cuò)誤率低,另一些類預(yù)測(cè)錯(cuò)誤率高。這通常發(fā)生在每個(gè)類的樣品數(shù)目差別較大時(shí)。隨機(jī)森林試圖最小化總錯(cuò)誤率,保持大的類有較低的分類錯(cuò)誤率,較小的類有較高的分類錯(cuò)誤率。例如,在藥物發(fā)現(xiàn)時(shí),一個(gè)給定的分子會(huì)分類為有活性或無(wú)活性。通常分類為有活性的的概率為1/10或1/100。這時(shí)分類為有活性組的錯(cuò)誤率就會(huì)很高。
用戶可以通過(guò)輸出每種分類的錯(cuò)誤率作為預(yù)測(cè)不平衡性的評(píng)估。為了說(shuō)明這個(gè)問(wèn)題,我們采用一個(gè)有20個(gè)變量的合成數(shù)據(jù)集。class 1的數(shù)據(jù)符合一個(gè)球形的高斯分布,class 2的數(shù)據(jù)符合另一個(gè)球形高斯分布。訓(xùn)練集包含1000個(gè)class 1樣品和50個(gè)class 2樣品。測(cè)試集包括5000個(gè)class 1樣品和250個(gè)class 2樣品。
包含500棵樹(shù)的隨機(jī)森林輸出的錯(cuò)誤率為500 3.7 0.0 78.4。總體錯(cuò)誤率較低(3.7%),但class 2的錯(cuò)誤率高,為(78.4%)。可以通過(guò)對(duì)每個(gè)class設(shè)置不同的權(quán)重來(lái)平衡錯(cuò)誤率。一個(gè)class的權(quán)重越高,它的分類錯(cuò)誤率降低的就越多。一個(gè)常規(guī)的設(shè)置權(quán)重的方式是與class中樣品數(shù)成反比。設(shè)置訓(xùn)練集中class 1的權(quán)重為1, class 2的權(quán)重為20,再次構(gòu)建模型,輸出為500 12.1 12.7 0.0。class 2的權(quán)重為20有點(diǎn)太高了,降低為10,獲得結(jié)果如下500 4.3 4.2 5.2。
這樣兩個(gè)分類的錯(cuò)誤率差不多平衡了。如果要求兩個(gè)分類錯(cuò)誤率相等,則還可以再微調(diào)class 2的權(quán)重。
需要注意的是,在平衡不同分類錯(cuò)誤率時(shí),總的錯(cuò)誤率升高了。這是正常的。
檢測(cè)新樣品 Detecting novelties
對(duì)于測(cè)試集異常樣品的檢測(cè)可用來(lái)尋找新的不能分類于之前鑒定好的類中的樣品。
以下面的衛(wèi)星圖像數(shù)據(jù)集做例子。訓(xùn)練集有4435個(gè)樣品,測(cè)試集有2000個(gè)樣品,36個(gè)變量,6個(gè)分組。
在測(cè)試集中,等間距的選取了5個(gè)樣品。被選中樣品的每個(gè)變量的值用從訓(xùn)練集中同一個(gè)變量的值隨機(jī)選取一個(gè)替換。采用參數(shù)noutlier=2; nprox=1作為運(yùn)行參數(shù),輸出下圖:
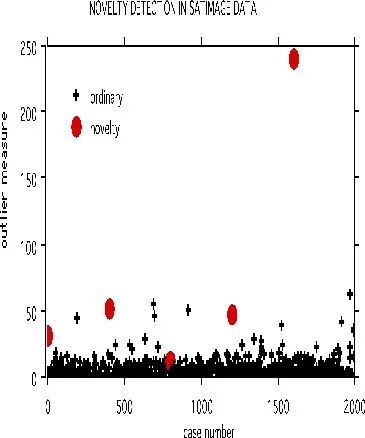
這展示了采用一個(gè)固定的訓(xùn)練集,可以檢測(cè)測(cè)試集中的新樣品。訓(xùn)練集構(gòu)建的樹(shù)可以存儲(chǔ)起來(lái)用于檢測(cè)后續(xù)的數(shù)據(jù)集。這個(gè)檢測(cè)新樣品的方法目前還處于試驗(yàn)階段,還不能區(qū)分DNA檢測(cè)中的新樣本。
接下來(lái)我們就選幾套數(shù)據(jù)集進(jìn)行實(shí)戰(zhàn)操作,邊操作邊理解概念了。
往期精品(點(diǎn)擊圖片直達(dá)文字對(duì)應(yīng)教程)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|



























后臺(tái)回復(fù)“生信寶典福利第一波”或點(diǎn)擊閱讀原文獲取教程合集
?
(請(qǐng)備注姓名-學(xué)校/企業(yè)-職務(wù)等)