
多模態(tài)中NLP與CV融合的一些方式
點(diǎn)擊上方,選擇星標(biāo)或置頂,每天給你送干貨!
多種不同的信息源(不同的信息形式)中獲取信息表達(dá)
表示(Multimodal Representation)的意思,比如shift旋轉(zhuǎn)尺寸不變形,圖像中研究出的一種表示
表示的冗余問題
不同的信號(hào),有的象征性信號(hào),有波信號(hào),什么樣的表示方式方便多模態(tài)模型提取信息
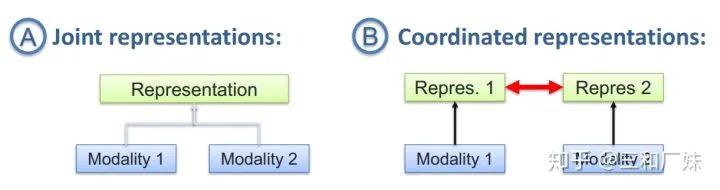
聯(lián)合表示將多個(gè)模態(tài)的信息一起映射到一個(gè)統(tǒng)一的多模態(tài)向量空間
協(xié)同表示負(fù)責(zé)將多模態(tài)中的每個(gè)模態(tài)分別映射到各自的表示空間,但映射后的向量之間滿足一定的相關(guān)性約束。
信號(hào)的映射,比如給一個(gè)圖像,將圖像翻譯成文字,文字翻譯成圖像,信息轉(zhuǎn)化成統(tǒng)一形式后來應(yīng)用
方式,這里就跟專門研究翻譯的領(lǐng)域是重疊,基于實(shí)例的翻譯,涉及到檢索,字典(規(guī)則)等,基于生成方法如生成翻譯的內(nèi)容
多模態(tài)對齊定義為從兩個(gè)或多個(gè)模態(tài)中查找實(shí)例子組件之間的關(guān)系和對應(yīng),研究不同的信號(hào)如何對齊(比如給電影,找出劇本中哪一段)
對齊方式,有專門研究對齊的領(lǐng)域,主要兩種,顯示對齊(比如時(shí)間維度上就是顯示對齊的),隱式對齊(比如語言的翻譯就不是位置對位置)
比如情感分析中語氣和語句的融合等
這個(gè)最難也是被研究最多的領(lǐng)域,比如音節(jié)和唇語頭像怎么融合,本筆記主要寫融合方式
給定一張圖片(視頻)和一個(gè)與該圖片相關(guān)的自然語言問題,計(jì)算機(jī)能產(chǎn)生一個(gè)正確的回答。這是文本QA和Image Captioning的結(jié)合,一般會(huì)涉及到圖像內(nèi)容上的推理,看起來更炫酷(不是指邏輯,就就指直觀感受)。
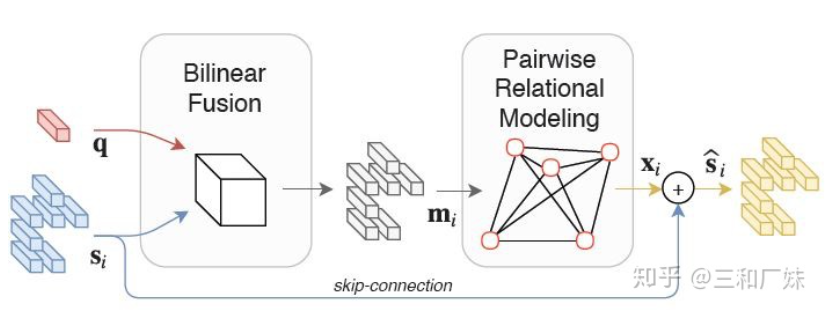
Joint embedding approaches,只是直接從源頭編碼的角度開始融合信息,這也很自然的聯(lián)想到最簡單粗暴的方式就是把文本和圖像的embedding直接拼接(ps:粗暴拼接這種方式很work),Billiner Fusion 最常用了,F(xiàn)usion屆的LR
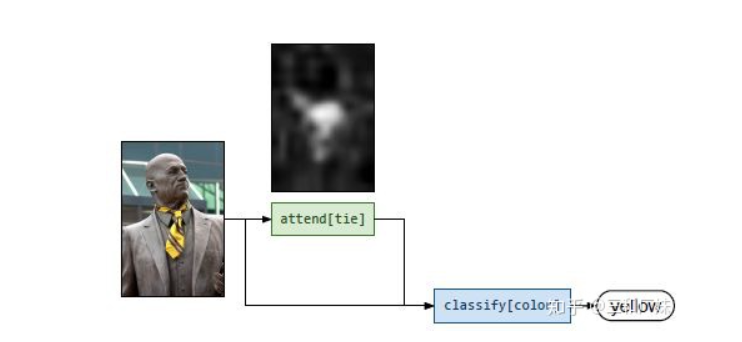
Attention mechanisms,很多VQA的問題都在attention上做文章,attention本身也是一個(gè)提取信息的動(dòng)作,自從attention is all you need后,大家對attention的應(yīng)用可以說是花式了,本文后面專門介紹CVPR2019的幾篇
Compositional Models,這種方式解決問題的思路是分模塊而治之,各模塊分別處理不同的功能,然后通過模塊的組裝推理得出結(jié)果






作者:三和廠妹
三和,一個(gè)城市邊緣貧瘠人群的棲息地。廠妹,在社會(huì)勞動(dòng)中尋找價(jià)值的初心青年。目前在平安科技AI研究院做算法,主要感興趣方向包括對話系統(tǒng),知識(shí)圖譜,文本搜索,推薦系統(tǒng)。三和什么都沒有,廠妹也無知,所以每一個(gè)任務(wù)都是全新的開始。
知乎ID:三和廠妹

參考
Neural Module Networks
Ask Me Anything: Free-form Visual Question Answering Based on Knowledge from External Sources
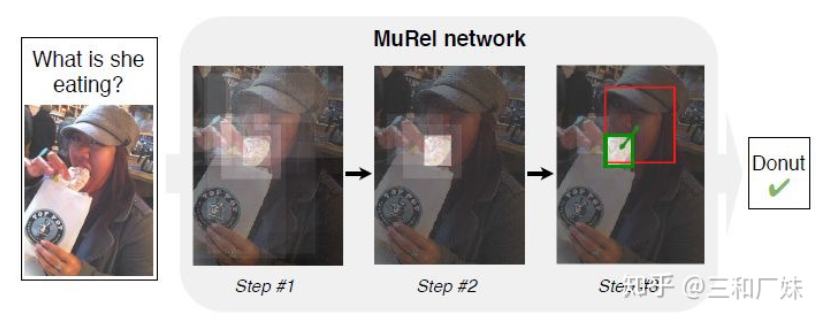
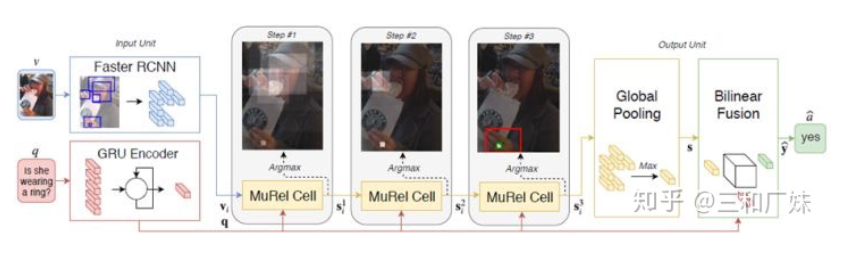
MUREL: Multimodal Relational Reasoning for Visual Question Answering
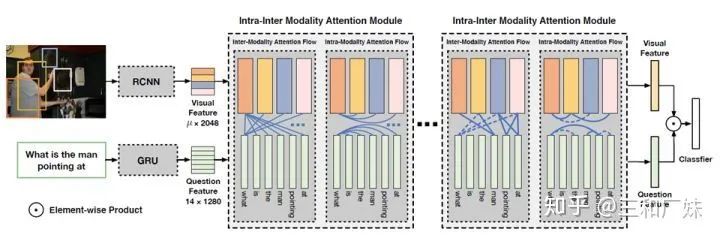
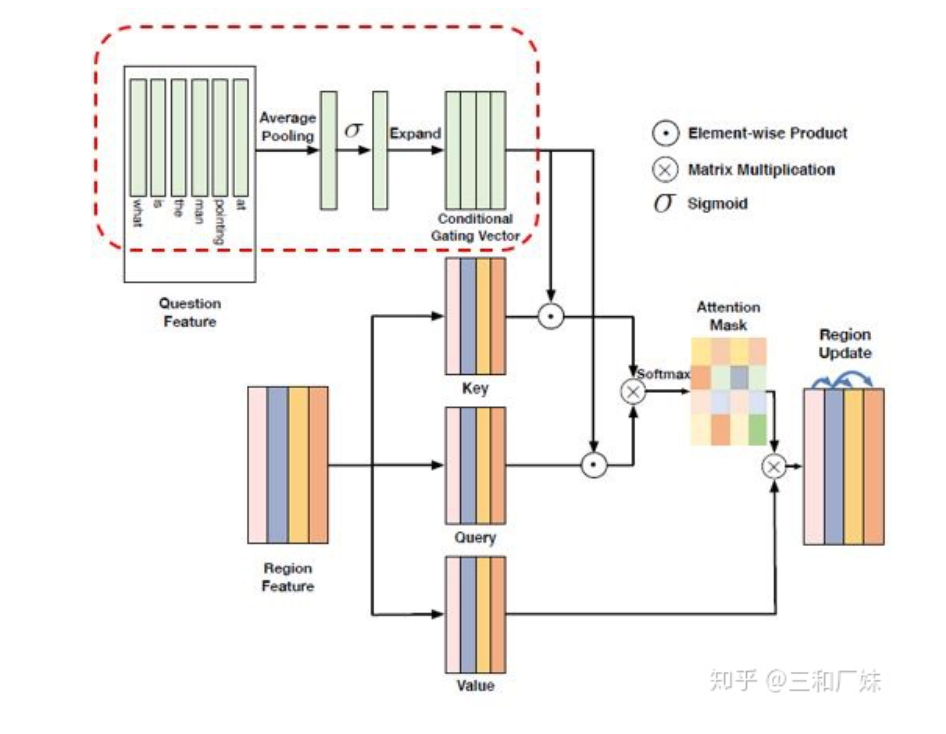
Dynamic Fusion with Intra- and Inter- Modality Attention Flow for Visual Question Answering
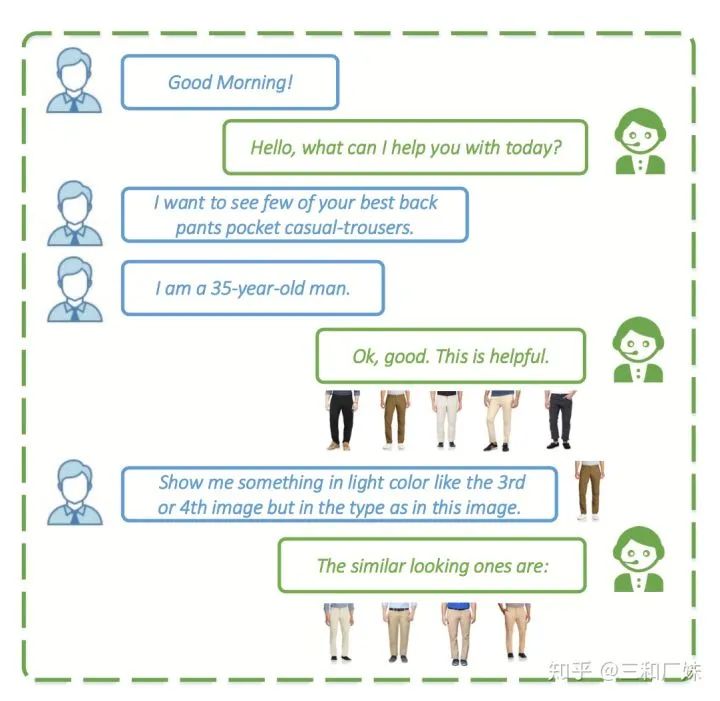
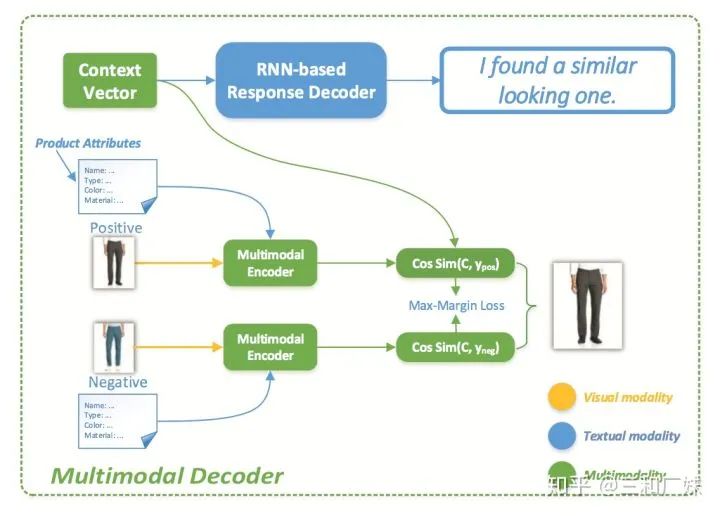
User Atention-guided Multimodal Dialog Systems
入門還不錯(cuò)的課程
新年新開始
長按加群,一起玩耍學(xué)習(xí)
整理不易,還望給個(gè)在看!