
基于深度學習的醫(yī)學圖像配準綜述
點擊上方“小白學視覺”,選擇加"星標"或“置頂”
重磅干貨,第一時間送達

轉(zhuǎn)載自:https://blog.csdn.net/weixin_41699811/article/details/84314070
已授權(quán)轉(zhuǎn)載,禁止二次轉(zhuǎn)載
作者簡介:本文的作者為上海交通大學的研究生,目前研三,正在整理自己三年的研究內(nèi)容和總結(jié),希望分享出來,讓更多對這個領域感興趣的小伙伴一起加入進來。
作者深知自己剛?cè)腴T時,無從下手,因此他也希望通過自己的一些努力,幫助到一部分同學,目前作者已經(jīng)分享很多自己的總結(jié)。
B站:https://space.bilibili.com/374628187
分享自己的答辯視頻!有興趣可以去看一下
https://github.com/Timmy-Fang/Deformable-Image-Registration-Projects
GitHub項目也在更新自己的工作成果。
這里僅分享了作者的一篇綜述,在CSDN還有其他的優(yōu)質(zhì)文章,比如:
1、關于圖像配準中的常用損失函數(shù)PyTorch實現(xiàn)
2、圖像配準中變形操作(warp)的pytorch
作者寫的都非常的用心,大家感興趣的可以去圍觀
寫在前面的話
本人碩士研究生在讀,主攻基于深度學習的醫(yī)學圖像處理方向,現(xiàn)在在做基于CNN的二維圖像非剛性配準的研究。配準是醫(yī)學圖像處理中常用的基本技術(shù),大量使用在醫(yī)療影像領域的各個方面,比如病灶檢測,疾病診斷,手術(shù)規(guī)劃,手術(shù)導航,療效評估等。相較于檢測、分類與分割任務,醫(yī)學圖像配準任務更加復雜,由于其任務本身的特性,將深度學習技術(shù)在自然圖像上取得的進展遷移到配準任務上也更難一些,但隨著深度學習的學習與研究熱潮的高漲,配準領域的研究也因此受益,目前也有一定量的工作發(fā)表。前不久我做了相關的文獻調(diào)研,寫了該篇文獻綜述給導師看,簡要總結(jié)了近兩三年該領域的研究進展與方向,現(xiàn)粘貼如下。因水平有限,還在學習與研究中,難免有不恰當、不準確的地方,歡迎大家批評指正,一起交流學習!
目錄
引言
一、配準分類
1、監(jiān)督學習
2、非監(jiān)督學習
二、相關問題
三.結(jié)論與討論
參考文獻
醫(yī)學圖像配準是醫(yī)學圖像分析中常用的技術(shù),它是將一幅圖像(移動圖像,Moving)的坐標轉(zhuǎn)換到另一幅圖像(固定圖像,F(xiàn)ixed)中,使得兩幅圖像相應位置匹配,得到配準圖像(Moved)。傳統(tǒng)的配準方法是一個迭代優(yōu)化的過程,首先定義一個相似性指標(例如,L2范數(shù)),通過對參數(shù)化轉(zhuǎn)換或非參數(shù)化轉(zhuǎn)換進行不斷迭代優(yōu)化,使得配準后的移動圖像與固定圖像相似性最高。
如今,深度學習在醫(yī)學圖像分析的研究中是比較火熱的技術(shù),在器官分割、病灶檢測與分類任務中取得了相當好的效果。基于深度學習的醫(yī)學圖像配準方法相較于傳統(tǒng)的配準方法,具有很大的優(yōu)勢與潛力,因此有越來越多的研究人員在研究該方法,近幾年來有不少相關的工作發(fā)表。
本文調(diào)查了近兩年來的基于深度學習的醫(yī)學圖像配準的文章,首先根據(jù)其中使用的深度學習方法進行分類,分別闡述;然后針對不同問題、從不同角度進行分析,比如分塊、輸入輸出、剛體配準、評價指標、與傳統(tǒng)方法比較、時間成本比較等;最后是結(jié)論與討論部分。
大體上,近幾年的文章可以分為兩大類[1] :(1)利用深度學習網(wǎng)絡估計兩幅圖像的相似性度量,驅(qū)動迭代優(yōu)化;(2)直接利用深度回歸網(wǎng)絡預測轉(zhuǎn)換參數(shù)。前者只利用了深度學習進行相似性度量,仍然需要傳統(tǒng)配準方法進行迭代優(yōu)化,沒有充分發(fā)揮深度學習的優(yōu)勢,花費時間長,難以實現(xiàn)實時配準。因此,本文只針對后者進行研究與討論,所得結(jié)論只限于此類的非剛性配準方法。
根據(jù)使用的深度學習的種類劃分,可以劃分為基于監(jiān)督學習的配準與基于非監(jiān)督學習的配準兩大類。
1、監(jiān)督學習
基于監(jiān)督學習的配準,也就是在訓練學習網(wǎng)絡時,需要提供與配準對相對應的真實變形場(即Ground Truth)。以二維圖像配準為例,監(jiān)督學習架構(gòu)如圖1所示。通常,先以兩幅圖像對應坐標為中心點進行切塊,將圖像塊輸入深度學習網(wǎng)絡(通常為卷積神經(jīng)網(wǎng)絡),網(wǎng)絡輸出為圖像塊中心點對應的變形向量(Deformation Vector)。在訓練監(jiān)督學習網(wǎng)絡時,需要提供訓練樣本相應的標簽,也即是真實的變形場。獲取標簽有兩種方式,(1)是利用傳統(tǒng)的經(jīng)典配準方法進行配準,得到的變形場作為標簽[4] [6] ;(2)是對原始圖像進行模擬變形,將原始圖像作為固定圖像,變形圖像作為移動圖像,模擬變形場作為標簽[2] [10] 。
在測試階段,對待配準圖像對進行采樣,輸入網(wǎng)絡,把預測的變形向量綜合成變形場,再利用預測的變形場對移動圖像進行插值,即得配準圖像。三維圖像與之類似。
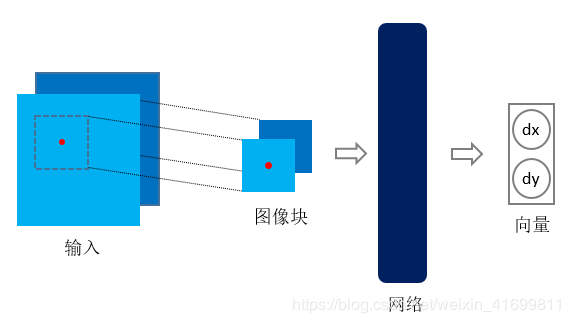
圖1、基于監(jiān)督學習的配準框架
2、非監(jiān)督學習
相較于監(jiān)督學習,基于非監(jiān)督學習的配準方法就是在訓練學習網(wǎng)絡時,只需要提供配準對,不需要標簽(即真實的變形場)。因此,該方法在訓練與測試階段,均不依靠傳統(tǒng)的配準方法。以二維圖像配準為例,非監(jiān)督學習框架如圖2所示。
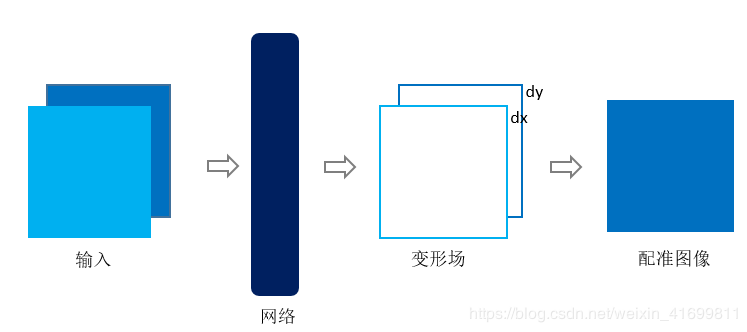
圖2、基于非監(jiān)督學習的配準框架
通常,基于非監(jiān)督學習的配準[3] [7] [8] [9] ,將配準對輸入網(wǎng)絡,獲得變形場,對移動圖像進行變形插值,即得配準圖像。三維圖像與之類似,將三維圖像輸入網(wǎng)絡,獲得變形場(dx,dy,dz),再插值得到配準圖像。由于空間轉(zhuǎn)換層[11] (Spatial Transformation Networks,STN)的提出,[7] 首次成功地將其應用到醫(yī)學圖像領域,使得在訓練階段能夠?qū)崿F(xiàn)非監(jiān)督學習的配準。空間轉(zhuǎn)換層直接連在深度學習網(wǎng)絡之后,利用獲得的變形場對移動圖像進行變形,得到變形后的圖像。訓練時,利用變形后的圖像與固定圖像求損失函數(shù)值(Loss function),對其進行反向傳播,不斷優(yōu)化,使得損失函數(shù)值最小。
二、相關問題
為了從不同角度、不同部分對基于深度學習的配準方法進行簡要分析與比較,我對參考文獻從以下六個方面進行了總結(jié),得到如下結(jié)論。
1、分塊
分塊是指對移動圖像與固定圖像進行采樣,以采樣點為塊中心點,從圖像中截取出來,輸入到深度學習網(wǎng)絡中。通常基于監(jiān)督學習的配準方法需要對圖像進行分塊(如[2] [4] [6] [7] [10]),輸入網(wǎng)絡,獲得塊中心點對應的變形向量,而基于非監(jiān)督學習的方法往往不需要分塊(如[3] [8] [9]),[7] 例外。
2、輸入輸出
大部分的配準網(wǎng)絡均將移動圖像與固定圖像作為兩通道圖像作為輸入(如[2] [3][5] [7] [10]),而基于監(jiān)督學習的配準網(wǎng)絡將其進行分塊后輸入。[6] 做了進一步的工作,除了輸入移動圖像塊與固定圖像塊之外,還輸入了兩圖像塊卷積得到的相似性圖像。[8] 在輸入層輸入固定圖像,而在網(wǎng)絡的中間層輸入移動圖像,這與其設計的獨特配準網(wǎng)絡有關。[9] 輸入網(wǎng)絡的是待學習的向量(Latent vector),預測變形場,對移動圖像進行變形插值,而只在訓練階段利用固定圖像求損失函數(shù)值。[4] 將固定圖像,移動圖像與固定圖像的差分圖像(Difference map)以及固定圖像的梯度圖像(Gradient map)作為三通道輸入網(wǎng)絡。
關于輸出,基于監(jiān)督學習的配準方法往往輸出的是變形向量,而基于非監(jiān)督學習的方法輸出的為變形圖像。
3、剛體配準
[10] 利用卷積神經(jīng)網(wǎng)絡來學習2D-3D剛體配準的參數(shù)。該文章使用人工合成圖像作為訓練樣本,截取圖像塊,分別輸入分支網(wǎng)絡,然后整合到主干網(wǎng)絡,以監(jiān)督學習的方式學習轉(zhuǎn)換參數(shù)(Transformation parameters)。得到的轉(zhuǎn)換參數(shù)為tx、ty、tz、tθ、tα、tβ,分別為x方向平移量、y方向平移量、z方向平移量以及三個旋轉(zhuǎn)量。
4、評價指標
配準效果的評價指標(Evaluation metrics)與使用的數(shù)據(jù)集有關。大多數(shù)文章中使用的數(shù)據(jù)集,如心臟與腦部圖像數(shù)據(jù)集,均有對應圖像的分割標簽,因此,大多數(shù)使用Dice(如[3][4] [6] [7] [8] [9])作為評價指標。而[2] [5] 使用的是胸部CT數(shù)據(jù)集,用TRE(Target Registration Error)來評價配準效果。
5、與傳統(tǒng)方法比較
多數(shù)文章(如[3] [4] [6] [8])使用的作為對比的傳統(tǒng)配準方法為SyN、Demons或其變體,如ANTs,LCC-Demons。[2] 使用的是Elastix(一種基于ITK的開源配準工具包),[7] 使用的是SimpleElastix。
6、 時間成本比較
[3] [4] 中對比了傳統(tǒng)配準方法與基于深度學習的配準方法的時間成本,以[4] 數(shù)據(jù)為例,如圖3所示,其中D.Demons(Diffeomorphic Demons),SyN與FNIRT為傳統(tǒng)方法,BIRNet為文中提出的基于深度學習的方法。從圖中可以看出,基于深度學習的配準方法BIRNet處理速度最快,在GPU上運行D.Demons次之,耗時1.1分鐘,SyN最慢,耗時9.7分鐘。值得注意的是,BIRNet為監(jiān)督學習方法,輸入網(wǎng)絡的是采樣得到的圖像塊,而非完整圖像。
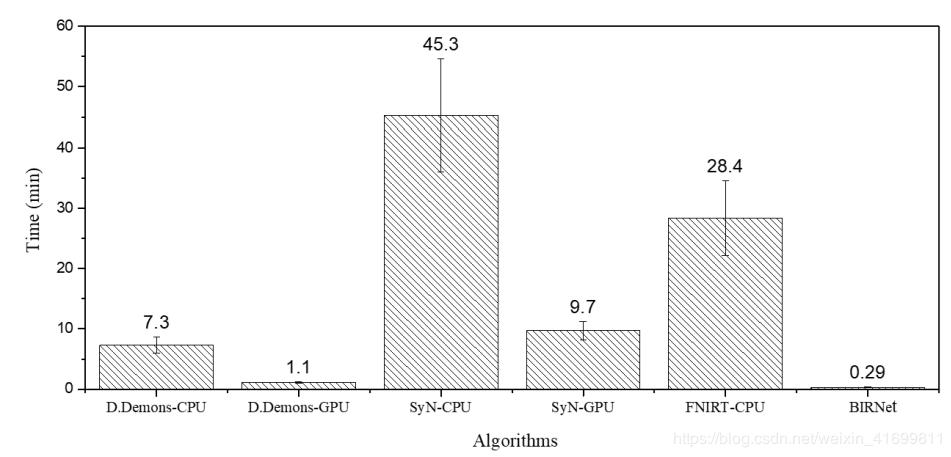
圖3、不同配準方法配準一幅220 × 220 × 184腦圖像平均計算時長(單位:分鐘)。
本文對比了近幾年基于深度學習的醫(yī)學圖像配準文章,根據(jù)深度學習種類對其分類并簡要描述,然后從不同角度對相關問題進行了總結(jié)。總體上,對比近期發(fā)表的相關文章,可以發(fā)現(xiàn)一個趨勢,即研究在逐漸從部分依靠深度學習(如利用深度學習網(wǎng)絡結(jié)果,初始化傳統(tǒng)方法優(yōu)化策略)到完全依靠深度學習(即基于非監(jiān)督學習的配準方法,學習網(wǎng)絡直接獲得配準圖像)實現(xiàn)配準任務的方向轉(zhuǎn)變,深度學習在配準任務上發(fā)揮越來越大的作用與潛能,配準效果與傳統(tǒng)經(jīng)典方法相近,甚至更好。我相信如果妥善解決訓練數(shù)據(jù)集匱乏問題,能更好地發(fā)揮基于深度學習的配準方法的優(yōu)勢,實現(xiàn)配準效果更好,速度更快。
交流群
歡迎加入公眾號讀者群一起和同行交流,目前有SLAM、三維視覺、傳感器、自動駕駛、計算攝影、檢測、分割、識別、醫(yī)學影像、GAN、算法競賽等微信群(以后會逐漸細分),請掃描下面微信號加群,備注:”昵稱+學校/公司+研究方向“,例如:”張三 + 上海交大 + 視覺SLAM“。請按照格式備注,否則不予通過。添加成功后會根據(jù)研究方向邀請進入相關微信群。請勿在群內(nèi)發(fā)送廣告,否則會請出群,謝謝理解~