
Python爬蟲,破解ajax動態(tài)網(wǎng)頁,爬取籃球比賽數(shù)據(jù)
前言
今天遇到了群友的一個需求:
爬取 https://www.sporttery.cn/jc/lqsgkj/ 全年的籃球賽果開獎數(shù)據(jù),如下所示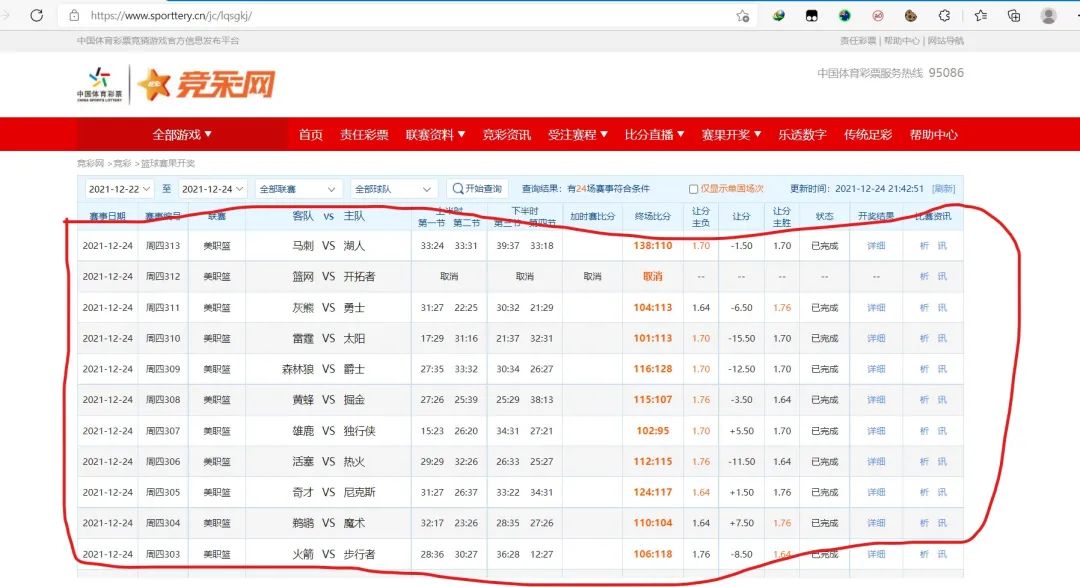
一、網(wǎng)站分析
這個網(wǎng)站的數(shù)據(jù)不是靜態(tài)的,是動態(tài)加載的(選取相應(yīng)日期,點擊”開始查詢“后,數(shù)據(jù)從服務(wù)端加載到瀏覽器)
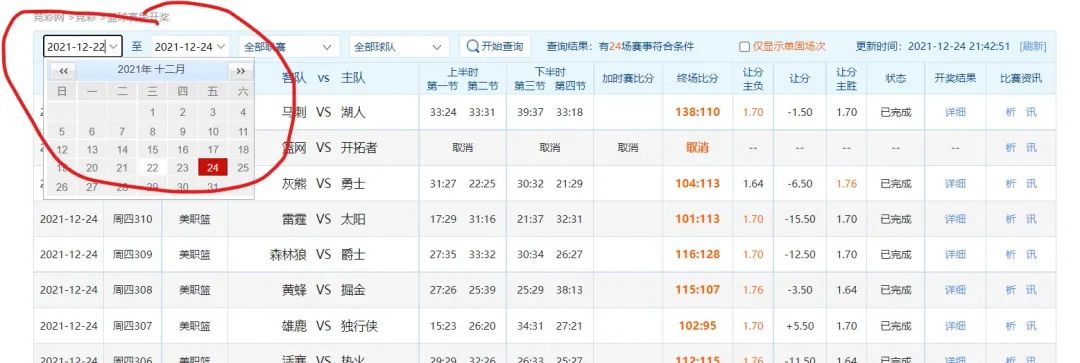
看一下網(wǎng)頁的低端,發(fā)現(xiàn)數(shù)據(jù)并不是一次性加載的,而是通過分頁的形式完成 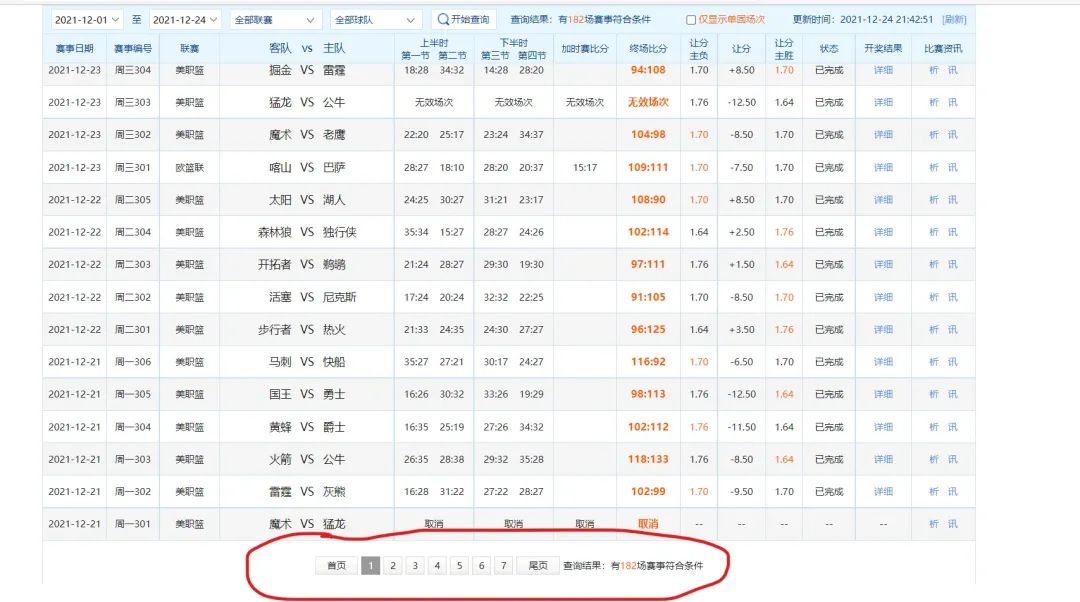 進一步研究還發(fā)現(xiàn),每個月份的分頁數(shù)并不是一致的,最多有8頁
進一步研究還發(fā)現(xiàn),每個月份的分頁數(shù)并不是一致的,最多有8頁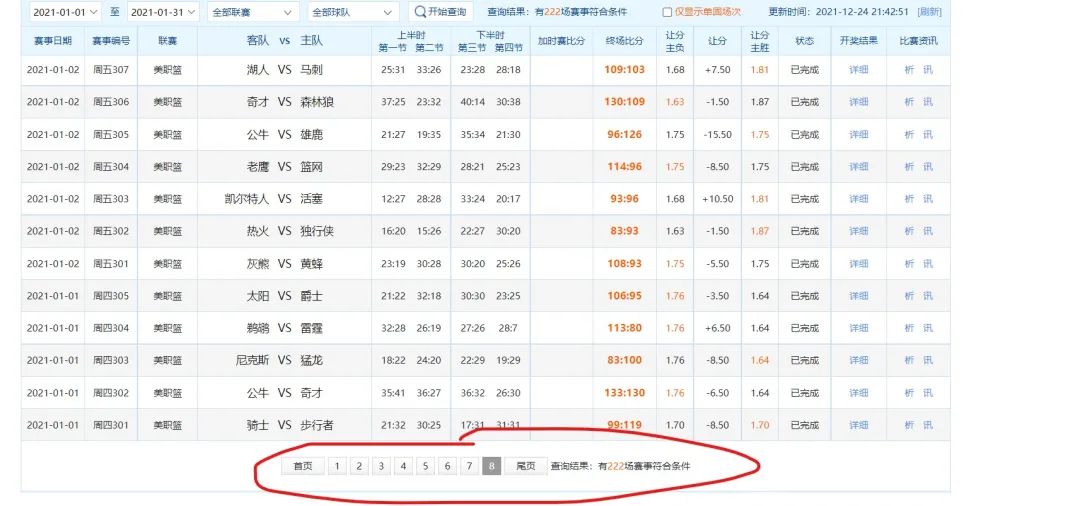
對日期的輸入框進行分析,發(fā)現(xiàn)它是可以直接通過鍵盤輸入日期的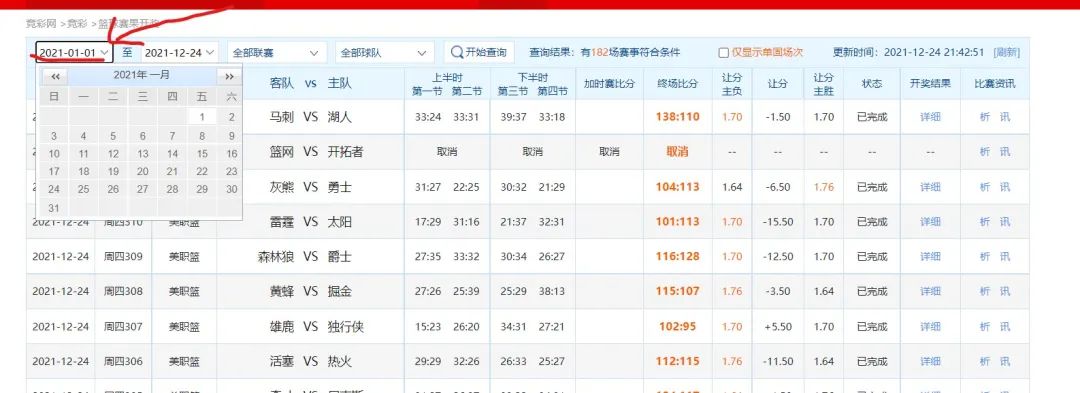
二:確定爬取方案
對于這種動態(tài)的網(wǎng)頁,直接通過request庫不太好爬取,而模擬人類操作瀏覽器的selenium對這種場景具有天然優(yōu)勢,所以我采用后者。對網(wǎng)頁元素的定位則使用xpath。再此推薦螞蟻老師的爬蟲課程,簡潔清晰,新手入門必備。
大概的思路就是,先構(gòu)建每月的開始月份、結(jié)束月份
date?=?[("2021-01-01",?"2021-01-31"),?("2021-02-01",?"2021-02-28"),?("2021-03-01",?"2021-03-31"),
??("2021-04-01",?"2021-04-30"),?("2021-05-01",?"2021-05-31"),?("2021-06-01",?"2021-06-30"),
??("2021-07-01",?"2021-07-31"),
??("2021-08-01",?"2021-08-30"),?("2021-09-01",?"2021-09-31"),?("2021-10-01",?"2021-10-30"),
??("2021-11-01",?"2021-11-31"),
??("2021-12-01",?"2021-12-24")]
再用這些數(shù)據(jù)分別輸入到開始框和結(jié)束框內(nèi) 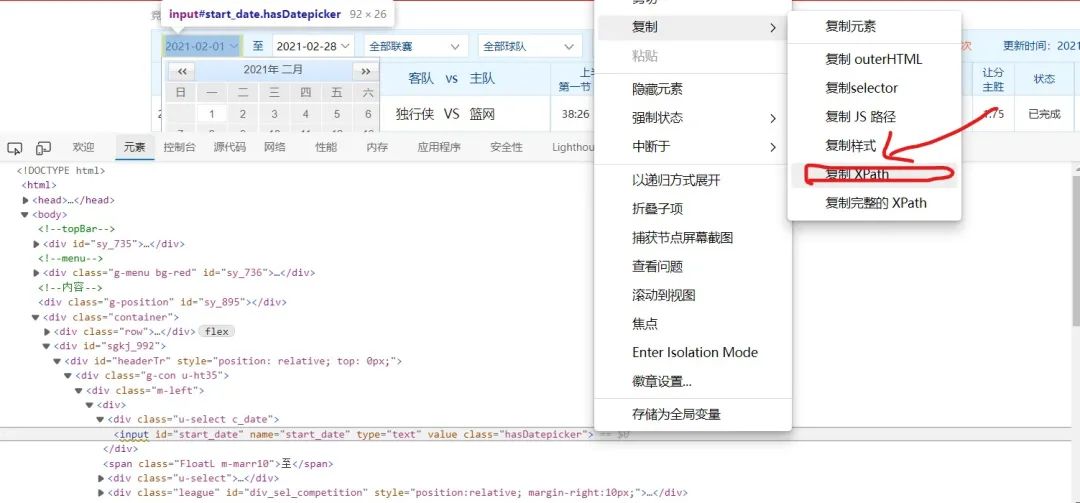
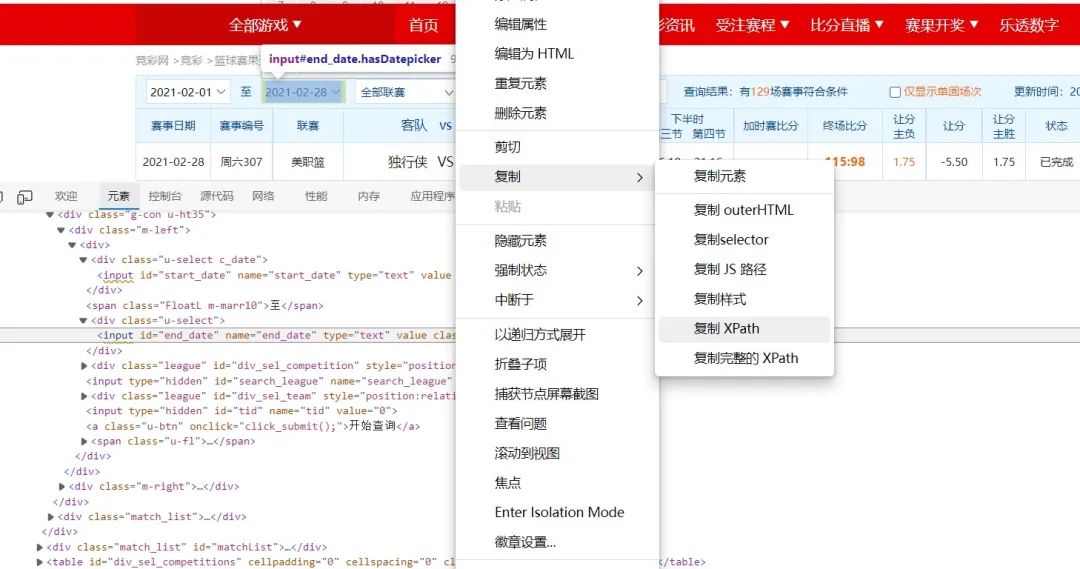
點擊查詢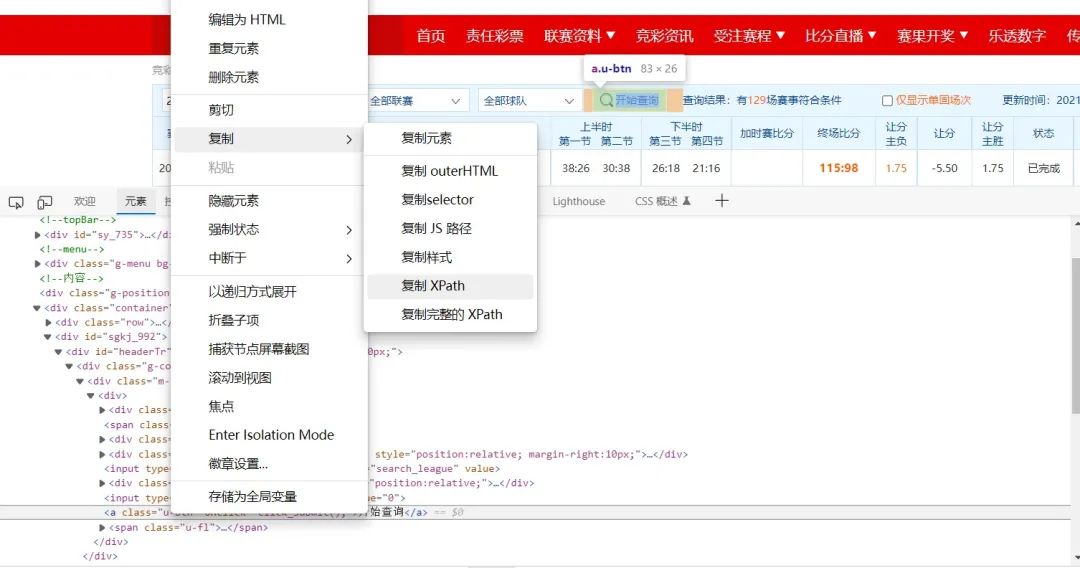
點擊分頁  特別注意到分頁的xpath路徑是有規(guī)律的,因而我們可以構(gòu)造xpath路徑,方便接下來的爬取
特別注意到分頁的xpath路徑是有規(guī)律的,因而我們可以構(gòu)造xpath路徑,方便接下來的爬取
Xpath?=?[f'//*[@id="matchList"]/div/div/ul/li[{i}]'?for?i?in?range(2,?10)]
爬取內(nèi)容
三:編碼實現(xiàn)
from?selenium.webdriver?import?Edge
from?selenium.webdriver.common.by?import?By
from?selenium.webdriver.support.ui?import?WebDriverWait
import?time
driver?=?Edge(executable_path="C:/WebDriver/bin/msedgedriver.exe")
date?=?[("2021-01-01",?"2021-01-31"),?("2021-02-01",?"2021-02-28"),?("2021-03-01",?"2021-03-31"),
??("2021-04-01",?"2021-04-30"),?("2021-05-01",?"2021-05-31"),?("2021-06-01",?"2021-06-30"),
??("2021-07-01",?"2021-07-31"),
??("2021-08-01",?"2021-08-30"),?("2021-09-01",?"2021-09-31"),?("2021-10-01",?"2021-10-30"),
??("2021-11-01",?"2021-11-31"),
??("2021-12-01",?"2021-12-24")]
Xpath?=?[f'//*[@id="matchList"]/div/div/ul/li[{i}]'?for?i?in?range(2,?10)]
#?判斷xpath存不存在的函數(shù)
def?NodeExists(xpath):
?try:
??driver.find_element_by_xpath(xpath)
??return?True
?except:
??return?False
def?crawler():
?for?item?in?date:
??#?打開網(wǎng)頁
??driver.get("https://www.sporttery.cn/jc/lqsgkj/")
??#?等待加載
??WebDriverWait(driver,?10).until(lambda?d:?"籃球賽果開獎"?in?d.title)
??#?等待一秒后?先清空再輸入開始日期
??time.sleep(1)
??driver.find_element(By.XPATH,?'//*[@id="start_date"]').clear()
??driver.find_element(By.XPATH,?'//*[@id="start_date"]').send_keys(item[0])
??#?再等一秒?先清空再輸入結(jié)束日期
??time.sleep(1)
??driver.find_element(By.XPATH,?'//*[@id="end_date"]').clear()
??driver.find_element(By.XPATH,?'//*[@id="end_date"]').send_keys(item[1])
??#?點擊查詢
??driver.find_element(By.XPATH,?'//*[@id="headerTr"]/div[1]/div[1]/div/a').click()
??print(f"開始爬取{item[0]}")
??with?open(f"{item[0]}.csv",?"w",?encoding='ANSI')?as?fin:
???#?點擊1-8頁內(nèi)容
???page?=?1
???for?this?in?Xpath:
????time.sleep(1)
????if?NodeExists(this):
?????driver.find_element(By.XPATH,?this).click()
????else:
?????print(f"沒有{this}這個xpath")
?????break
????time.sleep(1)
????content?=?driver.find_element(By.XPATH,?'//*[@id="matchList"]/table').text
????fin.write("\n"?+?content)
????print(f"完成第{page}頁的爬取,此時的xpath是:{this}")
????page?+=?1
??print(f"結(jié)束爬取{item[0]}")
if?__name__?==?"__main__":
?crawler()
最后,推薦螞蟻老師的《零基礎(chǔ)學(xué)Python到數(shù)據(jù)分析實戰(zhàn)》包含了爬蟲部分:
評論
圖片
表情