爬蟲實戰(zhàn) | 爬取東方財富網(wǎng)股票數(shù)據(jù)
↑↑↑關(guān)注后"星標(biāo)"簡說Python
人人都可以簡單入門Python、爬蟲、數(shù)據(jù)分析 簡說Python推薦 來源:志斌的python筆記 作者:志斌
今天有個朋友說,他想做個關(guān)于股票的可視化網(wǎng)頁,但是缺乏股票的數(shù)據(jù),想讓志斌幫他做個爬蟲來每天獲取數(shù)據(jù)。所以我將它寫成一個實戰(zhàn)案例,供大家一起參考學(xué)習(xí)!
頁面分析
此次我們獲取數(shù)據(jù)的網(wǎng)站是東方財富網(wǎng)!
首先我們按F12打開開發(fā)者模式,對name里面的網(wǎng)頁進(jìn)行觀察,發(fā)現(xiàn)數(shù)據(jù)是以jQuery加載進(jìn)網(wǎng)頁的,每次加載20個數(shù)據(jù),如圖:
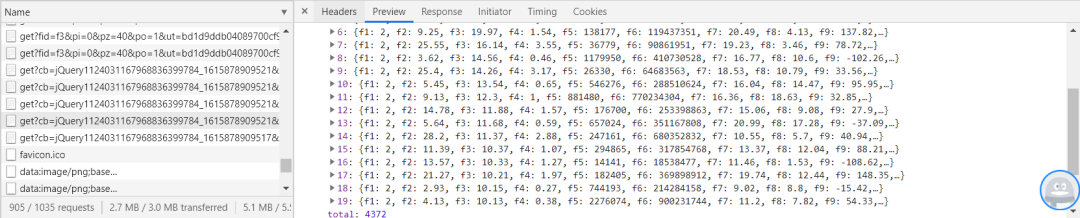
我們已經(jīng)發(fā)現(xiàn)單頁數(shù)據(jù)存儲的方式了,現(xiàn)在我們來看一下各頁URL之間的聯(lián)系,如圖:
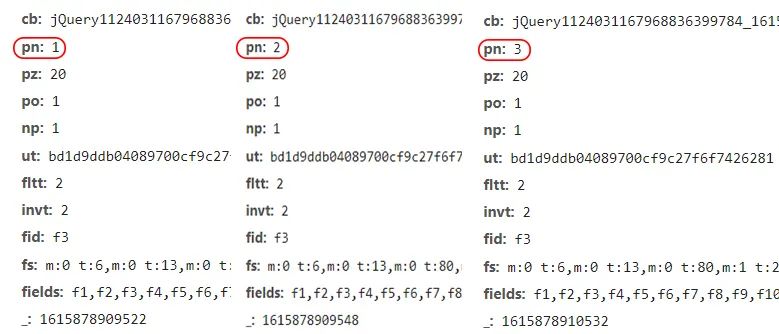
從圖中我們可以清楚的發(fā)現(xiàn),每翻一頁,pn的參數(shù)增加1,所以我們構(gòu)建URL時,只需讓params中的pn參數(shù)循環(huán),即可批量對網(wǎng)頁發(fā)起訪問請求,代碼如下:
for page in range(1,50):
params = (
('cb', 'jQuery1124031167968836399784_1615878909521'),
('pn', str(page)),
('pz', '20'),
('po', '1'),
('np', '1'),
('ut', 'bd1d9ddb04089700cf9c27f6f7426281'),
('fltt', '2'),
('invt', '2'),
('fid', 'f3'),
('fs', 'm:0 t:6,m:0 t:13,m:0 t:80,m:1 t:2,m:1 t:23'),
('fields', 'f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152'),
)
獲取數(shù)據(jù)
上面我們已經(jīng)將網(wǎng)頁的URL之間的聯(lián)系和數(shù)據(jù)存儲分析好了,下面我們就可以開始對數(shù)據(jù)進(jìn)行獲取了。
在上面對網(wǎng)頁進(jìn)行分析時,我們感覺這個網(wǎng)頁存儲數(shù)據(jù)是json格式的,其實不是,它前面多了一些臟數(shù)據(jù),如圖:

我們?nèi)绻胗胘son來將數(shù)據(jù)進(jìn)行解析的話,就必須將這些臟數(shù)據(jù)去掉。
當(dāng)然我們也可以用另一種方法來解決這個問題,就是將數(shù)據(jù)轉(zhuǎn)化成字符串的形式,然后用正則表達(dá)式將目標(biāo)數(shù)據(jù)提取出來。代碼如下:
daimas = re.findall('"f12":(.*?),',response.text)
names = re.findall('"f14":"(.*?)"',response.text)
zuixinjias = re.findall('"f2":(.*?),',response.text)
zhangdiefus = re.findall('"f3":(.*?),',response.text)
zhangdiees = re.findall('"f4":(.*?),',response.text)
chengjiaoliangs = re.findall('"f5":(.*?),',response.text)
chengjiaoes = re.findall('"f6":(.*?),',response.text)
zhenfus = re.findall('"f7":(.*?),',response.text)
zuigaos = re.findall('"f15":(.*?),',response.text)
zuidis = re.findall('"f16":(.*?),',response.text)
jinkais = re.findall('"f17":(.*?),',response.text)
zuoshous = re.findall('"f18":(.*?),',response.text)
liangbis = re.findall('"f10":(.*?),',response.text)
huanshoulvs = re.findall('"f8":(.*?),',response.text)
shiyinglvs = re.findall('"f9":(.*?),',response.text)
數(shù)據(jù)存儲
在之前的文章中,我們關(guān)于數(shù)據(jù)存儲的各種方式已經(jīng)介紹的很清楚了(如果有朋友不懂可以看這篇文章一文教會你,爬蟲數(shù)據(jù)如何存儲),這里我們就不在過多介紹了,此次才用Excel文件來對數(shù)據(jù)進(jìn)行存儲,代碼如下:
wb = openpyxl.Workbook()
sheet = wb.active
sheet['A1'] = '代碼'
sheet['B1'] = '名稱'
sheet['C1'] = '最新價'
sheet['D1'] = '漲跌幅'
sheet['E1'] = '漲跌額'
sheet['F1'] = '成交量'
sheet['G1'] = '成交額'
sheet['H1'] = '振幅'
for i in range(20):
sheet.append([daimas[i],names[i],zuixinjias[i],zhangdiefus[i],zhangdiees[i],
chengjiaoliangs[i],chengjiaoes[i],zhenfus[i],zuigaos[i],zuidis[i],
jinkais[i],zuoshous[i],liangbis[i],huanshoulvs[i],shiyinglvs[i]])
讓我們來看看最終效果:
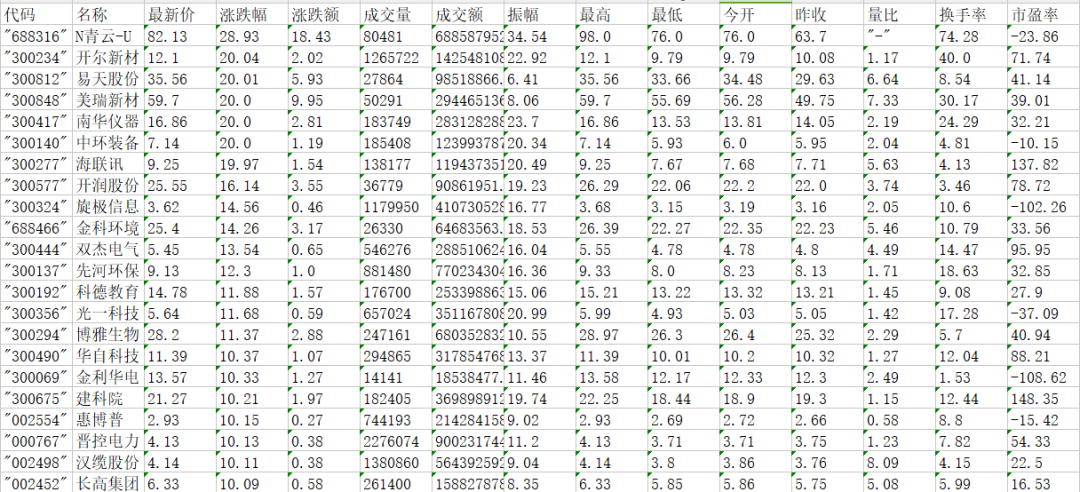
總結(jié)
1. 本文詳細(xì)的介紹了如何從東方財富網(wǎng)上批量獲取股票數(shù)據(jù),請讀者仔細(xì)閱讀,并加以操作。
2. 東方財富網(wǎng)沒有反爬,但是本著友好的原則,用戶在爬取時最好使用間隔爬取。
3. 本文僅供參考學(xué)習(xí),不做商用。
4. 后臺回復(fù)【股票】即可獲取源代碼。
掃下方二維碼添加我的私人微信,可以在我的朋友圈獲取最新的Python學(xué)習(xí)資料,以及近期推文中的源碼或者其他資源,另外不定期開放學(xué)習(xí)交流群,以及朋友圈福利(送書、紅包、學(xué)習(xí)資源等)。
掃碼查看我朋友圈
獲取最新學(xué)習(xí)資源
學(xué)習(xí)更多: 整理了我開始分享學(xué)習(xí)筆記到現(xiàn)在超過250篇優(yōu)質(zhì)文章,涵蓋數(shù)據(jù)分析、爬蟲、機器學(xué)習(xí)等方面,別再說不知道該從哪開始,實戰(zhàn)哪里找了
“點贊”傳統(tǒng)美德不能丟