
四萬字Hive調(diào)優(yōu)全方位指南(推薦收藏)
一、基于Hadoop的數(shù)據(jù)倉庫Hive基礎(chǔ)知識
二、HiveSQL語法
三、Hive性能優(yōu)化
四、Hive性能優(yōu)化之?dāng)?shù)據(jù)傾斜專題
五、HiveSQL優(yōu)化十二板斧
六、Hive面試題(一)
七、Hive/Hadoop高頻面試點(diǎn)集合(二)
基于Hadoop的數(shù)據(jù)倉庫Hive基礎(chǔ)知識
Hive是基于Hadoop的數(shù)據(jù)倉庫工具,可對存儲在HDFS上的文件中的數(shù)據(jù)集進(jìn)行數(shù)據(jù)整理、特殊查詢和分析處理,提供了類似于SQL語言的查詢語言–HiveQL,可通過HQL語句實(shí)現(xiàn)簡單的MR統(tǒng)計(jì),Hive將HQL語句轉(zhuǎn)換成MR任務(wù)進(jìn)行執(zhí)行。
一、概述
1.1 數(shù)據(jù)倉庫概念
數(shù)據(jù)倉庫(Data Warehouse)是一個(gè)面向主題的(Subject Oriented)、集成的(Integrated)、相對穩(wěn)定的(Non-Volatile)、反應(yīng)歷史變化(Time Variant)的數(shù)據(jù)集合,用于支持管理決策。
數(shù)據(jù)倉庫體系結(jié)構(gòu)通常含四個(gè)層次:數(shù)據(jù)源、數(shù)據(jù)存儲和管理、數(shù)據(jù)服務(wù)、數(shù)據(jù)應(yīng)用。
數(shù)據(jù)源:是數(shù)據(jù)倉庫的數(shù)據(jù)來源,含外部數(shù)據(jù)、現(xiàn)有業(yè)務(wù)系統(tǒng)和文檔資料等;
數(shù)據(jù)集成:完成數(shù)據(jù)的抽取、清洗、轉(zhuǎn)換和加載任務(wù),數(shù)據(jù)源中的數(shù)據(jù)采用ETL(Extract-Transform-Load)工具以固定的周期加載到數(shù)據(jù)倉庫中。
數(shù)據(jù)存儲和管理:此層次主要涉及對數(shù)據(jù)的存儲和管理,含數(shù)據(jù)倉庫、數(shù)據(jù)集市、數(shù)據(jù)倉庫檢測、運(yùn)行與維護(hù)工具和元數(shù)據(jù)管理等。
數(shù)據(jù)服務(wù):為前端和應(yīng)用提供數(shù)據(jù)服務(wù),可直接從數(shù)據(jù)倉庫中獲取數(shù)據(jù)供前端應(yīng)用使用,也可通過OLAP(OnLine Analytical Processing,聯(lián)機(jī)分析處理)服務(wù)器為前端應(yīng)用提供負(fù)責(zé)的數(shù)據(jù)服務(wù)。
數(shù)據(jù)應(yīng)用:此層次直接面向用戶,含數(shù)據(jù)查詢工具、自由報(bào)表工具、數(shù)據(jù)分析工具、數(shù)據(jù)挖掘工具和各類應(yīng)用系統(tǒng)。
1.2 傳統(tǒng)數(shù)據(jù)倉庫的問題
無法滿足快速增長的海量數(shù)據(jù)存儲需求,傳統(tǒng)數(shù)據(jù)倉庫基于關(guān)系型數(shù)據(jù)庫,橫向擴(kuò)展性較差,縱向擴(kuò)展有限。
無法處理不同類型的數(shù)據(jù),傳統(tǒng)數(shù)據(jù)倉庫只能存儲結(jié)構(gòu)化數(shù)據(jù),企業(yè)業(yè)務(wù)發(fā)展,數(shù)據(jù)源的格式越來越豐富。
傳統(tǒng)數(shù)據(jù)倉庫建立在關(guān)系型數(shù)據(jù)倉庫之上,計(jì)算和處理能力不足,當(dāng)數(shù)據(jù)量達(dá)到TB級后基本無法獲得好的性能。
1.3 Hive
Hive是建立在Hadoop之上的數(shù)據(jù)倉庫,由Facebook開發(fā),在某種程度上可以看成是用戶編程接口,本身并不存儲和處理數(shù)據(jù),依賴于HDFS存儲數(shù)據(jù),依賴MR處理數(shù)據(jù)。有類SQL語言HiveQL,不完全支持SQL標(biāo)準(zhǔn),如,不支持更新操作、索引和事務(wù),其子查詢和連接操作也存在很多限制。
Hive把HQL語句轉(zhuǎn)換成MR任務(wù)后,采用批處理的方式對海量數(shù)據(jù)進(jìn)行處理。數(shù)據(jù)倉庫存儲的是靜態(tài)數(shù)據(jù),很適合采用MR進(jìn)行批處理。Hive還提供了一系列對數(shù)據(jù)進(jìn)行提取、轉(zhuǎn)換、加載的工具,可以存儲、查詢和分析存儲在HDFS上的數(shù)據(jù)。
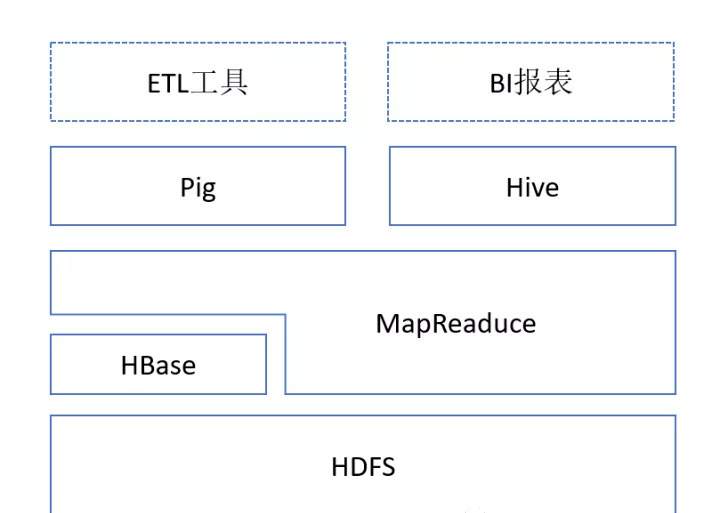
1.4 Hive與Hadoop生態(tài)系統(tǒng)中其他組件的關(guān)系
Hive依賴于HDFS存儲數(shù)據(jù),依賴MR處理數(shù)據(jù);
Pig可作為Hive的替代工具,是一種數(shù)據(jù)流語言和運(yùn)行環(huán)境,適合用于在Hadoop平臺上查詢半結(jié)構(gòu)化數(shù)據(jù)集,用于與ETL過程的一部分,即將外部數(shù)據(jù)裝載到Hadoop集群中,轉(zhuǎn)換為用戶需要的數(shù)據(jù)格式;
HBase是一個(gè)面向列的、分布式可伸縮的數(shù)據(jù)庫,可提供數(shù)據(jù)的實(shí)時(shí)訪問功能,而Hive只能處理靜態(tài)數(shù)據(jù),主要是BI報(bào)表數(shù)據(jù),Hive的初衷是為減少復(fù)雜MR應(yīng)用程序的編寫工作,HBase則是為了實(shí)現(xiàn)對數(shù)據(jù)的實(shí)時(shí)訪問。
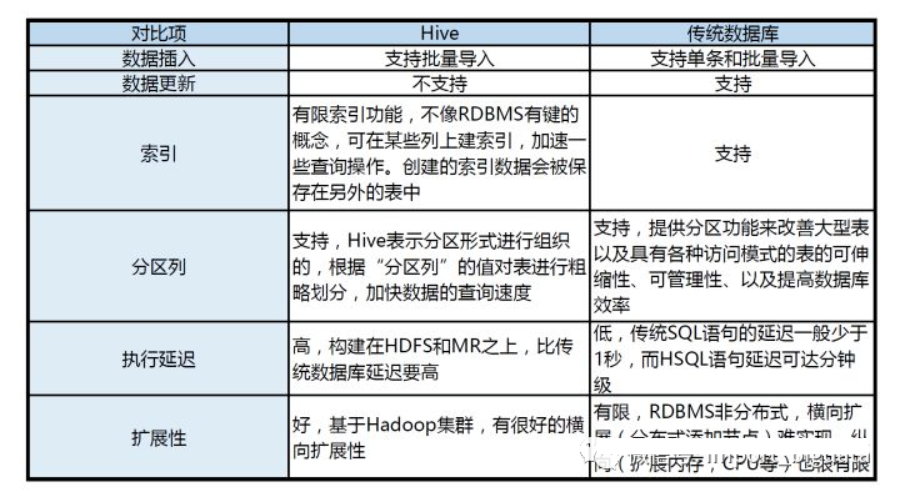
1.5 Hive與傳統(tǒng)數(shù)據(jù)庫的對比
1.6 Hive的部署和應(yīng)用
1.6.1 Hive在企業(yè)大數(shù)據(jù)分析平臺中的應(yīng)用
當(dāng)前企業(yè)中部署的大數(shù)據(jù)分析平臺,除Hadoop的基本組件HDFS和MR外,還結(jié)合使用Hive、Pig、HBase、Mahout,從而滿足不同業(yè)務(wù)場景需求。
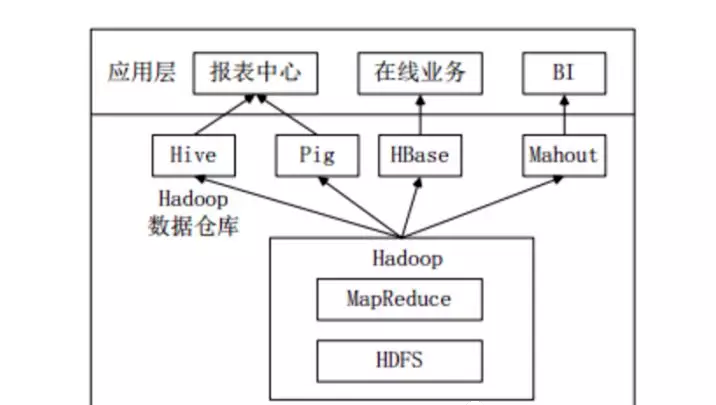
上圖是企業(yè)中一種常見的大數(shù)據(jù)分析平臺部署框架 ,在這種部署架構(gòu)中:
Hive和Pig用于報(bào)表中心,Hive用于分析報(bào)表,Pig用于報(bào)表中數(shù)據(jù)的轉(zhuǎn)換工作。
HBase用于在線業(yè)務(wù),HDFS不支持隨機(jī)讀寫操作,而HBase正是為此開發(fā),可較好地支持實(shí)時(shí)訪問數(shù)據(jù)。
Mahout提供一些可擴(kuò)展的機(jī)器學(xué)習(xí)領(lǐng)域的經(jīng)典算法實(shí)現(xiàn),用于創(chuàng)建商務(wù)智能(BI)應(yīng)用程序。
二、Hive系統(tǒng)架構(gòu)
下圖顯示Hive的主要組成模塊、Hive如何與Hadoop交互工作、以及從外部訪問Hive的幾種典型方式。
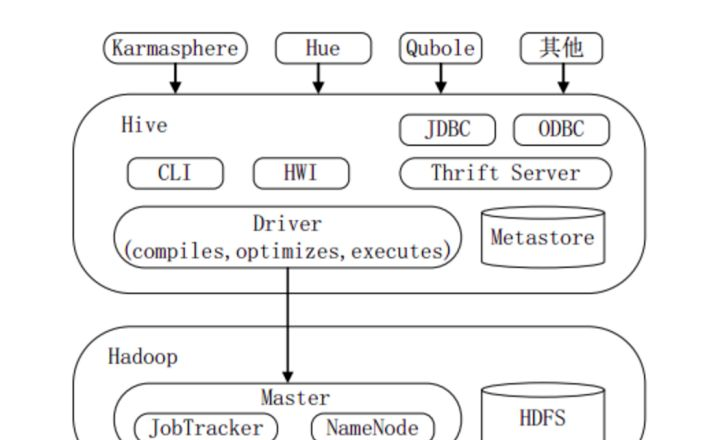
Hive主要由以下三個(gè)模塊組成:
用戶接口模塊,含CLI、HWI、JDBC、Thrift Server等,用來實(shí)現(xiàn)對Hive的訪問。CLI是Hive自帶的命令行界面;HWI是Hive的一個(gè)簡單網(wǎng)頁界面;JDBC、ODBC以及Thrift Server可向用戶提供進(jìn)行編程的接口,其中Thrift Server是基于Thrift軟件框架開發(fā)的,提供Hive的RPC通信接口。
驅(qū)動(dòng)模塊(Driver),含編譯器、優(yōu)化器、執(zhí)行器等,負(fù)責(zé)把HiveQL語句轉(zhuǎn)換成一系列MR作業(yè),所有命令和查詢都會(huì)進(jìn)入驅(qū)動(dòng)模塊,通過該模塊的解析變異,對計(jì)算過程進(jìn)行優(yōu)化,然后按照指定的步驟執(zhí)行。
元數(shù)據(jù)存儲模塊(Metastore),是一個(gè)獨(dú)立的關(guān)系型數(shù)據(jù)庫,通常與MySQL數(shù)據(jù)庫連接后創(chuàng)建的一個(gè)MySQL實(shí)例,也可以是Hive自帶的Derby數(shù)據(jù)庫實(shí)例。此模塊主要保存表模式和其他系統(tǒng)元數(shù)據(jù),如表的名稱、表的列及其屬性、表的分區(qū)及其屬性、表的屬性、表中數(shù)據(jù)所在位置信息等。
喜歡圖形界面的用戶,可采用幾種典型的外部訪問工具:Karmasphere、Hue、Qubole等。
三、Hive工作原理
3.1 SQL語句轉(zhuǎn)換成MapReduce作業(yè)的基本原理
3.1.1 用MapReduce實(shí)現(xiàn)連接操作
假設(shè)連接(join)的兩個(gè)表分別是用戶表User(uid,name)和訂單表Order(uid,orderid),具體的SQL命令:
SELECT name, orderid FROM User u JOIN Order o ON u.uid=o.uid;
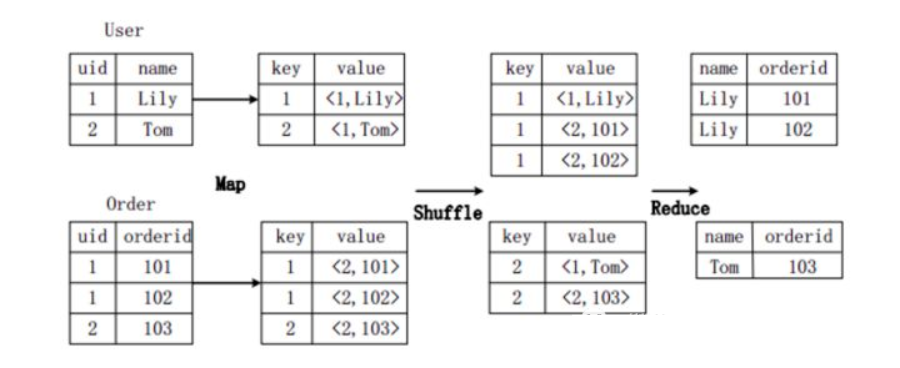
上圖描述了連接操作轉(zhuǎn)換為MapReduce操作任務(wù)的具體執(zhí)行過程。
首先,在Map階段,
User表以uid為key,以name和表的標(biāo)記位(這里User的標(biāo)記位記為1)為value,進(jìn)行Map操作,把表中記錄轉(zhuǎn)換生成一系列KV對的形式。比如,User表中記錄(1,Lily)轉(zhuǎn)換為鍵值對(1,< 1,Lily>),其中第一個(gè)“1”是uid的值,第二個(gè)“1”是表User的標(biāo)記位,用來標(biāo)示這個(gè)鍵值對來自User表;
同樣,Order表以uid為key,以orderid和表的標(biāo)記位(這里表Order的標(biāo)記位記為2)為值進(jìn)行Map操作,把表中的記錄轉(zhuǎn)換生成一系列KV對的形式;
接著,在Shuffle階段,把User表和Order表生成的KV對按鍵值進(jìn)行Hash,然后傳送給對應(yīng)的Reduce機(jī)器執(zhí)行。比如KV對(1,< 1,Lily>)、(1,< 2,101>)、(1,< 2,102>)傳送到同一臺Reduce機(jī)器上。當(dāng)Reduce機(jī)器接收到這些KV對時(shí),還需按表的標(biāo)記位對這些鍵值對進(jìn)行排序,以優(yōu)化連接操作;
最后,在Reduce階段,對同一臺Reduce機(jī)器上的鍵值對,根據(jù)“值”(value)中的表標(biāo)記位,對來自表User和Order的數(shù)據(jù)進(jìn)行笛卡爾積連接操作,以生成最終的結(jié)果。比如鍵值對(1,< 1,Lily>)與鍵值對(1,< 2,101>)、(1,< 2,102>)的連接結(jié)果是(Lily,101)、(Lily,102)。
3.1.2用MR實(shí)現(xiàn)分組操作
假設(shè)分?jǐn)?shù)表Score(rank, level),具有rank(排名)和level(級別)兩個(gè)屬性,需要進(jìn)行一個(gè)分組(Group By)操作,功能是把表Score的不同片段按照rank和level的組合值進(jìn)行合并,并計(jì)算不同的組合值有幾條記錄。SQL語句命令如下:
SELECT rank,level,count(*) as value FROM score GROUP BY rank,level;
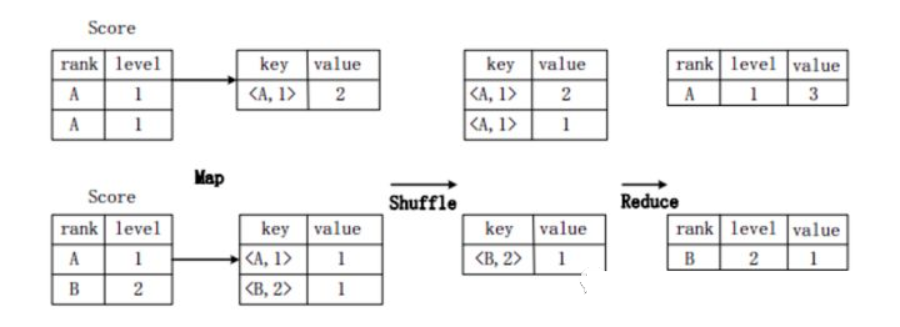
上圖描述分組操作轉(zhuǎn)化為MapReduce任務(wù)的具體執(zhí)行過程。
首先,在Map階段,對表Score進(jìn)行Map操作,生成一系列KV對,其鍵為< rank, level>,值為“擁有該< rank, level>組合值的記錄的條數(shù)”。比如,Score表的第一片段中有兩條記錄(A,1),所以進(jìn)行Map操作后,轉(zhuǎn)化為鍵值對(< A,1>,2);
接著在Shuffle階段,對Score表生成的鍵值對,按照“鍵”的值進(jìn)行Hash,然后根據(jù)Hash結(jié)果傳送給對應(yīng)的Reduce機(jī)器去執(zhí)行。比如,鍵值對(< A,1>,2)、(< A,1>,1)傳送到同一臺Reduce機(jī)器上,鍵值對(< B,2>,1)傳送另一Reduce機(jī)器上。然后,Reduce機(jī)器對接收到的這些鍵值對,按“鍵”的值進(jìn)行排序;
在Reduce階段,把具有相同鍵的所有鍵值對的“值”進(jìn)行累加,生成分組的最終結(jié)果。比如,在同一臺Reduce機(jī)器上的鍵值對(< A,1>,2)和(< A,1>,1)Reduce操作后的輸出結(jié)果為(A,1,3)。
3.2 Hive中SQL查詢轉(zhuǎn)換成MR作業(yè)的過程
當(dāng)Hive接收到一條HQL語句后,需要與Hadoop交互工作來完成該操作。HQL首先進(jìn)入驅(qū)動(dòng)模塊,由驅(qū)動(dòng)模塊中的編譯器解析編譯,并由優(yōu)化器對該操作進(jìn)行優(yōu)化計(jì)算,然后交給執(zhí)行器去執(zhí)行。執(zhí)行器通常啟動(dòng)一個(gè)或多個(gè)MR任務(wù),有時(shí)也不啟動(dòng)(如SELECT * FROM tb1,全表掃描,不存在投影和選擇操作)
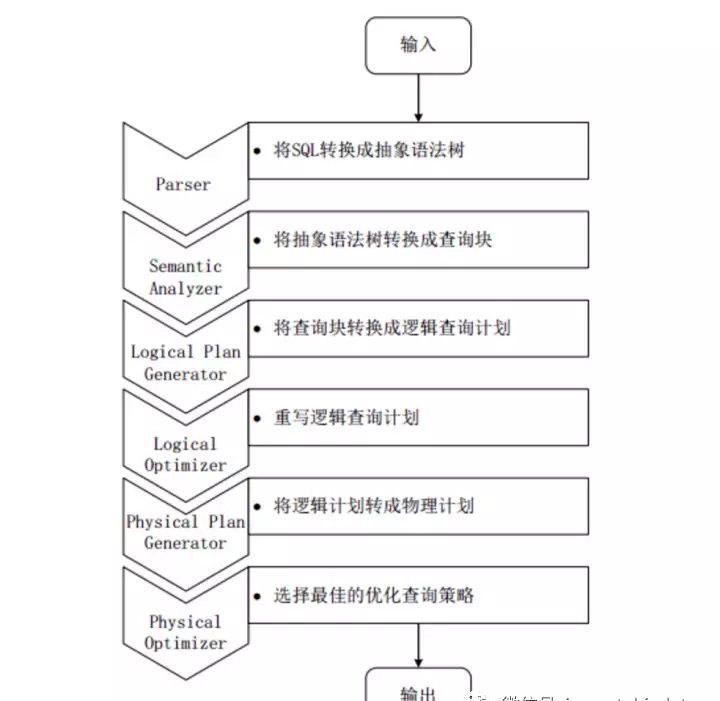
上圖是Hive把HQL語句轉(zhuǎn)化成MR任務(wù)進(jìn)行執(zhí)行的詳細(xì)過程。
由驅(qū)動(dòng)模塊中的編譯器–Antlr語言識別工具,對用戶輸入的SQL語句進(jìn)行詞法和語法解析,將HQL語句轉(zhuǎn)換成抽象語法樹(AST Tree)的形式;
遍歷抽象語法樹,轉(zhuǎn)化成QueryBlock查詢單元。因?yàn)锳ST結(jié)構(gòu)復(fù)雜,不方便直接翻譯成MR算法程序。其中QueryBlock是一條最基本的SQL語法組成單元,包括輸入源、計(jì)算過程、和輸入三個(gè)部分;
遍歷QueryBlock,生成OperatorTree(操作樹),OperatorTree由很多邏輯操作符組成,如TableScanOperator、SelectOperator、FilterOperator、JoinOperator、GroupByOperator和ReduceSinkOperator等。這些邏輯操作符可在Map、Reduce階段完成某一特定操作;
Hive驅(qū)動(dòng)模塊中的邏輯優(yōu)化器對OperatorTree進(jìn)行優(yōu)化,變換OperatorTree的形式,合并多余的操作符,減少M(fèi)R任務(wù)數(shù)、以及Shuffle階段的數(shù)據(jù)量;
遍歷優(yōu)化后的OperatorTree,根據(jù)OperatorTree中的邏輯操作符生成需要執(zhí)行的MR任務(wù);
啟動(dòng)Hive驅(qū)動(dòng)模塊中的物理優(yōu)化器,對生成的MR任務(wù)進(jìn)行優(yōu)化,生成最終的MR任務(wù)執(zhí)行計(jì)劃;
最后,有Hive驅(qū)動(dòng)模塊中的執(zhí)行器,對最終的MR任務(wù)執(zhí)行輸出。
Hive驅(qū)動(dòng)模塊中的執(zhí)行器執(zhí)行最終的MR任務(wù)時(shí),Hive本身不會(huì)生成MR算法程序。它通過一個(gè)表示“Job執(zhí)行計(jì)劃”的XML文件,來驅(qū)動(dòng)內(nèi)置的、原生的Mapper和Reducer模塊。Hive通過和JobTracker通信來初始化MR任務(wù),而不需直接部署在JobTracker所在管理節(jié)點(diǎn)上執(zhí)行。通常在大型集群中,會(huì)有專門的網(wǎng)關(guān)機(jī)來部署Hive工具,這些網(wǎng)關(guān)機(jī)的作用主要是遠(yuǎn)程操作和管理節(jié)點(diǎn)上的JobTracker通信來執(zhí)行任務(wù)。Hive要處理的數(shù)據(jù)文件常存儲在HDFS上,HDFS由名稱節(jié)點(diǎn)(NameNode)來管理。
四、Hive HA基本原理
在實(shí)際應(yīng)用中,Hive也暴露出不穩(wěn)定的問題,在極少數(shù)情況下,會(huì)出現(xiàn)端口不響應(yīng)或進(jìn)程丟失問題。Hive HA(High Availablity)可以解決這類問題。
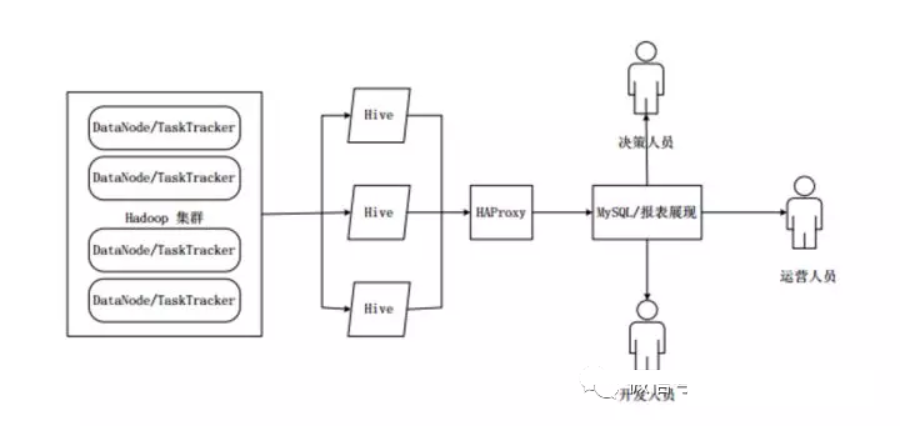
在Hive HA中,在Hadoop集群上構(gòu)建的數(shù)據(jù)倉庫是由多個(gè)Hive實(shí)例進(jìn)行管理的,這些Hive實(shí)例被納入到一個(gè)資源池中,由HAProxy提供統(tǒng)一的對外接口。客戶端的查詢請求,首先訪問HAProxy,由HAProxy對訪問請求進(jìn)行轉(zhuǎn)發(fā)。HAProxy收到請求后,會(huì)輪詢資源池中可用的Hive實(shí)例,執(zhí)行邏輯可用性測試。
如果某個(gè)Hive實(shí)例邏輯可用,就會(huì)把客戶端的訪問請求轉(zhuǎn)發(fā)到Hive實(shí)例上;
如果某個(gè)實(shí)例不可用,就把它放入黑名單,并繼續(xù)從資源池中取出下一個(gè)Hive實(shí)例進(jìn)行邏輯可用性測試。
對于黑名單中的Hive,Hive HA會(huì)每隔一段時(shí)間進(jìn)行統(tǒng)一處理,首先嘗試重啟該Hive實(shí)例,如果重啟成功,就再次把它放入資源池中。
由于HAProxy提供統(tǒng)一的對外訪問接口,因此,對于程序開發(fā)人員來說,可把它看成一臺超強(qiáng)“Hive”。
五、Impala
5.1 Impala簡介
Impala由Cloudera公司開發(fā),提供SQL語義,可查詢存儲在Hadoop和HBase上的PB級海量數(shù)據(jù)。Hive也提供SQL語義,但底層執(zhí)行任務(wù)仍借助于MR,實(shí)時(shí)性不好,查詢延遲較高。
Impala作為新一代開源大數(shù)據(jù)分析引擎,最初參照Dremel(由Google開發(fā)的交互式數(shù)據(jù)分析系統(tǒng)),支持實(shí)時(shí)計(jì)算,提供與Hive類似的功能,在性能上高出Hive3~30倍。Impala可能會(huì)超過Hive的使用率能成為Hadoop上最流行的實(shí)時(shí)計(jì)算平臺。Impala采用與商用并行關(guān)系數(shù)據(jù)庫類似的分布式查詢引擎,可直接從HDFS、HBase中用SQL語句查詢數(shù)據(jù),不需把SQL語句轉(zhuǎn)換成MR任務(wù),降低延遲,可很好地滿足實(shí)時(shí)查詢需求。
Impala不能替換Hive,可提供一個(gè)統(tǒng)一的平臺用于實(shí)時(shí)查詢。Impala的運(yùn)行依賴于Hive的元數(shù)據(jù)(Metastore)。Impala和Hive采用相同的SQL語法、ODBC驅(qū)動(dòng)程序和用戶接口,可統(tǒng)一部署Hive和Impala等分析工具,同時(shí)支持批處理和實(shí)時(shí)查詢。
5.2 Impala系統(tǒng)架構(gòu)
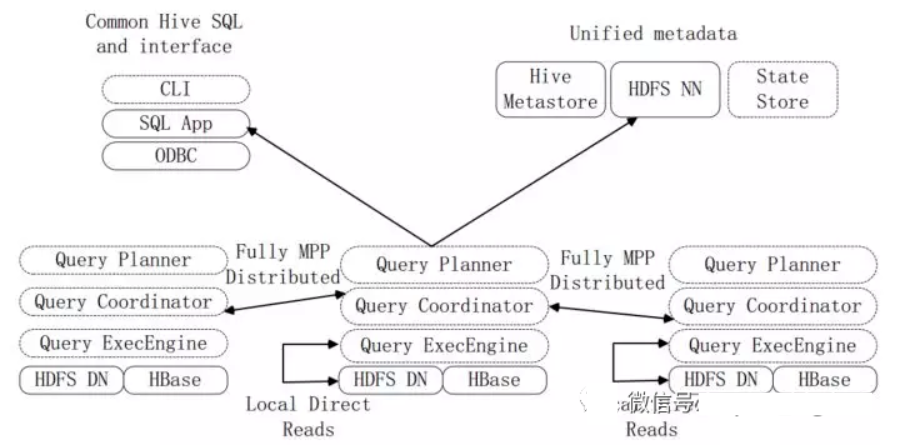
上圖是Impala系統(tǒng)結(jié)構(gòu)圖,虛線模塊數(shù)據(jù)Impala組件。Impala和Hive、HDFS、HBase統(tǒng)一部署在Hadoop平臺上。Impala由Impalad、State Store和CLI三部分組成。
Implalad:是Impala的一個(gè)進(jìn)程,負(fù)責(zé)協(xié)調(diào)客戶端提供的查詢執(zhí)行,給其他Impalad分配任務(wù),以及收集其他Impalad的執(zhí)行結(jié)果進(jìn)行匯總。Impalad也會(huì)執(zhí)行其他Impalad給其分配的任務(wù),主要是對本地HDFS和HBase里的部分?jǐn)?shù)據(jù)進(jìn)行操作。Impalad進(jìn)程主要含Query Planner、Query Coordinator和Query Exec Engine三個(gè)模塊,與HDFS的數(shù)據(jù)節(jié)點(diǎn)(HDFS DataNode)運(yùn)行在同一節(jié)點(diǎn)上,且完全分布運(yùn)行在MPP(大規(guī)模并行處理系統(tǒng))架構(gòu)上。
State Store:收集分布在集群上各個(gè)Impalad進(jìn)程的資源信息,用于查詢的調(diào)度,它會(huì)創(chuàng)建一個(gè)statestored進(jìn)程,來跟蹤集群中的Impalad的健康狀態(tài)及位置信息。statestored進(jìn)程通過創(chuàng)建多個(gè)線程來處理Impalad的注冊訂閱以及與多個(gè)Impalad保持心跳連接,此外,各Impalad都會(huì)緩存一份State Store中的信息。當(dāng)State Store離線后,Impalad一旦發(fā)現(xiàn)State Store處于離線狀態(tài)時(shí),就會(huì)進(jìn)入恢復(fù)模式,并進(jìn)行返回注冊。當(dāng)State Store重新加入集群后,自動(dòng)恢復(fù)正常,更新緩存數(shù)據(jù)。
CLI:CLI給用戶提供了執(zhí)行查詢的命令行工具。Impala還提供了Hue、JDBC及ODBC使用接口。
5.3 Impala查詢執(zhí)行過程
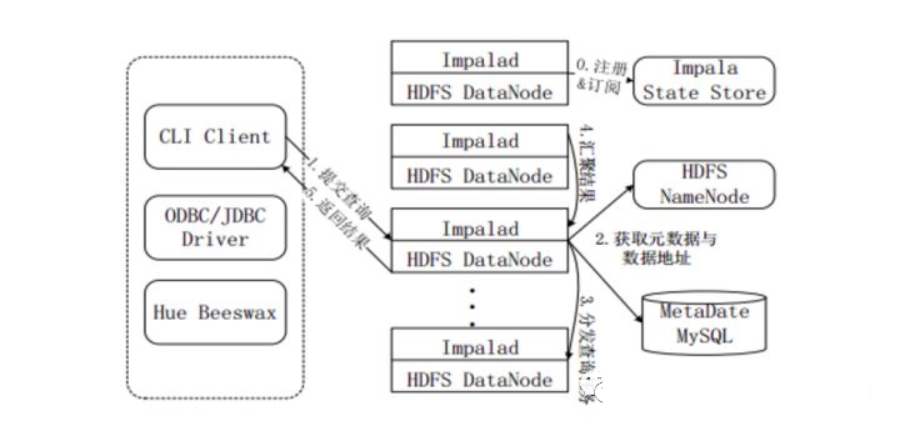
注冊和訂閱。當(dāng)用戶提交查詢前,Impala先創(chuàng)建一個(gè)Impalad進(jìn)程來負(fù)責(zé)協(xié)調(diào)客戶端提交的查詢,該進(jìn)程會(huì)向State Store提交注冊訂閱信息,State Store會(huì)創(chuàng)建一個(gè)statestored進(jìn)程,statestored進(jìn)程通過創(chuàng)建多個(gè)線程來處理Impalad的注冊訂閱信息。
提交查詢。通過CLI提交一個(gè)查詢到Impalad進(jìn)程,Impalad的Query Planner對SQL語句解析,生成解析樹;Planner將解析樹變成若干PlanFragment,發(fā)送到Query Coordinator。其中PlanFragment由PlanNode組成,能被分發(fā)到單獨(dú)的節(jié)點(diǎn)上執(zhí)行,每個(gè)PlanNode表示一個(gè)關(guān)系操作和對其執(zhí)行優(yōu)化需要的信息。
獲取元數(shù)據(jù)與數(shù)據(jù)地址。Query Coordinator從MySQL元數(shù)據(jù)庫中獲取元數(shù)據(jù)(即查詢需要用到哪些數(shù)據(jù)),從HDFS的名稱節(jié)點(diǎn)中獲取數(shù)據(jù)地址(即數(shù)據(jù)被保存到哪個(gè)數(shù)據(jù)節(jié)點(diǎn)上),從而得到存儲這個(gè)查詢相關(guān)數(shù)據(jù)的所有數(shù)據(jù)節(jié)點(diǎn)。
分發(fā)查詢?nèi)蝿?wù)。Query Coordinator初始化相應(yīng)的Impalad上的任務(wù),即把查詢?nèi)蝿?wù)分配給所有存儲這個(gè)查詢相關(guān)數(shù)據(jù)的數(shù)據(jù)節(jié)點(diǎn)。
匯聚結(jié)果。Query Executor通過流式交換中間輸出,并由Query Coordinator匯聚來自各個(gè)Impalad的結(jié)果。
返回結(jié)果。Query Coordinator把匯總后的結(jié)果返回給CLI客戶端。
5.4 Impala與Hive
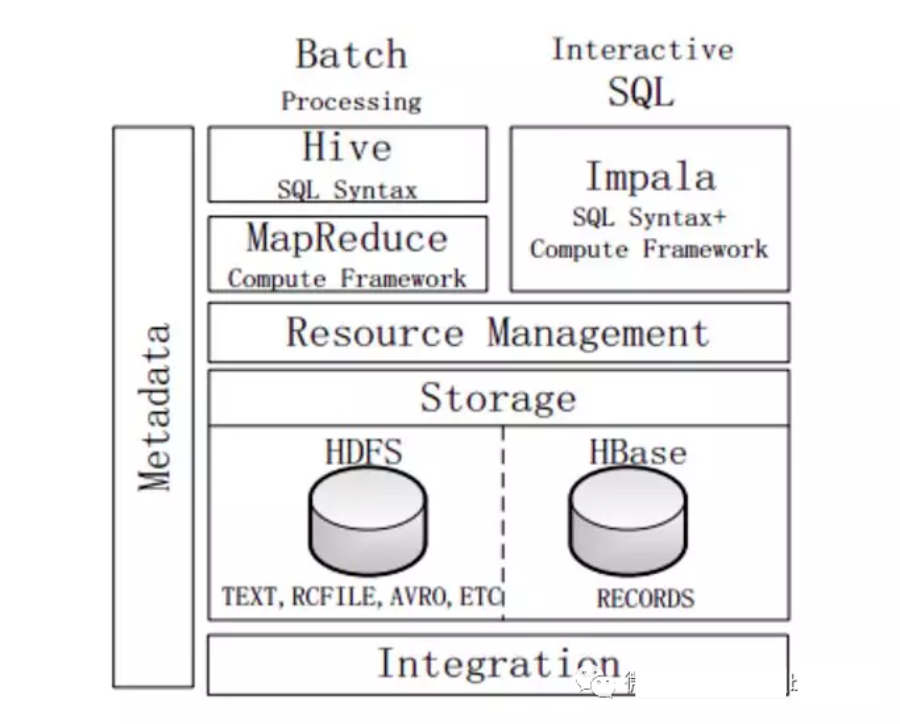
不同點(diǎn):
Hive適合長時(shí)間批處理查詢分析;而Impala適合進(jìn)行交互式SQL查詢。
Hive依賴于MR計(jì)算框架,執(zhí)行計(jì)劃組合成管道型MR任務(wù)模型進(jìn)行執(zhí)行;而Impala則把執(zhí)行計(jì)劃表現(xiàn)為一棵完整的執(zhí)行計(jì)劃樹,可更自然地分發(fā)執(zhí)行計(jì)劃到各個(gè)Impalad執(zhí)行查詢。
Hive在執(zhí)行過程中,若內(nèi)存放不下所有數(shù)據(jù),則會(huì)使用外存,以保證查詢能夠順利執(zhí)行完成;而Impala在遇到內(nèi)存放不下數(shù)據(jù)時(shí),不會(huì)利用外存,所以Impala處理查詢時(shí)會(huì)受到一定的限制。
相同點(diǎn):
使用相同的存儲數(shù)據(jù)池,都支持把數(shù)據(jù)存儲在HDFS和HBase中,其中HDFS支持存儲TEXT、RCFILE、PARQUET、AVRO、ETC等格式的數(shù)據(jù),HBase存儲表中記錄。
使用相同的元數(shù)據(jù)。
對SQL的解析處理比較類似,都是通過詞法分析生成執(zhí)行計(jì)劃。
HiveSQL語法原理
hive的DDL語法
對數(shù)據(jù)庫的操作
創(chuàng)建數(shù)據(jù)庫:
create database if not exists myhive; 說明:hive的表存放位置模式是由hive-site.xml當(dāng)中的一個(gè)屬性指定 的 :hive.metastore.warehouse.dir
創(chuàng)建數(shù)據(jù)庫并指定hdfs存儲位置 : create database myhive2 location '/myhive2';
修改數(shù)據(jù)庫:
alter database myhive2 set dbproperties('createtime'='20210329');說明:可以使用alter database 命令來修改數(shù)據(jù)庫的一些屬性。但是數(shù)據(jù)庫的元數(shù)據(jù)信息是不可更改的,包括數(shù)據(jù)庫的名稱以及數(shù)據(jù)庫所在的位置
對數(shù)據(jù)表的操作
對管理表(內(nèi)部表)的操作:
建內(nèi)部表:
hive (myhive)> use myhive; -- 使用myhive數(shù)據(jù)庫hive (myhive)> create table stu(id int,name string);hive (myhive)> insert into stu values (1,"zhangsan");hive (myhive)> insert into stu values (1,"zhangsan"),(2,"lisi"); -- 一次插入多條數(shù)據(jù)hive?(myhive)>?select?*?from?stu;
hive建表時(shí)候的字段類型:
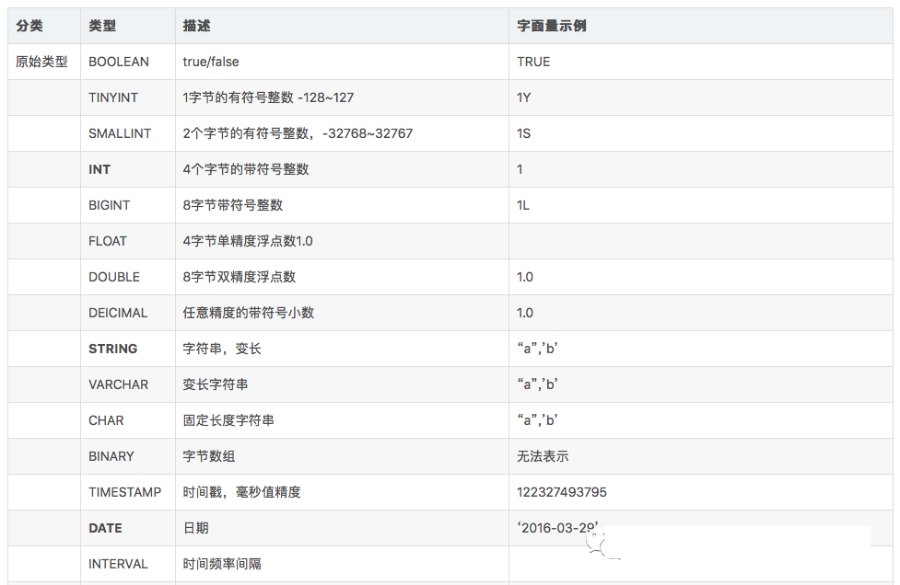

對decimal類型簡單解釋下:
用法:decimal(11,2) 代表最多有11位數(shù)字,其中后2位是小數(shù),整數(shù)部分是9位;如果整數(shù)部分超過9位,則這個(gè)字段就會(huì)變成null;如果小數(shù)部分不足2位,則后面用0補(bǔ)齊兩位,如果小數(shù)部分超過兩位,則超出部分四舍五入;
也可直接寫 decimal,后面不指定位數(shù),默認(rèn)是 decimal(10,0) 整數(shù)10位,沒有小數(shù)
對外部表操作:
外部表因?yàn)槭侵付ㄆ渌膆dfs路徑的數(shù)據(jù)加載到表當(dāng)中來,所以hive表會(huì)認(rèn)為自己不完全獨(dú)占這份數(shù)據(jù),所以刪除hive表的時(shí)候,數(shù)據(jù)仍然存放在hdfs當(dāng)中,不會(huì)刪掉,只會(huì)刪除表的元數(shù)據(jù)
構(gòu)建外部表:
create?external?table?student?(s_id?string,s_name?string)?row?format?delimited?fields?????terminated?by?'\t';對分區(qū)表的操作:
創(chuàng)建分區(qū)表的語法:
create?table?score(s_id?string,?s_score?int)?partitioned?by?(month?string);創(chuàng)建一個(gè)表帶多個(gè)分區(qū):
create?table?score2?(s_id?string,?s_score?int)?partitioned?by?(year?string,month?string,day?string);注意:
hive表創(chuàng)建的時(shí)候可以用 location 指定一個(gè)文件或者文件夾,當(dāng)指定文件夾時(shí),hive會(huì)加載文件夾下的所有文件,當(dāng)表中無分區(qū)時(shí),這個(gè)文件夾下不能再有文件夾,否則報(bào)錯(cuò)
當(dāng)表是分區(qū)表時(shí),比如 partitioned by (day string), 則這個(gè)文件夾下的每一個(gè)文件夾就是一個(gè)分區(qū),且文件夾名為 day=20201123 這種格式,然后使用:msck repair table score; 修復(fù)表結(jié)構(gòu),成功之后即可看到數(shù)據(jù)已經(jīng)全部加載到表當(dāng)中去了
對分桶表操作:
將數(shù)據(jù)按照指定的字段進(jìn)行分成多個(gè)桶中去,就是按照分桶字段進(jìn)行哈希劃分到多個(gè)文件當(dāng)中去
分區(qū)就是分文件夾,分桶就是分文件
創(chuàng)建桶表
create?table?course?(c_id?string,c_name?string)?clustered?by(c_id)?into?3?buckets;桶表的數(shù)據(jù)加載:由于桶表的數(shù)據(jù)加載通過hdfs dfs -put文件或者通過load data均不可以,只能通過insert overwrite 進(jìn)行加載
所以把文件加載到桶表中,需要先創(chuàng)建普通表,并通過insert overwrite的方式將普通表的數(shù)據(jù)通過查詢的方式加載到桶表當(dāng)中去
hive的DQL查詢語法
單表查詢
SELECT [ALL | DISTINCT] select_expr, select_expr, ...FROM table_reference[WHERE where_condition][GROUP BY col_list [HAVING condition]][CLUSTER BY col_list| [DISTRIBUTE BY col_list] [SORT BY| ORDER BY col_list]][LIMIT number]
注意:
1、order by 會(huì)對輸入做全局排序,因此只有一個(gè)reducer,會(huì)導(dǎo)致當(dāng)輸入規(guī)模較大時(shí),需要較長的計(jì)算時(shí)間。
2、sort by不是全局排序,其在數(shù)據(jù)進(jìn)入reducer前完成排序。因此,如果用sort by進(jìn)行排序,并且設(shè)置mapred.reduce.tasks>1,則sort by只保證每個(gè)reducer的輸出有序,不保證全局有序。
3、distribute by(字段)根據(jù)指定的字段將數(shù)據(jù)分到不同的reducer,且分發(fā)算法是hash散列。
4、Cluster by(字段) 除了具有Distribute by的功能外,還會(huì)對該字段進(jìn)行排序。
因此,如果分桶和sort字段是同一個(gè)時(shí),此時(shí),cluster by = distribute by + sort by
Hive函數(shù)
聚合函數(shù)
hive支持 count(),max(),min(),sum(),avg() 等常用的聚合函數(shù)
注意:
聚合操作時(shí)要注意null值;
count(*) 包含null值,統(tǒng)計(jì)所有行數(shù);
count(id) 不包含null值;
min 求最小值是不包含null,除非所有值都是null;
avg 求平均值也是不包含null
非空集合總體變量函數(shù): var_pop
語法: var_pop(col)
返回值: double
說明: 統(tǒng)計(jì)結(jié)果集中col非空集合的總體變量(忽略null)
非空集合樣本變量函數(shù): var_samp
語法: var_samp (col)
返回值: double
說明: 統(tǒng)計(jì)結(jié)果集中col非空集合的樣本變量(忽略null)總體標(biāo)準(zhǔn)偏離函數(shù): stddev_pop
語法: stddev_pop(col)
返回值: double
說明: 該函數(shù)計(jì)算總體標(biāo)準(zhǔn)偏離,并返回總體變量的平方根,其返回值與VAR_POP函數(shù)的平方根相同中位數(shù)函數(shù): percentile
語法: percentile(BIGINT col, p)
返回值: double
說明: 求準(zhǔn)確的第pth個(gè)百分位數(shù),p必須介于0和1之間,但是col字段目前只支持整數(shù),不支持浮點(diǎn)數(shù)類型
條件函數(shù)
If函數(shù): if
語法: if(boolean testCondition, T valueTrue, T valueFalseOrNull)返回值: T說明: 當(dāng)條件testCondition為TRUE時(shí),返回valueTrue;否則返回valueFalseOrNullhive> select if(1=2,100,200) ;200hive> select if(1=1,100,200) ;100非空查找函數(shù): coalesce
語法: coalesce(T v1, T v2, …)
返回值: T
說明: 返回參數(shù)中的第一個(gè)非空值;如果所有值都為NULL,那么返回NULLhive> select coalesce(null,'100','50') ;100條件判斷函數(shù):case when (兩種寫法,其一)
語法: case when a then b [when c then d]* [else e] end返回值: T說明:如果a為TRUE,則返回b;如果c為TRUE,則返回d;否則返回ehive> select case when 1=2 then 'tom' when 2=2 then 'mary' else 'tim' end from tableName;mary條件判斷函數(shù):case when(兩種寫法,其二)
語法: case a when b then c [when d then e]* [else f] end返回值: T說明:如果a等于b,那么返回c;如果a等于d,那么返回e;否則返回fhive> Select case 100 when 50 then 'tom' when 100 then 'mary' else 'tim' end from tableName;mary
日期函數(shù)
注:以下SQL語句中的 from tableName 可去掉,不影響查詢結(jié)果
獲取當(dāng)前UNIX時(shí)間戳函數(shù): unix_timestamp
語法: unix_timestamp()
返回值: bigint
說明: 獲得當(dāng)前時(shí)區(qū)的UNIX時(shí)間戳
hive> select unix_timestamp() from tableName;1616906976
UNIX時(shí)間戳轉(zhuǎn)日期函數(shù): from_unixtime
語法: from_unixtime(bigint unixtime[, string format])
返回值: string
說明: 轉(zhuǎn)化UNIX時(shí)間戳(從1970-01-01 00:00:00 UTC到指定時(shí)間的秒數(shù))到當(dāng)前時(shí)區(qū)的時(shí)間格式
hive> select from_unixtime(1616906976,'yyyyMMdd') from tableName;20210328
日期轉(zhuǎn)UNIX時(shí)間戳函數(shù): unix_timestamp
語法: unix_timestamp(string date)
返回值: bigint
說明: 轉(zhuǎn)換格式為"yyyy-MM-dd HH:mm:ss"的日期到UNIX時(shí)間戳。如果轉(zhuǎn)化失敗,則返回0。
hive> select unix_timestamp('2021-03-08 14:21:15') from tableName;1615184475
指定格式日期轉(zhuǎn)UNIX時(shí)間戳函數(shù): unix_timestamp
語法: unix_timestamp(string date, string pattern)
返回值: bigint
說明: 轉(zhuǎn)換pattern格式的日期到UNIX時(shí)間戳。如果轉(zhuǎn)化失敗,則返回0。
hive> select unix_timestamp('2021-03-08 14:21:15','yyyyMMdd HH:mm:ss') from tableName;1615184475
日期時(shí)間轉(zhuǎn)日期函數(shù): to_date
語法: to_date(string timestamp)
返回值: string
說明: 返回日期時(shí)間字段中的日期部分。
hive> select to_date('2021-03-28 14:03:01') from tableName;2021-03-28
日期轉(zhuǎn)年函數(shù): year
語法: year(string date)
返回值: int
說明: 返回日期中的年。
hive> select year('2021-03-28 10:03:01') from tableName;2021hive> select year('2021-03-28') from tableName;2021
日期轉(zhuǎn)月函數(shù): month
語法: month (string date)
返回值: int
說明: 返回日期中的月份。
hive> select month('2020-12-28 12:03:01') from tableName;12hive> select month('2021-03-08') from tableName;8
日期轉(zhuǎn)天函數(shù): day
語法: day (string date)
返回值: int
說明: 返回日期中的天。
hive> select day('2020-12-08 10:03:01') from tableName;8hive> select day('2020-12-24') from tableName;24
日期轉(zhuǎn)小時(shí)函數(shù): hour
語法: hour (string date)
返回值: int
說明: 返回日期中的小時(shí)。
hive> select hour('2020-12-08 10:03:01') from tableName;10
日期轉(zhuǎn)分鐘函數(shù): minute
語法: minute (string date)
返回值: int
說明: 返回日期中的分鐘。
hive> select minute('2020-12-08 10:03:01') from tableName;3
日期轉(zhuǎn)秒函數(shù): second
語法: second (string date)
返回值: int
說明: 返回日期中的秒。
hive> select second('2020-12-08 10:03:01') from tableName;1
日期轉(zhuǎn)周函數(shù): weekofyear
語法: weekofyear (string date)
返回值: int
說明: 返回日期在當(dāng)前的周數(shù)。
hive> select weekofyear('2020-12-08 10:03:01') from tableName;49
日期比較函數(shù): datediff
語法: datediff(string enddate, string startdate)
返回值: int
說明: 返回結(jié)束日期減去開始日期的天數(shù)。
hive> select datediff('2020-12-08','2012-05-09') from tableName;213
日期增加函數(shù): date_add
語法: date_add(string startdate, int days)
返回值: string
說明: 返回開始日期startdate增加days天后的日期。
hive> select date_add('2020-12-08',10) from tableName;2020-12-18
日期減少函數(shù): date_sub
語法: date_sub (string startdate, int days)
返回值: string
說明: 返回開始日期startdate減少days天后的日期。
hive> select date_sub('2020-12-08',10) from tableName;2020-11-28
字符串函數(shù)
字符串長度函數(shù):length
語法: length(string A)
返回值: int
說明:返回字符串A的長度
hive> select length('abcedfg') from tableName;
7
字符串反轉(zhuǎn)函數(shù):reverse
語法: reverse(string A)
返回值: string
說明:返回字符串A的反轉(zhuǎn)結(jié)果
hive> select reverse('abcedfg') from tableName;
gfdecba
字符串連接函數(shù):concat
語法: concat(string A, string B…)
返回值: string
說明:返回輸入字符串連接后的結(jié)果,支持任意個(gè)輸入字符串
hive> select concat('abc','def’,'gh')from tableName;
abcdefgh
hive當(dāng)中的lateral view 與 explode以及reflect和窗口函數(shù)使用explode函數(shù)將hive表中的Map和Array字段數(shù)據(jù)進(jìn)行拆分
lateral view用于和split、explode等UDTF一起使用的,能將一行數(shù)據(jù)拆分成多行數(shù)據(jù),在此基礎(chǔ)上可以對拆分的數(shù)據(jù)進(jìn)行聚合,lateral view首先為原始表的每行調(diào)用UDTF,UDTF會(huì)把一行拆分成一行或者多行,lateral view在把結(jié)果組合,產(chǎn)生一個(gè)支持別名表的虛擬表。
其中explode還可以用于將hive一列中復(fù)雜的array或者map結(jié)構(gòu)拆分成多行
需求:現(xiàn)在有數(shù)據(jù)格式如下
zhangsan child1,child2,child3,child4 k1:v1,k2:v2lisi child5,child6,child7,child8 k3:v3,k4:v4
字段之間使用\t分割,需求將所有的child進(jìn)行拆開成為一列
+----------+--+| mychild |+----------+--+| child1 || child2 || child3 || child4 || child5 || child6 || child7 || child8 |+----------+--+
將map的key和value也進(jìn)行拆開,成為如下結(jié)果
+-----------+-------------+--+| mymapkey | mymapvalue |+-----------+-------------+--+| k1 | v1 || k2 | v2 || k3 | v3 || k4 | v4 |+-----------+-------------+--+
行轉(zhuǎn)列
相關(guān)參數(shù)說明:
CONCAT(string A/col, string B/col…):返回輸入字符串連接后的結(jié)果,支持任意個(gè)輸入字符串;
CONCAT_WS(separator, str1, str2,...):它是一個(gè)特殊形式的 CONCAT()。第一個(gè)參數(shù)剩余參數(shù)間的分隔符。分隔符可以是與剩余參數(shù)一樣的字符串。如果分隔符是 NULL,返回值也將為 NULL。這個(gè)函數(shù)會(huì)跳過分隔符參數(shù)后的任何 NULL 和空字符串。分隔符將被加到被連接的字符串之間;
COLLECT_SET(col):函數(shù)只接受基本數(shù)據(jù)類型,它的主要作用是將某字段的值進(jìn)行去重匯總,產(chǎn)生array類型字段。
數(shù)據(jù)準(zhǔn)備: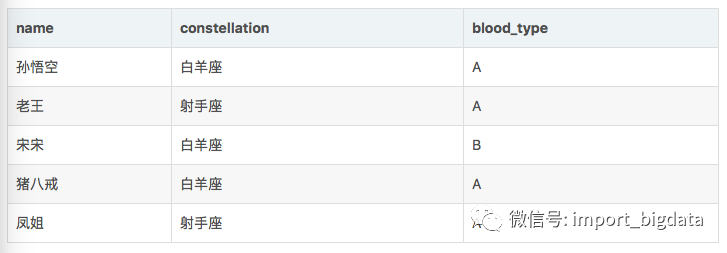
需求: 把星座和血型一樣的人歸類到一起。結(jié)果如下:
射手座,A 老王|鳳姐
白羊座,A 孫悟空|豬八戒
白羊座,B 宋宋
實(shí)現(xiàn)步驟: 創(chuàng)建本地constellation.txt,導(dǎo)入數(shù)據(jù)
node03服務(wù)器執(zhí)行以下命令創(chuàng)建文件,注意數(shù)據(jù)使用\t進(jìn)行分割
cd /export/servers/hivedatasvim constellation.txt
數(shù)據(jù)如下:
孫悟空 白羊座 A
老王 射手座 A
宋宋 白羊座 B
豬八戒 白羊座 A
鳳姐 射手座 A
創(chuàng)建hive表并導(dǎo)入數(shù)據(jù)
hive (hive_explode)> create table person_info(name string,constellation string,blood_type string)row format delimited fields terminated by "\t";
加載數(shù)據(jù)
hive (hive_explode)> load data local inpath '/export/servers/hivedatas/constellation.txt' into table person_info;
按需求查詢數(shù)據(jù)
hive (hive_explode)> selectt1.base,concat_ws('|', collect_set(t1.name)) namefrom(selectname,concat(constellation, "," , blood_type) basefromperson_info) t1group byt1.base;
列轉(zhuǎn)行
所需函數(shù):
EXPLODE(col):將hive一列中復(fù)雜的array或者map結(jié)構(gòu)拆分成多行。
LATERAL VIEW
用法:LATERAL VIEW udtf(expression) tableAlias AS columnAlias
解釋:用于和split, explode等UDTF一起使用,它能夠?qū)⒁涣袛?shù)據(jù)拆成多行數(shù)據(jù),在此基礎(chǔ)上可以對拆分后的數(shù)據(jù)進(jìn)行聚合。
數(shù)據(jù)準(zhǔn)備:
cd /export/servers/hivedatasvim movie.txt文件內(nèi)容如下: 數(shù)據(jù)字段之間使用\t進(jìn)行分割《疑犯追蹤》 懸疑,動(dòng)作,科幻,劇情《Lie to me》 懸疑,警匪,動(dòng)作,心理,劇情《戰(zhàn)狼2》 戰(zhàn)爭,動(dòng)作,災(zāi)難
需求: 將電影分類中的數(shù)組數(shù)據(jù)展開。結(jié)果如下:
《疑犯追蹤》 懸疑
《疑犯追蹤》 動(dòng)作
《疑犯追蹤》 科幻
《疑犯追蹤》 劇情
《Lie to me》 懸疑
《Lie to me》 警匪
《Lie to me》 動(dòng)作
《Lie to me》 心理
《Lie to me》 劇情
《戰(zhàn)狼2》 戰(zhàn)爭
《戰(zhàn)狼2》 動(dòng)作
《戰(zhàn)狼2》 災(zāi)難
實(shí)現(xiàn)步驟:
創(chuàng)建hive表
create table movie_info(movie string,category array<string>)row format delimited fields terminated by "\t"collection items terminated by ",";
加載數(shù)據(jù)
load data local inpath "/export/servers/hivedatas/movie.txt" into table movie_info;
按需求查詢數(shù)據(jù)
selectmovie,category_namefrommovie_info lateral view explode(category) table_tmp as category_name;
窗口函數(shù)與分析函數(shù)
在sql中有一類函數(shù)叫做聚合函數(shù),例如sum()、avg()、max()等等,這類函數(shù)可以將多行數(shù)據(jù)按照規(guī)則聚集為一行,一般來講聚集后的行數(shù)是要少于聚集前的行數(shù)的。但是有時(shí)我們想要既顯示聚集前的數(shù)據(jù),又要顯示聚集后的數(shù)據(jù),這時(shí)我們便引入了窗口函數(shù)。窗口函數(shù)又叫OLAP函數(shù)/分析函數(shù),窗口函數(shù)兼具分組和排序功能。
窗口函數(shù)最重要的關(guān)鍵字是 partition by 和 order by。
具體語法如下:over (partition by xxx order by xxx)
其他一些窗口函數(shù) lag,lead,first_value,last_value
LAG
LAG(col,n,DEFAULT) 用于統(tǒng)計(jì)窗口內(nèi)往上第n行值第一個(gè)參數(shù)為列名,第二個(gè)參數(shù)為往上第n行(可選,默認(rèn)為1),第三個(gè)參數(shù)為默認(rèn)值(當(dāng)往上第n行為NULL時(shí)候,取默認(rèn)值,如不指定,則為NULL)LEAD
與LAG相反 LEAD(col,n,DEFAULT) 用于統(tǒng)計(jì)窗口內(nèi)往下第n行值 第一個(gè)參數(shù)為列名,第二個(gè)參數(shù)為往下第n行(可選,默認(rèn)為1),第三個(gè)參數(shù)為默認(rèn)值(當(dāng)往下第n行為NULL時(shí)候,取默認(rèn)值,如不指定,則為NULL)FIRST_VALUE
取分組內(nèi)排序后,截止到當(dāng)前行,第一個(gè)值LAST_VALUE
取分組內(nèi)排序后,截止到當(dāng)前行,最后一個(gè)值
如果想要取分組內(nèi)排序后最后一個(gè)值,則需要變通一下:
SELECT cookieid,createtime,url,ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY createtime) AS rn,LAST_VALUE(url) OVER(PARTITION BY cookieid ORDER BY createtime) AS last1,FIRST_VALUE(url) OVER(PARTITION BY cookieid ORDER BY createtime DESC) AS last2FROM test_t4ORDER BY cookieid,createtime;
特別注意order by
如果不指定ORDER BY,則進(jìn)行排序混亂,會(huì)出現(xiàn)錯(cuò)誤的結(jié)果cume_dist,percent_rank
這兩個(gè)序列分析函數(shù)不是很常用,注意:序列函數(shù)不支持WINDOW子句CUME_DIST 和order byd的排序順序有關(guān)系
CUME_DIST 小于等于當(dāng)前值的行數(shù)/分組內(nèi)總行數(shù) order 默認(rèn)順序 正序 升序 比如,統(tǒng)計(jì)小于等于當(dāng)前薪水的人數(shù),所占總?cè)藬?shù)的比例PERCENT_RANK
PERCENT_RANK 分組內(nèi)當(dāng)前行的RANK值-1/分組內(nèi)總行數(shù)-1
經(jīng)調(diào)研 該函數(shù)顯示現(xiàn)實(shí)意義不明朗 有待于繼續(xù)考證grouping sets,grouping__id,cube,rollup
這幾個(gè)分析函數(shù)通常用于OLAP中,不能累加,而且需要根據(jù)不同維度上鉆和下鉆的指標(biāo)統(tǒng)計(jì),比如,分小時(shí)、天、月的UV數(shù)。GROUPING SETS
grouping sets是一種將多個(gè)group by 邏輯寫在一個(gè)sql語句中的便利寫法。
等價(jià)于將不同維度的GROUP BY結(jié)果集進(jìn)行UNION ALL。
GROUPING__ID,表示結(jié)果屬于哪一個(gè)分組集合。CUBE
根據(jù)GROUP BY的維度的所有組合進(jìn)行聚合。ROLLUP
是CUBE的子集,以最左側(cè)的維度為主,從該維度進(jìn)行層級聚合。
Hive性能優(yōu)化
Hive作為大數(shù)據(jù)平臺舉足輕重的框架,以其穩(wěn)定性和簡單易用性也成為當(dāng)前構(gòu)建企業(yè)級數(shù)據(jù)倉庫時(shí)使用最多的框架之一。
Hive性能調(diào)優(yōu)是我們大數(shù)據(jù)從業(yè)者必須掌握的技能。以下將給大家講解Hive性能調(diào)優(yōu)的一些方法及技巧。
一、 SQL語句優(yōu)化
SQL語句優(yōu)化涉及到的內(nèi)容太多,因篇幅有限,不能一一介紹到,所以就拿幾個(gè)典型舉例,讓大家學(xué)到這種思想,以后遇到類似調(diào)優(yōu)問題可以往這幾個(gè)方面多思考下。
1. union all
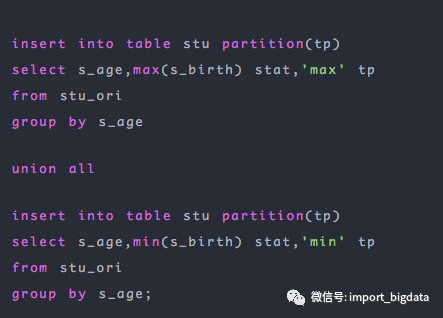
我們簡單分析上面的SQL語句,就是將每個(gè)年齡段的最大和最小的生日獲取出來放到同一張表中,union all 前后的兩個(gè)語句都是對同一張表按照s_age進(jìn)行分組,然后分別取最大值和最小值。
上面的SQL對同一張表的相同字段進(jìn)行兩次分組,這顯然造成了極大浪費(fèi),我們能不能改造下呢,當(dāng)然是可以的,為大家介紹一個(gè)語法:from ... insert into ... ,這個(gè)語法將from前置,作用就是使用一張表,可以進(jìn)行多次插入操作:
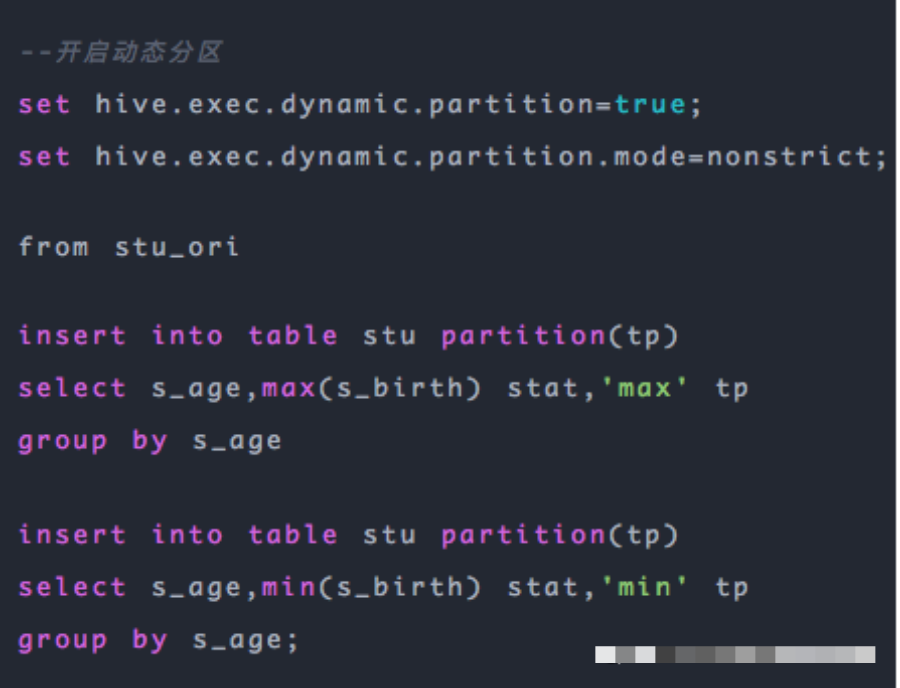
上面的SQL就可以對stu_ori表的s_age字段分組一次而進(jìn)行兩次不同的插入操作。
這個(gè)例子告訴我們一定要多了解SQL語句,如果我們不知道這種語法,一定不會(huì)想到這種方式的。
2. distinct
先看一個(gè)SQL,去重計(jì)數(shù):
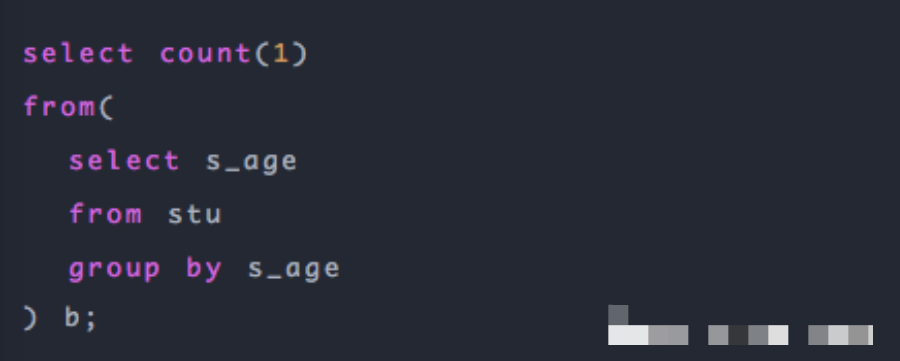
這是簡單統(tǒng)計(jì)年齡的枚舉值個(gè)數(shù),為什么不用distinct?

有人說因?yàn)樵跀?shù)據(jù)量特別大的情況下使用第一種方式(group by)能夠有效避免Reduce端的數(shù)據(jù)傾斜,但事實(shí)如此嗎?
我們先不管數(shù)據(jù)量特別大這個(gè)問題,就當(dāng)前的業(yè)務(wù)和環(huán)境下使用distinct一定會(huì)比上面那種子查詢的方式效率高。原因有以下幾點(diǎn):
- 上面進(jìn)行去重的字段是年齡字段,要知道年齡的枚舉值是非常有限的,這個(gè)數(shù)量是很小的。
- distinct的命令會(huì)在內(nèi)存中構(gòu)建一個(gè)hashtable,查找去重的時(shí)間復(fù)雜度是O(1);group by在不同版本間變動(dòng)比較大,有的版本會(huì)用構(gòu)建hashtable的形式去重,有的版本會(huì)通過排序的方式, 排序最優(yōu)時(shí)間復(fù)雜度無法到O(1)。另外,第一種方式(group by)去重會(huì)轉(zhuǎn)化為兩個(gè)任務(wù),會(huì)消耗更多的磁盤網(wǎng)絡(luò)I/O資源。
- 最新的Hive 3.0中新增了 count(distinct) 優(yōu)化,通過配置 hive.optimize.countdistinct,即使真的出現(xiàn)數(shù)據(jù)傾斜也可以自動(dòng)優(yōu)化,自動(dòng)改變SQL執(zhí)行的邏輯。
- 第二種方式(distinct)比第一種方式(group by)代碼簡潔,表達(dá)的意思簡單明了,如果沒有特殊的問題,代碼簡潔就是優(yōu)!
這個(gè)例子告訴我們,有時(shí)候我們不要過度優(yōu)化,調(diào)優(yōu)講究適時(shí)調(diào)優(yōu),過早進(jìn)行調(diào)優(yōu)有可能做的是無用功甚至產(chǎn)生負(fù)效應(yīng),在調(diào)優(yōu)上投入的工作成本和回報(bào)不成正比。調(diào)優(yōu)需要遵循一定的原則。
二、數(shù)據(jù)格式優(yōu)化
我們執(zhí)行同樣的SQL語句及同樣的數(shù)據(jù),只是數(shù)據(jù)存儲格式不同,得到如下執(zhí)行時(shí)長:
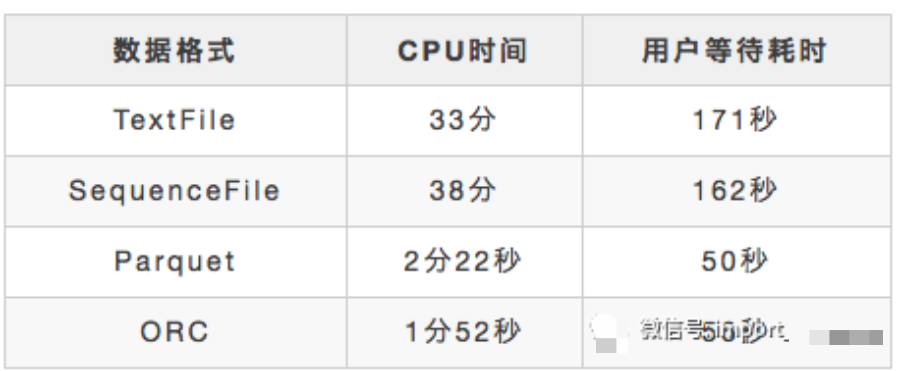
查詢TextFile類型的數(shù)據(jù)表耗時(shí)33分鐘, 查詢ORC類型的表耗時(shí)1分52秒,時(shí)間得以極大縮短,可見不同的數(shù)據(jù)存儲格式也能給HiveSQL性能帶來極大的影響。
三、小文件過多優(yōu)化
小文件如果過多,對 hive 來說,在進(jìn)行查詢時(shí),每個(gè)小文件都會(huì)當(dāng)成一個(gè)塊,啟動(dòng)一個(gè)Map任務(wù)來完成,而一個(gè)Map任務(wù)啟動(dòng)和初始化的時(shí)間遠(yuǎn)遠(yuǎn)大于邏輯處理的時(shí)間,就會(huì)造成很大的資源浪費(fèi)。而且,同時(shí)可執(zhí)行的Map數(shù)量是受限的。
所以我們有必要對小文件過多進(jìn)行優(yōu)化。
四、并行執(zhí)行優(yōu)化
Hive會(huì)將一個(gè)查詢轉(zhuǎn)化成一個(gè)或者多個(gè)階段。這樣的階段可以是MapReduce階段、抽樣階段、合并階段、limit階段。或者Hive執(zhí)行過程中可能需要的其他階段。默認(rèn)情況下,Hive一次只會(huì)執(zhí)行一個(gè)階段。不過,某個(gè)特定的job可能包含眾多的階段,而這些階段可能并非完全互相依賴的,也就是說有些階段是可以并行執(zhí)行的,這樣可能使得整個(gè)job的執(zhí)行時(shí)間縮短。如果有更多的階段可以并行執(zhí)行,那么job可能就越快完成。
通過設(shè)置參數(shù)hive.exec.parallel值為true,就可以開啟并發(fā)執(zhí)行。在共享集群中,需要注意下,如果job中并行階段增多,那么集群利用率就會(huì)增加。
set hive.exec.parallel=true; //打開任務(wù)并行執(zhí)行
set hive.exec.parallel.thread.number=16; //同一個(gè)sql允許最大并行度,默認(rèn)為8。
當(dāng)然得是在系統(tǒng)資源比較空閑的時(shí)候才有優(yōu)勢,否則沒資源,并行也起不來。
五、JVM優(yōu)化
JVM重用是Hadoop調(diào)優(yōu)參數(shù)的內(nèi)容,其對Hive的性能具有非常大的影響,特別是對于很難避免小文件的場景或task特別多的場景,這類場景大多數(shù)執(zhí)行時(shí)間都很短。
Hadoop的默認(rèn)配置通常是使用派生JVM來執(zhí)行map和Reduce任務(wù)的。這時(shí)JVM的啟動(dòng)過程可能會(huì)造成相當(dāng)大的開銷,尤其是執(zhí)行的job包含有成百上千task任務(wù)的情況。JVM重用可以使得JVM實(shí)例在同一個(gè)job中重新使用N次。N的值可以在Hadoop的mapred-site.xml文件中進(jìn)行配置。通常在10-20之間,具體多少需要根據(jù)具體業(yè)務(wù)場景測試得出。
<property><name>mapreduce.job.jvm.numtasksname><value>10value><description>How many tasks to run per jvm. If set to -1, there isno limit.description>property>
我們也可以在hive中設(shè)置
set mapred.job.reuse.jvm.num.tasks=10; //這個(gè)設(shè)置來設(shè)置我們的jvm重用
這個(gè)功能的缺點(diǎn)是,開啟JVM重用將一直占用使用到的task插槽,以便進(jìn)行重用,直到任務(wù)完成后才能釋放。如果某個(gè)“不平衡的”job中有某幾個(gè)reduce task執(zhí)行的時(shí)間要比其他Reduce task消耗的時(shí)間多的多的話,那么保留的插槽就會(huì)一直空閑著卻無法被其他的job使用,直到所有的task都結(jié)束了才會(huì)釋放。
六、推測執(zhí)行優(yōu)化
在分布式集群環(huán)境下,因?yàn)槌绦騜ug(包括Hadoop本身的bug),負(fù)載不均衡或者資源分布不均等原因,會(huì)造成同一個(gè)作業(yè)的多個(gè)任務(wù)之間運(yùn)行速度不一致,有些任務(wù)的運(yùn)行速度可能明顯慢于其他任務(wù)(比如一個(gè)作業(yè)的某個(gè)任務(wù)進(jìn)度只有50%,而其他所有任務(wù)已經(jīng)運(yùn)行完畢),則這些任務(wù)會(huì)拖慢作業(yè)的整體執(zhí)行進(jìn)度。為了避免這種情況發(fā)生,Hadoop采用了推測執(zhí)行(Speculative Execution)機(jī)制,它根據(jù)一定的法則推測出“拖后腿”的任務(wù),并為這樣的任務(wù)啟動(dòng)一個(gè)備份任務(wù),讓該任務(wù)與原始任務(wù)同時(shí)處理同一份數(shù)據(jù),并最終選用最先成功運(yùn)行完成任務(wù)的計(jì)算結(jié)果作為最終結(jié)果。
設(shè)置開啟推測執(zhí)行參數(shù):Hadoop的mapred-site.xml文件中進(jìn)行配置:
<property><name>mapreduce.map.speculativename><value>truevalue><description>If true, then multiple instances of some map tasksmay be executed in parallel.description>property><property><name>mapreduce.reduce.speculativename><value>truevalue><description>If true, then multiple instances of some reduce tasksmay be executed in parallel.description>property>
hive本身也提供了配置項(xiàng)來控制reduce-side的推測執(zhí)行:
set hive.mapred.reduce.tasks.speculative.execution=true
Hive性能優(yōu)化之?dāng)?shù)據(jù)傾斜專題
大家可以參考《Hive性能調(diào)優(yōu) | 》。關(guān)于Hive性能優(yōu)化,一直是一個(gè)核心關(guān)注的點(diǎn)。
Map數(shù)
通常情況下,作業(yè)會(huì)通過input的目錄產(chǎn)生一個(gè)或者多個(gè)map任務(wù)。主要的決定因素有:input的文件總個(gè)數(shù),input的文件大小,集群設(shè)置的文件塊大小(目前為128M,可在hive中通過set dfs.block.size;命令查看到,該參數(shù)不能自定義修改);
舉例:a)一個(gè)大文件:假設(shè)input目錄下有1個(gè)文件a,大小為780M,那么hadoop會(huì)將該文件a分隔成7個(gè)塊(6個(gè)128m的塊和1個(gè)12m的塊),從而產(chǎn)生7個(gè)map數(shù)。b) 多個(gè)小文件:假設(shè)input目錄下有3個(gè)文件a,b,c大小分別為10m,20m,150m,那么hadoop會(huì)分隔成4個(gè)塊(10m,20m,128m,22m),從而產(chǎn)生4個(gè)map數(shù)。即,如果文件大于塊大小(128m),那么會(huì)拆分,如果小于塊大小,則把該文件當(dāng)成一個(gè)塊。
是不是map數(shù)越多越好? 答案是否定的。如果一個(gè)任務(wù)有很多小文件(遠(yuǎn)遠(yuǎn)小于塊大小128m),則每個(gè)小文件也會(huì)被當(dāng)做一個(gè)塊,用一個(gè)map任務(wù)來完成,而一個(gè)map任務(wù)啟動(dòng)和初始化的時(shí)間遠(yuǎn)遠(yuǎn)大于邏輯處理的時(shí)間,就會(huì)造成很大的資源浪費(fèi)。而且,同時(shí)可執(zhí)行的map數(shù)是受限的。
是不是保證每個(gè)map處理接近128m的文件塊,就高枕無憂了?答案也是不一定。比如有一個(gè)127m的文件,正常會(huì)用一個(gè)map去完成,但這個(gè)文件只有一個(gè)或者兩個(gè)字段,卻有幾千萬的記錄,如果map處理的邏輯比較復(fù)雜,用一個(gè)map任務(wù)去做,肯定也比較耗時(shí)。
針對上面的問題3和4,我們需要采取兩種方式來解決:即減少map數(shù)和增加map數(shù)。
如何適當(dāng)?shù)脑黾觤ap數(shù)
當(dāng)input的文件都很大,任務(wù)邏輯復(fù)雜,map執(zhí)行非常慢的時(shí)候,可以考慮增加Map數(shù),來使得每個(gè)map處理的數(shù)據(jù)量減少,從而提高任務(wù)的執(zhí)行效率。針對上面的第4條 假設(shè)有這樣一個(gè)任務(wù):
Select data_desc,count(1),count(distinct id),sum(case when …),sum(case when …),sum(…)from a group by data_desc
如果表a只有一個(gè)文件,大小為120M,但包含幾千萬的記錄,如果用1個(gè)map去完成這個(gè)任務(wù),肯定是比較耗時(shí)的,這種情況下,我們要考慮將這一個(gè)文件合理的拆分成多個(gè),這樣就可以用多個(gè)map任務(wù)去完成。
set mapreduce.job.reduces =10;create table a_1 asselect * from adistribute by rand();
這樣會(huì)將a表的記錄,隨機(jī)的分散到包含10個(gè)文件的a_1表中,再用a_1代替上面sql中的a表,則會(huì)用10個(gè)map任務(wù)去完成。
每個(gè)map任務(wù)處理大于12M(幾百萬記錄)的數(shù)據(jù),效率肯定會(huì)好很多。
看上去,貌似這兩種有些矛盾,一個(gè)是要合并小文件,一個(gè)是要把大文件拆成小文件,這點(diǎn)正是重點(diǎn)需要關(guān)注的地方,根據(jù)實(shí)際情況,控制map數(shù)量需要遵循兩個(gè)原則:使大數(shù)據(jù)量利用合適的map數(shù);使單個(gè)map任務(wù)處理合適的數(shù)據(jù)量;
調(diào)整reduce數(shù)
調(diào)整reduce個(gè)數(shù)方法一
a) 每個(gè)Reduce 處理的數(shù)據(jù)量默認(rèn)是256MB
hive.exec.reducers.bytes.per.reducer=256123456b) 每個(gè)任務(wù)最大的reduce數(shù),默認(rèn)為1009
hive.exec.reducers.max=1009c)計(jì)算reducer數(shù)的公式
N=min(參數(shù)2,總輸入數(shù)據(jù)量/參數(shù)1)
參數(shù)1:每個(gè)Reduce處理的最大數(shù)據(jù)量 參數(shù)2:每個(gè)任務(wù)最大Reduce數(shù)量
調(diào)整reduce個(gè)數(shù)方法二
在hadoop的mapred-default.xml文件中修改 設(shè)置每個(gè)job的Reduce個(gè)數(shù)
set mapreduce.job.reduces = 15;reduce個(gè)數(shù)并不是越多越好
a)過多的啟動(dòng)和初始化reduce也會(huì)消耗時(shí)間和資源;b) 有多少個(gè)reduce,就會(huì)有多少個(gè)輸出文件,如果生成了很多個(gè)小文件,那么如果這些小文件作為下一個(gè)任務(wù)的輸入,則也會(huì)出現(xiàn)小文件過多的問題;
總結(jié): 在設(shè)置reduce個(gè)數(shù)的時(shí)候也需要考慮這兩個(gè)原則:處理大數(shù)據(jù)量利用合適的reduce數(shù);使單個(gè)reduce任務(wù)處理數(shù)據(jù)量大小要合適。
HiveSQL優(yōu)化十二板斧
limit限制調(diào)整
一般情況下,Limit語句還是需要執(zhí)行整個(gè)查詢語句,然后再返回部分結(jié)果。
有一個(gè)配置屬性可以開啟,避免這種情況---對數(shù)據(jù)源進(jìn)行抽樣。
hive.limit.optimize.enable=true --- 開啟對數(shù)據(jù)源進(jìn)行采樣的功能?
hive.limit.row.max.size --- 設(shè)置最小的采樣容量?
hive.limit.optimize.limit.file --- 設(shè)置最大的采樣樣本數(shù)
缺點(diǎn):有可能部分?jǐn)?shù)據(jù)永遠(yuǎn)不會(huì)被處理到
JOIN優(yōu)化
1)將大表放后頭 Hive假定查詢中最后的一個(gè)表是大表。它會(huì)將其它表緩存起來,然后掃描最后那個(gè)表。因此通常需要將小表放前面,或者標(biāo)記哪張表是大表:/streamtable(table_name)?/
2). 使用相同的連接鍵 當(dāng)對3個(gè)或者更多個(gè)表進(jìn)行join連接時(shí),如果每個(gè)on子句都使用相同的連接鍵的話,那么只會(huì)產(chǎn)生一個(gè)MapReduce job。
3). 盡量盡早地過濾數(shù)據(jù) 減少每個(gè)階段的數(shù)據(jù)量,對于分區(qū)表要加分區(qū),同時(shí)只選擇需要使用到的字段。
4). 盡量原子化操作 盡量避免一個(gè)SQL包含復(fù)雜邏輯,可以使用中間表來完成復(fù)雜的邏輯
本地模式
有時(shí)hive的輸入數(shù)據(jù)量是非常小的。在這種情況下,為查詢出發(fā)執(zhí)行任務(wù)的時(shí)間消耗可能會(huì)比實(shí)際job的執(zhí)行時(shí)間要多的多。對于大多數(shù)這種情況,hive可以通過本地模式在單臺機(jī)器上處理所有的任務(wù)。對于小數(shù)據(jù)集,執(zhí)行時(shí)間會(huì)明顯被縮短
set hive.exec.mode.local.auto=true;
當(dāng)一個(gè)job滿足如下條件才能真正使用本地模式:
1.job的輸入數(shù)據(jù)大小必須小于參數(shù):hive.exec.mode.local.auto.inputbytes.max(默認(rèn)128MB)
2.job的map數(shù)必須小于參數(shù):hive.exec.mode.local.auto.tasks.max(默認(rèn)4)
3.job的reduce數(shù)必須為0或者1
可用參數(shù)hive.mapred.local.mem(默認(rèn)0)控制child jvm使用的最大內(nèi)存數(shù)。
4.并行執(zhí)行
hive會(huì)將一個(gè)查詢轉(zhuǎn)化為一個(gè)或多個(gè)階段,包括:MapReduce階段、抽樣階段、合并階段、limit階段等。默認(rèn)情況下,一次只執(zhí)行一個(gè)階段。不過,如果某些階段不是互相依賴,是可以并行執(zhí)行的。
set hive.exec.parallel=true,可以開啟并發(fā)執(zhí)行。
set hive.exec.parallel.thread.number=16; //同一個(gè)sql允許最大并行度,默認(rèn)為8。
會(huì)比較耗系統(tǒng)資源。
5.strict模式
對分區(qū)表進(jìn)行查詢,在where子句中沒有加分區(qū)過濾的話,將禁止提交任務(wù)(默認(rèn):nonstrict)
set hive.mapred.mode=strict;
注:使用嚴(yán)格模式可以禁止3種類型的查詢:(1)對于分區(qū)表,不加分區(qū)字段過濾條件,不能執(zhí)行 (2)對于order by語句,必須使用limit語句 (3)限制笛卡爾積的查詢(join的時(shí)候不使用on,而使用where的)
6.調(diào)整mapper和reducer個(gè)數(shù)
Map階段優(yōu)化 map執(zhí)行時(shí)間:map任務(wù)啟動(dòng)和初始化的時(shí)間+邏輯處理的時(shí)間。
1.通常情況下,作業(yè)會(huì)通過input的目錄產(chǎn)生一個(gè)或者多個(gè)map任務(wù)。主要的決定因素有:input的文件總個(gè)數(shù),input的文件大小,集群設(shè)置的文件塊大小(目前為128M, 可在hive中通過set dfs.block.size;命令查看到,該參數(shù)不能自定義修改);
2.舉例:
a)假設(shè)input目錄下有1個(gè)文件a,大小為780M,那么hadoop會(huì)將該文件a分隔成7個(gè)塊(6個(gè)128m的塊和1個(gè)12m的塊),從而產(chǎn)生7個(gè)map數(shù) b)假設(shè)input目錄下有3個(gè)文件a,b,c,大小分別為10m,20m,130m,那么hadoop會(huì)分隔成4個(gè)塊(10m,20m,128m,2m),從而產(chǎn)生4個(gè)map數(shù) 即,如果文件大于塊大小(128m),那么會(huì)拆分,如果小于塊大小,則把該文件當(dāng)成一個(gè)塊。
3.是不是map數(shù)越多越好?
答案是否定的。如果一個(gè)任務(wù)有很多小文件(遠(yuǎn)遠(yuǎn)小于塊大小128m),則每個(gè)小文件也會(huì)被當(dāng)做一個(gè)塊,用一個(gè)map任務(wù)來完成,而一個(gè)map任務(wù)啟動(dòng)和初始化的時(shí)間遠(yuǎn)遠(yuǎn)大于邏輯處理的時(shí)間,就會(huì)造成很大的資源浪費(fèi)。而且,同時(shí)可執(zhí)行的map數(shù)是受限的。
4.是不是保證每個(gè)map處理接近128m的文件塊,就高枕無憂了?
答案也是不一定。比如有一個(gè)127m的文件,正常會(huì)用一個(gè)map去完成,但這個(gè)文件只有一個(gè)或者兩個(gè)小字段,卻有幾千萬的記錄,如果map處理的邏輯比較復(fù)雜,用一個(gè)map任務(wù)去做,肯定也比較耗時(shí)。
針對上面的問題3和4,我們需要采取兩種方式來解決:即減少map數(shù)和增加map數(shù);如何合并小文件,減少map數(shù)?
假設(shè)一個(gè)SQL任務(wù):Select count(1) from popt_tbaccountcopy_mes where pt = '2012-07-04' 該任務(wù)的inputdir /group/p_sdo_data/p_sdo_data_etl/pt/popt_tbaccountcopy_mes/pt=2012-07-04 共有194個(gè)文件,其中很多是遠(yuǎn)遠(yuǎn)小于128m的小文件,總大小9G,正常執(zhí)行會(huì)用194個(gè)map任務(wù)。Map總共消耗的計(jì)算資源:SLOTS_MILLIS_MAPS= 623,020 通過以下方法來在map執(zhí)行前合并小文件,減少map數(shù):
set mapred.max.split.size=100000000;set mapred.min.split.size.per.node=100000000;set mapred.min.split.size.per.rack=100000000;?set?hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
再執(zhí)行上面的語句,用了74個(gè)map任務(wù),map消耗的計(jì)算資源:SLOTS_MILLIS_MAPS=333,500 對于這個(gè)簡單SQL任務(wù),執(zhí)行時(shí)間上可能差不多,但節(jié)省了一半的計(jì)算資源。大概解釋一下,100000000表示100M
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;這個(gè)參數(shù)表示執(zhí)行前進(jìn)行小文件合并,前面三個(gè)參數(shù)確定合并文件塊的大小,大于文件塊大小128m的,按照128m來分隔,小于128m,大于100m的,按照100m來分隔,把那些小于100m的(包括小文件和分隔大文件剩下的),進(jìn)行合并,最終生成了74個(gè)塊。
如何適當(dāng)?shù)脑黾觤ap數(shù)?當(dāng)input的文件都很大,任務(wù)邏輯復(fù)雜,map執(zhí)行非常慢的時(shí)候,可以考慮增加Map數(shù), 來使得每個(gè)map處理的數(shù)據(jù)量減少,從而提高任務(wù)的執(zhí)行效率。假設(shè)有這樣一個(gè)任務(wù):
Select data_desc,count(1),count(distinct id),sum(case when …),sum(case when ...),sum(…)from a group by data_desc
如果表a只有一個(gè)文件,大小為120M,但包含幾千萬的記錄,如果用1個(gè)map去完成這個(gè)任務(wù),肯定是比較耗時(shí)的,這種情況下,我們要考慮將這一個(gè)文件合理的拆分成多個(gè),這樣就可以用多個(gè)map任務(wù)去完成。
set mapred.reduce.tasks=10;create table a_1 asselect * from adistribute by rand(123);
這樣會(huì)將a表的記錄,隨機(jī)的分散到包含10個(gè)文件的a_1表中,再用a_1代替上面sql中的a表,則會(huì)用10個(gè)map任務(wù)去完成。每個(gè)map任務(wù)處理大于12M(幾百萬記錄)的數(shù)據(jù),效率肯定會(huì)好很多。
看上去,貌似這兩種有些矛盾,一個(gè)是要合并小文件,一個(gè)是要把大文件拆成小文件,這點(diǎn)正是重點(diǎn)需要關(guān)注的地方,根據(jù)實(shí)際情況,控制map數(shù)量需要遵循兩個(gè)原則:使大數(shù)據(jù)量利用合適的map數(shù);使單個(gè)map任務(wù)處理合適的數(shù)據(jù)量。
控制hive任務(wù)的reduce數(shù):
1.Hive自己如何確定reduce數(shù):
reduce個(gè)數(shù)的設(shè)定極大影響任務(wù)執(zhí)行效率,不指定reduce個(gè)數(shù)的情況下,Hive會(huì)猜測確定一個(gè)reduce個(gè)數(shù),基于以下兩個(gè)設(shè)定:hive.exec.reducers.bytes.per.reducer(每個(gè)reduce任務(wù)處理的數(shù)據(jù)量,默認(rèn)為1000^3=1G) hive.exec.reducers.max(每個(gè)任務(wù)最大的reduce數(shù),默認(rèn)為999)
計(jì)算reducer數(shù)的公式很簡單N=min(參數(shù)2,總輸入數(shù)據(jù)量/參數(shù)1)
即,如果reduce的輸入(map的輸出)總大小不超過1G,那么只會(huì)有一個(gè)reduce任務(wù),如:
select pt,count(1) from popt_tbaccountcopy_mes where pt = '2012-07-04' group by pt;/group/p_sdo_data/p_sdo_data_etl/pt/popt_tbaccountcopy_mes/pt=2012-07-04 總大小為9G多,
因此這句有10個(gè)reduce
2.調(diào)整reduce個(gè)數(shù)方法一:
調(diào)整hive.exec.reducers.bytes.per.reducer參數(shù)的值;set hive.exec.reducers.bytes.per.reducer=500000000; (500M) select pt,count(1) from popt_tbaccountcopy_mes where pt = '2012-07-04' group by pt; 這次有20個(gè)reduce
3.調(diào)整reduce個(gè)數(shù)方法二
set mapred.reduce.tasks = 15; select pt,count(1) from popt_tbaccountcopy_mes where pt = '2012-07-04' group by pt;這次有15個(gè)reduce
4.reduce個(gè)數(shù)并不是越多越好;
同map一樣,啟動(dòng)和初始化reduce也會(huì)消耗時(shí)間和資源;另外,有多少個(gè)reduce,就會(huì)有多少個(gè)輸出文件,如果生成了很多個(gè)小文件, 那么如果這些小文件作為下一個(gè)任務(wù)的輸入,則也會(huì)出現(xiàn)小文件過多的問題;
5.什么情況下只有一個(gè)reduce;
很多時(shí)候你會(huì)發(fā)現(xiàn)任務(wù)中不管數(shù)據(jù)量多大,不管你有沒有設(shè)置調(diào)整reduce個(gè)數(shù)的參數(shù),任務(wù)中一直都只有一個(gè)reduce任務(wù);其實(shí)只有一個(gè)reduce任務(wù)的情況,除了數(shù)據(jù)量小于hive.exec.reducers.bytes.per.reducer參數(shù)值的情況外,還有以下原因:
a)沒有g(shù)roup by的匯總,比如把select pt,count(1) from popt_tbaccountcopy_mes where pt = '2012-07-04' group by pt; 寫成 select count(1) from popt_tbaccountcopy_mes where pt = '2012-07-04'; 這點(diǎn)非常常見,希望大家盡量改寫。
b)用了Order by
c)有笛卡爾積
通常這些情況下,除了找辦法來變通和避免,我們暫時(shí)沒有什么好的辦法,因?yàn)檫@些操作都是全局的,所以hadoop不得不用一個(gè)reduce去完成。同樣的,在設(shè)置reduce個(gè)數(shù)的時(shí)候也需要考慮這兩個(gè)原則:
使大數(shù)據(jù)量利用合適的reduce數(shù)
使單個(gè)reduce任務(wù)處理合適的數(shù)據(jù)量
Reduce階段優(yōu)化 調(diào)整方式:
set mapred.reduce.tasks=?
set hive.exec.reducers.bytes.per.reducer = ?
一般根據(jù)輸入文件的總大小,用它的estimation函數(shù)來自動(dòng)計(jì)算reduce的個(gè)數(shù):reduce個(gè)數(shù) = InputFileSize / bytes per reducer
7.JVM重用
用于避免小文件的場景或者task特別多的場景,這類場景大多數(shù)執(zhí)行時(shí)間都很短,因?yàn)閔ive調(diào)起mapreduce任務(wù),JVM的啟動(dòng)過程會(huì)造成很大的開銷,尤其是job有成千上萬個(gè)task任務(wù)時(shí),JVM重用可以使得JVM實(shí)例在同一個(gè)job中重新使用N次
set mapred.job.reuse.jvm.num.tasks=10; --10為重用個(gè)數(shù)
8.動(dòng)態(tài)分區(qū)調(diào)整
動(dòng)態(tài)分區(qū)屬性:設(shè)置為true表示開啟動(dòng)態(tài)分區(qū)功能(默認(rèn)為false)
hive.exec.dynamic.partition=true;
動(dòng)態(tài)分區(qū)屬性:設(shè)置為nonstrict,表示允許所有分區(qū)都是動(dòng)態(tài)的(默認(rèn)為strict) 設(shè)置為strict,表示必須保證至少有一個(gè)分區(qū)是靜態(tài)的
hive.exec.dynamic.partition.mode=strict;
動(dòng)態(tài)分區(qū)屬性:每個(gè)mapper或reducer可以創(chuàng)建的最大動(dòng)態(tài)分區(qū)個(gè)數(shù)
hive.exec.max.dynamic.partitions.pernode=100;
動(dòng)態(tài)分區(qū)屬性:一個(gè)動(dòng)態(tài)分區(qū)創(chuàng)建語句可以創(chuàng)建的最大動(dòng)態(tài)分區(qū)個(gè)數(shù)
hive.exec.max.dynamic.partitions=1000;
動(dòng)態(tài)分區(qū)屬性:全局可以創(chuàng)建的最大文件個(gè)數(shù)
hive.exec.max.created.files=100000;
控制DataNode一次可以打開的文件個(gè)數(shù) 這個(gè)參數(shù)必須設(shè)置在DataNode的$HADOOP_HOME/conf/hdfs-site.xml文件中
<property><name>dfs.datanode.max.xcieversname><value>8192value>property>
9.推測執(zhí)行
目的:是通過加快獲取單個(gè)task的結(jié)果以及進(jìn)行偵測將執(zhí)行慢的TaskTracker加入到黑名單的方式來提高整體的任務(wù)執(zhí)行效率
(1)修改 $HADOOP_HOME/conf/mapred-site.xml文件
<property><name>mapred.map.tasks.speculative.execution name><value>truevalue>property><property><name>mapred.reduce.tasks.speculative.execution name><value>truevalue>property>
(2)修改hive配置
set?hive.mapred.reduce.tasks.speculative.execution=true;10.數(shù)據(jù)傾斜
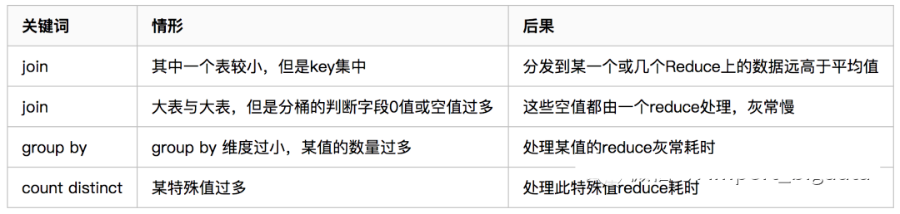
表現(xiàn):任務(wù)進(jìn)度長時(shí)間維持在99%(或100%),查看任務(wù)監(jiān)控頁面,發(fā)現(xiàn)只有少量(1個(gè)或幾個(gè))reduce子任務(wù)未完成。因?yàn)槠涮幚淼臄?shù)據(jù)量和其他reduce差異過大。單一reduce的記錄數(shù)與平均記錄數(shù)差異過大,通常可能達(dá)到3倍甚至更多。最長時(shí)長遠(yuǎn)大于平均時(shí)長。
原因
1)、key分布不均勻
2)、業(yè)務(wù)數(shù)據(jù)本身的特性
3)、建表時(shí)考慮不周
4)、某些SQL語句本身就有數(shù)據(jù)傾斜
解決方案:參數(shù)調(diào)節(jié)
hive.map.aggr=true
其他參數(shù)調(diào)優(yōu)
開啟CLI提示符前打印出當(dāng)前所在的數(shù)據(jù)庫名
set hive.cli.print.current.db=true;
讓CLI打印出字段名稱
hive.cli.print.header=true;
設(shè)置任務(wù)名稱,方便查找監(jiān)控
SET mapred.job.name=P_DWA_D_IA_S_USER_PROD;
決定是否可以在 Map 端進(jìn)行聚合操作
set hive.map.aggr=true;
有數(shù)據(jù)傾斜的時(shí)候進(jìn)行負(fù)載均衡
set hive.groupby.skewindata=true;
對于簡單的不需要聚合的類似SELECT col from table LIMIT n語句,不需要起MapReduce job,直接通過Fetch task獲取數(shù)據(jù)
set hive.fetch.task.conversion=more;
12、小文件問題
小文件是如何產(chǎn)生的 1.動(dòng)態(tài)分區(qū)插入數(shù)據(jù),產(chǎn)生大量的小文件,從而導(dǎo)致map數(shù)量劇增。
2.reduce數(shù)量越多,小文件也越多(reduce的個(gè)數(shù)和輸出文件是對應(yīng)的)。
3.數(shù)據(jù)源本身就包含大量的小文件。
小文件問題的影響 1.從Hive的角度看,小文件會(huì)開很多map,一個(gè)map開一個(gè)JVM去執(zhí)行,所以這些任務(wù)的初始化,啟動(dòng),執(zhí)行會(huì)浪費(fèi)大量的資源,嚴(yán)重影響性能。
2.在HDFS中,每個(gè)小文件對象約占150byte,如果小文件過多會(huì)占用大量內(nèi)存。這樣NameNode內(nèi)存容量嚴(yán)重制約了集群的擴(kuò)展。
小文件問題的解決方案 從小文件產(chǎn)生的途經(jīng)就可以從源頭上控制小文件數(shù)量,方法如下:
1.使用Sequencefile作為表存儲格式,不要用textfile,在一定程度上可以減少小文件
2.減少reduce的數(shù)量(可以使用參數(shù)進(jìn)行控制)
3.少用動(dòng)態(tài)分區(qū),用時(shí)記得按distribute by分區(qū)
對于已有的小文件,我們可以通過以下幾種方案解決:
1.使用hadoop archive命令把小文件進(jìn)行歸檔
2.重建表,建表時(shí)減少reduce數(shù)量
3.通過參數(shù)進(jìn)行調(diào)節(jié),設(shè)置map/reduce端的相關(guān)參數(shù),如下:
設(shè)置map輸入合并小文件的相關(guān)參數(shù):
//每個(gè)Map最大輸入大小(這個(gè)值決定了合并后文件的數(shù)量)set mapred.max.split.size=256000000;//一個(gè)節(jié)點(diǎn)上split的至少的大小(這個(gè)值決定了多個(gè)DataNode上的文件是否需要合并)set mapred.min.split.size.per.node=100000000;//一個(gè)交換機(jī)下split的至少的大小(這個(gè)值決定了多個(gè)交換機(jī)上的文件是否需要合并)set mapred.min.split.size.per.rack=100000000;//執(zhí)行Map前進(jìn)行小文件合并set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
設(shè)置map輸出和reduce輸出進(jìn)行合并的相關(guān)參數(shù):
//設(shè)置map端輸出進(jìn)行合并,默認(rèn)為trueset hive.merge.mapfiles = true//設(shè)置reduce端輸出進(jìn)行合并,默認(rèn)為falseset hive.merge.mapredfiles = true//設(shè)置合并文件的大小set hive.merge.size.per.task = 256*1000*1000//當(dāng)輸出文件的平均大小小于該值時(shí),啟動(dòng)一個(gè)獨(dú)立的MapReduce任務(wù)進(jìn)行文件merge。set hive.merge.smallfiles.avgsize=16000000
設(shè)置如下參數(shù)取消一些限制(HIVE 0.7后沒有此限制):
hive.merge.mapfiles=false
默認(rèn)值:true 描述:是否合并Map的輸出文件,也就是把小文件合并成一個(gè)map
hive.merge.mapredfiles=false
默認(rèn)值:false 描述:是否合并Reduce的輸出文件,也就是在Map輸出階段做一次reduce操作,再輸出.
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
這個(gè)參數(shù)表示執(zhí)行前進(jìn)行小文件合并,
前面三個(gè)參數(shù)確定合并文件塊的大小,大于文件塊大小128m的,按照128m來分隔,小于128m,大于100m的,按照100m來分隔,把那些小于100m的(包括小文件和分隔大文件剩下的),進(jìn)行合并,最終生成了74個(gè)塊。
Hive面試題(一)
1、hive內(nèi)部表和外部表的區(qū)別
未被external修飾的是內(nèi)部表,被external修飾的為外部表。
區(qū)別:
內(nèi)部表數(shù)據(jù)由Hive自身管理,外部表數(shù)據(jù)由HDFS管理;
內(nèi)部表數(shù)據(jù)存儲的位置是hive.metastore.warehouse.dir(默認(rèn):/user/hive/warehouse), 外部表數(shù)據(jù)的存儲位置由自己制定(如果沒有LOCATION,Hive將在HDFS上 的/user/hive/warehouse文件夾下以外部表的表名創(chuàng)建一個(gè)文件夾,并將屬于這個(gè)表的數(shù)據(jù)存 放在這里);
刪除內(nèi)部表會(huì)直接刪除元數(shù)據(jù)(metadata)及存儲數(shù)據(jù);刪除外部表僅僅會(huì)刪除元數(shù)據(jù),HDFS上的文件并不會(huì)被刪除。
2、Hive有索引嗎
Hive支持索引(3.0版本之前),但是Hive的索引與關(guān)系型數(shù)據(jù)庫中的索引并不相同。并且 Hive索引提供的功能很有限,效率也并不高,因此Hive索引很少使用。
索引適用的場景:
適用于不更新的靜態(tài)字段。以免總是重建索引數(shù)據(jù)。每次建立、更新數(shù)據(jù)后,都要重建索 引以構(gòu)建索引表。
3、運(yùn)維如何對hive進(jìn)行調(diào)度
將hive的sql定義在腳本當(dāng)中;
使用azkaban或者oozie進(jìn)行任務(wù)的調(diào)度;
監(jiān)控任務(wù)調(diào)度頁面。
4、ORC、Parquet等列式存儲的優(yōu)點(diǎn)
- ORC:ORC文件是自描述的,它的元數(shù)據(jù)使用Protocol Buffers序列化,文件中的數(shù)據(jù)盡可能的壓縮以降低存儲空間的消耗;以二進(jìn)制方式存儲,不可以直接讀取;自解析,包含許多元數(shù)據(jù),這些元數(shù)據(jù)都是同構(gòu)ProtoBuffer進(jìn)行序列化的;會(huì)盡可能合并多個(gè)離散的區(qū)間盡可能的減少I/O次數(shù);在新版本的ORC中也加入了對Bloom Filter的支持,它可以進(jìn)一 步提升謂詞下推的效率,在Hive 1.2.0版本以后也加入了對此的支 持。
- Parquet:Parquet支持嵌套的數(shù)據(jù)模型,類似于Protocol Buffers,每一個(gè)數(shù)據(jù)模型的schema包含多個(gè)字段,每一個(gè)字段有三個(gè)屬性:重復(fù)次數(shù)、數(shù)據(jù)類型和字段名;Parquet中沒有Map、Array這樣的復(fù)雜數(shù)據(jù)結(jié)構(gòu),但是可以通過repeated和group組合來實(shí)現(xiàn);通過Striping/Assembly算法,parquet可以使用較少的存儲空間表示復(fù)雜的嵌套格式,并且通常Repetition level和Definition level都是較小的整數(shù)值,可以通過RLE算法對其進(jìn)行壓縮,進(jìn)一步降低存儲空間;Parquet文件以二進(jìn)制方式存儲,不可以直接讀取和修改,Parquet文件是自解析的,文件中包括該文件的數(shù)據(jù)和元數(shù)據(jù)。
5、數(shù)據(jù)建模用的哪些模型
星型模型
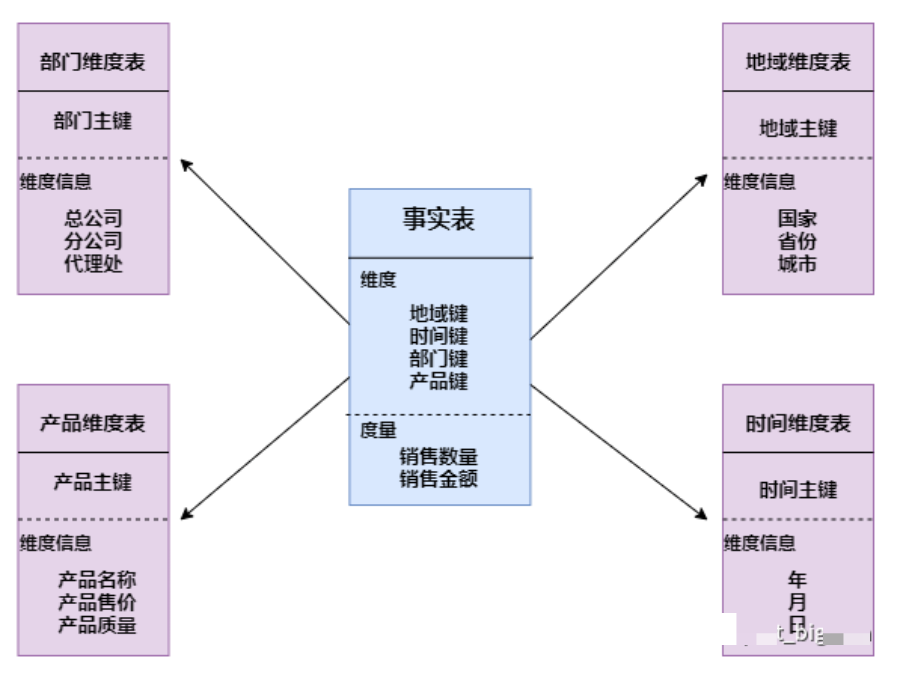
星形模式(Star Schema)是最常用的維度建模方式。星型模式是以事實(shí)表為中心,所有的維度表直接連接在事實(shí)表上,像星星一樣。星形模式的維度建模由一個(gè)事實(shí)表和一組維表成,且具有以下特點(diǎn):
a. 維表只和事實(shí)表關(guān)聯(lián),維表之間沒有關(guān)聯(lián);
b. 每個(gè)維表主鍵為單列,且該主鍵放置在事實(shí)表中,作為兩邊連接的外鍵;
c. 以事實(shí)表為核心,維表圍繞核心呈星形分布。
雪花模型
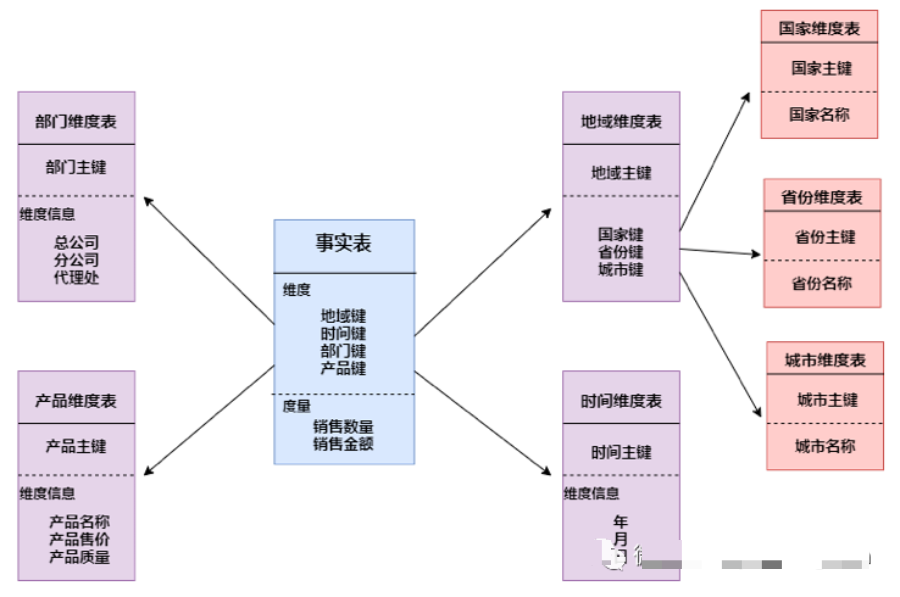
雪花模式(Snowflake Schema)是對星形模式的擴(kuò)展。雪花模式的維度表可以擁有其他維度表的,雖然這種模型相比星型更規(guī)范一些,但是由于這種模型不太容易理解,維護(hù)成本比較高,而且性能方面需要關(guān)聯(lián)多層維表,性能比星型模型要低。
星座模型
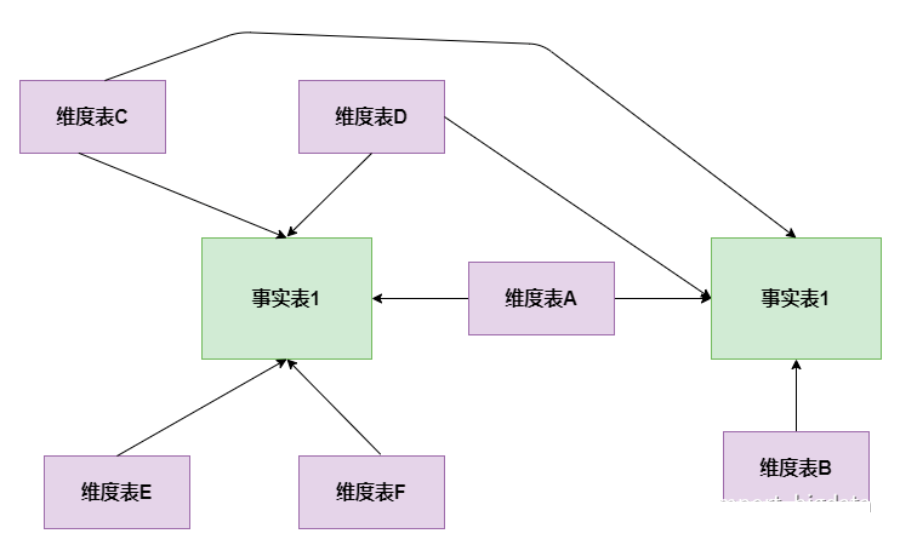
星座模式是星型模式延伸而來,星型模式是基于一張事實(shí)表的,而星座模式是基于多張事實(shí)表的,而且共享維度信息。前面介紹的兩種維度建模方法都是多維表對應(yīng)單事實(shí)表,但在很多時(shí)候維度空間內(nèi)的事實(shí)表不止一個(gè),而一個(gè)維表也可能被多個(gè)事實(shí)表用到。在業(yè)務(wù)發(fā)展后期,絕大部分維度建模都采用的是星座模式。
6、為什么要對數(shù)據(jù)倉庫分層
用空間換時(shí)間,通過大量的預(yù)處理來提升應(yīng)用系統(tǒng)的用戶體驗(yàn)(效率),因此數(shù)據(jù)倉庫會(huì) 存在大量冗余的數(shù)據(jù)。如果不分層的話,如果源業(yè)務(wù)系統(tǒng)的業(yè)務(wù)規(guī)則發(fā)生變化將會(huì)影響整個(gè)數(shù)據(jù)清洗過程,工作量巨大。
通過數(shù)據(jù)分層管理可以簡化數(shù)據(jù)清洗的過程,因?yàn)榘言瓉硪徊降墓ぷ鞣值搅硕鄠€(gè)步驟去完成,相當(dāng)于把一個(gè)復(fù)雜的工作拆成了多個(gè)簡單的工作,把一個(gè)大的黑盒變成了一個(gè)白盒,每一層的處理邏輯都相對簡單和容易理解,這樣我們比較容易保證每一個(gè)步驟的正確性,當(dāng)數(shù)據(jù)發(fā)生錯(cuò)誤的時(shí)候,往往我們只需要局部調(diào)整某個(gè)步驟即可。
7、使用過Hive解析JSON串嗎
Hive處理json數(shù)據(jù)總體來說有兩個(gè)方向的路走:
a.將json以字符串的方式整個(gè)入Hive表,然后通過使用UDF函數(shù)解析已經(jīng)導(dǎo)入到hive中的數(shù)據(jù),比如使用LATERAL VIEW json_tuple的方法,獲取所需要的列名。
b.在導(dǎo)入之前將json拆成各個(gè)字段,導(dǎo)入Hive表的數(shù)據(jù)是已經(jīng)解析過的。這將需要使用第三方的 SerDe。
8、sort by 和 order by 的區(qū)別
order by 會(huì)對輸入做全局排序,因此只有一個(gè)reducer(多個(gè)reducer無法保證全局有序)只有一個(gè)reducer,會(huì)導(dǎo)致當(dāng)輸入規(guī)模較大時(shí),需要較長的計(jì)算時(shí)間。
sort by不是全局排序,其在數(shù)據(jù)進(jìn)入reducer前完成排序. 因此,如果用sort by進(jìn)行排序,并且設(shè)置mapred.reduce.tasks>1, 則sort by只保證每個(gè)reducer的輸出有序,不保證全局有序。
9、數(shù)據(jù)傾斜怎么解決
空值引發(fā)的數(shù)據(jù)傾斜
解決方案:
第一種:可以直接不讓null值參與join操作,即不讓null值有shuffle階段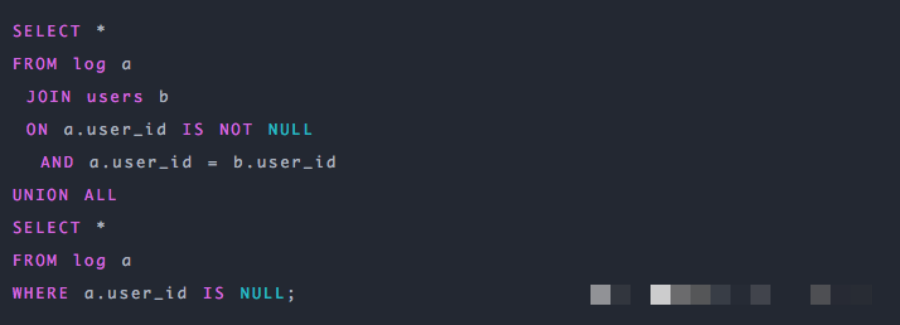
第二種:因?yàn)閚ull值參與shuffle時(shí)的hash結(jié)果是一樣的,那么我們可以給null值隨機(jī)賦值,這樣它們的hash結(jié)果就不一樣,就會(huì)進(jìn)到不同的reduce中: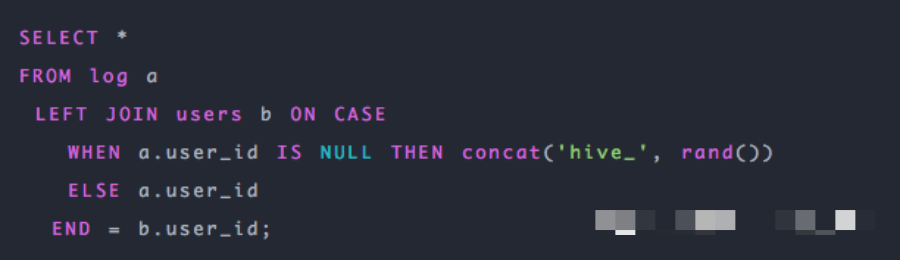
不同數(shù)據(jù)類型引發(fā)的數(shù)據(jù)傾斜
解決方案:
如果key字段既有string類型也有int類型,默認(rèn)的hash就都會(huì)按int類型來分配,那我們直接把int類型都轉(zhuǎn)為string就好了,這樣key字段都為string,hash時(shí)就按照string類型分配了:
不可拆分大文件引發(fā)的數(shù)據(jù)傾斜
解決方案:
這種數(shù)據(jù)傾斜問題沒有什么好的解決方案,只能將使用GZIP壓縮等不支持文件分割的文件轉(zhuǎn)為bzip和zip等支持文件分割的壓縮方式。
所以,我們在對文件進(jìn)行壓縮時(shí),為避免因不可拆分大文件而引發(fā)數(shù)據(jù)讀取的傾斜,在數(shù)據(jù)壓縮的時(shí)候可以采用bzip2和Zip等支持文件分割
的壓縮算法。
數(shù)據(jù)膨脹引發(fā)的數(shù)據(jù)傾斜
解決方案:
在Hive中可以通過參數(shù)hive.new.job.grouping.set.cardinality配置的方式自動(dòng)控制作業(yè)的拆解,該參數(shù)默認(rèn)值是30。表示針對grouping sets/rollups/cubes這類多維聚合的操作,如果最后拆解的鍵組合大于該值,會(huì)啟用新的任務(wù)去處理大于該值之外的組合。如果在處理數(shù)據(jù)時(shí),某個(gè)分組聚合的列有較大的傾斜,可以適當(dāng)調(diào)小該值。表連接時(shí)引發(fā)的數(shù)據(jù)傾斜
解決方案:
通常做法是將傾斜的數(shù)據(jù)存到分布式緩存中,分發(fā)到各個(gè)Map任務(wù)所在節(jié)點(diǎn)。在Map階段完成join操作,即MapJoin,這避免了 Shuffle,從而避免了數(shù)據(jù)傾斜。確實(shí)無法減少數(shù)據(jù)量引發(fā)的數(shù)據(jù)傾斜
解決方案:
這類問題最直接的方式就是調(diào)整reduce所執(zhí)行的內(nèi)存大小。
調(diào)整reduce的內(nèi)存大小使用mapreduce.reduce.memory.mb這個(gè)配置。
10、Hive 小文件過多怎么解決
使用 hive 自帶的 concatenate 命令,自動(dòng)合并小文件
調(diào)整參數(shù)減少M(fèi)ap數(shù)量
減少Reduce的數(shù)量
使用hadoop的archive將小文件歸檔
11、Hive優(yōu)化有哪些
數(shù)據(jù)存儲及壓縮
通過調(diào)參優(yōu)化
有效地減小數(shù)據(jù)集將大表拆分成子表;結(jié)合使用外部表和分區(qū)表
SQL優(yōu)化
Hive/Hadoop高頻面試點(diǎn)集合
1、Hive的兩張表關(guān)聯(lián),使用MapReduce怎么實(shí)現(xiàn)?
如果其中有一張表為小表,直接使用map端join的方式(map端加載小表)進(jìn)行聚合。
如果兩張都是大表,那么采用聯(lián)合key,聯(lián)合key的第一個(gè)組成部分是join on中的公共字段,第二部分是一個(gè)flag,0代表表A,1代表表B,由此讓Reduce區(qū)分客戶信息和訂單信息;在Mapper中同時(shí)處理兩張表的信息,將join on公共字段相同的數(shù)據(jù)劃分到同一個(gè)分區(qū)中,進(jìn)而傳遞到一個(gè)Reduce中,然后在Reduce中實(shí)現(xiàn)聚合。
2、請談一下Hive的特點(diǎn),Hive和RDBMS有什么異同?
hive是基于Hadoop的一個(gè)數(shù)據(jù)倉庫工具,可以將結(jié)構(gòu)化的數(shù)據(jù)文件映射為一張數(shù)據(jù)庫表,并提供完整的sql查詢功能,可以將sql語句轉(zhuǎn)換為MapReduce任務(wù)進(jìn)行運(yùn)行。其優(yōu)點(diǎn)是學(xué)習(xí)成本低,可以通過類SQL語句快速實(shí)現(xiàn)簡單的MapReduce統(tǒng)計(jì),不必開發(fā)專門的MapReduce應(yīng)用,十分適合數(shù)據(jù)倉庫的統(tǒng)計(jì)分析,但是Hive不支持實(shí)時(shí)查詢。
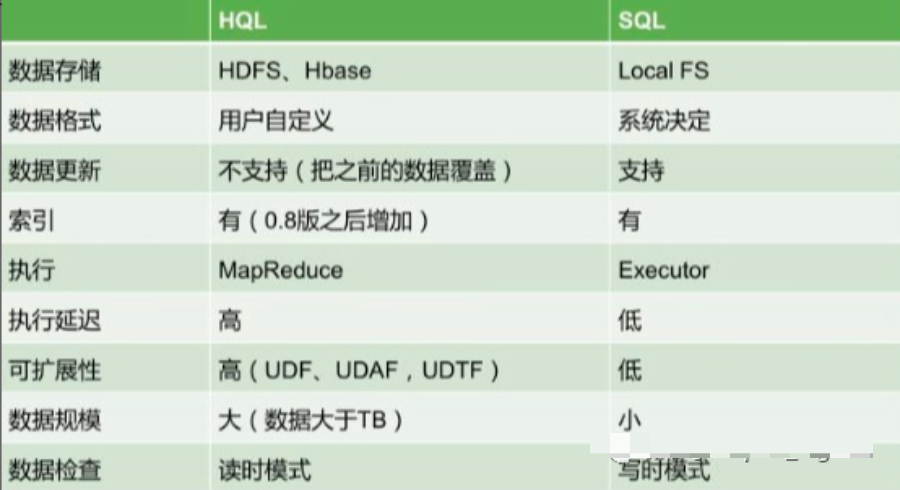
Hive與關(guān)系型數(shù)據(jù)庫的區(qū)別:
3、請說明hive中 Sort By,Order By,Cluster By,Distrbute By各代表什么意思?
Order by:會(huì)對輸入做全局排序,因此只有一個(gè)reducer(多個(gè)reducer無法保證全局有序)。只有一個(gè)reducer,會(huì)導(dǎo)致當(dāng)輸入規(guī)模較大時(shí),需要較長的計(jì)算時(shí)間。
Sort by:不是全局排序,其在數(shù)據(jù)進(jìn)入reducer前完成排序。1
Distribute by:按照指定的字段對數(shù)據(jù)進(jìn)行劃分輸出到不同的reduce中。
Cluster by:除了具有 distribute by 的功能外還兼具 sort by 的功能。
4、寫出Hive中split、coalesce及collect_list函數(shù)的用法(可舉例)?
split將字符串轉(zhuǎn)化為數(shù)組,即:split('a,b,c,d' , ',') ==> ["a","b","c","d"]。
coalesce(T v1, T v2, …) 返回參數(shù)中的第一個(gè)非空值;如果所有值都為 NULL,那么返回NULL。
collect_list列出該字段所有的值,不去重 => select collect_list(id) from table。
5、 Hive有哪些方式保存元數(shù)據(jù),各有哪些特點(diǎn)?
Hive支持三種不同的元存儲服務(wù)器,分別為:內(nèi)嵌式元存儲服務(wù)器、本地元存儲服務(wù)器、遠(yuǎn)程元存儲服務(wù)器,每種存儲方式使用不同的配置參數(shù)。
內(nèi)嵌式元存儲主要用于單元測試,在該模式下每次只有一個(gè)進(jìn)程可以連接到元存儲,Derby是內(nèi)嵌式元存儲的默認(rèn)數(shù)據(jù)庫。
在本地模式下,每個(gè)Hive客戶端都會(huì)打開到數(shù)據(jù)存儲的連接并在該連接上請求SQL查詢。
在遠(yuǎn)程模式下,所有的Hive客戶端都將打開一個(gè)到元數(shù)據(jù)服務(wù)器的連接,該服務(wù)器依次查詢元數(shù)據(jù),元數(shù)據(jù)服務(wù)器和客戶端之間使用Thrift協(xié)議通信。
6、Hive內(nèi)部表和外部表的區(qū)別?
創(chuàng)建表時(shí):創(chuàng)建內(nèi)部表時(shí),會(huì)將數(shù)據(jù)移動(dòng)到數(shù)據(jù)倉庫指向的路徑;若創(chuàng)建外部表,僅記錄數(shù)據(jù)所在的路徑,不對數(shù)據(jù)的位置做任何改變。
刪除表時(shí):在刪除表的時(shí)候,內(nèi)部表的元數(shù)據(jù)和數(shù)據(jù)會(huì)被一起刪除, 而外部表只刪除元數(shù)據(jù),不刪除數(shù)據(jù)。這樣外部表相對來說更加安全些,數(shù)據(jù)組織也更加靈活,方便共享源數(shù)據(jù)。
7、Hive的函數(shù):UDF、UDAF、UDTF的區(qū)別?
UDF:單行進(jìn)入,單行輸出
UDAF:多行進(jìn)入,單行輸出
UDTF:單行輸入,多行輸出
8、所有的Hive任務(wù)都會(huì)有MapReduce的執(zhí)行嗎?
不是,從Hive0.10.0版本開始,對于簡單的不需要聚合的類似SELECT from
LIMIT n語句,不需要起MapReduce job,直接通過Fetch task獲取數(shù)據(jù)。
9、說說對Hive桶表的理解?
桶表是對數(shù)據(jù)某個(gè)字段進(jìn)行哈希取值,然后放到不同文件中存儲。
數(shù)據(jù)加載到桶表時(shí),會(huì)對字段取hash值,然后與桶的數(shù)量取模。把數(shù)據(jù)放到對應(yīng)的文件中。物理上,每個(gè)桶就是表(或分區(qū))目錄里的一個(gè)文件,一個(gè)作業(yè)產(chǎn)生的桶(輸出文件)和reduce任務(wù)個(gè)數(shù)相同。
桶表專門用于抽樣查詢,是很專業(yè)性的,不是日常用來存儲數(shù)據(jù)的表,需要抽樣查詢時(shí),才創(chuàng)建和使用桶表。
10、Hive底層與數(shù)據(jù)庫交互原理?
Hive 的查詢功能是由 HDFS 和 MapReduce結(jié)合起來實(shí)現(xiàn)的,對于大規(guī)模數(shù)據(jù)查詢還是不建議在 hive 中,因?yàn)檫^大數(shù)據(jù)量會(huì)造成查詢十分緩慢。Hive 與 MySQL的關(guān)系:只是借用 MySQL來存儲 hive 中的表的元數(shù)據(jù)信息,稱為 metastore(元數(shù)據(jù)信息)。
11、Hive本地模式
大多數(shù)的Hadoop Job是需要Hadoop提供的完整的可擴(kuò)展性來處理大數(shù)據(jù)集的。不過,有時(shí)Hive的輸入數(shù)據(jù)量是非常小的。在這種情況下,為查詢觸發(fā)執(zhí)行任務(wù)時(shí)消耗可能會(huì)比實(shí)際job的執(zhí)行時(shí)間要多的多。對于大多數(shù)這種情況,Hive可以通過本地模式在單臺機(jī)器上處理所有的任務(wù)。對于小數(shù)據(jù)集,執(zhí)行時(shí)間可以明顯被縮短。
用戶可以通過設(shè)置hive.exec.mode.local.auto的值為true,來讓Hive在適當(dāng)?shù)臅r(shí)候自動(dòng)啟動(dòng)這個(gè)優(yōu)化。
12、Hive 中的壓縮格式TextFile、SequenceFile、RCfile 、ORCfile各有什么區(qū)別?
1、TextFile
默認(rèn)格式,存儲方式為行存儲,數(shù)據(jù)不做壓縮,磁盤開銷大,數(shù)據(jù)解析開銷大。可結(jié)合Gzip、Bzip2使用(系統(tǒng)自動(dòng)檢查,執(zhí)行查詢時(shí)自動(dòng)解壓),但使用這種方式,壓縮后的文件不支持split,Hive不會(huì)對數(shù)據(jù)進(jìn)行切分,從而無法對數(shù)據(jù)進(jìn)行并行操作。并且在反序列化過程中,必須逐個(gè)字符判斷是不是分隔符和行結(jié)束符,因此反序列化開銷會(huì)比SequenceFile高幾十倍。
2、SequenceFile
SequenceFile是Hadoop API提供的一種二進(jìn)制文件支持,存儲方式為行存儲,其具有使用方便、可分割、可壓縮的特點(diǎn)。
SequenceFile支持三種壓縮選擇:NONE,RECORD,BLOCK。Record壓縮率低,一般建議使用BLOCK壓縮。
優(yōu)勢是文件和hadoop api中的MapFile是相互兼容的
3、RCFile
存儲方式:數(shù)據(jù)按行分塊,每塊按列存儲。結(jié)合了行存儲和列存儲的優(yōu)點(diǎn):
首先,RCFile 保證同一行的數(shù)據(jù)位于同一節(jié)點(diǎn),因此元組重構(gòu)的開銷很低;
其次,像列存儲一樣,RCFile 能夠利用列維度的數(shù)據(jù)壓縮,并且能跳過不必要的列讀取;
4、ORCFile
存儲方式:數(shù)據(jù)按行分塊 每塊按照列存儲。
壓縮快、快速列存取。
效率比rcfile高,是rcfile的改良版本。
小結(jié):
相比TEXTFILE和SEQUENCEFILE,RCFILE由于列式存儲方式,數(shù)據(jù)加載時(shí)性能消耗較大,但是具有較好的壓縮比和查詢響應(yīng)。
數(shù)據(jù)倉庫的特點(diǎn)是一次寫入、多次讀取,因此,整體來看,RCFILE相比其余兩種格式具有較明顯的優(yōu)勢。
13、Hive表關(guān)聯(lián)查詢,如何解決數(shù)據(jù)傾斜的問題?
1)傾斜原因:map輸出數(shù)據(jù)按key Hash的分配到reduce中,由于key分布不均勻、業(yè)務(wù)數(shù)據(jù)本身的特、建表時(shí)考慮不周、等原因造成的reduce 上的數(shù)據(jù)量差異過大。(1)key分布不均勻; (2)業(yè)務(wù)數(shù)據(jù)本身的特性; (3)建表時(shí)考慮不周; (4)某些SQL語句本身就有數(shù)據(jù)傾斜;
如何避免:對于key為空產(chǎn)生的數(shù)據(jù)傾斜,可以對其賦予一個(gè)隨機(jī)值。
2)解決方案
(1)參數(shù)調(diào)節(jié):? ? hive.map.aggr = true ? ? hive.groupby.skewindata=true
有數(shù)據(jù)傾斜的時(shí)候進(jìn)行負(fù)載均衡,當(dāng)選項(xiàng)設(shè)定位true,生成的查詢計(jì)劃會(huì)有兩個(gè)MR Job。第一個(gè)MR Job中,Map的輸出結(jié)果集合會(huì)隨機(jī)分布到Reduce中,每個(gè)Reduce做部分聚合操作,并輸出結(jié)果,這樣處理的結(jié)果是相同的Group By Key有可能被分發(fā)到不同的Reduce中,從而達(dá)到負(fù)載均衡的目的;第二個(gè)MR Job再根據(jù)預(yù)處理的數(shù)據(jù)結(jié)果按照Group By Key 分布到 Reduce 中(這個(gè)過程可以保證相同的 Group By Key 被分布到同一個(gè)Reduce中),最后完成最終的聚合操作。
(2)SQL 語句調(diào)節(jié):
? ① 選用join key分布最均勻的表作為驅(qū)動(dòng)表。做好列裁剪和filter操作,以達(dá)到兩表做join 的時(shí)候,數(shù)據(jù)量相對變小的效果。? ② 大小表Join:? ? 使用map join讓小的維度表(1000 條以下的記錄條數(shù))先進(jìn)內(nèi)存。在map端完成reduce。? ③ 大表Join大表:? ? 把空值的key變成一個(gè)字符串加上隨機(jī)數(shù),把傾斜的數(shù)據(jù)分到不同的reduce上,由于null 值關(guān)聯(lián)不上,處理后并不影響最終結(jié)果。? ④ count distinct大量相同特殊值: ? ? count distinct 時(shí),將值為空的情況單獨(dú)處理,如果是計(jì)算count distinct,可以不用處理,直接過濾,在最后結(jié)果中加1。如果還有其他計(jì)算,需要進(jìn)行g(shù)roup by,可以先將值為空的記錄單獨(dú)處理,再和其他計(jì)算結(jié)果進(jìn)行union。
14、Fetch抓取
Fetch抓取是指,Hive中對某些情況的查詢可以不必使用MapReduce計(jì)算。例如:SELECT * FROM employees;在這種情況下,Hive可以簡單地讀取employee對應(yīng)的存儲目錄下的文件,然后輸出查詢結(jié)果到控制臺。
在hive-default.xml.template文件中hive.fetch.task.conversion默認(rèn)是more,老版本hive默認(rèn)是minimal,該屬性修改為more以后,在全局查找、字段查找、limit查找等都不走mapreduce。
15、小表、大表Join
將key相對分散,并且數(shù)據(jù)量小的表放在join的左邊,這樣可以有效減少內(nèi)存溢出錯(cuò)誤發(fā)生的幾率;再進(jìn)一步,可以使用Group讓小的維度表(1000條以下的記錄條數(shù))先進(jìn)內(nèi)存。在map端完成reduce。
實(shí)際測試發(fā)現(xiàn):新版的hive已經(jīng)對小表JOIN大表和大表JOIN小表進(jìn)行了優(yōu)化。小表放在左邊和右邊已經(jīng)沒有明顯區(qū)別。
16、大表Join大表
1)空KEY過濾 ? 有時(shí)join超時(shí)是因?yàn)槟承﹌ey對應(yīng)的數(shù)據(jù)太多,而相同key對應(yīng)的數(shù)據(jù)都會(huì)發(fā)送到相同的reducer上,從而導(dǎo)致內(nèi)存不夠。此時(shí)我們應(yīng)該仔細(xì)分析這些異常的key,很多情況下,這些key對應(yīng)的數(shù)據(jù)是異常數(shù)據(jù),我們需要在SQL語句中進(jìn)行過濾。例如key對應(yīng)的字段為空。2)空key轉(zhuǎn)換 ? 有時(shí)雖然某個(gè)key為空對應(yīng)的數(shù)據(jù)很多,但是相應(yīng)的數(shù)據(jù)不是異常數(shù)據(jù),必須要包含在join的結(jié)果中,此時(shí)我們可以表a中key為空的字段賦一個(gè)隨機(jī)的值,使得數(shù)據(jù)隨機(jī)均勻地分不到不同的reducer上。
17、Group By
默認(rèn)情況下,Map階段同一Key數(shù)據(jù)分發(fā)給一個(gè)reduce,當(dāng)一個(gè)key數(shù)據(jù)過大時(shí)就傾斜了。
并不是所有的聚合操作都需要在Reduce端完成,很多聚合操作都可以先在Map端進(jìn)行部分聚合,最后在Reduce端得出最終結(jié)果。1)開啟Map端聚合參數(shù)設(shè)置 ? ? (1)是否在Map端進(jìn)行聚合,默認(rèn)為True ? ? ? hive.map.aggr = true ? ? (2)在Map端進(jìn)行聚合操作的條目數(shù)目 ? ? ? hive.groupby.mapaggr.checkinterval = 100000 ? ? (3)有數(shù)據(jù)傾斜的時(shí)候進(jìn)行負(fù)載均衡(默認(rèn)是false) ? ? ? hive.groupby.skewindata = true
當(dāng)選項(xiàng)設(shè)定為 true,生成的查詢計(jì)劃會(huì)有兩個(gè)MR Job。第一個(gè)MR Job中,Map的輸出結(jié)果會(huì)隨機(jī)分布到Reduce中,每個(gè)Reduce做部分聚合操作,并輸出結(jié)果,這樣處理的結(jié)果是相同的Group By Key有可能被分發(fā)到不同的Reduce中,從而達(dá)到負(fù)載均衡的目的;
第二個(gè)MR Job再根據(jù)預(yù)處理的數(shù)據(jù)結(jié)果按照Group By Key分布到Reduce中(這個(gè)過程可以保證相同的Group By Key被分布到同一個(gè)Reduce中),最后完成最終的聚合操作。
18、Count(Distinct) 去重統(tǒng)計(jì)
數(shù)據(jù)量小的時(shí)候無所謂,數(shù)據(jù)量大的情況下,由于COUNT DISTINCT操作需要用一個(gè)Reduce Task來完成,這一個(gè)Reduce需要處理的數(shù)據(jù)量太大,就會(huì)導(dǎo)致整個(gè)Job很難完成,一般COUNT DISTINCT使用先GROUP BY再COUNT的方式替換
盡量避免笛卡爾積,join的時(shí)候不加on條件,或者無效的on條件,Hive只能使用1個(gè)reducer來完成笛卡爾積
20、行列過濾
列處理:在SELECT中,只拿需要的列,如果有,盡量使用分區(qū)過濾,少用SELECT *。
行處理:在分區(qū)剪裁中,當(dāng)使用外關(guān)聯(lián)時(shí),如果將副表的過濾條件寫在Where后面,那么就會(huì)先全表關(guān)聯(lián),之后再過濾。
21、并行執(zhí)行
Hive會(huì)將一個(gè)查詢轉(zhuǎn)化成一個(gè)或者多個(gè)階段。這樣的階段可以是MapReduce階段、抽樣階段、合并階段、limit階段。或者Hive執(zhí)行過程中可能需要的其他階段。默認(rèn)情況下,Hive一次只會(huì)執(zhí)行一個(gè)階段。不過,某個(gè)特定的job可能包含眾多的階段,而這些階段可能并非完全互相依賴的,也就是說有些階段是可以并行執(zhí)行的,這樣可能使得整個(gè)job的執(zhí)行時(shí)間縮短。不過,如果有更多的階段可以并行執(zhí)行,那么job可能就越快完成。
通過設(shè)置參數(shù)hive.exec.parallel值為true,就可以開啟并發(fā)執(zhí)行。不過,在共享集群中,需要注意下,如果job中并行階段增多,那么集群利用率就會(huì)增加。
推薦閱讀:
世界的真實(shí)格局分析,地球人類社會(huì)底層運(yùn)行原理
不是你需要中臺,而是一名合格的架構(gòu)師(附各大廠中臺建設(shè)PPT)
企業(yè)IT技術(shù)架構(gòu)規(guī)劃方案
論數(shù)字化轉(zhuǎn)型——轉(zhuǎn)什么,如何轉(zhuǎn)?
企業(yè)10大管理流程圖,數(shù)字化轉(zhuǎn)型從業(yè)者必備!
【中臺實(shí)踐】華為大數(shù)據(jù)中臺架構(gòu)分享.pdf
華為如何實(shí)施數(shù)字化轉(zhuǎn)型(附PPT)