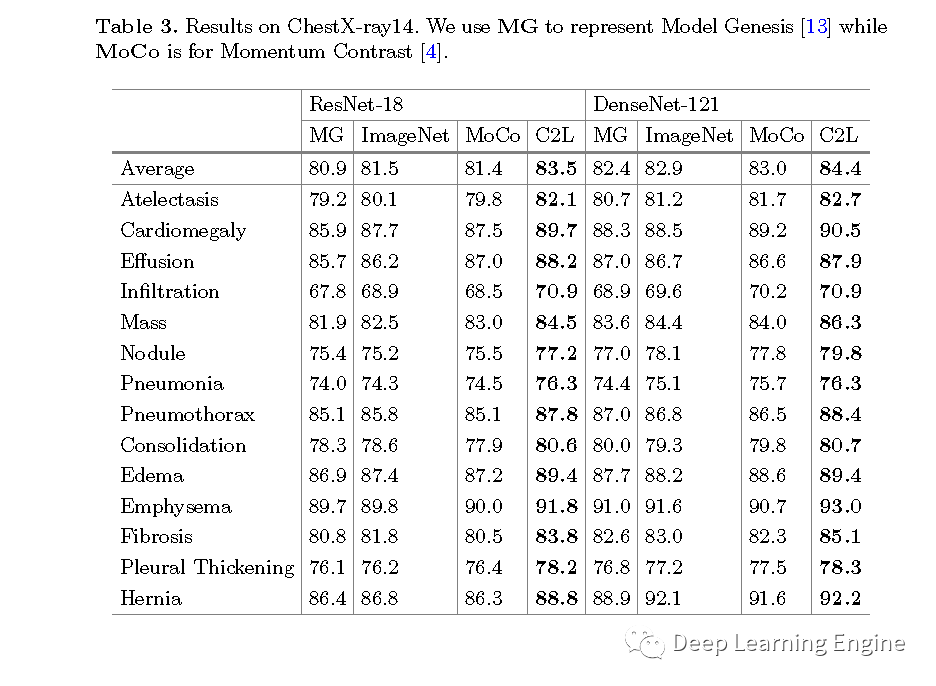
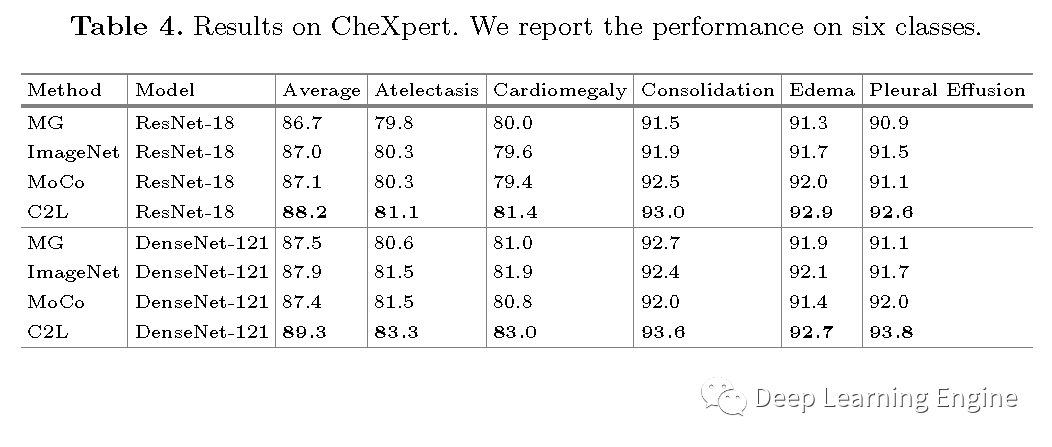
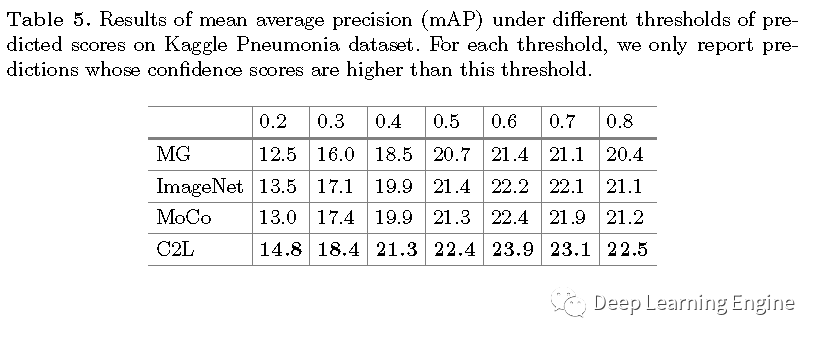
本期分享一篇MICCAI2020的一篇關(guān)于醫(yī)學(xué)圖像的預(yù)訓(xùn)練模型論文《Comparing to Learn: Surpassing ImageNet Pretraining on Radiographs by Comparing Image Representations》。在深度學(xué)習(xí)領(lǐng)域,預(yù)訓(xùn)練模型有著舉足輕重的地位,特別是以自然場景數(shù)據(jù)為代表的ImageNet預(yù)訓(xùn)練模型是大多任務(wù)模型初始化參數(shù)的不二選擇。對于醫(yī)學(xué)圖像來說,其和自然場景數(shù)據(jù)差異大。醫(yī)學(xué)任務(wù)模型用ImageNet預(yù)訓(xùn)練模型就不太合適。因此,作者提出了一種新型的預(yù)訓(xùn)練方法(C2L),利用該方法在70萬X光無標(biāo)注數(shù)據(jù)上進行訓(xùn)練。利用預(yù)訓(xùn)練模型在不同的任務(wù)和數(shù)據(jù)集上均取得了優(yōu)于ImageNet預(yù)訓(xùn)練模型更好的SOTA結(jié)果。
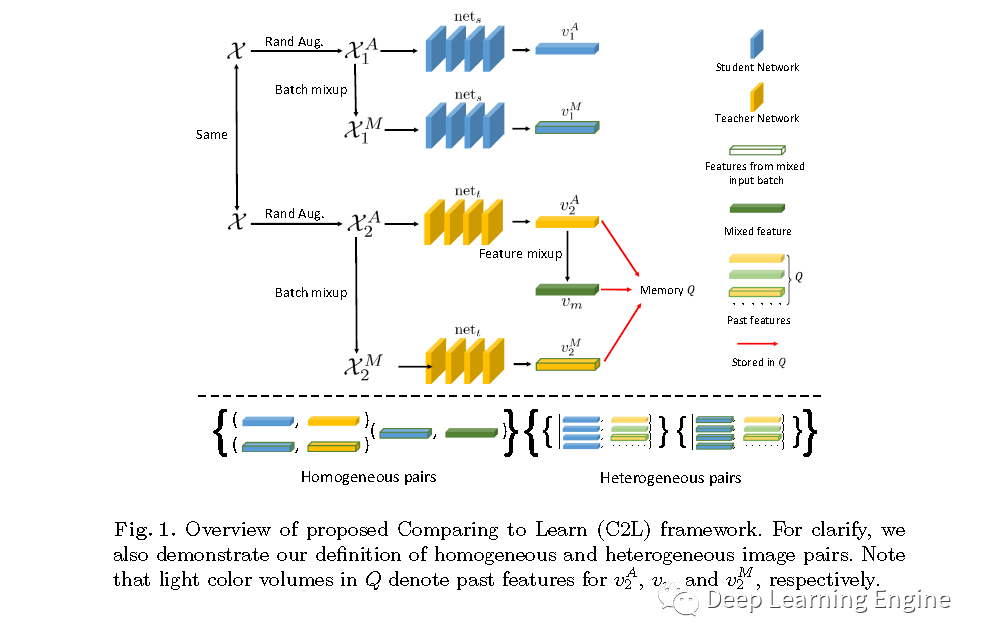
通過上述分析,作者提出了一種全新的自監(jiān)督預(yù)訓(xùn)練方法C2L(Compare to Learn)。此方法旨在利用大量的未標(biāo)注的X光圖像預(yù)訓(xùn)練一個2D深度學(xué)習(xí)模型,使得模型能夠在有監(jiān)督信息的條件下,通過對比不同圖像特征的差異,提取通用的圖像表達。與利用圖像修復(fù)等代理任務(wù)方法不同的是,作者提出的方法是一種自定義特征表達相似性度量。文中重點關(guān)注圖像特征級別的對比,通過混合每個批次的圖像和特征,提出了結(jié)構(gòu)同質(zhì)性和異質(zhì)性的數(shù)據(jù)配對方法。設(shè)計了一種基于動量的“老師-學(xué)生”(teacher-student architecture)對比學(xué)習(xí)網(wǎng)絡(luò)結(jié)構(gòu)。“老師”網(wǎng)絡(luò)和“學(xué)生”網(wǎng)絡(luò)共享同一個網(wǎng)絡(luò)結(jié)構(gòu),但是更新方式不同,其偽代碼如下。
02?proposed?Method
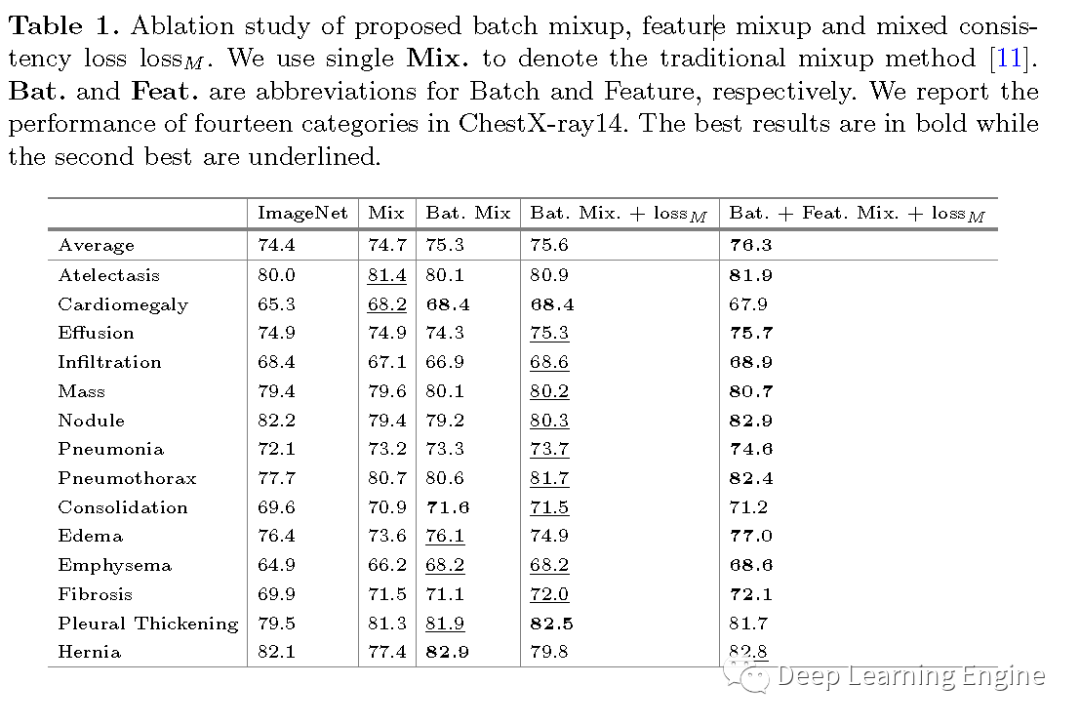
Batch Mixup and Feature Mixup:每一個批次的輸入圖像數(shù)據(jù),首先進行隨機數(shù)據(jù)增強(如隨機裁剪,旋轉(zhuǎn)等),生成兩組數(shù)據(jù)。與傳統(tǒng)的圖像級混合方法不同,作者提出了一種基于批次級的混合方法。假設(shè)每個批次包含Z張圖像,其中。隨機打亂,構(gòu)造配對數(shù)據(jù)。 其中,~ Beta(1.0,1.0)分布。通過實驗發(fā)現(xiàn),對兩組數(shù)據(jù)使用相同的混合因子和數(shù)據(jù)打亂方法對模型的性能有提升效果。作者對特征的表達也使用了相同的數(shù)據(jù)混合策略。其中指數(shù)因子控制著動量的程度。如偽代碼及流程圖所示,"教師"網(wǎng)絡(luò)同時利用自身和"學(xué)生"網(wǎng)絡(luò)進行更新。而在實際中,作者輸入和到"學(xué)生"模型,輸入和到"教師"模型。分別使用和表示"學(xué)生"網(wǎng)絡(luò)和"老師"網(wǎng)絡(luò)的輸出特征向量。Homogeneous and Heterogeneous Pairs:為了構(gòu)造同質(zhì)數(shù)據(jù)對,作者假設(shè)數(shù)據(jù)增強(包括文中用到的mixing operation混合操作)只會略微改變訓(xùn)練數(shù)據(jù)的分布。那么每個同質(zhì)性配對的數(shù)據(jù)包含的是經(jīng)過一些列同樣的數(shù)據(jù)增強,批次數(shù)據(jù)混合以及特征混合的數(shù)據(jù)。對于同質(zhì)數(shù)據(jù)對,只需要將當(dāng)前特征和所有的已經(jīng)存儲的隊列中特征進行對比。
Feature Comparison, Memory Q and Loss Function:如偽代碼如所示,C2L模型優(yōu)化最小化同質(zhì)數(shù)據(jù)對之間的距離,最大化異質(zhì)數(shù)據(jù)之間的距離。