
從零開(kāi)始深度學(xué)習(xí)Pytorch筆記(11)—— DataLoader類
 前文傳送門:從零開(kāi)始深度學(xué)習(xí)Pytorch筆記(1)——安裝Pytorch從零開(kāi)始深度學(xué)習(xí)Pytorch筆記(2)——張量的創(chuàng)建(上)從零開(kāi)始深度學(xué)習(xí)Pytorch筆記(3)——張量的創(chuàng)建(下)從零開(kāi)始深度學(xué)習(xí)Pytorch筆記(4)——張量的拼接與切分從零開(kāi)始深度學(xué)習(xí)Pytorch筆記(5)——張量的索引與變換從零開(kāi)始深度學(xué)習(xí)Pytorch筆記(6)——張量的數(shù)學(xué)運(yùn)算從零開(kāi)始深度學(xué)習(xí)Pytorch筆記(7)——?使用Pytorch實(shí)現(xiàn)線性回歸從零開(kāi)始深度學(xué)習(xí)Pytorch筆記(8)——?計(jì)算圖與自動(dòng)求導(dǎo)(上)
前文傳送門:從零開(kāi)始深度學(xué)習(xí)Pytorch筆記(1)——安裝Pytorch從零開(kāi)始深度學(xué)習(xí)Pytorch筆記(2)——張量的創(chuàng)建(上)從零開(kāi)始深度學(xué)習(xí)Pytorch筆記(3)——張量的創(chuàng)建(下)從零開(kāi)始深度學(xué)習(xí)Pytorch筆記(4)——張量的拼接與切分從零開(kāi)始深度學(xué)習(xí)Pytorch筆記(5)——張量的索引與變換從零開(kāi)始深度學(xué)習(xí)Pytorch筆記(6)——張量的數(shù)學(xué)運(yùn)算從零開(kāi)始深度學(xué)習(xí)Pytorch筆記(7)——?使用Pytorch實(shí)現(xiàn)線性回歸從零開(kāi)始深度學(xué)習(xí)Pytorch筆記(8)——?計(jì)算圖與自動(dòng)求導(dǎo)(上)
從零開(kāi)始深度學(xué)習(xí)Pytorch筆記(9)——?計(jì)算圖與自動(dòng)求導(dǎo)(下)從零開(kāi)始深度學(xué)習(xí)Pytorch筆記(10)—— Dataset類
DataLoader(dataset,?batch_size=1,?shuffle=False,?sampler=None,?batch_sampler=None,?num_workers=0,?collate_fn=None,?pin_memory=False,?drop_last=False,?timeout=0,?worker_init_fn=None,?multiprocessing_context=None)其中的參數(shù)含義為:dataset:加載的數(shù)據(jù)集(Dataset對(duì)象)batch_size:batch的大小shuffle::是否將數(shù)據(jù)打亂sampler:樣本抽樣num_workers:使用多進(jìn)程加載的進(jìn)程數(shù),0代表不使用多進(jìn)程collate_fn:如何將多個(gè)樣本數(shù)據(jù)拼接成一個(gè)batch,一般使用默認(rèn)的拼接方式即可pin_memory:是否將數(shù)據(jù)保存在pin memory區(qū),pin memory中的數(shù)據(jù)轉(zhuǎn)到GPU會(huì)快一些drop_last:dataset中的數(shù)據(jù)個(gè)數(shù)可能不是batch_size的整數(shù)倍,drop_last如果為True會(huì)將多出來(lái)不足一個(gè)batch的數(shù)據(jù)丟棄我們給出一個(gè)簡(jiǎn)單的DataLoader的例子:
import?torch
import?torch.utils.data?as?Data
BATCH_SIZE?=?5
x?=?torch.linspace(1,?20,?20)
y?=?torch.linspace(20,?1,?20)
torch_dataset?=?Data.TensorDataset(x,?y)#創(chuàng)建Dataset
loader?=?Data.DataLoader(
????dataset=torch_dataset,#數(shù)據(jù)
????batch_size=BATCH_SIZE,#批次的大小
????shuffle=True,#打亂數(shù)據(jù)
????num_workers=2,#多進(jìn)程
)
for?epoch?in?range(3):#三個(gè)epoch
????for?step,?(batch_x,?batch_y)?in?enumerate(loader):
????????print('Epoch:?',?epoch,?'|?Step:?',?step,?'|?batch?x:?',
??????????????batch_x.numpy(),?'|?batch?y:?',?batch_y.numpy())
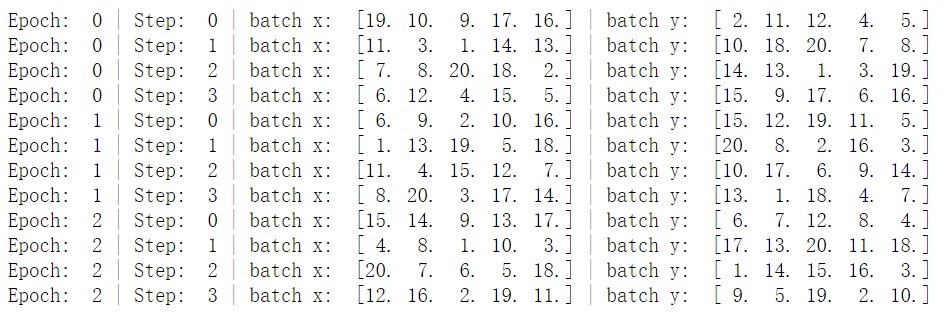 其中的一個(gè)epoch為將所有訓(xùn)練集訓(xùn)練一次的意思,而一個(gè)batch指的是將一批訓(xùn)練數(shù)據(jù)交給模型訓(xùn)練的意思。例如以上代碼的batchsize為5,訓(xùn)練集一共20條數(shù)據(jù),所以一個(gè)epoch分為4個(gè)batch(因?yàn)?0/5=4)。在深度學(xué)習(xí)中,所有訓(xùn)練集并不是只有一次加入模型訓(xùn)練,所以會(huì)有多個(gè)epoch的情況。我們把batchsize改為4,并且把數(shù)據(jù)打亂設(shè)置為False,再看看結(jié)果:
其中的一個(gè)epoch為將所有訓(xùn)練集訓(xùn)練一次的意思,而一個(gè)batch指的是將一批訓(xùn)練數(shù)據(jù)交給模型訓(xùn)練的意思。例如以上代碼的batchsize為5,訓(xùn)練集一共20條數(shù)據(jù),所以一個(gè)epoch分為4個(gè)batch(因?yàn)?0/5=4)。在深度學(xué)習(xí)中,所有訓(xùn)練集并不是只有一次加入模型訓(xùn)練,所以會(huì)有多個(gè)epoch的情況。我們把batchsize改為4,并且把數(shù)據(jù)打亂設(shè)置為False,再看看結(jié)果:import?torch
import?torch.utils.data?as?Data
BATCH_SIZE?=?4
x?=?torch.linspace(1,?20,?20)
y?=?torch.linspace(20,?1,?20)
torch_dataset?=?Data.TensorDataset(x,?y)#創(chuàng)建Dataset
loader?=?Data.DataLoader(
????dataset=torch_dataset,#數(shù)據(jù)
????batch_size=BATCH_SIZE,#批次的大小
????shuffle=False,#打亂數(shù)據(jù)
????num_workers=2,#多進(jìn)程
)
for?epoch?in?range(3):#三個(gè)epoch
????for?step,?(batch_x,?batch_y)?in?enumerate(loader):
????????print('Epoch:?',?epoch,?'|?Step:?',?step,?'|?batch?x:?',
??????????????batch_x.numpy(),?'|?batch?y:?',?batch_y.numpy())
 我們可以看到數(shù)據(jù)的batchsize變?yōu)榱?,并且數(shù)據(jù)的輸出是有序的,而深度學(xué)習(xí)中為了避免數(shù)據(jù)分布的干擾,一般都會(huì)講數(shù)據(jù)打亂輸入模型中!
我們可以看到數(shù)據(jù)的batchsize變?yōu)榱?,并且數(shù)據(jù)的輸出是有序的,而深度學(xué)習(xí)中為了避免數(shù)據(jù)分布的干擾,一般都會(huì)講數(shù)據(jù)打亂輸入模型中!歡迎關(guān)注公眾號(hào)學(xué)習(xí)之后的深度學(xué)習(xí)連載部分~
歷史文章推薦閱讀:
從零開(kāi)始學(xué)自然語(yǔ)言處理(四)—— 做 NLP 任務(wù)文本 id 化與預(yù)訓(xùn)練詞向量初始化方法
從零開(kāi)始學(xué)自然語(yǔ)言處理(三)——手把手帶你實(shí)現(xiàn)word2vec(skip-gram)
從零開(kāi)始學(xué)自然語(yǔ)言處理(二)——手把手帶你用代碼實(shí)現(xiàn)word2vec
從零開(kāi)始學(xué)自然語(yǔ)言處理(一)—— jieba 分詞
一文詳解NLP語(yǔ)料構(gòu)建技巧你不知道的Python環(huán)境管理技巧,超級(jí)好用!
Python快速安裝庫(kù)的靠譜辦法你只會(huì)用Python的pip安裝包?別錯(cuò)過(guò)這些好用功能!
掃碼下圖關(guān)注我們不會(huì)讓你失望!

 喜歡記得點(diǎn)再看哦,證明你來(lái)看過(guò)~
喜歡記得點(diǎn)再看哦,證明你來(lái)看過(guò)~評(píng)論
圖片
表情