
從零開始深度學(xué)習(xí)Pytorch筆記(2)——張量的創(chuàng)建(上)

在該系列的上一篇文章中,我們完整實(shí)現(xiàn)了Pytorch的cpu和gpu版本的安裝,如果你還沒有安裝Pytorch,戳這里:從零開始深度學(xué)習(xí)Pytorch筆記(1)——安裝Pytorch
本文我們正式開始學(xué)習(xí)Pytorch,說(shuō)起Pytorch,我們首先要聊到他的基本數(shù)據(jù)類型——張量(Tensor),就像我們聊到Numpy一定是先學(xué)習(xí)他的數(shù)據(jù)類型ndarray一樣。
那張量到底是什么呢?
張量類似于Numpy中的ndarray,我們都知道深度學(xué)習(xí)的基礎(chǔ)是神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu),而在Pytorch中,張量是構(gòu)建神經(jīng)網(wǎng)絡(luò)的基礎(chǔ)。
比較重要的一點(diǎn)是張量可以在GPU上進(jìn)行計(jì)算。
所以從本質(zhì)上來(lái)說(shuō),PyTorch 是一個(gè)處理張量的庫(kù)。一個(gè)張量是一個(gè)數(shù)字、向量、矩陣或任何 n 維數(shù)組。
下圖分別展示了1維張量,2維張量和3維張量:
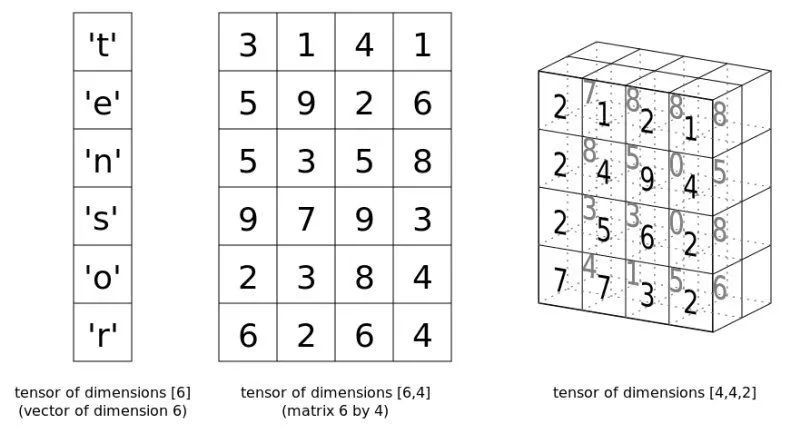
接下來(lái)我們看看如何創(chuàng)建張量。
我們導(dǎo)入pytorch和numpy
import?torch
import?numpy?as?np
我們可以看看張量的相關(guān)參數(shù):
torch.tensor(data,?dtype=None,?device=None,?requires_grad=False,?pin_memory=False)
其中:
data: 數(shù)據(jù),可以是list,numpy的ndarray
dtype: 數(shù)據(jù)類型,默認(rèn)與data的類型一致
device: 所在設(shè)備,gpu/cpu
requires_grad: 是否需要梯度,因?yàn)樯窠?jīng)網(wǎng)絡(luò)結(jié)構(gòu)經(jīng)常會(huì)要求梯度
pin_memory: 是否存于鎖頁(yè)內(nèi)存
使用Numpy創(chuàng)建張量
通過(guò)np創(chuàng)建ndarray,然后轉(zhuǎn)化為張量,數(shù)據(jù)類型默認(rèn)與data一致,這里是創(chuàng)建了一個(gè)3*3的全1張量:
arr?=?np.ones((3,3))
print("數(shù)據(jù)類型為:",arr.dtype)
t?=?torch.tensor(arr)
print(t)

如果你已經(jīng)搭建了GPU環(huán)境,可以通過(guò)如下代碼將張量創(chuàng)建在GPU上(創(chuàng)建需要幾秒的等待時(shí)間):
arr?=?np.ones((3,3))
print("數(shù)據(jù)類型為:",arr.dtype)
t?=?torch.tensor(arr,device='cuda')
print(t)
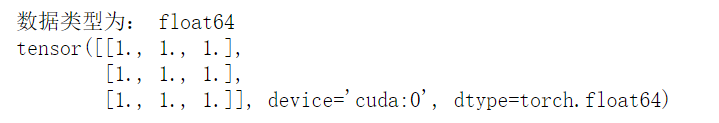
還有一種通過(guò)Numpy創(chuàng)建張量的方法,是使用torch.from_numpy(ndarray)。
torch.from_numpy(ndarray)
我們可以看到,它只需要接受一個(gè)ndarray即可。
arr?=?np.array([[1,2,3],[4,5,6]])
t?=?torch.from_numpy(arr)
print(arr)
print(t)

但是要注意的一點(diǎn)是:從torch.from_numpy創(chuàng)建的tensor和ndarray共享內(nèi)存,當(dāng)修改其中一個(gè)的數(shù)據(jù),另外一個(gè)也會(huì)被修改。
例如我們修改array的內(nèi)容:
arr?=?np.array([[1,2,3],[4,5,6]])
t?=?torch.from_numpy(arr)
#修改array內(nèi)容
arr[0,0]?=?999
print(arr)
print(t)

或是我們修改張量的內(nèi)容:
arr?=?np.array([[1,2,3],[4,5,6]])
t?=?torch.from_numpy(arr)
#修改tensor內(nèi)容
t[0,0]?=?-888
print(arr)
print(t)
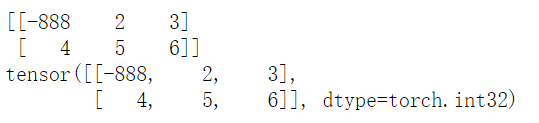
創(chuàng)建全0張量
我們可以通過(guò)torch.zeros()來(lái)創(chuàng)建全0張量:
zeros(*size,?out=None,?dtype=None,?layout=torch.strided,?device=None,?requires_grad=False)
其中:
size:為張量的形狀
out:輸出的張量
dtype: 數(shù)據(jù)類型
layout:內(nèi)存中的布局形式,有strided,sparse_coo等
device:所在設(shè)備,gpu/cpu
requires_grad:是否需要梯度
t1?=?torch.tensor([1,2,3])#創(chuàng)建一個(gè)t1張量,賦一個(gè)初始值
t?=?torch.zeros((2,3),out=t1)#將創(chuàng)建的t張量輸出到t1
print(t,'\n',t1)
print(id(t),id(t1),id(t)==id(t1))

torch.zeros_like(input,?dtype=None,?layout=None,?device=None,?requires_grad=False)會(huì)根據(jù)input形狀創(chuàng)建全0張量,例如我們創(chuàng)建一個(gè)3*5的全0張量:input?=?torch.empty(3,?5)
t?=?torch.zeros_like(input)
print(t)
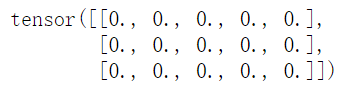
創(chuàng)建全1張量
全1張量的創(chuàng)建和全0張量的創(chuàng)建方式基本一致,使用如下方式創(chuàng)建:
torch.ones()
torch.ones_like()
根據(jù)數(shù)值創(chuàng)建張量
torch.full
torch.full(size,?fill_value,?out=None,?dtype=None,?layout=torch.strided,?device=None,?requires_grad=False)
其中的新出現(xiàn)參數(shù):
fill_value: 填充的值
例如創(chuàng)建一個(gè)2*2的元素都是8的張量:
t?=?torch.full((2,2),8)
print(t)
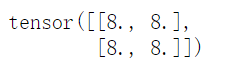
torch.full_like()
torch.full_like(input,?fill_value,?out=None,?dtype=None,?layout=torch.strided,?device=None,?requires_grad=False)
input?=?torch.empty(3,?5)
t?=?torch.full_like(input,8)
print(t)

上面是根據(jù)input的形狀創(chuàng)建了一個(gè)元素都為8的張量。
創(chuàng)建等差的1維張量
可以通過(guò)torch.arange()創(chuàng)建等差的一維張量:
arange(start=0,?end,?step=1,?out=None,?dtype=None,?layout=torch.strided,?device=None,?requires_grad=False)
其中:
start:數(shù)列的起始值
end:數(shù)列的結(jié)束值,取不到,只能取到 end-1
step:公差(步長(zhǎng)),默認(rèn)為 1
t?=?torch.arange(1,9,2)
print(t)
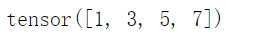
創(chuàng)建等間距(均分)的1維張量
torch.linspace()
linspace(start,?end,?steps=100,?out=None,?dtype=None,?layout=torch.strided,?device=None,?requires_grad=False)
其中:
steps:創(chuàng)建出的一維張量的元素個(gè)數(shù)
end:結(jié)束位置可以取到
t?=?torch.linspace(1,9,5)
print(t)

t?=?torch.linspace(1,9,7)
print(t)
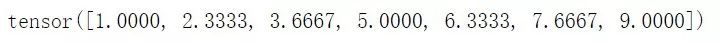 創(chuàng)建對(duì)數(shù)均分的1維張量
創(chuàng)建對(duì)數(shù)均分的1維張量
torch.logspace()
logspace(start,?end,?steps=100,?base=10.0,?out=None,?dtype=None,?layout=torch.strided,?device=None,?requires_grad=False)
參數(shù):
base: 對(duì)數(shù)函數(shù)的底,默認(rèn)為10
t?=?torch.logspace(start=-5,?end=10,steps=4)
print(t)
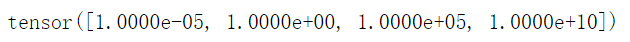
創(chuàng)建單位對(duì)角矩陣(2維張量)
torch.eye()
torch.eye(n,?m=None,?out=None,?dtype=None,?layout=torch.strided,?device=None,?requires_grad=False)
參數(shù):
m:矩陣行數(shù)
n:矩陣列數(shù)
t?=?torch.eye(4)
print(t)

默認(rèn)為方陣。
這些張量創(chuàng)建的方式你記住了么?
 你點(diǎn)的每個(gè)在看,我都認(rèn)真當(dāng)成了喜歡
你點(diǎn)的每個(gè)在看,我都認(rèn)真當(dāng)成了喜歡