
ConvNeXt:手把手教你改模型

極市導(dǎo)讀
?本文目的是結(jié)合代碼對(duì)該工作中的trick進(jìn)行梳理,幫助廣大工程師童鞋抄作業(yè),整合到自己的項(xiàng)目中。?>>加入極市CV技術(shù)交流群,走在計(jì)算機(jī)視覺(jué)的最前沿
A ConvNet for the 2020s
我愿稱之為2022年cv算法工程師抄作業(yè)必備手冊(cè),手把手教你改模型,把ResNet50從76.1一步步干到82.0。或許對(duì)于廣大researcher而言這只是一個(gè)堆trick的工作,但對(duì)于工程師來(lái)說(shuō),光是驗(yàn)證哪些trick能work,哪些trick堆疊在一起能都產(chǎn)生收益,這件事本身就已經(jīng)散發(fā)著money的味道了。現(xiàn)在大佬們燒了這么多電費(fèi)把結(jié)果擺到大家面前,還要什么自行車(chē)。
本文的目的是結(jié)合代碼對(duì)該工作中的trick進(jìn)行梳理,幫助廣大工程師童鞋抄作業(yè),整合到自己的項(xiàng)目中。
Roadmap
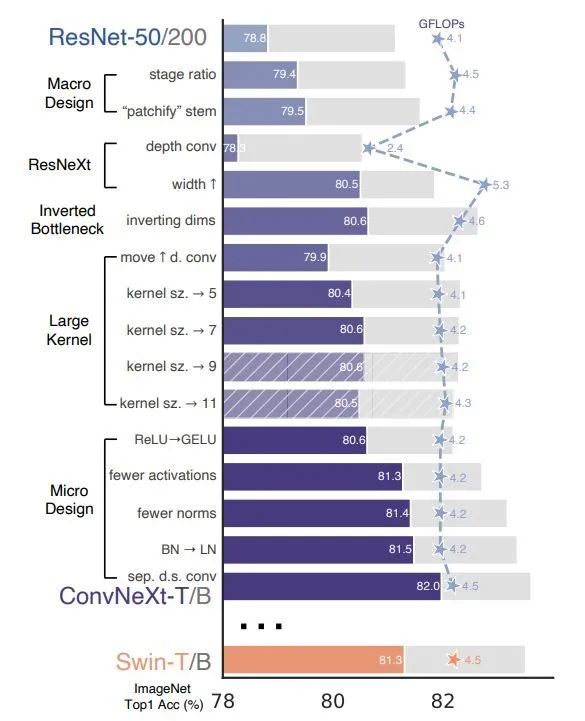
這張圖可以說(shuō)是整篇論文的精華,有經(jīng)驗(yàn)的童鞋光是看這張圖就知道該做什么了。
0. 訓(xùn)練策略優(yōu)化(76.1-78.8)
深度學(xué)習(xí)發(fā)展了這么久,除了結(jié)構(gòu)上的創(chuàng)新,各種訓(xùn)練策略也在升級(jí)。2021年timm和torchvision團(tuán)隊(duì)均有工作講述如何通過(guò)優(yōu)化訓(xùn)練策略來(lái)使resnet50性能提升到80以上。
考慮到跟Swin Transformer的公平對(duì)比,本文的訓(xùn)練策略沒(méi)有完全follow前面的工作,但仍然可以將ResNet50從76.1提升到78.8。
這里我匯總了一下訓(xùn)練策略橫向?qū)Ρ龋奖愦蠹也楸恚?/p>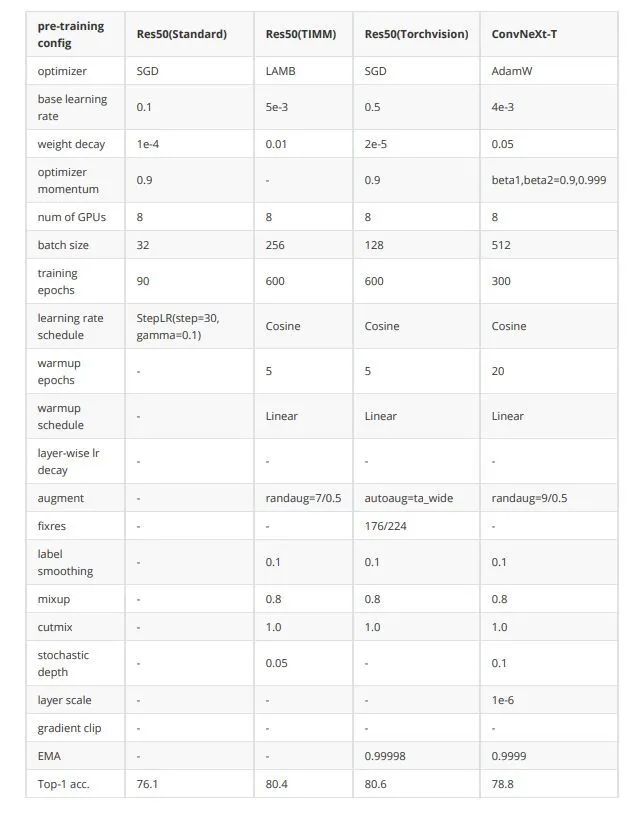
1. 宏觀設(shè)計(jì)
1.1 改變stage compute ratio(78.8-79.4)
改變layer0到layer3的block數(shù)量比例,由標(biāo)準(zhǔn)的(3,4,6,3)改為Swin-T使用的(3,3,9,3),即1:1:3:1。對(duì)于更大的模型,也跟進(jìn)了Swin所使用的1:1:9:1。
1.2 使用Patchify的stem(79.4-79.5)
從ViT開(kāi)始,為了將圖片轉(zhuǎn)化為token,圖片都會(huì)先被分割成一個(gè)一個(gè)的patch,而在傳統(tǒng)ResNet中stem層是使用一個(gè)stride=2的7x7卷積加最大池化層。
本文仿照Swin-T的做法,用stride=4的4x4卷積來(lái)進(jìn)行stem,使得滑動(dòng)窗口不再相交,每次只處理一個(gè)patch的信息。
#?標(biāo)準(zhǔn)ResNet
stem?=?nn.Sequential(
????nn.Conv2d(in_chans,?dims[0],?kernel_size=7,?stride=2),
????nn.MaxPool2d(kernel_size=3,?stride=2,?padding=1)
)
#?ConvNeXt
stem?=?nn.Sequential(
????nn.Conv2d(in_chans,?dims[0],?kernel_size=4,?stride=4),
????LayerNorm(dims[0],?eps=1e-6,?data_format="channels_first")
)
通過(guò)代碼我們可以注意到,在stem中還加入了一個(gè)LN。
2. ResNeXt化(79.5-80.5)
由于ResNeXt在FLOPs/accuracy的trade-off比ResNet更優(yōu)秀,于是進(jìn)行了一些借鑒,主要是使用了分組卷積。
ResNeXt的指導(dǎo)準(zhǔn)則是“分更多的組,拓寬width”,因此本文直接使用了depthwise conv,即分組數(shù)等于輸入通道數(shù)。這個(gè)技術(shù)在之前主要是應(yīng)用在MobileNet這種輕量級(jí)網(wǎng)絡(luò)中,用于降低計(jì)算量。但在這里,作者發(fā)現(xiàn)dw conv由于每個(gè)卷積核單獨(dú)處理一個(gè)通道,這種形式跟self-attention機(jī)制很相似,都是在單個(gè)通道內(nèi)做空間信息的混合加權(quán)。
將bottleneck中的3x3卷積替換成dw conv,再把網(wǎng)絡(luò)寬度從64提升到96。
3. 反瓶頸結(jié)構(gòu)(80.5-80.6)
在標(biāo)準(zhǔn)ResNet中使用的bottleneck是(大維度-小維度-大維度)的形式來(lái)減小計(jì)算量。后來(lái)在MobileNetV2中提出了inverted bottleneck結(jié)構(gòu),采用(小維度-大維度-小維度)形式,認(rèn)為這樣能讓信息在不同維度特征空間之間轉(zhuǎn)換時(shí)避免壓縮維度帶來(lái)的信息損失,后來(lái)在Transformer的MLP中也使用了類(lèi)似的結(jié)構(gòu),中間層全連接層維度數(shù)是兩端的4倍。
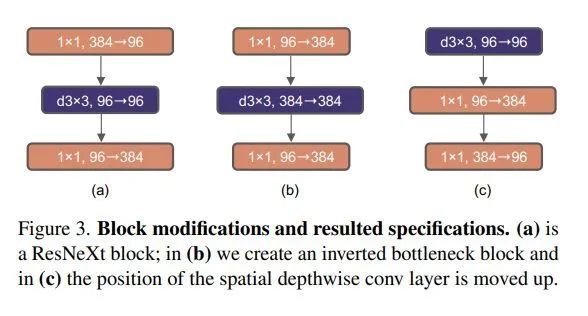
4. 大卷積核(80.6-80.6)
由于Swin-T中使用了7x7卷積核,這一步主要是為了對(duì)齊比較。又因?yàn)閕nverted bottleneck放大了中間卷積層的緣故,直接替換會(huì)導(dǎo)致參數(shù)量增大,因而作者把dw conv的位置進(jìn)行了調(diào)整,放到了反瓶頸的開(kāi)頭。最終結(jié)果相近,說(shuō)明在7x7在相同參數(shù)量下效果是一致的。
5. 微觀設(shè)計(jì)
5.1 用GELU替換ReLU(80.6-80.6)
主要是為了對(duì)齊比較,并沒(méi)有帶來(lái)提升。
5.2 減少激活層數(shù)量(80.6-81.3)
由于Transformer中只使用了一個(gè)激活層,因此在設(shè)計(jì)上進(jìn)行了效仿,結(jié)果發(fā)現(xiàn)只在block中的兩個(gè)1x1卷積之間使用一層激活層,其他地方不適用,反而帶來(lái)了0.7個(gè)點(diǎn)的提升。這說(shuō)明太頻繁地做非線性投影對(duì)于網(wǎng)絡(luò)特征的信息傳遞實(shí)際上是有害的。
5.3 減少歸一化層數(shù)量(81.3-81.4)
基于跟減少激活層相同的邏輯,由于Transformer中BN層很少,本文也只保留了1x1卷積之前的一層BN,而兩個(gè)1x1卷積層之間甚至沒(méi)有使用歸一化層,只做了非線性投影。
5.4 用LN替換BN(81.4-81.5)
由于Transformer中使用了LN,且一些研究發(fā)現(xiàn)BN會(huì)對(duì)網(wǎng)絡(luò)性能帶來(lái)一些負(fù)面影響,本文將所有的BN替換為L(zhǎng)N。
5.5 單獨(dú)的下采樣層(81.5-82.0)
標(biāo)準(zhǔn)ResNet的下采樣層通常是stride=2的3x3卷積,對(duì)于有殘差結(jié)構(gòu)的block則在短路連接中使用stride=2的1x1卷積,這使得CNN的下采樣層基本與其他層保持了相似的計(jì)算策略。而Swin-T中的下采樣層是單獨(dú)的,因此本文用stride=2的2x2卷積進(jìn)行模擬。又因?yàn)檫@樣會(huì)使訓(xùn)練不穩(wěn)定,因此每個(gè)下采樣層后面增加了LN來(lái)穩(wěn)定訓(xùn)練。
self.downsample_layers?=?nn.ModuleList()?
#?stem也可以看成下采樣層,一起存到downsample_layers中,推理時(shí)通過(guò)index進(jìn)行訪問(wèn)
stem?=?nn.Sequential(
????nn.Conv2d(in_chans,?dims[0],?kernel_size=4,?stride=4),
????LayerNorm(dims[0],?eps=1e-6,?data_format="channels_first")
)
self.downsample_layers.append(stem)
for?i?in?range(3):
????downsample_layer?=?nn.Sequential(
????????????LayerNorm(dims[i],?eps=1e-6,?data_format="channels_first"),
????????????nn.Conv2d(dims[i],?dims[i+1],?kernel_size=2,?stride=2),
????)
self.downsample_layers.append(downsample_layer)
#?由于網(wǎng)絡(luò)結(jié)構(gòu)是downsample-stage-downsample-stage的形式,所以stem和后面的下采樣層中的LN是不會(huì)連在一起的
對(duì)以上內(nèi)容進(jìn)行整合,最終得到了單個(gè)block的設(shè)計(jì)及代碼:
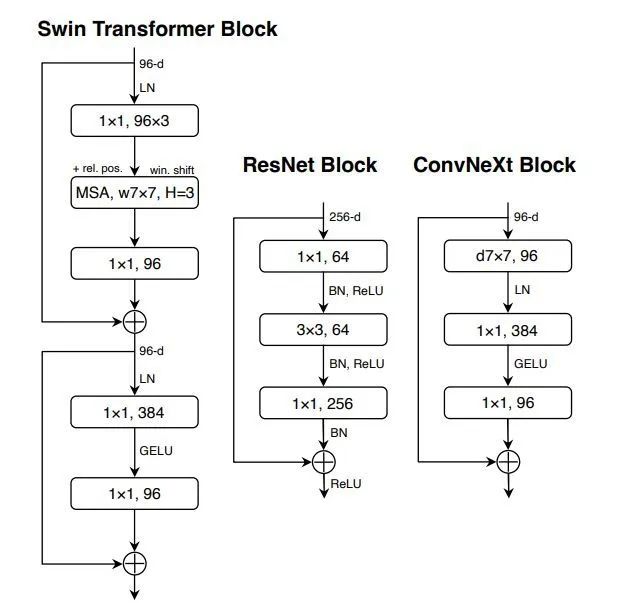
class?Block(nn.Module):
????def?__init__(self,?dim,?drop_path=0.,?layer_scale_init_value=1e-6):
????????super().__init__()
????????#?分組卷積+大卷積核
????????self.dwconv?=?nn.Conv2d(dim,?dim,?kernel_size=7,?padding=3,?groups=dim)?
????????#?在1x1之前使用唯一一次LN做歸一化
????????self.norm?=?LayerNorm(dim,?eps=1e-6)?
????????#?全連接層跟1x1conv等價(jià),但pytorch計(jì)算上fc略快
????????self.pwconv1?=?nn.Linear(dim,?4?*?dim)
????????#?整個(gè)block只使用唯一一次激活層
????????self.act?=?nn.GELU()
????????#?反瓶頸結(jié)構(gòu),中間層升維了4倍
????????self.pwconv2?=?nn.Linear(4?*?dim,?dim)
????????#?gamma的作用是用于做layer?scale訓(xùn)練策略
????????self.gamma?=?nn.Parameter(layer_scale_init_value?*?torch.ones((dim)),?
????????????????????????????????????requires_grad=True)?if?layer_scale_init_value?>?0?else?None
????????#?drop_path是用于stoch.?depth訓(xùn)練策略
????????self.drop_path?=?DropPath(drop_path)?if?drop_path?>?0.?else?nn.Identity()
????def?forward(self,?x):
????????input?=?x
????????x?=?self.dwconv(x)
????????#?由于用FC來(lái)做1x1conv,所以需要調(diào)換通道順序
????????x?=?x.permute(0,?2,?3,?1)?#?(N,?C,?H,?W)?->?(N,?H,?W,?C)?
????????x?=?self.norm(x)
????????x?=?self.pwconv1(x)
????????x?=?self.act(x)
????????x?=?self.pwconv2(x)
????????if?self.gamma?is?not?None:
????????????x?=?self.gamma?*?x
????????x?=?x.permute(0,?3,?1,?2)?#?(N,?H,?W,?C)?->?(N,?C,?H,?W)
????????x?=?input?+?self.drop_path(x)
????????return?x
通過(guò)代碼可以注意到,以上Block中兩層1x1卷積是用全連接層來(lái)實(shí)現(xiàn)的,按照作者的說(shuō)法,這樣會(huì)比使用卷積層略快。
但作者是在GPU上進(jìn)行的實(shí)驗(yàn),考慮到CPU上很多情況會(huì)不同,因此我縮減得到了一個(gè)輕量的ConvNeXt-ExTiny模型,并轉(zhuǎn)換成MNN模型,測(cè)試了兩種實(shí)現(xiàn)方案的速度,發(fā)現(xiàn)在CPU上還是使用1x1卷積層的速度更快。
實(shí)現(xiàn)如下:
class?Block(nn.Module):
????def?__init__(self,?dim,?drop_path=0.,?layer_scale_init_value=1e-6):
????????super().__init__()
????????self.dwconv?=?nn.Conv2d(dim,?dim,?kernel_size=7,?padding=3,?groups=dim)??#?depthwise?conv
????????self.act?=?nn.GELU()
????????self.norm?=?LayerNorm(dim,?eps=1e-6,?data_format="channels_first")
????????self.pwconv1?=?nn.Conv2d(dim,?dim*4,?kernel_size=1,?stride=1)
????????self.pwconv2?=?nn.Conv2d(dim*4,?dim,?kernel_size=1,?stride=1)
????????self.gamma?=?nn.Parameter(layer_scale_init_value?*?torch.ones((dim,1,1)),
??????????????????????????????????requires_grad=True)?if?layer_scale_init_value?>?0?else?None
????????self.drop_path?=?DropPath(drop_path)?if?drop_path?>?0.?else?nn.Identity()
????def?forward(self,?x):
????????input?=?x
????????x?=?self.dwconv(x)
????????x?=?self.norm(x)
????????x?=?self.pwconv1(x)
????????x?=?self.act(x)
????????x?=?self.pwconv2(x)
????????if?self.gamma?is?not?None:
????????????x?=?self.gamma?*?x
????????x?=?input?+?self.drop_path(x)
????????return?x
MNN下CPU推理速度對(duì)比:
fc版:
mnn_inference: 16.39620065689087
mnn_inference: 17.782490253448486?
mnn_inference: 17.42337703704834?
mnn_inference: 16.68517827987671
mnn_inference: 15.608322620391846
1x1 conv版本:
mnn_inference: 14.232232570648193?
mnn_inference: 14.07259225845337?
mnn_inference: 13.94277572631836?
mnn_inference: 14.112122058868408?
mnn_inference: 13.633315563201904
如果覺(jué)得有用,就請(qǐng)分享到朋友圈吧!
公眾號(hào)后臺(tái)回復(fù)“transformer”獲取最新Transformer綜述論文下載~

#?CV技術(shù)社群邀請(qǐng)函?#

備注:姓名-學(xué)校/公司-研究方向-城市(如:小極-北大-目標(biāo)檢測(cè)-深圳)
即可申請(qǐng)加入極市目標(biāo)檢測(cè)/圖像分割/工業(yè)檢測(cè)/人臉/醫(yī)學(xué)影像/3D/SLAM/自動(dòng)駕駛/超分辨率/姿態(tài)估計(jì)/ReID/GAN/圖像增強(qiáng)/OCR/視頻理解等技術(shù)交流群
每月大咖直播分享、真實(shí)項(xiàng)目需求對(duì)接、求職內(nèi)推、算法競(jìng)賽、干貨資訊匯總、與?10000+來(lái)自港科大、北大、清華、中科院、CMU、騰訊、百度等名校名企視覺(jué)開(kāi)發(fā)者互動(dòng)交流~
