
【數(shù)據(jù)分析】干貨!一文教會你 Scrapy 爬蟲框架的基本使用
??出品:Python數(shù)據(jù)之道 (ID:PyDataLab)?
作者:葉庭云?
編輯:Lemon
一、scrapy 爬蟲框架介紹
在編寫爬蟲的時候,如果我們使用 requests、aiohttp 等庫,需要從頭至尾把爬蟲完整地實現(xiàn)一遍,比如說異常處理、爬取調(diào)度等,如果寫的多了,的確會比較麻煩。利用現(xiàn)有的爬蟲框架,可以提高編寫爬蟲的效率,而說到 Python 的爬蟲框架,Scrapy 當(dāng)之無愧是最流行最強大的爬蟲框架了。
scrapy 介紹
Scrapy 是一個基于 Twisted 的異步處理框架,是純 Python 實現(xiàn)的爬蟲框架,其架構(gòu)清晰,模塊之間的耦合程度低,可擴展性極強,可以靈活完成各種需求。我們只需要定制開發(fā)幾個模塊就可以輕松實現(xiàn)一個爬蟲。
scrapy 爬蟲框架的架構(gòu)如下圖所示:
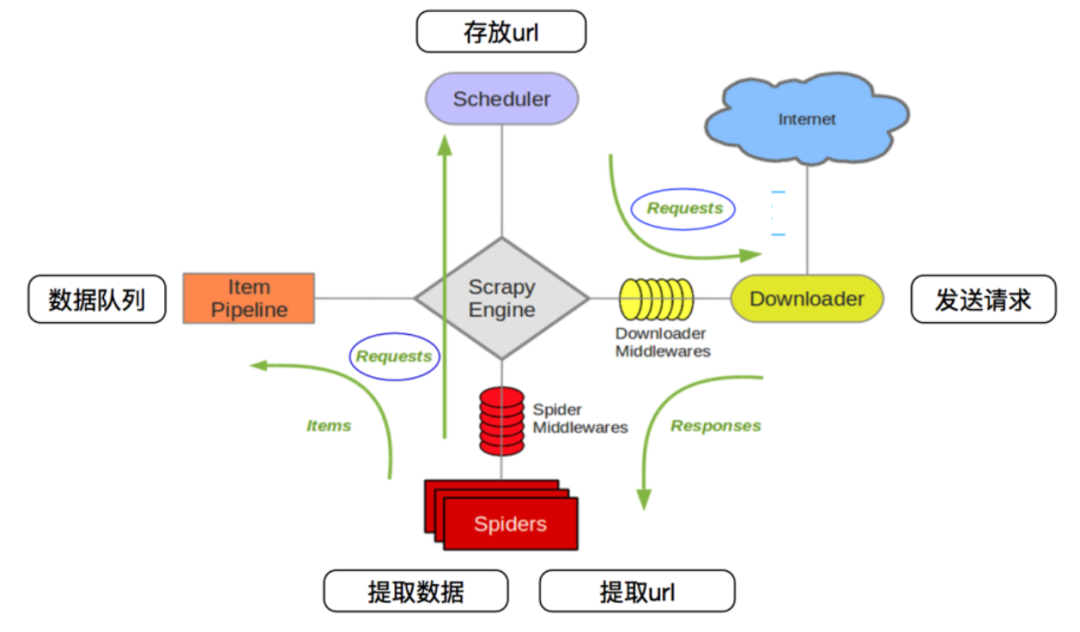
它有如下幾個部分:
Scrapy Engine(引擎):用來處理整個系統(tǒng)的數(shù)據(jù)流處理、觸發(fā)事務(wù),是整個框架的核心。 Item(項目):定義了爬取結(jié)果的數(shù)據(jù)結(jié)構(gòu),爬取的數(shù)據(jù)會被賦值成該對象。 Scheduler(調(diào)度器):用來接受引擎發(fā)過來的請求并加入隊列中,并在引擎再次請求的時候提供給引擎。 Item Pipeline(項目管道):負責(zé)處理由蜘蛛從網(wǎng)頁中抽取的項目,它的主要任務(wù)是清洗、驗證和存儲數(shù)據(jù)。 Downloader(下載器):用于下載網(wǎng)頁內(nèi)容,并將網(wǎng)頁內(nèi)容返回給 Spiders。 Spiders(蜘蛛):其內(nèi)定義了爬取的邏輯和網(wǎng)頁的解析規(guī)則,它主要負責(zé)解析響應(yīng)并生成提取結(jié)果和新的請求。 Downloader Middlewares(下載器中間件):位于引擎和下載器之間的鉤子框架,主要是處理引擎與下載器之間的請求及響應(yīng)。 Spider Middlewares(Spiders 中間件):位于引擎和蜘蛛之間的鉤子框架,主要工作是處理蜘蛛輸入的響應(yīng)和輸出的結(jié)果及新的請求。
Scrapy 數(shù)據(jù)流機制
scrapy 中的數(shù)據(jù)流由引擎控制,其過程如下:
Engine 首先打開一個網(wǎng)站,找到處理該網(wǎng)站的 Spider 并向該 Spider 請求第一個要爬取的 URL。 Engine 從 Spider 中獲取到第一個要爬取的 URL 并通過 Scheduler 以 Request 的形式調(diào)度。 Engine 向 Scheduler 請求下一個要爬取的 URL。 Scheduler 返回下一個要爬取的 URL 給 Engine,Engine 將 URL 通過 Downloader Middlewares 轉(zhuǎn)發(fā)給 Downloader 下載。 一旦頁面下載完畢, Downloader 生成一個該頁面的 Response,并將其通過 Downloader Middlewares 發(fā)送給 Engine。 Engine 從下載器中接收到 Response 并通過 Spider Middlewares 發(fā)送給 Spider 處理。 Spider 處理 Response 并返回爬取到的 Item 及新的 Request 給 Engine。 Engine 將 Spider 返回的 Item 給 Item Pipeline,將新的 Request 給 Scheduler。 重復(fù)第二步到最后一步,直到 Scheduler 中沒有更多的 Request,Engine 關(guān)閉該網(wǎng)站,爬取結(jié)束。
通過多個組件的相互協(xié)作、不同組件完成工作的不同、組件很好地支持異步處理,scrapy 最大限度地利用了網(wǎng)絡(luò)帶寬,大大提高了數(shù)據(jù)爬取和處理的效率。
二、scrapy 的安裝和創(chuàng)建項目
pip?install?Scrapy?-i?http://pypi.douban.com/simple?--trusted-host?pypi.douban.com
安裝方法參考官方文檔:https://docs.scrapy.org/en/latest/intro/install.html
安裝完成之后,如果可以正常使用 scrapy 命令,那就是安裝成功了。
Scrapy 是框架,已經(jīng)幫我們預(yù)先配置好了很多可用的組件和編寫爬蟲時所用的腳手架,也就是預(yù)生成一個項目框架,我們可以基于這個框架來快速編寫爬蟲。
Scrapy 框架是通過命令行來創(chuàng)建項目的,創(chuàng)建項目的命令如下:
scrapy?startproject?practice
命令執(zhí)行后,在當(dāng)前運行目錄下便會出現(xiàn)一個文件夾,叫作 practice ,這就是一個Scrapy 項目框架,我們可以基于這個項目框架來編寫爬蟲。
project/
?__pycache__
??spiders/
???__pycache__
????????__init__.py
????????spider1.py
????????spider2.py
????????...
????__init__.py
????items.py
????middlewares.py
????pipelines.py
????settings.py
scrapy.cfg
各個文件的功能描述如下:
scrapy.cfg:它是 Scrapy 項目的配置文件,其內(nèi)定義了項目的配置文件路徑、部署相關(guān)信息等內(nèi)容。 items.py:它定義 Item 數(shù)據(jù)結(jié)構(gòu),所有的 Item 的定義都可以放這里。 pipelines.py:它定義 Item Pipeline 的實現(xiàn),所有的 Item Pipeline 的實現(xiàn)都可以放這里。 settings.py:它定義項目的全局配置。 middlewares.py:它定義 Spider Middlewares 和 Downloader Middlewares 的實現(xiàn)。 spiders:其內(nèi)包含一個個 Spider 的實現(xiàn),每個 Spider 都有一個文件。
三、scrapy 的基本使用
實例 1:爬取 Quotes
創(chuàng)建一個 Scrapy 項目。 創(chuàng)建一個 Spider 來抓取站點和處理數(shù)據(jù)。 通過命令行運行,將抓取的內(nèi)容導(dǎo)出。
目標(biāo)URL:http://quotes.toscrape.com/
創(chuàng)建項目
創(chuàng)建一個 scrapy 項目,項目文件可以直接用 scrapy 命令生成,命令如下所示:
scrapy?startproject?practice?
創(chuàng)建 Spider
Spider 是自己定義的類,scrapy 用它從網(wǎng)頁里抓取內(nèi)容,并解析抓取的結(jié)果。這個類必須繼承 Scrapy 提供的Spider 類 scrapy.Spider ,還要定義 Spider 的名稱和起始請求,以及怎樣處理爬取后的結(jié)果的方法。
使用命令行創(chuàng)建一個 Spider,命令如下:
cd?practice
scrapy?genspider?quotes?quotes.toscrape.com
切換路徑到剛才創(chuàng)建的 practice 文件夾,然后執(zhí)行 genspider 命令。第一個參數(shù)是 Spider 的名稱,第二個參數(shù)是網(wǎng)站域名。執(zhí)行完畢之后,spiders 文件夾中多了一個quotes.py,它就是剛剛創(chuàng)建的 Spider,內(nèi)容如下:
import?scrapy
class?QuotesSpider(scrapy.Spider):
????name?=?"quotes"
????allowed_domains?=?["quotes.toscrape.com"]
????start_urls?=?['http://quotes.toscrape.com/']
????def?parse(self,?response):
????????pass
可以看到 quotes.py 里有三個屬性—— name、allowed_domains 和 start_urls,還有一個方法 parse。
name:它是每個項目唯一的名字,用來區(qū)分不同的 Spider。 allowed_domains:它是允許爬取的域名,如果初始或后續(xù)的請求鏈接不是這個域名下的,則請求鏈接會被過濾掉。 start_urls:它包含了 Spider 在啟動時爬取的 url 列表,初始請求是由它來定義的。 parse:它是 Spider 的一個方法。默認(rèn)情況下,被調(diào)用時 start_urls 里面的鏈接構(gòu)成的請求完成下載執(zhí)行后,返回的響應(yīng)就會作為唯一的參數(shù)傳遞給這個函數(shù)。該方法負責(zé)解析返回的響應(yīng)、提取數(shù)據(jù)或者進一步生成要處理的請求。
創(chuàng)建 Item
Item 是保存爬取數(shù)據(jù)的容器,它的使用方法和字典類似。不過,相比字典,Item 多了額外的保護機制,可以避免拼寫錯誤或者定義字段錯誤。
創(chuàng)建 Item 需要繼承 scrapy.Item 類,并且定義類型為 scrapy.Field 的字段。觀察目標(biāo)網(wǎng)站,我們可以獲取到的內(nèi)容有 text、author、tags。
定義 Item ,此時進入 items.py 修改如下:
import?scrapy
class?QuoteItem(scrapy.Item):
????text?=?scrapy.Field()
????author?=?scrapy.Field()
????tags?=?scrapy.Field()
定義了三個字段,并將類的名稱修改為 QuoteItem ,接下來爬取時會使用到這個 Item。
解析 Response
parse 方法的參數(shù) response 是 start_urls 里面的鏈接爬取后的結(jié)果。所以在 parse 方法中,我們可以直接對 response 變量包含的內(nèi)容進行解析,比如瀏覽請求結(jié)果的網(wǎng)頁源代碼,或者進一步分析源代碼內(nèi)容,或者找出結(jié)果中的鏈接而得到下一個請求。
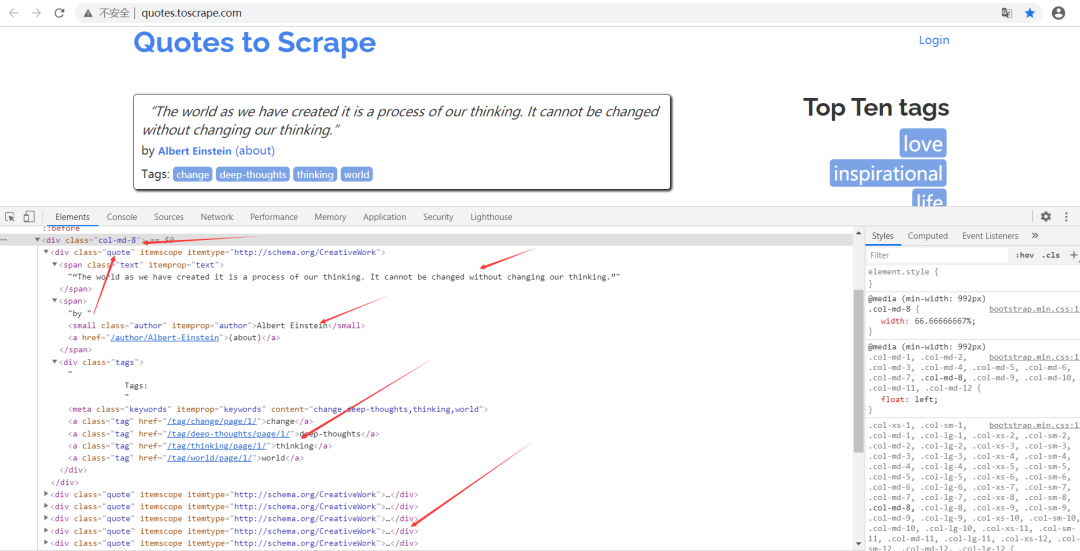
可以看到網(wǎng)頁中既有想要提取的數(shù)據(jù),又有下一頁的鏈接,這兩部分內(nèi)容都可以進行處理。
首先看看網(wǎng)頁結(jié)構(gòu),如圖所示。每一頁都有多個 class 為 quote 的區(qū)塊,每個區(qū)塊內(nèi)都包含 text、author、tags。那么我們先找出所有的 quote,然后提取每一個 quote 中的內(nèi)容。
提取數(shù)據(jù)的方式可以是 CSS 選擇器 或 XPath 選擇器
使用 Item
上文定義了 Item,接下來就要使用它了。Item 可以理解為一個字典,不過在聲明的時候需要實例化。然后依次用剛才解析的結(jié)果賦值 Item 的每一個字段,最后將 Item 返回即可。
import?scrapy
from?practice.items?import?QuoteItem
class?QuotesSpider(scrapy.Spider):
????name?=?'quotes'
????allowed_domains?=?['quotes.toscrape.com']
????start_urls?=?['http://quotes.toscrape.com/']
????def?parse(self,?response,?**kwargs):
????????quotes?=?response.css('.quote')
????????for?quote?in?quotes:
????????????item?=?QuoteItem()
????????????item['text']?=?quote.css('.text::text').extract_first()
????????????item['author']?=?quote.css('.author::text').extract_first()
????????????item['tags']?=?quote.css('.tags?.tag::text').extract()
????????????yield?item
后續(xù) Request
上面的操作實現(xiàn)了從初始頁面抓取內(nèi)容。實現(xiàn)翻頁爬取,這就需要從當(dāng)前頁面中找到信息來生成下一個請求,然后在下一個請求的頁面里找到信息再構(gòu)造下一個請求。這樣循環(huán)往復(fù)迭代,從而實現(xiàn)整站的爬取。
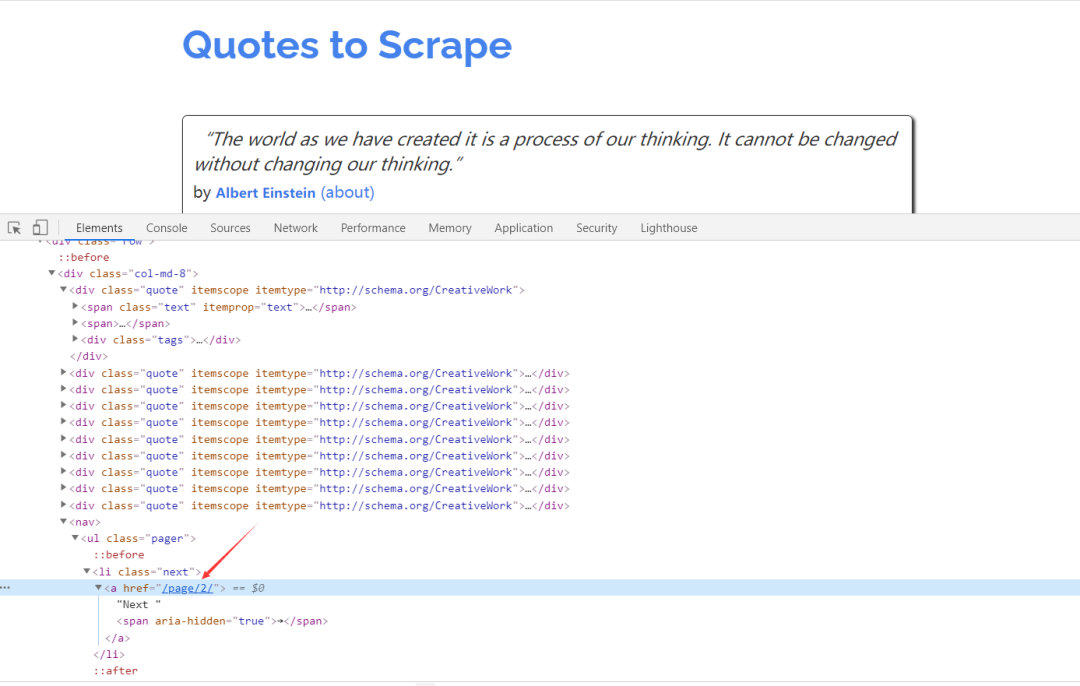
查看網(wǎng)頁源代碼,可以發(fā)現(xiàn)下一頁的鏈接是 /page/2/,但實際上全鏈接為:http://quotes.toscrape.com/page/2/,通過這個鏈接就可以構(gòu)造下一個請求。
構(gòu)造請求時需要用到 scrapy.Request。這里我們傳遞兩個參數(shù)——url 和 callback,這兩個參數(shù)的說明如下:
url:它是請求鏈接 callback:它是回調(diào)函數(shù)。當(dāng)指定了該回調(diào)函數(shù)的請求完成之后,獲取到響應(yīng),引擎會將該響應(yīng)作為參數(shù)傳遞給這個回調(diào)函數(shù)。回調(diào)函數(shù)進行解析或生成下一個請求,回調(diào)函數(shù)如上文的 parse() 所示。
由于 parse 就是解析 text、author、tags 的方法,而下一頁的結(jié)構(gòu)和剛才已經(jīng)解析的頁面結(jié)構(gòu)是一樣的,所以我們可以再次使用 parse 方法來做頁面解析。
"""
@Author ?:葉庭云
@Date ???:2020/10/2 11:40
@CSDN ???:https://blog.csdn.net/fyfugoyfa
"""
import?scrapy
from?practice.items?import?QuoteItem
class?QuotesSpider(scrapy.Spider):
????name?=?'quotes'
????allowed_domains?=?['quotes.toscrape.com']
????start_urls?=?['http://quotes.toscrape.com/']
????def?parse(self,?response,?**kwargs):
????????quotes?=?response.css('.quote')
????????for?quote?in?quotes:
????????????item?=?QuoteItem()
????????????item['text']?=?quote.css('.text::text').extract_first()
????????????item['author']?=?quote.css('.author::text').extract_first()
????????????item['tags']?=?quote.css('.tags?.tag::text').extract()
????????????yield?item
????????next_page?=?response.css('.pager?.next?a::attr("href")').extract_first()
????????next_url?=?response.urljoin(next_page)
????????yield?scrapy.Request(url=next_url,?callback=self.parse)
運行
接下來,進入目錄,運行如下命令:
scrapy?crawl?quotes?-o?quotes.csv
命令運行后,項目內(nèi)多了一個 quotes.csv 文件,文件包含了剛才抓取的所有內(nèi)容。
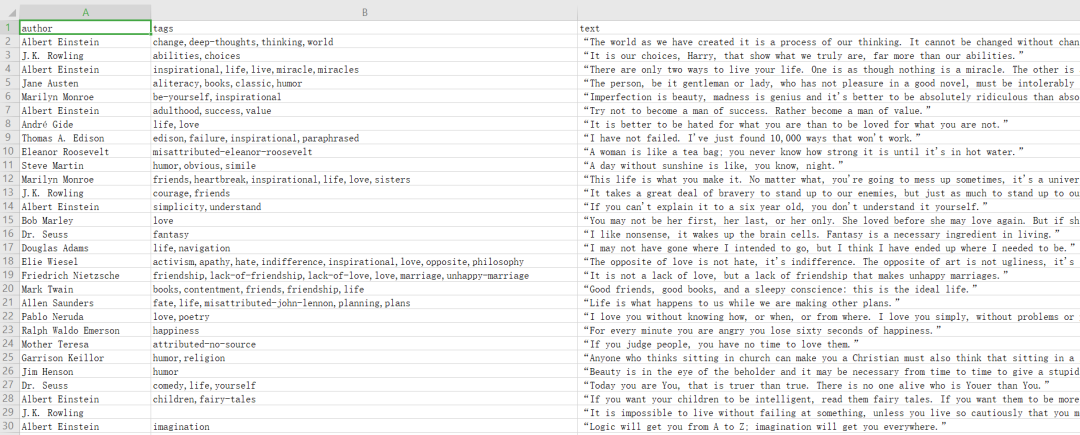
輸出格式還支持很多種,例如 json、xml、pickle、marshal 等,還支持 ftp、s3 等遠程輸出,另外還可以通過自定義 ItemExporter 來實現(xiàn)其他的輸出。
scrapy?crawl?quotes?-o?quotes.json
scrapy?crawl?quotes?-o?quotes.xml
scrapy?crawl?quotes?-o?quotes.pickle
scrapy?crawl?quotes?-o?quotes.marshal
scrapy?crawl?quotes?-o?ftp://user:pass@ftp.example.com/path/to/quotes.csv
其中,ftp 輸出需要正確配置用戶名、密碼、地址、輸出路徑,否則會報錯。
通過 scrapy 提供的 Feed Exports,我們可以輕松地輸出抓取結(jié)果到文件,對于一些小型項目來說,這應(yīng)該足夠了。不過如果想要更復(fù)雜的輸出,如輸出到數(shù)據(jù)庫等,可以靈活使用 Item Pileline 來完成。
實例 2:爬取圖片
目標(biāo)URL:http://sc.chinaz.com/tupian/dangaotupian.html
創(chuàng)建項目
scrapy?startproject?get_img
cd?get_img
scrapy?genspider?img_spider?sc.chinaz.com
構(gòu)造請求
img_spider.py 中定義 start_requests() 方法,比如爬取這個網(wǎng)站里的蛋糕圖片,爬取頁數(shù)為 10 ,生成 10 次請求,如下所示:
????def?start_requests(self):
????????for?i?in?range(1,?11):
????????????if?i?==?1:
????????????????url?=?'http://sc.chinaz.com/tupian/dangaotupian.html'
????????????else:
????????????????url?=?f'http://sc.chinaz.com/tupian/dangaotupian_{i}.html'
????????????yield?scrapy.Request(url,?self.parse)
編寫 items.py
import?scrapy
class?GetImgItem(scrapy.Item):
????img_url?=?scrapy.Field()
????img_name?=?scrapy.Field()
編寫 img_spider.py
Spider 類定義了如何爬取某個(或某些)網(wǎng)站,包括了爬取的動作(例如:是否跟進鏈接)以及如何從網(wǎng)頁的內(nèi)容中提取結(jié)構(gòu)化數(shù)據(jù)(抓取item)
"""
@Author ?:葉庭云
@Date ???:2020/10/2 11:40
@CSDN ???:https://blog.csdn.net/fyfugoyfa
"""
import?scrapy
from?get_img.items?import?GetImgItem
class?ImgSpiderSpider(scrapy.Spider):
????name?=?'img_spider'
????def?start_requests(self):
????????for?i?in?range(1,?11):
????????????if?i?==?1:
????????????????url?=?'http://sc.chinaz.com/tupian/dangaotupian.html'
????????????else:
????????????????url?=?f'http://sc.chinaz.com/tupian/dangaotupian_{i}.html'
????????????yield?scrapy.Request(url,?self.parse)
????def?parse(self,?response,?**kwargs):
????????src_list?=?response.xpath('//div[@id="container"]/div/div/a/img/@src2').extract()
????????alt_list?=?response.xpath('//div[@id="container"]/div/div/a/img/@alt').extract()
????????for?alt,?src?in?zip(alt_list,?src_list):
????????????item?=?GetImgItem()???????#?生成item對象
????????????#?賦值
????????????item['img_url']?=?src
????????????item['img_name']?=?alt
????????????yield?item
編寫管道文件 pipelines.py
Scrapy 提供了專門處理下載的 Pipeline ,包括文件下載和圖片下載。下載文件和圖片的原理與抓取頁面的原理一樣,因此下載過程支持異步和多線程,十分高效。
from?scrapy.pipelines.images?import?ImagesPipeline??#?scrapy圖片下載器
from?scrapy?import?Request
from?scrapy.exceptions?import?DropItem
class?GetImgPipeline(ImagesPipeline):
????#?請求下載圖片
????def?get_media_requests(self,?item,?info):
????????yield?Request(item['img_url'],?meta={'name':?item['img_name']})
????def?item_completed(self,?results,?item,?info):
????????#?分析下載結(jié)果并剔除下載失敗的圖片
????????image_paths?=?[x['path']?for?ok,?x?in?results?if?ok]
????????if?not?image_paths:
????????????raise?DropItem("Item?contains?no?images")
????????return?item
????#?重寫file_path方法,將圖片以原來的名稱和格式進行保存
????def?file_path(self,?request,?response=None,?info=None):
????????name?=?request.meta['name']??#?接收上面meta傳遞過來的圖片名稱
????????file_name?=?name?+?'.jpg'????#?添加圖片后綴名
????????return?file_name
在這里實現(xiàn)了 GetImagPipeline,繼承 Scrapy 內(nèi)置的 ImagesPipeline,重寫了下面幾個方法:
get_media_requests()。它的第一個參數(shù) item 是爬取生成的 Item 對象。我們將它的 url 字段取出來,然后直接生成 Request 對象。此 Request 加入調(diào)度隊列,等待被調(diào)度,執(zhí)行下載。 item_completed(),它是當(dāng)單個 Item 完成下載時的處理方法。因為可能有個別圖片未成功下載,所以需要分析下載結(jié)果并剔除下載失敗的圖片。該方法的第一個參數(shù) results 就是該 Item 對應(yīng)的下載結(jié)果,它是一個列表形式,列表每一個元素是一個元組,其中包含了下載成功或失敗的信息。這里我們遍歷下載結(jié)果找出所有成功的下載列表。如果列表為空,那么說明該 Item 對應(yīng)的圖片下載失敗了,隨即拋出異常DropItem,該 Item 忽略。否則返回該 Item,說明此 Item 有效。 file_path(),它的第一個參數(shù) request 就是當(dāng)前下載對應(yīng)的 Request 對象。這個方法用來返回保存的文件名,接收上面meta傳遞過來的圖片名稱,將圖片以原來的名稱和定義格式進行保存。
配置文件 settings.py
#?setting.py
BOT_NAME?=?'get_img'
SPIDER_MODULES?=?['get_img.spiders']
NEWSPIDER_MODULE?=?'get_img.spiders'
#?Crawl?responsibly?by?identifying?yourself?(and?your?website)?on?the?user-agent
USER_AGENT?=?'Mozilla/5.0?(Windows?NT?6.1;?Win64;?x64)?AppleWebKit/537.36?(KHTML,?like?Gecko)?Chrome/58.0.3029.110?Safari/537.36'
#?Obey?robots.txt?rules
ROBOTSTXT_OBEY?=?False
#?Configure?maximum?concurrent?requests?performed?by?Scrapy?(default:?16)
CONCURRENT_REQUESTS?=?32
#?Configure?a?delay?for?requests?for?the?same?website?(default:?0)
#?See?https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
#?See?also?autothrottle?settings?and?docs
DOWNLOAD_DELAY?=?0.25
#?Configure?item?pipelines
#?See?https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES?=?{
???'get_img.pipelines.GetImgPipeline':?300,
}
IMAGES_STORE?=?'./images'???#?設(shè)置保存圖片的路徑?會自動創(chuàng)建
運行程序:
#?切換路徑到img_spider的目錄
scrapy?crawl?img_spider
scrapy 框架爬蟲一邊爬取一邊下載,下載速度非常快。
查看本地 images 文件夾,發(fā)現(xiàn)圖片都已經(jīng)成功下載,如圖所示:

到現(xiàn)在為止我們就大體知道了 Scrapy 的基本架構(gòu)并實操創(chuàng)建了一個 Scrapy 項目,編寫代碼進行了實例抓取,熟悉了 scrapy 爬蟲框架的基本使用。之后還需要更加詳細地了解和學(xué)習(xí) scrapy 的用法,感受它的強大。
作者簡介:
葉庭云
個人格言: 熱愛可抵歲月漫長
CSDN博客: https://blog.csdn.net/fyfugoyfa/
往期精彩回顧
獲取一折本站知識星球優(yōu)惠券,復(fù)制鏈接直接打開:
https://t.zsxq.com/y7uvZF6
本站qq群704220115。
加入微信群請掃碼: