
iOS底層 - 關(guān)于死鎖,你了解多少?
作者 阿華12年,原文發(fā)表于掘金,點擊閱讀原文查看作者更多文章
https://juejin.cn/post/6994698940843032612
前言
我們從GCD函數(shù)和隊列的內(nèi)容中最后的經(jīng)典案例中關(guān)于死鎖的案例開始,從死鎖的發(fā)生開始,看看其產(chǎn)生的本質(zhì)原因是為什么。話不多說這就開始。
引用我們在GCD函數(shù)和隊列一文中和死鎖相關(guān)的內(nèi)容:
創(chuàng)建串行調(diào)度隊列的解釋:
當我們希望任務(wù)以特定的順序執(zhí)行時,串行隊列很有用。串行隊列一次只執(zhí)行一個任務(wù),并且總是從隊列的頭部拉去任務(wù)。我們可以使用串行隊列而不是鎖來保護共享資源或可變數(shù)據(jù)結(jié)構(gòu)。與鎖不同,串行隊列確保任務(wù)以可以預(yù)測的順序執(zhí)行。而且 只要我們將任務(wù)異步提交到串行隊列,隊列就永遠不會死鎖。
在將單個任務(wù)添加到隊列中的解釋:
有兩種方法可以將任務(wù)添加到隊列中:異步或同步。如果可能,使用dispatch_async和dispatch_async_f函數(shù)的異步執(zhí)行優(yōu)先于同步替代方案。當您將塊對象或函數(shù)添加到隊列時,無法知道該代碼何時執(zhí)行。因此,異步添加塊或函數(shù)可讓您安排代碼的執(zhí)行并繼續(xù)從調(diào)用線程執(zhí)行其他工作。如果您從應(yīng)用程序的主線程調(diào)度任務(wù),這尤其重要——也許是為了響應(yīng)某些用戶事件。
盡管您應(yīng)該盡可能以異步方式添加任務(wù),但有時您仍可能需要同步添加任務(wù)以防止競爭條件或其他同步錯誤。在這些情況下,您可以使用dispatch_sync和dispatch_sync_f函數(shù)將任務(wù)添加到隊列中。這些函數(shù)會阻塞當前的執(zhí)行線程,直到指定的任務(wù)完成執(zhí)行。
重要提示: 您永遠不應(yīng)從在您計劃傳遞給函數(shù)的同一隊列中執(zhí)行的任務(wù)調(diào)用dispatch_sync或dispatch_sync_f函數(shù)。這對于保證死鎖的串行隊列尤其重要,但對于并發(fā)隊列也應(yīng)避免。
以上兩部分內(nèi)容,是在闡述串行隊列的概念解釋和將任務(wù)添加到隊列中的兩種方式的規(guī)范內(nèi)容。總的來說,是幫助我們在正確使用串行隊列,以及在將任務(wù)添加到隊列中時,避免死鎖的發(fā)生。
下面,我們從案例中的死鎖開始。
死鎖的發(fā)生
正如上面的重要提示中鎖闡述的一樣,我們永遠不應(yīng)該將函數(shù)添加到隊列中執(zhí)行任務(wù)時使用同步的方式。這對于保證死鎖的串行隊列尤其重要,但對于并發(fā)隊列也應(yīng)避免。
的確,這是避免死鎖的重要思路,但是,還是難以避免,在實際開發(fā)中,我們使用了下面的代碼:
串行隊列,同步函數(shù)中同步函數(shù)
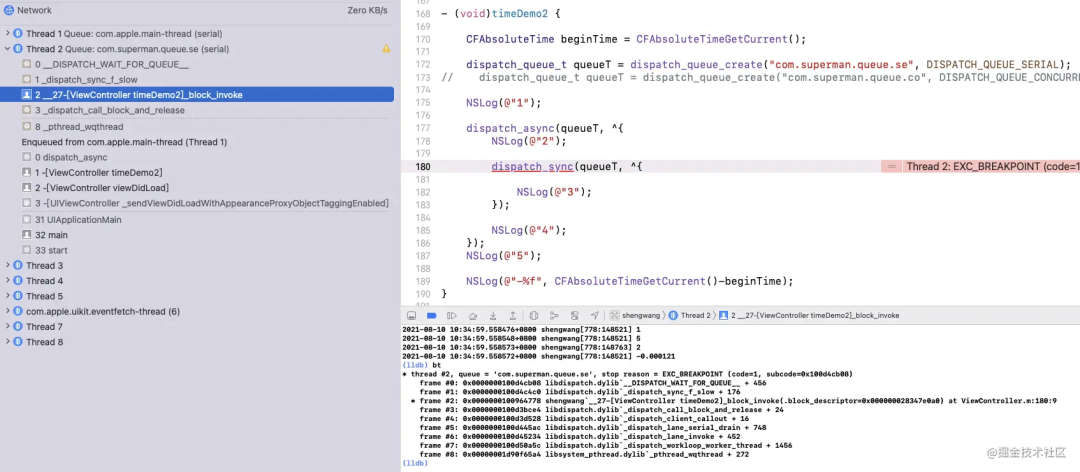
第180行,我們的程序發(fā)生來死鎖,從堆棧的信息中可以看到是 :
libdispatch.dylib _dispatch_sync_f_slow: -> libdispatch.dylib __DISPATCH_WAIT_FOR_QUEUE__:
跟蹤流程
在180行,打上斷點。在GCD函數(shù)和隊列篇章中,我們知道dispatch_syn函數(shù)的執(zhí)行流程如下:
dispatch_sync -> _dispatch_sync_f -> _dispatch_sync_f_inline
在_dispatch_sync_f_inline中,有五條分支,我們分別下五個符號斷點:
_dispatch_sync_f_inline
static inline void
_dispatch_sync_f_inline(dispatch_queue_t dq, void *ctxt,
dispatch_function_t func, uintptr_t dc_flags)
{
if (likely(dq->dq_width == 1)) {
return _dispatch_barrier_sync_f(dq, ctxt, func, dc_flags);
}
if (unlikely(dx_metatype(dq) != _DISPATCH_LANE_TYPE)) {
DISPATCH_CLIENT_CRASH(0, "Queue type doesn't support dispatch_sync");
}
dispatch_lane_t dl = upcast(dq)._dl;
// 全局并發(fā)隊列和綁定到非分派線程的隊列
// 總是落在慢的情況下 DISPATCH_ROOT_QUEUE_STATE_INIT_VALUE
if (unlikely(!_dispatch_queue_try_reserve_sync_width(dl))) {
return _dispatch_sync_f_slow(dl, ctxt, func, 0, dl, dc_flags);
}
if (unlikely(dq->do_targetq->do_targetq)) {
return _dispatch_sync_recurse(dl, ctxt, func, dc_flags);
}
_dispatch_introspection_sync_begin(dl);
_dispatch_sync_invoke_and_complete(dl, ctxt, func DISPATCH_TRACE_ARG(
_dispatch_trace_item_sync_push_pop(dq, ctxt, func, dc_flags)));
}
先來到了 _dispatch_barrier_sync_f 分支
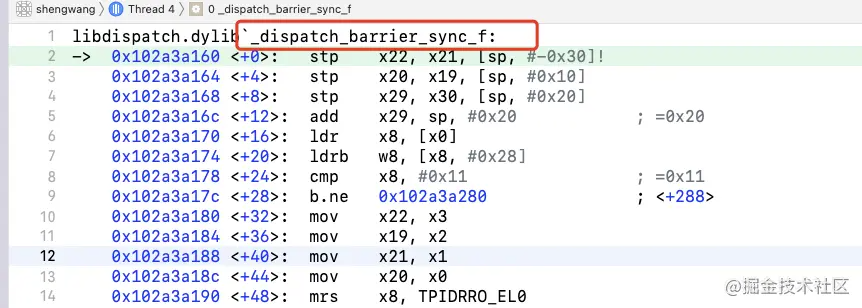
_dispatch_barrier_sync_f
static void
_dispatch_barrier_sync_f(dispatch_queue_t dq, void *ctxt,
dispatch_function_t func, uintptr_t dc_flags)
{
_dispatch_barrier_sync_f_inline(dq, ctxt, func, dc_flags);
}
再下 _dispatch_barrier_sync_f_inline 符號斷點, 很遺憾沒有斷住,直接來到了 _dispatch_sync_f_slow :
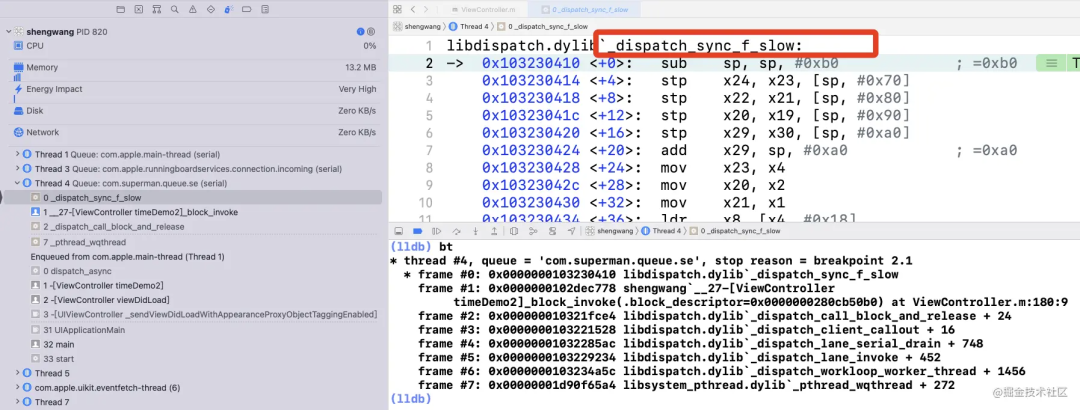
我們來到 _dispatch_barrier_sync_f_inline 內(nèi)部的實現(xiàn):
_dispatch_barrier_sync_f_inline
DISPATCH_ALWAYS_INLINE
static inline void
_dispatch_barrier_sync_f_inline(dispatch_queue_t dq, void *ctxt,
dispatch_function_t func, uintptr_t dc_flags)
{
dispatch_tid tid = _dispatch_tid_self();
if (unlikely(dx_metatype(dq) != _DISPATCH_LANE_TYPE)) {
DISPATCH_CLIENT_CRASH(0, "Queue type doesn't support dispatch_sync");
}
dispatch_lane_t dl = upcast(dq)._dl;
// 更正確的做法是合并線程的qos
// 剛剛獲得了進入隊列狀態(tài)的barrier鎖。
//
// 然而,這對于快速路徑來說太昂貴了,所以跳過它。
// 選擇的權(quán)衡是,如果隊列在較低優(yōu)先級的線程上
// 與此快速路徑,此線程可能收到無用的覆蓋。
//
// 全局并發(fā)隊列和綁定到非分派線程的隊列
// 總是落在慢的情況下 DISPATCH_ROOT_QUEUE_STATE_INIT_VALUE
if (unlikely(!_dispatch_queue_try_acquire_barrier_sync(dl, tid))) {
return _dispatch_sync_f_slow(dl, ctxt, func, DC_FLAG_BARRIER, dl,
DC_FLAG_BARRIER | dc_flags);
}
if (unlikely(dl->do_targetq->do_targetq)) {
return _dispatch_sync_recurse(dl, ctxt, func,
DC_FLAG_BARRIER | dc_flags);
}
_dispatch_introspection_sync_begin(dl);
_dispatch_lane_barrier_sync_invoke_and_complete(dl, ctxt, func
DISPATCH_TRACE_ARG(_dispatch_trace_item_sync_push_pop(
dq, ctxt, func, dc_flags | DC_FLAG_BARRIER)));
}
(_dispatch_sync_f_inline 和 _dispatch_barrier_sync_f_inline 內(nèi)部實現(xiàn)有點相似)
其內(nèi)部的第二個分支便是調(diào)用 _dispatch_sync_f_slow
_dispatch_sync_f_slow
DISPATCH_NOINLINE
static void
_dispatch_sync_f_slow(dispatch_queue_class_t top_dqu, void *ctxt,
dispatch_function_t func, uintptr_t top_dc_flags,
dispatch_queue_class_t dqu, uintptr_t dc_flags)
{
dispatch_queue_t top_dq = top_dqu._dq;
dispatch_queue_t dq = dqu._dq;
if (unlikely(!dq->do_targetq)) {
return _dispatch_sync_function_invoke(dq, ctxt, func);
}
pthread_priority_t pp = _dispatch_get_priority();
struct dispatch_sync_context_s dsc = {
.dc_flags = DC_FLAG_SYNC_WAITER | dc_flags,
.dc_func = _dispatch_async_and_wait_invoke,
.dc_ctxt = &dsc,
.dc_other = top_dq,
.dc_priority = pp | _PTHREAD_PRIORITY_ENFORCE_FLAG,
.dc_voucher = _voucher_get(),
.dsc_func = func,
.dsc_ctxt = ctxt,
.dsc_waiter = _dispatch_tid_self(),
};
_dispatch_trace_item_push(top_dq, &dsc);
__DISPATCH_WAIT_FOR_QUEUE__(&dsc, dq);
if (dsc.dsc_func == NULL) {
// dsc_func being cleared means that the block ran on another thread ie.
// case (2) as listed in _dispatch_async_and_wait_f_slow.
dispatch_queue_t stop_dq = dsc.dc_other;
return _dispatch_sync_complete_recurse(top_dq, stop_dq, top_dc_flags);
}
_dispatch_introspection_sync_begin(top_dq);
_dispatch_trace_item_pop(top_dq, &dsc);
_dispatch_sync_invoke_and_complete_recurse(top_dq, ctxt, func,top_dc_flags
DISPATCH_TRACE_ARG(&dsc));
}
看到其實現(xiàn)內(nèi)容,依然會覺得和上面兩個(_dispatch_sync_f_inline 和 _dispatch_barrier_sync_f_inline) 有點相似。
再次根據(jù)分支下符號斷點,就斷不住了,直接會崩潰,根據(jù)堆棧,我們會來到:__DISPATCH_WAIT_FOR_QUEUE__(&dsc, dq) 的執(zhí)行。
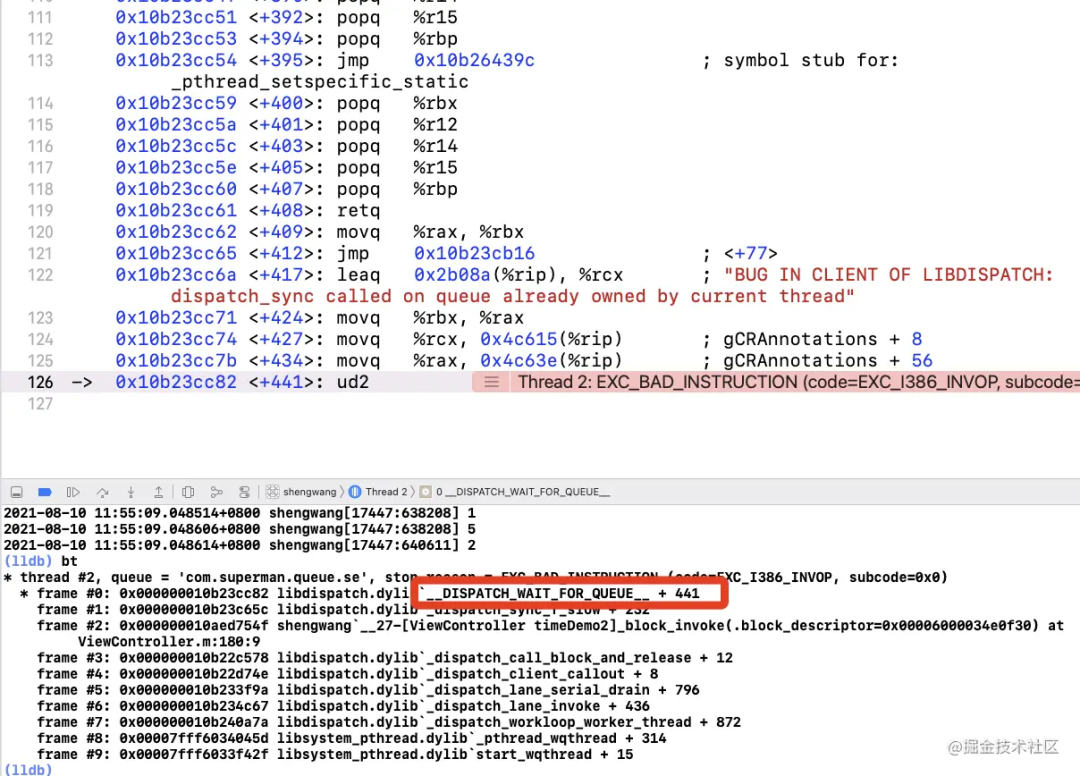
最終奔潰的點
__DISPATCH_WAIT_FOR_QUEUE__
DISPATCH_NOINLINE
static void
__DISPATCH_WAIT_FOR_QUEUE__(dispatch_sync_context_t dsc, dispatch_queue_t dq)
{
uint64_t dq_state = _dispatch_wait_prepare(dq);
if (unlikely(_dq_state_drain_locked_by(dq_state, dsc->dsc_waiter))) {
DISPATCH_CLIENT_CRASH((uintptr_t)dq_state,
"dispatch_sync called on queue "
"already owned by current thread");
}
...
}
程序崩潰在這里,那么,我們就需要重點分析下這里的 if 判斷條件是什么?符合了怎樣的條件,以至于程序崩潰的發(fā)生。
函數(shù)對比的兩個內(nèi)容:
// 1、當前的隊列線程的線程ID
#define _dispatch_tid_self() ((dispatch_tid)_dispatch_thread_port())
#define _dispatch_thread_port() pthread_mach_thread_np(_dispatch_thread_self())
#define _dispatch_thread_self() ((uintptr_t)pthread_self())
// 2、隊列的狀態(tài)
_dispatch_wait_prepare(dq);
_dq_state_drain_locked_by
ISPATCH_ALWAYS_INLINE
static inline bool
_dq_state_drain_locked_by(uint64_t dq_state, dispatch_tid tid)
{
return _dispatch_lock_is_locked_by((dispatch_lock)dq_state, tid);
}
#define DLOCK_OWNER_MASK ((dispatch_lock)0xfffffffc)
DISPATCH_ALWAYS_INLINE
static inline bool
_dispatch_lock_is_locked_by(dispatch_lock lock_value, dispatch_tid tid)
{
// equivalent to _dispatch_lock_owner(lock_value) == tid
// DLOCK_OWNER_MASK 是一個很大的數(shù) ((dispatch_lock)0xfffffffc)
// 前面的結(jié)果只要不為0 與上 DLOCK_OWNER_MASK 也不為0
// 如果前面的結(jié)果與上DLOCK_OWNER_MASK結(jié)果為0 那前面的結(jié)果 必然為0
// 最終, lock_value 和 tid 相同 才會 為 0
return ((lock_value ^ tid) & DLOCK_OWNER_MASK) == 0;
}
總結(jié)
最后, 本來這個鎖住要等待的線程的狀態(tài)和我們的線程ID相同。也就是我們的線程本來應(yīng)該在等待狀態(tài),然而這個時候,又調(diào)用了線程的隊列來添加任務(wù),告訴系統(tǒng)要調(diào)起此線程,結(jié)果在我們的系統(tǒng)中此線程又是等待的狀態(tài)。所以,此次添加任務(wù)是無法實現(xiàn)的。
在這里,又要調(diào)起線程,然后線程又是等待狀態(tài),此時就是一個矛盾,無法繼續(xù)執(zhí)行下去,所以就發(fā)生了死鎖。