
快速指南:使用OpenCV預處理神經(jīng)網(wǎng)絡(luò)中的面部圖像
點擊上方“小白學視覺”,選擇加"星標"或“置頂”
重磅干貨,第一時間送達

本期將介紹臉部檢測、眼睛檢測;圖像拉直、裁剪、調(diào)整大小、歸一化等內(nèi)容

目前,涉及面部分類的計算機視覺問題,通常都需要使用深度學習。因此在將圖像輸入神經(jīng)網(wǎng)絡(luò)之前,需要經(jīng)過一個預處理階段,以便達到更好的分類效果。
圖像預處理通常來說非常簡單,只需執(zhí)行幾個簡單的步驟即可輕松完成。但為了提高模型的準確性,這也是一項非常重要的任務。對于這些問題,我們可以使用OpenCV完成:一個針對(實時)計算機視覺應用程序的高度優(yōu)化的開源庫,包括C ++,Java和Python語言。
接下來我們將一起探索可能會應用在每個面部分類或識別問題上應用的基本原理,示例和代碼。
注意:下面使用的所有圖像均來自memes.。
我們使用該imread()函數(shù)加載圖像,并指定文件路徑和圖像模式。第二個參數(shù)對于運行基本通道和深度轉(zhuǎn)換很重要。
img = cv2.imread('path/image.jpg', cv2.IMREAD_COLOR)
要查看圖像可以使用imshow()功能:
cv2.imshow(img)

如果使用的type(img)話,將顯示該圖像的尺寸包括高度、重量、通道數(shù)。
彩色圖像有3個通道:藍色,綠色和紅色(在OpenCV中按此順序)。

我們可以很輕松查看單個通道:
# Example for green channel
img[:, :, 0]; img[:, :, 2]; cv2.imshow(img)
Grayscale version
為了避免在人臉圖像分類過程中存在的干擾,通常選擇黑白圖像(當然也可以使用彩圖!請小伙伴們自行嘗試兩者并比較結(jié)果)。要獲得灰度圖像,我們只需要在圖像加載函數(shù)中通過將適當?shù)闹底鳛榈诙€參數(shù)傳遞來指定它:
img = cv2.imread('path/image.jpg', cv2.IMREAD_GRAYSCALE)

現(xiàn)在,我們的圖像只有一個灰度通道了!
在處理人臉分類問題時,我們可能需要先對圖形進行裁剪和拉直,再進行人臉檢測以驗證是否有人臉的存在。為此,我們將使用OpenCV中自帶的的基于Haar特征的級聯(lián)分類器進行對象檢測。
首先,我們選擇用于面部和眼睛檢測的預訓練分類器。以下時可用的XML文件列表:
1)對于面部檢測,OpenCV提供了這些(從最松的先驗到最嚴格的先驗):
? haarcascade_frontalface_default.xml
? haarcascade_frontalface_alt.xml
? haarcascade_frontalface_alt2.xml
? haarcascade_frontalface_alt_tree.xml
2)對于眼睛檢測,我們可以選擇以下兩種:
? haarcascade_eye.xml
? haarcascade_eye_tree_eyeglasses.xml(正在嘗試處理眼鏡!)
我們以這種方式加載預訓練的分類器:
face_cascade = cv2.CascadeClassifier(cv2.data.haarcascades + ‘haarcascade_frontalface_default.xml’)eyes_cascade = cv2.CascadeClassifier(cv2.data.haarcascades + ‘haarcascade_eye.xml’)
我們可以測試幾種組合,但我們要記住一點,沒有一種分類器在所有情況下都是最好的(如果第一個分類失敗,您可以嘗試第二個分類,甚至嘗試所有分類)。
對于人臉檢測,我們可使用以下代碼:
faces_detected = face_cascade.detectMultiScale(img, scaleFactor=1.1, minNeighbors=5)
結(jié)果是一個數(shù)組,其中包含所有檢測到的臉部特征的矩形位置。我們可以很容易地繪制它:
(x, y, w, h) = faces_detected[0]
cv2.rectangle(img, (x, y), (x+w, y+h), (0, 255, 0), 1);
cv2.imshow(img)

對于眼睛,我們以類似的方式進行,但將搜索范圍縮小到剛剛提取出來的面部矩形框內(nèi):
eyes = eyes_cascade.detectMultiScale(img[y:y+h, x:x+w])for (ex, ey, ew, eh) in eyes:
cv2.rectangle(img, (x+ex, y+ey), (x+ex+ew, y+ey+eh),
(255, 255, 255), 1)

盡管這是預期的結(jié)果,但是很多時候再提取的過程中我們會遇到一些難以解決的問題。比如我們沒有正面清晰的人臉視圖。

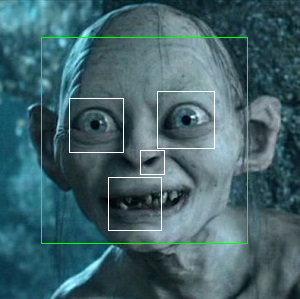

不能正確檢測的案例
通過計算兩只眼睛之間的角度,我們就可以拉直面部圖像(這很容易)。計算之后,我們僅需兩個步驟即可旋轉(zhuǎn)圖像:
rows, cols = img.shape[:2]
M = cv2.getRotationMatrix2D((cols/2, rows/2), <angle>, 1)
img_rotated = cv2.warpAffine(face_orig, M, (cols,rows))

為了幫助我們的神經(jīng)網(wǎng)絡(luò)完成面部分類任務,最好去除外界無關(guān)信息,例如背景,衣服或配件。在這些情況下,面部裁切非常方便。
我們需要做的第一件事是再次從旋轉(zhuǎn)后的圖像中獲取面部矩形。然后我們需要做出決定:我們可以按原樣裁剪矩形區(qū)域,也可以添加額外的填充,以便在周圍獲得更多空間。這取決于要解決的具體問題(按年齡,性別,種族等分類);也許我們需要保留頭發(fā),也許不需要。

最后進行裁剪(p用于填充):
cv2.imwrite('crop.jpg', img_rotated[y-p+1:y+h+p, x-p+1:x+w+p])
現(xiàn)在這張臉的圖像是非常單一的,基本可用于深度學習:

神經(jīng)網(wǎng)絡(luò)需要的所有輸入圖像具有相同的形狀和大小,因為GPU應用相同的指令處理一批相同大小圖像,可以達到較快的速度。我們雖然可以隨時調(diào)整它們的大小,但這并不是一個好主意,因為需要在訓練期間將對每個文件執(zhí)行幾次轉(zhuǎn)換。因此,如果我們的數(shù)據(jù)集包含大量圖像,我們應該考慮在訓練階段之前實施批量調(diào)整大小的過程。
在OpenCV中,我們可以與同時執(zhí)行縮小和升頻resize(),有幾個插值方法可用。指定最終大小的示例:
cv2.resize(img, (<width>, <height>), interpolation=cv2.INTER_LINEAR)
要縮小圖像,OpenCV建議使用INTER_AREA插值法,而放大圖像時,可以使用INTER_CUBIC(慢速)或INTER_LINEAR(更快,但效果仍然不錯)。最后,這是質(zhì)量和時間之間的權(quán)衡。
我對升級進行了快速比較:
 前兩個圖像似乎質(zhì)量更高(但是您可以觀察到一些壓縮偽像)。線性方法的結(jié)果顯然更平滑(沒有對比度)并且噪點更少(黑白圖像證明)。最后一個像素化。
前兩個圖像似乎質(zhì)量更高(但是您可以觀察到一些壓縮偽像)。線性方法的結(jié)果顯然更平滑(沒有對比度)并且噪點更少(黑白圖像證明)。最后一個像素化。
我們可以使用normalize()功能使視覺圖像標準化,以修復非常暗/亮的圖像(甚至可以修復低對比度)。該歸一化類型是在函數(shù)參數(shù)指定:
norm_img = np.zeros((300, 300))
norm_img = cv2.normalize(img, norm_img, 0, 255, cv2.NORM_MINMAX)
例子:

 當使用圖像作為深度卷積神經(jīng)網(wǎng)絡(luò)的輸入時,無需應用這種歸一化(上面的結(jié)果對我們來說似乎不錯,但是并不針對他們的眼睛)。在實踐中,我們將對每個通道進行適當?shù)臍w一化,例如減去均值并除以像素級別的標準差(這樣我們得到均值0和偏差1)。如果我們使用轉(zhuǎn)移學習,最好的方法總是使用預先訓練的模型統(tǒng)計信息。
當使用圖像作為深度卷積神經(jīng)網(wǎng)絡(luò)的輸入時,無需應用這種歸一化(上面的結(jié)果對我們來說似乎不錯,但是并不針對他們的眼睛)。在實踐中,我們將對每個通道進行適當?shù)臍w一化,例如減去均值并除以像素級別的標準差(這樣我們得到均值0和偏差1)。如果我們使用轉(zhuǎn)移學習,最好的方法總是使用預先訓練的模型統(tǒng)計信息。
當我們處理面部分類/識別問題時,如果輸入的圖像不是護照照片時,檢測和分離面部是一項常見的任務。
OpenCV是一個很好的圖像預處理任務庫,不僅限于此。對于許多計算機視覺應用來說,它也是一個很好的工具……

https://www.youtube.com/watch?v=GebcshN4OdE

https://www.youtube.com/watch?v=z1Cvn3_4yGo

https://github.com/vjgpt/Face-and-Emotion-Recognition
交流群
歡迎加入公眾號讀者群一起和同行交流,目前有SLAM、三維視覺、傳感器、自動駕駛、計算攝影、檢測、分割、識別、醫(yī)學影像、GAN、算法競賽等微信群(以后會逐漸細分),請掃描下面微信號加群,備注:”昵稱+學校/公司+研究方向“,例如:”張三 + 上海交大 + 視覺SLAM“。請按照格式備注,否則不予通過。添加成功后會根據(jù)研究方向邀請進入相關(guān)微信群。請勿在群內(nèi)發(fā)送廣告,否則會請出群,謝謝理解~