
【NLP】競賽必備的NLP庫
NLP必備的庫
本周我們給大家整理了機(jī)器學(xué)習(xí)和競賽相關(guān)的NLP庫,方便大家進(jìn)行使用,建議收藏本文。
import jiebaseg_list = jieba.cut("我來到北京清華大學(xué)", cut_all=True)print("Full Mode: " + "/ ".join(seg_list)) # 全模式# 【全模式】: 我/ 來到/ 北京/ 清華/ 清華大學(xué)/ 華大/ 大學(xué)seg_list = jieba.cut("我來到北京清華大學(xué)", cut_all=False)print("Default Mode: " + "/ ".join(seg_list)) # 精確模式# 【精確模式】: 我/ 來到/ 北京/ 清華大學(xué)seg_list = jieba.cut("他來到了網(wǎng)易杭研大廈") # 默認(rèn)是精確模式print(", ".join(seg_list))# 【新詞識別】:他, 來到, 了, 網(wǎng)易, 杭研, 大廈
spaCy是功能強(qiáng)化的NLP庫,可與深度學(xué)習(xí)框架一起運(yùn)行。spaCy提供了大多數(shù)NLP任務(wù)的標(biāo)準(zhǔn)功能(標(biāo)記化,PoS標(biāo)記,解析,命名實(shí)體識別)。spaCy與現(xiàn)有的深度學(xué)習(xí)框架接口可以一起使用,并預(yù)裝了常見的語言模型。
import spacy# Load English tokenizer, tagger, parser, NER and word vectorsnlp = spacy.load("en_core_web_sm")# Process whole documentstext = ("When Sebastian Thrun started working on self-driving cars at ""Google in 2007, few people outside of the company took him ""seriously. “I can tell you very senior CEOs of major American ""car companies would shake my hand and turn away because I wasn’t ""worth talking to,” said Thrun, in an interview with Recode earlier ""this week.")doc = nlp(text)# Analyze syntaxprint("Noun phrases:", [chunk.text for chunk in doc.noun_chunks])print("Verbs:", [token.lemma_ for token in doc if token.pos_ == "VERB"])# Find named entities, phrases and conceptsfor entity in doc.ents:print(entity.text, entity.label_)
spaCy項(xiàng)目主頁:https://spacy.io/
from gensim.test.utils import common_texts, get_tmpfilefrom gensim.models import Word2Vecpath = get_tmpfile("word2vec.model")model = Word2Vec(common_texts, size=100, window=5, min_count=1, workers=4)model.save("word2vec.model")
import nltksentence = """At eight o'clock on Thursday morningArthur didn't feel very good."""tokens = nltk.word_tokenize(sentence)tokens['At', 'eight', "o'clock", 'on', 'Thursday', 'morning','Arthur', 'did', "n't", 'feel', 'very', 'good', '.']tagged = nltk.pos_tag(tokens)tagged[0:6][('At', 'IN'), ('eight', 'CD'), ("o'clock", 'JJ'), ('on', 'IN'),('Thursday', 'NNP'), ('morning', 'NN')]
from textblob import TextBlobtext = '''The titular threat of The Blob has always struck me as the ultimate moviemonster: an insatiably hungry, amoeba-like mass able to penetratevirtually any safeguard, capable of--as a doomed doctor chillinglydescribes it--"assimilating flesh on contact.Snide comparisons to gelatin be damned, it's a concept with the mostdevastating of potential consequences, not unlike the grey goo scenarioproposed by technological theorists fearful ofartificial intelligence run rampant.'''blob = TextBlob(text)blob.tags # [('The', 'DT'), ('titular', 'JJ'),# ('threat', 'NN'), ('of', 'IN'), ...]blob.noun_phrases # WordList(['titular threat', 'blob',# 'ultimate movie monster',# 'amoeba-like mass', ...])for sentence in blob.sentences:print(sentence.sentiment.polarity)# 0.060# -0.341
TextBlob官網(wǎng):https://textblob.readthedocs.io/en/dev/


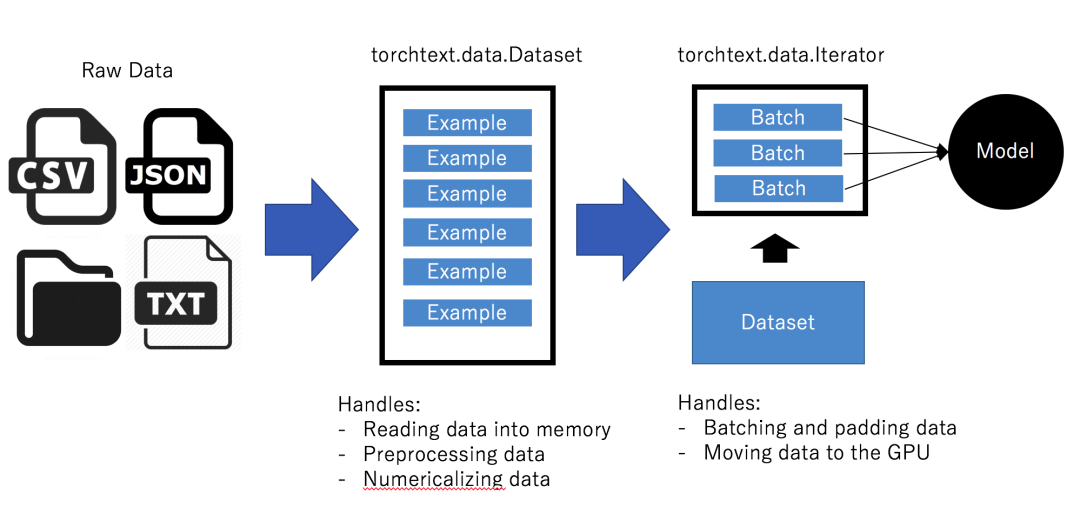
Transformers是現(xiàn)如今最流行的庫,它實(shí)現(xiàn)了從 BERT 和 GPT-2 到 BART 和 Reformer 的各種轉(zhuǎn)換。huggingface 的代碼可讀性強(qiáng)和文檔也是清晰易讀。在官方github的存儲庫中,甚至通過不同的任務(wù)來組織 python 腳本,例如語言建模、文本生成、問題回答、多項(xiàng)選擇等。

huggingface官網(wǎng):https://huggingface.co/
OpenNMT 是用于機(jī)器翻譯和序列學(xué)習(xí)任務(wù)的便捷而強(qiáng)大的工具。其包含的高度可配置的模型和培訓(xùn)過程,讓它成為了一個非常簡單的框架。因其開源且簡單的特性,建議大家使用 OpenNMT 進(jìn)行各種類型的序列學(xué)習(xí)任務(wù)。
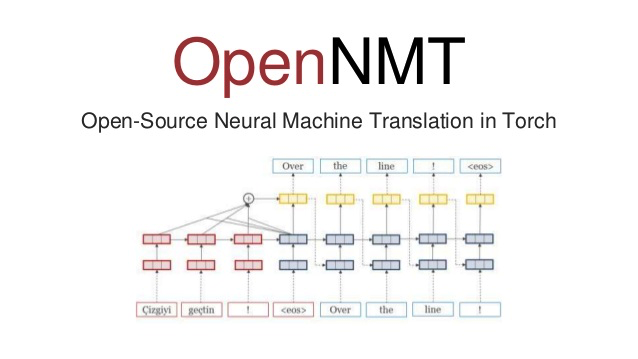
OpenNMT官網(wǎng):https://opennmt.net/
往期精彩回顧
獲取一折本站知識星球優(yōu)惠券,復(fù)制鏈接直接打開:
https://t.zsxq.com/662nyZF
本站qq群704220115。
加入微信群請掃碼進(jìn)群(如果是博士或者準(zhǔn)備讀博士請說明):